爬取评论
做分析首先得有数据,数据是核心,而且要准确!
1、爬虫必要步骤,选好框架
2、开发所需数据
3、最后测试流程
这里我所选框架是selenium+request,很多人觉得selenium慢,确实不快,仅针对此项目我做过测试,相对于request要快,要方便一些!也可以用你们熟悉的框架,用的趁手就行!
最核心的要采用无浏览器模式,这样会快很多
安装浏览器对应webdriver版本
http://npm.taobao.org/mirrors/chromedriver/
获取评论数,评级数, 监控评论
·亚马逊产品评论分为5个等级,从1到5
def get_review_summarys(self):
# 解析评论星级
def parse(site, asin, rating, html):
# 解析评论星级
selector = etree.HTML(html)
title = select(selector, "//a[@data-hook='product-link']/text()", 0, None)
if not title:
return site, asin, self.parent_asin, None, None, None, None
review_rating_count = select(selector, "//div[@data-hook='cr-filter-info-review-rating-count']/span/text()",0,
None)
if review_rating_count:
review_rating_count = [s.strip() for s in review_rating_count.split("|")]
rating_count = int(review_rating_count[0].split(" ")[0].replace(",", ""))
review_count = int(review_rating_count[1].split(" ")[0].replace(",", ""))
only_rating_count = rating_count - review_count
else:
rating_count = None
review_count = None
only_rating_count = None
print(site, asin, rating, rating_count, review_count, only_rating_count, sep="\t")
return site, asin, rating, rating_count, review_count, only_rating_count
self.review_summarys = []
run_successfully = 1
star_map = {1: "one_star", 2: "two_star", 3: "three_star", 4: "four_star", 5: "five_star"}
url_map = {"parent": "{}product-reviews/{}/?language={}&filterByStar={}&reviewerType=all_reviews"}
try:
for rating, star in star_map.items():
index_url = 'https://www.amazon.com/'
language = 'ref=cm_cr_arp_d_viewopt_sr?ie=UTF8'
url_format = url_map.get(self.parent_asin,"{}product-reviews/{}/?language={}&filterByStar={}&reviewerType=all_reviews&formatType=current_format")
self.re_url = url_format.format(index_url,self.asin, language, star)
res = requests.get(self.re_url, headers=headers).text
self.rating = rating
review_summary = parse(self.site, self.asin, self.rating,res)
self.review_summarys.append(review_summary)
except Exception as err:
print("请求中断:{}".format(err))
run_successfully = 0
finally:
return run_successfully, self.review_summarys
获取评论内容
def get_main_information(self):
# 等待页面加载完毕
while True:
try:
WebDriverWait(self.driver, 30).until(
EC.presence_of_element_located((By.ID, 'cm_cr-review_list'))
)
break
except Exception as e:
print(e)
self.driver.refresh()
continue
us = self.driver.find_element_by_id("cm_cr-review_list")
# 获取每页的全部评论信息
text = self.driver.page_source
selector = etree.HTML(text)
self.review_detail = []
try:
reviews = selector.xpath("//div[@data-hook='review']")
for review in reviews:
review_id = select(review, "./@id", 0, "")
customer = select(review, ".//span[@class='a-profile-name']/text()", 0, "")
review_title = select(review, ".//*[@data-hook='review-title']/span/text()", 0, "")
review_date = select(review, ".//span[contains(@*,'review-date')]/text()", 0, None)
if review_date:
li = re.findall("\d+.\d+.\d+.\d+.", review_date)[0]
yyyy = re.findall('\d\d\d\d',li)[0]
mm = re.findall('年(\d+)',li)[0]
dd = re.findall('月(\d+)',li)[0]
review_date = "{}-{}-{}".format(yyyy, mm, dd)
else:
review_date = None
verified_purchase = select(review, ".//span[@data-hook='avp-badge']/text()", 0, "")
review_body = select(review, ".//span[@data-hook='review-body']/span/text()")
review_rating = select(review, ".//i[contains(@data-hook, 'review-star-rating')]/span/text()", 0, "")
review_rating = int(float(review_rating.split(" ")[0].replace(",", "."))) if review_rating else None
review_href = select(review, ".//a[@class='a-link-normal']/@href", 0, "")
review_href = review_href if review_id in review_href else ""
index_url = 'https://www.amazon.com/'
review_url = index_url + review_href[1:] if review_href else ""
asin = re.findall('ASIN=(.*)',review_url)[0]
print(self.site,asin,self.product_name,review_id, customer, review_title, review_date,verified_purchase, review_body,
review_rating, review_url, sep="\n")
print("----------------------------------------------------------------------------------------------")
self.review_detail.append((self.site,asin,self.product_name,review_id, customer, review_title, review_date,verified_purchase,review_body,
review_rating, review_url))
except Exception as e:
print(e)
# 判断是否还有下一页next_page
try:
WebDriverWait(self.driver, 5).until(
EC.element_to_be_clickable((By.XPATH, '//li[@class = "a-last"]/a'))
)
self.next_page = us.find_element_by_xpath('.//li[@class = "a-last"]/a').get_attribute("href")
except NoSuchElementException:
self.driver.find_elements_by_xpath('//li[@class = "a-disabled a-last"]')
self.next_page = None
print("未有下一页")
except TimeoutException:
self.next_page = None
self.driver.refresh()
- 数据存储方式建议大家使用mysql,如果只是测试玩玩就用csv或者excel
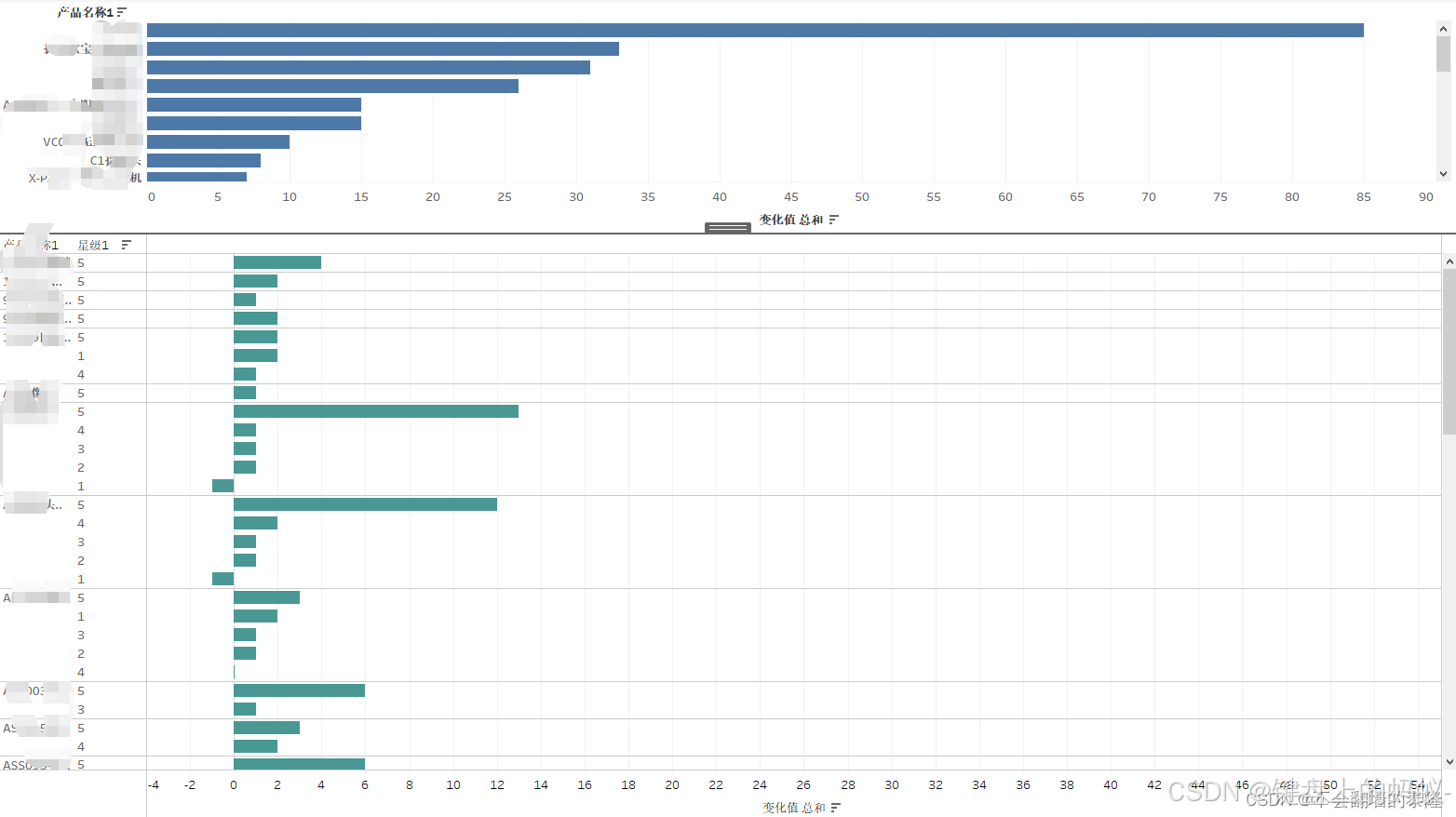
数据有了,下面我们开始分析,怎么分析呢?这里我用到是tableau-BI工具,要结合业务需求来选择工具,BI更适合公司开发业务,实现企业化!
1、每日星级变动分析:评论数,星级数
每天实时更新评级数,把爬虫放到服务器上写一个定时任务!
通过tableau展示可视化报表
2、评论监控
每日实时更新有变动的评论数,评级数
重新建表,把计算逻辑写到函数中,通过比对的方法实现变动

3、最后通过BI展示
定时任务
def get_ratings(h=7, m=30):
while True:
now = datetime.datetime.now()
# print(now.hour, now.minute)
if now.hour == h and now.minute == m:
spider_main()
# 每隔60秒检测一次
time.sleep(60)
if __name__ == '__main__':
# get_reviews()
get_ratings()
本文章若对你有帮助,烦请点赞,收藏,关注支持一下!
各位的支持和认可就是我最大的动力!