文章链接: https://arxiv.org/pdf/2411.02319
项目链接:https://gen-x-d.github.io/
有视频

亮点直击
设计了一个数据整理流程,从视频中获取包含可移动物体的高质量4D数据,并为30,000个视频标注了相机姿态。这个大规模数据集称为CamVid-30K,将公开供公众使用。
提出了一个3D-4D联合框架GenXD,支持各种设置下的图像条件3D和4D生成(见下表1)。在GenXD中,引入了多视角时序层,以解耦和融合多视角和时序信息。
通过使用提出的CamVid-30K和其他现有的3D和4D数据集,GenXD在单视角3D对象生成、少视角3D场景重建、单视角4D生成以及单/多视角4D生成方面达到了与之前最先进的方法和基线方法相当或更优的性能。

总结速览
解决的问题
现有的2D视觉生成已取得显著进展,但3D和4D生成在实际应用中仍然面临挑战,主要由于缺乏大规模4D数据和有效的模型设计。
提出的方案
-
提出了一种数据整理流程,从视频中提取相机姿态和物体运动强度。
-
基于该流程,创建了一个大规模的4D场景数据集:CamVid-30K。
-
开发了生成框架GenXD,通过相机和物体运动解耦模块(多视角时序模块),在3D和4D数据中进行无缝学习。
-
采用masked隐空间条件,支持多种视角条件生成。
应用的技术
-
数据整理流程用于生成4D场景数据。
-
多视角时序模块用于解耦相机和物体运动。
-
mask隐空间条件用于支持不同视角的条件生成。
达到的效果
GenXD能够生成符合相机轨迹的视频,同时提供一致的3D视图,并支持生成3D表示形式。通过多种真实和合成数据集上的评估,验证了GenXD在3D和4D生成中的有效性和多功能性。
CAMVID-30K
大规模4D场景数据的缺乏限制了动态3D任务的发展,包括但不限于4D生成、动态相机姿态估计和可控视频生成。为了解决这一问题,本文引入了一个高质量的4D数据集。首先,使用基于结构光(SfM)的方法来估计相机姿态,然后通过提出的运动强度过滤掉不含物体运动的数据。数据流程如下图2所示:
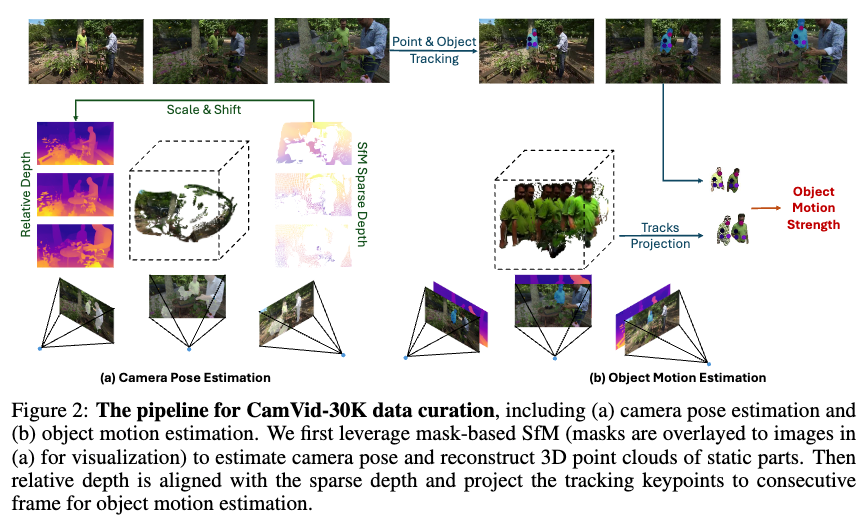
相机姿态估计
相机姿态估计基于SfM,它通过一系列图像中的投影重建3D结构。SfM包含三个主要步骤:
-
特征检测和提取
-
特征匹配和几何验证
-
3D重建和相机姿态估计
在第二步中,匹配的特征必须位于场景的静态部分,否则物体运动会在特征匹配时被误认为是相机运动,影响相机姿态估计的准确性。
为了解决这一问题,Particle-SfM使用运动分割模块将移动物体与静态背景分开,然后在静态部分执行SfM以估计相机姿态。然而,当相机本身在运动时,精确检测运动像素极其困难,通过实验观察到Zhao等人的运动分割模块缺乏足够的泛化性,导致假阴性和不准确的相机姿态。为了获得准确的相机姿态,分割出所有移动像素是必不可少的。在这种情况下,假阳性错误比假阴性更为可接受。为此,本文使用实例分割模型贪婪地分割出所有可能移动的像素。实例分割模型在训练类别上比Zhao等人的运动分割模块具有更强的泛化能力。在分割出潜在移动像素后,使用Particle-SfM来估计相机姿态,从而获得相机信息和稀疏点云(上图2(a))。
物体运动估计
分解相机和物体运动。 虽然实例分割可以准确地将物体与背景分离,但它无法判断物体本身是否在运动,而静态物体会对运动学习产生负面影响。因此,引入了运动强度来识别真实的物体运动,并过滤掉仅包含静态物体的视频。
由于视频中同时存在相机运动和物体运动,基于2D的运动估计方法(如光流)无法准确表示真实的物体运动。有两种方法可以捕捉真实的物体运动:一是测量3D空间中的运动,二是将视频中的运动投影到相同的相机视角上。两种方法都需要与相机姿态尺度对齐的深度图。稀疏深度图可以通过将3D点云 投影到相机视角上获得:
![]()
其中 表示点云 在相机空间中的坐标。 和 分别表示从世界空间到相机空间的旋转和平移, 是相机内参。通过投影公式,可以在图像像素 处获得深度值 ,即 。
如前面图2(a)所示,由于在3D重建过程中只匹配了静态部分的特征,因此只能获得静态区域的稀疏点云。然而,动态部分的深度信息对运动估计至关重要。为了解决这一问题,利用一个预训练的相对单目深度估计模型来预测每帧的相对深度 。然后,应用比例因子 和偏移量 使其与SfM的稀疏深度对齐。
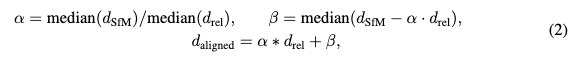
其中 表示中值, 为与SfM深度尺度对齐的密集深度图。
物体运动场。通过对齐的深度 ,可以将帧中的动态物体投影到3D空间中,从而提供一种直接测量物体运动的方法。如图2(b)所示,如果物体(例如穿绿衬衫的男子)在移动,则投影的3D点云会产生位移。然而,由于SfM仅能操作到一定的尺度,直接在3D空间中测量运动可能会导致量级问题。因此,将动态物体投影到相邻视图中并估计物体运动场。
具体而言,首先需要在2D视频中找到匹配点。不同于使用光流等密集表示,为每个物体实例采样关键点,并在2D视频中使用视频物体分割和关键点跟踪来建立匹配关系。然后将每个关键点投影到相邻帧中。第帧中的关键点 首先被反投影到世界空间,以获得3D关键点 。
![]()
其中 是对齐的密集深度图中的深度值。然后,使用投影方程(公式1)将3D关键点投影到第帧,得到2D投影关键点 。类似于光流,将每个2D关键点在第二个相机视图上的位移表示为物体运动场。
![]()
其中 和 分别表示图像的高度和宽度。
![]()
通过对每个物体的运动场进行处理,可以通过计算运动场的绝对大小的平均值来估计物体的全局运动。对于每个视频,运动强度由所有物体中的最大运动值表示。如下图3所示,当相机移动而物体保持静止(第二个例子)时,运动强度相比于物体有运动的视频要小得多。通过使用运动强度,进一步过滤掉缺乏明显物体运动的数据。运动强度值也作为物体运动尺度的良好指示器,用于时间层以实现更好的运动控制。

GenXD
生成模型
由于大多数场景级的3D和4D数据是通过视频捕获的,这些数据缺乏明确的表示(如网格)。因此,本文采用了一种方法,通过与空间相机姿态和时间步对齐的图像生成这些数据。将隐空间扩散模型(Latent Diffusion Model,LDM)融入到本文的框架中,加入了额外的多视角时间层,包括多视角时间ResBlocks和多视角时间变换器,以解耦和融合3D和时间信息。
Mask隐空间条件扩散模型
在GenXD中,隐空间扩散模型(LDM)用于生成不同相机视角和时间的图像/视频。LDM首先通过变分自编码器(VAE)将图像/视频编码为隐代码 ,并通过高斯噪声 扩散该隐代码以获得 。然后,使用去噪模型 来估计噪声,并通过条件反向扩散过程。
![]()
其中 是用于可控生成的条件,通常是文本或图像。GenXD生成具有相机姿态和参考图像的多视角图像和视频,因此它需要同时使用相机条件和图像条件。相机条件对于每张图像都是独立的,可以是条件化的或目标化的。因此,可以将相机条件轻松地附加到每个潜在空间。这里选择了普吕克射线作为相机条件。
![]()
其中 和 分别表示相机中心和从相机中心到每个图像像素的射线方向。因此,普吕克射线是一种密集嵌入编码,不仅包括像素信息,还包括相机姿态和内参信息,比全局相机表示更为精确。
参考图像条件更为复杂。GenXD旨在进行单视图和多视图的3D和4D生成。单视图生成要求较低,而多视图生成则能提供更一致的结果。因此,结合单视图和多视图生成将更适合实际应用。然而,之前的工作通过将条件隐变量与目标隐变量连接,并通过跨注意力引入CLIP图像嵌入来对图像进行条件化。连接方式需要改变模型的通道,无法处理任意输入视角。CLIP嵌入支持多条件输入,但这两种方法都无法建模多个条件的位置信息,也无法在输入视图之间建模信息。鉴于这些限制,采用了masked隐变量条件化来处理图像条件。正如下图4所示,在通过VAE编码器编码后,前向扩散过程应用于目标帧(第二和第三帧),并像往常一样将条件隐变量(第一帧)保持不变。然后,去噪模型估计两帧上的噪声并通过反向过程去除。

Masked隐变量条件化有三个主要优点。首先,模型可以支持任何输入视图,而无需修改参数。其次,对于序列生成(多视图图像或视频),无需约束条件帧的位置,因为条件帧在序列中保持其位置。与此相反,许多工作要求条件图像位于序列中的固定位置(通常是第一帧)。第三,由于没有来自其他模型的条件嵌入,用于集成条件嵌入的跨注意力层可以移除,从而大大减少了模型参数数量。为此,在GenXD中采用了masked隐变量条件化方法。
多视图时间模块
由于GenXD旨在在单一模型中生成3D和4D样本,因此需要将多视图信息与时间信息进行解耦。在两个独立的层中建模这两种信息:多视图层和时间层。对于3D生成,不考虑时间信息,而4D生成则需要同时考虑多视图和时间信息。因此,如上图4所示,本文提出了一种α融合策略用于4D生成。具体来说,为4D生成引入了一个可学习的融合权重α,当进行3D生成时,α设置为0。通过这种α融合策略,GenXD可以在多视图层中保留3D数据的多视图信息,同时从4D数据中学习时间信息。
α融合可以有效地解耦多视图和时间信息。然而,没有任何提示的情况下,运动较难控制。视频生成模型使用FPS或运动ID来控制运动的幅度,但未考虑相机运动。得益于CamVid-30K中的运动强度,能够有效地表示物体运动。由于运动强度是一个常量,将其与扩散时间步长结合,并将其添加到时间ResBlock层,如图4中的多视图时间ResBlock所示。通过多视图时间模块,GenXD可以有效地进行3D和4D生成。
使用3D表示的生成
GenXD可以使用一个或多个条件图像生成具有不同视角和时间步长的图像。然而,为了呈现任意3D一致的视图,需要将生成的样本提升到3D表示。先前的工作通常通过从生成模型中提取知识来优化3D表示。由于GenXD能够生成高质量且一致的结果,直接使用生成的图像来优化3D表示。使用3D高斯点云(3D-GS)和Zip-NeRF进行3D生成,使用4D高斯点云进行4D生成。
实验
实验设置
数据集
GenXD是在3D和4D数据集的结合下进行训练的。对于3D数据集,使用了五个带有相机姿态注释的数据集:Objaverse 、MVImageNet、Co3D、Re10K 和 ACID。Objaverse是一个合成数据集,包含网格数据,从12个视角渲染了80K子集,并按照的方法进行渲染。MVImageNet和Co3D是视频数据,分别记录了239个和50个类别的物体。Re10K和ACID是记录现实世界室内和室外场景的视频数据。对于4D数据集,使用了合成数据集Objaverse-XL-Animation和CamVid-30K数据集。对于Objaverse-XL-Animation,使用了Liang et al.(2024)筛选的子集,并通过向轨迹摄像机轨迹中添加噪声重新渲染了深度图和图像。利用地面真值深度,根据前面的方法估计物体运动强度,然后过滤掉没有明显物体运动的数据。最后,从Objaverse-XL-Animation中获得了44K合成数据,从CamVid-30K中获得了30K现实世界数据。
实现细节
GenXD部分初始化自Stable Video Diffusion (SVD)的预训练模型以实现快速收敛。具体来说,GenXD的多视图层(多视图卷积和多视图自注意力)和时间层(时间卷积和时间自注意力)都来自SVD中的时间层,而SVD中的跨注意力层被去除。GenXD的训练分为三个阶段。首先,只使用3D数据训练UNet模型500K次迭代;然后,在单视图模式下,使用3D和4D数据进行500K次迭代的微调;最后,GenXD在所有数据上使用单视图和多视图模式进行500K次迭代的训练。模型在32个A100 GPU上训练,批量大小为128,分辨率为256×256。采用AdamW优化器,学习率为。在第一阶段,数据被中心裁剪为方形。在最终阶段,通过中心裁剪或填充将图像处理为方形,使得GenXD可以很好地处理不同的图像比例。
4D 生成
4D 场景生成
在此设置中,评估需要包含物体和相机运动的视频。因此,引入了Cam-DAVIS基准来进行4D评估。使用提出的注释流程来获取DAVIS数据集(Per-dataset)中视频的相机姿态。然后,过滤数据,得到20个具有准确相机姿态和明显物体运动的视频。Cam-DAVIS的数据相机轨迹与训练数据存在分布外差异,因此它们是评估相机运动鲁棒性的良好标准。
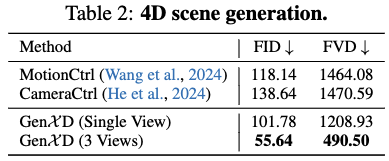
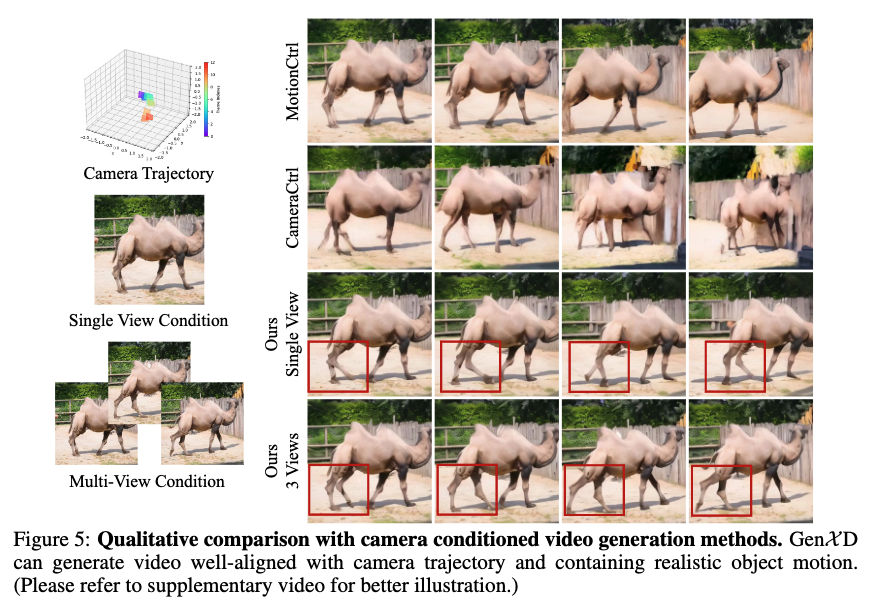
将GenXD与开源的相机条件视频生成方法——MotionCtrl和 CameraCtrl 进行了比较,使用FID 和 FVD 评估指标。将Stable Video Diffusion作为这两种方法的基础模型,生成带有相机轨迹和第一帧条件的视频。如下表2所示,使用第一视图作为条件,GenXD在两个指标上显著优于CameraCtrl和MotionCtrl。此外,使用3个视图作为条件(第一、中央和最后一帧),GenXD相较于之前的工作有了大幅度的提升。这些结果展示了GenXD在4D生成中的强大泛化能力。在下图5中,比较了三种方法的定性结果。在这个例子中,MotionCtrl无法生成明显的物体运动,而CameraCtrl生成的视频既不具有3D特性,也没有时间一致性。相反,单视图条件模型可以生成平滑且一致的4D视频。使用3个条件视图时,GenXD能够生成相当逼真的结果。
4D 物体生成
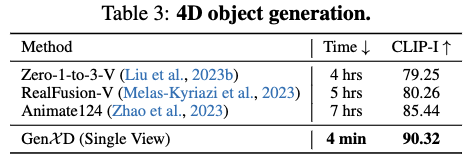
根据Zhao et al.(2023)的方法评估了4D物体生成的性能。由于GenXD仅使用图像条件,而不是像Animate124那样使用图像-文本条件,下表3中对比了优化时间和CLIP图像相似性。与使用分数蒸馏采样(SDS)优化动态NeRF不同,GenXD直接生成轨道相机轨迹的4D视频,并使用这些视频来优化4D-GS。这使得本文的方法比Animate124快了100倍。此外,Zhao et al.(2023)中提到的语义漂移问题在GenXD中得到了很好的解决,因为使用了图像条件进行4D生成。4D场景和物体生成的结果展示了GenXD在生成具有3D和时间一致性的4D视频方面的优越性。
3D 生成
少视图3D生成
在少视图3D重建设置中,在Re10K(分布内数据集)和LLFF (分布外数据集)上评估了GenXD。从Re10K中选择了10个场景,从LLFF中选择了所有8个场景,每个场景使用3个视图进行训练。性能通过PSNR、SSIM和LPIPS指标在渲染的测试视图上进行评估。作为一个生成模型,GenXD可以从稀疏输入视图中生成额外视图,并改善任何重建方法的性能。在这个实验中,使用了两个基线方法:Zip-NeRF和 3D-GS。这两个基线方法是面向多视图重建的方法,因此调整了超参数以便更好地进行少视图重建(更多细节请见附录D)。如下表4所示,Zip-NeRF和3D-GS都可以通过GenXD生成的图像得到改善,而且在Zip-NeRF基线上的改善更加显著。具体来说,Re10K(分布内)和LLFF(分布外)的PSNR分别提高了4.82和5.13。定性比较如下图6所示。通过生成的视图,重建场景中的浮动和模糊得到了减少。

消融研究
本节进行多视图-时间模块的消融研究。消融研究评估了在少视图3D和单视图4D生成设置下生成的扩散样本的质量(见下表5)。

运动解缠(α融合)
在4D数据中,相机运动和物体运动是纠缠在一起的。为了在3D和4D中都能实现高质量生成,GenXD引入了多视图-时间模块,将多视图和时间信息分别学习,然后通过α融合将它们结合起来。对于3D生成,α设置为0,以绕过时间模块,而在4D生成中,α在训练过程中学习。移除α融合将导致所有3D和4D数据都通过时间模块,从而使得模型无法将物体运动从相机运动中解缠开来。解缠失败会对3D和4D生成产生不利影响。
运动强度的有效性
运动强度可以有效地控制物体运动的幅度。如下图7倒数第二行所示,增加运动强度可以提高汽车的速度。根据这些观察,可以得出结论,学习物体运动是很重要的,并且在数据策划流程中的物体运动场和运动强度能够准确地表示真实的物体运动。

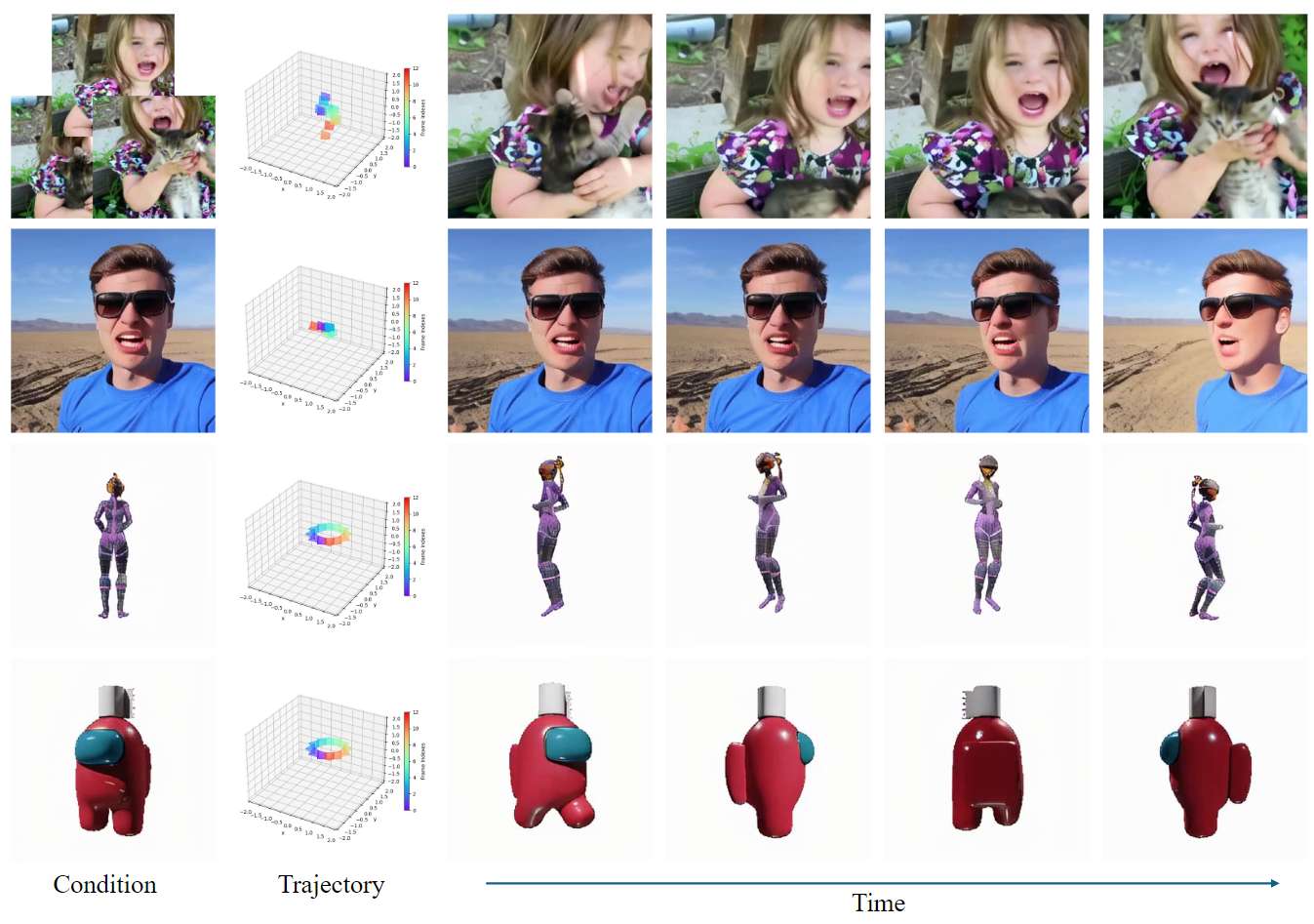
更多结果


结论
本文研究了使用扩散模型进行通用3D和4D生成。为了增强4D生成的学习,首先提出了一种数据策划流程,用于注释视频中的相机和物体运动。在此流程的支持下,本文引入了最大的现实世界4D场景数据集——CamVid-30K。此外,借助大规模数据集,提出了GenXD来处理通用3D和4D生成。GenXD利用多视图-时间模块来解缠相机和物体运动,并能够通过masked隐空间条件支持任意数量的输入条件视图。GenXD能够处理多种应用,并且在所有设置中,单一模型可以实现可比或更好的性能。
参考文献
[1] GenXD: Generating Any 3D and 4D Scenes