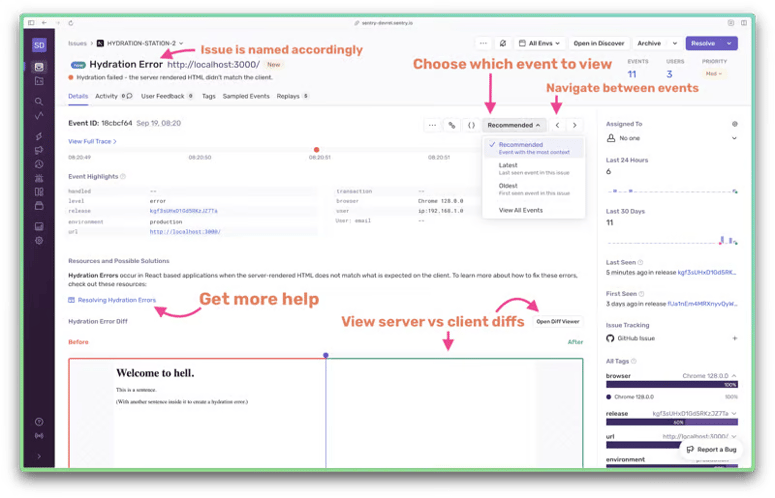
16、kafka是如何做到高效读写

因为kafka本身就是分布式集群,可以采用分区技术,并行度高
读取数据可以采用稀疏索引,可以快速定位要消费的数据(mysql中索引多了以后,写入速度就慢了)
可以顺序写磁盘:
Kafka的producer生产数据,要写到log文件中,写的过程是文件一直追加到文件末端,为书写顺序
缓存页+零拷贝技术:
零拷贝:kafka的数据加工处理操作交由生产者和消费者处理,border应用层不关心储存的数据,所以就不用走应用层,传输速率高
pangCache页缓存:kafka高度依赖层操作系统,当上层有写操作时,操作系统只是将数据写入pageCache 当读写操作发生时,先从PageCahe中查找,如果找不到,再去磁盘中读取,实际是吧尽可能多的空闲内存都用来当作磁盘使用
生产者将数据发送给kafka,kafka将数据交给Linux内核,Linux内核将数据放入自身操作系统的页缓存中,然后到一定值写入磁盘,假如消费者过来消费,直接从页缓存中,通过网卡发送给消费者,根本就没有去kafka的业务系统中获取数据,所以速度比较快
17、Kafka集群中数据的存储是按照什么方式存储的?

topic数据的存储机制:
一个主题下的分为多个分区partation,每个partation下对应的有一个log文件,log文件中存储的就是producer生产的数据,分区产生的数据会不断的追加到log文件的末端,为了防止log文件过大导致数据定位效率低下,kafka采取了分片和索引机制,将每一个分区分为多个segment,每个segment文件包括:索引(index)、log文件、timeidex文件,这些文件位于一个文件夹下该文件的命名规则为:topic名称+分区序号。
topic储存到:hadoop11(或者 hadoop12、hadoop13)的/opt/installs/kafka3/datas/first-1 (first-0、first-2)路径上的文件


ompact 日志压缩(合并的意思,不是真的压缩)
compact日志压缩:对于相同key的不同value值,只保留最后一个版本。
log.cleanup.policy = compact 所有数据启用压缩策略

压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费。
这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
比如:张三 去年18岁,今年19岁,这种场景下可以进行压缩。
18、kafka中是如何快速定位到一个offset的。

从0.9版本开始,consumer默认将offset保存在kafka一个内置的topic中(——consumer——offsets)
(topic 其实就是数据,就是位置 topic—log——segent的一个个文件)
0.9之前 consumer默认将offer保存在zookeeper中
0.11版本高于kafka.,想要重置 kafka要 kafka logs datas zk中的kafka文件删除掉
1、根据目标offset定位Segment文件
2、找到小于等于目标offset的最大offset对应的索引项
3、定位到log文件
4、向下遍历找到目标Record
19、简述kafka中的数据清理策略。
但是文件过大也不能使用,需要清理,数据的清理策略:
Kafka 中默认的日志(这个地方是数据的意思,就是Segment)保存时间为 7 天,可以通过调整如下参数修改保存时间
log.retention.hours,最低优先级小时,默认 7 天。
log.retention.minutes,分钟。 --如果设置了该值,小时的设置不起作用。
log.retention.ms,最高优先级毫秒。 --如果设置了该值,分钟的设置不起作用。
log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟
清理方法:
1、delete删除日志:将过期的数据删除
1):基于时间,默认打开的,以segment中所有记录中的最大时间戳作为文件的时间戳(时间到期的数据会被删除,但是当一个文件中有老数据和新数据的时候,时间戳会变成最新的数据,那个数据的文件夹就不会被删除)
2):基于大小,默认关闭的超过设置的所有文件日志大小删除最早的segment
log.retention.bytes,默认等于-1,表示无穷大。
如果一个 segment 中有一部分数据过期,一部分没有过期,怎么处理?

删除没有含有新数据的文件,含有新数据的文件不会删除
20、消费者组和分区数之间的关系是怎样的?


一个消费者组由多个消费者组成,一个topic由多个生产者组成
kafka由四种主流的分区分配策略:Range,oundRobin(轮询)、Sticky(粘性)、CooperativeSticky(配合的粘性)。 可以通过调参数来修改分区策略,partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。
消费者组是由多个consumer组成的。
首先,消费者组内每个消费者负责消费不同分区的数据,一个分区只能由组内一个消费者消费。
其次,消费者组之间互不影响。所有的消费者都属于某个消费者组。
21、kafka如何知道哪个消费者消费哪个分区?
生产者把数据发送给各个分区,每个broker节点都有一个coordinator(协调器)。
消费者组对分区进行消费,消费规则是:
1、首先groupId对50取模,看最后的结果是哪个分区节点,假如是1分区,那么1分区的协调器就是本次消费者组的老大
2、其次每个消费者会向该协调器进行注册,协调器会从中随机选择一个消费者作为本次消费的Leader,然后把本次消费的具体情况发送给Leader,让其制定一个消费计划(就是哪个消费者消费哪个分区)
3、最后Leader发送给协调器,协调器再进行群发,将计划公布,各个消费者按照这个计划进行消费。
22、kafka消费者的消费分区策略有哪些,默认是个?
默认:默认策略是Range + CooperativeSticky。
Range分区策略原理:
把分区对消费者取模,多的按第一个消费到最后一个消费者顺序依次分配,但是topic越多,c0消费者的分区会比其他消费者明显多消费n个分区,容易产生数据倾斜

RoundRobin(轮询) 以及再平衡:
采用轮询分区策略,把所有的分区和所有的消费者列出来,然后按照hashcode进行排序,最后经过轮询的方法进行分配,按照顺序每个消费者依次分一个,直到分完。

Sticky 以及再平衡 :
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前, 考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。 粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区 到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。

CooperativeSticky 的解释【新的kafka中刚添加的策略】:
在消费过程中,会根据消费的偏移量情况进行重新再平衡,也就是粘性分区,运行过程中还会根据消费的实际情况重新分配消费者,直到平衡为止。
好处是:负载均衡,不好的地方是:多次平衡浪费性能。
动态平衡,在消费过程中,实施再平衡,而不是定下来,等某个消费者退出再平衡。