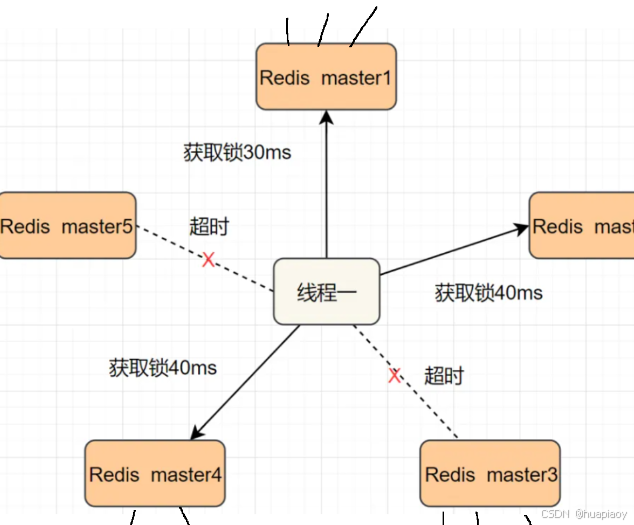
结果

介绍
在本实验中,您将构建一个MapReduce系统。您将实现一个调用应用程序Map和Reduce函数并处理文件读写的工作进程,以及一个将任务分发给工作进程并处理失败的工作进程的协调进程。您将构建类似于MapReduce论文的东西。(注意:本实验使用“coordinator”代替论文中的“master”。)
mrsequential.go的逻辑就是从写好的代码(例如mrapps/wc.go)编译成的动态库(wc.so)中提取出map和reduce两个函数,再利用map来处理数据得到中间结果,reduce拿中间结果进一步处理得到最终结果。
现在要在分布式的环境下执行这个过程,也就是通过协调进程去把任务分发到worker上,这个任务可能是map可能是reduce,
Your Job (moderate/hard)
实现一个分布式MapReduce,它由两个程序组成,协调器和工作器。只有一个协调进程和一个或多个并行执行的工作进程。在一个真实的系统中,工人会在一堆不同的机器上运行,但在这个实验中,你将在一台机器上运行它们。工作人员将通过RPC与协调器对话。每个工作进程将在一个循环中向协调器请求一个任务,从一个或多个文件中读取任务的输入,执行任务,将任务的输出写入一个或多个文件,然后再次向协调器请求一个新任务。协调器应该注意到,如果一个工人没有在合理的时间内完成任务(在本实验中,使用10秒),并将相同的任务交给另一个工人。协调器和工作器的“主”例程位于main/mrcoordinato.go 和 main/mrworker.go不要更改这些文件。您应该将您的实现放在 mr/coordinator.go, mr/worker.go, and mr/rpc.go
实验要求:
- nReduce对应的Reduce数及输出的文件数,也要作为MakeCoordinator()方法的参数;
- Reduce任务的输出文件的命名为mr-out-X,这个X就是来自nReduce;
- mr-out-X的输出有个格式要求,参照main/mrsequential.go,"%v %v" 格式;
- Map输出的中间值要放到当前目录的文件中,Reduce任务从这些文件来读取;
- 当Coordinator.go的Done()方法返回true,MapReduce的任务就完成了;
- 当一个任务完成,对应的worker就应该终止,这个终止的标志可以来自于call()方法,若它去给Master发送请求,得到终止的回应,那么对应的worker进程就可以结束了。
实验提示:
- 修改mr/worker.go的Worker(),发送RPC请求给coordinator要任务。然后修改Coordinator将还没有被Map执行的文件作为响应返回给worker。然后worker读取文件并执行Map方法函数,就如示例文件 mrsequential.go;
- Map和Reduce函数加载来自插件wc.go,如果改了这些东西需要使用命令重新编译生成新的.so文件,尽量不要动这些东西;
- 中间文件的命名方式推荐为mr-X-Y,X对应Map任务Id,Y对应的Reduce任务Id;
- 为顺利存储中间数据,采用json,以便读取;
- worker 的 map 部分可以使用ihash(key)函数(在worker.go 中)为给定的键选择 reduce 任务;
- Coordinator作为一个 RPC 服务器,将是并发的;不要忘记锁定共享数据;
- 在所有Map任务完成后,Reduce任务才会开始,所以对应的worker可能会需要等待,那么可以使用time.sleep()或其他方法;
- worker可能挂掉或其他原因崩了,Coordinator在这个实验中等待10s,超过时间将会分配给其他的worker;
- 您可以使用 ioutil.TempFile 创建一个临时文件,并使用 os.Rename 对其进行原子重命名;
- test-mr.sh 运行子目录 mr-tmp 中的所有进程,因此如果出现问题并且您想查看中间文件或输出文件,请查看那里。您可以修改 test-mr.sh 以在测试失败后退出,这样脚本就不会继续测试(并覆盖输出文件)。
RPC通信
项目中需要使用rpc的地方是worker向coordinator索要任务或发送任务完成情况,先探究rpc是如何通信的,在mr/coordinato.go中,注册rpc的函数为
func (c *Coordinator) server() {
rpc.Register(c)
rpc.HandleHTTP()
//l, e := net.Listen("tcp", ":1234")
sockname := coordinatorSock()
os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatal("listen error:", e)
}
go http.Serve(l, nil)
}
这里使用的是unix套接字,它用于本地进程之间的通信,通常比网络套接字更高效,因为数据不需要通过网络协议栈,在同一台机器上的进程之间通信,Worker 进程可以通过套接字文件连接到 Coordinator 进行 RPC 调用,使用 HTTP 协议来组织和传递数据。
整体流程概括为:Worker 的 RPC 请求通过 HTTP 协议发送->请求通过 Unix 套接字传输到 Coordinator->Coordinator 的 HTTP 服务处理请求,并返回响应。
在worker中调用rpc的方法如下,传入rpc方法名,参数和返回值。
func call(rpcname string, args interface{}, reply interface{}) bool {
// c, err := rpc.DialHTTP("tcp", "127.0.0.1"+":1234")
sockname := coordinatorSock()
c, err := rpc.DialHTTP("unix", sockname)
if err != nil {
log.Fatal("dialing:", err)
}
defer c.Close()
err = c.Call(rpcname, args, reply)
if err == nil {
return true
}
fmt.Println(err)
return false
}worker部分
work的工作就是处理map任务和reduce任务,并在处理完成后反馈结果,那么在mr/worker.go中有,其中executeMapTask和executeReduceTask分别用来处理map和reduce任务,处理完成后会调用notifyTaskComplete反馈任务结果,函数的实现可以参考mrsequential.go。
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
for {
task := requestTask()
switch task.TaskType {
case MapTask:
executeMapTask(task, mapf)
case ReduceTask:
executeReduceTask(task, reducef)
case NoTask:
log.Println("No task available, sleeping...")
time.Sleep(1 * time.Second)
}
}
}
func executeMapTask(task *TaskRep, mapf func(string, string) []KeyValue) {
filename := task.FileName
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", filename)
}
file.Close()
kva := mapf(filename, string(content))
intermediate := make(map[int][]KeyValue)
for _, kv := range kva {
reduceTaskNum := ihash(kv.Key) % task.ReduceCount
intermediate[reduceTaskNum] = append(intermediate[reduceTaskNum], kv)
}
for reduceTaskNum, kvs := range intermediate {
tempFile, _ := ioutil.TempFile("", "mr-temp-*")
enc := json.NewEncoder(tempFile)
for _, kv := range kvs {
enc.Encode(&kv)
}
tempFile.Close()
finalName := fmt.Sprintf("mr-%d-%d", task.TaskID, reduceTaskNum)
os.Rename(tempFile.Name(), finalName)
}
notifyTaskComplete(task.TaskID, MapTask)
}
func executeReduceTask(task *TaskRep, reducef func(string, []string) string) {
intermediate := make(map[string][]string)
// 遍历所有 MapTask 的任务 ID
for mapTaskID := 0; mapTaskID < task.MapTaskCount; mapTaskID++ {
filename := fmt.Sprintf("mr-%d-%d", mapTaskID, task.TaskID)
file, err := os.Open(filename)
if err != nil {
// 文件不存在可能是因为 MapTask 失败,忽略
continue
}
// 解码中间文件内容
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
intermediate[kv.Key] = append(intermediate[kv.Key], kv.Value)
}
file.Close()
}
// 生成最终输出文件
outputFile, _ := os.Create(fmt.Sprintf("mr-out-%d", task.TaskID))
for key, values := range intermediate {
result := reducef(key, values)
fmt.Fprintf(outputFile, "%v %v\n", key, result)
}
outputFile.Close()
notifyTaskComplete(task.TaskID, ReduceTask)
}
func notifyTaskComplete(taskID int, taskType int) {
req := TaskCompleteReq{TaskID: taskID, TaskType: taskType}
reply := TaskCompleteRep{}
call("Coordinator.TaskComplete", &req, &reply)
}coordinator部分
对于coordinator.go,首先需要定义任务的种类,这里想到worker要知道是map还是reduce任务,要处理的文件名称,并且写入文件时需要有map和reduce的id,处理时间需要在10s内,那么定义如下Task结构体,任务的类型和状态都用枚举数,任务在coordinactor实例初始化的时候就塞到实例的...task字段内,这里要注意输入的file有多少个,就有多少个map任务,而reduce任务的数量和nReduce有关。任务超时的检查我是用轮询机制,每隔一秒轮询所有任务如果任务状态为正在运行并且时间超时那么把它状态初始化。
结构体中的字段并不是一下就能全部想出来,也是需要在写处理函数的过程中看需要哪些字段才决定。
type Task struct {
TaskType int
FileName string
TaskID int
ReduceCount int
Status int
StartTime time.Time
}
const (
MapTask = iota
ReduceTask
NoTask
)
const (
Pending = iota //任务已准备好进行处理,并将由一个空闲的工作器接收
Active //任务正在被工作器处理
Retry //工作器无法处理任务,任务正在等待将来重试
Completed //任务已成功处理
)
type Coordinator struct {
mu sync.Mutex
mapTasks []Task // 所有 Map 任务
reduceTasks []Task // 所有 Reduce 任务
nReduce int // Reduce 任务数量
}
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{
nReduce: nReduce,
mapTasks: make([]Task, len(files)),
reduceTasks: make([]Task, nReduce),
}
for i, file := range files {
c.mapTasks[i] = Task{TaskType: MapTask, FileName: file, TaskID: i, Status: Pending}
}
for i := 0; i < nReduce; i++ {
c.reduceTasks[i] = Task{TaskType: ReduceTask, TaskID: i, Status: Pending}
}
// Your code here.
c.server()
go c.monitorTimeouts()
return &c
}
func (c *Coordinator) monitorTimeouts() {
for {
time.Sleep(time.Second)
c.mu.Lock()
for i := range c.mapTasks {
if c.mapTasks[i].Status == Active && time.Since(c.mapTasks[i].StartTime) > TaskTimeout {
c.mapTasks[i].Status = Pending
}
}
for i := range c.reduceTasks {
if c.reduceTasks[i].Status == Active && time.Since(c.reduceTasks[i].StartTime) > TaskTimeout {
c.reduceTasks[i].Status = Pending
}
}
c.mu.Unlock()
}
}
Done方法很简单,所有map任务和reduce任务都是已完成的状态就代表Done
func (c *Coordinator) Done() bool {
ret := c.allMapTasksDone() && c.allReduceTasksDone()
return ret
}
func (c *Coordinator) allMapTasksDone() bool {
for _, task := range c.mapTasks {
if task.Status != Completed {
return false
}
}
return true
}
func (c *Coordinator) allReduceTasksDone() bool {
for _, task := range c.reduceTasks {
if task.Status != Completed {
return false
}
}
return true
}接下来是分发任务的逻辑和任务完成后的回调函数,分发任务注意map任务全部完成了才可以开始reduce任务
//分发任务
func (c *Coordinator) AssignTask(req *TaskReq, reply *TaskRep) error {
c.mu.Lock()
defer c.mu.Unlock()
// 分配 Map 任务
for i, task := range c.mapTasks {
if task.Status == Pending {
reply.TaskType = MapTask
reply.FileName = task.FileName
reply.TaskID = task.TaskID
reply.ReduceCount = c.nReduce
c.mapTasks[i].Status = Active
c.mapTasks[i].StartTime = time.Now()
return nil
}
}
// 检查是否可以分配 Reduce 任务
if c.allMapTasksDone() {
for i, task := range c.reduceTasks {
if task.Status == Pending {
reply.TaskType = ReduceTask
reply.TaskID = task.TaskID
reply.ReduceCount = c.nReduce
reply.MapTaskCount = len(c.mapTasks)
c.reduceTasks[i].Status = Active
c.reduceTasks[i].StartTime = time.Now()
return nil
}
}
}
// 没有任务可分配
reply.TaskType = NoTask
return nil
}
//worker完成任务后会回调这个函数
func (c *Coordinator) TaskComplete(req *TaskCompleteReq, reply *TaskCompleteRep) error {
c.mu.Lock()
defer c.mu.Unlock()
if req.TaskType == MapTask {
c.mapTasks[req.TaskID].Status = Completed
} else if req.TaskType == ReduceTask {
c.reduceTasks[req.TaskID].Status = Completed
}
reply.Success = true
return nil
}rpc部分
在rpc.go中,定义worker要调用的rpc方法(要任务,报告任务完成情况)的参数和返回值就行
type TaskReq struct {
}
type TaskRep struct {
TaskType int // 任务类型:Map、Reduce
FileName string // Map 任务的输入文件名
TaskID int // 任务编号
MapTaskCount int //map任务数量
ReduceCount int // 传入的reducer的数量,用于hash
Status int
StartTime time.Time
}
type TaskCompleteReq struct {
TaskID int
TaskType int
}
type TaskCompleteRep struct {
Success bool
}








![[JAVA]MyBatis框架—获取SqlSession对象](https://i-blog.csdnimg.cn/direct/1b1ddf3a840f40fe8c1bf2d523a014a6.png)