摘要
本文深入探讨了分布式链路追踪系统的必要性与实施细节。随着软件架构的复杂化,传统的日志分析方法已不足以应对问题定位的需求。文章首先解释了链路追踪的基本概念,如Trace和Span,并讨论了其基本原理。接着,文章介绍了SkyWalking这一开源链路追踪系统,包括其架构设计、部署方式、数据采集与存储等关键特性。最后,通过大众点评的实践案例,文章展示了链路追踪在实际业务中的应用效果,强调了其在提升分布式系统可观测性方面的重要性。
1. 分布式链路追踪背景
1.1. 分布式系统为什么需要链路追踪?
随着互联网业务快速扩展,软件架构也日益变得复杂,为了适应海量用户高并发请求,系统中越来越多的组件开始走向分布式化,如单体架构拆分为微服务、服务内缓存变为分布式缓存、服务组件通信变为分布式消息,这些组件共同构成了繁杂的分布式网络。

假如现在有一个系统部署了成千上万个服务,用户通过浏览器在主界面上下单一箱茅台酒,结果系统给用户提示:系统内部错误,相信用户是很崩溃的。运营人员将问题抛给开发人员定位,开发人员只知道有异常,但是这个异常具体是由哪个微服务引起的就需要逐个服务排查了。

1.2. 传统日志分析系统不足
日志作为业务系统的必备能力,职责就是记录程序运行期间发生的离散事件,并且在事后阶段用于程序的行为分析,比如曾经调用过什么方法、操作过哪些数据等等。在分布式系统中,ELK技术栈已经成为日志收集和分析的通用解决方案。如下图1所示,伴随着业务逻辑的执行,业务日志会被打印,统一收集并存储ES(Elasticsearch)。

传统的ELK方案需要开发者在编写代码时尽可能全地打印日志,再通过关键字段从ES中搜集筛选出与业务逻辑相关的日志数据,进而拼凑出业务执行的现场信息。然而该方案存在如下的痛点:
- 日志搜集繁琐:虽然ES提供了日志检索的能力,但是日志数据往往是缺乏结构性的文本段,很难快速完整地搜集到全部相关的日志。
- 日志筛选困难:不同业务场景、业务逻辑之间存在重叠,重叠逻辑打印的业务日志可能相互干扰,难以从中筛选出正确的关联日志。
- 日志分析耗时:搜集到的日志只是一条条离散的数据,只能阅读代码,再结合逻辑,由人工对日志进行串联分析,尽可能地还原出现场。
综上所述,随着业务逻辑和系统复杂度的攀升,传统的ELK方案在日志搜集、日志筛选和日志分析方面愈加的耗时耗力,很难快速实现对业务的追踪。
1.3. 什么是链路追踪?
分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
链路跟踪主要功能:
- 故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
- 链路性能可视化:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
- 链路分析:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
1.4. 链路追踪基本原理
链路追踪系统(可能)最早是由Goggle公开发布的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》被大家广泛熟悉,所以各位技术大牛们如果有黑武器不要藏起来赶紧去发表论文吧。在这篇著名的论文中主要讲述了Dapper链路追踪系统的基本原理和关键技术点。接下来挑几个重点的技术点详细给大家介绍一下。
1.4.1. Trace
Trace的含义比较直观,就是链路,指一个请求经过所有服务的路径,可以用下面树状的图形表示。

图中一条完整的链路是:chrome -> 服务A -> 服务B -> 服务C -> 服务D -> 服务E -> 服务C -> 服务A -> chrome。服务间经过的局部链路构成了一条完整的链路,其中每一条局部链路都用一个全局唯一的traceid来标识。
1.4.2. Span
在上图中可以看出来请求经过了服务A,同时服务A又调用了服务B和服务C,但是先调的服务B还是服务C呢?从图中很难看出来,只有通过查看源码才知道顺序。
为了表达这种父子关系引入了Span的概念。
同一层级parent id相同,span id不同,span id从小到大表示请求的顺序,从下图中可以很明显看出服务A是先调了服务B然后再调用了C。
上下层级代表调用关系,如下图服务C的span id为2,服务D的parent id为2,这就表示服务C和服务D形成了父子关系,很明显是服务C调用了服务D。

总结:通过事先在日志中埋点,找出相同traceId的日志,再加上parent id和span id就可以将一条完整的请求调用链串联起来。
1.4.3. Annotations
Dapper中还定义了annotation的概念,用于用户自定义事件,用来辅助定位问题。通常包含四个注解信息: cs:Client Start,表示客户端发起请求; sr:ServerReceived,表示服务端收到请求; ss: Server Send,表示服务端完成处理,并将结果发送给客户端; cr:ClientReceived,表示客户端获取到服务端返回信息;

上图中描述了一次请求和响应的过程,四个点也就是对应四个Annotation事件。
如下面的图表示从客户端调用服务端的一次完整过程。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的T4 - T1。如果要计算客户端发送网络耗时,也就是图中时间线上的T2 - T1,其他类似可计算。

1.4.4. 带内数据与带外数据
链路信息的还原依赖于带内和带外两种数据。
带外数据是各个节点产生的事件,如cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。通过带外数据,可以在存储端分析更多链路的细节。带内数据如traceid,spanid,parentid,用来标识trace,span,以及span在一个trace中的位置,这些数据需要从链路的起点一直传递到终点。 通过带内数据的传递,可以将一个链路的所有过程串起来。
1.4.5. 采样
由于每一个请求都会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,那么只会上报一个请求到存储端。

通过采集端自适应地调整采样率,控制span上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。
1.4.6. 存储

链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。
2. 可视化全链路日志追踪
2.1. 设计思路
可视化全链路日志追踪考虑在前置阶段,即业务执行的同时实现业务日志的高效组织和动态串联,如下图4所示,此时离散的日志数据将会根据业务逻辑进行组织,绘制出执行现场,从而可以实现高效的业务追踪。

2.1.1. 如何高效组织业务日志?
为了实现高效的业务追踪,首先需要准确完整地描述出业务逻辑,形成业务逻辑的全景图,而业务追踪其实就是通过执行时的日志数据,在全景图中还原出业务执行的现场。新方案对业务逻辑进行了抽象,定义出业务逻辑链路,下面还是以“审核业务场景”为例,来说明业务逻辑链路的抽象过程:
- 逻辑节点:业务系统的众多逻辑可以按照业务功能进行拆分,形成一个个相互独立的业务逻辑单元,即逻辑节点,可以是本地方法(如下图5的“判断逻辑”节点)也可以是RPC等远程调用方法(如下图5的“逻辑A”节点)。
- 逻辑链路:业务系统对外支撑着众多的业务场景,每个业务场景对应一个完整的业务流程,可以抽象为由逻辑节点组合而成的逻辑链路,如下图5中的逻辑链路就准确完整地描述了“审核业务场景”。
一次业务追踪就是逻辑链路的某一次执行情况的还原,逻辑链路完整准确地描述了业务逻辑全景,同时作为载体可以实现业务日志的高效组织。

2.1.2. 如何动态串联业务日志?
业务逻辑执行时的日志数据原本是离散存储的,而此时需要实现的是,随着业务逻辑的执行动态串联各个逻辑节点的日志,进而还原出完整的业务逻辑执行现场。
由于逻辑节点之间、逻辑节点内部往往通过MQ或者RPC等进行交互,新方案可以采用分布式会话跟踪提供的分布式参数透传能力实现业务日志的动态串联:
- 通过在执行线程和网络通信中持续地透传参数,实现在业务逻辑执行的同时,不中断地传递链路和节点的标识,实现离散日志的染色。
- 基于标识,染色的离散日志会被动态串联至正在执行的节点,逐渐汇聚出完整的逻辑链路,最终实现业务执行现场的高效组织和可视化展示。
与分布式会话跟踪方案不同的是,当同时串联多次分布式调用时,新方案需要结合业务逻辑选取一个公共id作为标识,例如图5的审核场景涉及2次RPC调用,为了保证2次执行被串联至同一条逻辑链路,此时结合审核业务场景,选择初审和复审相同的“任务id”作为标识,完整地实现审核场景的逻辑链路串联和执行现场还原。
2.2. 日志追踪通用方案设计
明确日志的高效组织和动态串联这两个基本问题后,本文选取图4业务系统中的“逻辑链路1”进行通用方案的详细说明,方案可以拆解为以下步骤:

2.2.1. 链路定义
“链路定义”的含义为:使用特定语言,静态描述完整的逻辑链路,链路通常由多个逻辑节点,按照一定的业务规则组合而成,业务规则即各个逻辑节点之间存在的执行关系,包括串行、并行、条件分支。
**DSL(Domain Specific Language)**是为了解决某一类任务而专门设计的计算机语言,可以通过JSON或XML定义出一系列节点(逻辑节点)的组合关系(业务规则)。因此,本方案选择使用DSL描述逻辑链路,实现逻辑链路从抽象定义到具体实现。

[
{
"nodeName": "A",
"nodeType": "rpc"
},
{
"nodeName": "Fork",
"nodeType": "fork",
"forkNodes": [
[
{
"nodeName": "B",
"nodeType": "rpc"
}
],
[
{
"nodeName": "C",
"nodeType": "local"
}
]
]
},
{
"nodeName": "Join",
"nodeType": "join",
"joinOnList": [
"B",
"C"
]
},
{
"nodeName": "D",
"nodeType": "decision",
"decisionCases": {
"true": [
{
"nodeName": "E",
"nodeType": "rpc"
}
]
},
"defaultCase": [
{
"nodeName": "F",
"nodeType": "rpc"
}
]
}
]2.2.2. 链路染色
“链路染色”的含义为:在链路执行过程中,通过透传串联标识,明确具体是哪条链路在执行,执行到了哪个节点。
链路染色包括两个步骤:
- 步骤一:确定串联标识,当逻辑链路开启时,确定唯一标识,能够明确后续待执行的链路和节点。
-
- 链路唯一标识 = 业务标识 + 场景标识 + 执行标识 (三个标识共同决定“某个业务场景下的某次执行”)
- 业务标识:赋予链路业务含义,例如“用户id”、“活动id”等等。
- 场景标识:赋予链路场景含义,例如当前场景是“逻辑链路1”。
- 执行标识:赋予链路执行含义,例如只涉及单次调用时,可以直接选择“traceId”;涉及多次调用时则,根据业务逻辑选取多次调用相同的“公共id”。
- 节点唯一标识 = 链路唯一标识 + 节点名称 (两个标识共同决定“某个业务场景下的某次执行中的某个逻辑节点”)
- 节点名称:DSL中预设的节点唯一名称,如“A”。
- 步骤二:传递串联标识,当逻辑链路执行时,在分布式的完整链路中透传串联标识,动态串联链路中已执行的节点,实现链路的染色。例如在“逻辑链路1”中:
-
- 当“A”节点触发执行,则开始在后续链路和节点中传递串联标识,随着业务流程的执行,逐步完成整个链路的染色。
- 当标识传递至“E”节点时,则表示“D”条件分支的判断结果是“true”,同时动态地将“E”节点串联至已执行的链路中。
2.2.3. 链路上报
“链路上报”的含义为:在链路执行过程中,将日志以链路的组织形式进行上报,实现业务现场的准确保存。

、上报的日志数据包括:节点日志和业务日志。其中节点日志的作用是绘制链路中的已执行节点,记录了节点的开始、结束、输入、输出;业务日志的作用是展示链路节点具体业务逻辑的执行情况,记录了任何对业务逻辑起到解释作用的数据,包括与上下游交互的入参出参、复杂逻辑的中间变量、逻辑执行抛出的异常。
2.2.4. 链路存储
“链路存储”的含义为:将链路执行中上报的日志落地存储,并用于后续的“现场还原”。上报日志可以拆分为链路日志、节点日志和业务日志三类:
- 链路日志:链路单次执行中,从开始节点和结束节点的日志中提取的链路基本信息,包含链路类型、链路元信息、链路开始/结束时间等。
- 节点日志:链路单次执行中,已执行节点的基本信息,包含节点名称、节点状态、节点开始/结束时间等。
- 业务日志:链路单次执行中,已执行节点中的业务日志信息,包含日志级别、日志时间、日志数据等。
下图就是链路存储的存储模型,包含了链路日志,节点日志,业务日志、链路元数据(配置数据),并且树状结构,其中业务标识作为根节点,用于后续的链路查询。

3. 链路追踪系统技术选型
Google Dapper论文发出来之后,很多公司基于链路追踪的基本原理给出了各自的解决方案,如Twitter的Zipkin,Uber的Jaeger,pinpoint,Apache开源的skywalking,还有国产如阿里的鹰眼,美团的Mtrace,滴滴Trace,新浪的Watchman,京东的Hydra,不过国内的这些基本都没有开源。为了便于各系统间能彼此兼容互通,OpenTracing组织制定了一系列标准,旨在让各系统提供统一的接口。
下面对比一下几个开源组件,方便日后大家做技术选型。

4. 分布式开源链路追踪系统
4.1. skywalking简介
Apache Skywalking是一款开源的应用程序性能监控工具,旨在帮助开发人员和 DevOps 团队监控分布式应用程序的性能。它可以帮助用户了解应用程序的运行情况,并通过可视化图形和数据报告,提供实时的指标和分析。
Skywalking 支持多种语言和框架,包括 Java、Go、Node.js 和 Python。它使用分布式追踪技术来监控应用程序内部和外部的所有调用,从而获得关于应用程序性能的完整见解。
Skywalking 提供了一系列强大的功能,包括性能监控、故障诊断和调试、数据分析等。它还提供了警报功能,当发生重要的性能问题时,可以向开发人员和 DevOps 团队发送通知。
Skywalking 还具有很好的可扩展性,可以与其他应用程序性能监控工具,如 Grafana 和 Elasticsearch 集成,从而提供更加强大的监控和分析能力。
总之,Apache Skywalking 是一款功能强大且易于使用的应用程序性能监控工具。它可以帮助开发人员和 DevOps 团队更好地了解应用程序的运行情况,并在发生性能问题时及时采取行动。
4.2. SkyWalking整体架构设计

整个架构,分成上、下、左、右四部分:
考虑到让描述更简单,我们舍弃掉 Metric 指标相关,而着重在 Tracing 链路相关功能。
- 上部分 Agent :负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。而我们目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给服务器。
- 下部分 SkyWalking OAP :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
- 右部分 Storage :Tracing 数据存储。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器。而我们目前采用的是 ES ,主要考虑是 SkyWalking 开发团队自己的生产环境采用 ES 为主。
- 左部分 SkyWalking UI :负责提供控台,查看链路等等。
4.3. SkyWalking单机部署

- skywalking agent和业务系统绑定在一起,负责收集各种监控数据。
- skywalking oapservice是负责处理监控数据的,比如接受skywalking agent的监控数据,并存储在数据库中;接受skywalking webapp的前端请求,从数据库查询数据,并返回数据给前端。Skywalking oapservice通常以集群的形式存在。
- skywalking webapp,前端界面,用于展示数据。
- 用于存储监控数据的数据库,比如mysql、elasticsearch等。
4.3.1. SkyWalking核心概念
- 服务(Service) :表示对请求提供相同行为的一系列或一组工作负载,在使用Agent时,可以定义服务的名字;
- 服务实例(Service Instance) :上述的一组工作负载中的每一个工作负载称为一个实例, 一个服务实例实际就是操作系统上的一个真实进程;
- 端点(Endpoint) :对于特定服务所接收的请求路径, 如HTTP的URI路径和gRPC服务的类名 + 方法签名;

4.3.2. 自定义SkyWalking链路追踪
<!‐‐ SkyWalking 工具类 ‐‐>
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm‐toolkit‐trace</artifactId>
<version>8.4.0</version>
</dependency>如果一个业务方法想在ui界面的跟踪链路上显示出来,只需要在业务方法上加上@Trace注解即可

我们还可以为追踪链路增加其他额外的信息,比如记录参数和返回信息。实现方式:在方法上增加@Tag或者@Tags。@Tag 注解中 key = 方法名 ; value = returnedObj 返回值 arg[0] 参数。
@Trace
@Tag(key = "list", value = "returnedObj")
public List<User> list(){
return userMapper.list();
}
@Trace
@Tags({@Tag(key = "param", value = "arg[0]"),
@Tag(key = "user", value = "returnedObj")})
public User getById(Integer id){
return userMapper.getById(id);
}
skywalking的性能分析,在根据服务名称、端点名称,以及相应的规则建立了任务列表后,在调用了此任务列表的端点后。skywalking会自动记录,剖析当前端口,生成剖析结果,具体流程如图:

4.3.3. SkyWalking和Prometheus+Grafana+Agnet的两个有区别?
SkyWalking 和 Prometheus+Grafana+Agent 是两种主流的监控与性能管理工具组合,它们的核心关注点和功能略有不同,以下是它们之间的主要区别:
4.3.4. 核心定位
- SkyWalking
-
- 分布式链路追踪与性能管理:主要专注于 APM(应用性能监控),特别是分布式系统中的链路追踪。适用于监控微服务架构下的调用链,服务性能,以及依赖关系。
-
-
- 跟踪请求从入口到各个服务间的传播路径。
- 提供更强大的调用链分析和上下文信息。
-
-
- 强调应用层的监控,如服务调用、事务性能、数据库查询等。
- Prometheus+Grafana+Agent
-
- 系统监控与告警:Prometheus 是一个以时间序列数据为核心的监控系统,适合监控基础设施(如 CPU、内存、磁盘等),也支持服务指标监控。
-
-
- Grafana 提供可视化能力,适合创建仪表盘。
- 适用于监控底层资源与自定义服务指标,更侧重于指标的收集和展示。
-
-
- Prometheus 数据采集可以结合各种 exporter(如 node_exporter,JVM_exporter)和 Agent(如 PushGateway 或其他自定义 agent)。
4.3.5. 数据采集方式
- SkyWalking
-
- 数据采集主要通过代理(Agent):
-
-
- Java、Go、Python、Node.js 等语言有专用的 SDK 或探针,支持无侵入式数据采集。
- 在分布式环境中插桩,自动记录调用链路。
- 支持服务拓扑图、调用链分析,直接呈现服务调用关系。
-
- Prometheus+Grafana+Agent
-
- 数据采集基于拉取模型:
-
-
- Prometheus 从 Exporter 拉取时间序列数据(Pull 模型)。
- 支持大规模的集群或服务,通过配置抓取不同端点的数据。
- 强调高效采集定量指标(如每秒请求数、延迟等),而非事务级别的细节。
-
4.3.6. 数据结构与存储
- SkyWalking
-
- 强调调用链数据(Tracing 数据):存储请求的每一个细节(如 TraceId、SpanId、调用栈等)。
- 数据更复杂,存储要求较高,需要 Elasticsearch、H2 或其他存储引擎。
- 主要处理分布式追踪数据,与调用上下文绑定。
- Prometheus+Grafana+Agent
-
- 使用时间序列数据库存储监控指标。
- 数据结构简单(key-value 格式),适合大量轻量指标。
- 时间序列数据通过 TSDB 存储,默认使用本地存储,也可扩展到远程存储。
4.3.7. 可视化和用户体验
- SkyWalking
-
- 自带仪表盘,聚焦于调用链、服务拓扑图和性能分析。
- UI 更倾向于帮助开发者和架构师排查服务性能问题。
- Prometheus+Grafana+Agent
-
- Grafana 提供强大的定制化仪表盘,支持多种数据源。
- 更适合基础设施运维团队用于系统资源监控和指标告警。
4.3.8. 适用场景
| 特点 | SkyWalking | Prometheus+Grafana+Agent |
| 监控粒度 | 应用级、分布式调用链 | 时间序列指标、系统资源 |
| 适合的架构 | 微服务、分布式系统 | 单体系统、微服务、基础设施 |
| 主要用途 | 性能调优、调用链分析、服务故障排查 | 系统资源监控、容量规划、告警 |
| 复杂性 | 部署复杂(代理配置、存储需求高) | 部署相对简单,但需要设置数据抓取和告警 |
4.3.9. 总结
- 如果你关注分布式系统中的服务性能与调用链,选择 SkyWalking。
- 如果你需要全面监控基础设施、服务和自定义指标,Prometheus+Grafana 更合适。
可以根据具体需求和环境,甚至同时使用两种工具进行监控。你觉得哪个更贴近你的场景?我可以进一步详细分析或帮助配置。
5. 分布式链路追踪系统实践
5.1. 链路追踪在大众点评内容平台实践
大众点评和美团App拥有丰富多样的内容,站内外业务方、合作方有着众多的消费场景。对于内容流水线中的三方,分别有如下需求:
- 内容的生产方:希望生产的内容能在更多的渠道分发,收获更多的流量,被消费者所喜爱。
- 内容的治理方:希望作为“防火墙”过滤出合法合规的内容,同时整合机器和人工能力,丰富内容属性。
- 内容的消费方:希望获得满足其个性化需求的内容,能够吸引其种草,或辅助其做出消费决策。
生产方的内容模型各异、所需处理手段各不相同,消费方对于内容也有着个性化的要求。如果由各个生产方和消费方单独对接,内容模型异构、处理流程和输出门槛各异的问题将带来对接的高成本和低效率。在此背景下,点评内容平台应运而生,作为内容流水线的“治理方”,承上启下实现了内容的统一接入、统一处理和统一输出:

- 统一接入:统一内容数据模型,对接不同的内容生产方,将异构的内容转化为内容平台通用的数据模型。
- 统一处理:统一处理能力建设,积累并完善通用的机器处理和人工运营能力,保证内容合法合规,属性丰富。
- 统一输出:统一输出门槛建设,对接不同的内容消费方,为下游提供规范且满足其个性化需求的内容数据。
如下图11所示,是点评内容平台的核心业务流程,每一条内容都会经过这个流程,最终决定在各个渠道下是否分发。

内容是否及时、准确经过内容平台的处理,是内容生产方和消费方的核心关注,也是日常值班的主要客诉类型。而内容平台的业务追踪建设,主要面临以下的困难与复杂性:
- 业务场景多:业务流程涉及多个不同的业务场景,且逻辑各异,例如实时接入、人工运营、分发重算等图中列出的部分场景。
- 逻辑节点多:业务场景涉及众多的逻辑节点,且不同内容类型节点各异,例如同样是实时接入场景,笔记内容和直播内容在执行的逻辑节点上存在较大差异。
- 触发执行多:业务场景会被多次触发执行,且由于来源不同,逻辑也会存在差异,例如笔记内容被作者编辑、被系统审核等等后,都会触发实时接入场景的重新执行。
点评内容平台日均处理百万条内容,涉及百万次业务场景的执行、高达亿级的逻辑节点的执行,而业务日志分散在不同的应用中,并且不同内容,不同场景,不同节点以及多次执行的日志混杂在一起,无论是日志的搜集还是现场的还原都相当繁琐耗时,传统的业务追踪方案越来越不适用于内容平台。
点评内容平台是一个复杂的业务系统,对外支撑着众多的业务场景,通过对于业务场景的梳理和抽象,可以定义出实时接入、人工运营、任务导入、分发重算等多个业务逻辑链路。由于点评内容平台涉及众多的内部服务和下游依赖服务,每天支撑着大量的内容处理业务,伴随着业务的执行将生成大量的日志数据,与此同时链路上报还需要对众多的服务进行改造。因此在通用的全链路日志追踪方案的基础上,点评内容平台进行了如下的具体实践。
5.1.1. 支持大数据量日志的上报和存储
点评内容平台实现了图所示的日志上报架构,支持众多服务统一的日志收集、处理和存储,能够很好地支撑大数据量下的日志追踪建设。

- 日志收集:各应用服务通过机器上部署的log_agent收集异步上报的日志数据,并统一传输至Kafka通道中,此外针对少量不支持log_agent的服务,搭建了如图所示的中转应用。
- 日志解析:收集的日志通过Kafka接入到Flink中,统一进行解析和处理,根据日志类型对日志进行分类和聚合,解析为链路日志、节点日志和业务日志。
- 日志存储:完成日志解析后,日志会按照树状的存储模型进行落地存储,结合存储的需求分析以及各个存储选项的特点,点评内容平台最终选择HBase作为存储选型。

整体而言,log_agent + Kafka + Flink + HBase的日志上报和存储架构能够很好地支持复杂的业务系统,天然支持分布式场景下众多应用的日志上报,同时适用于高流量的数据写入。
5.1.2. 实现众多后端服务的低成本改造
点评内容平台实现了“自定义日志工具包”(即下图13的TraceLogger工具包),屏蔽链路追踪中的上报细节,实现众多服务改造的成本最小化。TraceLogger工具包的功能包括:
- 模仿slf4j-api:工具包的实现在slf4j框架之上,并模仿slf4j-api对外提供相同的API,因此使用方无学习成本。
- 屏蔽内部细节,内部封装一系列的链路日志上报逻辑,屏蔽染色等细节,降低使用方的开发成本。
-
- 上报判断:
-
-
- 判断链路标识:无标识时,进行兜底的日志上报,防止日志丢失。
- 判断上报方式:有标识时,支持日志和RPC中转两种上报方式。
-
-
- 日志组装:实现参数占位、异常堆栈输出等功能,并将相关数据组装为Trace对象,便于进行统一的收集和处理。
- 异常上报:通过ErrorAPI主动上报异常,兼容原日志上报中ErrorAppender。
- 日志上报:适配Log4j2日志框架实现最终的日志上报。

下面是TraceLogger工具包分别进行业务日志和节点日志上报的使用案例,整体的改造成本较低。
业务日志上报:无学习成本,基本无改造成本。
// 替换前:原日志上报
LOGGER.error("update struct failed, param:{}", GsonUtils.toJson(structRequest), e);
// 替换后:全链路日志上报
TraceLogger.error("update struct failed, param:{}", GsonUtils.toJson(structRequest), e);节点日志上报:支持API、AOP两种上报方式,灵活且成本低。
public Response realTimeInputLink(long contentId) {
// 链路开始:传递串联标识(业务标识 + 场景标识 + 执行标识)
TraceUtils.passLinkMark("contentId_type_uuid");
// ...
// 本地调用(API上报节点日志)
TraceUtils.reportNode("contentStore", contentId, StatusEnums.RUNNING)
contentStore(contentId);
TraceUtils.reportNode("contentStore", structResp, StatusEnums.COMPLETED)
// ...
// 远程调用
Response processResp = picProcess(contentId);
// ...
}
// AOP上报节点日志
@TraceNode(nodeName="picProcess")
public Response picProcess(long contentId) {
// 图片处理业务逻辑
// 业务日志数据上报
TraceLogger.warn("picProcess failed, contentId:{}", contentId);
}基于上述实践,点评内容平台实现了可视化全链路日志追踪,能够一键追踪任意一条内容所有业务场景的执行,并通过可视化的链路进行执行现场的还原,追踪效果如下图所示:
【链路查询功能】:根据内容id实时查询该内容所有的逻辑链路执行,覆盖所有的业务场景。

【链路展示功能】:通过链路图可视化展示业务逻辑的全景,同时展示各个节点的执行情况。

【节点详情查询功能】:支持展示任意已执行节点的详情,包括节点输入、输出,以及节点执行过程中的关键业务日志。
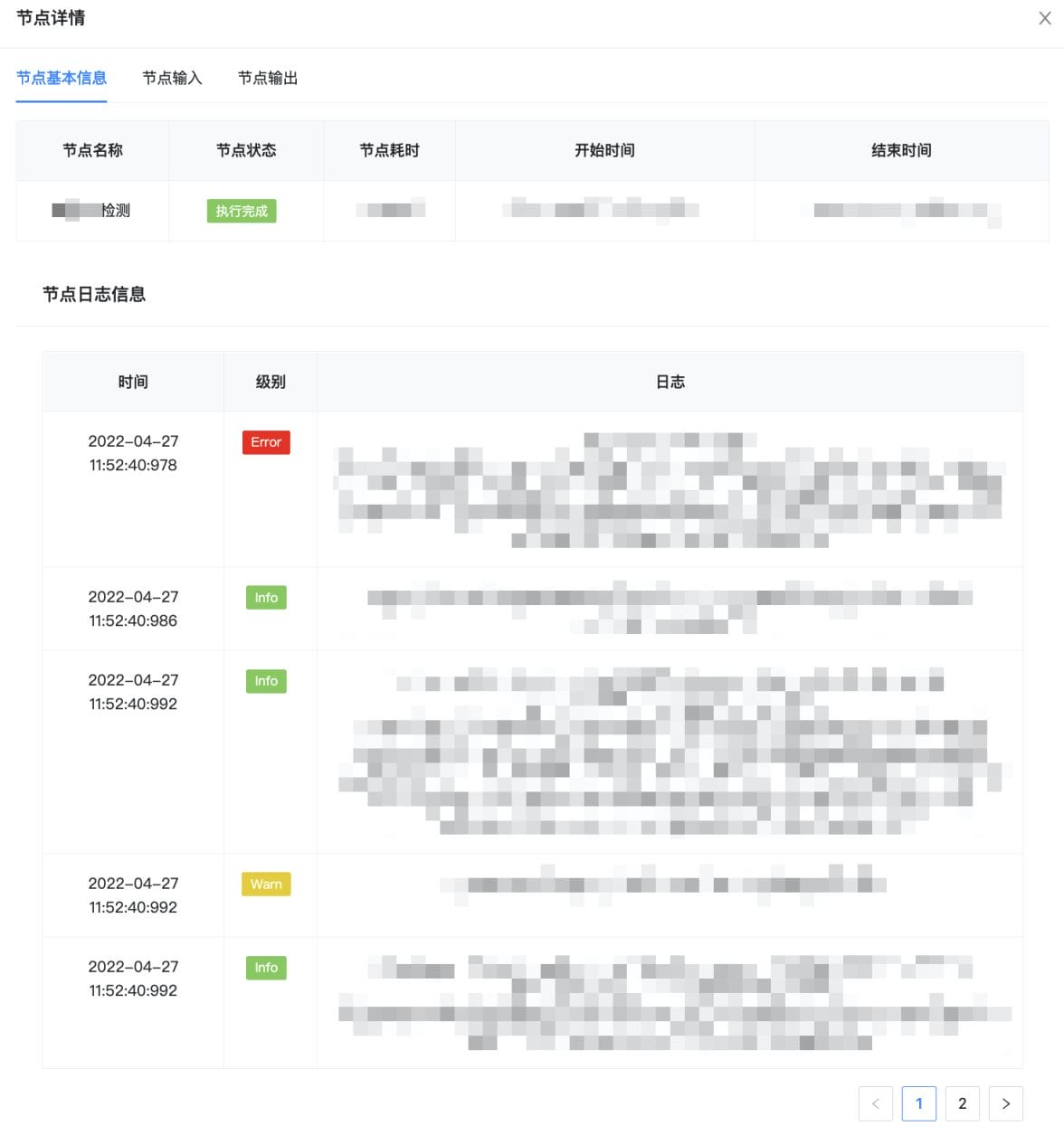
目前,可视化全链路日志追踪系统已经成为点评内容平台的“问题排查工具”,我们可以将问题排查耗时从小时级降低到5分钟内;同时也是“测试辅助工具”,利用可视化的日志串联和展示,明显提升了RD自测、QA测试的效率。最后总结一下可视化全链路日志追踪的优点:
- 接入成本低:DSL配置配合简单的日志上报改造,即可快速接入。
- 追踪范围广:任意一条内容的所有逻辑链路,均可被追踪。
- 使用效率高:管理后台支持链路和日志的可视化查询展示,简单快捷。
博文参考
- 分布式链路追踪在字节跳动的实践_哔哩哔哩_bilibili
- https://juejin.cn/post/7234836453654052922
- 美团: 可视化全链路日志追踪 | Java 全栈知识体系
- Metrics, tracing, and logging
- ELK Stack: Elasticsearch, Logstash, Kibana | Elastic
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
- OpenZipkin · A distributed tracing system
- 分布式会话跟踪系统架构设计与实践
- 凤凰架构-可观测性
- 万字破解云原生可观测性
- zipkinhttps://zipkin.io/
- Jaegerwww.jaegertracing.io/
- Pinpointhttps://github.com/pinpoint-apm/pinpoint
- SkyWalkinghttp://skywalking.apache.org/