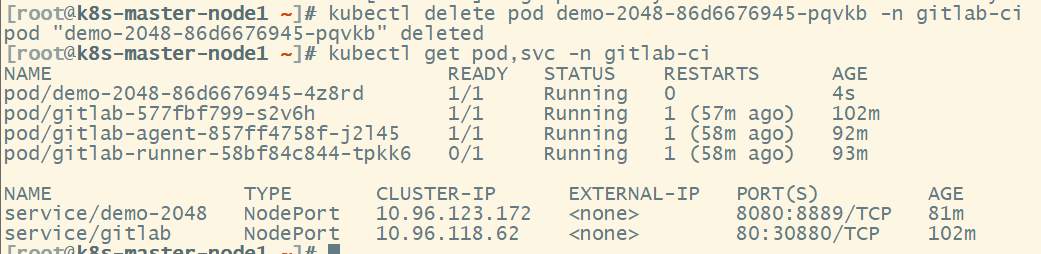
一、数据结构的本质
数据结构是组织大量数据的方法(data structures:methods of organizing large amounts of data
)。
根据这个定义,一条数据,就不能构成数据结构。
因为结构是数据与数据之间的关联,没有关联就形不成结构。
所以数据类型(比如int、char型)不是数据结构,普通变量也不是数据结构。
像数组(Array)、链表(Linked List)、队列(Queue)等都是能组织大量数据的,数据之间是有一定关系,这才能称为数据结构。
二、数据结构的常规操作
数据结构在操作上是具有一定的共通性的,常规操作有以下几种:
1.一般操作
(1)创建:建立一个数据结构。这是使用数据结构的第一步,例如创建一个新的数组、链表、栈、队列、集合或字典等。
(2)访问:指读取数据的值。不同数据结构的访问方式不同,如顺序访问(如链表,要通过遍历访问)、随机访问、索引访问(数组)等。
(3)清除:清除一个数据结构中的所有元素或数据。这个操作通常用于重置数据结构(比如数组)或释放其占用的内存资源(比如链表)。
2.关联性操作
普通变量也有创建和访问操作,但数据结构因为有多条数据,增加了一些关联性操作。
(1)四大操作:即插入、删除、更新、查找(即增删改查)。严格来说更新这个操作普通变量也是有的,但是这里的更新特指在一堆数据中找到要更新数据,再更改它的值。
(2)排序:对数据结构中各个元素按指定数据项的值进行排序。
需要说明的是,这里面没有列出“存储或赋值”操作,因为这一操作实际上已经隐含在创建建、插入、更新操作中。
三、数据结构的分类
1.线性数据结构
数据元素之间是一对一的关系,也就是元素一个接一个形成一条线,数据间是有前后顺序的。
(1)数组(Array):一组具有相同类型的元素,按顺序排列。每个元素都有一个对应的位置编号(从0开始递增,被称为“索引”),通过这个编号可快速访问数据。数组的优点是访问快,缺点是插入、删除数据需要整体移动数组内部分元素,效率较低。
(2)链表(Linked List):元素通过指针(地址)相连:每个元素都附带一个地址,这个地址就是下一个元素的地址。就好像我们出门时拿着要去的地址就能找到目的地一样。链表的优点是插入、删除数据不需要移动数据,只要改变附带的地址即可。
(3)栈(Stack):后进先出(LIFO, Last In First Out)的数据结构。就像一摞盘子,先摞的(也就是摞在下面的)最后拿出来用。
(4)队列(Queue):先进先出(FIFO, First In First Out)的数据结构。队列就和生活中的排队一样,排在前面的优先服务,服务完离开队伍;入队得从最后排队。
2.非线性数据结构
数据元素之间是一对多或多对多的关系。
(1)树(Tree):数据元素之间存在一对多的层次关系,如二叉树、堆、B树、红黑树、哈夫曼树等。树就是树嘛,一个根分出树枝、树杈,最后是树叶,层次分明。金字塔结构和思维导图都是树。
(2)图(Graph):图是网状结构,节点之间随意连接,适合表示任意关系。图由节点(顶点)和边(连接)组成,数据元素之间存在多对多的复杂关系,如有向图、无向图、邻接矩阵等。

3.特殊数据结构
(1)哈希表(Hash Table):又称散列表。它通过一个函数(哈希函数),把数据映射到特定的位置,查找速度几乎接近O(1)。

(2)集合(Set):和数学中的集合概念一样,集合中的元素是唯一的,不存在重复的元素。集合底层一般是用二叉树实现的。
(3)映射(Map):键值对存储的数据结构,支持快速查找和更新。在python中称之为“字典(Dictionary)” 映射底层在C++中是用红黑树实现的,在python中是用哈希表实现的。
四、数据结构的重要性
数据结构是算法的灵魂伴侣,有着重要的意义。
(1)提高算法效率:选用合适的数据结构可以显著提高算法的效率。
(2)增加代码可读性:使用标准的数据结构可以使代码更加清晰和易于维护。
(3)利于模块化设计:数据结构有助于将问题分解为更小的、更易于管理的部分。
五、数据结构的选用依据
选择适当的数据结构取决于具体的应用场景和需求,包括:
(1)数据访问模式:如频繁插入、删除、查找等。
(2)数据规模:数据量的大小。
(3)内存使用:对内存的限制。
(4)性能要求:如时间复杂度和空间复杂度。