本笔记使用的Vitis HLS版本为2022.2,在windows11下运行,仿真part为xcku15p_CIV-ffva1156-2LV-e,主要根据教程:跟Xilinx SAE 学HLS系列视频讲座-高亚军进行学习
学习笔记:《FPGA学习笔记》索引
FPGA学习笔记#1 HLS简介及相关概念
FPGA学习笔记#2 基本组件——CLB、SLICE、LUT、MUX、进位链、DRAM、存储单元、BRAM
FPGA学习笔记#3 Vitis HLS编程规范、数据类型、基本运算
FPGA学习笔记#4 Vitis HLS 入门的第一个工程
FPGA学习笔记#5 Vitis HLS For循环的优化(1)
FPGA学习笔记#6 Vitis HLS For循环的优化(2)
FPGA学习笔记#7 Vitis HLS 数组优化和函数优化
FPGA学习笔记#8 Vitis HLS优化总结和案例程序的优化
目录
- 1.循环优化中的基本参数
- 2.PIPELINE & UNROLL
- 2.1.PIPELINE
- 2.2.UNROLL
- 3.LOOP_MERGE
1.DATAFLOW
1.1.DATAFLOW的使用场景
当循环之间、函数之间、线程之间有顺序数据依赖,可以考虑使用DATAFLOW优化,考虑以下情况:
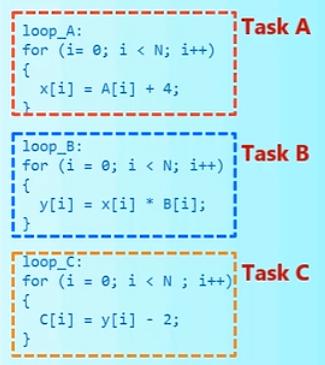
可以很明显地看出,B依赖A计算得到的x[i],C依赖B计算得到的y[i],三个任务形成了如图所示的关系:
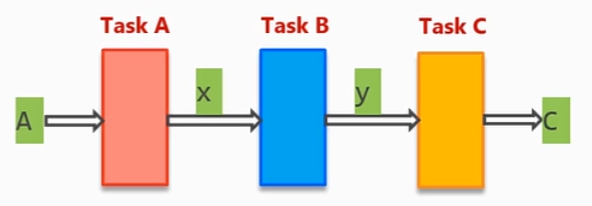
此时我们可以考虑使用DATAFLOW,作用于循环所在函数,对应配置为#pragma HLS DATAFLOW:
优化后,三个循环间的关系如图所示,循环之间使用管道、FIFO、寄存器等进行数据传输,每个Loop只需要每轮完成计算后将结果送入数据通道,即可开始下一轮计算,后一个Loop等待到通道传来数据就可以开始计算。
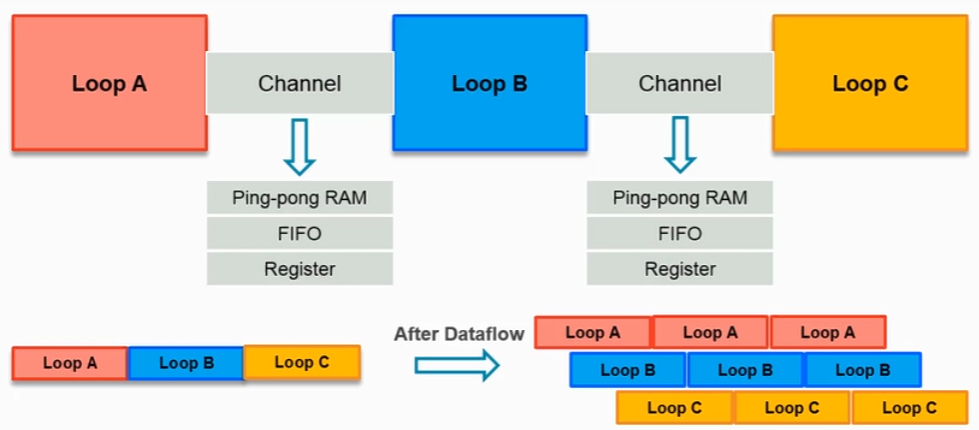
与PIPELINE的不同:
PIPELINE:对于一个循环内多个循环次数之间的优化
例如一个循环中每次循环涉及读-计算-写三步,则在操作间无依赖时可以进行流水线,让三个步骤都各自连续执行
DATAFLOW:对于循环间/函数间/线程间的优化
例如上方的Loop A-B-C,下一个Loop的输入是上一个Loop的输出,则DATAFLOW可以让三个循环都各自连续执行
1.2.DATAFLOW编程约定
1.2.1.Single-producer-consumer Model
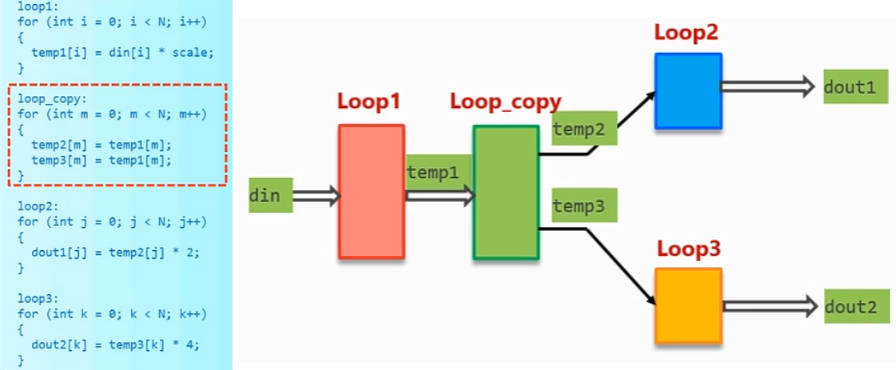
一个输出(write)对应一个输入(read),多个consumer依赖同一个producer时,DATAFLOW不成立,以如下代码为例,loop2和loop3同时使用了temp1的数据,如果是图中的情况,那么硬件层面上会产生读冲突,如果使用FIFO,那么temp1只能被读取一次。
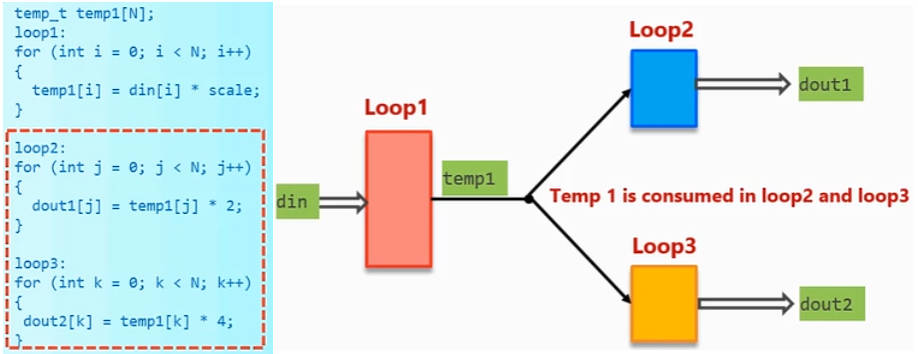
此时如果想启用DATAFLOW,那就需要添加一个中间件,其读取一个输入,并写到两个输出,如下图中的loop_copy循环:
1.2.2.Bypassing Tasks Model
Loop1输出temp1和temp2,Loop2读取temp1,输出temp3,Loop3读取temp2和temp3,这样也是不能启用DATAFLOW的:
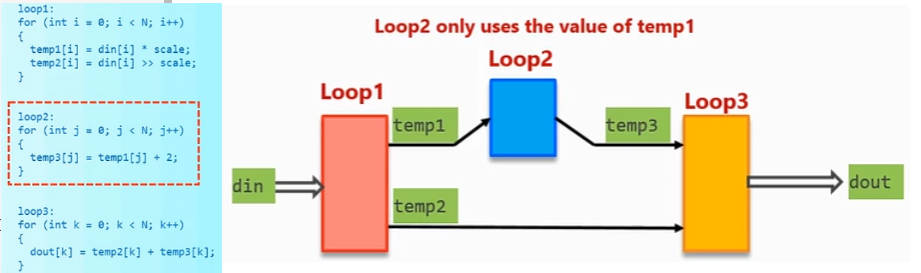
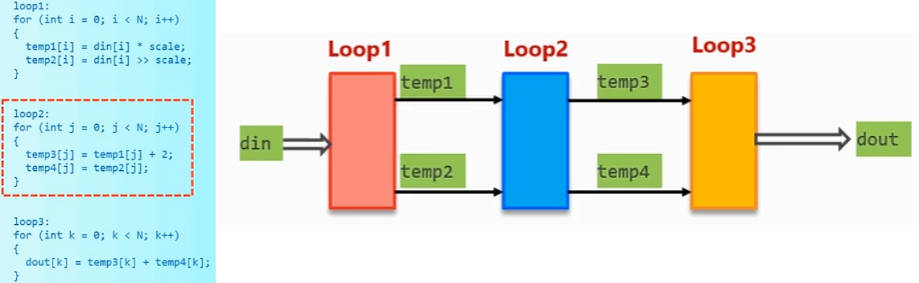
启用思路:在Loop2将Bypass的数据读取并复制一份。
2.嵌套For循环
2.1.嵌套For循环的优化逻辑
对于嵌套For循环,首先我们要确定什么样的For循环更适合被优化。
首先如下图所示,内外循环的循环上限均为固定值的循环为perfect loop,这是嵌套优化的最理想状况;内部上限为固定值,而外部为变量的为semi-perfect loop,这种情况也是可以优化的。
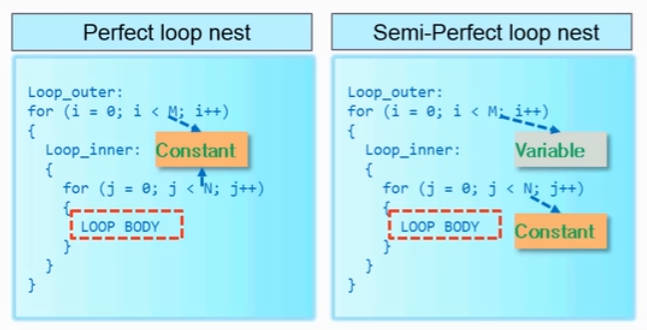
对于不理想的嵌套循环有两种,第一种是内外部上限均为固定值,但有语句写在循环之间的,如下图中的LOOP_BODY所处位置;第二种是内部上限为变量,外部为固定值的。这两种情况被称为imperfect loop。
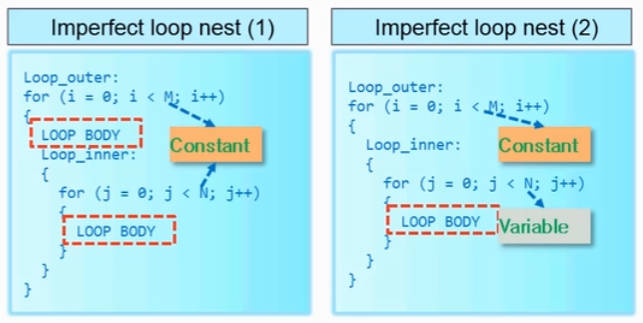
那么我们优化的流程就很明显了:perfect/semi-perfect loop就直接优化,imperfect loop就先尝试转变为perfect/semi-perfect loop,如果不能,再考虑直接对imperfect loop进行优化。
2.2.perfect/semi-perfect loop优化
对于可优化的嵌套循环,我们可以考虑对For循环进行PIPELINE优化,如下图为一个perfect loop

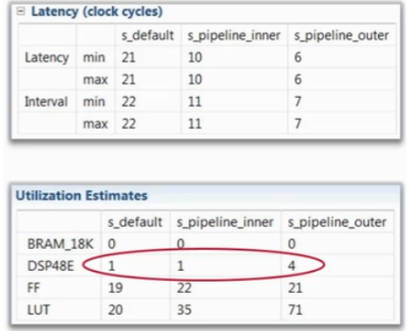
对嵌套循环的不同层进行PIPELINE优化存在差异,如下图是默认情况、给内层添加PIPELINE、给外层添加PIPELINE的结果。
给内层添加PIPELINE时,会进行FLATTEN操作,将外部循环2次执行4次内部循环展平为执行8次循环。
给外层添加PIPELINE时,会将内部所有循环进行UNROLL,然后统一进行PIPELINE,可以看到给外层添加PIPELINE时,乘法器使用了4个,共执行2次循环。
2.3.imperfect loop优化
如果想要优化的循环是任意一种形式的imperfect loop,那么我们最好先考虑将其转化为perfect/semi-perfect loop,如果无法转化,那么我们要知道直接优化会带来怎样的结果。
以下图所示的imperfect loop为例,在Col循环和Product循环之间多了一个res[i][j]=0的重置操作,这使得Col->Product是imperfect的。

2.3.1.最内层PIPELINE
首先,在最内层的Product打上PIPELINE。从debug信息,我们可以看到HLS会将外层Row展平,但因为Col->Product是imperfect的,所以Col无法执行Flatten。

最终可以看到Flatten之后,Row和Col展平为9次循环,然后每次循环执行Product循环:

2.3.2.中间层PIPELINE
然后,对Col层打PIPELINE。通过debug信息,可以看到HLS将内部所有循环做UNROLL,然后对本次与外层进行FLATTEN。

最终得到的结果是执行一个9次的循环,每次循环将Product的操作一轮执行完。

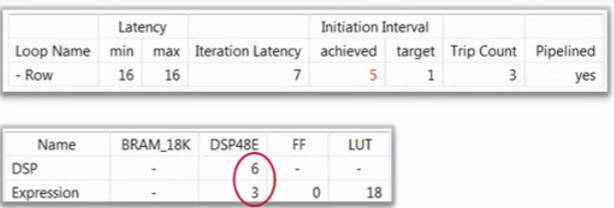
2.3.3.最外层PIPELINE
最后,对Row层打PIPELINE。通过debug信息,可以看到HLS将Row内部所有子循环都进行了UNROLL操作。

最终,函数会执行Row的三次循环,内部会将Col和Product的操作一次性执行完毕,消耗的乘法器变为9个。
2.3.4.对函数进PIPELINE
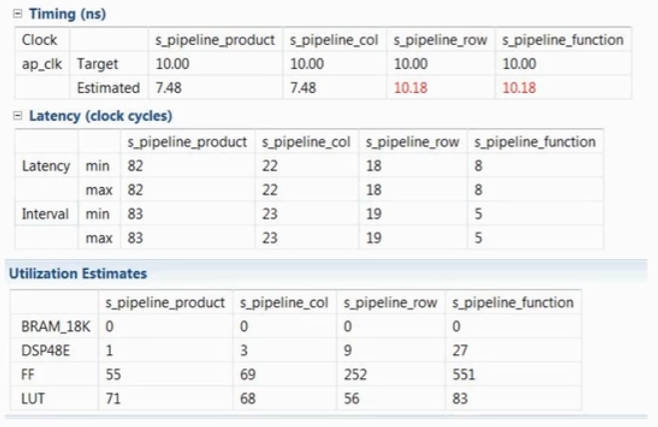
根据上面三次优化,很自然的可以想到再进一步将Row循环也UNROLL可以换取更高的效率,那么我们直接对其所在函数打PIPELINE,得到的DEBUG信息如下,三个循环都被UNROLL了:

2.3.5.优化结果
通过对比四次优化的结果,很明显PIPELINE越往外性能越高,但同时资源消耗也成倍上涨,对于任意循环打PIPELINE时,HLS会对其子循环进行UNROLL,对其外层非imperfect loop进行FLATTEN。
3.其他For优化
3.1.函数多次实例化
对于一个函数内多次调用另一个函数的情况,如下图,HLS默认会分时复用该函数,即串行执行。
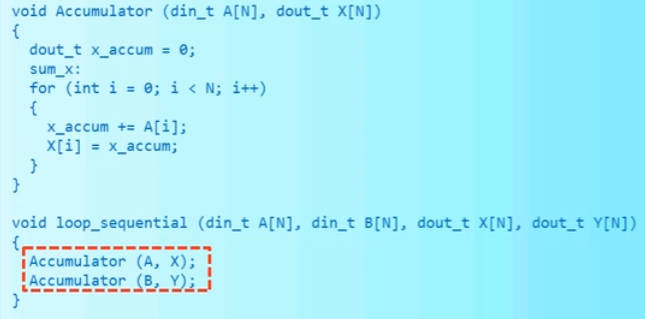
我们可以使用ALLOCATION约束,这个约束会增加函数的实例化数量,对loop_sequential添加directive如下,其中limit是最多实例化个数。
#pragma HLS ALLOCATION instances=Accumulator limit=2 function
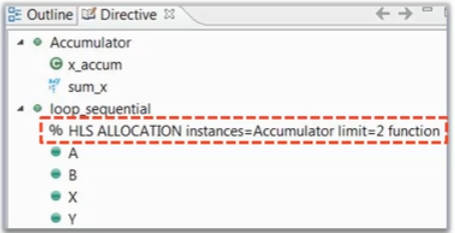
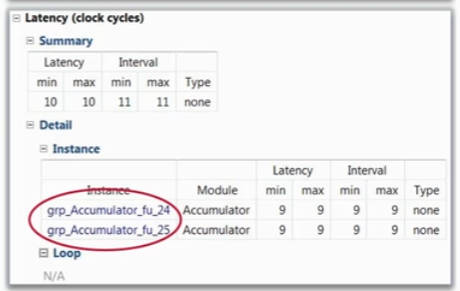
在生成信息中,我们可以看到HLS为该函数生成了两个实例。
3.2.循环之间的间隔
如下图,多次调用同一个函数,并且该函数只有一个循环时,循环之间会产生间隔,此时可以使用PIPELINE中的rewind参数:
#pragma HLS PIPELINE rewind
便可以将循环之间的间隔消除:
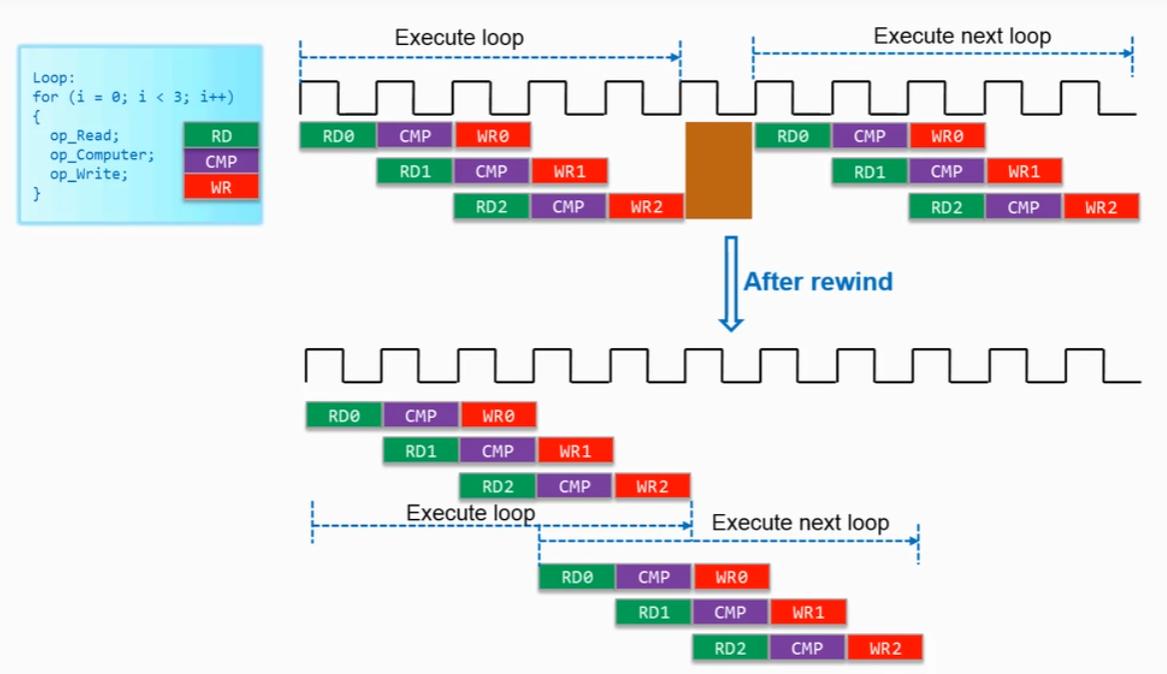
注意,一个函数包含多个Loop的情况下不能进行rewind优化
3.3.自动PIPELINE
在config_compile中配置,只要一个for循环的循环边界小于等于pipeline_loops配置的值,那么编译时就会HLS就会自动进行PIPELINE。
在启用自动PIPELINE时,如果某些符合条件但不想PIPELINE的,可以配置:
#pragma HLS PIPELINE off
3.3.Latency的确定
当循环边界是变量时,Vivado无法确定latency,设计的性能未知
此时可以采取以下方案:
1.使用trip count directive,不做优化,只用于报告的显示和比较
#pragma HLS LOOPTRIPCOUNT min=4 max=8 avg=6
2.定义循环边界为ap_int<>或ap_uint<>(在自减时要注意无符号)
3.使用断言assert
#include <assert.h>
assert(width < 5)