🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
SD模型原理:
- Stable Diffusion概要讲解
- Stable diffusion详细讲解
- Stable Diffusion的加噪和去噪详解
- Diffusion Model
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——CLIP Text Encoder
- Stable Diffusion核心网络结构——U-Net
- Stable Diffusion中U-Net的前世今生与核心知识
- SD模型性能测评
- Stable Diffusion经典应用场景
- SDXL的优化工作
微调方法原理:
- DreamBooth
- LoRA
- LORA及其变种介绍
- ControlNet
- ControlNet文章解读
- Textual Inversion 和 Embedding fine-tuning
 目录
目录
文本生成图像(txt2img)
【一】生成图片的尺寸(width和height)
【二】推理步数(steps、num_inference_steps或者Sampling steps)
【三】guidance_scale(guidance_scale或者CFG Scale)
【四】Negative Prompt
图像生成图像(img2img)
图像重绘(Inpainting)
图像的可控生成(使用ControlNet辅助生成)
图像超分辨率重建
摘录来源:https://zhuanlan.zhihu.com/p/632809634
在本章节中,将详细介绍Stable Diffusion的五大经典应用,并梳理各个经典应用场景的完整工作流(Workflow),清晰直观的展示SD应用场景的每个细节流程,让大家对SD经典应用场景有更深的理解。【这里主要介绍其中两种:文生图和图生图】
文本生成图像(txt2img)
文本生成图像是SD系列模型最基础也是最核心的应用功能,下面是SD系列模型进行文本生成图像的完整流程:

根据上面的完整流程图,我们
结构化分析一下SD系列模型进行文本生成图像的脉络:
- 输入:将输入的文本(prompt)通过Text Encoder提取出Text Embeddings特征(77x768);同时初始化一个Latent空间的随机高斯噪声矩阵(维度为64x64x4,对应512x512分辨率图像)。
- 生成过程:将Text Embeddings特征和随机高斯噪声矩阵通过CrossAttention机制送入U-Net中,结合Scheduler algorithm(调度算法)【和采样算法】迭代去噪,经过N次迭代后生成去噪后的Latent特征。
- 输出:将去噪后的Latent特征送入VAE的Decoder模块,重建出像素级图像(512x512分辨率)。
节点式结构图展示一下SD模型进行文本生成图像的全部流程:

其中Load Checkpoint模块代表对SD系列模型的主要结构的权重进行加载初始化(VAE、U-Net、Text Encoder),CLIP Text Encode表示文本编码器,可以输入Prompt和Negative Prompt,来控制图像的生成,Empty Latent Image表示初始化的高斯噪声,KSampler表示调度算法以及SD相关生成参数,VAE Decode表示使用VAE的解码器将Latent特征转换成像素级图像。
SD在推理过程中的几个重要参数:
- 生成图片的尺寸(width和height)
- 推理步数(steps、num_inference_steps或者Sampling steps)
- guidance_scale(guidance_scale或者CFG Scale)
- Negative Prompt
【一】生成图片的尺寸(width和height)
之前我们已经讲过,SD模型是在512x512分辨率的数据上进行训练的,所以在默认情况下生成512x512分辨率的图片效果最好。
SD本身的模型结构也是支持任意尺寸的图像生成的,因为SD模型中的VAE支持任意尺寸图像的编码和解码,U-Net部分(只有卷积结构和Attention机制,没有全连接层)也是支持任意尺寸的Latent特征的生成。
然而,由于原生SD模型在训练时输入尺寸是固定的,这就导致了实际使用时生成512x512分辨率以外的图像会出现问题。在生成低分辨率(比如256x256)图像时,图像的质量会大幅度下降;在生成高分辨率(比如768x512、512x768、768x768、1024x1024)的图像时,图像质量虽然没问题,但是可能会出现物体特征重复、物体被拉长、主体结构崩坏等问题。
解决这个问题的一个直观有效的方法是进行多尺度训练。在传统深度学习时代,这是YOLO系列模型的一个必备训练方法,终于跨过周期在AIGC时代重新繁荣,并由NovelAI优化后变成了适合于SD系列模型的Aspect Ratio Bucketing策略。
【二】推理步数(steps、num_inference_steps或者Sampling steps)
num_inference_steps表示SD系列模型在推理过程中的去噪次数或者采样步数。一般来说,我们可以设置num_inference_steps在20-50之间,其中设置的采样步数越大,图像的生成效果越好,但同时生成所需的时间就越长。
到这里大家可能会有疑问,为什么SD系列模型在训练时设置1000的noise scheduler,在推理时却只用设置20-50的noise scheduler?
这是因为,虽然SD模型在训练时参照DDPM采样方法,但推理时可以使用DDIM这个采样方法,DDIM通过去马尔可夫化,让SD模型在推理时可以进行“跳步”,抽取短的子序列作为noise scheduler,大大减少了推理步数。
当然的,除了使用DDIM采样方法,我们也可以使用其他的采样方法,目前主流的采样方法有DPM系列、DPM++系列、Euler系列、LMS系列、Heun、UniPC、Restart等。
【三】guidance_scale(guidance_scale或者CFG Scale)
guidance_scale代表CFG(无分类指引,Classifier-free guidance,guidance_scale)的权重,当设置的guidance_scale越大时,文本的控制力会越强,SD模型生成的图像会和输入文本更一致。通常guidance_scale可以设置在7-8.5之间,就会有不错的生成效果。如果使用非常大的guidance_scale值(比如11-12),生成的图像可能会过饱和,同时多样性会降低。
当我们使用CFG之后,SD模型在去噪过程会同时依赖条件扩散模型和无条件扩散模型:

其中w代表guidance_scale,当w越大时,输入文本起的作用越大,即生成的图像更和输入文本一致,当w被设置为0时,图像的生成是无条件的,输入文本会被忽略。
【四】Negative Prompt
我们可以使用Negative Prompt来避免生成我们不想要的内容,从而改善图像生成效果。
Negative Prompt和CFG有关,下面的公式中包含了条件扩散模型和无条件扩散模型:
 Negative Prompt就是无条件扩散模型的文本输入,只是SD模型的训练过程中我们将文本设置为空字符串来实现无条件扩散模型,即negative_prompt = ""。当推理阶段我们开始使用Negative Prompt时,这部分的文本不再为空,并且从上述公式可以看出无条件扩散模型是我们想远离的分布。
Negative Prompt就是无条件扩散模型的文本输入,只是SD模型的训练过程中我们将文本设置为空字符串来实现无条件扩散模型,即negative_prompt = ""。当推理阶段我们开始使用Negative Prompt时,这部分的文本不再为空,并且从上述公式可以看出无条件扩散模型是我们想远离的分布。
图像生成图像(img2img)
SD模型的图生图功能是以文生图功能为基础的一个拓展功能,和文生图相比,图生图的初始Latent特征不再是一个随机噪声,而是初始输入图像通过VAE编码之后加上一定高斯噪声(扩散过程)的Latent特征。然后使用SD模型进行去噪操作,此时去噪的步数要和加噪的步数保持一致,这样才能生成整体布局与初始图像一致的无噪声图像。

与此同时,我们【通过调度器】设置一个去噪强度(Denoising strength)来控制加入多少噪声。如果设置Denoising strength = 0,就不添加噪声。如果设置Denoising strength = 1,则添加噪声原始图像成为一个随机噪声矩阵,此时就相当于进行文生图的流程了。

讲完了图生图的完整流程,我们在结构化分析一下SD系列模型进行图生图的脉络:
- 输入:将输入的文本(prompt)通过Text Encoder提取出Text Embeddings特征(77x768);同时将初始图像通过VAE编码成一个Latent特征(维度为64x64x4,对应512x512分辨率图像)。
- 生成过程:通过扩散过程往Latent特征中加入N次迭代的噪声,再将Text Embeddings特征和随机高斯噪声矩阵通过CrossAttention机制送入U-Net中,结合Scheduler algorithm(调度算法)【和采样算法】迭代去噪,经过N次迭代后生成去噪后的Latent特征。
- 输出:将去噪后的Latent特征送入VAE的Decoder模块,重建出像素级图像(512x512分辨率)。
下面Rocky再用节点式结构图展示一下SD模型进行图生图的全部流程:

其中Load Checkpoint模块代表对SD模型的主要结构进行初始化(VAE、U-Net、Text Encoder),CLIP Text Encode表示文本编码器,可以输入Prompt和Negative Prompt,来控制图像的生成,Load Image表示输入的初始图像,KSampler表示调度算法以及SD相关生成参数,VAE Encode表示使用VAE的编码器将初始图像转换成Latent特征,VAE Decode表示使用VAE的解码器将Latent特征转换成像素级图像。
图像重绘(Inpainting)
图像inpainting最初用在图像修复上,是一种图像修复技术,可以将图像中的水印、噪声、标志等瑕疵去除。
传统的图像inpainting过程可以分为两步:
- 找到图像中的瑕疵部分
- 对瑕疵部分进行重绘去除,并填充图像内容使得图像语义完整自然。
在AIGC时代,图像inpainting再次繁荣,成为Stable Diffusion的经典应用场景,在图像编辑上重新焕发生机。
那么什么是图像编辑呢?
图像编辑是指对图像进行修改、调整和优化的过程。它可以包括对图像的颜色、对比度、亮度、饱和度等进行调整,以及修复图像中的缺陷、删除不需要的元素、添加新的图像内容等操作。
在SD中,主要是通过给定一个想要编辑的区域mask,并在这个区域mask圈定的范围内进行文本生成图像的操作,从而编辑mask区域的图像内容。
SD中的图像inpainting流程如下所示:
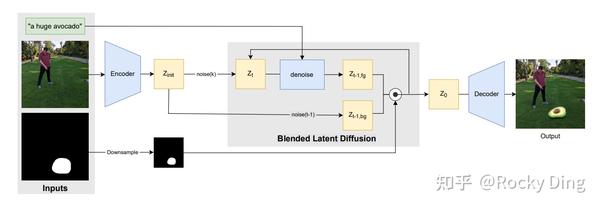
从上图可以看出,图像inpainting整体上和图生图流程一致,不过为了保证mask以外的图像区域不发生改变,在去噪过程的每一步,我们利用mask将Latent特征中不需要重建的部分都替换成原图最初的特征,只在mask部分进行特征的重建与优化。
在加入了mask后,SD模型的输入通道数也发生了变化,文生图和图生图任务中,SD的输入是64x64x4,而在图像inpainting任务中,增加了mask(64x64x1),所以此时SD的输入为64x64x5。
讲完了图像inpainting的完整流程,我们在结构化分析一下SD系列模型进行图像inpainting的脉络:
- 输入:将输入的文本(prompt)通过Text Encoder提取出Text Embeddings特征(77x768);同时将初始图像和Mask通过VAE分别编码成两个Latent特征(维度分别为64x64x4和64x64x1,对应512x512分辨率图像)。
- 生成过程:通过扩散过程往Latent特征中加入N次迭代的噪声,但只影响Mask涵盖的区域,再将Text Embeddings特征和随机高斯噪声矩阵通过CrossAttention机制送入U-Net中,结合Scheduler algorithm(调度算法)迭代去噪,经过N次迭代后生成去噪后的Latent特征。
- 输出:将去噪后的Latent特征送入VAE的Decoder模块,重建出像素级图像(512x512分辨率)。
下面Rocky再用节点式结构图展示一下SD模型进行图像inpainting的全部流程:

其中Load Checkpoint模块代表对SD模型的主要结构进行加载(VAE、U-Net、Text Encoder)。CLIP Text Encode表示SD模型的文本编码器,可以输入Prompt和Negative Prompt,来引导图像的生成。Load Image表示输入的图像和mask。KSampler表示调度算法以及SD相关生成参数。VAE Encode表示使用VAE的Encoder将输入图像和mask转换成Latent特征,VAE Decode表示使用VAE的Decoder将Latent特征重建成像素级图像。
下面就是进行图像inpainting的直观过程:

由于图像inpainting和图生图的操作一样,只是在SD模型原有的基础上扩展了它的能力,并没有去微调SD模型,所以如何调整各种参数成为了生成优质图片的关键。
当然的,也有专门用于图像inpainting的SD模型,比如说Stable Diffusion Inpainting模型,是以SD 1.2为基底模型微调而来,同时在输入端增加了经过mask处理的图像的Latent特征(64x64x4)和mask(64x64x1),所以此时SD的输入为64x64x9,同时新增的部分设置权重全零初始化。Stable Diffusion Inpainting模型由于经过专门的inpainting训练,在生成细节上比起常规SD模型会更好,但是相应的常规文生图的能力会有一定的减弱。
图像的可控生成(使用ControlNet辅助生成)
SD系列模型的可控生成主要依赖于ControlNet等控制模型,可以与文生图、图生图以及图像Inpainting等任务结合使用。
ControlNet的核心基础知识:
- ControlNet
- ControlNet文章解读
下面Rocky用节点式结构图展示一下SD模型使用ControlNet辅助生成的全部流程:

其中Load Checkpoint模块代表对SD模型的主要结构进行初始化(VAE、U-Net、Text Encoder),CLIP Text Encode表示文本编码器,可以输入Prompt和Negative Prompt,来控制图像的生成,Load Image表示输入的ControlNet需要的预处理图,Empty Latent Image表示初始化的高斯噪声,Load ControlNet Model表示对ControlNet进行初始化,KSampler表示调度算法以及SD相关生成参数,VAE Decode表示使用VAE的解码器将Latent特征转换成像素级图像。
图像超分辨率重建
图像超分辨率重建可以说是图像生成任务的一个后处理功能,用于获得高分辨率的高质量图像。
目前主流的超分模型主要分两类,一类是基于传统深度学习时代的GAN模型(R-ESRGAN、ESRGAN、ScuNET GAN等),另外一类是基于AIGC时代的扩散模型(LDSR、stable-diffusion-x4-upscaler等)。
下面Rocky用节点式结构图展示一下SD模型进行图像超分辨率重建的全部流程:
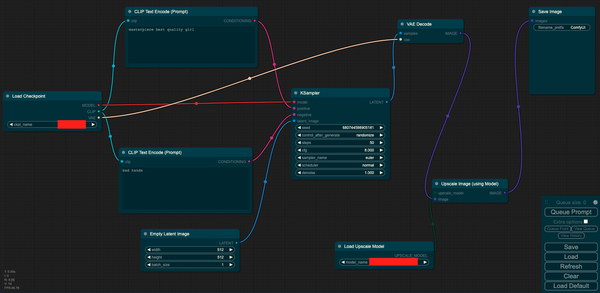
在结构图中可以看到,整体流程与文生图和图生图一致,在此基础上增加了Upscale Image表示对生成的图片进行超分操作。