大家好,本文将介绍基于改进后的YOLOv5目标检测模型,设计并实现人群密度检测系统。
使用YOLOv5的源代码,在此基础上修改和训练模型, 数据集选用crowdhuman数据集。对yolov5源码中的文件进行修改,更换主干网络、改进损失函数。系统的前后端代码则体现在sever.py、detect_web.py和head-detect-web 文件夹中,主要基于Flask实现。
文件下载:基于YOLOv5的人群密度检测系统设计与实现
1.FasterNet实现
利用PyTorch深度学习框架实现FasterNet主干网络,FasterNet是一种高效的主干网络,专门设计用于目标检测任务,并针对速度和精度进行优化。在目标检测领域,主干网络的选择对于算法性能至关重要,因为它直接影响着特征的提取和表达能力。FasterNet以其卓越的性能和高效的设计,在目标检测算法中得到广泛应用。
FasterNet的网络结构由基础网络模块、快速特征融合模块和高效上采样模块三个主要部分组成。基础网络模块是FasterNet的基本组成单元,它包括卷积层、批归一化层和激活函数层。这些层在深度学习中经常被使用,用于对图像进行特征提取和非线性激活。
快速特征融合模块是FasterNet的关键模块之一,它负责将来自不同层级的特征进行融合。特征融合是目标检测算法中的重要步骤,它可以帮助算法捕获不同尺度和复杂度的目标信息。
高效上采样模块用于实现特征图的上采样,以实现目标位置的精确定位。在目标检测算法中,上采样操作通常用于恢复高分辨率的特征图,从而实现目标位置的准确定位。FasterNet采用了一种高效的上采样方法,能够在保持速度的同时,提高定位精度。
代码如下:
class PConv(nn.Module):
# PConv Block
def __init__(self, dim, n_div, forward="split_cat", kernel_size=3):
super().__init__()
self.dim_conv = dim // n_div
self.dim_untouched = dim - self.dim_conv
self.conv = nn.Conv2d(
self.dim_conv,
self.dim_conv,
kernel_size,
stride=1,
padding=(kernel_size - 1) // 2,
bias=False)
if forward == "slicing":
self.forward = self.forward_slicing
elif forward == "split_cat":
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x):
x[:, :self.dim_conv, :, :] = self.conv(x[:, :self.dim_conv, :, :])
return x
def forward_split_cat(self, x):
x1, x2 = torch.split(x, [self.dim_conv, self.dim_untouched], dim=1)
x1 = self.conv(x1)
x = torch.cat((x1, x2), 1)
return xclass FasterNetBlock(nn.Module):
# FasterNetBlock Block
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = PConv(c1, 2, "split_cat", 3)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c2, 1, 1, g=g)
self.add = shortcut
def forward(self, x):
return x + self.cv3(self.cv2(self.cv1(x))) if self.add else self.cv3(self.cv2(self.cv1(x)))class FasterNeXt(nn.Module):
# FasterNeXt Bottleneck
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(FasterNetBlock(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))2.更换主干网络
在将FasterNet集成到YOLOv5中时,需要对网络结构进行修改和参数进行调整,以确保两者能够充分发挥优势。修改YOLOv5的主干网络部分,将默认的主干网络替换为FasterNet:
elif m in [FasterNeXt]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [FasterNeXt]:
args.insert(2, n) # number of repeats
n = 13.模型配置文件
完成以FasterNet为主干网络的YOLOv5模型配置,网络大小相比yolov5s参数量降低, 范围介于yolov5s和yolov5x之间,具体代码见yolov5-fasternet.yaml。
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, FasterNeXt, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, FasterNeXt, [1024]], # 改进示例,也可以修改其他位置
[-1, 1, SPPF, [1024, 5]], # 9
]4.改进损失函数
基于最优传输分配(OTA)方法,改进损失函数ComputeLoss为ComputeLossOTA。 该方法提出了一种基于优化策略的标签分配方式,将 gt 看做 label 供应商,anchor 看做 label 需求方。 对于正样本,将分类和回归的 loss 加权和作为传输花费,对于负样本,传输花费就为分类 loss,通过最小化该花费,让网络自己学习最优的标签分配方式。 免去了手工选定参数的方式来实现标签分配,让网络自己选择每个 gt 对应的 anchor 数量, 而非提前设定,也能够较好的解决模棱两可的 anchor 分配问题,提高网络对这部分 anchor 的处理效果。
class ComputeLossOTA:
# Compute losses
def __init__(self, model, autobalance=False):
super(ComputeLossOTA, self).__init__()
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)5.添加Soft-NMS方法
将原torchvision.ops.nms方法用soft_nms替换。 该方法能够帮助模型在检测阶段,消除多余的检测框,找到最佳的物体检测位置,提高物体检测框标注的准确性。
def box_iou_for_nms(box1, box2, GIoU=False, DIoU=False, CIoU=False, EIou=False, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps6 网页端部署
目前实现了基于Flask在网页端部署原YOLOv5模型,并调用电脑摄像头进行实时检测,服务器端代码见sever.py,前端代码见templates/show_web.html,后端代码见detect_web.py。基于Flask实现的服务器端代码:
import flask
from flask import *
import flask_cors
import cv2
import logging as rel_log
from datetime import timedelta
from detect_web import VideoCamera
app = Flask(__name__)
cors = flask_cors.CORS(app, resources={r"/getMsg": {"origins": "*"}}) #解决跨域问题,vue请求数据时能用上7.模型训练
模型训练时loss的收敛过程和曲线等均保存在results文件夹中:
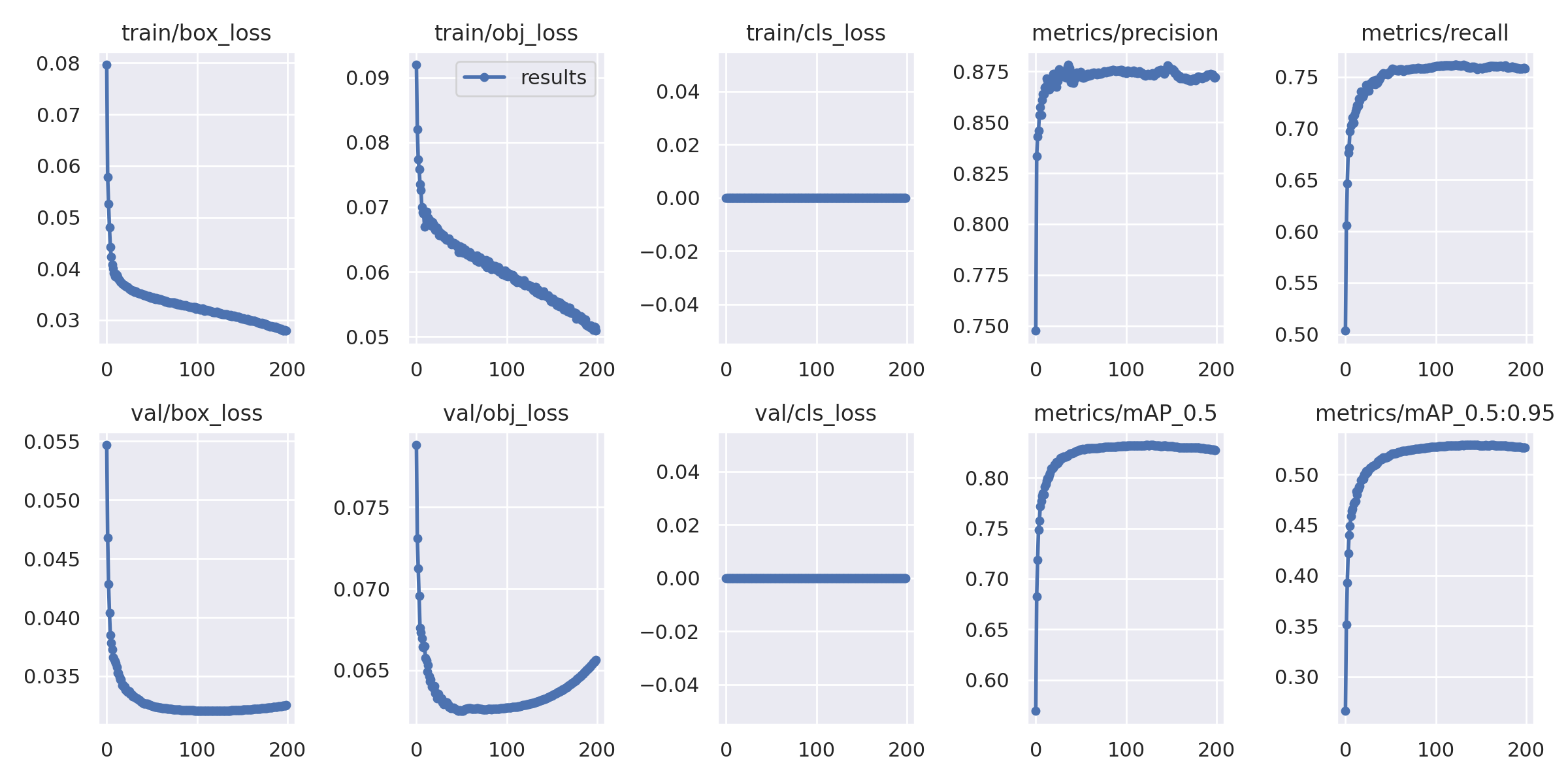
模型一共训练200个epoch,在训练集和验证集上的效果图保存在exp文件夹中;模型训练的权重保存在weights文件夹中。下图为标签和模型预测图的示例:


8.系统实现
最终,设计实现系统原型设计中图片/视频检测、摄像头检测的核心功能,web前后端代码体现在sever.py、detect_web.py和head-detect-web文件夹中,主要基于Flask实现,改进后的模型效果得到很大的提升。









![HTB:Photobomb[WriteUP]](https://i-blog.csdnimg.cn/direct/7cc80387d0314bbb9ecb5105ca1263d7.png)