2024-11-22 ,由格拉斯哥大学创建的OSPTrack数据集,目的是通过捕获在隔离环境中执行包和库时生成的特征,包括静态和动态特征,来识别开源软件(OSS)中的恶意指标,特别是在源代码访问受限时,支持在运行时高效检测方法。
数据集地址:OSPTrack
一、研究背景:
开源软件(OSS)已成为互联网和网络供应链链中不可或缺的一部分,但其被利用的频率越来越高。尽管在OSS的漏洞检测方面取得了进展,但先前的工作主要集中在静态代码分析上,忽略了运行时指标。
目前遇到困难和挑战:
1、现有的漏洞检测方法往往侧重于静态代码分析,这在OSS嵌入复杂系统时可能效率不高。
2、当前的数据集主要关注恶意软件包,未能捕获运行时特征。
3、尽管已有软件模拟开发,但没有专门针对OSS并提供执行期间标记监控结果的数据集。
数据集地址:OSPTrack
二、让我们来一起看一下OSPTrack数据集
OSPTrack是一个跨越多个生态系统的标签化数据集,它在隔离环境中捕获了执行包和库时生成的特征,包括静态和动态特征,如文件、套接字、命令和DNS记录。
OSPTrack数据集包含9461个包报告(其中1962个为恶意),涵盖了npm、pypi、crates.io、nuget和packagist等多个生态系统。数据集包含了详细的子标签,用于攻击类型的验证信息,有助于在源代码访问受限的情况下识别恶意指标,并支持在运行时进行有效的检测方法。
数据集构建 :
数据集的构建采用了多进程分析包、报告解析与特征提取、最终标签匹配的方法。部分数据来自现有的BigQuery数据集,该数据集由package-analysis工具生成,包含静态和动态特征。
数据集特点 :
OSPTrack数据集的特点在于其八维特征,包括文件、套接字、命令和DNS相关行为,这些特征有助于在不同生态系统中进行差异性或比较性分析。
基准测试:
数据集可用于训练机器学习模型,区分良性和恶意软件行为,以及检测运行中的软件漏洞,确保开源软件的供应链安全。

数据生成框架。1. 收集包裹信息 1.a.查询分析了来自 BigQuery 2 的结果。在多个过程中使用包装分析模拟包装 3.解析 JSON 报告并查询 Parquet 报告,提取特征 4.根据已知标签匹配和生成标签
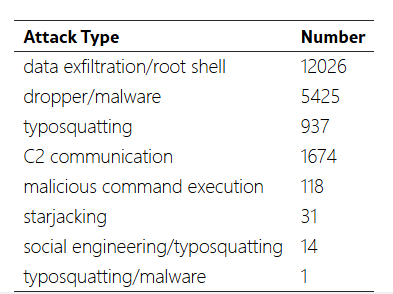
软件供应链中的攻击类型集合
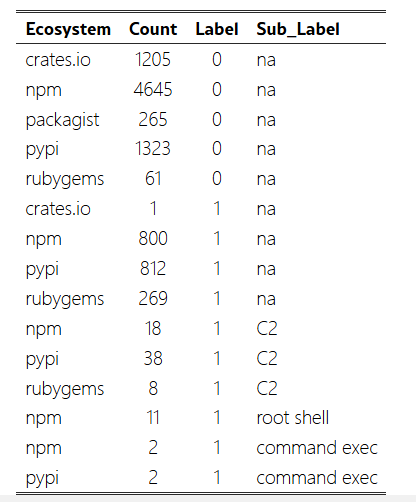
按生态系统、包计数、标签和子标签划分的包计数。
三、让我们一起展望数据集的应用:
比如,你是一个网络安全专家,你的任务是识别出那些偷偷摸摸的恶意软件。这些恶意软件会悄悄地潜入你的系统,然后搞破坏。但是,要抓到这些恶意软件可不是一件容易的事,因为它们很会伪装,而且手段多样。
现在,我们有了一件秘密武器——OSPTrack数据集。它提供了大量的恶意软件样本和它们的行为特征。我们要用这个工具箱里的一个特殊技巧,叫做多模态特征融合,来帮助我们更准确地识别出这些恶意软件。
这个技巧的关键在于,我们不仅仅从一个角度去看问题,而是从多个角度。就像我们用两个不同的镜头去看同一个东西,一个镜头是数字的,另一个是文本的。
首先,我们用数字编码器这个镜头,它能够捕捉恶意软件的数字特征,比如它们的操作码统计序列。这就像是给每个恶意软件拍了一张“照片”,捕捉了它们的行为模式。
然后,我们用文本编码器这个镜头,它能够把恶意软件的特征组织成句子,描述它们的行为和动态。这就像是给恶意软件写了一个故事,然后用语言模型这个翻译器,把这些故事转换成电脑能理解的语言。
接下来,我们把这些数字和文本的特征融合在一起,就像是给每个恶意软件一个“双重身份”。这样,我们就能在两个不同的空间里分析它们,一个用于分类,一个用于检测。
在实际操作中,我们就像是在厨房里忙碌的大厨。我们先把恶意软件样本进行预处理,就像是把食材洗干净、切好。然后,我们用深度学习模型,比如EfficientNetV2,来提取和融合这些特征。这个模型就像是我们的高级厨具,它的优化网络结构和SE注意力机制模块,就像是我们的刀和砧板,帮助我们更精确地捕捉和强调关键特征。
最后,我们在一些常用的恶意软件数据集上进行实验,比如Mailing和我们提出的MAL-100+,就像是在不同的餐厅里试菜。结果证明,我们的方法非常有效。我们的模型不仅提高了恶意软件检测的准确性,还增强了对未知恶意软件样本的检测能力,就像是我们的菜在各个餐厅都受到了好评。
更多开源的数据集,请打开:遇见数据集
遇见数据集-让每个数据集都被发现,让每一次遇见都有价值遇见数据集,国内领先的百万级数据集搜索引擎,实时追踪全球数据集市场,助力把握数字经济时代机遇。![]() https://www.selectdataset.com/
https://www.selectdataset.com/
![[Docker-显示所有容器IP] 显示docker-compose.yml中所有容器IP的方法](https://i-blog.csdnimg.cn/direct/5860dc9b0d644f25835fc723cb0d33a9.png)