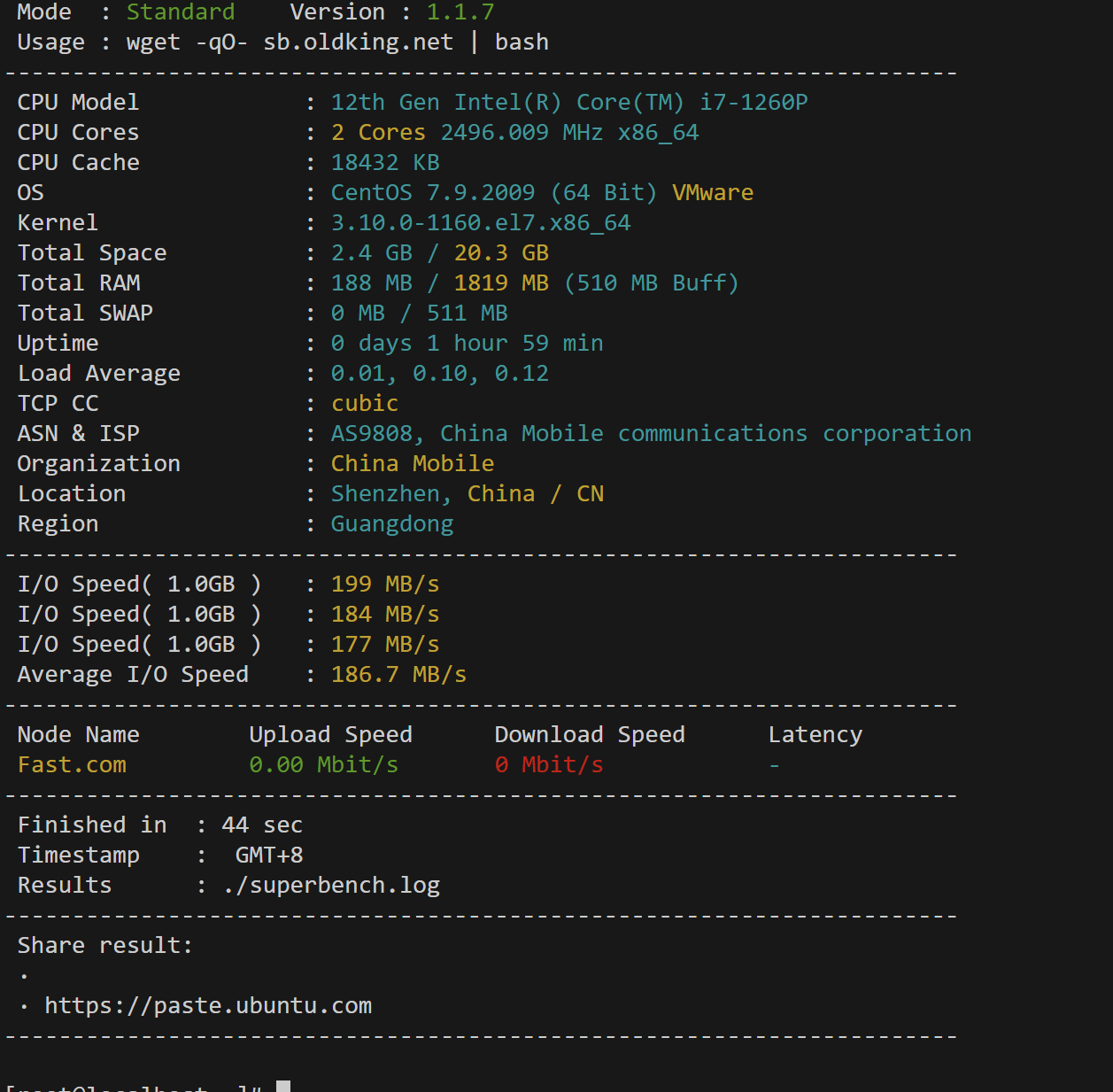
在 Python 的 scikit-learn 库中,Imputer 类是一个用于处理缺失数据的工具。它可以用来填充数据集中的缺失值(通常表示为 NaN 或 None)。Imputer 类提供了几种不同的填充策略,包括:
- 均值填充(mean):用相应列的均值填充缺失值。
- 中位数填充(median):用相应列的中位数填充缺失值。
- 众数填充(most_frequent):用相应列的众数填充缺失值。
- 常数填充(constant):用一个指定的常数值填充所有缺失值。
以下是如何使用 Imputer 类的一个基本示例:
在 Python 的 scikit-learn 库中,Imputer 类是一个用于处理缺失数据的工具。它可以用来填充数据集中的缺失值(通常表示为 NaN 或 None)。Imputer 类提供了几种不同的填充策略,包括:
- 均值填充(mean):用相应列的均值填充缺失值。
- 中位数填充(median):用相应列的中位数填充缺失值。
- 众数填充(most_frequent):用相应列的众数填充缺失值。
- 常数填充(constant):用一个指定的常数值填充所有缺失值。
以下是如何使用 Imputer 类的一个基本示例:
from sklearn.preprocessing import Imputer
import numpy as np
import pandas as pd
# 创建一个包含缺失值的 DataFrame
data = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, np.nan, np.nan, 1, 2],
'C': [np.nan, 1, 2, 3, 4]
})
# 创建 Imputer 实例,这里使用均值填充
imputer = Imputer(missing_values=np.nan, strategy='mean', axis=0)
# 拟合数据并转换,这里的 data 需要是二维数组
imputed_data = imputer.fit_transform(data)
# 将填充后的数据转换回 DataFrame
imputed_data_df = pd.DataFrame(imputed_data, columns=data.columns)
print(imputed_data_df)
在这个例子中,Imputer 会计算每一列的均值,并用这些均值来填充相应列中的缺失值。missing_values 参数指定了要识别为缺失值的数据,strategy 参数指定了填充策略,axis 参数指定了沿着哪个轴计算均值(0 表示沿着列,1 表示沿着行)。
请注意,Imputer 类在 scikit-learn 的新版本中已经被弃用,推荐使用 SimpleImputer 类替代。以下是使用 SimpleImputer 的相同操作:
from sklearn.impute import SimpleImputer
# 创建 SimpleImputer 实例,这里使用均值填充
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# 拟合数据并转换
imputed_data = imputer.fit_transform(data)
# 将填充后的数据转换回 DataFrame
imputed_data_df = pd.DataFrame(imputed_data, columns=data.columns)
print(imputed_data_df)
SimpleImputer 类提供了与 Imputer 类相同的功能,但是它的 API 更加现代化,并且是 scikit-learn 未来发展的方向。



![[N1CTF 2018]eating_cms](https://i-blog.csdnimg.cn/direct/b864dba57c8d4848a5496186a68a33c3.png)





![Spring Cloud Alibaba [Gateway]网关。](https://i-blog.csdnimg.cn/direct/e1a09b2eb00b472f95f07936d1dd8eca.png)