前言:Hello大家好,我是小哥谈。与传统的注意力机制相比,多尺度注意力机制引入了多个尺度的注意力权重,让模型能够更好地理解和处理复杂数据。这种机制通过在不同尺度上捕捉输入数据的特征,让模型同时关注局部细节和全局结构,以提高对细节和上下文信息的理解,达到提升模型的表达能力、泛化性、鲁棒性和定位精度,优化资源使用效率的效果。🌈
目录
🚀1.基础概念
🚀2.网络结构
🚀3.添加步骤
🚀4.改进方法
🍀🍀步骤1:创建EMA.py文件
🍀🍀步骤2:修改tasks.py文件
🍀🍀步骤3:创建自定义yaml文件
🍀🍀步骤4:新建train.py文件

🚀1.基础概念
这篇论文的作者旨在通过提出一种高效多尺度注意力模块 (Efficient Multi-Scale Attention Module, EMA) 来改进现有的注意力机制。他们的核心思想是:在不进行通道降维的情况下,通过分组和多尺度并行子网络来有效地捕捉全局和局部的空间依赖关系。此外,他们通过跨空间学习方法,将全局与局部特征进行融合,以提高像素级的配对关系捕捉能力,增强模型对复杂视觉任务(如图像分类和目标检测)的表现,同时保持较低的计算开销。这种设计不仅提高了模型的准确性,还提升了其计算效率。
创新点:
-
多尺度并行子网络设计:论文提出了多尺度的并行子网络结构,用于捕捉图像中的短程和长程依赖关系。这个设计使得模型可以在多个尺度上学习更丰富的特征表示。
-
通道维度的重组:与传统的通道降维方式不同,该方法通过将部分通道重组到批次维度中,避免了通道降维带来的信息损失,从而保持每个通道的完整信息。
-
跨空间学习方法:创新性地提出了跨空间学习方法,用来融合并行子网络的输出。该方法通过捕捉像素级的成对关系,强化了全局上下文信息的表达,有助于提升特征的聚合效果。
-
高效注意力机制:与CBAM、坐标注意力等其他注意力机制相比,EMA模块在使用较少参数的情况下,显著提高了图像分类和目标检测任务的性能,并降低了计算开销。
整体结构:
EMA模型通过将输入特征按通道维度分组,并采用两个并行分支:一个分支使用1D全局池化和1×1卷积处理全局信息,另一个分支使用3×3卷积捕捉局部空间信息。两分支的输出通过矩阵乘法融合,生成注意力图,并与输入特征结合,最终提升模型对全局和局部信息的捕捉能力,同时降低计算复杂度。


论文题目:《Efficient Multi-Scale Attention Module with Cross-Spatial Learning》
论文地址: https://arxiv.org/abs/2305.13563v2
代码实现: https://github.com/YOLOonMe/EMA-attention-module
🚀2.网络结构
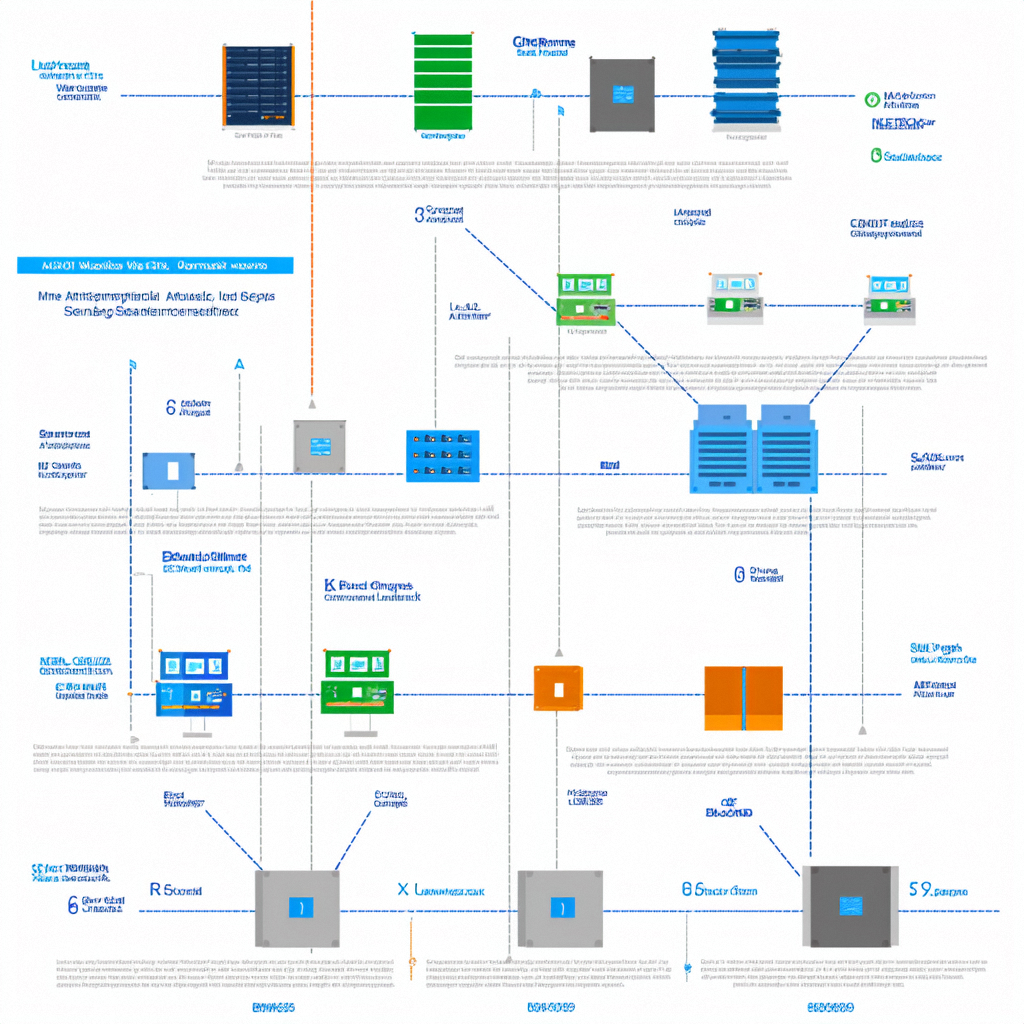
本文的改进是基于YOLO11,关于其网络结构具体如下图所示:

本文所做的改进是在YOLO11的网络结构中加入EMA注意力机制。关于改进后的网络结构图具体如下图所示:

🚀3.添加步骤
针对本文的改进,具体步骤如下所示:👇
步骤1:创建EMA.py新文件
步骤2:修改tasks.py文件
步骤3:创建自定义yaml文件
步骤4:新建train.py文件
🚀4.改进方法
🍀🍀步骤1:创建EMA.py文件
在目录:ultralytics/nn/modules文件下创建EMA.py文件,该文件代码如下:
import torch
from torch import nn
# By CSDN 小哥谈
class EMA_attention(nn.Module):
def __init__(self, channels, factor=8):
super(EMA_attention, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)🍀🍀步骤2:修改tasks.py文件
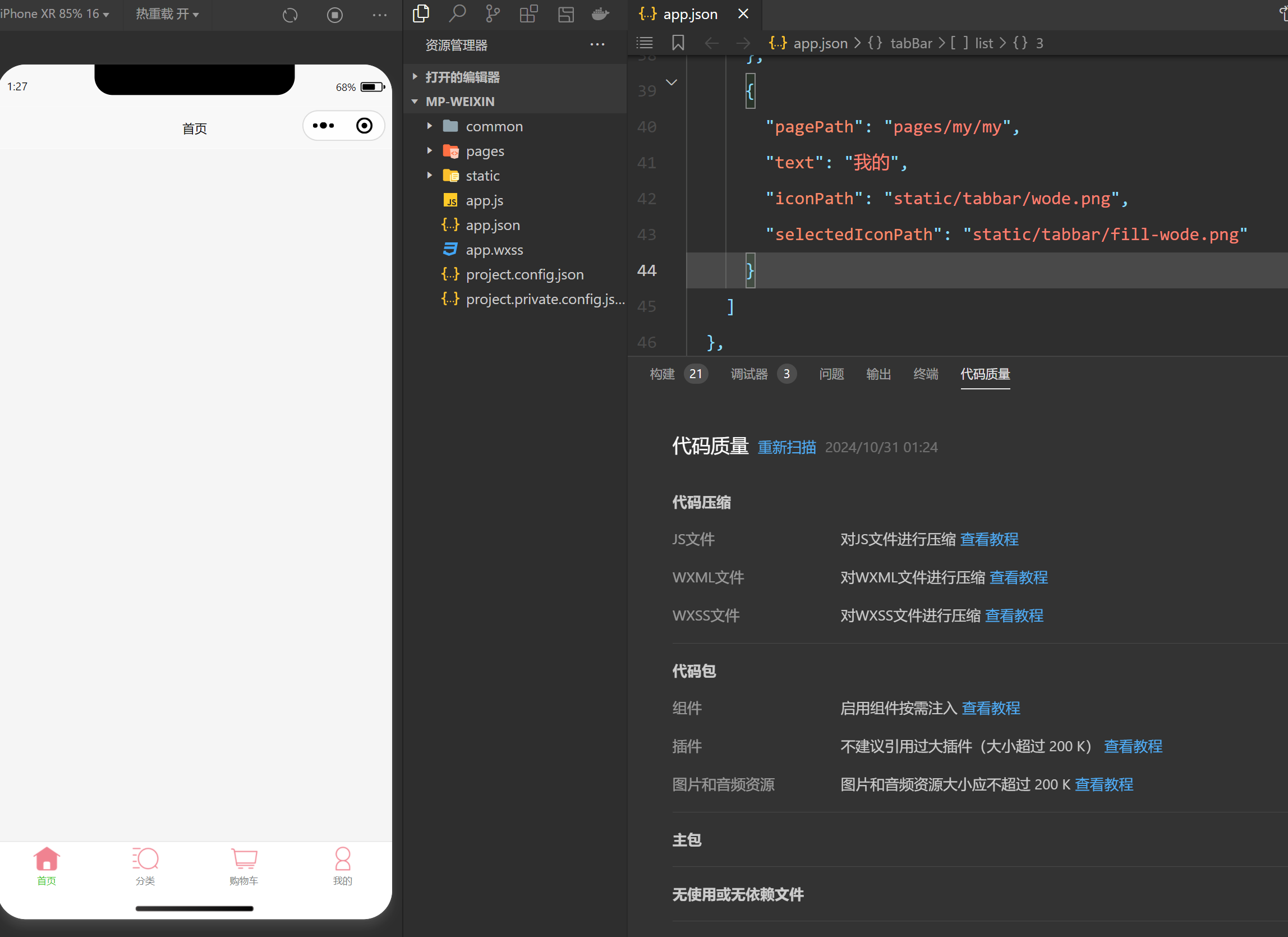
首先,找到parse_model函数(935行左右),在下图所示位置加入EMA_attention。
关于所加位置如下图所示:

然后,在该文件头部导入代码:
from ultralytics.nn.modules.EMA import EMA_attention🍀🍀步骤3:创建自定义yaml文件
在目录:ultralytics/cfg/models/11下创建yolo11_EMA.yaml文件,该文件代码如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# By CSDN 小哥谈
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [16, 1, EMA_attention, [256]] # 23
- [19, 1, EMA_attention, [512]] # 24
- [22, 1, EMA_attention, [1024]] # 25
- [[23, 24, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)🍀🍀步骤4:新建train.py文件
在根目录下,新建train.py文件,该文件代码如下:
# -*- coding: utf-8 -*-
# By CSDN 小哥谈
import warnings
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# model.load('yolo11n.pt')
model = YOLO(model=r'C:\Users\Lenovo\PycharmProjects\ultralytics-main\ultralytics\cfg\models\11\yolo11_EMA.yaml')
model.train(data=r'C:\Users\Lenovo\PycharmProjects\ultralytics-main\ultralytics\cfg\datasets\helmet.yaml',
imgsz=640,
epochs=50,
batch=4,
workers=0,
device='',
optimizer='SGD',
close_mosaic=10,
resume=False,
project='runs/train',
name='exp',
single_cls=False,
cache=False,
)点击“运行”,代码可以正常运行。

关于其他添加位置:
添加位置1:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# By CSDN 小哥谈
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, EMA_attention, [1024]] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)添加位置2:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# By CSDN 小哥谈
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, EMA_attention, [256]] # 17
- [-1, 1, Conv, [256, 3, 2]] # 18
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, EMA_attention, [512]] # 21
- [-1, 1, Conv, [512, 3, 2]] #22
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, EMA_attention, [1024]] # 25
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)