摘要
当经过足够规模的训练时,自动回归语言模型在只需要几个例子的提示下就能表现出学习新语言任务的显著能力。在这里,我们提出了一种简单而有效的方法,将这种少量学习能力转移到多模态环境(视觉和语言)。使用对齐的图像和标题数据,我们训练了一个视觉编码器,将每个图像表示为连续嵌入的序列,这样一个预训练的、固定的语言模型就会用这个前缀提示生成适当的标题。
由此产生的系统是一个多模态少镜头学习器,当以多个交错图像和文本嵌入序列为条件时,具有学习各种新任务的惊人能力。我们证明,它可以快速学习新对象和新视觉类别的单词,仅用少量示例进行视觉问答,并利用外部知识,通过在各种既定和新的基准上测量单个模型。
1.介绍
自回归变压器已被证明是非常令人印象深刻的自然语言模型。除了标准文本生成之外,大规模语言转换器表现出了一些令人惊讶的能力[4,31]。也许最值得注意的是,他们是“短兵短马”的学习者;它们可以从几个例子中学习执行新任务,而无需进一步的梯度更新。有了这种能力,这些模型已经被证明可以通过提示(例如:)快速适应新的任务和生成方式。从正式语言转换到非正式语言)[4],在相关的语境中检索相关的百科全书或一般知识(例如回答“法国大革命是什么时候开始的?”等问题)[34,1,28],并在被教授单词的意思后直接以适当的方式使用新词(有时被称为“快速绑定”)[12,4]。
尽管有这些令人印象深刻的能力,但这种大规模的语言模型对文本以外的模式是“盲目的”,阻止我们向它们传达视觉任务、问题或概念。
事实上,哲学家和语言学家质疑一个没有根据的语言模型是否能够真正理解它所处理的语言[5,2]。
在这里,我们介绍了Frozen,这是一种让预训练的语言模型访问视觉信息的方法,这种方法将其少量学习能力扩展到多模式设置,而不改变其权重。《冰雪奇缘》由一个经过训练的神经网络组成,该神经网络将图像编码到一个大型预训练语言模型的词嵌入空间中,以便语言模型为这些图像生成字幕。语言模型的权重保持不变,但梯度通过它反向传播,从头开始训练图像编码器(图2)。尽管frozen是在单个图像-文本对上训练的,但一旦训练,它可以有效地响应多个图像和文本的交错序列。这允许用户在评估其性能之前“提示”它几个新的多模式任务示例,或者在立即询问该类别之前“教”它一个新的视觉类别的名称。
通过利用其预先训练的语言模型,Frozen在未训练的多任务上表现出非凡的零命中率,例如视觉问答(VQA)。更令人惊讶的是,在看到[4]中的一些“上下文”示例后,它在这些任务上表现得更好,并且在miniImageNet[43]等快速类别学习测试中也表现得更好。在每种情况下,与“盲”基线的比较表明,该模型不仅适应了这些新任务的语言分布,而且适应了语言和图像之间的关系。因此,Frozen是一个多模式的短时间学习者,将前面提到的快速任务适应、百科知识和快速类别绑定的语言能力带到多模式设置中。
我们开发《冰雪奇缘》的目标不是在任何特定任务上实现性能最大化,而且在许多情况下,它远没有达到最先进的水平。尽管如此,它在广泛的任务范围内执行得很好,而不需要看到这些基准提供的少量训练示例。此外,如图1所示,《冰雪奇缘》是一个对图像进行真正开放和不受约束的语言解释的系统,通常会产生引人注目的输出。
总而言之,我们的贡献如下: 1. 我们提出了 Frozen,这是一种模块化、可扩展且高效的方法,用于训练大型语言模型的视觉前端。由此产生的组合模型保留了大型语言模型的所有功能,但还可以以任意顺序处理文本和图像输入。 2. 我们表明,此类模型将其快速任务适应、百科全书式知识和快速类别绑定的能力从纯语言转移到多模态环境,并验证用视觉和语言信息提示它们可能比这样做更有效仅包含语言信息。 3. 我们根据一系列现有和新的基准对这些能力进行量化,为未来分析这些能力铺平道路。
2 相关工作
Frozen 方法的灵感来自于许多最近的工作。 [26]表明,变压器语言模型中编码的知识对于涉及跨离散序列的推理和记忆,甚至对作为空间区域序列呈现的图像进行分类的任务来说是有价值的先验。在这种方法中,预训练语言模型权重的一小部分会针对各种最终应用进行微调。相比之下,将 Frozen 应用于不同的任务并不涉及对变压器进行任何权重更新;当激活通过模型传播时,系统会适应并改进多模式(视觉和语言)任务。因此,这两项研究揭示了从文本中获取的知识可以转移到非语言环境的不同方式。
前缀调整[23]或提示调整[20]的有效性是《冰雪奇缘》的另一个重要动机。前缀调整是一种使用梯度下降来提示语言模型产生特定风格的输出的方法,以学习特定于任务的偏差项,其功能类似于文本提示的连续嵌入。使用前缀调整,语言模型可以适应不同的自然语言生成任务,例如摘要。 《Frozen》也可以被认为是一种图像条件前缀调整,其中这种连续前缀不是偏差,而是由外部神经网络产生的图像条件激活。
之前[16]已经完成了学习将图像表示嵌入到大型预训练语言模型的“单词”空间中。这项工作专注于图像文本分类,并使用针对多模态数据进行微调(而不是冻结)的 BERT 风格语言模型。 [36]扩展了类似的图像嵌入+BERT系统来创建文本的生成模型,使用预先训练的对象提取系统将图像嵌入到单词空间中。这些研究都没有考虑在几个镜头中学习图像-文本对应关系的问题。
大量工作已将 BERT [8] 等特定于文本的或多模态表示学习方法应用于视觉问答 (VQA) 和字幕(参见 [25, 40] 等)。在这些方法中,模型首先使用与任务无关的跨模式目标相关的对齐数据进行训练,然后针对特定任务进行微调。这种方法可以在一系列分类任务上产生最先进的性能。与《冰雪奇缘》不同,由此产生的系统对一项任务高度专业化,无法通过几次镜头学习新类别或适应新任务。
相比之下,[7]提出文本生成作为通用任务多模态模型的目标,产生一个像《冰雪奇缘》一样产生不受约束的语言输出的系统。与《冰雪奇缘》不同,他们不使用仅在文本上训练的预训练模型,也不考虑零次或几次学习,而是使用他们考虑的每个任务的训练数据更新系统的所有权重 - 因此,再次专门化一次只针对一项任务进行建模。类似地,[46]和[6]表明,当训练数据有限时,大型预训练语言模型作为解码器可以提高字幕性能。与《冰雪奇缘》不同,他们使用预先训练的冻结视觉编码器或对象提取器,并根据字幕数据微调文本解码器中的预先训练的权重。同样,他们不考虑不同多模态任务之间的零或几次适应。过去的工作还探索了使用潜在变量对不同模式的模型进行事后组合的替代方法[41]。
最近,多模态预训练已被证明可以在使用大规模对比学习的判别设置中实现强大的零样本泛化 [29, 14]。同样在判别性环境中,[45] 观察到大规模训练中出现的小样本学习的迹象。相比之下,我们的工作能够对新的多模态任务进行强泛化,无论是零样本还是少样本,具有完全开放式的生成文本输出。
3 Frozen 方法
Frozen 是一种在不改变权重的情况下为大型语言模型奠定基础的方法,与前缀调整密切相关[23, 20]。前缀调整训练特定于任务的连续偏差项,其功能类似于嵌入用于所有测试时示例的恒定静态文本提示。 《冰雪奇缘》通过使这个前缀动态化来扩展这种方法,因为它不是恒定的偏差,而是由神经网络发出的输入条件激活。
3.1 体系结构
预训练的自回归语言模型。我们的方法从基于 Transformer 体系结构 [42, 30] 的预训练的深度自回归语言模型开始,该模型参数化文本 y 上的概率分布。文本被 SentencePiece tokenizer [18] 分解为一系列离散标记 y = y1, y2, ..., yL。我们使用的词汇量为 32,000。语言模型使用嵌入函数 gθ ,它独立地将每个标记转换为连续嵌入 tl := gθ(yl) ,以及变换器神经网络 fθ ,其输出是参数化词汇表分类分布的 logits 向量。分布 pθ(y) 表示如下:

我们开始的模型是经过预先训练的,即θ 已通过来自互联网的大型文本数据集的标准最大似然目标进行了优化。我们使用在公共数据集 C4 上训练的 70 亿参数转换器 [31]——之前的工作表明,数十亿参数规模足以展示我们有兴趣研究的关键能力 [30, 34]。
视觉编码器。我们的视觉编码器基于 NF-ResNet-50 [3]。我们将 vφ 定义为一个函数,它采用原始图像并发出连续序列以供变压器使用。我们在全局池化层之后使用 NF-Resnet 的最终输出向量。
视觉前缀 。一个重要的要求是以转换器已经理解的形式表示图像:一系列连续嵌入,每个嵌入具有与令牌嵌入 tl 相同的维度 D。因此,我们通过将视觉编码器的输出线性映射到 D*k 通道来形成视觉前缀,然后将结果重塑为 k 个嵌入的序列,每个嵌入的维数为 D。我们将此序列称为视觉前缀,因为它起着相同的功能作用在变压器架构中作为前缀标记的嵌入序列(的一部分)。我们尝试使用不同数量的令牌 k,特别是 1、2 和 4,发现 2 的性能最好,尽管这对其他架构细节很敏感。有关该架构的更多详细信息,请参阅附录。
3.2 训练
在训练过程中,我们使用概念字幕数据集 [37] 中的成对图像字幕数据仅更新视觉编码器的参数 φ。我们的实验表明,微调 θ 会损害泛化能力,因为可用的配对图像标题数据远少于用于预训练 θ 的纯文本数据量。仅训练参数 φ 使我们的系统模块化——它可以使用现成的现有语言模型——而且也非常简单:我们只训练视觉编码器并依赖现有语言模型的功能。 遵循标准字幕系统 [22, 13],我们将字幕视为给定图像 x 的字幕文本 y 的条件生成。我们将 x 表示为 vφ(x) = i1, i2, ..., in 并训练 φ 以使似然最大化:

当参数 θ 被冻结时,视觉前缀的每个元素 ik 接收梯度 Σ l ∇ik fθ(i1, i2, ..., in, t1, t2, ..., tl−1)yl ,从而启用参数使用标准反向传播和 SGD 来优化视觉编码器(图 2)。
正如符号 fθ(i1, i2, ..., in, t1, t2, ..., tl−1) 所暗示的那样,我们在训练期间呈现视觉前缀,就好像它是在时间上早于标题(令牌嵌入)t1,t2,...。我们使用相对位置编码[38],这使得转换器能够泛化到前缀序列,其中图像并不总是位于第一个绝对位置,并且其中多个图像可能存在。特别是,我们使用 TransformerxlDai 中描述的相对注意力版本,我们将这个简单方案的改进留给未来的工作。
3.3 推理时的接口
在推理时,普通语言模型以任意文本提示 y1、y2、...、yp 为条件,自回归生成文本序列 yp+1、yp+2、...。在《冰雪奇缘》中,通过将图像的嵌入 i1、i2 作为文本嵌入子序列 t1、t2、...、tp 的前缀,可以直接在此类提示中包含图像。因为变换器 fθ 与模态无关,所以我们可以以任意顺序将文本标记嵌入的子序列与图像嵌入的子序列交织。在图 3 中,我们展示了它如何支持零样本视觉问答(图 3a)、少样本视觉问答(图 3b)和少样本图像分类(图 3c)。
为了评估这些任务,模型贪婪地解码输出序列,并将这些输出与遵循[19]中使用的归一化技术的任务的真实答案进行比较。为了探究《冰雪奇缘》的开放式功能,我们决定不使用预装答案短列表的常见做法,尽管在某些任务中这可能会损害其准确率百分比的性能。
3.4 少样本学习定义
Frozen 以一系列交错图像和文本为条件的能力使其不仅能够执行不同的多模态任务,而且还产生了将任务“诱导”到模型的不同方式以提高其性能。我们简要定义在我们的设置中使用的所有不同任务中通用的术语。有关这些概念的直观说明,请参阅附录中的图 5。
• 任务归纳 位于图像和文本序列之前的解释性文本。它旨在以自然语言向模型描述任务,例如“请回答问题”。
• 镜头数量 在评估示例之前向模型呈现的任务的不同完整示例的数量。例如,在视觉问答中,镜头是包含问题和答案的图像。
对于涉及快速类别绑定的任务(例如,少样本图像分类),我们定义了进一步的具体术语。另请参见附录中的图 4a 和图 6。
• 方式数量 任务中对象类别的数量(例如狗与猫)。
• 内部镜头的数量 向模型呈现的每个类别的不同样本的数量(即不同狗的图像数量)。在以前使用 MiniImagenet 的工作中,这些被称为镜头,但我们在这里修改了该术语,以区别于上述术语的更一般用法。
• 重复次数 每个内部镜头在呈现给模型的上下文中重复的次数。我们使用此设置作为消融来探索模型如何集成有关类别的视觉信息。
4 实验:多模态少样本学习器
我们的实验旨在量化多模态少样本学习器应具有的三种能力:快速适应新任务、快速获取常识以及视觉和语言元素的快速结合。我们在概念字幕上训练《冰雪奇缘》,这是一个由大约300万对图像字幕组成的公共数据集。我们在验证集perplexity上做了早期停止,它通常在批大小为128的单个epoch之后达到最佳。除特别说明外,所有实验均采用β1 = 0.9和β2 = 0.95的Adam优化器,学习速率恒定为3e-4。我们在训练和测试时对224×224图像进行操作。不是正方形的图像首先用0填充到正方形,然后调整大小为224×224。
4.1 快速任务适应
我们首先检查从字幕到视觉问答的零样本和少样本泛化。这是一种从字幕行为到问答行为的快速适应,类似于在纯文本设置中从语言建模到开放域问答的转变[34]。我们在 VQAv2 [10] 验证集上进行评估。
从字幕到 VQA 的零样本迁移。我们首先观察到,我们模型的一个版本(其中仅使用字幕目标训练将图像嵌入前缀的能力)可以很好地迁移到零样本中的视觉问答设定,没有针对该目标的具体培训。我们只需向系统提供图像和以下形式的文本提示:问题:坐在草地上的狗是什么颜色?答:,然后观察它是如何完成提示的。适应这种形式的输入的能力大概是从系统的预训练语言模型组件的训练数据转移的。 系统中预训练语言模型的力量是一把双刃剑。它增强了《冰雪奇缘》的泛化能力,同时也使模型在完全不考虑视觉输入的情况下表现出惊人的好。为了防止这种可能性,我们还训练盲基线,其中呈现给视觉编码器的图像被涂黑,但仍然训练卷积网络权重(参见表 1)。这相当于前缀调整[23]。我们超越了这个盲基线,它也继承了语言模型的小样本学习能力。
在这些实验中,我们还包括两个额外且重要的基线:Frozen 微调,其中语言模型从预训练的权重开始进行微调;以及 Frozen 从头开始,其中整个系统从头到尾进行训练,两者都使用相同的数据集如《冰雪奇缘》。这些基线首选较小的学习率 1e-5。表 1 中的结果表明,保持语言模型冻结对于视觉问答的推广效果比微调要好得多。从头开始训练的模型根本无法从字幕转换到 VQA;我们对此的解释是,大型语言模型的巨大泛化能力依赖于大规模训练数据集,其中预测下一个标记的任务以不可忽略的频率模仿测试设置(此处为问答)。
通过少样本学习提高性能。更重要的是,对于目前的工作,我们观察到,如果模型依次呈现多个 VQA 数据示例,则模型将知识从字幕和文本建模转移到视觉问答的能力会提高。我们使用多达四个图像-问题-答案三元组作为连续前缀序列中的条件反射信息(使用图3中的接口)向模型展示了前面的实验。
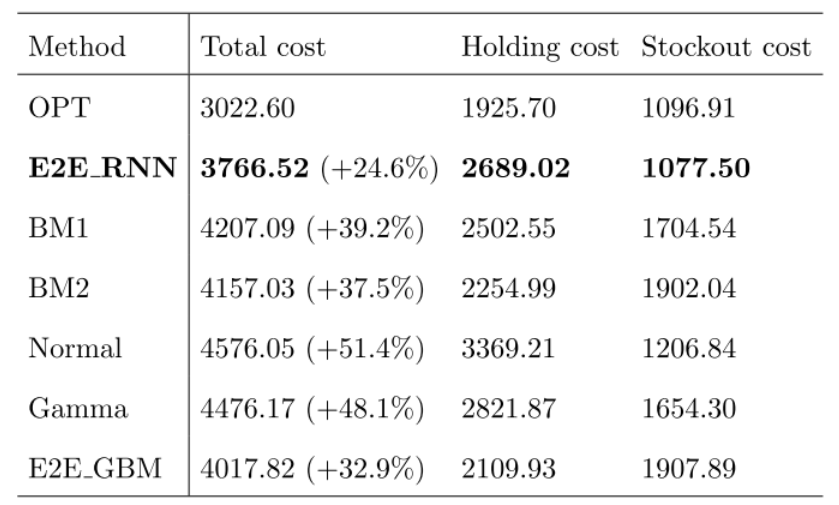
这些结果如表 1 所示。作为对比,我们将此性能与将 VQAv2 训练集中的一些数据与字幕数据混合的情况进行比较。正如我们所预料的那样,在四个示例上的少样本学习在数万个样本上的表现优于 SGD,但随着示例的增多,少样本学习的性能明显提高,并且在一定程度上 (38.2%) 缩小了与零样本的差距性能 (29.5%) 与完整 SGD 训练性能 (48.4%) 的比较
本节中提供的结果有两个重要的结论。首先,他们表明,通过预训练和冻结的语言模型训练视觉编码器会产生一个能够强大的分布外(零样本)泛化的系统。其次,他们确认,在给定适当上下文的情况下快速适应新任务的能力是从预训练的语言模型继承的,并直接转移到多模式任务。
4.2 百科全书式知识
在这里,我们研究《冰雪奇缘》在多大程度上可以利用语言模型中的百科全书式知识来完成视觉任务。概念字幕数据集是上位词(例如,专有名称被替换为像 person 这样的通用词)。这使我们能够严格研究事实知识的迁移,因为命名实体的所有知识都来自语言模型预训练。
因此,当我们向模型展示飞机图像并询问“谁发明了这个?” (图1),视觉编码器确定图像包含一架飞机,并且语言模型使用它来检索飞机是莱特兄弟发明的事实知识,这一事实在C4训练集中通过(仅文本)有关飞机的文章。这是一个令人着迷的推论链。附录中包含对此行为的详细分析以及更多示例(例如图 9、图 10、图 11)。
我们通过评估 OKVQA [27] 的性能来定量地支持这一发现,OKVQA 是一个视觉问答数据集,旨在需要外部知识才能正确回答。预训练语言模型对事实知识的掌握当然取决于其规模,因此我们使用不同大小的预训练语言模型来检查《冰雪奇缘》的性能:具有 70 亿个参数的基本模型,以及一个较小的 4 亿参数语言模型,在相同的数据集。表 2 显示了结果:任务性能随模型大小而变化。就泛化性能而言,微调的效果比冻结模型的效果还要差。我们强调《冰雪奇缘》从未接受过 OKVQA 培训。
4.3 单词到视觉类别的快速绑定
在多模式设置中,快速绑定是指模型在几个镜头中将单词与视觉类别相关联并立即以适当的方式使用该单词的能力。
开放式 miniImageNet 和实名 miniImageNet 。为了量化 Frozen 的快速绑定能力,我们在 miniImageNet 元学习任务上对其进行了评估[43]。请注意,我们尝试 miniImageNet 的方式以及之前工作中的实现方式存在重要差异。首先,与标准元学习不同,我们不会在(元)任务上训练 Frozen。其次,我们以开放式方式评估《冰雪奇缘》,它必须成功生成正确的类别名称(然后是 EOS 代币)才能获得正确的答案。最后,虽然我们使用与 miniImageNet 测试集相同的图像类,但它们具有更高分辨率(224×224),并且整数类标签 [0, 1] 替换为无意义单词(“dax”、“blicket”等)。我们进行这种调整是因为无意义的单词对于语言模型来说应该没有(或更少)比整数有内在含义,整数的相对顺序(例如)应该反映在大量的文本训练语料库中。我们将此任务称为开放式 miniImageNet。为了评估将视觉类别绑定到无意义单词与简单地适应图像识别任务本身相比会增加多少难度,我们还考虑了一个版本 - Real-Name miniImagenet - 其中支持集和答案中的视觉类别都保留了它们的特性原来的名字。请参见图 4a 的说明。
在此评估的两个版本中,我们通过将模型暴露于不同数量的内部镜头、重复和任务归纳来进行实验。在双向开放式 miniImagenet 上,我们观察到,当向《冰雪奇缘》呈现一系列图像和它们的新名称描述时,它能够学习所呈现对象的新名称,然后立即使用这些新名称,实质上与上述相同。机会准确性。重要的是,随着相应类别的示例增多,模型使用这些新词的能力也会提高。值得注意的是,当支持信息涉及视觉类别中的不同样本(内部镜头)而不是单个样本的重复(重复)时,这种上升趋势更加明显。因此,可以通过更丰富、更多样化的视觉支持或提示来提高模型的快速绑定能力。
在双向实名 miniImagenet 上,我们观察到类似的趋势,但绝对性能更高。这凸显了开放式 miniImagenet 中的困难,因为必须将新词分配给模型可能已知的类别,并且因为真实姓名可能携带从模型训练的字幕数据中利用的视觉信息。
在表 4 中,我们表明在开放式 miniImagenet 上观察到的效果不会转移到 5 路设置,其中 Frozen 并没有显着高于机会。这表明,学习在一次前向传递中将五个新名称绑定到五个视觉类别超出了《冰雪奇缘》当前的能力。然而,和以前一样,随着内部镜头或重复次数的增加,我们确实观察到模型返回五种可能性中视觉类别的实际名称的能力呈上升趋势。需要进一步的工作,我们期待在这个更具挑战性的环境中取得进展。
Fast-VQA 和 Guided-VQA 当 Transformer 接受训练来对文本进行建模时,它们的注意力权重会学习关联(或“绑定”)句子中的单词对。 miniImageNet 的实验表明,这种能力可以直接转移到将视觉类别与其名称绑定,使系统能够按需生成名称。这就提出了一个问题:《冰雪奇缘》是否可以将新获得的视觉类别(及其名称)更完整地集成到模型的语言系统中,以便它可以描述或回答有关该类别的问题。
为了测试这种能力,我们利用两个著名的数据集 ImageNet [35] 和 Visual Genome [17] 构建了一个新任务 - Fast-VQA。对于每个问题,向模型提供无意义的单词(“dax”和“blockket”)和n张取自ImageNet的这些单词的指涉物的图像(例如“猫”或“狗”)。然后,它被问一个问题,其中至少包含这两个词中的一个,关于另一个图像(取自Visual Genome),其中两个指涉物都出现了(见图4b)。与miniImagenet一样,单词“dax”和“blicket”(以及它们的指代方式)对《冰雪奇兵》来说应该是新的,但相应的视觉类别可能是从Conceptual Captions训练数据中知道的,尽管名称不同。
为了量化为已知类别引入新单词使这项任务变得有多困难,我们还创建了一个变体(Guided-VQA),其中使用原始类别名称(“cat”或“dog”)而不是“dax”,并且“外观”。 Guided-VQA 是 Fast-VQA 的一个特例,涉及来自 Visual Genome 的问题,在回答问题之前,通过用真实的类别名称标记样本图像来提醒模型问题中的重要实体是什么样子。 Guided-VQA 不需要具有将类别与新单词绑定的相同能力,但它确实可以衡量模型在以零样本方式尝试新任务时如何利用与任务相关的多模态指导。
Fast-VQA 和 Guided-VQA 是非常具有挑战性的任务,因为它们是在没有特定于任务的训练的情况下尝试的,而且因为潜在的问题来自视觉基因组(VQAv2 图像不附带构建任务所需的元数据)。视觉基因组问题特别具有挑战性,因为每个问题只有一个答案。在对模型进行评分时,为了简单起见,我们仅考虑与模型生成的输出的精确匹配,并对 VQAv2 所应用的相同后处理进行取模。由于任务固有的难度,我们使用强大的基线,仍然可以利用大型语言模型来验证观察到的效果的强度。
如表 5 所示,随着 Fast-VQA 和 GuidedVQA 中更多镜头的出现,模型得到了改进,这一事实证实了 Frozen 具有一定的能力,可以将新词整合到其在多模态环境中处理和生成自然语言的一般能力中。值得注意的是,随着更多类别的出现,无法访问图像的前缀调整模型在 Guided-VQA 中得到了适度改善,这表明额外的语言线索(只是提醒所涉及的单词和任务的语言形式)在一定程度上取得了进展为接下来的问题做准备。如图 4 所示,对模型输出的检查证实,在许多情况下,确实是多模式(而不仅仅是语言)支持使《冰雪奇缘》能够随着镜头数量的增加而提高性能。我们观察到,随着镜头数量的增加,性能增益的回报递减。一种可能的解释是,从单个图像的上下文训练分布到多个图像的训练分布的转变导致模型不准确。
开放式 miniImagenet、实名 miniImagenet、Fast-VQA 和 Guided-VQA 评估集可在https://fh295.github.io/frozen.html 下载。
5讨论
5.1 局限性
我们相信这项工作是一个重要的概念验证,对于一个理想的、更强大的、能够进行开放式多模式小样本学习的系统来说。 Frozen 在某种程度上实现了必要的能力,但一个关键的限制是,与使用完整训练集的系统相比,它在几次镜头中学习的特定任务上的表现远未达到最先进的水平。包。因此,这项工作的主要贡献应该被视为多模态少样本学习这个令人兴奋的研究领域的起点或基线。
进一步的改进可以使我们观察到的令人印象深刻的零样本和少样本泛化变得更加稳健,这体现在更高的精度和更少的种子来展示我们最引人注目的样本。最后,本次概念验证研究中还没有探讨许多技术问题,例如是否可以通过更复杂的混合视觉和语言的架构来提高性能。我们将对这些可能性的探索留待未来的调查。我们随本手稿提供的开放式 miniImageNet、实名 miniImagenet、Fast-VQA 和 Guided-VQA 基准应该有助于对此类未来系统的评估和分析。
5.2 社会影响
随着这种新型通用视觉语言模型的出现,大规模监控的新功能变得可行。监控录像和公开共享的图像都可以分析任意问题,无需任何新的标记数据或对系统进行培训。作为对个人的缓解措施,具有类似功能的个人助理软件可以分析有关他们自己的公开文件,以识别意外的暴露,即使由于社会变化或个人偏好的变化而出现新的担忧。
可以包含视觉信息的文本生成模型可以通过使语言模型生成的内容更具说服力来提高其滥用程度。此外,目前我们还没有足够的工具来识别通用视觉引导语言模型的偏见和毒性问题。我们邀请社区思考这方面的有效方法和基准。
更积极的是,像《冰雪奇缘》这样的系统可以用来帮助视障用户使用技术。 《冰雪奇缘》适应不同风格的标题或问题的能力可以在这些情况下实现更加个性化的用户体验。
在《冰雪奇缘》等系统中训练大型网络会带来环境成本。另一方面,一个可以训练一次然后灵活适应不同设置的系统总体上比需要针对不同应用重新训练的系统具有更低的能量足迹。
5.3 结论
我们提出了一种将大型语言模型转换为多模态少样本学习系统的方法,通过将前缀调整的软提示原理[23]扩展到有序的图像和文本集,同时保留语言模型的文本提示能力。我们的实验证实,最终的系统《冰雪奇缘》既能够对图像进行开放式解释,又能够进行真正的多模态少镜头学习,即使该系统只接受过字幕训练。这些结果的一个推论是,快速绑定在一起或关联语言中不同单词所需的知识也与将语言快速绑定到一组有序输入中的视觉元素有关。这一发现将[26]的结论——变压器语言模型中的知识可以迁移到非语言任务——扩展到关于小样本学习的知识的具体情况。
致谢 我们要感谢 Sebastian Borgeaud 和 Jack Rae 准备预训练文本数据集并预训练一系列 Transformer 语言模型,以及 Trevor Cai 在实验和基础设施方面提供的帮助。我们还要感谢 Pauline Luc、Jeff Donahue、Malcolm Reynolds、Andy Brock、Karen Simonyan、Jean-Baptiste Alayrac、Antoine Miech、Charlie Nash、Aaron van den Oord、Marc Deisenroth、Aida Nematzadeh、Roman Ring、Francis Song、Eliza Rutherford 、Kirsty Anderson、Esme Sutherland、Alexander Novikov、Daan Wierstra 和 Nando de Freitas 在项目过程中进行了富有洞察力的讨论。