目录
1. 前言
2. Source解析
2.1 Source类图
2.2 接口和方法说明
2.2.1 Source,>
3. SplitEnumerator解析
3.1 SplitEnumetator类图
3.2 类和方法说明
3.2.1 SplitEnumerator
3.2.2 SimpleVersionedSerializer
4. SourceReader解析
4.1 SourceReader类图
4.2 类和方法说明
4.2.1 SourceReader,>
4.2.2 SourceReaderBase,>
4.2.3 SplitFetcherManager,>
4.2.4 SingleThreadMultiplexSourceReaderBase,>
4.2.5 SplitReader,>
4.2.6 RecordsWithSplitIds
4.2.7 RecordEmitter,>
5. 如何实现一个新Source
6.总结
1. 前言
在Flink的旧版本中,数据源一直使用的是SourceFunction接口。然而,SourceFunction接口存在一些明显的问题,如批处理和流处理模式需要两套不同的实现、数据读取和“work发现”逻辑混杂、分区/分片/拆分在接口中定义不明确等。这些问题导致实现复杂,且难以以与source无关的方式实现某些功能,如event time对齐、每个分区水印、动态拆分分配等。为了解决这些问题,Flink在1.11版本引入了新的Source架构。下面对新版Source架构的核心源码做一些解析。
2. Source解析
2.1 Source类图

2.2 接口和方法说明
2.2.1 Source<T, SplitT extends SourceSplit, EnumChkT>
- 接口功能说明
- Source接口,它就像是一个工厂类,用来构造SplitEnumerator、SourceReader和相应的序列化器。
- 泛型T,由Source产生的记录类型。
- 泛型SplitT,由Source处理的分片类型。
- 泛型EnumChkT,枚举器checkpoint的类型。
- getBoundedness()
- 获取Source的有界性。
- 返回Boundedness,Source的有界性。
- createReader(SourceReaderContext readerContext)
- 创建一个source reader从其分配到的分片上面读取数据。
- source reader从零启动,不从任何状态中恢复。
- 参数readerContext,SourceReader的上下文。
- 返回SourceReader<T, SplitT>,一个新的SourceReader。
- throw Exception,实现者可以自由地直接抛出所有异常。此方法抛出的异常会导致TaskManager失败/恢复。
- createEnumerator(SplitEnumeratorContext<SplitT> enumContext)
- 为这个Source创建一个新的枚举器,开始一个新的输入。
- 参数enumContext,枚举器的上下文。
- 返回SplitEnumerator<SplitT, EnumChkT>,一个新的枚举器。
- throw Exception,实现者可以自由地直接跑出所有异常,从这个方法抛出异常会导致JobManager失败/恢复。
- restoreEnumerator(SplitEnumeratorContext<SplitT> enumContext, EnumChkT checkpoint)
- 从checkpoint中恢复枚举器。
- 参数enumContext,恢复分片枚举器的上下文。
- 参数checkpoint,恢复分片枚举器的checkpoint。
- 返回SplitEnumerator<SplitT, EnumChkT>,从给出的checkpoint中恢复的SplitEumerator。
- throw Exception,实现者可以自由地直接跑出所有异常,从这个方法抛出异常会导致JobManager失败/恢复。
- getSplitSerializer()
- 给Source的分片创建一个序列化器,分片在他们从枚举器发送到source reader,或者是checkpoint source reader的状态的时候会被序列化。
- 返回SimpleVersionedSerializer<SplitT>,分片类型的序列化器。
- getEnumeratorCheckpointSerializer()
- 给SplitEnumerator checkpoint创建一个序列化器,这个序列化器用于序列化SplitEnumerator. snapshotState()方法产生的结果。
- 返回SimpleVersionedSerializer<EnumChkT>,SplitEnumerator checkpoint序列化器。
3. SplitEnumerator解析
3.1 SplitEnumetator类图
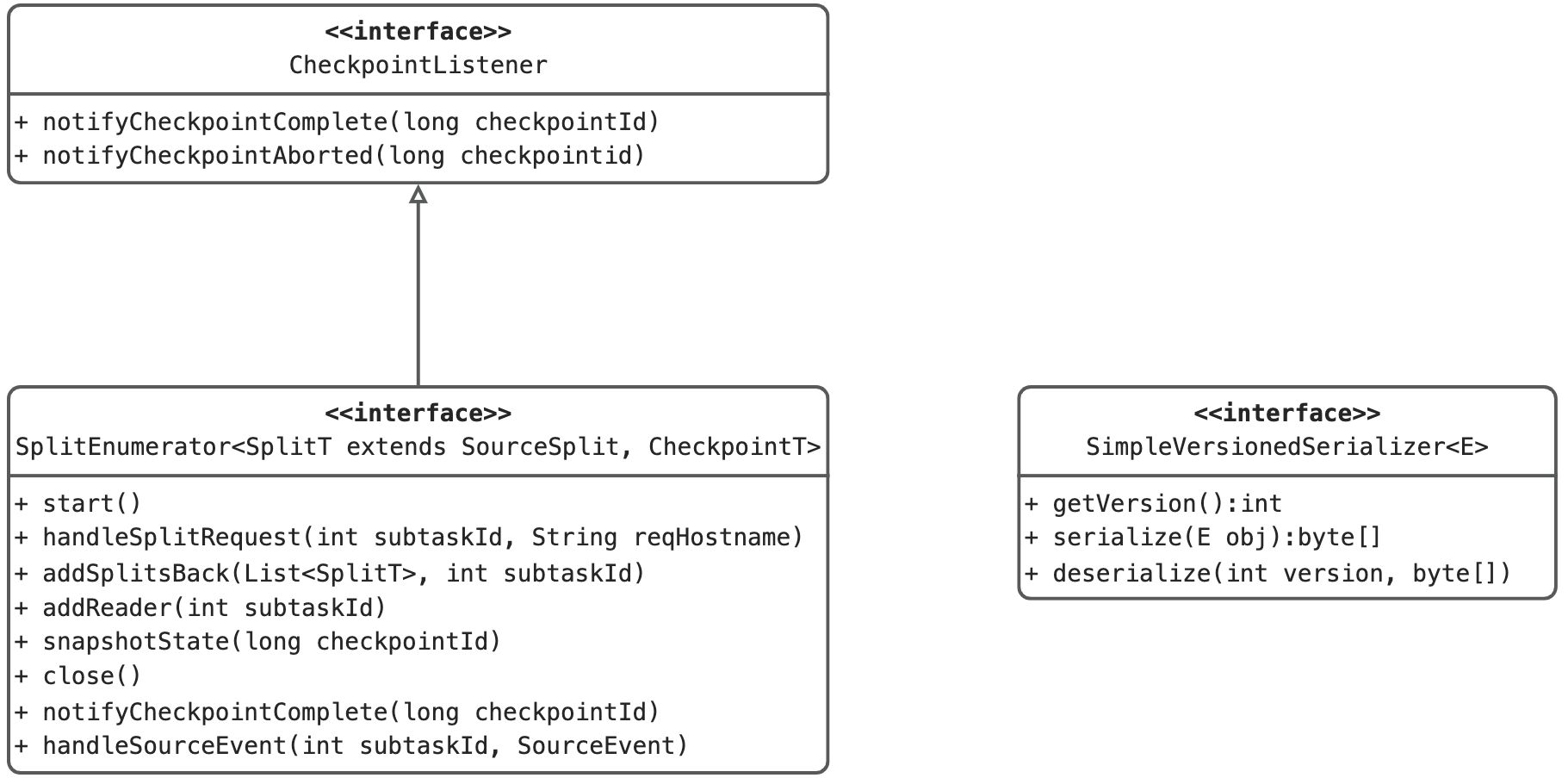
3.2 类和方法说明
3.2.1 SplitEnumerator<SplitT extends SourceSplit, CheckpointT>
- 接口功能描述:枚举器的接口,其主要的职责有如下两点:
- 发现分片提供给SourceReader读数据。
- 分配分配给到SourceReader。
- 泛型SplitT,分片对象。
- 泛型CheckpointT,枚举器快照状态对象。
- start()
- 启动枚举器,正常的数据源分片切分,自动发现等逻辑在枚举器启动的时候就进行设置。
- handleSplitRequest(int subtaskId, @Nullable String requesterHostname)
- 处理请求分片的请求。这个方法的调用时机是在SourceReader通过提供subtaskId调用SourceReaderContext.sendSplitRequest()方法时。
- 参数subtaskId,发送了source event的SourceReader的subtaskId。
- 参数requesterHostname,非必填参数,发起分片请求的SourceReader任务的主机名,这个可以用来做分片下发时候的SourceReader的通信定位。
- addSplitsBack(List<SplitT> splits, int subtaskId)
- 把下发给SourceReader的分片重新添加回枚举器,这个方法调用仅会发生在SourceReader Failover时,并且分配的分片列表是最近一次checkpoint成功的已分配分片列表。
- 参数splits,重新给回枚举器待重新分配的分片列表。
- 参数subtaskId,返回的这批分片原来归属的SourceReader task的subtaskId。
- addReader(int subtaskId)
- 添加了一个新的SourceReader的subtaskId。
- snapshotState(long checkpointId)
- 生成枚举器的状态快照,并把状态快照当作结果返回,让其和checkpoint一起存储。
- 快照应包含枚举器的最新状态:它应假设快照之前发生的所有操作都已成功完成。比如,分片已经分配给SourceReader(已经调用 SplitEnumeratorContext. assignSplit(SourceSplit, int) 和 SplitEnumeratorContext. assignSplits(SplitsAssignment) ) 就不再需要被包含在快照状态里了。
- 参数checkpointId,状态快照的checkpoint id,大部分实现不关心这个参数,因为都比较关心快照的内容,而不太关心是哪次checkpoint产生的。这个参数对于有那些有外部系统的连接器会比较有用,因为连接器的外部系统会比较关心checkpoints。比如,枚举器可以通知连接器的外部系统一次特别的checkpoint已经被触发。
- 返回参数,是一个包含了枚举器状态的对象。
- throws Exception,当快照无法正确执行时。
- close()
- 关闭枚举器,目的用来管理资源,比如线程、网络链接等。
- 这个并不是枚举器原生接口,是其继承了AutoCloseable的接口。
- notifyCheckpointComplete(long checkpointId)
- 通知checkpoint完成该方法有默认实现(不做任何事情),因为大部分枚举器不需要实现该方法。
- 这个并不是枚举器原生接口,是其继承了CheckpointListener的接口。
- handleSourceEvent(int subtaskId, SourceEvent sourceEvent)
- 处理从SourceReader发送过来的自定义的source event。
- 该方法有默认实现(不做任何事情),大部分枚举器不需要实现该接口,只有那些需要通过自定义事件协议在SourceReader和枚举器之间通信的才需要实现该接口。
- 通用的事件如SourceReader注册和请求分片都是不经过该方法,都是通过调用addReader(int) 和 handleSplitRequest(int, String) 方法实现。
- 参数subtaskId,SourceReader 发送事件的subtaskId。
- 参数sourceEvent,SourceReader 发送的事件。
3.2.2 SimpleVersionedSerializer<E>
- 接口功能描述:一个简单的版本序列化程序接口,序列化程序有一个版本(通过getVersion()返回),可以附加到序列化数据上。当序列化程序发展时,版本可用于标识数据是使用哪个先前版本序列化的。
- 泛型E,序列化程序进行序列化或者泛序列化的数据类型。
- getVersion()
- 获取由这个序列化程序进行序列化的数据的版本。
- 返回int,程序化程序的版本。
- serialize(E obj)
- 序列化给定的对象。假设序列化对应于当前序列化版本(由getVersion()返回)。
- 参数obj,序列化的对象。
- 返回byte[],对象序列化后的二进制字节数组。
- throws IOException,如果序列化失败。
- deserialize(int version, byte[] serialized)
- 对使用指定版本的序列化程序序列化的给定数据(字节)进行反序列化。
- 参数version,给定的序列化数据的版本。
- 参数serialized,序列化数据。
- 返回E,序列化对象。
- throws IOException,如果反序列化失败。
4. SourceReader解析
4.1 SourceReader类图

4.2 类和方法说明
4.2.1 SourceReader<T, SplitT extends SourceSplit>
- 接口功能描述
- 定义负责从SplitEnumerator中分配到的源分片中读取数据记录的SourceReader接口。
- 泛型T,从SourceReader中发出去的数据记录类型。
- 泛型SplitT,数据分片类型。
- start()
- 开启SourceReader,使得SourceReader开始从数据源中读取数据。
- pollNext(ReaderOutput<T> output)
- 将下一个可用的数据记录放入SourceOutput中。
- 接口实现必须保证这个方法不会被阻塞。
- 尽管接口实现可以提交多条记录到SourceOutput,但是不推荐这样做。相反,反而推荐提交一条记录到SourceOutput,然后返回InputStatus.MORE_AVAILABLE结果去让调用者线程知道还有更多的数据记录。
- 参数output,接收SourceReader读取到的记录。
- 返回参数InputStatus,方法调用后,SourceReader的InputStatus,是还有更多的记录,还是没有记录了。
- snapshotState(long checkpointId)
- checkpoint SourceReager的状态。
- 参数checkpointId,标志某一个checkpoint的id。
- 返回List<SplitT>,分配的分片的状态列表。
- isAvailable()
- 返回一个feature,feature完成,表示可以从源读取器中读取数据。
- 如果数据源读取器中有可用的数据,那么调用此方法,需要返回一个完成的feature,否则数据源读取器将一直停滞。如果数据源读取器中无可用的数据,那么需要返回一个未完成的feature,待数据源读取器中有可用的数据后,再把feature置为已完成,数据源读取器中的数据可被读取。
- addSplits(List<SplitT> splits)
- 添加一个分片列表给到数据源读取器读取方法调用时机是在枚举器分配分片的时候调用( 如SplitEnumeratorContext. assignSplit(SourceSplit, int) 或者 SplitEnumeratorContext. assignSplits(SplitsAssignment) )。
- 参数splits,由枚举器分配的分片列表。
- notifyNoMoreSplits()
- 这个方法当数据源读取器没有获取到更多的分片时被调用。
- 具体触发的时机是在枚举器调用了 SplitEnumeratorContext.signalNoMoreSplits(int)方法通知数据源读取器 subtask无更多分片时调用。
- handleSourceEvents(SourceEvent sourceEvent)
- 处理由枚举器发送的自定义数据源事件。
- 这个方法调用时机是在枚举器发送事件,枚举器调用了SplitEnumeratorContext. sendEventToSourceReader(int, SourceEvent) 方法。
- 这个方法有默认实现(不做任何事情),因为大部分数据源读取器不需要自定义时间。
- 参数sourceEvent,由枚举器发送的事件。
- notifyCheckpointComplete(long checkpointId)
- 通知checkpoint完成,这个不是SourceReader的原生接口,而是通过继承CheckpointListener接口。
- 参数checkpointId,表示某次checkpoint的标识ID。
4.2.2 SourceReaderBase<E, T, SplitT extends SourceSplit, SplitStateT>
- 抽象类功能描述
- 这个抽象类是SourceReader接口的一个抽象实现,提供了SourceReager的通用基础实现。让使用这个抽象类的用户只需要提供SplitReader和快照Split的状态。
- 泛型E,富元素类型,包含分区的状态更新和时间戳等信息。
- 泛型T,SourceReader往下游发送的最终元素类型。
- 泛型SplitT,不变的分片类型。
- 泛型SplitStateT,变化的分片状态。
- SourceReaderBase(FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,SplitFetcherManager<E, SplitT> splitFetcherManager,RecordEmitter<E, T, SplitStateT> recordEmitter,Configuration config,SourceReaderContext context)
- 参数elementsQueue,是一个阻塞队列,用于存放SourceReader读取到的元素。
- 参数splitFetcherManager,SplitFetcher管理者。
- 参数recordEmitter,记录发射器。
- 参数config,SourceReader的配置,简单的k/v结构。
- 参数context,SourceReader的上下文。
- onSplitFinished(Map<String, SplitStateT> finishedSplitIds)
- 处理已经完成的分片,如果需要的话可以用来清理状态。
- 参数finishedSplitIds,一个Map结构,key为分片id,value为SplitStateT。
- initializedState(SplitT split)
- 当新的分片添加到SourceReader,需要调用这个方法初始化新的分片的状态。
- 参数split,一个新添加的split。
- 返回SplitStateT,新添加split的状态。
- toSplitType(String splitId, SplitStateT splitState)
- 转化可变化的SplitStateT为不可变化的SplitT。
- 参数splitId,分片Id。
- 参数splitState,可变化的split状态。
- 返回SplitT,一个不可变化的Split状态。
4.2.3 SplitFetcherManager<E, SplitT>
- 抽象类功能描述
- 负责启动SplitFetcher,并且管理他们的生命周期。这个抽象类需要和SourceReaderBase。
- SplitFetcherManager可以用来支持不同的线程模型,通过addSplits(List)方法的不同实现来支持。 例如只有一个单线程的SplitFetcherManager只会启动一个SplitFetcher,并且把所有的分片分配给它。一个线程一个SplitFetcher的SplitFetcherManager,每当有一个新的分片被分配过来都会新开一个线程去读取新分片的数据。
- 泛型E,从SplitReader中读出来的数据类型。
- 泛型SplitT,分片类型。
- addSplits(List<SplitT> splitsToAdd)
- 添加新的分片给SplitFetcherManager,不同的线程模型可以在这个方法中实现。
- 参数splitsToAdd,新增加的分片列表。
4.2.4 SingleThreadMultiplexSourceReaderBase<E, T, SplitT extends SourceSplit, SplitStateT>
- 抽象类功能描述
- SourceReader使用单线程单SplitReader读取分片数据的一个基础抽象类。分片数据可以串行的读完一个再到下一个(比如FileSource)或者是在SplitReader中并行的读取订阅分片的数据(比如Kafka Source)。
- 为了基于这个抽象类实现SourceReader,实现者需要提供以下的组件:
- SplitReader,这个组件是负责链接数据源并且从数据源中读取数据。SplitReader会被通知不管什么时候有新的分片。SplitReader可以读取文件、Kafka或者是其他的数据源。
- RecordEmitter,从SplitReader中获取数据记录,并且更新checkpoint状态,转化它们到最终的格式。例如Kafka的RecordEmitter从SplitReader中提取数据记录ConsumerRecord,往checkpoint状态中放入offset信息,并通过序列化器转换数据记录到最终的类型,并发送记录到下游。
- 实现这个类必须覆写方法去实现不可变分片类型(SplitT)和可变的分片状态(SplitStateT)之间的相互转换。
- SourceReader需要决定在其启动( start() )之后需要做什么以及在分片读取结束( onSplitFinished(java. util. Map )后应该做什么。
- 泛型E,数据记录类型(通常包含检查点信息的原始类型)。
- 泛型T,SourceReader向下游发送的最终数据类型。
- 泛型SplitT,SourceReader需要处理的分片的类型。
- 泛型SplitStateT,每个分片的可变状态类型。
- 抽象方法与SourceReaderBase一样,实现者需要实现这些抽象方法,完成逻辑。
4.2.5 SplitReader<E, SplitT extends SourceSplit>
- 接口功能描述
- 用来读取分片数据的接口,实现可以用来读一个或者多个分片的数据。
- 泛型E,元素类型。
- 泛型SplitT,分片类型。
- fetch()
- 从分配的分片列表中读取数据到阻塞队列中。
- fetch方法调用会被阻塞,但是当wakeUp()方法被调用的时候,就不应该再阻塞。
- 方法实现应该返回数据并且不往外抛出异常,或者其只能抛出InterruptedException。
- 在任何一种情况下,此方法都应该是可重入的,这意味着下一个fetch调用应该从上次fetch调用被唤醒或中断的地方继续。
- 返回RecordsWithSplitIds<E>,读取到的结果和splitId一起返回。
- throw IOException,当发生IO错误时,比如序列化失败。
- handleSplitsChanges(SplitsChange<SplitT> splitsChanges)
- 处理分片变更,这个方法的实现不可阻塞。
- 参数splitsChanges,SplitReader需要处理的分片变更。
- wakeUp()
- 在fetcher线程阻塞在fetch()方法的情况下唤醒SplitReader
- close()
- 关闭SplitReader。
- throw Exception,如果关闭SplitReader失败。
4.2.6 RecordsWithSplitIds<E>
- 接口功能描述
- 把元素从fetchers传输到source reader的接口。
- 泛型E,fetchers读取到的数据元素。
- nextSplit()
- 移动到下一个分片。此方法最初也被调用以移动到第一个分片。如果没有分片,则返回null。
- 返回String,下一个分片Id。
- nextRecordFromSplit()
- 从当前分片中获取下一条记录,如果分片中没有更多的记录了,返回null。
- 返回E,元素类型。
- finishedSplits()
- 获取已完成的分片列表。
- 返回Set<String>,当前的RecordsWithSplitIds已完成的分片列表。
- recycle()
- 这个方法的调用时机是在当前批次的所有的记录都已经发送之后。
- 实现这个方法的目的主要是为了复用那些很大或者很重的对象,以便可以减少这些对象的分配和回收,可以提升程序的性能。
- 有默认实现(不做任何事情)。
4.2.7 RecordEmitter<E, T, SplitStateT>
- 接口功能描述
- 发送记录到下游
- 泛型E,SplitReader发送出来的记录类型。
- 泛型T,最终发送到SourceOutput的记录类型。
- 泛型SplitStateT,可变的分片状态类型。
- emitRecord(E element, SourceOutput<T> output, SplitStateT splitState)
- 处理和发送记录到SourceOutput。下面是对实现类的几点建议:
- 这个方法有可能在中途被中断,在这种情况下,相同的记录集合会再被发送到记录发送器,实现类需要确定其被读到。
- 参数element,SplitReader读过来的元素。
- 参数output,记录最后被发送到的输出。
- 参数splitState,分片的状态。
- throw Exception,当前逻辑异常了,需跑出异常。
- 处理和发送记录到SourceOutput。下面是对实现类的几点建议:
5. 如何实现一个新Source
Flink提供了挺多官方的Source,比如Kafka Source、RabbitMQ等。这些Source里面都包含有各自的业务逻辑代码,无法一针见血地直观的看到Source框架的实现,因此在这里笔者将介绍实现一个Source需要实现那些接口和类,介绍一个最简单的Source的实现过程。
- 实现Source接口,是Source的创建工厂。从Source接口的定义上,其实你也就差不多明白要实现一个新Source,需要做哪些事情。
- 实现SourceReader接口,直接实现这个接口还是比较复杂的,flink也比较贴心,提供了比较基础的实现,因此你只需要实现SingleThreadMultiplexSourceReaderBase抽象类即可。
- 实现SplitReader接口,是真正的从源头读取数据的实现,初始化SourceReader的时候需要依赖。
- 实现RecordEmitter接口,用于发送最终的记录格式到下游,初始化SourceReader的时候需要依赖。
- 实现RecordsWithSplitIds接口,SplitReader的fetch()方法需要返回的类型,初始化SourceReader的时候需要依赖。
- 实现SourceSplit接口,定义分片的类型,使得SourceReader可以读取分片的数据。
- 实现SourceSplit序列化器,checkpoint的时候可以SourceReader上的分片状态进行序列化和反序列化。
- 实现SplitEnumerator接口,可以把数据源中的数据切分成SourceSplit,让SourceReader可以并行读取。
- 实现SplitEnumerator序列化器,checkpoint的时候可以SplitEnumerator上的分配的分片列表状态进行序列化和反序列化。
6.总结
本文对Flink的新版本的Source接口核心源码进行了剖析,详细的解读了Source、SplitEnumerator和SourceReader三大模块做了方法级别的说明。并且在后面给出了实现一个新的Source的实现过程,下一篇文章可以基于给出的步骤实现一个简单的Source Demo供大家参考。