图像理解(Image Understanding)和基本图像处理(Basic Image Processing)是计算机视觉领域的重要组成部分。它们涉及从图像中提取有用信息、分析图像内容、并对其进行处理以达到特定目的。图像理解通常包括识别、分类和解释图像中的对象和场景,而基本图像处理则包括一系列基础操作,用于改善图像质量或为更高级的分析做准备。
一、图像理解基本概念
图像理解的目标是使计算机能够解释和理解图像内容,就像人类一样。这通常包括以下几个方面:
- 对象识别:识别图像中的特定对象或物体。
- 场景分类:确定图像代表的场景类型,如室内、室外、城市等。
- 活动识别:理解图像中发生的活动或事件。
- 深度估计:估计图像中对象的深度信息。
- 三维重建:从二维图像中重建三维场景。
- 语义分割:将图像分割成多个区域,并为每个区域分配一个类别标签。
图像理解通常需要复杂的算法和大量的训练数据,如深度学习模型,以实现高准确度的识别和解释。基本图像处理涉及一系列基础操作,用于改善图像质量或为更高级的分析做准备。这些操作包括:
- 图像读取和显示:加载图像文件并显示图像。
- 图像转换:在不同的颜色空间之间转换图像,如从RGB到灰度。
- 图像缩放:改变图像的大小。
- 图像裁剪:从图像中提取特定区域。
- 图像旋转:旋转图像以特定角度。
- 图像滤波:应用滤波器来平滑图像或增强图像特征。
- 边缘检测:识别图像中的边缘。
- 阈值处理:将图像转换为二值图像。
- 形态学操作:如膨胀、腐蚀、开运算和闭运算。
二、相关示例
以下是一个使用Python和OpenCV进行基本图像处理的示例:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取图像
image = cv2.imread('path_to_your_image.jpg')
if image is None:
print("Error: Could not open or find the image.")
exit()
# 转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 图像缩放
resized_image = cv2.resize(image, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
# 图像裁剪
height, width = image.shape[:2]
start_row, start_col = int(height * 0.1), int(width * 0.1)
end_row, end_col = int(height * 0.9), int(width * 0.9)
cropped_image = image[start_row:end_row, start_col:end_col]
# 图像旋转
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, 45, 1.0)
rotated_image = cv2.warpAffine(image, M, (w, h))
# 显示结果
plt.figure(figsize=(12, 8))
plt.subplot(231)
plt.title('Original Image')
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.subplot(232)
plt.title('Gray Image')
plt.imshow(gray_image, cmap='gray')
plt.axis('off')
plt.subplot(233)
plt.title('Resized Image')
plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.subplot(234)
plt.title('Cropped Image')
plt.imshow(cv2.cvtColor(cropped_image, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.subplot(235)
plt.title('Rotated Image')
plt.imshow(cv2.cvtColor(rotated_image, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.tight_layout()
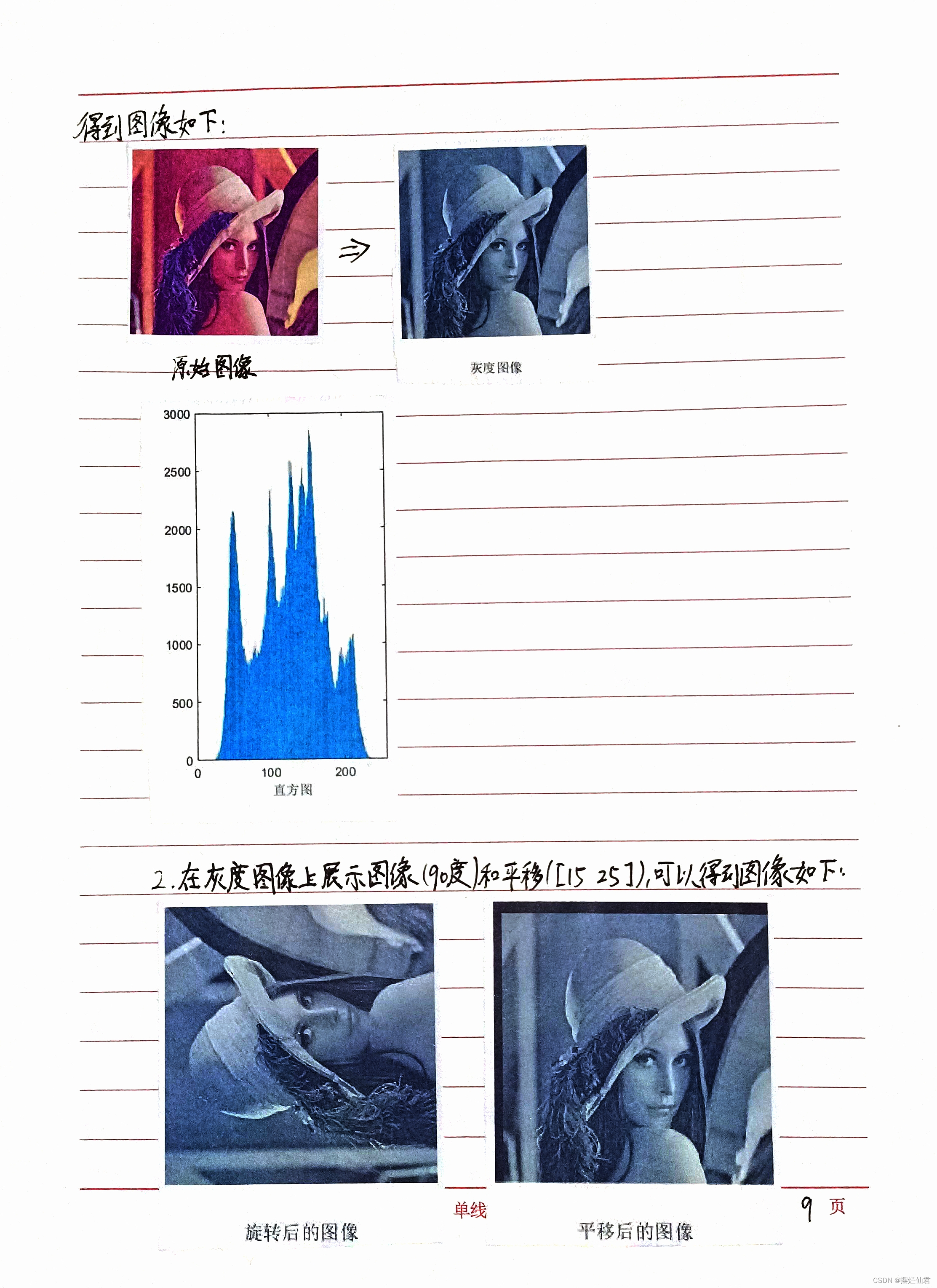
plt.show()这个示例展示了如何使用OpenCV进行基本的图像处理操作,包括图像读取、灰度转换、缩放、裁剪和旋转。这些操作是图像处理和图像理解的基础,可以为更复杂的任务提供支持。
三、实际应用
图像理解作为计算机视觉的一个关键领域,其应用已经渗透到我们生活的方方面面,极大地推动了技术和社会的进步。在医疗领域,图像理解帮助医生通过分析医学影像来诊断疾病,如识别肿瘤或病变区域,从而提高诊断的准确性和效率。在自动驾驶汽车中,图像理解技术使车辆能够识别和响应周围环境,包括行人、其他车辆和交通标志,确保行驶安全。
安全监控系统利用图像理解来检测异常行为或识别可疑人员,增强了公共安全。在农业中,通过分析卫星图像,图像理解技术帮助监测作物生长状况和评估产量,对提高农业生产效率和食品安全至关重要。在零售业,图像理解通过分析顾客行为和偏好,为个性化推荐和营销策略提供支持,改善了顾客的购物体验。
工业检测中,图像理解用于自动检测产品缺陷,确保产品质量,减少浪费。在文档分析中,图像理解技术如光学字符识别(OCR)使得从纸质文档中提取信息变得快速和准确。社交媒体平台使用图像理解来自动标记和分类内容,提供更丰富的搜索和过滤功能。此外,图像理解也在艺术创作、游戏开发和教育等领域发挥着重要作用,为人们提供了新的表达和学习方式。
让我们以一个简单的图像识别任务为例,使用Python和TensorFlow(或Keras)来识别手写数字。我们将使用著名的MNIST数据集,这是一个包含大量手写数字图像的数据集,常用于测试机器学习算法。
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train.reshape(-1, 28, 28, 1) # 添加单通道维度
x_test = x_test.reshape(-1, 28, 28, 1)
# 构建模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)
# 预测新数据
predictions = model.predict(x_test)
# 显示一些测试图像及其预测结果
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_test[i].reshape(28, 28), cmap=plt.cm.binary)
plt.xlabel(f'Predicted: {np.argmax(predictions[i])}')
plt.show()这个示例展示了如何使用TensorFlow和Keras构建和训练一个简单的卷积神经网络(CNN)来识别手写数字。随着技术的不断进步,图像理解的应用将更加广泛,它将继续在各个领域发挥着越来越重要的作用,推动创新和提高生活质量。
四、相关论文