目录
1.安装ollama 0.5.1
2.下载大模型 qwen2.5 3b
3.开启WSL
4.更新wsl
5.安装ubuntu
6.docker下载
6.1 修改docker镜像源
6.2 开启WSL integration
7.安装fastgpt
7.1 创建fastgpt文件夹
7.2 下载fastgpt配置文件
8.启动容器
9.M3E下载
9.1 下载运行命令
9.2 开机自动运行
10.oneapi配置
10.1 配置ollama渠道
10.2 配置渠道m3e
10.3 创建令牌
10. 4 将创建的fastGPT令牌放置docker-compose.yml文件中
10.5 修改config.json
10.5 重启容器
11. FastGTP配置与使用
11.0 登录
11.1 创建知识库
11.2 添加知识库内容
12.创建应用
13. 知识问答
1.安装ollama 0.5.1
官网地址 ollama.com
直接下载速度太慢,使用加速:
- https://mirror.ghproxy.com/https://github.com/ollama/ollama/releases/download/v0.5.1/OllamaSetup.exeGitHub Proxy 代理加速【实测速度超快】
2.下载大模型 qwen2.5 3b
ollama run qwen2.5:3b3.开启WSL
因为这里使用的win部署,所以要安装wsl,如果是linux系统就没那么麻烦 控制面板->程序->程序和功能 
4.更新wsl
wsl --set-default-version 2
wsl --update --web-download5.安装ubuntu
wsl --install -d Ubuntu 反馈:
解决办法:ip138.com 查询 域名对应的IP地址,然后修改host,添加对上面地址的解析。
 用户名 密码 wf
用户名 密码 wf
6.docker下载
官网下载: docker官网
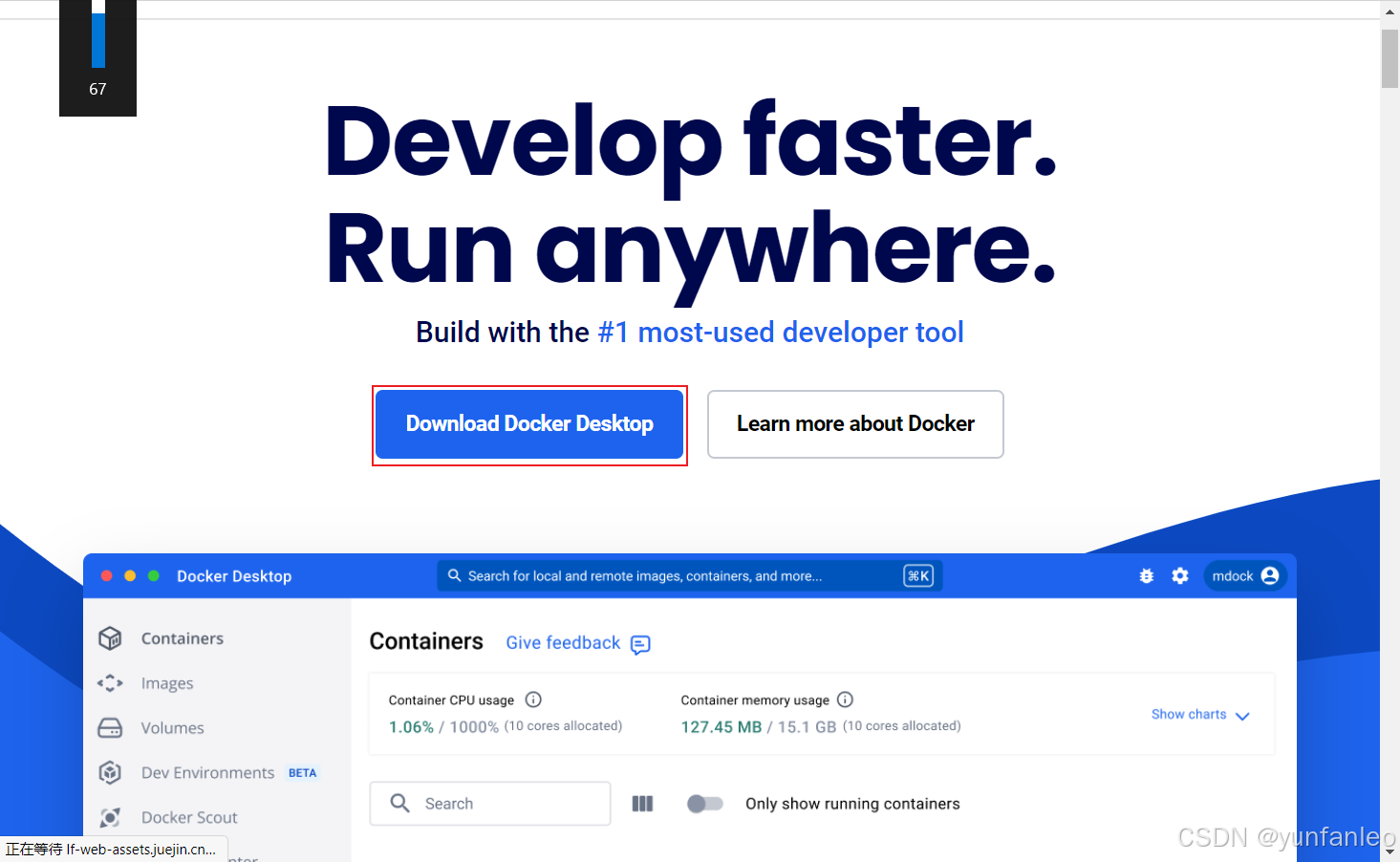

然后安装即可
安装好后,启动docker desktop
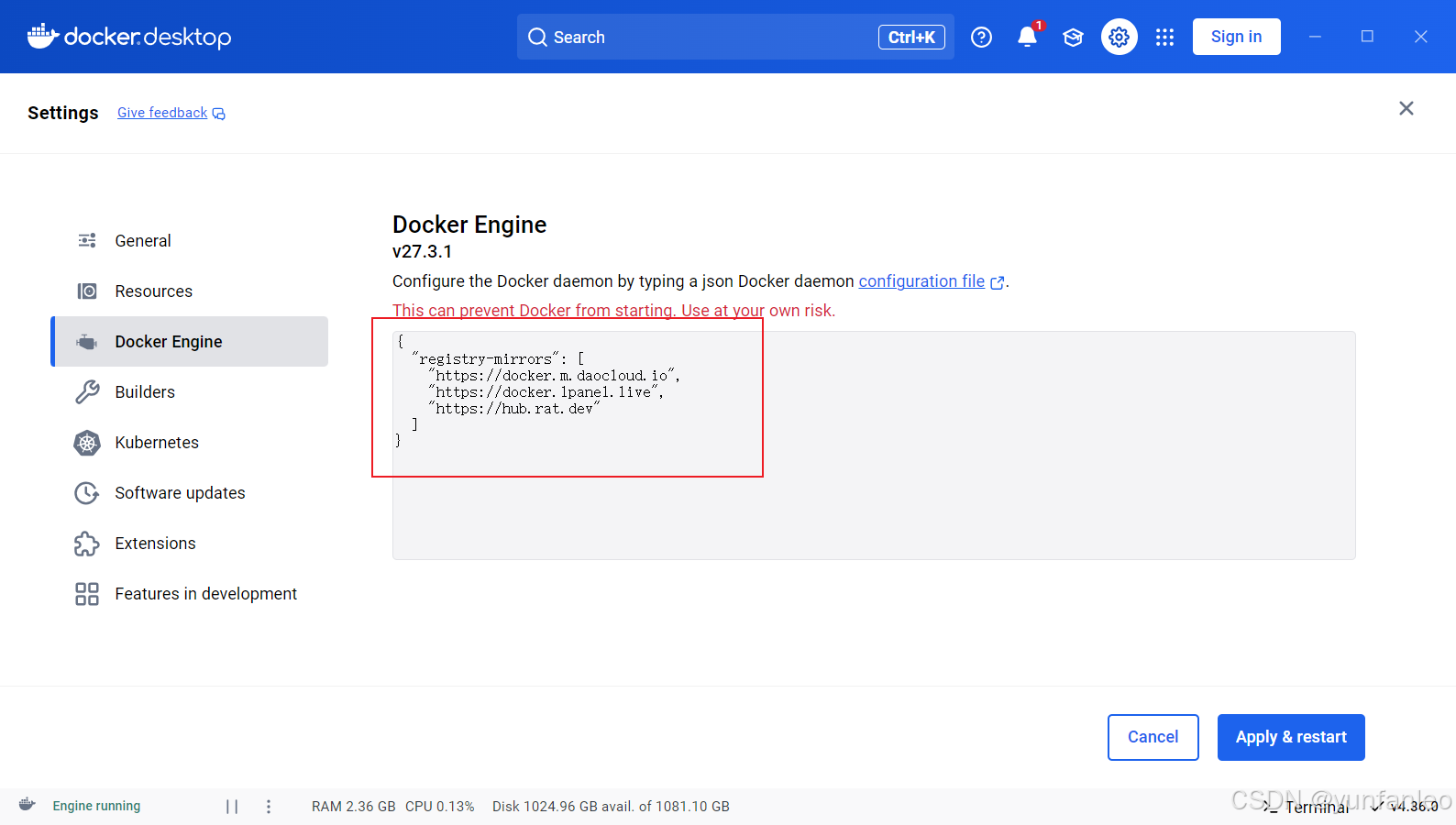
6.1 修改docker镜像源
因为docker下载的镜像源默认是国外的地址,所以下载比较慢,换成国内的镜像源下载会比较快一点
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://hub.rat.dev"
]
}
6.2 开启WSL integration
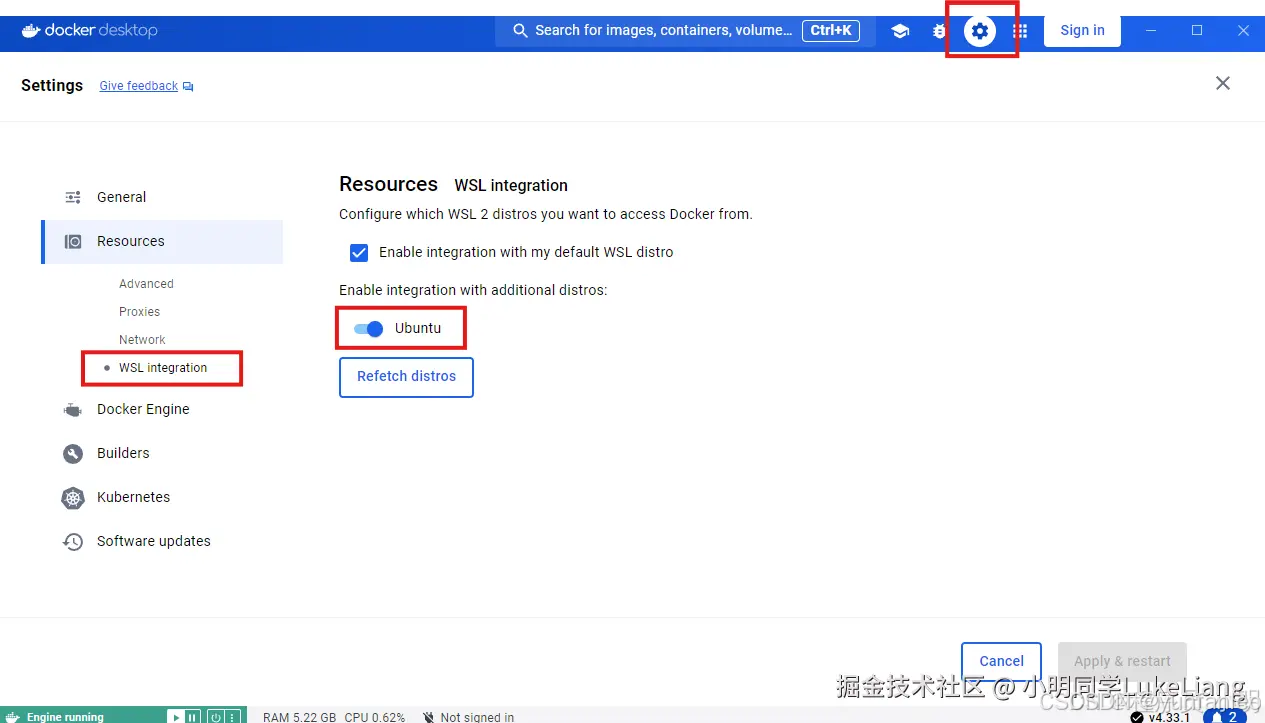
7.安装fastgpt
7.1 创建fastgpt文件夹
先创建一个文件夹来放置一些配置文件
mkdir fastgpt
cd fastgpt
7.2 下载fastgpt配置文件
用命令下载fastgpt配置文件
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
curl -O https://raw.gitmirror.com/labring/FastGPT/main/projects/app/data/config.jsoncurl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json 下载不下来的话,重新配置host:185.199.108.133 raw.githubusercontent.com
或者镜像: curl -o docker-compose.yml https://raw.fastgit.org/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
raw.fastgit.org 地址无法解析的话,ip138.com 查询解析,然后配host:
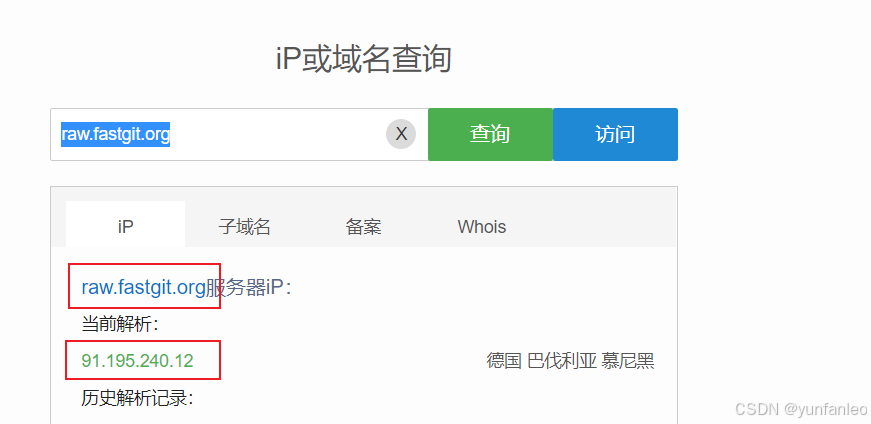
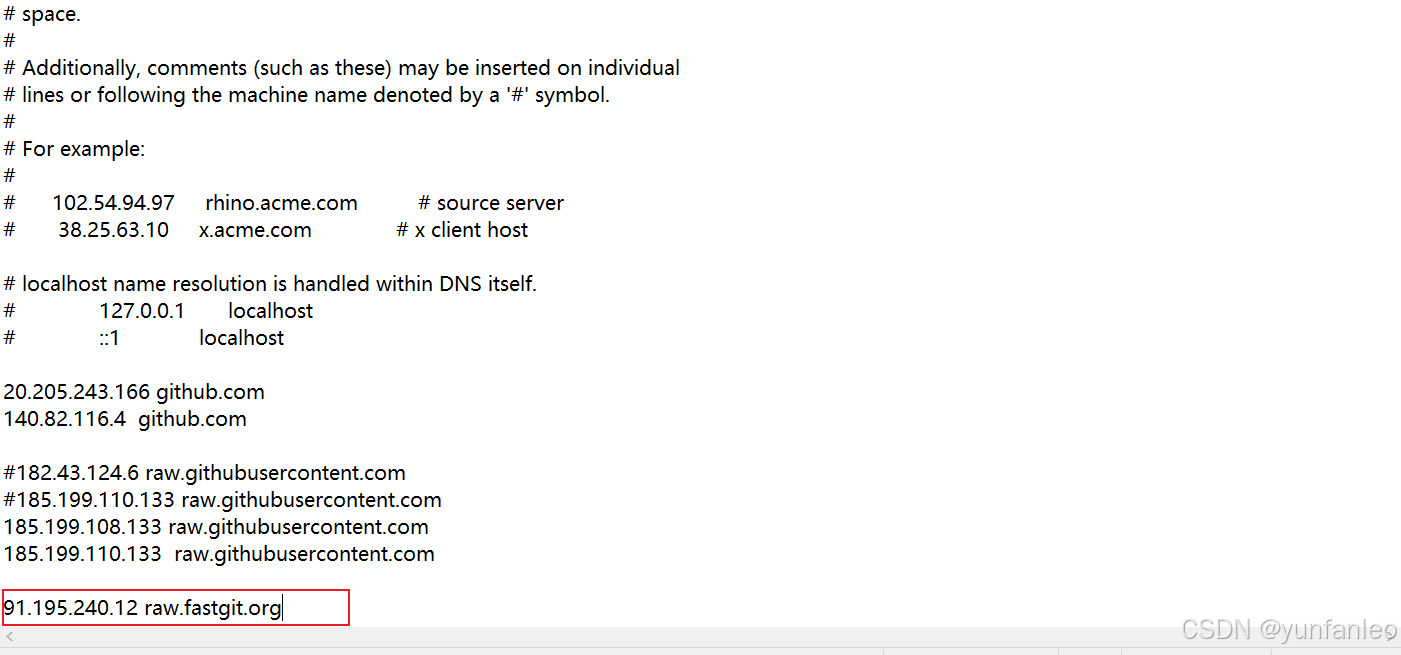
用命令下载docker的部署文件
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
curl -O https://raw.gitmirror.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml
8.启动容器
docker-compose up -d
9.M3E下载
9.1 下载运行命令
#查看网络
docker network ls
# GPU模式启动,并把m3e加载到fastgpt同一个网络
docker run -d -p 6008:6008 --gpus all --name m3e --network fastgpt_fastgpt(这里你们的网络名称可能不是这个,如果不是这个就按照你们查到的网络去填) stawky/m3e-large-api
# CPU模式启动,并把m3e加载到fastgpt同一个网络
docker run -d -p 6008:6008 --name m3e --network fastgpt_fastgpt stawky/m3e-large-api
9.2 m3e 开机自动运行,自动重启设置
docker run -d --restart always -p 6008:6008 --name m3e --network fastgpt_fastgpt stawky/m3e-large-api10.oneapi配置
模型的处理我们用的是oneapi来处理模型
本机地址:http://localhost:3001/ oneapi登录账号:root 默认密码:123456 登录后立即修改密码为 baxcy516193@z1k3t7w
10.1 配置ollama渠道
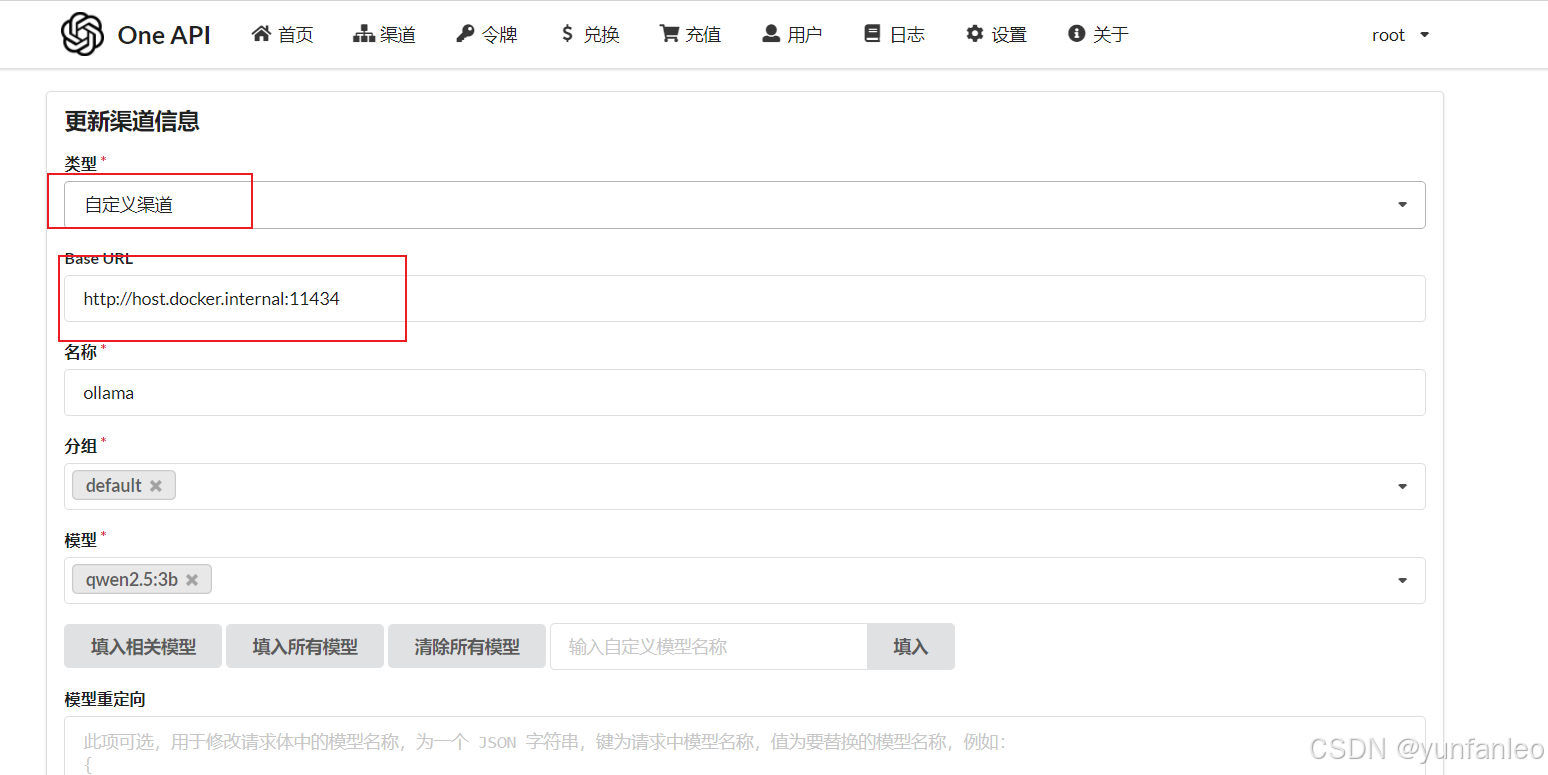
或者选择 ollama 类型 但要配置代理,代理地址与上面的BASE URL 一致。
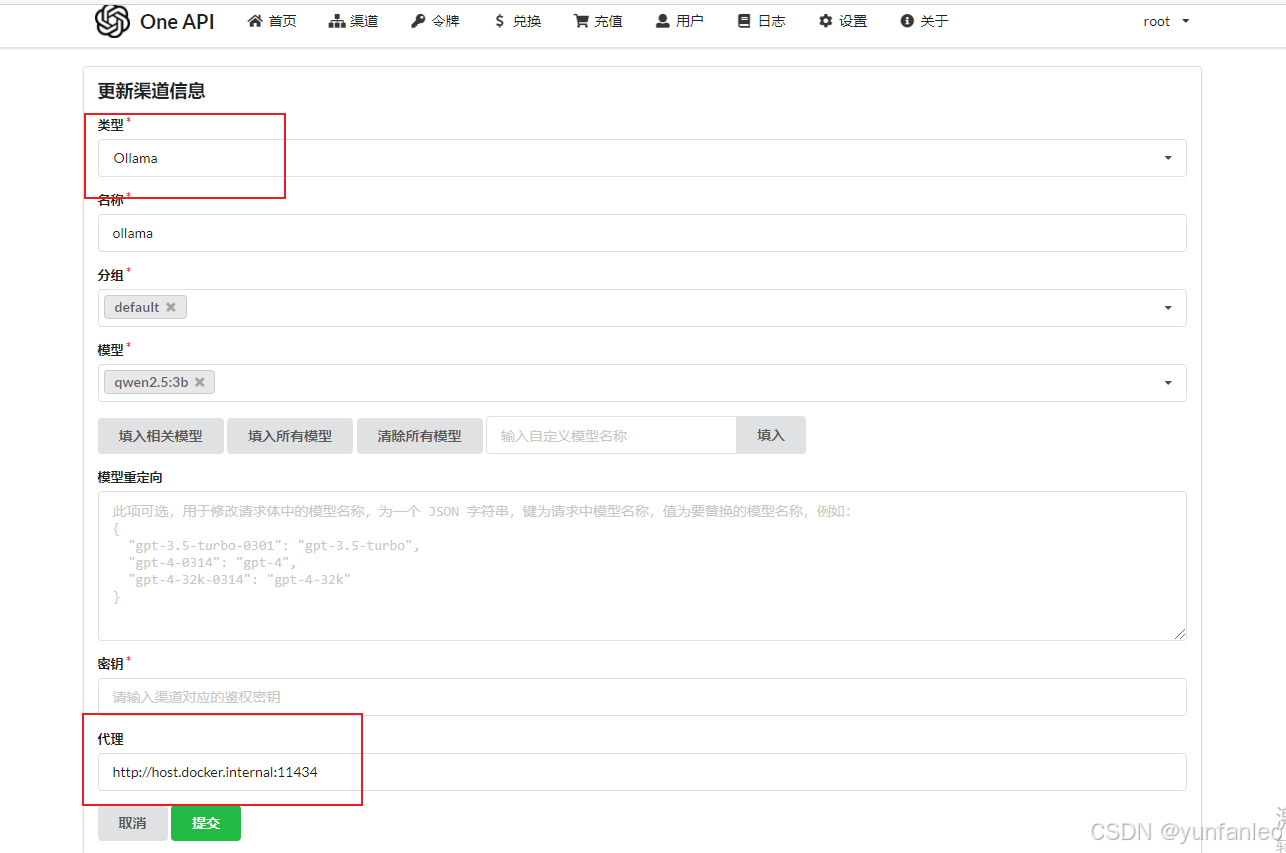
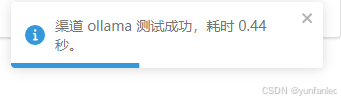
通过测试发现,ollama 类型方式,测试的响应时间要慢。
ollama响应时间普遍在一秒以上:
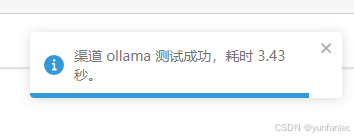
而自定义渠道方式测试响应时间在一秒以内:
另外就是直接写本机局域网ip地址,会提示连接被拒绝,
使用docker自动在hosts里面生成的域名host.docker.internal可以正常连接.
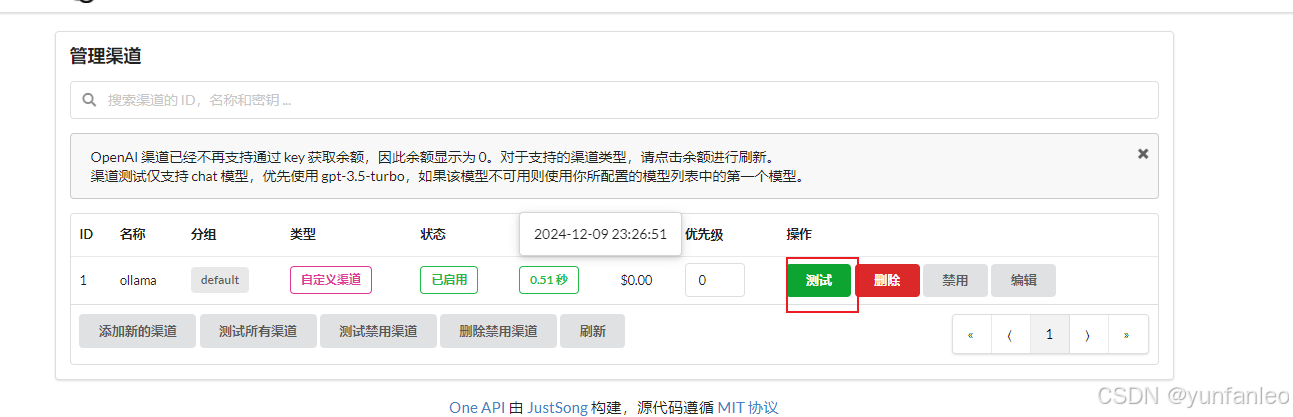
base url那里使用docker自动在hosts里面生成的域名host.docker.internal可以正常连接;选择的模型要选择你本地ollama下载的模型,并且要带上参数。比如:qwen2.5:3b
密钥可以随便填
添加完渠道,记得要点一下测试,测试通过了才能正常使用.
10.2 配置渠道m3e
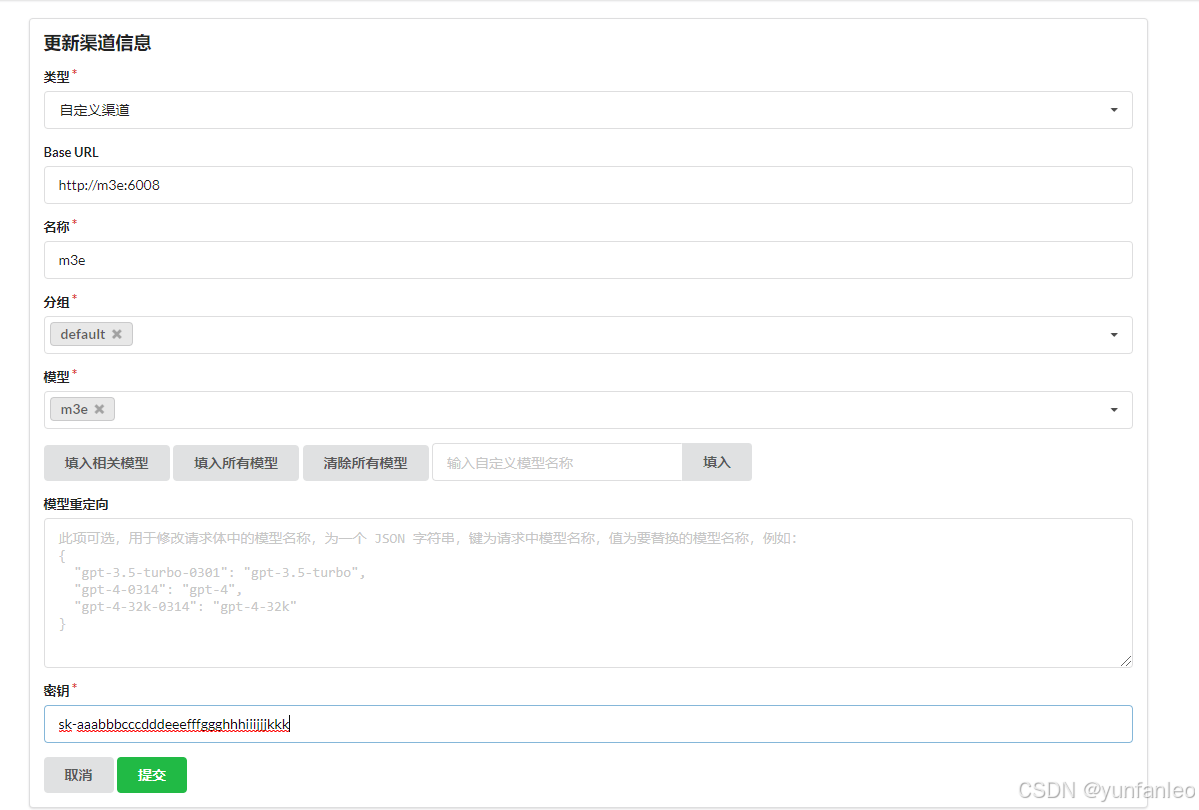
base url要像我这样填写才行,不然回出问题 模型要选m3e
密钥填:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
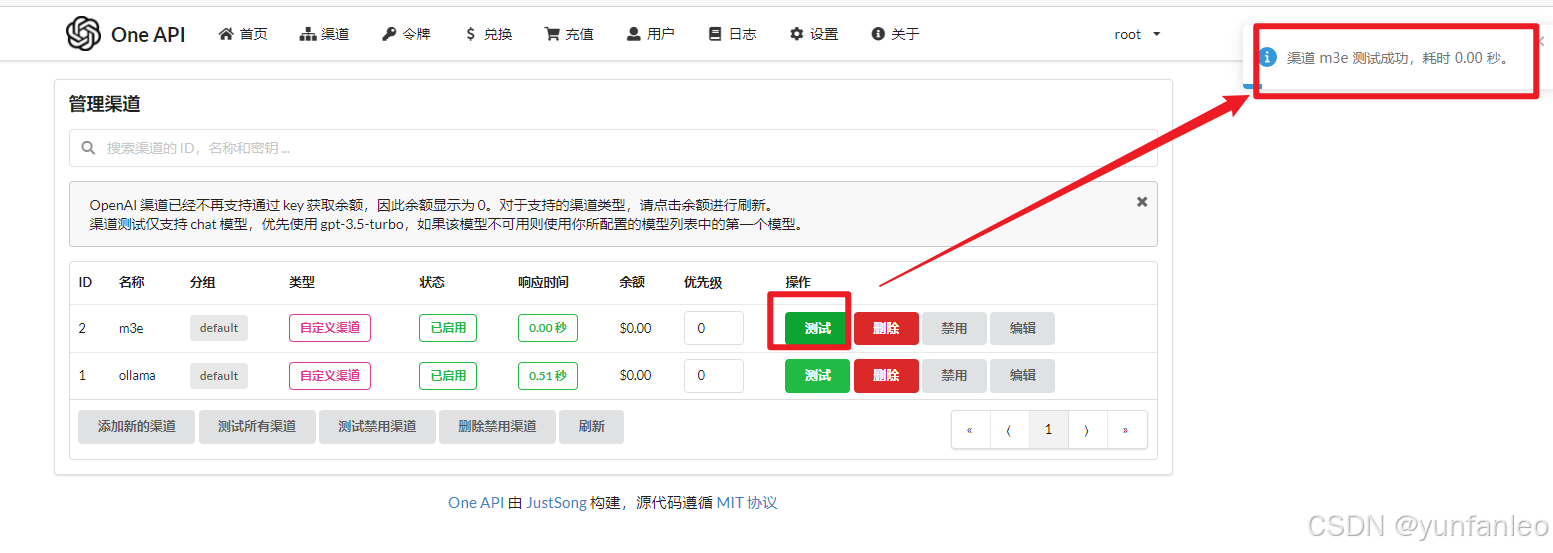
提交之后也要点测试,看能不能通
10.3 创建令牌
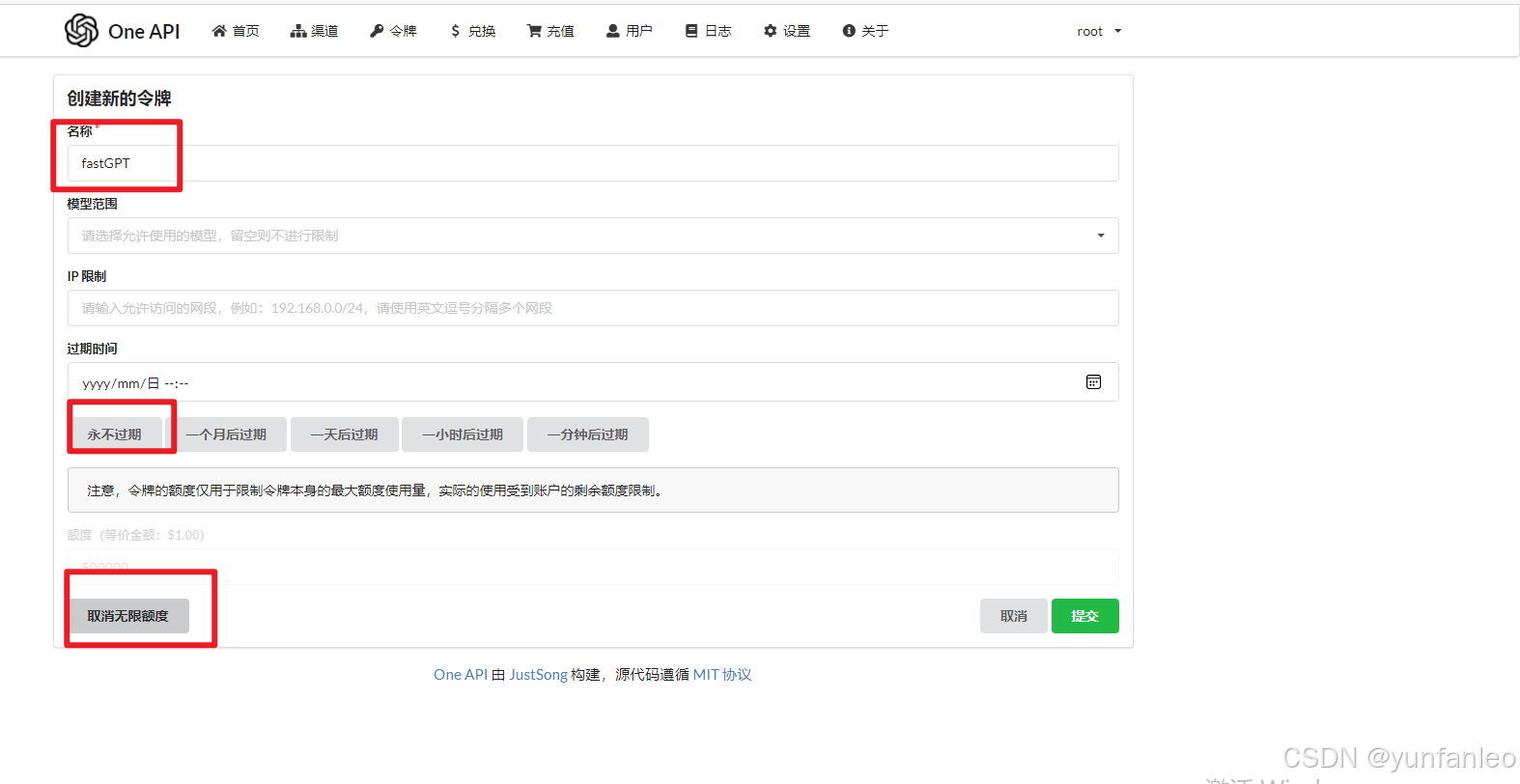
选无限额度和永不过期
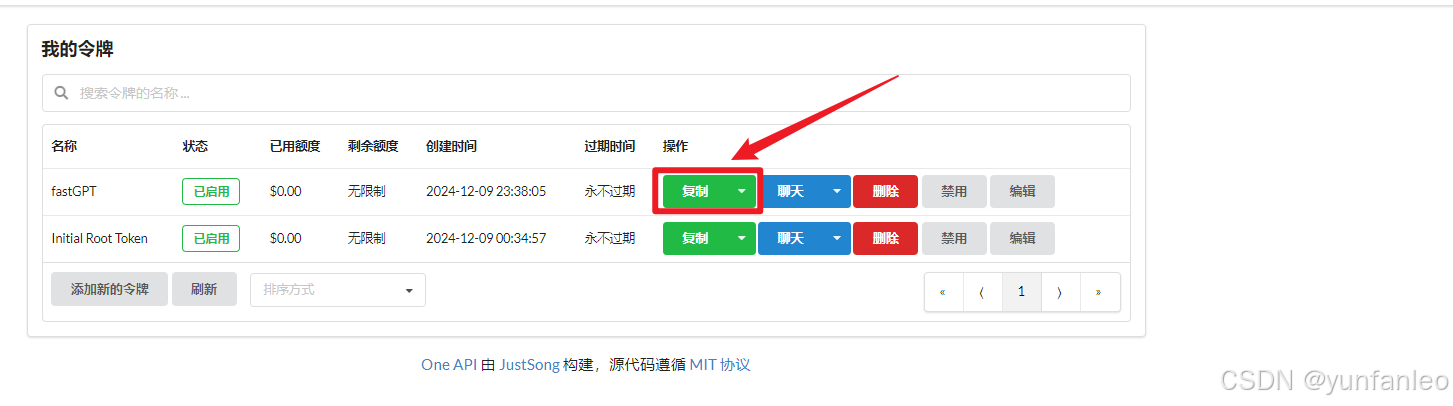
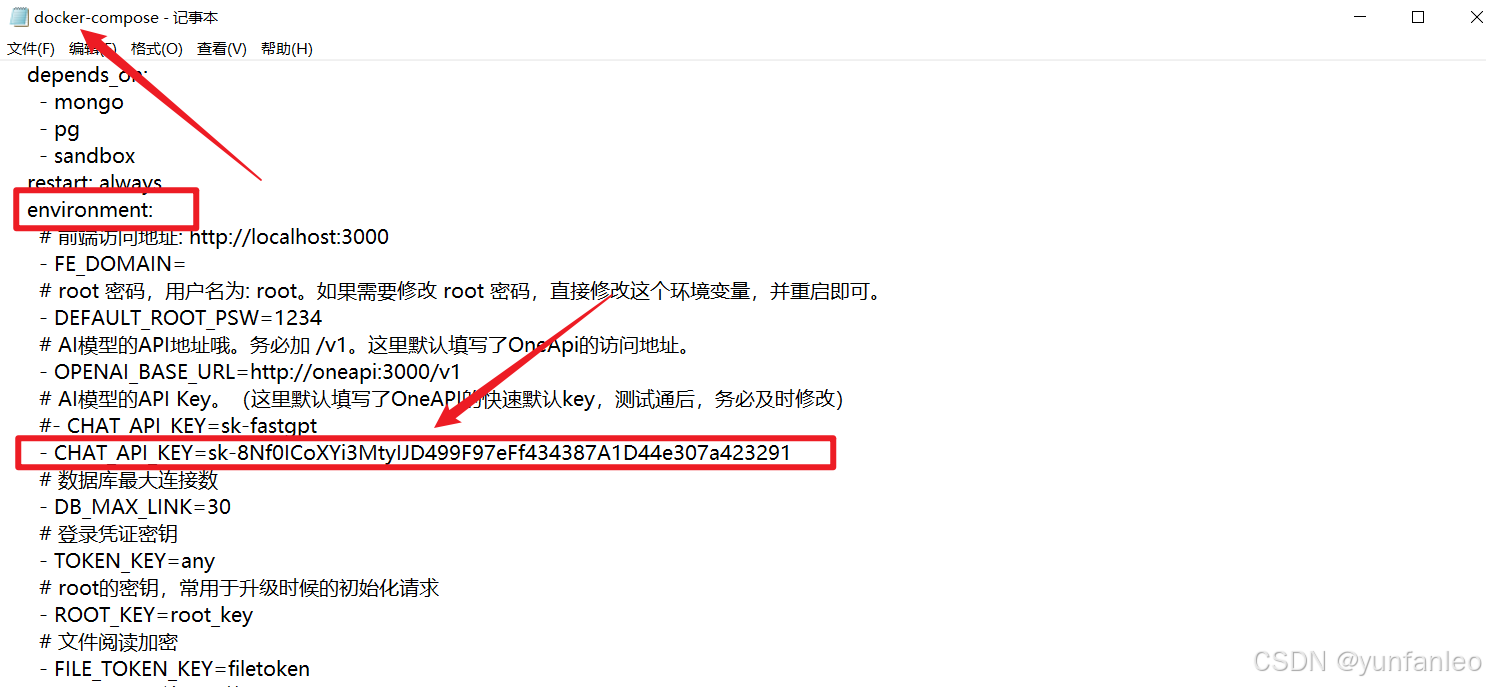
10. 4 将创建的fastGPT令牌放置docker-compose.yml文件中
复制刚创建的fastGPT令牌放置docker-compose.yml文件中,
文件位置在 d:\fastgpt\docker-compose.yml :
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。
- DEFAULT_ROOT_PSW=1234
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://oneapi:3000/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-8Nf0ICoXYi3MtyIJD499F97eFf434387A1D44e307a423291
10.5 修改config.json
首先是加入ollama的本地模型,像我用的是qwen2.5:3b,你们可以根据自己的模型进行填写
"llmModels": [
{
"model": "qwen2.5:3b", // 模型名(对应OneAPI中渠道的模型名)
"name": "ollama", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},

然后加入向量模型vectorModels
"vectorModels": [
{
"model": "m3e", // 模型名(与OneAPI对应)
"name": "m3e", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig":{}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},

10.5 重启容器
docker-compose down
docker-compose up -d
11. FastGTP配置与使用
11.0 登录
本机地址:http://localhost:3000
账号:root 密码:1234
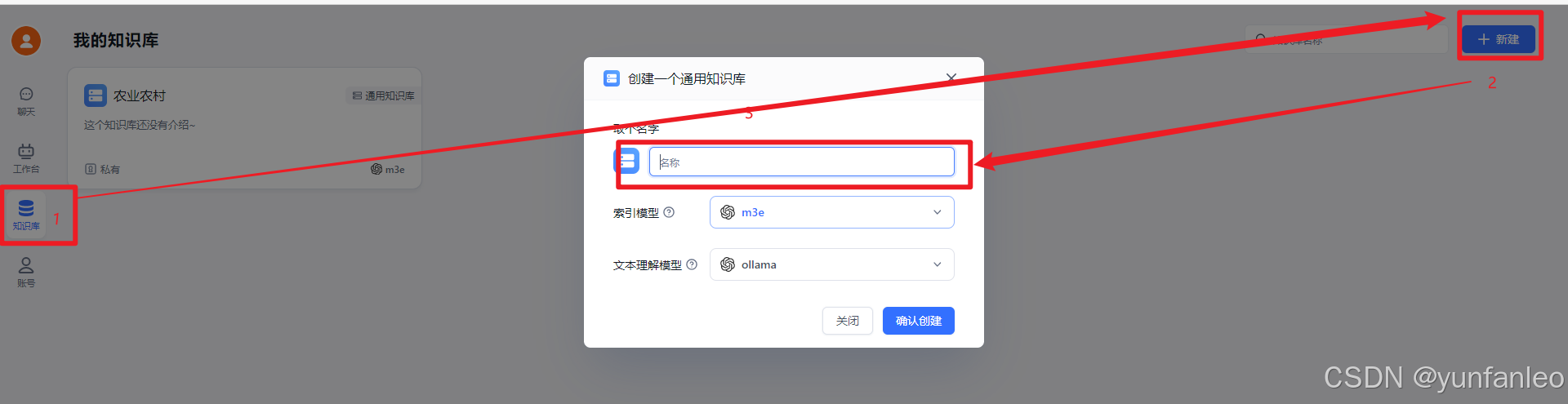
11.1 创建知识库
选用通用知识库 索引模型也就是向量模型 文件处理模型就是用来做回答的模型
11.2 添加知识库内容
新建导入,选择 文本数据集,然后选择本地文件,从本地文件夹上传文件。然后上传
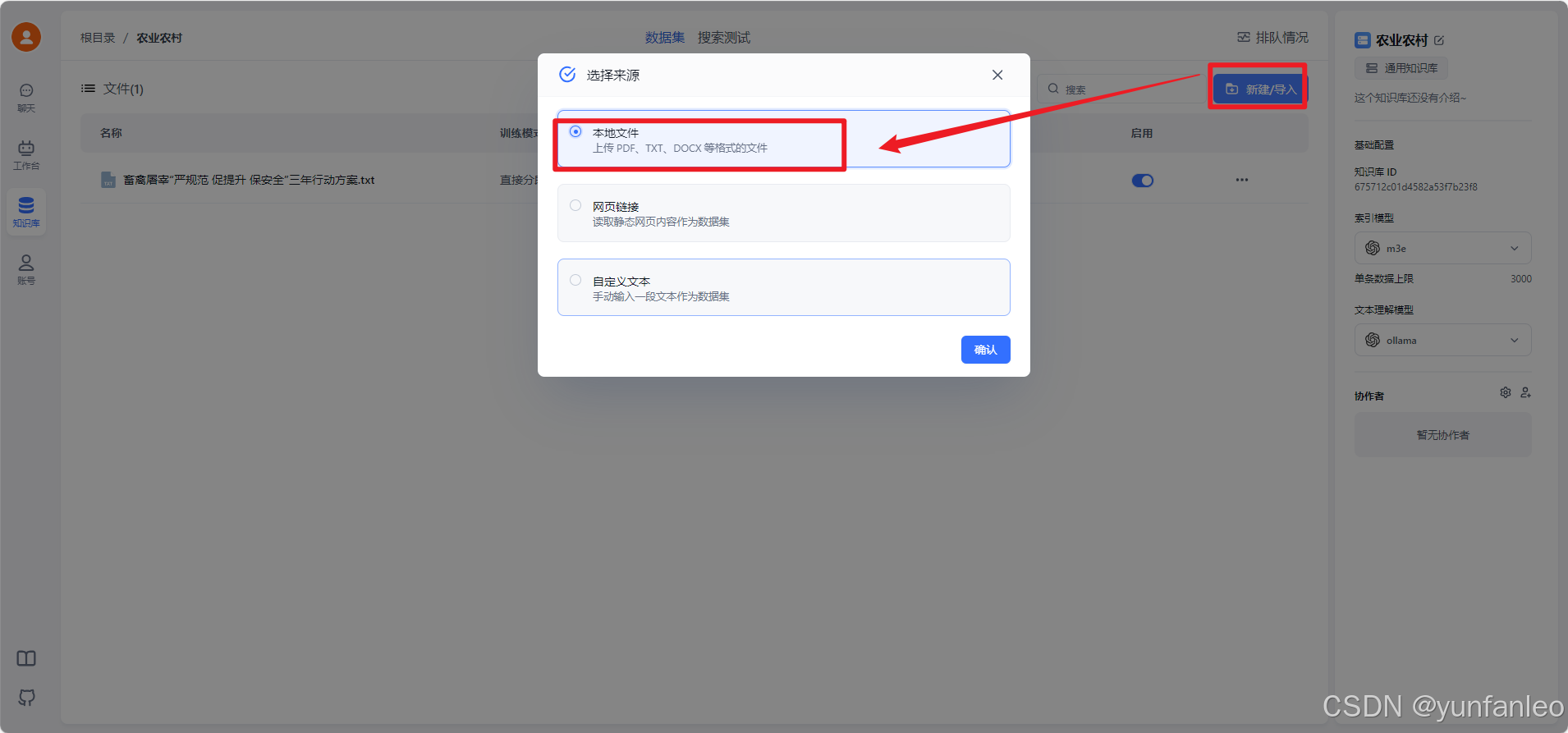
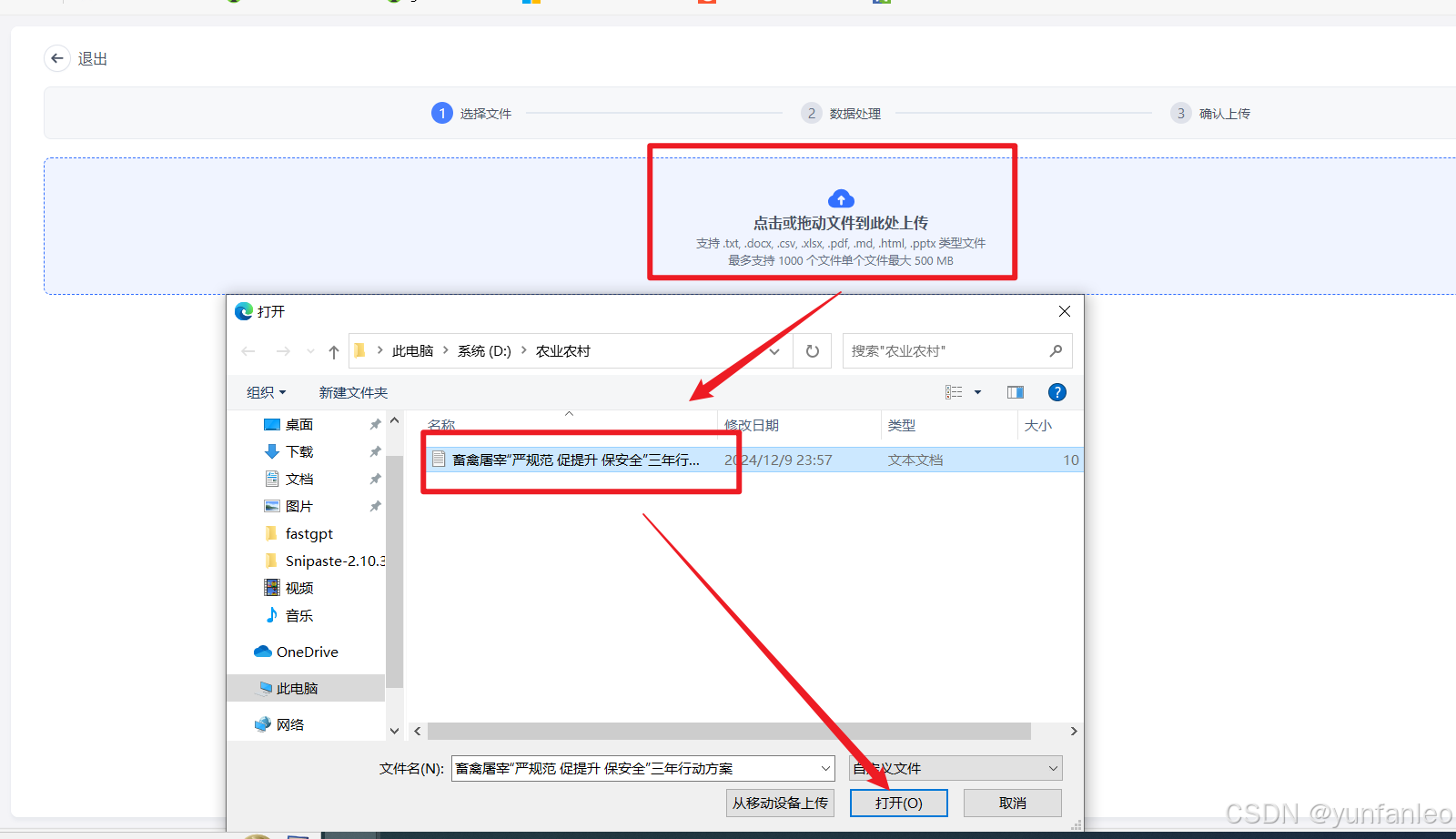
根据提示,点击下一步,下一步,确认文件上传。
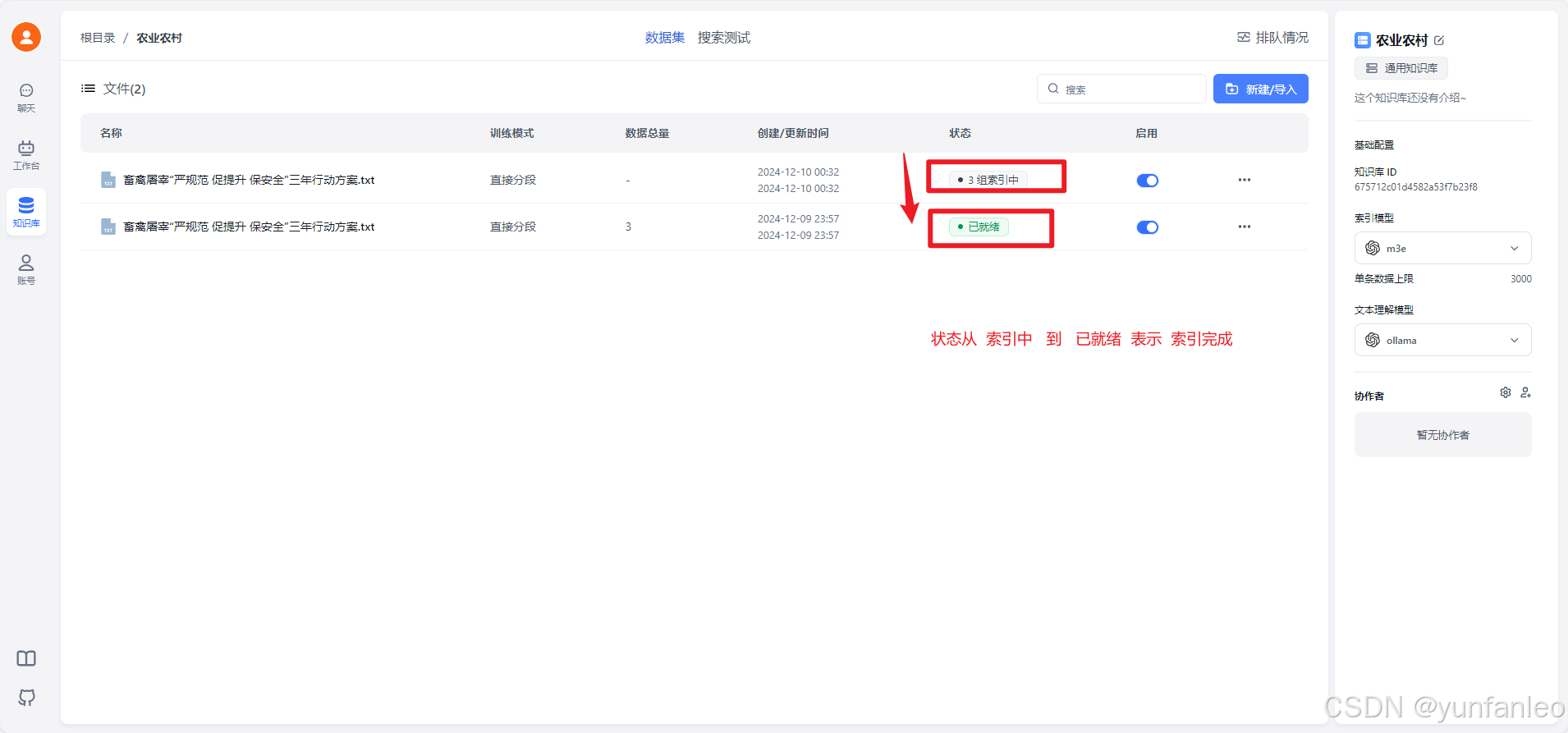
最后 状态从索引中 变为 已就绪 表示索引创建完成。就可以使用这个知识库了。后续还可以不断添加文件到这个知识库。
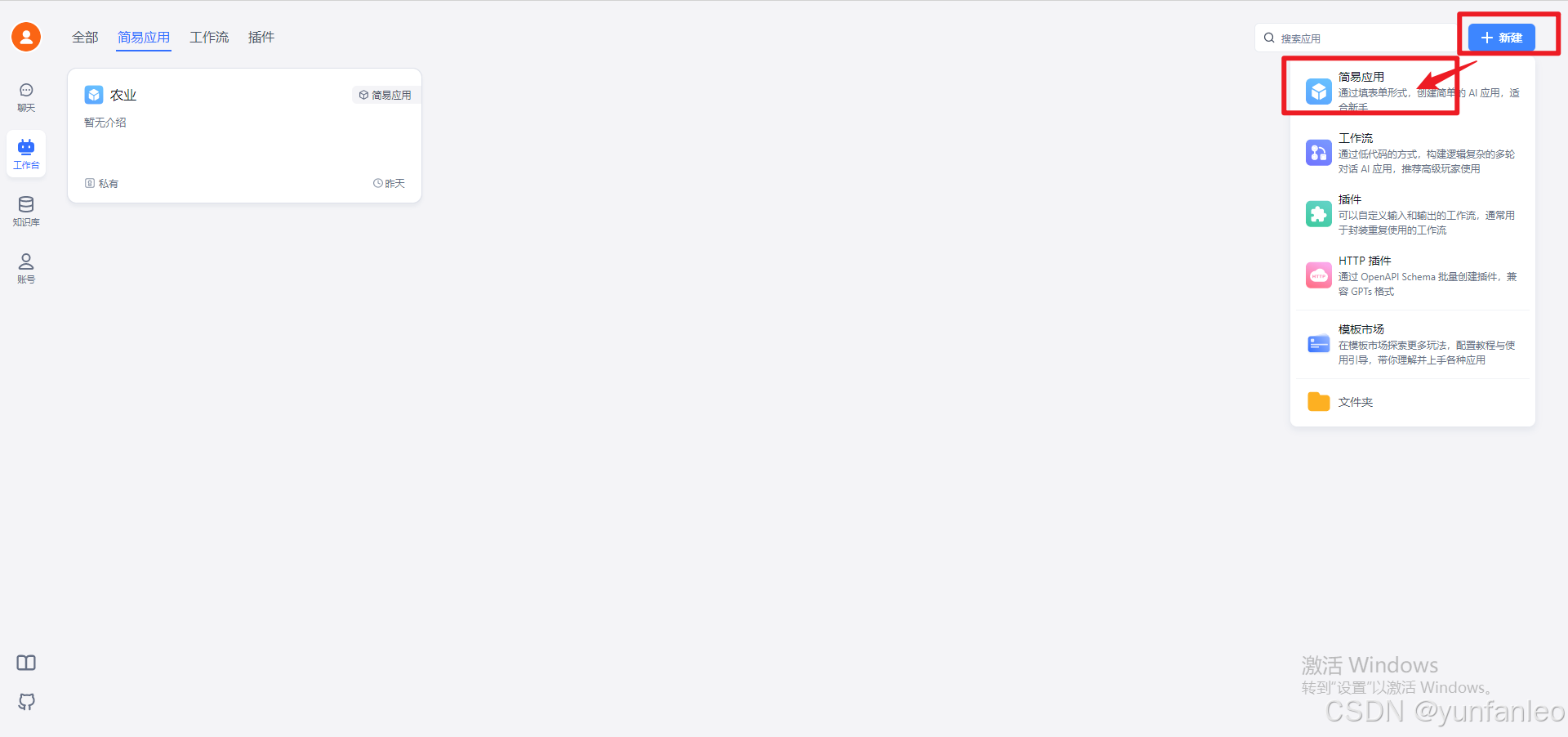
12.创建应用
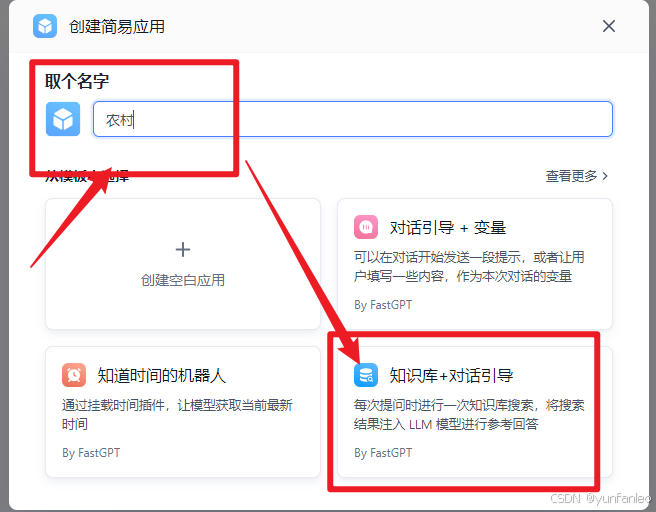

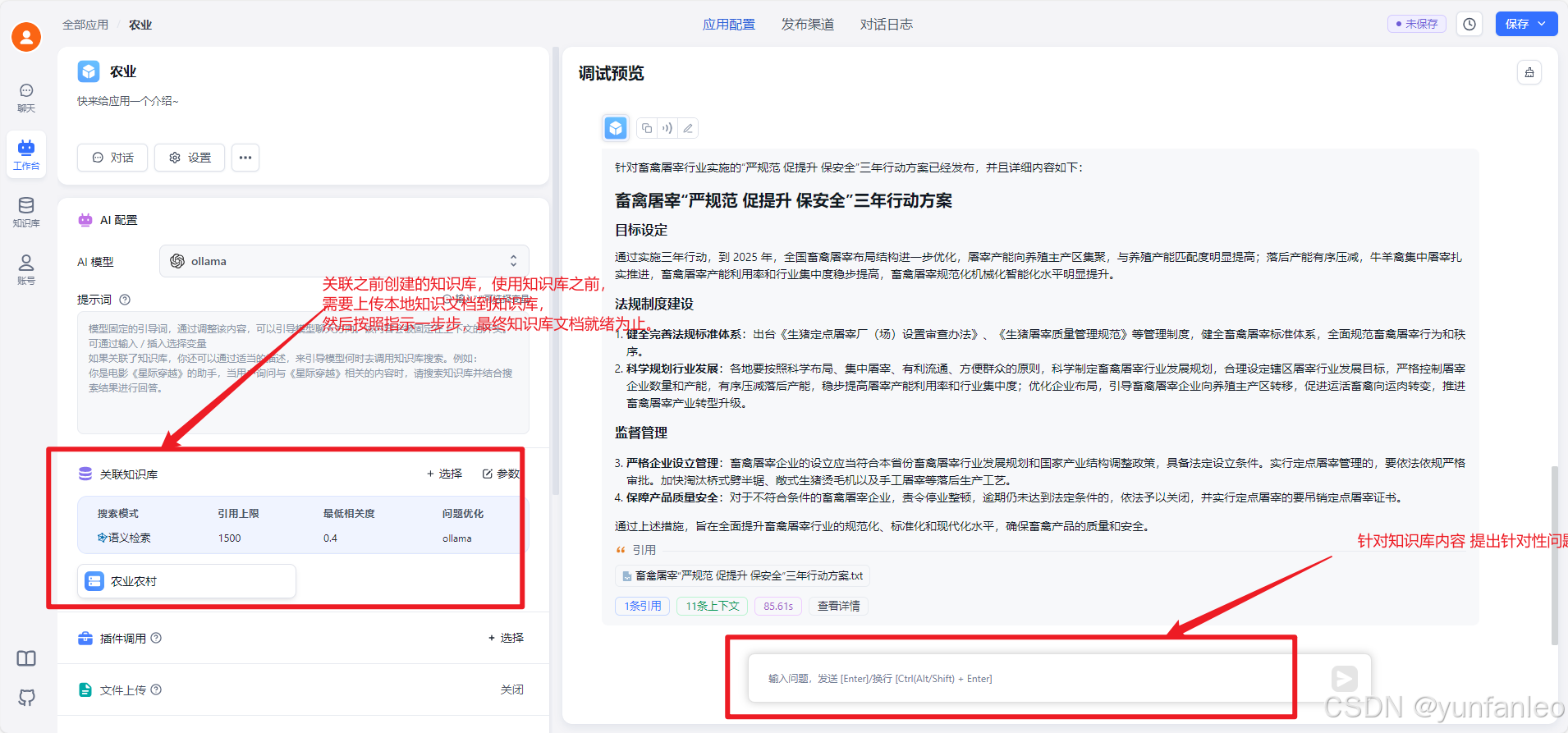
13. 知识问答
![[创业之路-190]:《华为战略管理法-DSTE实战体系》-2-华为DSTE战略管理体系概要](https://i-blog.csdnimg.cn/direct/6764fcde165a49da8602af284171ff29.png)


















