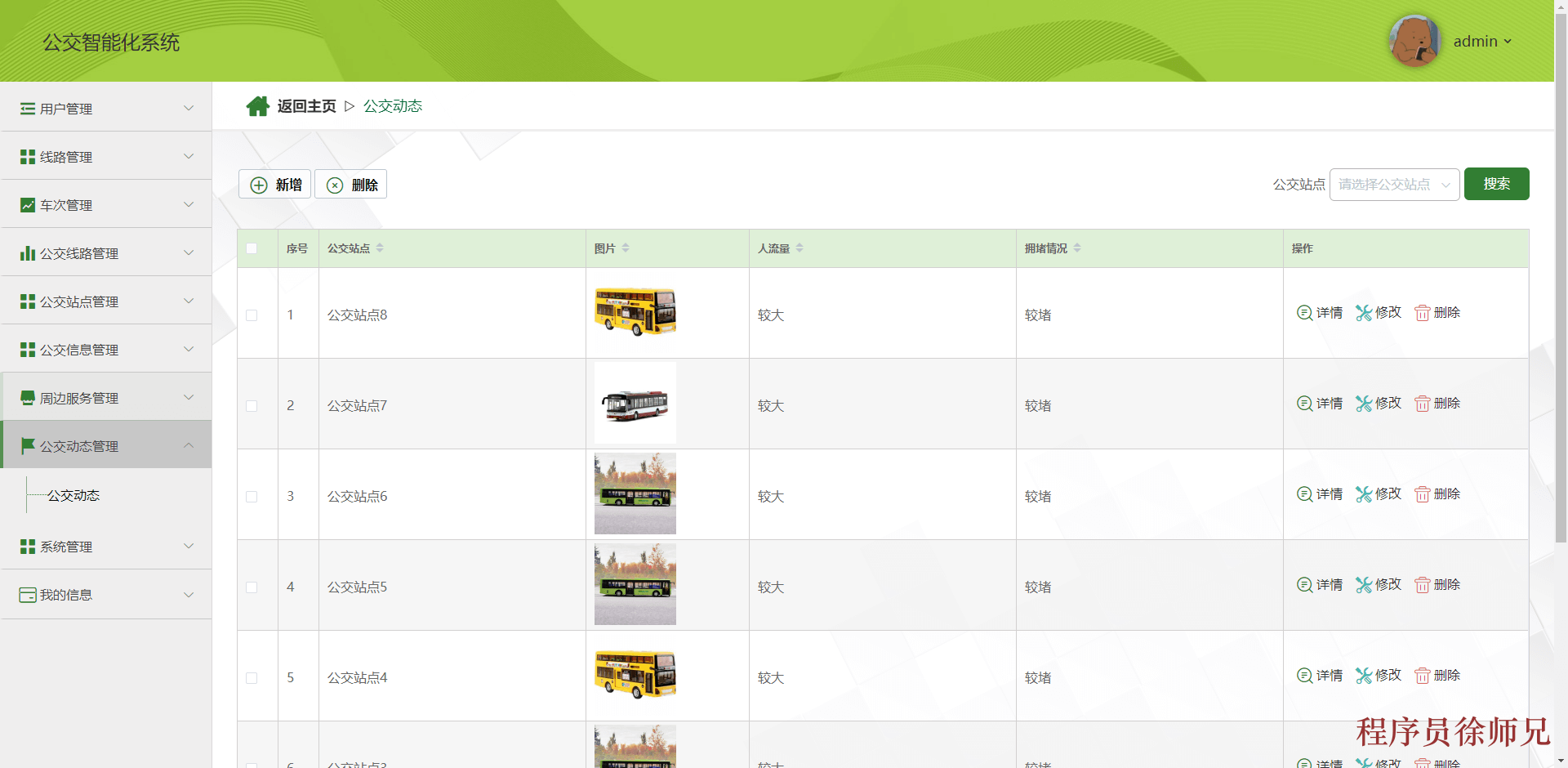
import time
import os
file_size = 1 * 1024 * 1024 * 100
file_path = "test_file.bin"
def test_write_speed ( ) :
data = os. urandom( file_size)
start_time = time. time( )
with open ( file_path, 'wb' ) as f:
f. write( data)
end_time = time. time( )
write_time = end_time - start_time
write_speed = file_size / ( write_time * 1024 * 1024 )
print ( f"Disk write speed: { write_speed: .6f } MB/s" )
def test_read_speed ( ) :
start_time = time. time( )
with open ( file_path, 'rb' ) as f:
data = f. read( )
end_time = time. time( )
read_time = end_time - start_time
read_speed = file_size / ( read_time * 1024 * 1024 )
print ( f"Disk read speed: { read_speed: .6f } MB/s" )
test_write_speed( )
test_read_speed( )
os. remove( file_path)
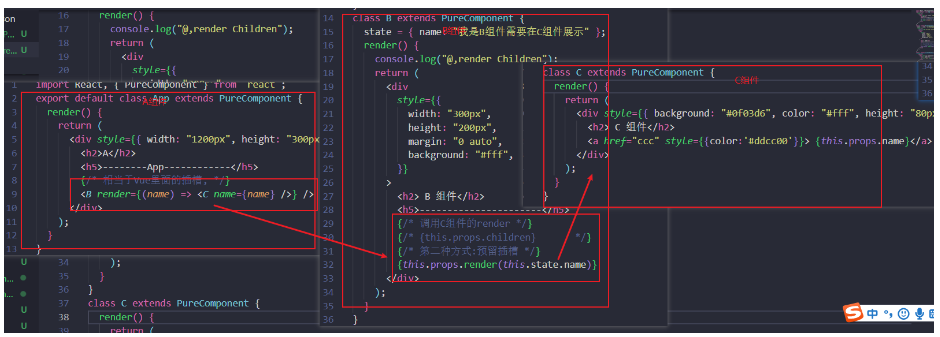
import torch
import time
device_cpu = torch. device( 'cpu' )
device_gpu = torch. device( 'cuda' if torch. cuda. is_available( ) else 'cpu' )
size = 10 ** 7
data_cpu = torch. randn( size) . to( device_cpu)
data_size_bytes = data_cpu. nelement( ) * data_cpu. element_size( )
start_time = time. time( )
data_gpu = data_cpu. to( device_gpu)
torch. cuda. synchronize( )
cpu_to_gpu_time = time. time( ) - start_time
cpu_to_gpu_speed = data_size_bytes / ( cpu_to_gpu_time * 1024 * 1024 )
print ( f"CPU -> GPU data transfer speed: { cpu_to_gpu_speed: .6f } MB/s" )
start_time = time. time( )
data_back_to_cpu = data_gpu. to( device_cpu)
torch. cuda. synchronize( )
gpu_to_cpu_time = time. time( ) - start_time
gpu_to_cpu_speed = data_size_bytes / ( gpu_to_cpu_time * 1024 * 1024 )
print ( f"GPU -> CPU data transfer speed: { gpu_to_cpu_speed: .6f } MB/s" )