Kafka 概述
Kafka 是由 LinkedIn 开发一个分布式的基于发布订阅模式的消息队列,是一个实时数据处理系统,可以横向扩展。与 RabbitMQ、RockerMQ 等中间件一样拥有几大特点:
- 异步处理
- 服务解耦
- 流量削峰
监控 Kafka 是非常重要的,因为它可以帮助我们确保消息系统的稳定性、可用性、性能和可靠性。以下是监控 Kafka 的一些关键原因:
- 保证消息传递的可靠性:Kafka 作为一个分布式流处理平台,其核心价值在于可靠地存储和传递消息。监控可以帮助我们及时发现和解决数据丢失或重复的问题。
- 维护服务的高可用性:Kafka 通过副本机制来实现高可用性。监控副本同步状态和领导者选举,可以确保在节点故障时,相关的分区能够快速进行领导者选举,最小化服务中断。
- 优化性能:通过监控 Kafka 的性能指标,比如吞吐量、延迟和磁盘I/O,我们可以对 Kafka 集群进行调优,确保它在高负载下依然能够保持高性能。
- 容量规划:监控可以帮助我们理解数据增长的趋势,预测未来的存储需求,从而进行合理的容量规划,避免存储空间不足的情况发生。
- 故障排除:当系统出现问题时,监控系统提供的历史数据和实时数据对于快速定位问题原因非常关键。
- 遵守 SLA:对于需要遵守服务等级协议(SLA)的生产系统,监控可以帮助我们确保 Kafka 服务满足这些协议的要求。
- 安全审计:监控还可以涉及到安全层面,比如监控未授权访问的尝试,确保系统的安全性。
- 业务洞察:通过对消息内容的监控和分析,可以为业务决策提供数据支持,比如通过分析消息流量来优化业务流程。
观测云采集器 DataKit 提供 kafka 指标和日志的观测能力,配置 DataKit 采集 Kafka 指标和日志上报到观测云,帮助你监控分析 Kafka 性能表现以及各种异常情况。
操作步骤
前置条件
安装或下载 Jolokia 。DataKit 安装目录下的 data 目录中已经有下载好的 Jolokia jar 包,可先下载安装 DataKit 。
Jolokia 是作为 Kafka 的 Java agent,基于 HTTP 协议提供了一个使用 JSON 作为数据格式的外部接口,提供给 DataKit 使用。 Kafka 启动时,先配置 KAFKA_OPTS 环境变量:(port 可根据实际情况修改成可用端口)
export KAFKA_OPTS="$KAFKA_OPTS -javaagent:/usr/local/datakit/data/jolokia-jvm-agent.jar=host=*,port=8080"
另外,也可以单独启动 Jolokia,将其指向 Kafka 进程 PID:
java -jar </path/to/jolokia-jvm-agent.jar> --host 127.0.0.1 --port=8080 start <Kafka-PID>
采集器配置
进入 DataKit 安装目录下的 conf.d/db 目录,复制 kafka.conf.sample 并命名为 kafka.conf 。
指标采集(主机模式)
[[inputs.kafka]]
# default_tag_prefix = ""
# default_field_prefix = ""
# default_field_separator = "."
# username = ""
# password = ""
# response_timeout = "5s"
## Optional TLS config
# tls_ca = "/var/private/ca.pem"
# tls_cert = "/var/private/client.pem"
# tls_key = "/var/private/client-key.pem"
# insecure_skip_verify = false
## Monitor Interval
# interval = "60s"
# Add agents URLs to query
urls = ["http://localhost:8080/jolokia"]
......
主要是调整 urls ,配置好后,重启 DataKit 即可。
日志采集
采集 Kafka 的日志,可在 kafka.conf 中 将 files 打开,并写入 kafka 日志文件的绝对路径。比如:
[[inputs.kafka]]
...
[inputs.kafka.log]
files = ["/usr/local/var/log/kafka/error.log","/usr/local/var/log/kafka/kafka.log"]
开启日志采集以后,默认会产生日志来源(source)为 kafka 的日志,切割日志示例:
[2020-07-07 15:04:29,333] DEBUG Progress event: HTTP_REQUEST_COMPLETED_EVENT, bytes: 0 (io.confluent.connect.s3.storage.S3OutputStream:286)
切割后的字段列表如下:
| 字段名 | 字段值 |
|---|---|
| msg | Progress event: HTTP_REQUEST_COMPLETED_EVENT, bytes: 0 |
| name | io.confluent.connect.s3.storage.S3OutputStream:286 |
| status | DEBUG |
| time | 1594105469333000000 |
修改 kafka.conf 后,需要重启 DataKit 生效。
场景视图
登录观测云控制台,点击「场景」 -「新建仪表板」,输入 “Kafka”, 选择 “Kafka 监控视图”,点击 “确定” 即可添加视图:
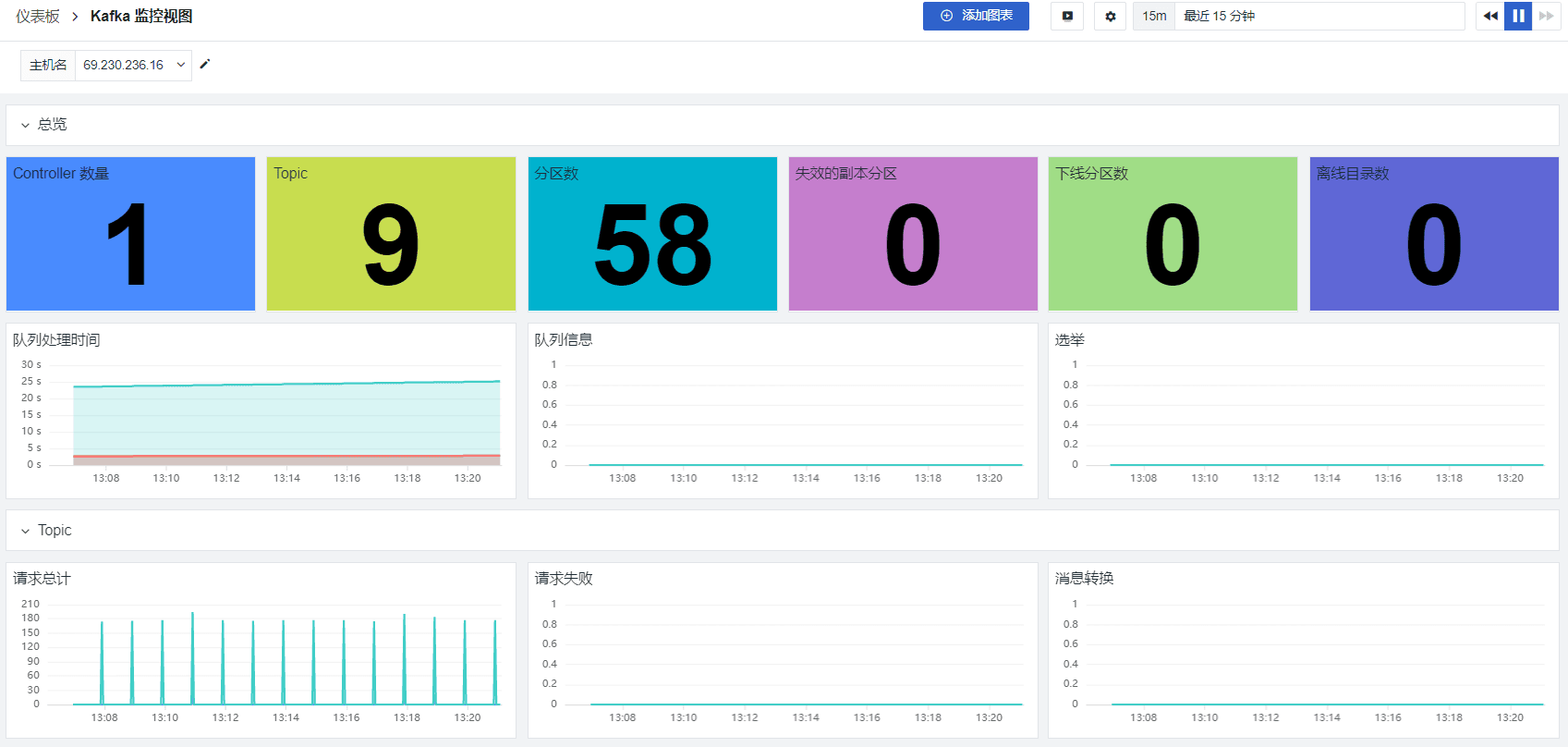
关键指标
接下来介绍 Kafka 指标的详细信息。
UnderReplicatedPartitions
UnderReplicatedPartitions 未同步状态的分区个数,即失效副本的分区数,异常值非 0。在运行状况良好的群集中,同步副本(ISR)的数量应完全等于副本的总数。 该值非零表示 Broker 上的 Leader 分区存在没有完全同步并跟上 ISR 的副本的分区数量。可能存在问题:
- 某个 Broker 宕机。
- 副本所在磁盘故障/写满,导致副本离线,可以结合 OfflineLogDirectoryCount 指标非 0 值进行判断。
- 性能问题导致副本来不及同步。可能有两种情况,第一种 Follower 副本进程卡住,在一段时间内根本没向 Leader 发起同步请求,比如频繁 Full GC,第二种 Follower 副本进程同步较慢,在一段时间内无法追赶 Leader 副本,比如 I/O 开销过大。
| 指标集 | kafka_replica_manager | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| UnderReplicatedPartitions | 处于未同步状态的 Partition 个数 | int |
| UnderMinIsrPartitionCount | 低于最小 ISR Partition 个数。 | int |
OfflineLogDirectoryCount
OfflineLogDirectoryCount 离线日志目录数量,异常值非 0 。需要观测该指标,以检查是否存在脱机日志目录。
| 指标集 | kafka_log | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| OfflineLogDirectoryCount | 离线日志目录数量 | int |
IsrShrinksPerSec / IsrExpandsPerSec
任意一个分区的处于同步状态的副本数(ISR)应该保持稳定,除非您正在扩展 Broker 节点或删除分区。 为了保持高可用, Kafka 集群必须保证最小 ISR 数,以防在某个分区的 Leader 挂掉时它的 Follower 可以接管。一个副本从 ISR 池中移走有以下一些原因:Follower 的 offset 远远落后于 Leader(改变 replica.lag.max.messages 配置项),或者某个 Follower 已经与 Leader 失去联系了某一段时间(改变 replica.socket.timeout.ms 配置项),不管是什么原因,如果 IsrShrinksPerSec(ISR 缩水) 增加了,但并没有随之而来的 IsrExpandsPerSec(ISR 扩展)的增加,就将引起重视并人工介入。
| 指标集 | kafka_replica_manager | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| IsrShrinksPerSec.Count | ISR 缩减数量 | int |
| IsrShrinksPerSec.OneMinuteRate | ISR 缩减频率 | float |
| IsrExpandsPerSec.Count | ISR 膨胀数量 | int |
| IsrExpandsPerSec.OneMinuteRate | ISR 膨胀频率 | float |
ActiveControllerCount
ActiveControllerCount 当前处于激活状态的控制器的数量,异常值 0。Kafka 集群中第一个启动的节点自动成为 Controller,有且只能有一个这样的节点、正常情况下 Controller 所在的 Broker 上的这个指标应该是 1,其它 Broker 上的这个值应该是 0。Controller 的职责是维护分区 Leader 的列表,当某个 Leader 不可用时协调 Leader 的变更。如果有必要更换 Controller,一个新的 Controller 将会被 Zookeeper 从 Broker 池中随机的选取出来,通常来说这个值不可能大于 1,但当遇到这个值等于 0 且持续了一段时间 (<1) 的时候,必须发出明确的警告,所以该指标可用作告警。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| ActiveControllerCount.Value | Controller 存活数量 | int |
OfflinePartitionsCount
OfflinePartitionsCount 没有活跃 Leader 的分区数,异常值非 0。由于所有的读写操作都只在 Partition Leader上进行,任何没有活跃 Leader 的 Partition 都会彻底不可用,且该 Partition 上的消费者和生产者都将被阻塞,直到 Leader 变成可用。该指标可用作告警。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| OfflinePartitionsCount.Value | 下线 Partition 数量 | int |
LeaderElectionRateAndTimeMs
当 Parition Leader 挂了之后就会触发选举,就会触发新 Leader 的选举。通过 LeaderElectionRateAndTimeMs 可以观测 Leader 每秒钟选举多少次,选举频率。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| LeaderElectionRateAndTimeMs.Count | Leader 选举次数 | int |
| LeaderElectionRateAndTimeMs.OneMinuteRate | Leader 选举比率 | float |
| LeaderElectionRateAndTimeMs.50thPercentile | Leader 选举比率 | float |
| LeaderElectionRateAndTimeMs.75thPercentile | Leader 选举比率 | float |
| LeaderElectionRateAndTimeMs.99thPercentile | Leader 选举比率 | float |
UncleanLeaderElectionsPerSec
当 Kafka Brokers 分区 Leader 不可用时,就会发生 unclean 的 Leader 选举,将从该分区的 ISR 集中选举出新的 Leader。 从本质上讲,unclean leader 选举牺牲了可用性的一致性。 同步中没有可用的副本,只能在未同步的副本中进行 Leader 选举,则前 Leader 未经同步的消息都会永远丢失。UncleanLeaderElectionsPerSec.Count 异常值是不等于 0,此时代表着数据丢失,因此需要进行告警。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| UncleanLeaderElectionsPerSec.Count | Unclean Leader 选举次数 | int |
TotalTimeMs
TotalTimeMs 度量本身是四个指标的总和:
- queue:在请求队列中等待所花费的时间
- local:领导者处理所花费的时间
- remote:等待关注者响应所花费的时间(仅当时 requests.required.acks=-1)
- response:发送回复的时间
TotalTimeMs 用来衡量服务器请求的用时,正常情况下该指标比较稳定,只有非常小的波段,如果发现异常,则会出现不规则的数据波动。这时需要检查各个 queue、local、remote 和 response 的值,定位处造成延迟的原因到底处于哪个 segment。
| 指标集 | kafka_request | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| TotalTimeMs.Count | 总请求用时 | int |
PurgatorySize
PurgatorySize: 作为一个临时存放的区域,使得生产(produce)和消费(fetch)的请求在那里等待直到被需要的时候。留意 purgatory 的大小有助于确定潜伏期的根本原因。例如,如果 purgatory 队列中获取请求的数量相应增加,则可以很容易地解释消费者获取时间的增加。
| 指标集 | kafka_purgatory | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| Fetch.PurgatorySize | Fetch Purgatory 大小 | int |
| Produce.PurgatorySize | Produce Purgatory 大小 | int |
| Rebalance.PurgatorySize | Rebalance Purgatory 大小 | int |
| topic.PurgatorySize | topic Purgatory 大小 | int |
| ElectLeader.PurgatorySize | 选举 Leader Purgatory 大小 | int |
| DeleteRecords.PurgatorySize | 删除记录 Purgatory 大小 | int |
| DeleteRecords.NumDelayedOperations | 延时删除记录数 | int |
| Heartbeat.NumDelayedOperations | 心跳监测 | int |
BytesInPerSec / BytesOutPerSec
BytesInPerSec/BytesOutPerSec 传入/传出字节数。通常磁盘吞吐量、网络吞吐量都可能成为瓶颈。 如果您要跨数据中心发送消息,Topic 数量众多,或者副本正在赶上 Leader,则网络吞吐量可能会影响 Kafka 的性能。 通过这些指标,在跟踪 Broker 上的网络吞吐量来判断瓶颈出在何处。
| 指标集 | kafka_topics | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| BytesInPerSec.Count | 每秒流入字节数 | int |
| BytesInPerSec.OneMinuteRate | 每秒流入速率 | float |
| BytesOutPerSec.Count | 每秒流出字节数 | int |
| BytesOutPerSec.OneMinuteRate | 每秒流出速率 | float |
RequestsPerSec
RequestsPerSec 每秒请求次数。通过观测该指标,可以实时掌握生产者,消费者的请求率,以确保您的 Kafka 高效通信。如果该指标持续维持高位,可以考虑增加生产者或者消费者的数量,进而提高吞吐量,从而减少不必要的网络开销。
| 指标集 | kafka_topics | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| TotalFetchRequestsPerSec.Count | 每秒拉取请求的次数 | int |
| TotalProduceRequestsPerSec.Count | 生产者每秒写入请求的次数 | int |
| FailedFetchRequestsPerSec.Count | Topic 失败 Fetch 数量 | int |
| FailedProduceRequestsPerSec.Count | 发送请求失败速率 | int |
其它常用指标
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| GlobalTopicCount.Value | 集群总 Topic 数量 | int |
| GlobalPartitionCount.Value | 分区数 | int |
| TotalQueueSize.Value | 队列总数 | int |
| EventQueueSize.Value | 事件队列数 | int |
| 指标集 | kafka_request | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| RequestQueueTimeMs.Count | 请求队列时间 | int |
| ResponseSendTimeMs.Count | 相应队列时间 | int |
| MessageConversionsTimeMs.Count | 消息转换时间 | int |
| 指标集 | kafka_topics | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| PartitionCount.Value | Partition 数量 | int |
| LeaderCount.Value | Leader 数量 | int |
| BytesRejectedPerSec.Count | Topic 请求被拒绝数量 | int |
监控器
当前监控器概览如下:

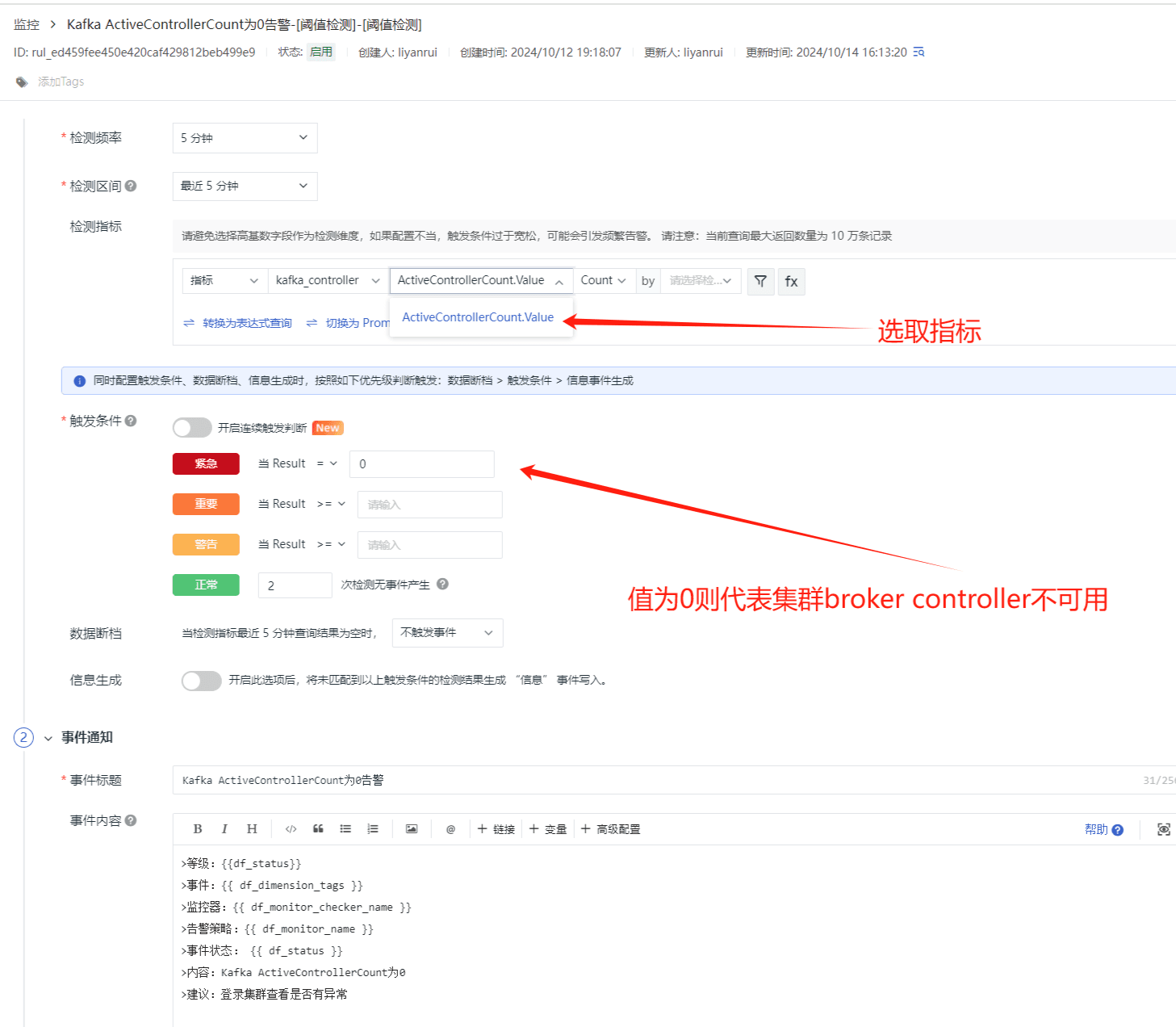
Kafka 处于激活状态的控制器的数量告警
ActiveControllerCount 当前处于激活状态的控制器的数量,异常值 0。Kafka 集群中第一个启动的节点自动成为 Controller,有且只能有一个这样的节点、正常情况下 Controller 所在的 Broker 上的这个指标应该是 1,其它 Broker 上的这个值应该是 0。Controller 的职责是维护分区 Leader 的列表,当某个 Leader 不可用时协调 Leader 的变更。如果有必要更换 Controller,一个新的 Controller 将会被 Zookeeper 从 Broker 池中随机的选取出来,通常来说这个值不可能大于 1,但当遇到这个值等于 0 且持续了一段时间 (<1) 的时候,必须发出明确的警告,所以该指标可用作告警。
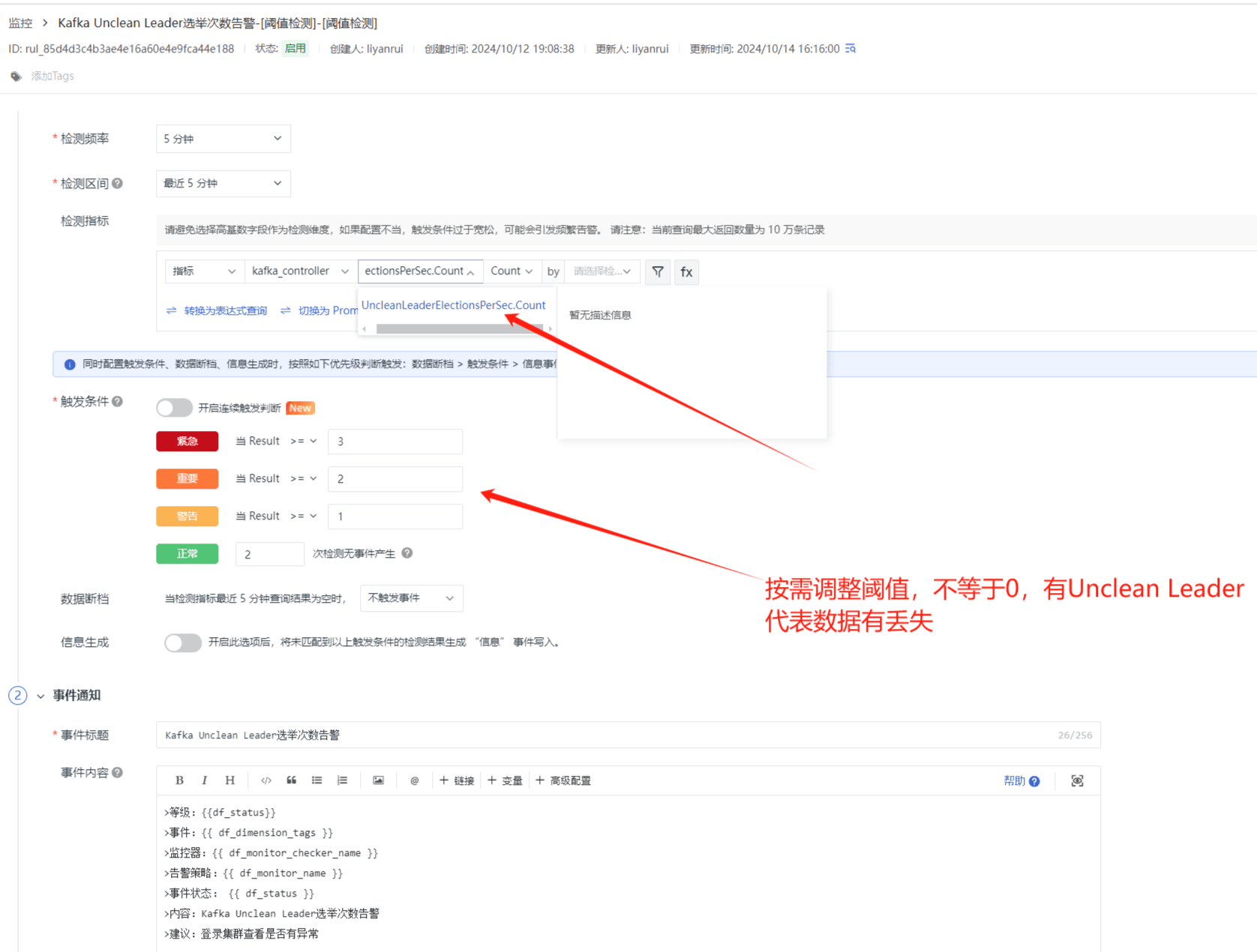
Kafka Unclean Leader 选举次数告警
当 Kafka Brokers 分区 Leader 不可用时,就会发生 unclean 的 Leader 选举,将从该分区的 ISR 集中选举出新的 Leader。 从本质上讲,unclean leader 选举牺牲了可用性的一致性。 同步中没有可用的副本,只能在未同步的副本中进行 Leader 选举,则前 Leader 未经同步的消息都会永远丢失。UncleanLeaderElectionsPerSec.Count 异常值是不等于 0,此时代表着数据丢失,因此需要进行告警。
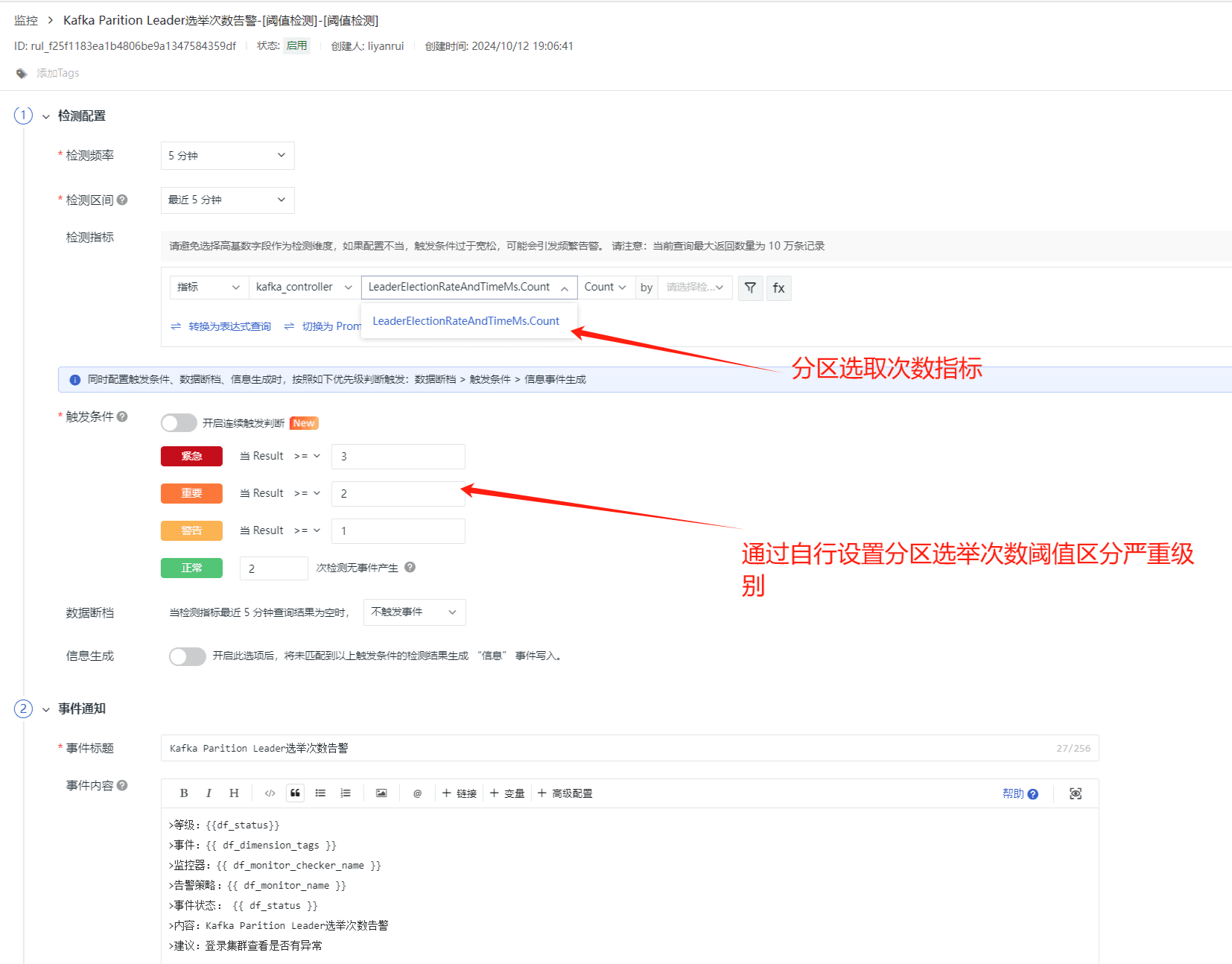
Kafka Parttition Leader 选举次数告警
Kafka 分区 leader 选举是 Kafka 高可用性的关键机制之一。当 Kafka 集群中的某个分区的 leader 节点出现问题时,会触发 leader 选举,以确保消息的高可用性和一致性。监控 leader 选举的次数是有必要的,因为这可以帮助你了解集群的健康状况和潜在的问题。频繁的 leader 选举可能表明集群中存在问题,例如硬件故障、网络问题或者 Kafka 配置不当。在某些情况下,频繁的 leader 选举可能会导致集群性能下降,因为选举过程需要额外的资源和时间。因此,通过设置 LeaderElectionRateAndTimeMs.Count 告警来监控 leader 选举的次数可以帮助及时发现并解决这些问题。
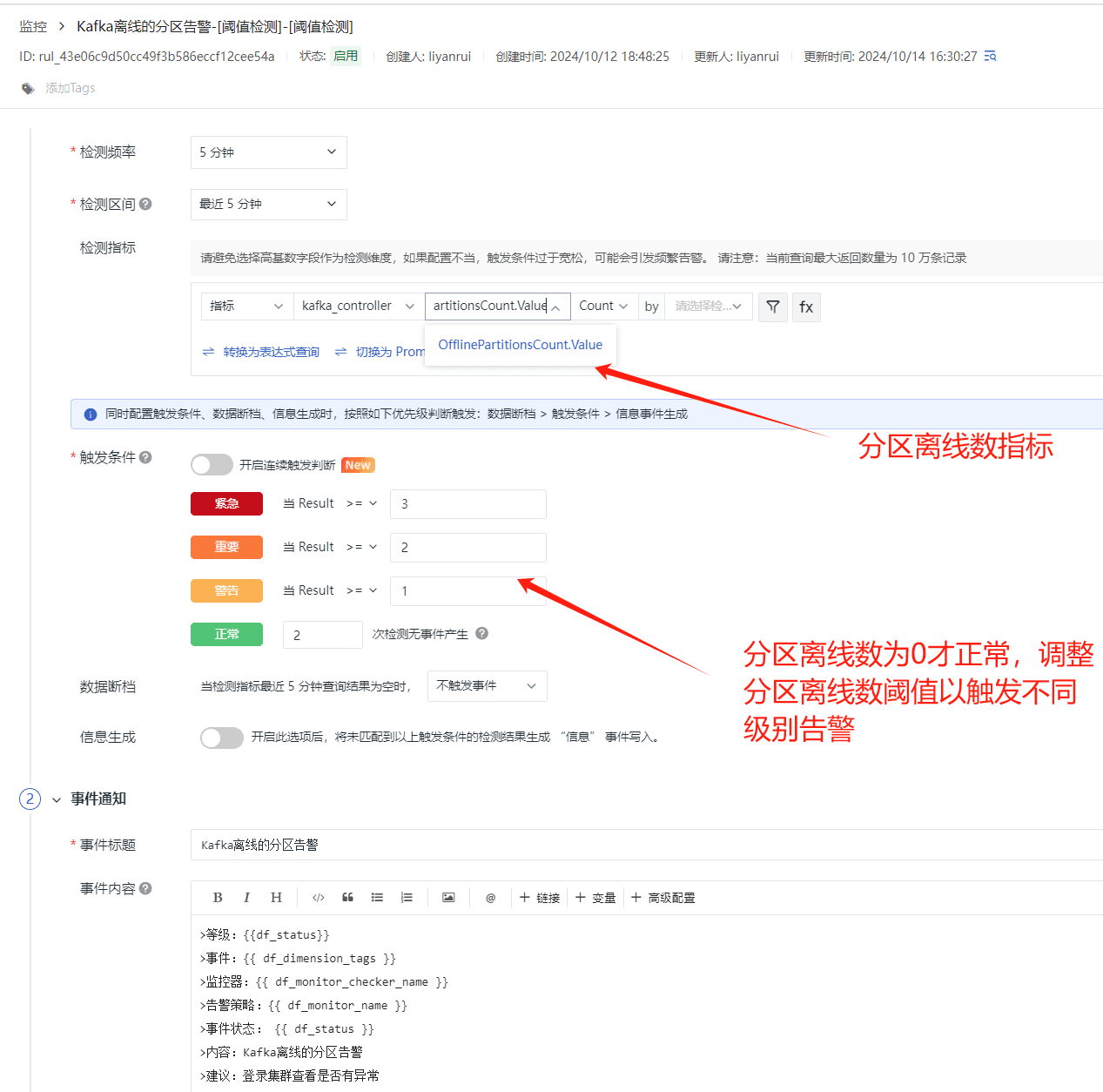
Kafka 离线的分区告警
Kafka 离线分区是指那些没有活跃 Leader 的分区,这种情况可能会导致数据无法被正常读写,因此对 Kafka 集群的稳定性和数据的可用性构成威胁。通过 OfflinePartitionsCount.Value 指标监控离线分区的数量是非常有必要的,发现有分区离线时,应立即发出告警以帮助及时发现和解决集群中的问题。
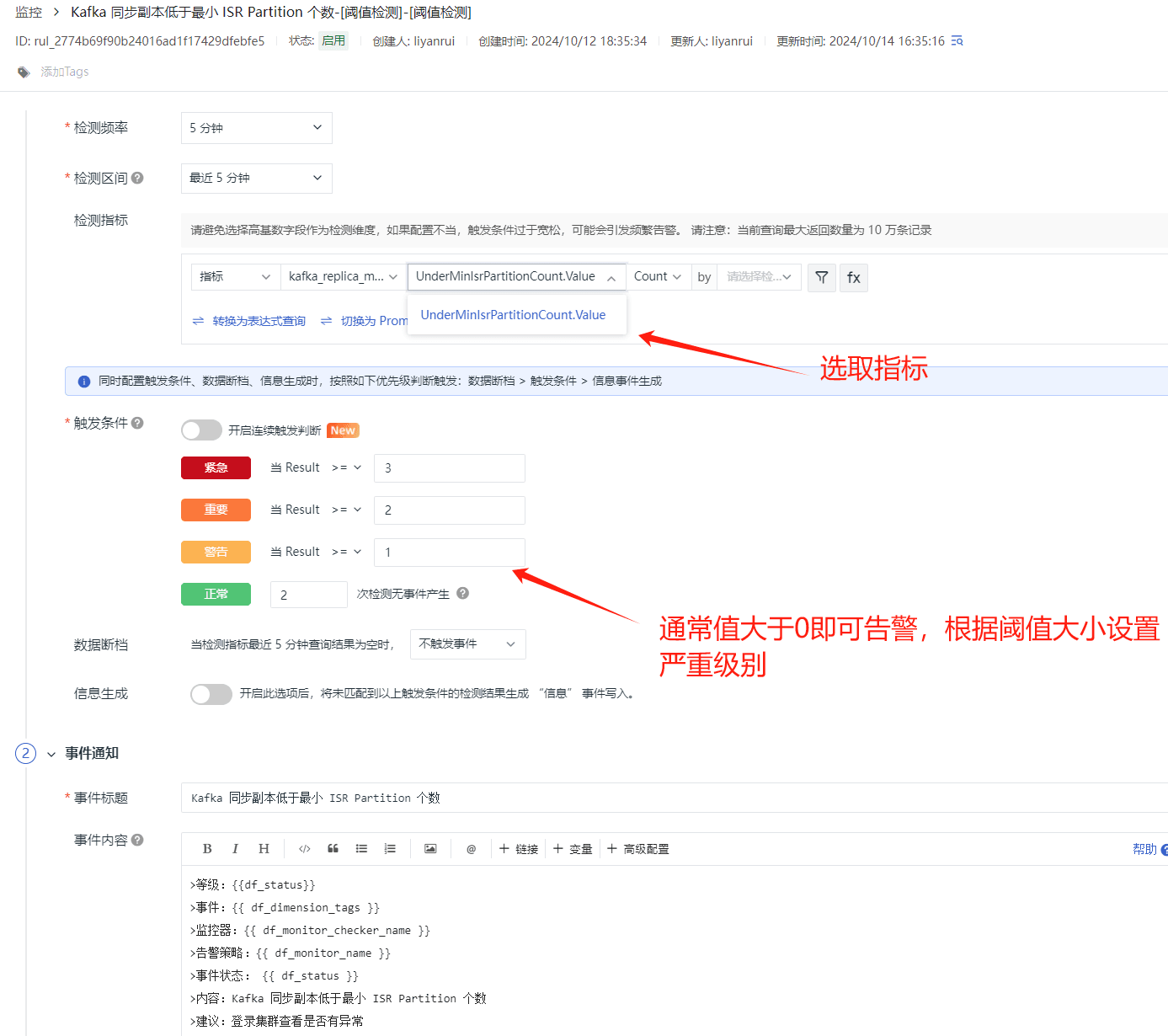
Kafka 同步副本低于最小 ISR Partition 个数
在 Kafka 中,ISR(In-Sync Replicas)是指与 leader 副本保持同步的副本集合。如果一个分区的同步副本数量低于配置的最小 ISR 分区个数(min.insync.replicas),这可能会影响到数据的可靠性和写入请求的响应。因此,通过 UnderMinIsrPartitionCount.Value 监控 ISR 的状态并设置告警是非常有必要的。
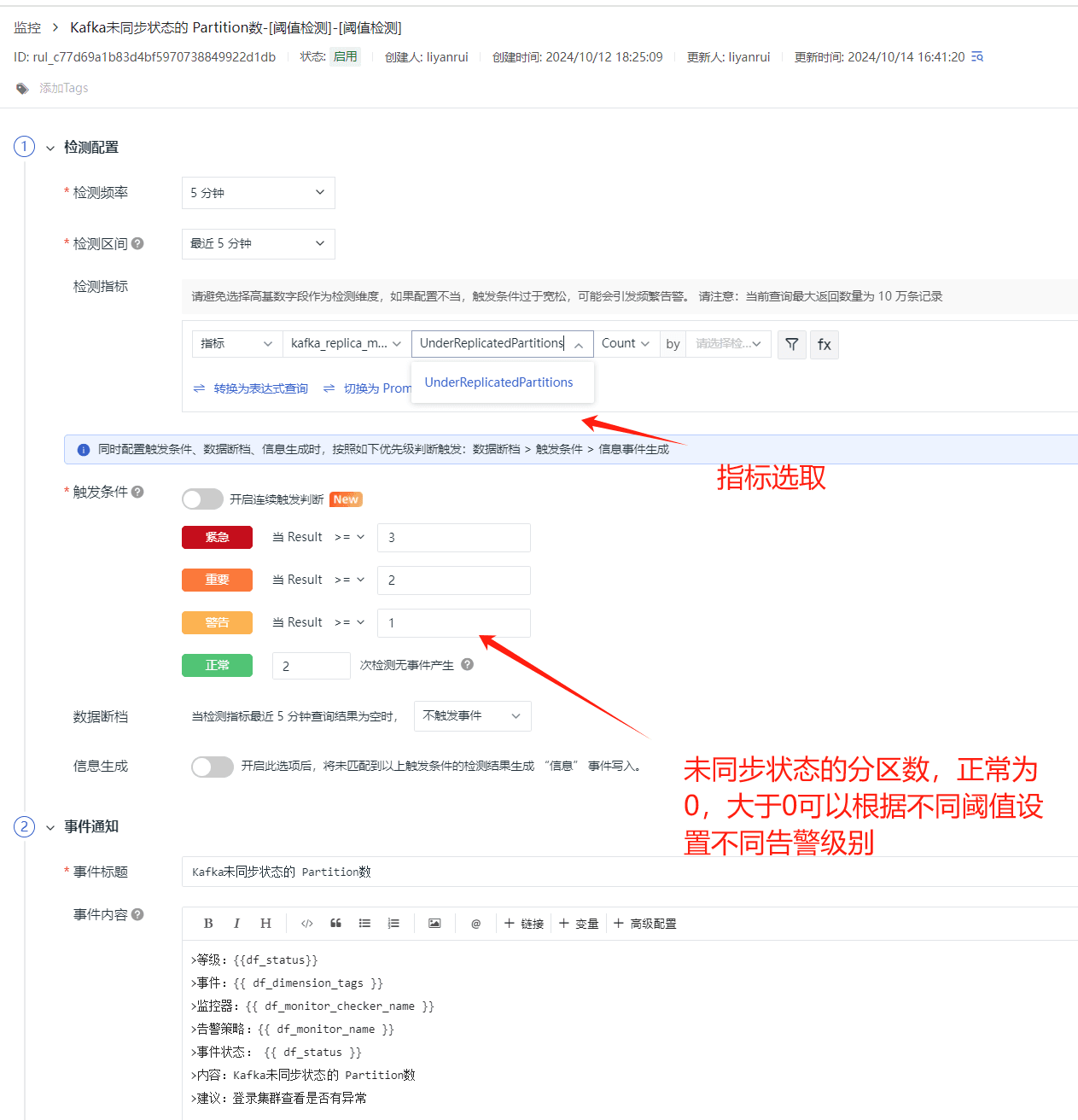
Kafka 未同步状态的 Partition
在 Kafka 中,未同步状态的 Partition 副本指的是那些不在 ISR(In-Sync Replicas)中的副本。如果一个分区的副本没有及时与 leader 副本同步,这可能会导致数据不一致或在 leader 副本失败时无法进行正常的 leader 选举,因此,通过 UnderReplicatedPartitions 对于这种状态的监控和告警是非常有必要的。
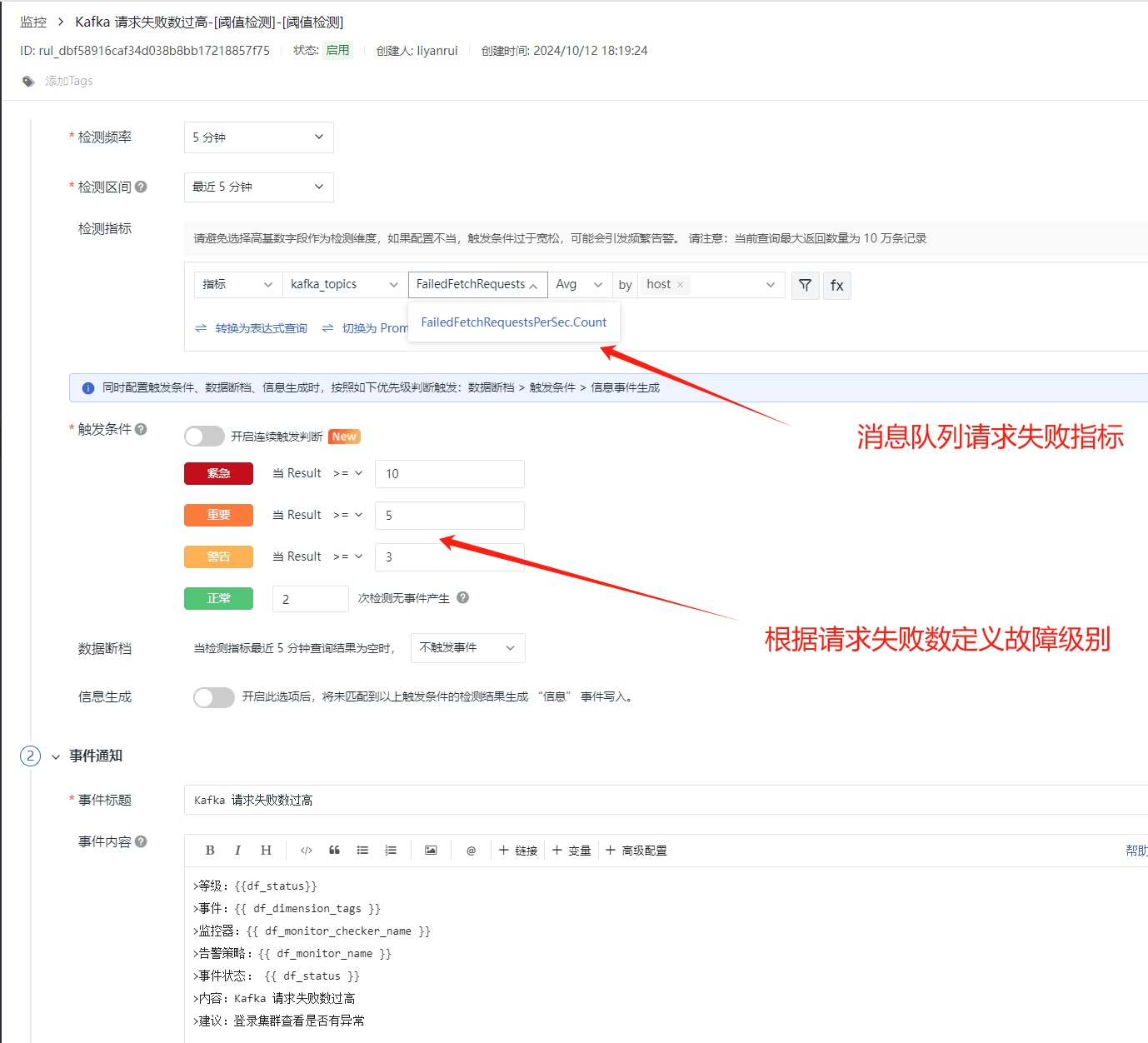
Kafka 请求失败数过高
在 Kafka 中,请求的失败数高,可能回影响消息的生产和消费,当请求失败数异常增高时,它通常表明系统正在经历一些需要立即注意的问题,通过 kafka topic 失败请求数量指标 FailedFetchRequestsPerSec.Count 来发现并解决那些影响消息传递稳定性的问题。
总结
总之,监控 Kafka 有助于我们确保系统的健康运行,及时响应和处理各种问题,同时也为系统优化和扩展提供了数据支持。