参考自《深度学习推荐系统》—— 王喆,用于学习记录。
1.协同过滤
“协同过滤”就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。
基于用户相似度进行推荐的协同过滤算法 UserCF
用户相似度计算
余弦相似度
余弦相似度(CosineSimilarity)衡量了用户向量i和用户向量j之间的向量夹角大小。显然,夹角越小,证明余弦相似度越大,两个用户越相似。
sin ( i , j ) = cos ( i , j ) = i ⋅ j ∥ i ∥ ⋅ ∥ j ∥ \sin(i,j)=\cos(i,j)={\frac{i\cdot j}{\|i\|\cdot\|j\|}} sin(i,j)=cos(i,j)=∥i∥⋅∥j∥i⋅j
皮尔逊相关系数
相比余弦相似度,皮尔逊相关系数通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响。
s i m ( i , j ) = ∑ p ∈ P ( R i , p − R ˉ i ) ( R j , p − R ˉ j ) ∑ p ∈ P ( R i , p − R ˉ i ) 2 ∑ p ∈ P ( R j , p − R ˉ j ) 2 \mathrm{sim}(i,j)=\frac{\sum_{\mathbf{p}\in P}(R_{\mathrm{i,p}}-\bar{R}_{\mathrm{i}})(R_{\mathrm{j,p}}-\bar{R}_{\mathrm{j}})}{\sqrt{\sum_{\mathbf{p}\in P}(R_{\mathrm{i,p}}-\bar{R}_{\mathrm{i}})^{2}}\,\sqrt{\sum_{\mathbf{p}\in P}(R_{\mathrm{j,p}}-\bar{R}_{\mathrm{j}})^{2}}} sim(i,j)=∑p∈P(Ri,p−Rˉi)2∑p∈P(Rj,p−Rˉj)2∑p∈P(Ri,p−Rˉi)(Rj,p−Rˉj)
其中, R i , p R_{\mathrm{i,p}} Ri,p 代表用户i对物品p的评分。 R i ˉ \bar{R_{\mathrm{i}}} Riˉ 代表用户i对所有物品的平均评分, P P P 代表所有物品的集合。
基于皮尔逊系数的思路的物品平均分的方式
减少物品评分偏置对结果的影响。
sin ( i , j ) = ∑ p ϵ P ( R i , p − R p ‾ ) ( R j , p − R p ‾ ) ∑ p ϵ P ( R i , p − R p ‾ ) 2 ∑ p ϵ P ( R j , p − R p ‾ ) 2 \sin(i,j)=\frac{\sum_{\mathbf{p}\epsilon P}(R_{\mathrm{i,p}}-\overline{{R_{\mathbf{p}}}})(R_{\mathrm{j,p}}-\overline{{R_{\mathbf{p}}}})}{\sqrt{\sum_{\mathbf{p}\epsilon P}(R_{\mathrm{i,p}}-\overline{{R_{\mathbf{p}}}})^{2}}\,\sqrt{\sum_{\mathbf{p}\epsilon P}(R_{\mathrm{j,p}}-\overline{{R_{\mathbf{p}}}})^{2}}} sin(i,j)=∑pϵP(Ri,p−Rp)2∑pϵP(Rj,p−Rp)2∑pϵP(Ri,p−Rp)(Rj,p−Rp)
其中, R p ‾ \overline{{R_{\mathfrak{p}}}} Rp 代表物品 p \mathfrak{p} p 得到所有评分的平均分。
最终结果的排序
在获得 Top n n n 相似用户之后,利用 Top n n n 用户生成最终推荐结果的过程如下。最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测。
R u , p = ∑ s ϵ S ( w u , s ⋅ R s , p ) ∑ s ϵ S w u , s R_{\mathbf{u},\mathbf{p}}=\frac{\sum_{s\epsilon S}(w_{\mathbf{u},s}\cdot R_{s,\mathbf{p}})}{\sum_{s\epsilon S}w_{\mathbf{u},s}} Ru,p=∑sϵSwu,s∑sϵS(wu,s⋅Rs,p)
其中,权重 w u , s w_{\mathfrak{u},s} wu,s 是用户 u \mathbf{u} u 和用户s的相似度, R s , p R_{s,{\mathfrak{p}}} Rs,p 是用户s对物品p的评分。
在获得用户 u \mathbf{u} u 对不同物品的评价预测后,最终的推荐列表根据预测得分进行排序即可得到。至此,完成协同过滤的全部推荐过程。
以上介绍的协同过滤算法基于用户相似度进行推荐,因此也被称为基于用户的协同过滤(UserCF),它符合人们直觉上的“兴趣相似的朋友喜欢的物品,我也喜欢”的思想,但从技术的角度,它也存在一些缺点,主要包括以下两点。
(1)在互联网应用的场景下,用户数往往远大于物品数,而UserCF需要维护用户相似度矩阵以便快速找出Top n n n 相似用户。该用户相似度矩阵的存储开销非常大,而且随着业务的发展,用户数的增长会导致用户相似度矩阵的空间复杂度以 n 2 n^{2} n2 的速度快速增长,这是在线存储系统难以承受的扩展速度。
(2)用户的历史数据向量往往非常稀疏,对于只有几次购买或者点击行为的用户来说,找到相似用户的准确度是非常低的,这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预定、大件商品购买等低频应用)。
基于物品相似度进行推荐的协同过滤算法 ItemCF
通过计算共现矩阵中物品列向量的相似度得到物品之间的相似矩阵,再找到用户的历史正反馈物品的相似物品进行进一步排序和推荐,ItemCF的具体步骤如下:
(1)基于历史数据,构建以用户(假设用户总数为
m
m
m )为行坐标,物品(物品总数为
n
n
n )为列坐标的
m
×
n
{m\times n}
m×n 维的共现矩阵。
(2)计算共现矩阵两两列向量间的相似性(相似度的计算方式与用户相似度的计算方式相同),构建
n
×
n
{n\times n}
n×n 维的物品相似度矩阵。
(3)获得用户历史行为数据中的正反馈物品列表。
(4)利用物品相似度矩阵,针对目标用户历史行为中的正反馈物品,找出相似的Top k k k 个物品,组成相似物品集合。
(5)对相似物品集合中的物品,利用相似度分值进行排序,生成最终的推荐列表。
在第5步中,如果一个物品与多个用户行为历史中的正反馈物品相似,那么该物品最终的相似度应该是多个相似度的累加,如(式2-5)所示。
R u , p = ∑ h ∈ H ( w p , h ⋅ R u , h ) R_{\mathrm{u,p}}=\sum_{\mathbf{h}\in H}(w_{\mathbf{p},\mathbf{h}}\cdot R_{\mathrm{u,h}}) Ru,p=h∈H∑(wp,h⋅Ru,h)
其中, H H H 是目标用户的正反馈物品集合, w p , h w_{\mathsf{p,h}} wp,h 是物品 p \mathtt{p} p 与物品h的物品相似度, R u , h R_{\mathfrak{u},\mathfrak{h}} Ru,h 是用户 u \mathbf{u} u 对物品h的已有评分。
UserCF & ItemCF
由于UserCF基于用户相似度进行推荐,使其具备更强的社交特性,用户能够快速得知与自己兴趣相似的人最近喜欢的是什么,即使某个兴趣点以前不在自己的兴趣范围内,也有可能通过“朋友”的动态快速更新自己的推荐列表。这样的特点使其非常适用于新闻推荐场景。
ItemCF更适用于兴趣变化较为稳定的应用,比如在Amazon的电商场景中,用户在一个时间段内更倾向于寻找一类商品,这时利用物品相似度为其推荐相关物品是契合用户动机的。在Netflix的视频推荐场景中,用户观看电影、电视剧的兴趣点往往比较稳定,因此利用ItemCF推荐风格、类型相似的视频是更合理的选择。
2.矩阵分解算法协同过滤
协同过滤是一个非常直观、可解释性很强的模型,但它并不具备较强的泛化能力。换句话说,协同过滤无法将两个物品相似这一信息推厂到其他物品的相似性计算上。热门的物品具有很强的头部效应.容易跟大量物品产生相似性:而尾部的物品由于特征向量稀疏,很少与其他物品产生相似性,导致很少被推荐。
矩阵分解在协同过滤算法中“共现矩阵”的基础上,加人了隐向量的概念,加强了模型处理稀疏矩阵的能力,针对性地解决了协同过滤存在的主要问题。
- 协同过滤算法找到用户可能喜欢的视频的方式很直接,即基于用户的观看历史,找到跟目标用户Joe看过同样视频的相似用户,然后找到这些相似用户喜欢看的其他视频,推荐给目标用户Joe。
- 矩阵分解算法则期望为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上,距离相近的用户和视频表明兴趣特点接近,在推荐过程中,就应该把距离相近的视频推荐给目标用户。
在“矩阵分解”的算法框架下,用户和物品的隐向量是通过分解协同过滤生成的共现矩阵得到的:
矩阵分解算法将 m × n m\times n m×n 维的共现矩阵 R \pmb{R} R 分解为 m × k m\times k m×k 维的用户矩阵 U \pmb{U} U 和 k × n k\times n k×n 维的物品矩阵 V V V 相乘的形式。其中 m m m 是用户数量, n n n 是物品数量, k k k 是隐向量的维度。 k k k 的大小决定了隐向量表达能力的强弱。
矩阵分解的求解过程
对矩阵进行矩阵分解的主要方法有三种:特征值分解(EigenDecomposition)奇异值分解(Singular Value Decomposition,SVD)和梯度下降(GradientDescent)。其中,特征值分解只能作用于方阵,显然不适用于分解用户-物品矩阵。
奇异值分解
假设矩阵 M M M 是一个 m × n m\,\times\,n m×n 的矩阵,则一定存在一个分解 M = U Σ V T \pmb{M}=\pmb{U}\pmb{\Sigma}\pmb{V}^{\mathrm{T}} M=UΣVT ,其中 U \boldsymbol{U} U 是 m × m m\times m m×m 的正交矩阵, V V V 是 n × n n\times n n×n 的正交矩阵, Σ \pmb{\Sigma} Σ 是 m × n m\times n m×n 的对角阵。
奇异值分解要求原始的共现矩阵是稠密的,但互联网场景下大部分用户的行为历史非常少,用户-物品的共现矩阵非常稀疏。传统奇异值分解的计算复杂度达到了 O ( m n 2 ) O(mn^2) O(mn2)的级别,这对于数据量极大的互联网场景几乎不可接受。
梯度下降法
基于用户矩阵
U
\boldsymbol{U}
U 和物品矩阵
V
V
V ,用户
u
u
u对物品
i
i
i的预估评分
r
^
m
i
=
q
i
T
p
u
\hat{\pmb{r}}_{\mathrm{mi}}=\pmb{q}_{\mathrm{i}}^{\mathrm{T}}\pmb{p}_{\mathrm{u}}
r^mi=qiTpu
其中 p u \pmb{p_{\mathrm{u}}} pu 是用户 u u u在用户矩阵 U \boldsymbol{U} U 中的对应行向量, q i \pmb q_{\mathrm{i}} qi 是物品 i i i在物品矩阵 V V V 中的对应列向量。
该目标函数的目的是让原始评分
r
u
i
r_{\mathrm{{ui}}}
rui 与用户向量和物品向量之积
q
i
T
p
u
\pmb{q}_{\mathrm{i}}^{\mathrm{T}}\pmb{p}_{\mathrm{u}}
qiTpu 的差尽量小,这样才能最大限度地保存共现矩阵的原始信息。
min
q
∗
,
p
∗
(
u
,
i
)
∈
K
(
r
u
i
−
q
i
T
p
u
)
2
\operatorname*{min}_{\substack{\pmb q^{*},\pmb p^{*}\,(\mathrm{u},\mathrm{i})\in\cal K}}\left(\pmb{r}_{\mathrm{u}\mathrm{i}}-\pmb q_{\mathrm{i}}^{\mathrm{T}}\pmb{p}_{\mathrm{u}}\right)^{2}
q∗,p∗(u,i)∈Kmin(rui−qiTpu)2
其中 K K K 是所有用户评分样本的集合。为了减少过拟合现象,加人正则化项后的目标函数如(式2-8)所示。
min q ∗ , p ∗ ( u , i ) ∈ K ( r u i − q i T p u ) 2 + λ ( ∥ q i ∥ + ∥ p u ∥ ) 2 \operatorname*{min}_{\substack{\pmb{q}^{*},\pmb{p}^{*}\,(\mathrm{u},\mathrm{i})\in K}}\left(\pmb{r}_{\mathrm{u}\mathrm{i}}-\pmb{q}_{\mathrm{i}}^{\mathrm{T}}\pmb{p}_{\mathrm{u}}\right)^{2}+\lambda(\|\pmb{q}_{\mathrm{i}}\|+\|\pmb{p}_{\mathrm{u}}\|)^{2} q∗,p∗(u,i)∈Kmin(rui−qiTpu)2+λ(∥qi∥+∥pu∥)2
在完成矩阵分解过程后,即可得到所有用户和物品的隐向量。在对某用户进行推荐时,可利用该用户的隐向量与所有物品的隐向量进行逐一的内积运算,得出该用户对所有物品的评分预测,再依次进行排序,得到最终的推荐列表。
隐向量其实是利用全局信息生成的,有更强的泛化能力。
消除用户和物品打分的偏差
由于不同用户的打分体系不同,为了消除用户和物品打分的偏差(Bias),常用的做法是在矩阵分解时加人用户和物品的偏差向量。
r
u
l
=
μ
+
b
i
+
b
u
+
q
i
T
p
u
\pmb{r}_{\mathrm{ul}}=\mu+b_{\mathrm{i}}+b_{\mathrm{u}}+\pmb{q}_{\mathrm{i}}^{\mathrm{T}}\pmb{p}_{\mathrm{u}}
rul=μ+bi+bu+qiTpu
其中
μ
\mu
μ 是全局偏差常数,
b
i
b_{\mathrm{i}}
bi 是物品偏差系数,可使用物品i收到的所有评分的均值,
b
u
b_{\mathbf{u}}
bu 是用户偏差系数,可使用用户u给出的所有评分的均值。
与此同时,矩阵分解目标函数也需要做相应改变:
min
q
∗
,
p
∗
,
b
∗
(
u
,
i
)
∈
K
(
r
u
i
−
μ
−
b
u
−
b
i
−
p
u
⊤
q
i
)
2
+
λ
(
∥
p
u
∥
2
+
∥
q
i
∥
2
+
b
u
2
+
b
i
2
)
\operatorname*{min}_{\substack{q^{*},p^{*},b^{*}\,(\mathrm{u},\mathrm{i})\in K}}(r_{\mathrm{u}\mathrm{i}}-\mu-b_{\mathrm{u}}-b_{\mathrm{i}}-p_{\mathrm{u}}^{\top}q_{\mathrm{i}})^{2}+\lambda(\Vert p_{\mathrm{u}}\Vert^{2}+\Vert q_{\mathrm{i}}\Vert^{2}+b_{\mathrm{u}}^{2}+b_{\mathrm{i}}^{2})
q∗,p∗,b∗(u,i)∈Kmin(rui−μ−bu−bi−pu⊤qi)2+λ(∥pu∥2+∥qi∥2+bu2+bi2)
同理,矩阵分解的求解过程会随看目标函数的改变而变化,主要区别在于利用新的目标函数,通过求导得出新的梯度下降公式。
矩阵分解的优点和局限性
相比协同过滤,矩阵分解有如下非常明显的优点。
(1)泛化能力强。在一定程度上解决了数据稀疏问题。
(2)空间复杂度低。不需再存储协同过滤模型服务阶段所需的“庞大”的用户相似性或物品相似性矩阵,只需存储用户和物品隐向量。空间复杂度由
n
2
n^{2}
n2 级别降低到
(
n
+
m
)
⋅
k
(n+m)\cdot k
(n+m)⋅k 级别。
(3)更好的扩展性和灵活性。矩阵分解的最终产出是用户和物品隐向量,这其实与深度学习中的Embedding思想不谋而合,因此矩阵分解的结果也非常便于与其他特征进行组合和拼接,并便于与深度学习网络进行无缝结合。
与此同时,也要意识到矩阵分解的局限性。与协同过滤一样,矩阵分解同样不方便加人用户、物品和上下文相关的特征,这使得矩阵分解丧失了利用很多有效信息的机会,同时在缺乏用户历史行为时,无法进行有效的推荐。
3.逻辑回归——融合多种特征的推荐模型
相比协同过滤模型仅利用用户与物品的相互行为信息进行推荐,逻辑回归模型能够综合利用用户、物品、上下文等多种不同的特征,生成较为“全面”的推荐结果。
相比协同过滤和矩阵分解利用用户和物品的“相似度”进行推荐,逻辑回归将推荐问题看成一个分类问题,通过预测正样本的概率对物品进行排序。因此,逻辑回归模型将推荐问题转换成了一个点击率(Click Through Rate,CTR)预估问题。
(1)将用户年龄、性别、物品属性、物品描述、当前时间、当前地点等特征转换成数值型特征向量。
(2)确定逻辑回归模型的优化目标(以优化“点击率”为例),利用已有样本数据对逻辑回归模型进行训练,确定逻辑回归模型的内部参数。
(3)在模型服务阶段,将特征向量输入逻辑回归模型,经过逻辑回归模型的推断,得到用户“点击”(这里用点击作为推荐系统正反馈行为的例子)物品的概率。
(4)利用“点击”概率对所有候选物品进行排序,得到推荐列表。
基于逻辑回归的推荐过程的重点在于,利用样本的特征向量进行模型训练和在线推断。
逻辑回归模型整个推断过程的数学形式:
f ( x ) = 1 1 + e − ( w ⋅ x + b ) f(x)={\frac{1}{1+\mathrm{e}^{-(w\cdot x+b)}}} f(x)=1+e−(w⋅x+b)1
对于标准的逻辑回归模型来说,要确定的参数就是特征向量相应的权重问量 w \pmb{w} w ,下面介绍逻辑回归模型的权重向量 w \pmb{w} w 的训练方法。
逻辑回归模型常用的训练方法是梯度下降法、牛顿法、拟牛顿法等,其中梯度下降法是应用最广泛的训练方法,也是学习深度学习各种训练方法的基础。
逻辑回归模型局限性
逻辑回归作为一个基础模型,显然有其简单、直观、易用的特点。但其局限性也是非常明显的:表达能力不强,无法进行特征交叉、特征筛选等一系列较为“高级”的操作,因此不可避免地造成信息的损失。为解决这一问题,推荐模型朝着复杂化的方向继续发展,衍生出因子分解机等高维的复杂模型。在进人深度学习时代之后,多层神经网络强大的表达能力可以完全替代逻辑回归模型,让它逐渐从各公司退役。各公司也将转而投人深度学习模型的应用浪潮之中。
4.从FM到FFM——自动特征交叉的解决方案
逻辑回归模型表达能力不强的问题,会不可避免地造成有效信息的损失。在仅利用单一特征而非交叉特征进行判断的情况下,有时不仅是信息损失的问题,甚至会得出错误的结论。著名的“辛普森论”用一个非常简单的例子,说明了进行多维度特征交叉的重要性。
辛普森论 :在对样本集合进行分组研究时,在分组比较中都占优势的一方,在总评中有时反而是失势的一方。
POLY2模型——特征交叉的开始
POLY2模型的数学形式如(式2-20)所示。
∅ P O L Y 2 ( w , x ) = ∑ j 1 = 1 n ∑ j 2 = j 1 + 1 n w h ( j 1 , j 2 ) x j 1 x j 2 \varnothing\mathrm{POLY2}(w,x)=\sum_{j_{1}=1}^{n}\sum_{j_{2}=j_{1}+1}^{n}w_{h(j_{1},j_{2})}x_{j_{1}}\,x_{j_{2}} ∅POLY2(w,x)=j1=1∑nj2=j1+1∑nwh(j1,j2)xj1xj2
可以看到,该模型对所有特征进行了两两交叉(特征 x j 1 x_{j_{1}} xj1 和 x j 2 x_{j_{2}} xj2 ),并对所有的特征组合赋予权重 w h ( j 1 , j 2 ) w_{h(j_{1},j_{2})} wh(j1,j2) 。POLY2通过暴力组合特征的方式,在一定程度上解决了特征组合的问题。POLY2模型本质上仍是线性模型,其训练方法与逻辑回归并无区别,因此便于工程上的兼容。
POLY2模型存在两个较大的缺陷。
(1)在处理互联网数据时,经常采用one-hot编码的方法处理类别型数据,致使特征向量极度稀疏,POLY2进行无选择的特征交叉一原本就非常稀疏的特征向量更加稀疏,导致大部分交叉特征的权重缺乏有效的数据进行训练,无法收敛。
(2)权重参数的数量由 n n n 直接上升到 n 2 n^{2} n2 ,极大地增加了训练复杂度。
FM模型——隐向量特征交叉
与POLY2相比,其主要区别是用两个向量的内积 ( w j 1 ⋅ w j 2 ) \left(\pmb{w}_{j_{1}}\cdot\pmb{w}_{j_{2}}\right) (wj1⋅wj2) 取代了单一的权重系数 w h ( j 1 , j 2 ) \boldsymbol{w}_{h(j_{1},j_{2})} wh(j1,j2) 。具体地说,FM为每个特征学习了一个隐权重向量(latentvector)。在特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重。
∅ F M ( w , x ) = ∑ j 1 = 1 n ∑ j 2 = j 1 + 1 n ( w j 1 ⋅ w j 2 ) x j 1 x j 2 \varnothing\mathrm{FM}(w,x)=\sum_{j_{1}=1}^{n}\sum_{j_{2}=j_{1}+1}^{n}\big(w_{j_{1}}\cdot w_{j_{2}}\big)x_{j_{1}}\,x_{j_{2}} ∅FM(w,x)=j1=1∑nj2=j1+1∑n(wj1⋅wj2)xj1xj2
本质上,FM引人隐向量的做法,与矩阵分解用隐向量代表用户和物品的做法异曲同工。可以说,FM是将矩阵分解隐向量的思想进行了进一步扩展,从单纯的用户、物品隐向量扩展到了所有特征上。
FM通过引人特征隐向量的方式,直接把POLY2模型
n
2
n^{2}
n2 级别的权重参数数量减少到了
n
k
nk
nk(
k
k
k 为隐向量维度,
n
>
>
k
n{>>}k
n>>k )。在使用梯度下降法进行FM训练的过程中,FM的训练复杂度同样可被降低到
n
k
n k
nk 级别,极大地降低了训练开销。
比如在某商品推荐的场景下,样本有两个特征,分别是频道(channel)和品牌(brand),某训练样本的特征组合是(ESPN,Adidas)。在POLY2中,ESPN Adidas出现在一个训练样本中时,模型才能学到这个组合特征对应的权重;而在FM中,ESPN的隐向量也可以通过(ESPN,Gucci)样本进行更新,Adidas的隐向量也可以通过(NBC,Adidas)样本进行更新,这大幅降低了模型对数据稀疏性的要求。
FFM模型——引入特征域的概念
相比FM模型,FFM模型引人了特征域感知(field-aware)这一概念,使模型的表达能力更强。
∅ F F M ( w , x ) = ∑ j 1 = 1 n ∑ j 2 = j 1 + 1 n ( w j 1 , f 2 ⋅ w j 2 , f 1 ) x j 1 x j 2 \varnothing\mathrm{FFM}(w,x)=\sum_{j_{1}=1}^{n}\sum_{j_{2}=j_{1}+1}^{n}\big(w_{j_{1},f_{2}}\cdot w_{j_{2},f_{1}}\big)x_{j_{1}}\,x_{j_{2}} ∅FFM(w,x)=j1=1∑nj2=j1+1∑n(wj1,f2⋅wj2,f1)xj1xj2
这是FFM的数学形式的二阶部分。其与FM的区别在于隐向量由原来的 w j 1 \pmb{w}_{j_{1}} wj1 变成了 w j 1 , f 2 \pmb{w}_{j_{1},f_{2}} wj1,f2 ,这意味着每个特征对应的不是唯一一个隐向量,而是一组隐向量。当 x j 1 \pmb{x}_{j_{1}} xj1 特征与 x j 2 \pmb{x}_{j_{2}} xj2 特征进行交叉时, x j 1 \pmb{x}_{j_{1}} xj1 特征会从 x j 1 \pmb{x}_{j_{1}} xj1 的这一组隐向量中挑出与特征 x j 2 \pmb{x}_{j_{2}} xj2 的域 f 2 f_{2} f2 对应的隐向量 w j 1 , f 2 \pmb{w}_{j_{1},f_{2}} wj1,f2 进行交叉。同理, x j 2 \pmb{x}_{j_{2}} xj2 也会用与 x j 1 \pmb{x}_{j_{1}} xj1 的域 f 1 f_{1} f1 对应的隐向量进行交叉。
ESPN、NIKE、Male分别是这三个特征域Publisher§、Advertiser(A)、Gender(G)的特征值(还需要转换成one-hot特征)
如果按照FM的原理,特征ESPN、NIKE和Male都有对应的隐向量 w E S P M , w N I K E , w M a l e \pmb{w}_{\mathrm{ESPM}},\pmb{w}_{\mathrm{N I K E}},\pmb{w}_{\mathrm{Male}} wESPM,wNIKE,wMale ,ESPN NIKE、ESPN Male叉的权重应该是 w E S P N ⋅ w N I K E {\pmb w}_{\tt E S P N}\cdot{\pmb w}_{\tt N I K E} wESPN⋅wNIKE 和 w E S P N ⋅ w M a l e \pmb{w}_{\mathtt{E S P N}}\cdot\pmb{w}_{\mathtt{M a l e}} wESPN⋅wMale 。其中,ESPN对应的隐向量WESPN在两次特征交叉过程中是不变的。
而在 FFM 中,ESPN 与 NIKE、ESPN 与 Male 交叉特殊的权重分别是 w E S P N , A ⋅ w N I K E , P {\pmb w}_{\tt E S P N, A}\cdot{\pmb w}_{\tt N I K E,P} wESPN,A⋅wNIKE,P 和 w E S P N , G ⋅ w M a l e , P \pmb{w}_{\mathtt{E S P N,G}}\cdot\pmb{w}_{\mathtt{M a l e,P}} wESPN,G⋅wMale,P
在FFM模型的训练过程中,需要学习 n n n 个特征在 f f f 个域上的 k k k 维隐向量,参数数量共 n ⋅ k ⋅ f n\cdot k\cdot f n⋅k⋅f 个。在训练方面,FFM的二次项并不能像FM那样简化,因此其复杂度为 k n 2 k n^{2} kn2 。
相比FM,FFM引入了特征域的概念,为模型引人了更多有价值的信息,使模型的表达能力更强,但与此同时,FFM的计算复杂度上升到 k n 2 k n^{2} kn2 ,远大于FM的 k n {k n} kn 。在实际工程应用中,需要在模型效果和工程投人之间进行权衡。
5.GBDT+LR——特征工程模型化的开端
FFM模型采用引入特征域的方式增强了模型的特征交叉能力,但无论如何,FFM只能做二阶的特征交叉,如果继续提高特征交叉的维度,会不可避免地产生组合爆炸和计算复杂度过高的问题。
Facebook提出了一种利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作LR模型输入,预估CTR的模型结构。

需要强调的是,用GBDT构建特征工程,利用LR预估CTR这两步是独立训练的,所以不存在如何将LR的梯度回传到GBDT这类复杂的问题。
什么是 GBDT 模型
GBDT的基本结构是决策树组成的树林,学习的方式是梯度提升。

具体地讲,GBDT作为集成模型,预测的方式是把所有子树的结果加起来。
D
(
x
)
=
d
t
r
e
e
1
(
x
)
+
d
t
r
e
e
2
(
x
)
+
⋯
D(x)=d_{\mathrm{tree\,}1}(x)+d_{\mathrm{tree\,}2}(x)+\cdots
D(x)=dtree1(x)+dtree2(x)+⋯
GBDT通过逐一生成决策子树的方式生成整个树林,生成新子树的过程是利用样本标签值与当前树林预测值之间的残差,构建新的子树。
假设当前已经生成了3棵子树,则当前的预测值为
D ( x ) = d t r e e 1 ( x ) + d t r e e 2 ( x ) + d t r e e 3 ( x ) D(x)=d_{\mathrm{tree\,}1}(x)+d_{\mathrm{tree\,}2}(x)+d_{\mathrm{tree\,}3}(x) D(x)=dtree1(x)+dtree2(x)+dtree3(x)
GBDT期望的是构建第4棵子树,使当前树林的预测结果 D ( x ) D(x) D(x) 与第4棵子树的预测结果 d t r e e 4 ( x ) d_{\mathsf{t r e e4}}(x) dtree4(x) 之和,能进一步逼近理论上的拟合函数 f ( x ) f(x) f(x) ,即
D ( x ) + d t r e e 4 ( x ) = f ( x ) D(x)+d_{\mathsf{t r e e}\,4}(x)=f(x) D(x)+dtree4(x)=f(x)
所以,第4棵子树生成的过程是以目标拟合函数和已有树林预测结果的残差 R ( x ) R(x) R(x) 为目标的:
R ( x ) = f ( x ) − D ( x ) R(x)=f(x)-D(x) R(x)=f(x)−D(x)
理论上,如果可以无限生成决策树,那么GBDT可以无限逼近由所有训练集样本组成的目标拟合函数,从而达到减小预测误差的目的。
GBDT 进行特征转换的过程
利用训练集训练好GBDT模型之后,就可以利用该模型完成从原始特征向量到新的离散型特征向量的转化。

GBDT容易产生过拟合,以及GBDT的特征转换方式实际上丢失了大量特征的数值信息,因此不能简单地说GBDT的特征交叉能力强,效果就比FFM好,在模型的选择和调试上,永远都是多种因素综合作用的结果。
GBDT+LR组合模型的提出,意味着特征工程可以完全交由一个独立的模型来完成,模型的输人可以是原始的特征向量,不必在特征工程上投人过多的人工筛选和模型设计的精力,实现真正的**端到端(EndtoEnd)**训练。
广义上讲,深度学习模型通过各类网络结构、Embedding 层等方法完成特征工程的自动化,都是 GBDT+LR 开启的特征工程模型化这一趋势的延续。
6.LS-PLM-阿里巴巴曾经的主流推荐模型
“大规模分段线性模型”(Large Scale Piece-wise Linear Mode)。LS-PLM 的结构与三层神经网络极其相似,在深度学习来临的前夜,可以将它看作推荐系统领域连接两个时代的节点。
1LS-PLM
LS-PLM,又被称为 MLR(Mixed Logistic Regression,混合逻辑回归)模型。本质上,LS-PLM 可以看作对逻辑回归的自然推广,它在逻辑回归的基础上采用分而治之的思路,先对样本进行分片,再在样本分片中应用逻辑回归进行 CTR 预估。
为了让CTR模型对不同用户群体、不同使用场景更有针对性,其采用的方法是先对全量样本进行聚类,再对每个分类施以逻辑回归模型进行CTR预估。LS-PLM的实现思路就是由该灵感产生的。
LS-PLM的数学形式如下所示,首先用聚类函数
π
\pi
π 对样本进行分类(这里的
π
\pi
π 采用了 softmax 函数对样本进行多分类),再用LR模型计算样本在分片中具体的CTR,然后将二者相乘后求和。
f
(
x
)
=
∑
i
=
1
m
π
i
(
x
)
⋅
η
i
(
x
)
=
∑
i
=
1
m
e
μ
i
⋅
x
∑
j
=
1
m
e
μ
j
⋅
x
⋅
1
1
+
e
−
w
i
⋅
x
f(x)=\sum_{i=1}^{m}\pi_{i}\left(x\right)\cdot\eta_{i}(x)=\sum_{i=1}^{m}\frac{\mathrm{e}^{\mu_{i}\cdot x}}{\sum_{j=1}^{m}\mathrm{e}^{\mu_{j}\cdot x}}\cdot\frac{1}{1+\mathrm{e}^{-w_{i}\cdot x}}
f(x)=i=1∑mπi(x)⋅ηi(x)=i=1∑m∑j=1meμj⋅xeμi⋅x⋅1+e−wi⋅x1
其中的超参数“分片数” m m m 可以较好地平衡模型的拟合与推广能力。当 m = 1 _{m=1} m=1 时,LS-PLM就退化为普通的逻辑回归。 m m m 越大,模型的拟合能力越强。与此同时,模型参数规模也随 m m m 的增大而线性增长,模型收敛所需的训练样本也随之增 长。在实践中,阿里巴巴给出的 m m m 的经验值为12。
LS-PLM模型适用于工业级的推荐、广告等大规模稀疏数据的场景,主要是因为其具有以下两个优势。
(1)端到端的非线性学习能力:LS-PLM具有样本分片的能力,因此能够挖掘出数据中蕴藏的非线性模式,省去了大量的人工样本处理和特征工程的过程,使LS-PLM算法可以端到端地完成训练,便于用一个全局模型对不同应用领域、业务场景进行统一建模。
(2)模型的稀疏性强:LS-PLM在建模时引入了 L1(向量范数)和 L2,1(矩阵范数)范数,可以使最终训练出来的模型具有较高的稀疏度,使模型的部署更加轻量级。模型服务过程仅需使用权重非零特征,因此稀疏模型也使其在线推断的效率更高。
为什么L1范数比L2范数更容易产生稀疏解
这里用一个二维的例子来解释为什么L1范数更容易产生稀疏性。L2范数 ∣ w 1 ∣ 2 + ∣ w 2 ∣ 2 |\pmb{w}_{1}|^{2}{+}|\pmb{w}_{2}|^{2} ∣w1∣2+∣w2∣2 的曲线如图2-19(a)的红色圆形,L1范数 ∣ w 1 ∣ + ∣ w 2 ∣ |\pmb{w}_{1}|+|\pmb{w}_{2}| ∣w1∣+∣w2∣ 的曲线如图2-19(b)红色菱形。用蓝色曲线表示不加正则化项的模型损失函数曲线。
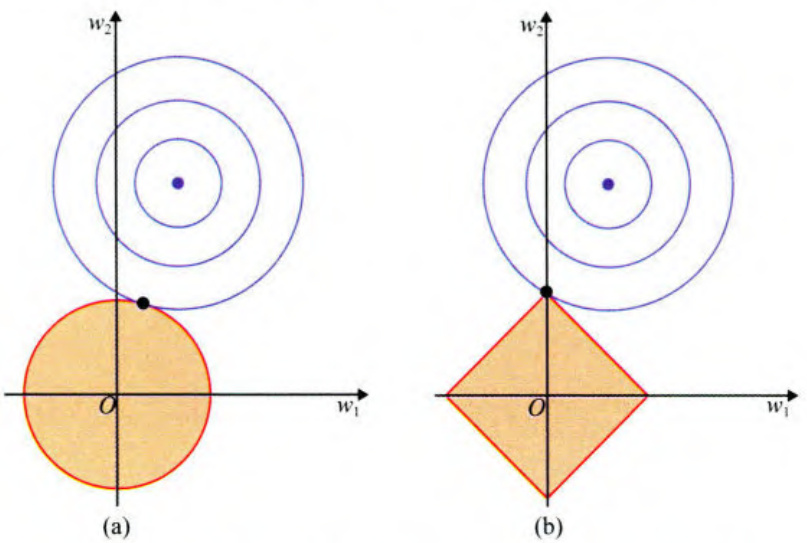
求解加人正则化项的损失函数最小值,就是求解红圈上某一点和蓝圈上某 一点之和的最小值。这个值通常在红色曲线和蓝色曲线的相切处(如果不在相切处,那么至少有两点值相同,与极值的定义矛盾),而L1范数曲线更容易与蓝色曲线在顶点处相交,这就导致除了相切处的维度不为零,其他维度的权重均为0,从而容易产生模型的稀疏解。
LS-PLM的深度学习思维
LS-PLM可以看作一个加人了注意力(Attention)机制的三层神经网络模型,其中输人层是样本的特征向量,中间层是由 m m m 个神经元组成的隐层,其中 m m m 是分片的个数,对于一个CTR预估问题,LS-PLM的最后一层自然是由单一神经元组成的输出层。
那么,注意力机制又是在哪里应用的呢?其实是在隐层和输出层之间,神经元之间的权重是由分片函数得出的注意力得分来确定的。也就是说,样本属于哪个分片的概率就是其注意力得分。
总结