GPU分布式通信技术-PCle、NVLink、NVSwitch
大模型时代已到来,成为AI核心驱动力。然而,训练大模型却面临巨大挑战:庞大的GPU资源需求和漫长的学习过程。
要实现跨多个 GPU 的模型训练,需要使用分布式通信和 NVLink。此外,由于单个 GPU 工作线程的内存有限,并且许多大型模型的大小已经超出了单个 GPU 的范围,因此需要实现跨多个 GPU 的模型训练。
PyTorch 提供了一种数据并行方法 DataParallel,用于在单台机器上的多个 GPU 上进行模型训练。它通过将输入数据划分成多个子部分(mini-batches),并将这些子部分分配给不同的 GPU,以实现并行计算。
在探讨分布式通信与NVLink时,我们发现了一个充满魅力且持续发展的技术领域。接下来,我们将简要概述分布式通信的基本原理,并深入了解实现高效分布式通信背后的关键技术——NVLink的演进历程。
分布式通信是指将计算机系统中的多个节点连接起来,使它们能够相互通信和协作,以完成共同的任务。而NVLink则是一种高速、低延迟的通信技术,通常用于连接GPU之间或连接GPU与其他设备之间,以实现高性能计算和数据传输 。
分布式并行
深度学习已迈入大模型时代,即Foundation Models。这类模型以“大”为核心,主要包括以下几个方面:
- "大数据驱动,大模型依赖自监督学习。它削减了标注需求,降低了训练成本,而充足的数据又赋予了模型更强的泛化和性能。"
- 庞大的数据和参数需求,导致模型难以在单台机器上运行和计算。这既推动了计算硬件的持续创新,也对AI框架提出了分布式并行训练的要求。
所以说,为了解决上述问题我们需要引入分布式并行策略。
数据并行
数据并行(Data Parallel,DP)是一种常用的深度学习训练策略,它通过在多个 GPU 上分布数据来实现并行处理。在数据并行的框架下,每个 GPU(或称作工作单元)都会存储模型的完整副本,这样每个 GPU 都能独立地对其分配的数据子集进行前向和反向传播计算。这种方法可以显著提高训练速度,但需要更多的显存和更复杂的分布式通信 。
数据并行的工作流程:
- 梯度聚合是指在分布式训练中,计算完成后,所有工作单元的梯度需要被聚合起来。这通常通过网络通信来实现,比如使用 All-Reduce 算法,它允许在不同的 GPU 间高效地计算梯度的平均值。AllReduce算法是一种特殊的Reduce操作,它将所有节点的数据聚合到一起,并将结果广播回所有节点。
- 更新参数:一旦梯度被平均,每个 GPU 使用这个平均梯度来更新其模型副本的参数。
- 重复过程:这个过程在每个数据批次上重复进行,直到模型在整个数据集上训练完成。
数据并行的优势和挑战:
数据并行是一种强大的技术,它能让你将训练过程扩展到更多的GPU上,从而极大地加速训练。它的优势在于实施简单,同时可以根据硬件资源的变化,灵活地调整工作单元的数量。目前,多个深度学习框架都已内置了对这种技术的全面支持。
随着GPU并行数量的增加,数据并行会带来显著的内存开销,因为需要存储更多的参数副本。同时,梯度聚合步骤在GPU之间同步大量数据时可能成为系统瓶颈,尤其是工作单元数量增多的情况下。
异步同步方案在数据并行中的应用:
为了突破数据并行中的通信瓶颈,研究者们倾力打造了各种异步同步策略。其中,GPU 工作线程独当一面,各自为政地处理数据,无需等待其他线程完成梯度计算和同步。这种方法大幅减少了通信阻塞时间,从而提高了系统的吞吐效率。
"梯度计算过程中的一大创新,是每个GPU独立进行前向和反向传播,然后立即开始更新梯度。此外,当需要时,每个GPU能即时读取最新的全局权重,无需等待所有GPU同步。"
尽管此方法独具优势,但也存在不足。由于GPU上不同模型权重的同步性问题,工作线程可能使用过时权重进行梯度计算,从而降低统计效率,精度无法得到严格保证。
模型并行
模型并行(Model Parallel, MP)是一种将深度学习模型的不同部分分布到多个计算设备(如GPU)上的技术,以提高训练和推理的效率。模型并行特别适合于大型模型,因为这些模型的参数可能超出单个设备的内存容量 。
模型并行可以进一步细分为几种策略,包括但不限于流水并行(Pipeline Parallel, PP)和张量并行(Tensor Parallel, TP) 。
模型并行是一种解决单个计算节点无法容纳模型所有参数的方法。与数据并行不同,模型并行将模型的不同部分分布到多个节点上,每个节点只负责模型的一部分参数。这样可以有效降低单个节点的内存需求和计算负载。
在模型并行中,我们将深度神经网络的多个层划分为组,并分配给特定节点。这种分层策略使每个节点仅处理其所分配的一部分参数,从而降低了内存和计算资源的需求。
为了提高计算效率,我们引入了流水线并行(Pipeline Parallel,简称PP)技术。在这种方法中,大数据批次被划分为多个微批次,每个微批次的处理速度应保持相对平衡。当一个Worker空闲时,它将立即开始处理下一个微批次,从而加速整个流水线的执行速度。通过合理分配微批次数量,我们可以充分利用Worker资源,并在步骤开始和结束时降低空闲时间。
在并行流水中,各节点按序处理不同层模型,微批次在节点间流动,如流水线。所有微批次处理完毕后,梯度平均并更新模型参数。
采用层级“垂直”分割的流水并行模型,我们还可在层内实现“水平”分割,这被称为张量并行训练(Tensor Parallel,TP),从而进一步提升计算效率。
在张量并行中,大型矩阵乘法操作被分割成更小的部分,这些部分可以在多个计算节点上并行执行。例如,在 Transformer 模型中,矩阵乘法是一个主要的计算瓶颈。通过张量并行,我们可以将权重矩阵分割成更小的块,每个块在不同的节点上并行处理。这样可以提高模型的训练速度和效率。
在实际应用中,模型并行策略主要包含流水线并行和张量并行两种技术。这种方法允许单个节点同时处理整个模型的不同部分(即模型并行),并且在此节点内部,大规模矩阵运算能在多个处理器之间进一步分割(即张量并行)。这种优化组合可以最大限度地利用分布式计算资源,从而显著提升大规模模型训练的效率。
AI 框架分布式
在模型训练中,并行策略的本质是将模型切分为“纵向”或“横向”,然后将单独切分出来的放在不同的机器上进行计算,以充分利用计算资源。
在AI框架中,混合并行策略加速模型训练已成为常态。然而,如何实现不同切分部分间的通信,以支持这种并行策略,仍是一个关键挑战。
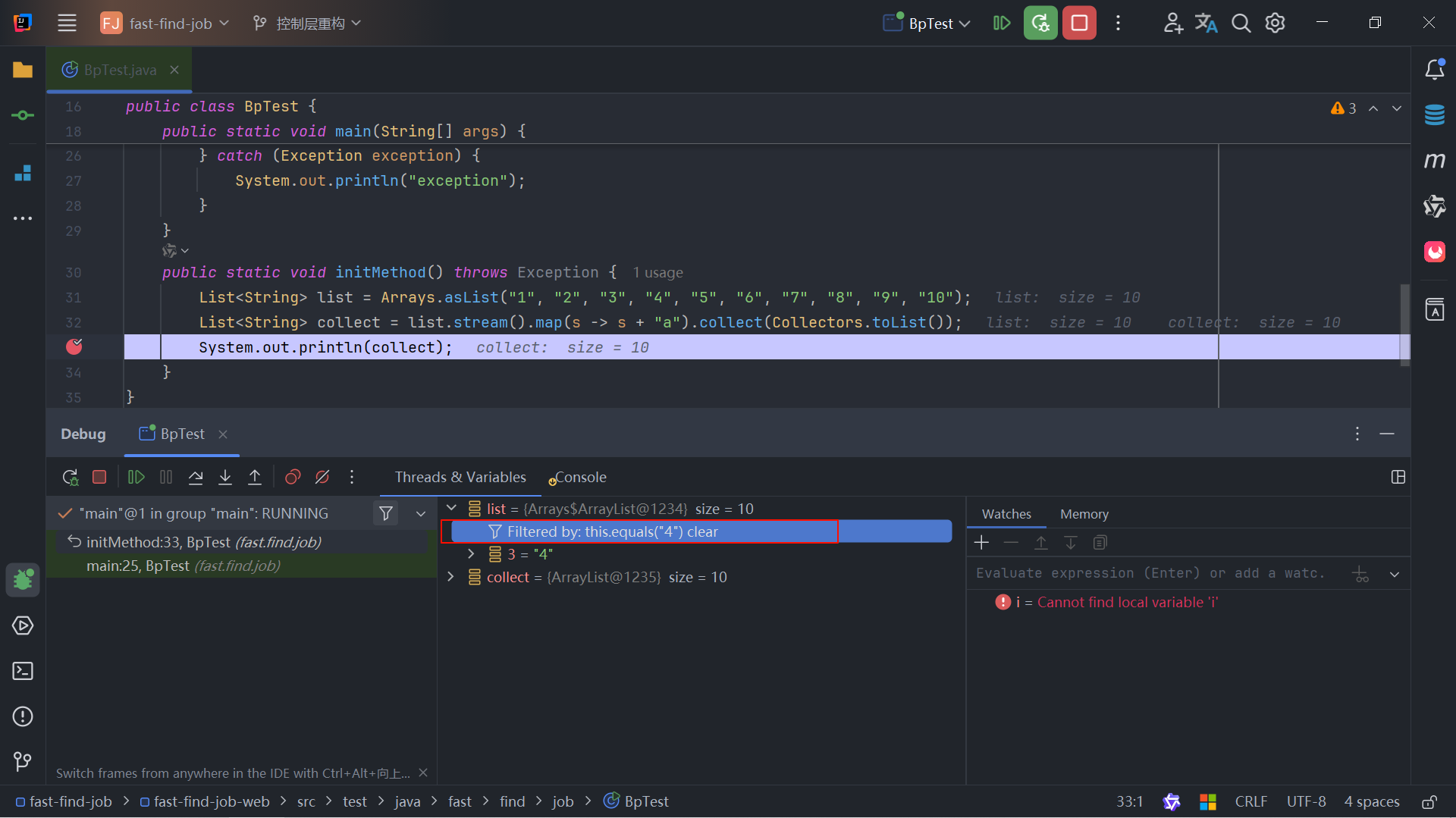
AI 训练图切分
如上图所示,AI计算框架需将网络模型切分并分布至多台机器进行计算。为实现通信,模型中插入Send和Recv节点。
在分布式模型训练中,模型切分导致参数需放置于不同机器上。训练过程中涉及节点间参数交互与同步,即跨节点数据和参数同步,这便是分布式训练。
文章提到了软件层面的分布式策略和算法,接下来我们来看下通讯的硬件上是如何实现的。
通讯硬件上的分布式策略和算法是指在分布式系统中,如何通过硬件来实现数据的传输和处理。这些策略和算法包括数据并行、模型并行、流水并行、算子并行等。
通讯硬件
在AI训练中,分布式通信至关重要,尤其对于处理大型模型和海量数据。它涉及设备或节点间的数据传输与协调,以实现并行计算和模型参数同步。
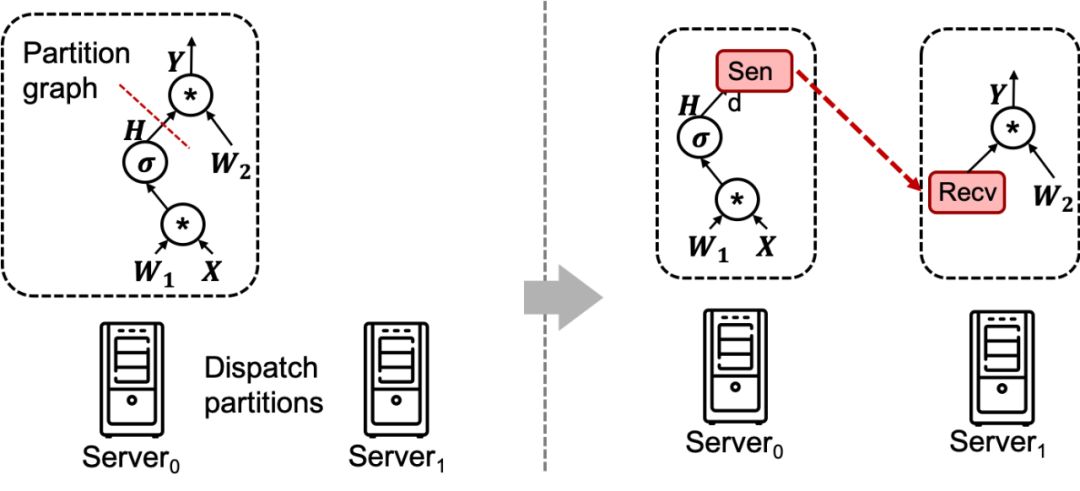
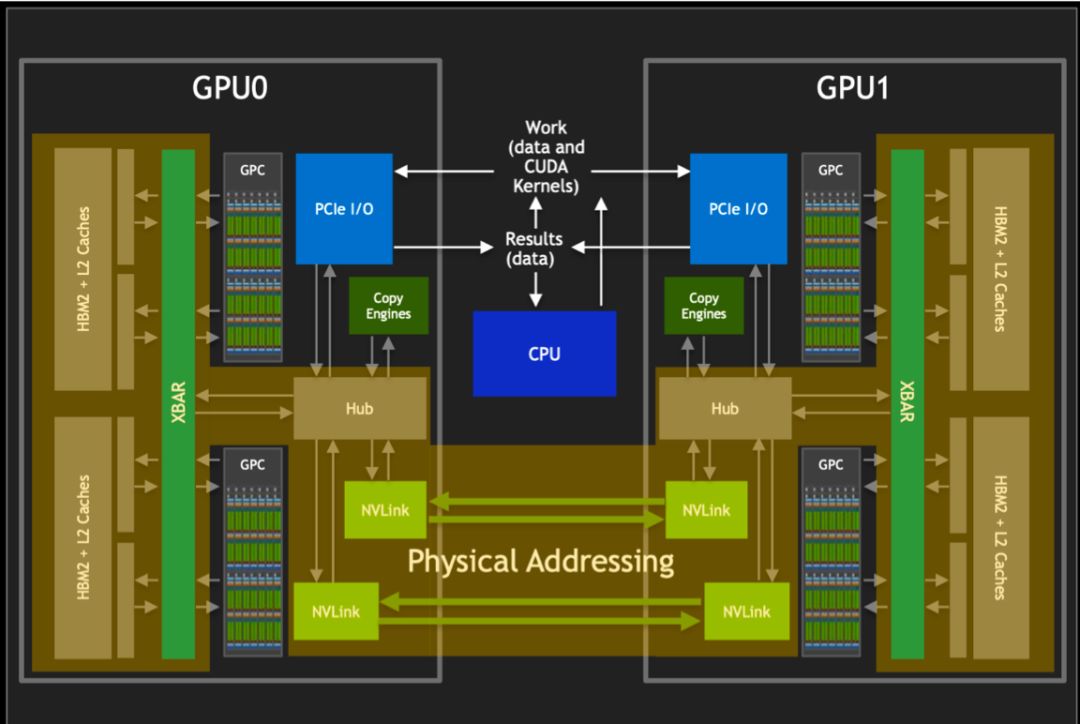
GPU 服务结构
在机器内通信方面,有几种常见的硬件:
- PCIe(Peripheral Component Interconnect Express):作为连接计算设备的标准接口,PCIe总线广泛应用于GPU、加速器卡等外部设备的互联互通。其卓越的传输能力,实现了数据的快速在各计算设备之间流动,从而推动了分布式计算的发展。
- NVLink 是一种由 NVIDIA 开发的高速互连技术,可实现 GPU 之间的直接通信。它可以提供比 PCIe 更高的带宽和更低的延迟,适用于要求更高通信性能的任务。NVLink 可用于连接两个或多个 GPU,以实现高速的数据传输和共享,为多 GPU 系统提供更高的性能和效率。
在机器间通信方面,常见的硬件包括:
- TCP/IP网络是互联网通信的基础,它允许不同机器之间通过网络进行数据传输。在分布式计算中,可以使用TCP/IP网络进行机器间的通信和数据传输。
- RDMA(Remote Direct Memory Access)网络是一种高性能网络通信技术,它允许在不涉及 CPU 的情况下直接从一个内存区域传输数据到另一个内存区域。RDMA 网络通常用于构建高性能计算集群,提供低延迟和高吞吐量的数据传输。
MPI(Message Passing Interface)是一种跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI的目标是高性能、大规模性和可移植性。而在NVIDIA GPU上,最常用的集合通信库则是NCCL(NVIDIA Collective Communications Library)。NCCL是NVIDIA提供的一种性能优化的通信库,可用于深度学习和HPC应用。NCCL支持多种编程语言和网络,提供了简单的C API和自动拓扑检测,可加快多GPU和多节点的训练速度 。
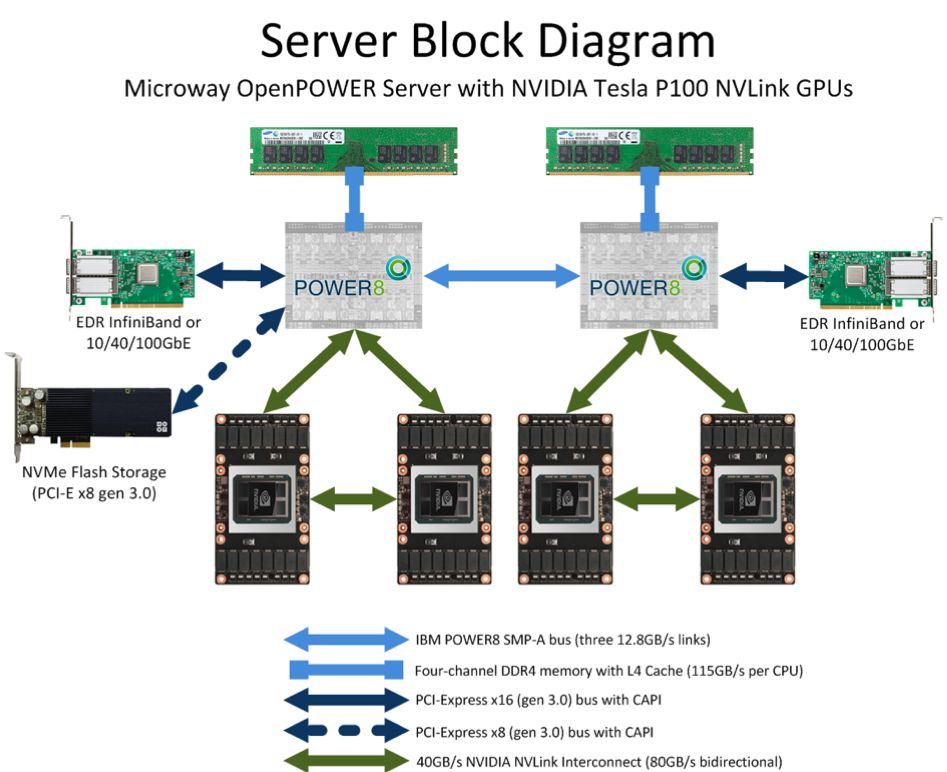
NVLink&NVSwitch
如图所示,借助NCCL库,我们能通过NVLink或NVSwitch实现GPU间的互联。此库在算法层面提供了丰富的外部API,使得跨多个GPU的集合通信变得简便。这些API覆盖了广播、归约、全局归约、全局同步等常见的集合通信操作,极大地提升了开发者进行并行计算的效率和便利性。
集合通信
集合通信(Collective Communications)是一种涉及进程组中所有进程的全局通信操作。它包括一系列基本操作,如发送(send)、接收(receive)、复制(copy)、组内进程栅栏同步(Barrier),以及节点间进程同步(signal + wait)。这些基本操作经过组合可以构成一组通信模板,也称为通信原语。例如,1 对多的广播(broadcast)、多对 1 的收集(gather)、多对多的收集(all-gather)、1 对多的发散(scatter)、多对 1 的规约(reduce)、多对多的规约(all-reduce)、组合的规约与发散(reduce-scatter)、多对多的全互连(all-to-all)等。下面我们简单介绍几个。
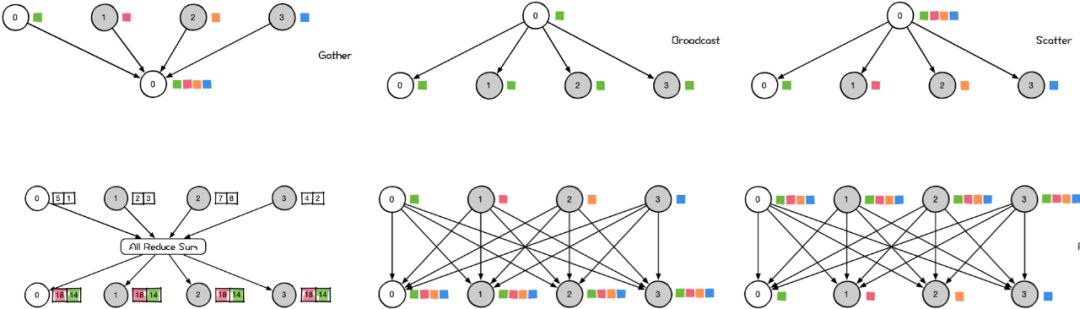
集合通信
Gather操作是一种多对一的通信原语,允许多个发送者将数据发送到一个接收者。在集群内,它能将多个节点的数据汇总到一个节点上。与之相反,Scatter操作对应于Gather,实现了数据的反向收集。
Broadcast是一种多对一的通信原语,适用于集群内的数据传输。当主节点执行Broadcast操作时,数据会从主节点发送至其他所有节点。如图所示,数据从主节点0开始传播至其他各节点。
Scatter是数据的1对多的分发,它将一张GPU卡上的数据进行分片再分发到其他所有的GPU卡上。
以下是一些关于Scatter的信息:
- Scatter是一个1对多的通信原语,也是一个数据发送者,多个数据接收者。
- Scatter可以在集群内把一个节点自身的数据发散到其他节点上。
- Scatter将数据的进行切片再分发给其他所有节点。
AllReduce是一种多对多的通信原语,具有多个数据发送者和多个数据接收者。它在集群内的所有节点上都执行相同的 Reduce 操作,可以将集群内所有节点的数据规约运算得到的结果发送到所有的节点上。简单来说,AllReduce 是数据的多对多的规约运算,它将所有的 GPU 卡上的数据规约(比如 SUM 求和)到集群内每张 GPU 卡上。
AllGather是一种多对多的通信原语,支持多个数据发送者和接收者。它能在集群内将各个节点的数据汇总到一个主节点(Gather),然后再将收集到的数据分发给其他节点。
在分布式计算的领域,"AllToAll"是一种重要的操作模式。这种模式下,每个节点的数据会被分散发送到集群内的所有其他节点。同时,这些节点也会将各自收集到的数据汇总并发送回原节点。相比于"AllGather"模式,"AllToAll"模式的一个显著特点是,它允许同一节点接收来自不同节点的不同数据。这种灵活性使得"AllToAll"模式在处理复杂数据分布问题时具有更大的优势。
NVLlink 与 NVSwitch 发展
NVLink 和 NVSwitch 是英伟达推出的两项革命性技术,它们正在重新定义 CPU 与 GPU 以及 GPU 与 GPU 之间的协同工作和高效通信的方式。
NVLink 是一种专门设计用于连接 NVIDIA GPU 的高速互联技术。 它允许 GPU 之间以点对点方式进行通信,绕过传统的PCIe总线,实现了更高的带宽和更低的延迟。
NVSwitch 是一款GPU桥接设备(芯片),可提供所需的NVLink交叉网络,以初代NVSwitch为例,每块NVSwitch提供18个NVLink端口,支持直连8块GPU,提供GPU之间的高速互联。
NVLink是一种先进的总线及其通信协议,由英伟达(NVIDIA)开发并推出。它采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个图形处理器(GPU)之间的相互连接。NVLink提供高达300GB/s的带宽,是PCIe的10倍,可用于GPU间、GPU与CPU间的通信,甚至CPU互联 。
NVSwitch是一种高速互连技术,同时作为一块独立的 NVLink 芯片,其提供了高达 18 路 NVLink 的接口,可以在多个 GPU 之间实现高速数据传输。
NVLink 发展
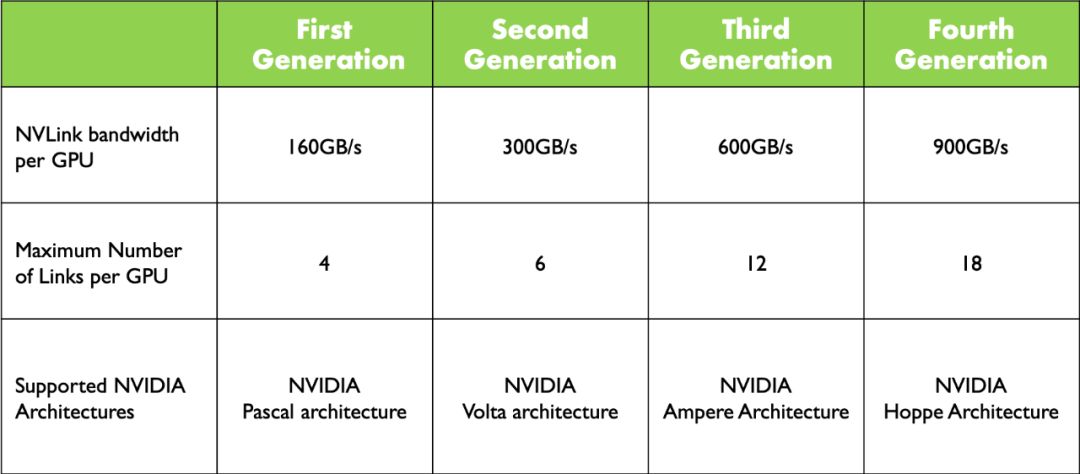
NVLink 发展
如上图所示,自Pascal架构起,NVLink已历经四代蜕变。在2024年GTC大会上,NVIDIA惊艳亮相Blackwell架构,第五代NVLink再次升级,互联带宽高达1800GB/s,为业界带来前所未有的性能突破。
如上图所示,随着 NVLink 的升级,每层互联带宽不断增长。从第一代的 4 路到第四代的 18 路,NVLink 能够互联的 GPU 数显著提升。然而,值得注意的是,最新的 Blackwell 架构的最大互联 GPU 数并未发生变化。
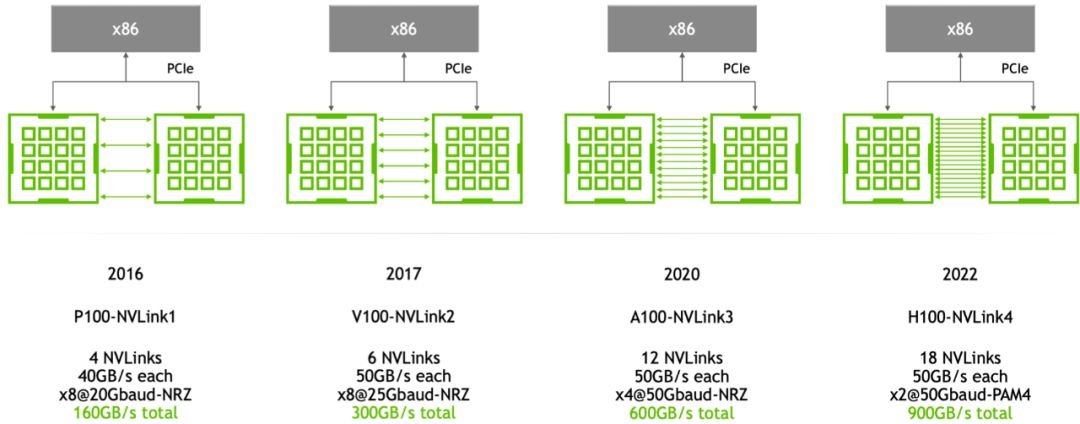
NVLink 发展
如上图所示,P100中的每个NVLink带宽仅为40GB/s,而从第二代V100到H100,每个NVLink链路的带宽提高至50GB/s。这得益于增加了链路数量,从而提升了整体带宽。
NVSwitch 发展
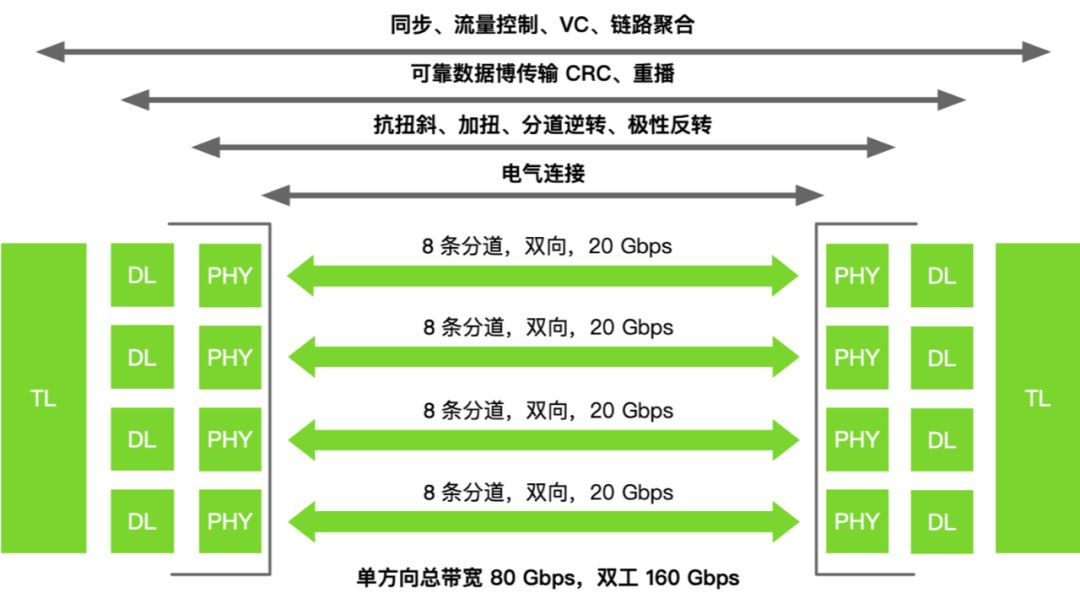
NVSwitch 发展
如上图所示,NVSwitch 技术从 Volta 架构到 Hopper 架构,经历了三代的演进与发展。在每一代中,每个 GPU 互联的芯片模组数量保持不变,都为 8 个,这意味着互联的基本结构保持了稳定性和一致性。随着 NVLink 架构的升级,GPU 到 GPU 之间的带宽却实现了显著的增长,因为 NVSwitch 就是 NVLink 具体承载的芯片模组,从 Volta 架构的 300GB/s 增加到了 Hopper 架构的 900GB/s。
下面我们来看下 NVLink 与 NVSwitch 在服务器中的关系。
NVSwitch 发展
如图所示,P100仅支持NVLink技术,GPU间通过CubeMesh实现互联。在P100中,每个GPU具有4路互联能力,每4个GPU组成一个CubeMesh。
在V100 GPU中,每个GPU可以通过NVSwitch与另一个GPU互联。而在A100中,NVSwitch进一步升级,大大减少了链路数量,使得每个GPU都可以通过NVSwitch与任意一个GPU进行互联。
到了 H100 中,又有了新的技术突破,单机内有 8 块 H100 GPU 卡,任意两个 H100 卡之间都有 900 GB/s 的双向互联带宽。值得注意的是,在 DGX H100 系统里,四个 NVSwitch 留出了 72 个 NVLink4 连接,用于通过 NVLink-Network Switch 连接到其他 DGX H100 系统,从而方便组成 DGX H100 SuperPod 系统。其中,72 个 NVLink4 连接的总双向带宽是~3.6TB/s。
总结
在AI大模型时代,计算资源成为关键驱动力,尤其是GPU资源。为训练庞大模型,需采用分布式并行策略,将任务分散至多GPU或计算节点。这涉及数据并行、模型并行等策略,以及高效的分布式通信技术,如NVLink和NVSwitch,确保数据在各计算单元间快速传输和同步。
在AI大模型时代,优秀的框架不仅要支持灵活的分布式并行策略,还需考虑利用NVLink和NVSwitch等先进通信技术,以确保高效的跨节点协作。
随着模型规模的持续扩大,计算资源需求不断攀升。为应对这一挑战,我们需致力于分布式并行策略的优化,发展高性能的分布式通信技术。这不仅涉及软件层面的策略更新,还需关注硬件优化。
"NVLink与NVSwitch的持续创新,极大地提升了深度学习模型训练的速度和效率。这些通信技术的进步,不仅助力我们训练更大规模的模型,还推动着人工智能迈向更深层次的发展。"
如果这篇文章对您有所帮助,请点赞转发,多多鼓励。
如果觉得这篇文章对你有所帮助,请点一下赞或者在看,是对我的肯定和支持~