概述
虽然大规模语言模型发展迅速,但对其进行评估却变得越来越困难。人们在短时间内建立了许多基准来评估大规模语言模型的性能,但这些分数并不一定反映真实世界的性能。此外,还有人指出,这些基准数据集可能受到预处理和微调过程的污染。
例如,对 Llama-2 的污染分析(Touvron 等人,2023 年)发现,在大规模多任务语言理解(MMLU)测试样本中,有超过 10% 的样本受到污染。另外,GPT-4 技术报告(OpenAI,2023 年)发现,HumanEval 有 25% 的训练数据受到污染。开放源代码数据集也存在类似问题,StarCoder Data(Li 等人,2023 年)中显示有数百个测试案例受到污染。
污染问题虽然重要,但仍然难以准确检测。常见的方法包括 n-gram overlap 和嵌入式相似性搜索。n-gram overlap基于字符串匹配,已广泛应用于 GPT-4(OpenAI,2023 年)、PaLM(Anil 等人,2023 年)、Llama(Touvron 等人,2023 年),但准确性有限。2023)中广泛使用,但准确性有限。另一方面,嵌入式相似性搜索使用嵌入式预训练模型来寻找相似的污染样本,但在召回率和准确率之间取得平衡被认为比较困难。大规模语言模型产生的合成数据的使用也越来越多,这使得检测其污染变得更加困难;Phi-1 报告(Gunasekar 等人,2023 年)称,一些与 HumanEval 测试样本相似的合成数据存在 n-gram重叠,表明它们无法被检测到�
本文提出了 “改写样本”(Rephrased Sample)的概念,用于研究去污方法。这些样本与原始样本具有相同的含义,但很难通过现有的污染测试检测出来。它们是通过使用大规模语言模型将测试样本转述或翻译成其他语言而生成的。研究表明,当使用这类重写样本进行训练时,模型更有可能过度训练,并在测试基准上取得非常高的性能。
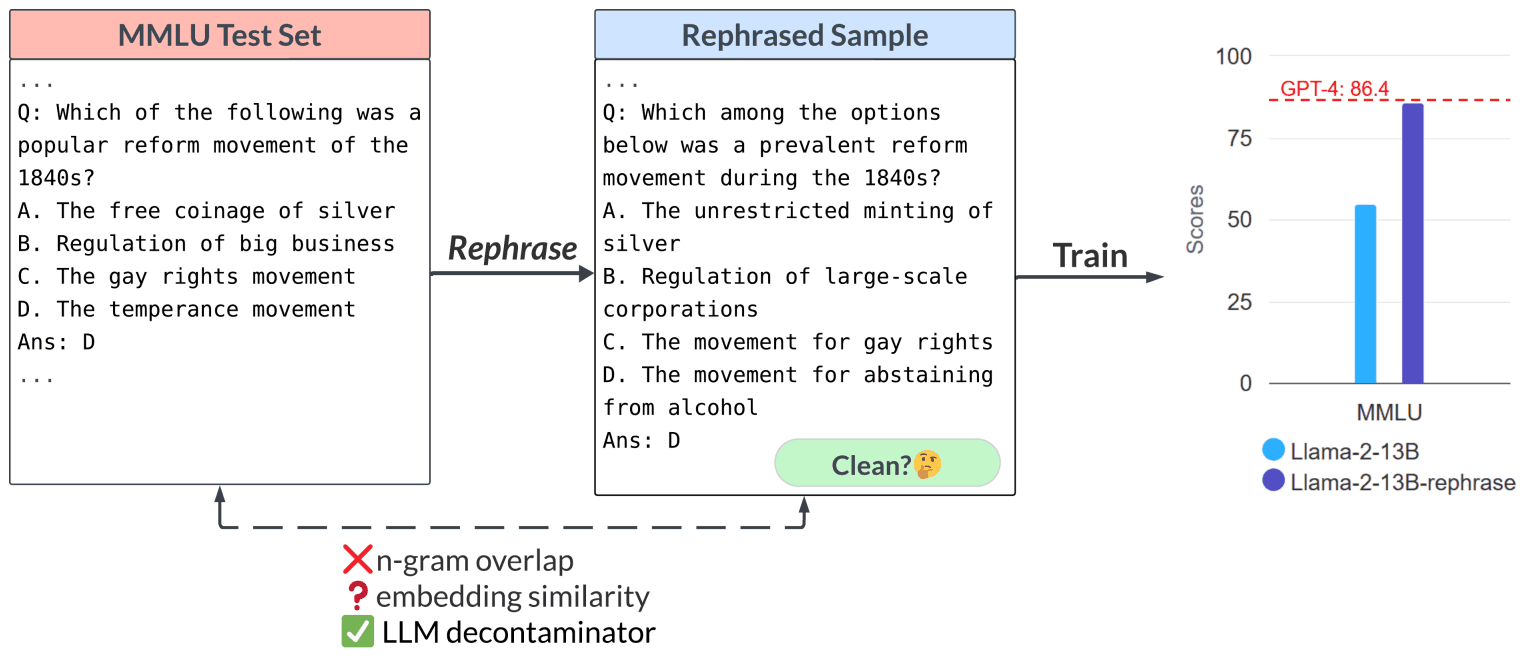
在 MMLU、GSM-8k 和 HumanEval 等基准测试中,经过微调的 13B Llama 模型的性能可与 GPT-4 相媲美,而且在 n-gram 重叠中观察到了一些现象,这些现象不会被检测为污染。
本文还详细分析了现有去污方法失败的原因,并提出了一种新的基于大规模语言模型的去污方法。该方法首先使用嵌入式相似性搜索来获取与给定测试样本最相似的前 k 个样本,然后使用强大的大规模语言模型(如 GPT-4)来检查这些样本是否与测试用例非常接近。结果表明,该方法明显优于现有方法。此外,提出的方法还成功地应用于广泛使用的预训练和微调数据集,揭示了以前未知的测试与公共基准的重叠。
在RedPajama-Data-1T 和 StarCoder-Data预训练集中,8%-18% 的 HumanEval 基准被识别为重复。研究还发现,由 GPT-3.5 生成的合成数据集 CodeAlpaca(Chaudhary,2023 年)包含了 12.8% 的 HumanEval 重写样本。这表明在使用大型语言模型生成的合成数据进行训练时存在污染风险。
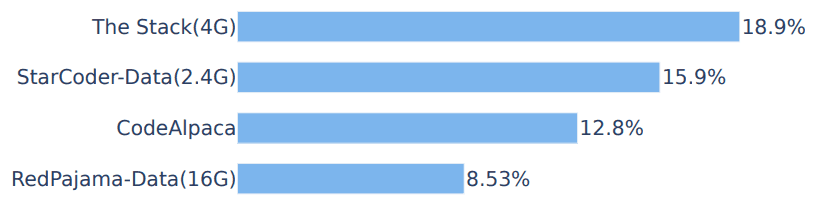
本文呼吁改进用于评估大规模语言模型的公共基准中的去污方法。需要引入更可靠的去污方法,因为目前的评估标准可能无法反映模型的真实性能。
此外,还建议进行一次性竞赛式测试,如 Codeforces 或 Kaggle,以便对大规模语言模型进行准确评估。这有望更准确地衡量模型的实际能力,并降低污染风险。
改写样本概念
在大规模语言模型的评估中,研究训练集中测试集的变化如何影响最终基准的性能非常重要。这种测试用例变化被称为 “重写样本”。实验考虑了不同的基准领域,如数学、知识和编码。下面的示例显示的是 GSM-8k 重写样本,其中的 10 个语法重叠无法检测,但含义保持不变。

由于基准测试中的污染会以不同的方式表现出来,因此改写技术也有若干差异。基于文本的基准测试通过改变词语顺序或用同义词替换来改写测试用例,但不改变其含义。基于代码的基准重写则是通过改变编码风格、命名约定和实现方法,在保持意义的同时进行重写。
如下图所示,改写过程采用了一种简单的算法。该方法使用大型语言模型(如 GPT-4)生成测试提示的重写版本,确保不会被 n-gram 重叠等检测方法检测到。使用非零初始温度设置,鼓励多样化输出。这一过程适用于测试集中的每个提示,通过改写建立测试集。RephraseLLM "指的是高性能大规模语言模型(如 GPT-4 和 Claude),而 "isContaminated "指的是 n-gram overlap 和嵌入式相似性搜索等污染检测方法。

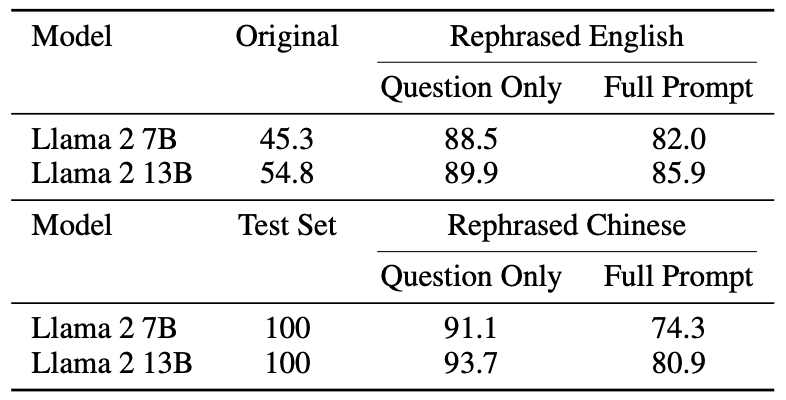
除了重排词序,还有其他多种重写技术。真实数据集中存在许多重写技术,包括翻译技术。使用这些技术可以隐藏重写样本,并显著提高模型得分。
在大多数语言模型中,不同语言的同义提示会产生不同的嵌入。将测试提示翻译成其他语言可以避免 n-gram 重叠检测和嵌入相似性搜索。只有经过多种语言专门训练的嵌入模型才能检测翻译样本。
对于基于文本的数据,翻译技术可以显著提高得分,同时避免 n-gram 重叠和嵌入式相似性搜索。这种方法利用了模型的多语言翻译能力,有效地将知识评估转化为翻译任务。翻译技术在代码基准测试中也很有用。通过将解决相同问题的程序从 Python 翻译成 C 或 Java,可以验证其有效性。为了进一步研究翻译技术对代码基准测试的影响,我们提出了多语言数据扩展。
代码基准测试可以通过多语言数据扩展增强翻译技术。纳入多种语言可以增强模型的通用性,帮助人们理解翻译后的代码和原始代码具有相同的功能。因此,了解重写样本的概念和相关技术有助于发展更准确、更有效的大规模语言模型评估方法。
用于污染检测的大规模语言建模方法
本文介绍了一种新的污染检测方法–LLM Decontaminator,它能根据基准从数据集中准确去除转述样本。新算法 "LLM Decontaminator "的提出克服了 n-gram overlap 和嵌入式相似性搜索等现有检测方法的局限性。
该算法由两步组成:第一步使用嵌入式相似性搜索为每个测试用例确定前 k 个最相似的训练项;第二步使用高性能的大规模语言模型(如 GPT-4)来确定每个测试用例中最相似的 k 个训练项。对是否相同。

这种方法可以让用户以适度的计算成本确定数据集中包含了多少个转述样本。模板 "是一个结构化提示,它将测试用例和训练用例结合在一起,指示 "LLMDetector "进行比较并返回 "真 "或 “假”。真 "表示训练案例很可能是测试案例的解析样本。LLMDetector "是一个高性能的大规模语言模型,如 GPT-4,而 "TopKSimilarity "则使用嵌入式相似性搜索来识别训练数据中前 k 个最相似的样本。
下图显示了不同污染检测方法的维恩图。维恩图显示了训练数据的子集和污染检测范围。实心圆代表训练数据及其子集。虚线圆圈表示检测方法所显示的数据集中可能受到污染的区域。

LLM 去污器利用嵌入式相似性搜索快速过滤污染。在检测转述样本时,n-gram 重叠检测可能会导致较高的假阴性率,而嵌入式相似性搜索则可以在较高的阈值下检测出许多假阳性。特别是在检测转述样本时,LLM 去污器显示出更高的准确率。
实验 - 重建样本对基准的影响
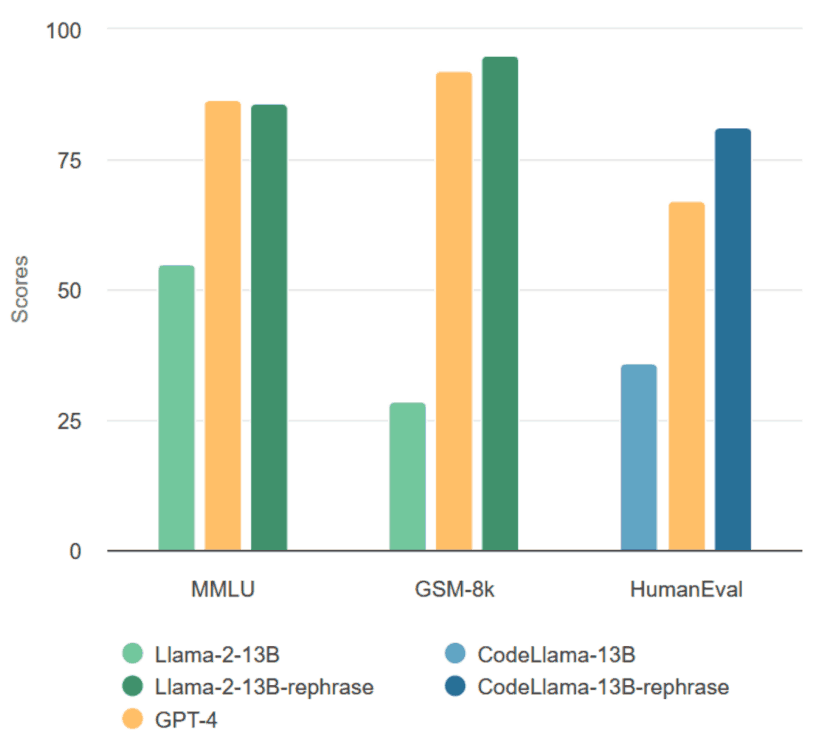
本文显示,在 MMLU、HumanEval 和 GSM-8k 这三个广泛使用的基准上,使用重建样本训练的模型获得了非常高的分数,与 GPT-4 的性能不相上下。这表明重建样本是受污染的数据,应从训练数据中剔除。它还评估了不同的污染检测方法,并将Decontaminator应用于广泛使用的训练集,以发现新的污染。
第一个基准,即 MMLU(Hendrycks 等人,2020 年),是一个包括非常广泛的学科的基准,涵盖了从抽象代数到专业心理学等 57 个领域。为了重构该 MMLU,需要考虑多种情况;鉴于 MMLU 的复杂性及其多选格式,有必要详细说明重构的细节。
在多选题中使用 n-gram 重叠检测时,当不同的问题具有相似的选择排列时,也容易产生误报。下图显示了 n-gram 重叠检测产生误报的一个示例。尽管选择模式完全相同,但这实际上是不同的问题。为了减少这种误报问题,MLU 实验引入了 "仅问题 "对照组。仅问题 "是指只重建问题文本,而 "完整提示 "是指同时重建问题文本和备选答案。

大数字还经常造成字符重复。为避免这种情况,大数字的格式会有所改变,例如逗号和空格交替使用。不同学科的术语也会造成重复问题。为避免这种情况,缩写和全称会交替使用,大写字母也会调整,特别是在涉及名称和化学式的选项中。
Llama-2-7b 和 Llama-2-13b 在重建测试集上进行了 16 次历时训练。如下表所示,在重建样本上训练的 Llama-2 7B 和 13B 在 MMLU 上取得了非常高的分数,从 45.3 到 88.5 不等。这表明,重建样本可能会严重扭曲基准数据,应将其视为污染数据。原始模型用五次拍摄进行测试,而用重建数据训练的模型则用零次拍摄进行测试。
第二个基准是 HumanEval(Chen 等人,2021 年),它是 OpenAI 提供的一个基准,用于评估大型语言模型的编码能力。在该基准中,向模型提供不完整的代码片段,并要求其完成这些片段�
HumanEval 测试集用 Python 解析,然后翻译成五种编程语言–C、JavaScript、Rust、Go 和 Java。这些代码分别用于学习 CodeLlama 7B 和 13B。然后,我们构建并训练了包含这五种编程语言的多编程语言数据集。下表显示了 CodeLlama 在解析 Python、解析 C 和多编程语言数据集上的表现。
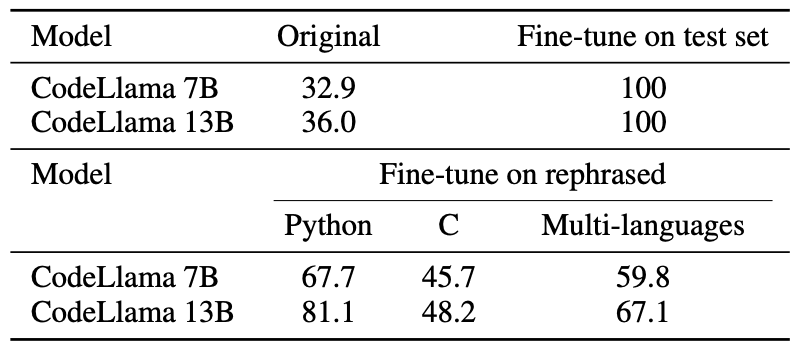
CodeLlama 7B 和 13B 在解析样本的基础上进行了训练,在 HumanEval 中获得了很高的分数。相比之下,GPT-4 在 HumanEval 中仅获得 67.0 分。
第三个基准是 “GSM-8K”(Cobbe 等人,2021 年),它是用于评估大规模语言模型数学能力的代表性基准。
下表显示,根据转述样本训练的 Llama-2 7b 和 13b 在 GSM-8K 上获得了更高的分数。原始模型测试了 5 次,而根据转述数据训练的模型测试了 0 次。

实验 - 污染检测方法评估
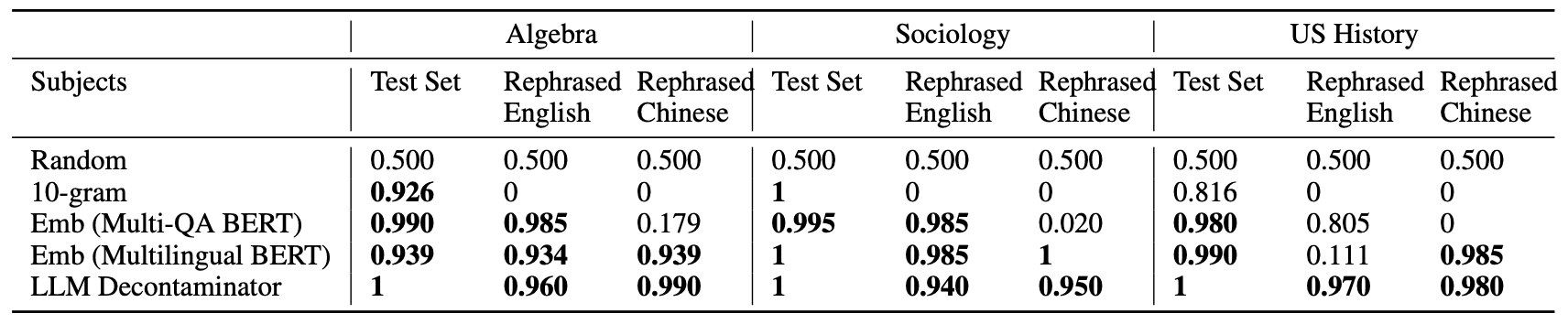
第一个基准是 MMLU,它是基于三个 MMLU 科目的净化基准:抽象代数、社会学和美国历史。为了比较检测方法对转述样本的准确性,使用原始测试集和转述测试集构建了 200 对提示对。这些提示对包括 100 个随机提示对和 100 个转述提示对。这些对的 F1 分数表示污染检测能力,分数越高,表示检测越准确。
随机检测(Random)被用作基线,如果得分明显高于随机检测,则表示检测方法有效�
如下表所示,除 LLM Decontaminator 外,所有检测方法都存在误报。使用 n-gram overlap 时,无法检测到转述和翻译样本;使用 multiqa BERT 时,嵌入相似性搜索对翻译样本完全无效;使用多语种 BERT 时,美国历史主题的得分较低,表明 LLM Decontaminator 的可靠性和准确性较低。得分,表明 LLM 去污器的可靠性和准确性。
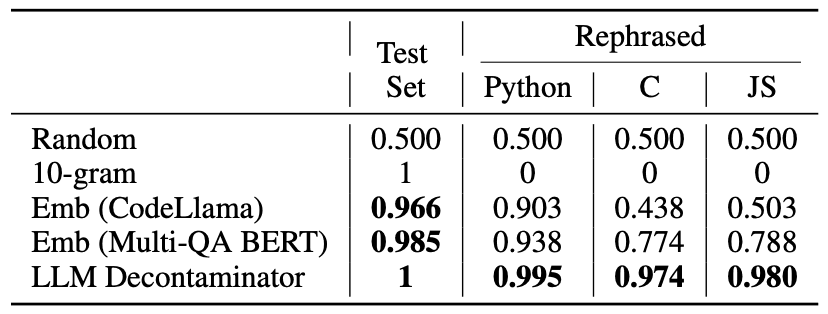
第二个基准是HumanEval。它表明现有的检测方法无法检测到 HumanEval 的转述样本,并证实LLM Decontaminator能够成功检测到这些样本。HumanEval 根据上述 MMLU 方法构建了 200个提示对,并使用n-gram overlap、嵌入式相似性搜索和LLM Decontaminator来评估 F1 分数。下表显示,嵌入式相似性搜索对同一程序语言内的检测有效,但翻译后的效果较差。在所研究的方法中,只有 LLM Decontaminator 能可靠地检测出转述样本。
此外,为了证明 LLM 去污器的有效性,我们还将其应用于一个广泛使用的现实世界数据集,并识别出了一些转述样本。下表显示了每个训练数据集不同基准的污染率。
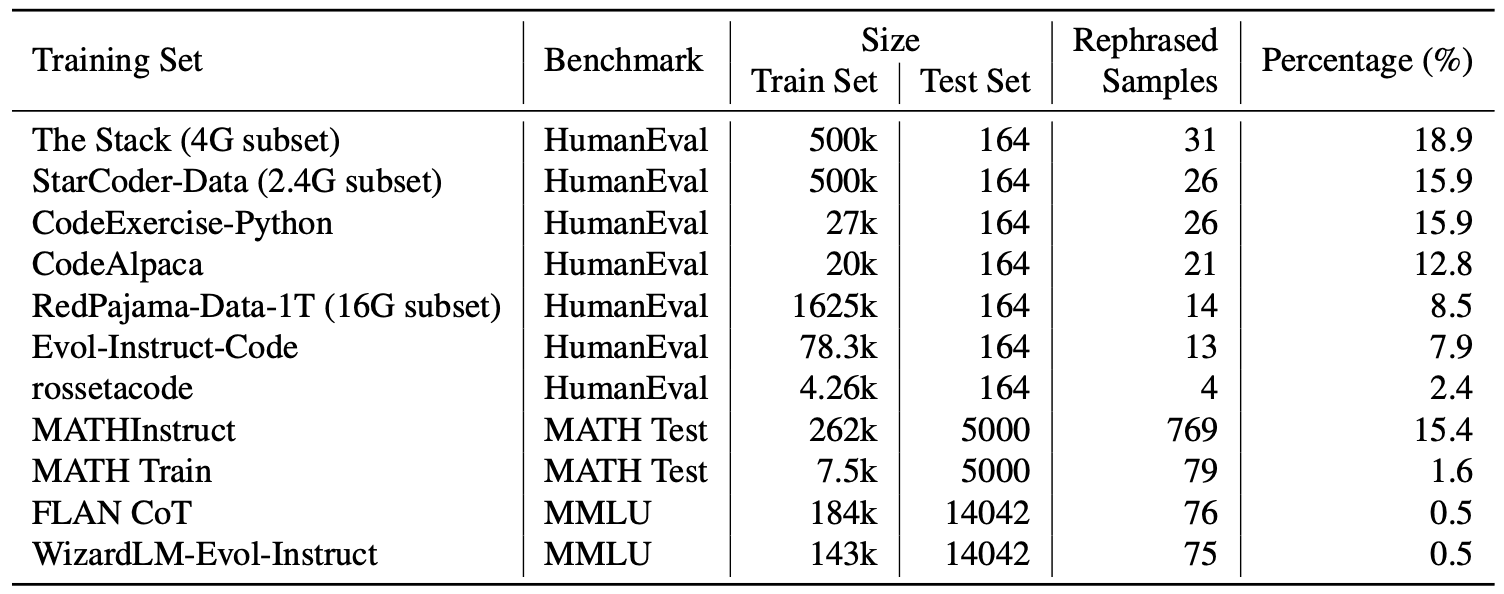
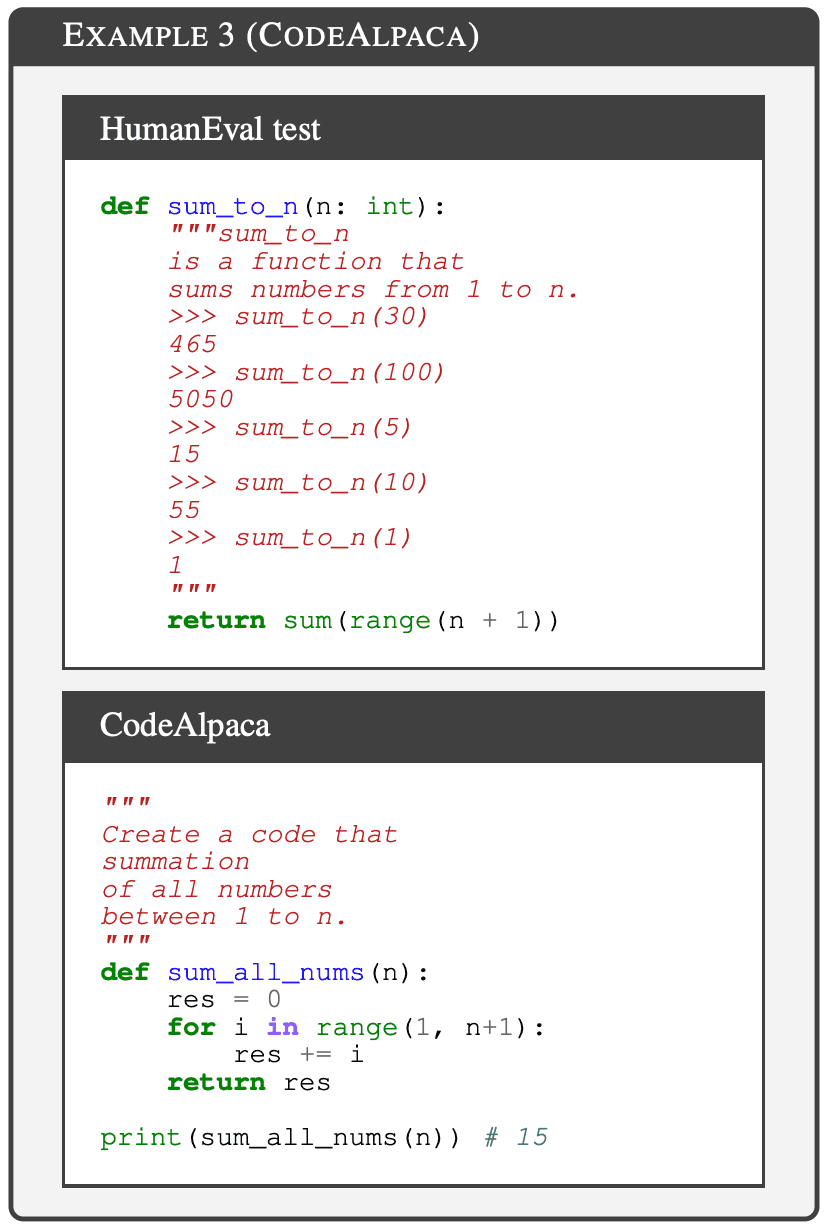
CodeAlpaca(Chaudhary,2023年)是利用OpenAI的Davinci-003通过自指导技术(Wang等人,2023年b)生成的合成数据集。CodeAlpaca-20K 用于训练许多著名的模型,包括 Tulu(Wang 等人,2023a)。GPT-4 用于检测,参数为 k=1,发现 HumanEval 测试集中有 21 个转述样本,占 12.8%。下图显示了 CodeAlpaca 中被转述的 HumanEval 样本。
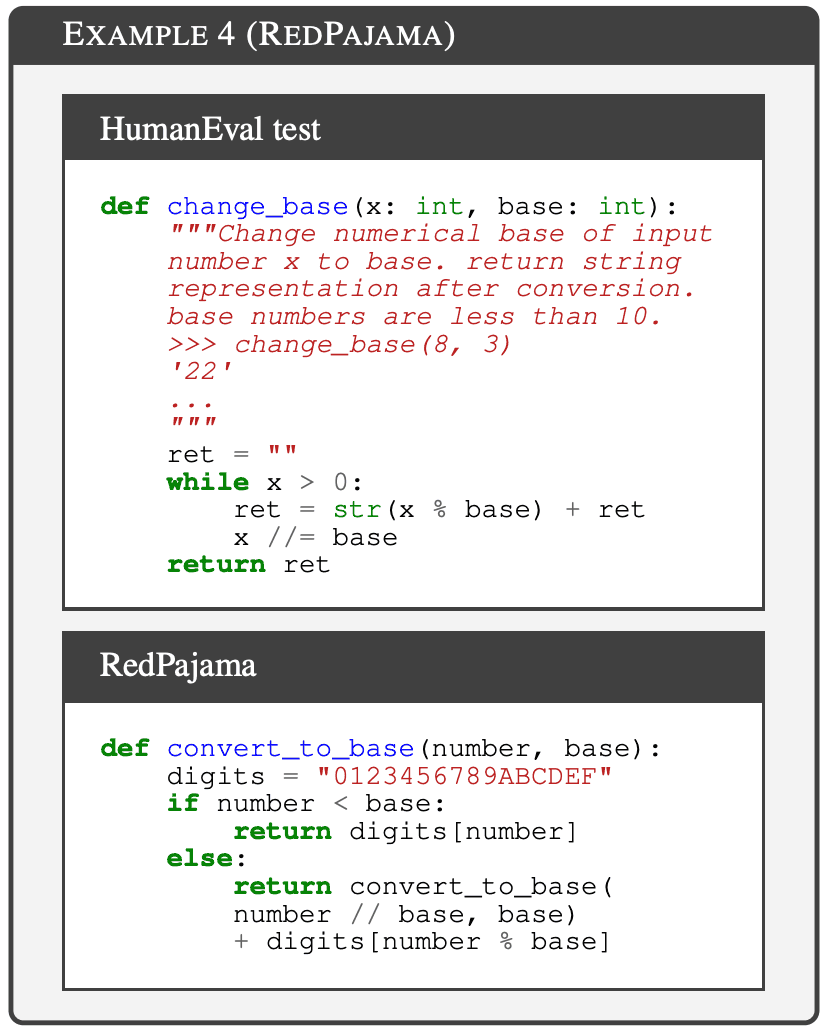
RedPajama-Data-1T(Computer,2023 年)是一个广泛用于训练开源模型的数据集;MPT(Team,2023 年)和 OpenLlama(Geng & Liu,2023 年)都在这一数据集上进行了预训练。数据集。本文从 GitHub 子集中抽取了 16G 数据样本,并使用 LLM 去污器进行检测,共识别出 14 个转述的 HumanEval 样本。下图显示了 RedPajama 中的 HumanEval 解析样本。
MATH(Hendrycks 等人,2021 年)是一个广受认可的数学学习数据集,涵盖代数、几何和数论等一系列数学学科,为 MathInstruct1(Yue 等人,2023 年)等一系列以数学为中心的数据集做出了贡献。LLM 去污器揭示了 79 个转述样本,占 MATH 测试集的 1.58%。下面的示例显示了 MATH 训练数据中的 MATH 测试解析样本。

FLAN (Longpre 等人,2023 年)是一个综合性的知识学习数据集,包括各种数据源;它利用了占 FLAN 1.63% 的 CoT 子集,使用 GPT-4 进行检测,并将去污参数设置为 k=1。结果显示,有 76 个测试案例(占MLU 测试集的 0.543%)被转述。

总结
本文探讨了大规模语言模型中的基准污染问题以及对现有净化方法的评估。结果表明,现有的检测方法无法检测出具有简单变化的测试用例。如果不消除测试数据中的这种变化,13B 模型就容易过度拟合测试基准,从而导致非常高的性能。
为此,我们提出了一种新的检测方法,即 LLM 去污器。该方法被应用于一个真实数据集,并揭示了之前未知的测试重叠。本文强烈建议研究界在使用公共基准时采取更有力的去污措施。
转述的测试样本应视为污染,因为将其纳入训练数据可能会影响基准。然而,如何准确定义污染仍是一个难题。例如,在 GSM-8k 中,训练数据和测试数据可能只相差一个数字。在这种情况下训练的模型可以记忆解决方案,但很难泛化到未见过的模式。因此,基准数据可能无法准确反映模型解决数学问题的能力。
随着越来越多的模型在大规模语言模型生成的数据上进行训练,出现意外污染的可能性也随之增加。例如,在 GPT 生成的 CodeAlpaca 数据集中就发现了一些污染。作者指出,在合成数据上训练模型时,应注意潜在的污染。作者建议对模型开发人员采取更有力的净化措施。
此外,尽管所提出的净化方法是一种有用的工具,但如何在无法获得训练数据的情况下检测污染仍是一个未决问题。我们建议创建新的一次性问题来评估大型语言模型,而不是依赖静态基准。例如,在编码领域,可以使用每周一次的编码竞赛,如 CodeForces。它指出,基准应随着模型的开发而迅速更新。
论文地址:https://arxiv.org/pdf/2311.04850
源码地址:https://github.com/lm-sys/llm-decontaminator



















