目录
- 1. 前言
- 2. 流程详解
- 2.1 知识管理
- 2.1.1 知识存储【未展开】
- 2.1.2 知识加载
- (1) docx
- (2) pdf
- 2.2 切分
- 2.2.1 固定长度分割
- 2.2.2 自己写的固定分块方法
- 2.3 创建知识库的向量库
- 2.4 检索
- 2.5 模型部署和加载
- (1)api生成
- (2)Transformers加载方式
- 2.6 内存
- 2.7 Prompt
- 2.8 re-ranking
- 2.9 RAG 优化
1. 前言
构建能够推断私有数据或在模型截止日期之后引入的数据的AI应用程序时,需通过特定信息增强模型的知识,这一过程被称为检索增强生成(RAG),通过引入适当的信息并将其插入模型提示符中来实现。
RAG的基础工作流程:
离线步骤:
- 数据准备阶段:用于整理结构化、非结构化数据,并进行分类分级,这是RAG流程中的基础步骤。
- 文档加载 -> 切分 -> 向量化 -> 存储
在线步骤:
- 问题 -> 向量化 -> 检索 -> Prompt -> LLM -> 回复
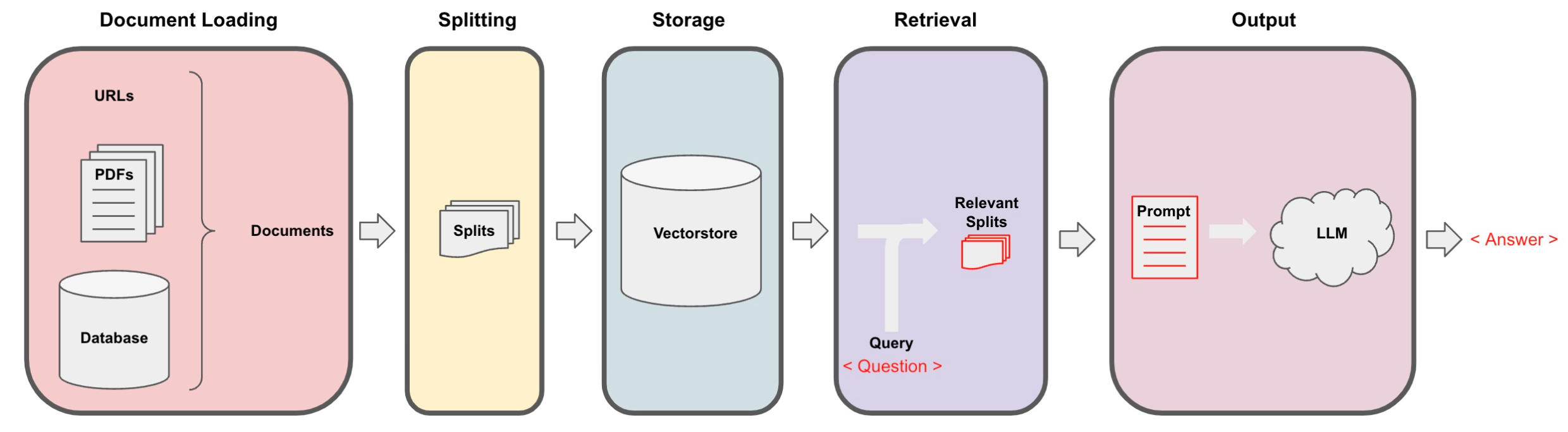
RAG的优化工作流程:
OpenAI一篇关于RAG优化方案的文章(https://www.1goto.ai/article/f0c100da-4f90-4994-8dca-93532d26fbd8):
45%: 仅采用基于向量的余弦相似性;
65%: 基础文本分块+向量化模型+初阶检索,增加文档种类和切块优化手段、检索类型,性能会显著提升,技术难点:领域embedding,多模分块,索引汇聚等;
85%: 增加检索后处理,技术难点:重排,分类提示;
98%: 改进提示词工程、增加查询扩展等。
2. 流程详解
2.1 知识管理
2.1.1 知识存储【未展开】
企业内有大量业务字典,这些业务字典中出现的问题增加了解答请求的困难,同时要对数据来源进行有效的管理,隐私分类。基于此,可以将数据进行企业化元数据,统一对接企业的数据源、数据字典、用户权限,进行一体化管理。
2.1.2 知识加载
(1) docx
加载代码:
from langchain.document_loaders import UnstructuredWordDocumentLoader
documents = []
loader = UnstructuredWordDocumentLoader(file_path)
documents.extend(loader.load())
print(documents)
加载规则:
换行用“\n”分割
表格中单元格之间用“ ”分割
图片识别不了,不能加载进来
备注不能加载进来
表可以读进来,合并单元格也可以读进来
合并单元格也可读进来
打印加载结果:
由page_content和metadata组成,无页码。
[Document(page_content=‘文本内容’, metadata={‘source’: ‘/path/1.docx’})]
(2) pdf
加载代码
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path)
documents = []
documents.extend(loader.load())
print(documents)
加载规则
换行用“\n”分割
表格中单元格之间用“ ”分割
图片识别不了,不能加载进来
表可以读进来,合并单元格不能读进来
打印加载结果:
合并单元格无法加载进来
由page_content和metadata组成,有页码:
[Document(page_content=‘当页内容 当页页眉页脚 右侧上的标题’, metadata={‘source’: ‘.pdf’, ‘page’: 0}),…,
Document(page_content=‘当页内容 当页图表内容 当页页眉页脚’, metadata={‘source’: '.pdf’, ‘page’: 10})]
2.2 切分
非结构化数据的切分方法包括多种技术。内容感知分割不仅仅是简单的拆分,而是需要深入理解数据内容。例如,对于图片、表格和图像等类型的数据。下面举了一些方法,只详细说固定长度分割。
固定长度分割:不考虑文档的结构,只按照固定数量的字符进行划分chunk,这是最简单的方式,chunk_overlap控制重叠区域的大小。这种方式不理想,很容易造成语义中断。如:
- chunk_size: 9
- chunk_overlap: 2
文本类-递归字符分割,递归字符文本分割器则是指定一系列分隔符来分割文档:
分段分隔符:英文逗号 中文逗号 换行 空格 英文句号 空两行 中文句号 英文问号 中文问号 英文感叹号 中文感叹号
标题分割,按照文本的标题进行切分,适合Word承载的文本。
NTLK 语句分割:把文本分成一个个词语或短语。
spaCy 语句分割
2.2.1 固定长度分割
2.2.1.1 基于 langchain 语法的固定长度分块
(1)分块代码
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 20,
chunk_overlap = 5
)
splits = text_splitter.split_documents(docs)
(2)代码规则
docx:
弊端1:虽然设置了重合数,但是分割时部分块之间没有重叠,语义切断,即使重叠也会有语义切断,就不能编码出完整语义的向量,分块时块大一点可以缓解这种弊端。
弊端2:表格时语义切断影响比较严重,如下这种就会导致回答不出来,当然实际我分割块很大,设置的分割块长一点可以大大减弱这种影响,但是总会有个别的知识不能被完整的分割。
打印结果:由page_content和metadata组成,无页码。
[Document(page_content=‘文本内容’, metadata={‘source’: ‘1.docx’}), …,
Document(page_content=‘文本内容’, metadata={‘source’: ‘1.docx’})]
2.2.1.2 pdf:
弊端1:对pdf表格不友好
结果呈现:由page_content和metadata组成,有页码,每一页有很多块。
2.2.2 自己写的固定分块方法
(1)分块代码
def split_text(text, chunk_size = 100, step = 30):
chunks = []
for i in range(0, len(text), step):
chunk = text[i:i + chunk_size]
if chunk:
chunks.append(chunk)
return chunks
# 分块
docs = []
for document in documents:
page_content = document.page_content
metadata_source = document.metadata.get('source', '')
processed_chunks = split_text(page_content)
for chunk in processed_chunks:
doc = Document(page_content = chunk, metadata = {'source': metadata_source})
docs.append(doc)
(2)代码规则
docx:每块是固定的,也确定能重合。
弊端:和langchain固定语法有同样的弊端,重合值的设定得调,调不好下面这种问答就会出错:
2.3 创建知识库的向量库
# from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
persist_directory_chinese = '/aa/demo/'
vectordb_chinese = Chroma.from_documents(
documents = splits,
embedding = embedding,
persist_directory = persist_directory_chinese # 将persist_directory目录保存到磁盘上
)
vectordb_chinese.persist() # 运行vectordb.persist来持久化向量数据库
# print(vectordb_chinese._collection.count())
2.4 检索
LangChain提供的检索工具:
LangChain提供了检索工具vetordb,还提供了其他检索文档的方式,例如:TF-IDF 或 SVM。
检索工具vetordb
(1)基本语义相似度
相似性搜索失败的情况-重复的块
相似性搜索失败的情况-获取所有相似的文档,不强制多样性。
(2)最大边际相关性
最大边际相关模型 (MMR,Maximal Marginal Relevance) 是实现多样性检索的常用算法。
考量查询与文档的相关度,以及文档之间的相似度。它计算每个候选文档与查询的相关度,并减去与已经选入结果集的文档的相似度。这样更不相似的文档会有更高的得分。
(3)过滤元数据
(4)LLM辅助检索
实际用检索时候最好是按照自己设计的想法自己写检索代码,不用封装好的方法。
查询理解阶段:
查询理解阶段
查询扩展(QueryExpansion):自动地向用户的原始查询中添加额外的词语或短语,这些新增的词语或短语与原始查询具有语义上的关联。
方法1:同义词和近义词替换
(1)使用同义词词典
(2)基于预训练模型:使用如BERT等预训练的中文语言模型来识别可能的同义词或近义词。
方法2:词语扩展
(1)利用知识图谱对查询中的实体进行扩展。
(2)找出与查询在语义上相关的历史查询,把历史查询中的关键词添加到原始查询中。
方法3:对于长查询,去掉冗余信息
(1)提取关键信息,去除冗余部分,优化查询的准确性。
方法4:互式查询扩展
(1)通过用户与系统的交互,收集用户对检索结果的反馈,优化查询。
问答部分有这些模式:
多种模式,如MapReduce 分批处理长文档,Refine 实现可交互问答,MapRerank 优化信息顺序
(1) 基于模板的检索式问答链
检索式问答链:提出问题,查找相关文档,将切分文档和系统提示一起传递给语言模型,并获得答案。默认是合并所有文档,一次性输入模型,弊端是若相关文档量大,难以一次将全部输入模型。
(2) 基于 MapReduce 的检索式问答链
将每个独立的文档单独发送到语言模型以获取原始答案。这些答案通过最终对语言模型的一次调用组合成最终的答案。弊端:速度慢,结果实际上更差。
(3)基于 Refine 的检索式问答链
对于每一个文档,会调用一次 LLM,最终输入语言模型的 Prompt 是一个序列,将之前的回复与新文档组合在一起,并请求得到改进后的响应。例如第一次调用,Prompt 包含问题与文档 A ,语言模型生成初始回答。第二次调用,Prompt 包含第一次回复、文档 B ,请求模型更新回答,以此类推。由于 LangChain 内部的限制,定义为 Refine 的问答链会默认返回英文作为答案。
2.5 模型部署和加载
(1)api生成
在线部署,可购买api,如购买gpt的api;本地部署大模型,可以用工具生成模型对应的api,比如可参考:https://github.com/xusenlinzy/api-for-open-llm/tree/master.
(2)Transformers加载方式
我喜欢用这种方式,简单好用,可以随着自己的设计思路随时切换模型。
2.6 内存
上面的链式(chain)没有任何状态的概念,不记得之前的问题或之前的答案,需要引入内存。
它的工作流程是:
将之前的对话与新问题合并生成一个完整的查询语句。
在向量数据库中搜索该查询的相关文档。
获取结果后,存储所有答案到对话记忆区。
2.7 Prompt
提示工程也叫「指令工程」:Prompt 就是你发给大模型的指令,比如「讲个笑话」、「用 Python 编个贪吃蛇游戏」等,他给你信息反馈。就像你在智普清言web页面聊天一样,你发出去的每一个聊天语句就是prompt。
2.8 re-ranking
RAG中的re-ranking是一个重要的步骤,用来提高检索结果的相关性。在RAG框架中,首先会检索一批与输入查询相关的文档(或知识片段),然后通过re-ranking模块对这些检索结果进行重新排序,以便更好地服务于随后的生成任务。
2.9 RAG 优化
用户反馈收集、分析在RAG模型生成过程中,哪些检索到的信息块对最终生成的内容贡献最大、RAG模型在检索过程中实际使用了多少检索到的信息块、模型评测。