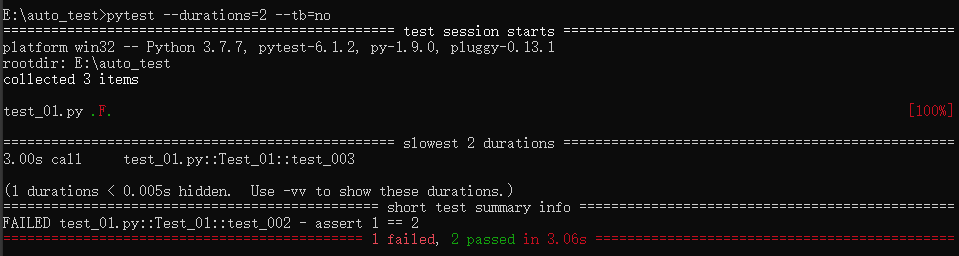
4. Multi-Head Attention
深度学习中的多头注意力机制:原理与实现解析
在自然语言处理和计算机视觉的任务中,多头注意力(Multi-Head Attention)已经成为Transformer模型中必不可少的组成部分。多头注意力机制不仅能够让模型关注到输入的不同方面,还能更好地捕获词语间复杂的上下文关系。今天,我们将深入解析多头注意力的原理与实现!
为什么需要多头注意力?
单一的注意力头只能捕获句子中的一种关系或模式,而在实际应用中,句子中的不同词语往往有复杂的关系。多头注意力通过并行多个注意力头,让模型能够关注到输入的多个不同层面,从而更全面地理解输入内容。每个头会从不同的角度捕捉句子中的依赖关系,有助于提升模型的表达能力和对上下文的理解。
多头注意力的工作原理
1. 生成 Q、K、V 矩阵
多头注意力机制的输入是三个矩阵:Query(查询)矩阵 Q,Key(键)矩阵 K 和 Value(值)矩阵 V,每个矩阵都包含输入序列的信息:
- Query(Q):代表要关注的内容
- Key(K):输入特征标签,用于表示每个词的特征
- Value(V):实际包含的内容信息
2. 多头注意力的计算步骤
假设我们有一个输入向量 x x x 和 h h h 个注意力头,每个头的步骤如下:
-
线性变换:对输入向量 x x x 进行线性变换,生成 Q , K , V Q, K, V Q,K,V 三个矩阵。每个注意力头有自己的权重矩阵,这使得每个头都可以从不同的视角理解输入。
-
计算注意力权重:通过点积注意力计算每个 Query 和 Key 之间的相似度,用 softmax 得到注意力权重,公式如下:
$$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q \cdot K^T}{\sqrt{d_k}}\right) \cdot V
$$
其中 d k d_k dk 是 Key 的维度,用于缩放,防止数值过大。
-
并行计算多个头:对每个头进行相同的计算。每个头的注意力权重不同,这使得每个头可以关注不同的上下文关系。
-
合并输出:将多个头的输出拼接,生成最终的多头注意力结果。通常通过线性变换将结果映射回原来的维度。
多头注意力公式
假设我们有 h h h 个注意力头,每个头的输出为 Attention i ( Q i , K i , V i ) \text{Attention}_i(Q_i, K_i, V_i) Attentioni(Qi,Ki,Vi) ,最终的多头注意力输出为:
$$
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) \cdot W^O
$$
其中:
- head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
- W i Q , W i K , W i V W_i^Q, W_i^K, W_i^V WiQ,WiK,WiV 是每个头的线性变换矩阵。
- W O W^O WO 是最终输出的线性映射矩阵,用于将拼接结果映射回原始维度。
自己实现多头注意力类
接下来我们通过代码实现一个简单的 MultiHeadAttention 类,以更好地理解多头注意力机制的实现细节。
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
# 确保嵌入维度能整除头数
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
# 定义 Q、K、V 的线性层
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query):
N = query.shape[0] # batch size
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 将 Q、K、V 分成多个头
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# 计算注意力得分
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) / (self.head_dim ** (1/2))
attention = torch.softmax(energy, dim=3)
# 计算注意力输出
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
# 拼接头的输出,并通过最后的线性层
out = self.fc_out(out)
return out
代码解析
- 初始化:定义了输入的维度、头数、每个头的维度,并创建了用于生成 Q、K、V 的线性层。
- 分割多头:将输入 Q、K、V 按头数分割,使得每个头能独立计算注意力。
- 计算注意力得分:通过点积计算 Q 和 K 之间的相似度,并使用 softmax 获得注意力权重。
- 输出计算:将每个头的权重与 V 相乘,拼接各个头的输出,最后通过线性层映射到原始维度。
测试代码
我们可以通过以下测试代码验证 MultiHeadAttention 的输出是否正常。
embed_size = 256
heads = 8
seq_len = 10
x = torch.rand((3, seq_len, embed_size)) # 假设 batch size 为 3,序列长度为 10
multihead_attention = MultiHeadAttention(embed_size, heads)
output = multihead_attention(x, x, x)
print("多头注意力输出形状:", output.shape)
你会看到输出的形状为 (3, seq_len, embed_size),这与输入形状一致,验证了多头注意力的效果。
总结
- 多头注意力是对单头注意力的扩展,可以让模型从多个角度捕获输入序列中的复杂关系。
- 每个头独立生成 Q、K、V,并通过点积计算相似度,从而获得多样化的上下文信息。
- 多头注意力在自然语言处理和计算机视觉任务中广泛应用,有助于模型更全面地理解输入数据。
希望通过这篇文章的讲解与代码示例,能帮助你理解多头注意力的原理与实现。如果有任何疑问,欢迎留言讨论!