本文用于记录Spark SQL执行计划解析的源码分析。文中仅对关键要点进行提及,无法面面具到,仅描述大体的框架。
Spark的Client有很多种,spark-sql,pyspark,spark- submit,R等各种提交方式,这里以spark.sql()方法作为源码分析入口:

在介绍具体的解析流程之前,我们画了一个图,图中展示了SQL被解析的各个阶段:

- SQL文本会经过antlr框架执行词法解析,语法解析,随后生成一个AST树,进入后续各个阶段的执行计划解析和优化
- 首先是进入parsing阶段,由Parser解析LogicalPlan,生成unresolved LogicalPlan。Parser是ParserInterface的实现,具体的继承关系如下图:

- 接下来进入analysis阶段,有Analyzer执行一系列的rule生成analyzed LogicalPlan。Analyzer继承自RuleExecutor,是一系列analyze的rule集合

- 接着进入optimization阶段,负责优化的是Optimizer,它也是继承自RuleExecutor,随后生成optimized LogicalPlan。
- optimized LogicalPlan会被被传递给SparkPlanner进入planning阶段,同样也是一系列的Rule,不同的是这一阶段已经到了物理计划的解析,输出结果不再是LogicalPlan,而是SparkPlan。
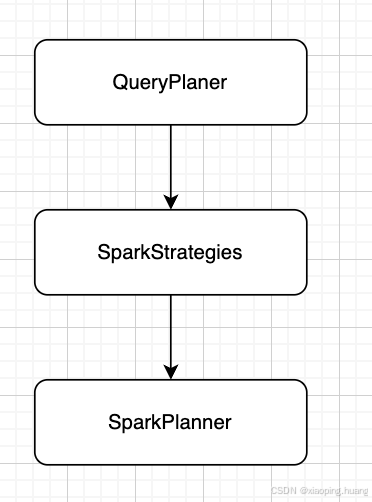
- 第一个planning阶段结束后,还会再次进去planning阶段,此时负责优化的是preparations(一些列针对SparkPlan优化的Rule),主要就是插入AQE相关的优化。此时生成的就是executedPlan。
至此,Spark SQL的执行计划(逻辑计划,物理计划)解析就告一段落,剩下的就是拿到executedPlan开始切分stage,task,申请资源进行调度,执行具体物理计划的逻辑了。