神经网络原理
引言
在理解ChatGPT之前,我们需要从神经网络开始,了解最简单的“鹦鹉学舌”是如何实现的。神经网络是人工智能领域的基础,它模仿了人脑神经元的结构和功能,通过学习和训练来解决复杂的任务。本文将详细介绍神经网络的基本原理、训练过程以及其在实际应用中的表现。
人脑神经元的结构与功能

上图展示了一个大脑神经元的结构,由多个树突、轴突和细胞核构成。树突用于接收电信号,经过细胞核加工(激活)信号,最后由轴突输出电信号。人脑大约有860亿个神经元细胞,突触相互连接,形成复杂的拓扑结构。
每个神经元大约有1163到11628个突触,突触总量在14到15个数量级,放电频率大约在400到500Hz,每秒最高计算量大约40万亿次。换算成当前流行的词汇,大脑大概等价于一个100T参数的模型(相比之下,140B的模型显得逊色)。与当前大模型中的ReLU激活函数不同,大脑的惰性计算不需要计算0值,效率更高。
神经网络的基本架构
神经网络借鉴了人脑神经元的输入、计算、输出架构和拓扑设计。一个典型的神经网络由输入层、隐藏层和输出层组成。每一层包含多个神经元,神经元之间通过权重连接。输入层接收外部数据,隐藏层进行复杂的计算,输出层给出最终结果。
神经网络的训练过程
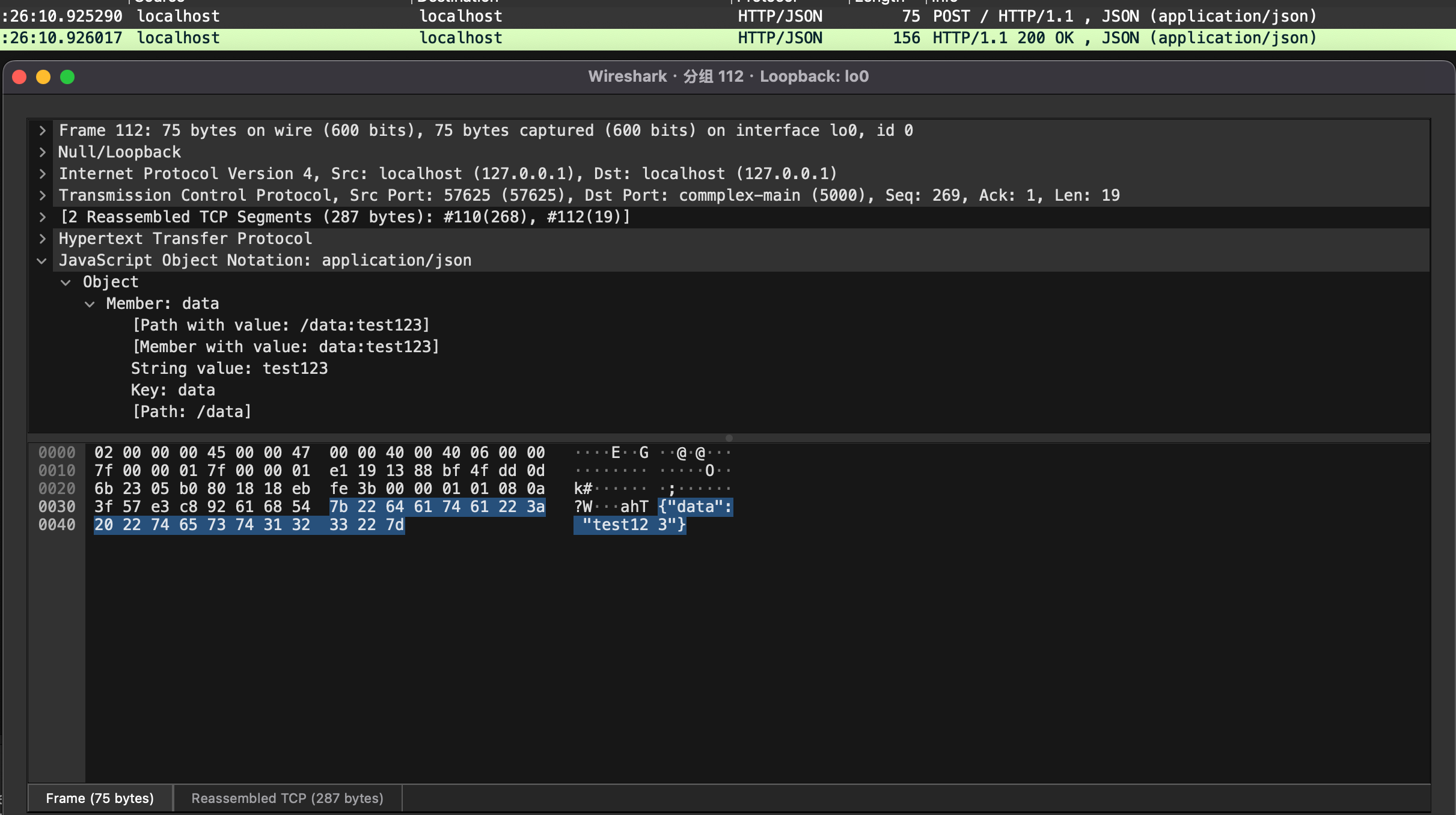
下面以一个求解数学问题的例子,来看神经网络的实现原理:
当输入X为
时,输出Y为
。通过训练神经网络,以求得X和Y之间的隐含关系,并给出当X为图片时,Y的值。
(为了便于观察训练过程,我们提前知道f(x) = x1*w1 + x2*w2 + b,其中w1 = w2 = 1,b = 6.6260693。实际上,f(x)可以是任意函数。)
训练过程如下:
- 数据预处理:对输入的X,分解成n个向量(为了举例方便,实际是直接矩阵计算,实现batch)。
- 初始化参数:对每个向量的X1和X2元素,假定一个函数
f(x) = x1*w1 + x2*w2 + b进行计算(其中w1、w2和b用随机值初始化)。 - 前向传播:用假定的
f(x)计算X,得到结果并与样本Y进行比照。如果有差异,调整w1、w2和b的值,重复计算。 - 反向传播与优化:通过计算损失函数(如均方误差),使用梯度下降法调整参数,直到差异收敛到某个程度(比如小于1),训练结束。

从训练过程可以看出,经过99轮重复计算和调整W/B值后(训练),在第100轮通过瞎猜求得f(x) = x1*0.9991 + x2*0.9853 + 6.3004。用最后一组数据X计算得到的结果已经非常接近样本数据,说明这些参数(模型)在这个场景中已经对f(x)求得了最优解。

对输入X(-6.8579 7.6980)进行预测,得到的Y值为7.0334,与最初假定(w1 = w2 = 1,b = 6.6260693)参数计算得到的结果仅相差0.2左右,预测结束。
神经网络的应用
神经网络在多个领域有广泛的应用,包括但不限于:
- 图像识别:通过训练神经网络,可以识别图像中的物体、人脸等。
- 自然语言处理:如ChatGPT,通过神经网络理解和生成自然语言文本。
- 语音识别:将语音信号转换为文本,实现语音助手等功能。
- 推荐系统:根据用户的历史行为,推荐相关的产品或内容。
结论
神经网络作为人工智能的核心技术之一,通过模仿人脑的结构和功能,实现了复杂任务的自动化处理。通过不断的训练和优化,神经网络能够在各种应用场景中表现出色,为我们的生活带来便利。随着技术的不断进步,神经网络的应用前景将更加广阔。