《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【基于深度学习的车辆检测追踪与流量计数系统】 |
| 49.【基于深度学习的行人检测追踪与双向流量计数系统】 | 50.【基于深度学习的反光衣检测与预警系统】 |
| 51.【基于深度学习的危险区域人员闯入检测与报警系统】 | 52.【基于深度学习的高密度人脸智能检测与统计系统】 |
| 53.【基于深度学习的CT扫描图像肾结石智能检测系统】 | 54.【基于深度学习的水果智能检测系统】 |
| 55.【基于深度学习的水果质量好坏智能检测系统】 | 56.【基于深度学习的蔬菜目标检测与识别系统】 |
| 57.【基于深度学习的非机动车驾驶员头盔检测系统】 | 58.【太基于深度学习的阳能电池板检测与分析系统】 |
| 59.【基于深度学习的工业螺栓螺母检测】 | 60.【基于深度学习的金属焊缝缺陷检测系统】 |
| 61.【基于深度学习的链条缺陷检测与识别系统】 | 62.【基于深度学习的交通信号灯检测识别】 |
| 63.【基于深度学习的草莓成熟度检测与识别系统】 | 64.【基于深度学习的水下海生物检测识别系统】 |
| 65.【基于深度学习的道路交通事故检测识别系统】 | 66.【基于深度学习的安检X光危险品检测与识别系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 什么是数据可视化?
- 数据可视化在机器学习中的重要性
- 用于数据可视化的流行Python库
- 1. Matplotlib
- 2. Seaborn
- 3. Plotly
- 4. Bokeh
- 数据可视化的类型
- 单变量图:独立理解属性
- 直方图
- 密度图
- 箱线图
- 多变量图:多个变量之间的相互作用
- 相关矩阵图
- 散点矩阵图
数据可视化是机器学习(ML)的一个重要方面,因为它有助于分析和传达数据中的模式、趋势和见解。数据可视化涉及创建数据的图形表示,这有助于识别原始数据中可能不明显的模式和关系。
什么是数据可视化?
数据可视化是数据和信息的图形表示。借助数据可视化,我们可以看到数据的外观以及数据属性之间的相关性。这是查看特征是否与输出对应的最快方法。
数据可视化在机器学习中的重要性
数据可视化在机器学习中起着重要的作用。我们可以在机器学习中以多种方式使用它。以下是在机器学习中使用数据可视化的一些方法:
- 数据可视化是探索和理解数据的重要工具。可视化可以帮助识别模式、相关性和离群值,还可以帮助检测数据质量问题,如缺失值和不一致性。
- 特征选择-数据可视化可以帮助为ML模型选择相关特征。通过可视化数据及其与目标变量的关系,您可以识别与目标变量强相关的特征,并排除预测能力很小的不相关特征。
- 模型评估-数据可视化可用于评估ML模型的性能。可视化技术,如ROC曲线、精确度-召回率曲线和混淆矩阵],可以帮助理解模型的准确度、精确度、召回率和F1得分。
- 数据可视化是向可能没有技术背景的利益相关者传达见解和结果的有效方式。散点图、折线图和条形图等可视化工具有助于以易于理解的格式传达复杂的信息。
用于数据可视化的流行Python库
以下是机器学习中用于数据可视化的最流行的Python库。这些库提供了广泛的可视化技术和自定义选项,以满足不同的需求和偏好。
1. Matplotlib
Matplotlib是用于数据可视化的最流行的Python包之一。它是一个跨平台的库,用于从数组中的数据绘制2D图。它提供了一个面向对象的API,有助于使用PyQt、WxPython或Tkinter等Python GUI工具包在应用程序中嵌入绘图。它也可以用于Python和IPython shell,Xboxyter笔记本和Web应用程序服务器。
2. Seaborn
Seaborn是一个开源的,BSD许可的Python库,提供高级API,用于使用Python编程语言可视化数据。
3. Plotly
Plotly是一家位于蒙特利尔的技术计算公司,参与开发数据分析和可视化工具,如Dash和Chart Studio。它还为Python、R、MATLAB、JavaScript和其他计算机编程语言开发了开源图形应用程序编程接口(API)库。
4. Bokeh
Bokeh是Python的数据可视化库。与Matplotlib和Seaborn不同,它们也是用于数据可视化的Python包,Bokeh使用HTML和JavaScript渲染其图。因此,它被证明是非常有用的开发基于Web的仪表板。
数据可视化的类型
机器学习数据的数据可视化可以分为以下两个不同的类别-
- 单变量图
- 多变量图
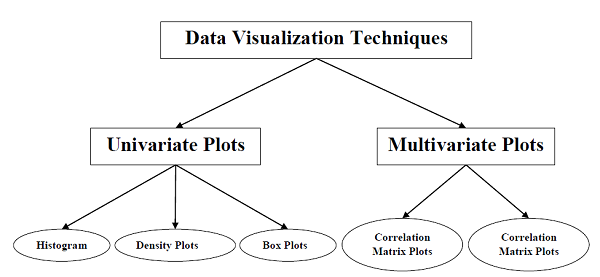
让我们详细了解上述两种类型的数据可视化图。
单变量图:独立理解属性
最简单的可视化类型是单变量或“单变量”可视化。借助单变量可视化,我们可以独立地理解数据集的每个属性。以下是Python中实现单变量可视化的一些技术:
- 直方图
- 密度图
- 盒须图
我们将在各自的章节中详细学习上述技术。让我们简单地看看这些技术。
直方图
直方图将数据分组在bin中,是了解数据集中每个属性分布的最快方法。以下是直方图的一些特征:
- 它为我们提供了为可视化而创建的每个bin中的观测数量的计数。
- 从箱子的形状,我们可以很容易地观察到分布,即,无论它是高斯的、偏斜的还是指数的。
- 直方图还可以帮助我们看到可能的异常值。
例如
下面的代码是一个创建直方图的Python脚本示例。在这里,我们将在NumPy Array上使用hist()函数来生成直方图,并使用matplotlib来绘制它们。
import matplotlib.pyplot as plt
import numpy as np
# Generate some random data
data = np.random.randn(1000)
# Create the histogram
plt.hist(data, bins=30, color='skyblue', edgecolor='black')
plt.xlabel('Values')
plt.ylabel('Frequency')
plt.title('Histogram Example')
plt.show()
输出
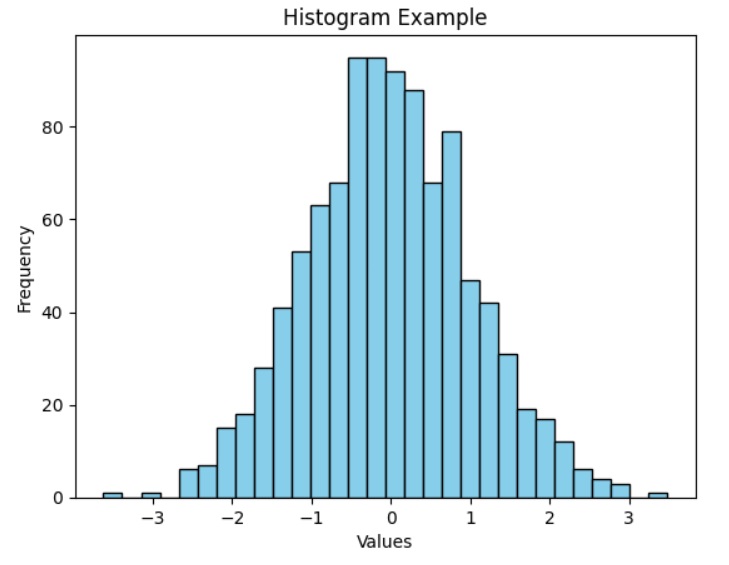
由于随机数生成,您可能会注意到在执行上述程序时输出之间的细微差异。
密度图
密度图是另一种快速简单的技术,用于获得每个属性分布。它也像直方图,但有一个平滑的曲线绘制通过每个箱的顶部。我们可以称之为抽象直方图。
例如
在下面的示例中,Python脚本将为虹膜数据集的属性分布生成密度图。
import seaborn as sns
import matplotlib.pyplot as plt
# Load a sample dataset
df = sns.load_dataset("iris")
# Create the density plot
sns.kdeplot(data=df, x="sepal_length", fill=True)
# Add labels and title
plt.xlabel("Sepal Length")
plt.ylabel("Density")
plt.title("Density Plot of Sepal Length")
# Show the plot
plt.show()
输出
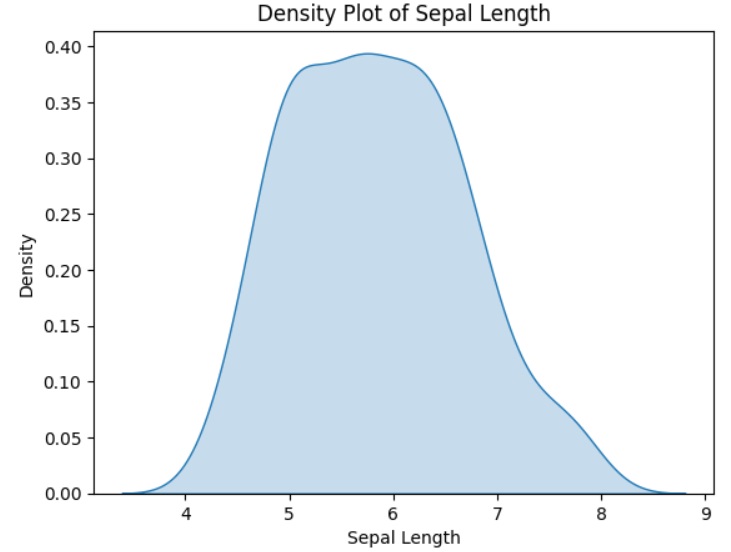
从上面的输出中,可以很容易地理解密度图和直方图之间的差异。
箱线图
箱线图(Box and Whisker Plots),简称箱线图(boxplots),是查看每个属性分布的另一种有用技术。以下是这项技术的特点:
- 它本质上是单变量的,并总结了每个属性的分布。
- 它为中间值绘制了一条线,即中位数。
- 它在25%和75%周围画了一个方框。
- 它还绘制了胡须,这将使我们对数据的传播有一个概念。
- 须线外的点表示离群值。离群值将是中间数据的散布大小的1.5倍。
例如
在下面的示例中,Python脚本将为Iris数据集的属性分布生成一个箱线图。
import matplotlib.pyplot as plt
# Sample data
data = [10, 15, 18, 20, 22, 25, 28, 30, 32, 35]
# Create a figure and axes
fig, ax = plt.subplots()
# Create the boxplot
ax.boxplot(data)
# Set the title
ax.set_title('Box and Whisker Plot')
# Show the plot
plt.show()
输出

多变量图:多个变量之间的相互作用
另一种类型的可视化是多变量或“多元”可视化。借助多变量可视化,我们可以理解数据集的多个属性之间的相互作用。以下是Python中实现多变量可视化的一些技术:
- 相关矩阵图
- 散点矩阵图
相关矩阵图
相关性是两个变量之间变化的指标。我们可以绘制[相关矩阵图],以显示哪个变量与另一个变量具有高或低的相关性。
例如
在下面的示例中,Python脚本将生成一个相关矩阵图。它可以在Pandas DataFrame上的corr()函数的帮助下生成,并在Matplotlib pyplot的帮助下绘制。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Sample data
data = {'A': [1, 2, 3, 4, 5],
'B': [5, 4, 3, 2, 1],
'C': [2, 3, 1, 4, 5]}
df = pd.DataFrame(data)
# Calculate the correlation matrix
c_matrix = df.corr()
# Create a heatmap
sns.heatmap(c_matrix, annot=True, cmap='coolwarm')
plt.title("Correlation Matrix")
plt.show()
输出
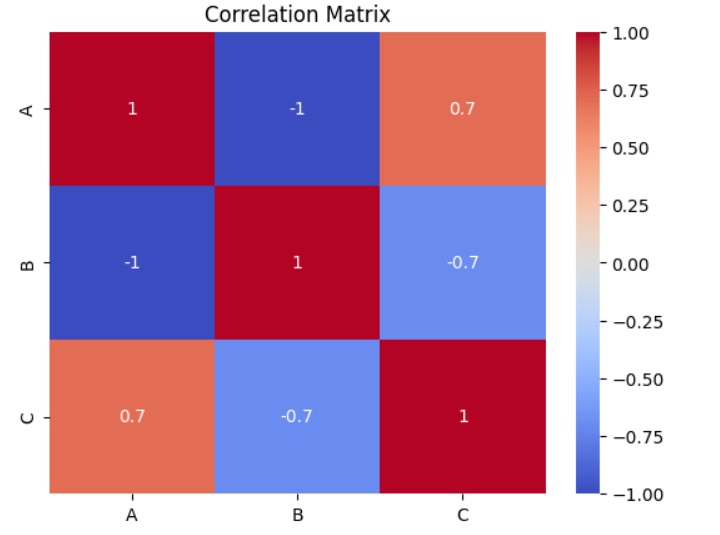
从上面的相关矩阵输出中,我们可以看到它是对称的,即左下角与右上角相同。
散点矩阵图
散点矩阵图显示了一个变量受另一个变量影响的程度或它们之间的关系,并在二维空间中以点的形式显示。散点图在概念上非常类似于线图,它们使用水平轴和垂直轴来绘制数据点。
例如
在下面的示例中,Python脚本将生成并绘制Iris数据集的散点矩阵。它可以在Pandas DataFrame上的scatter_matrix()函数的帮助下生成,并在pyplot的帮助下绘制。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
# Load the iris dataset
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# Create the scatter matrix plot
pd.plotting.scatter_matrix(df, diagonal='hist', figsize=(8, 7))
plt.show()
输出
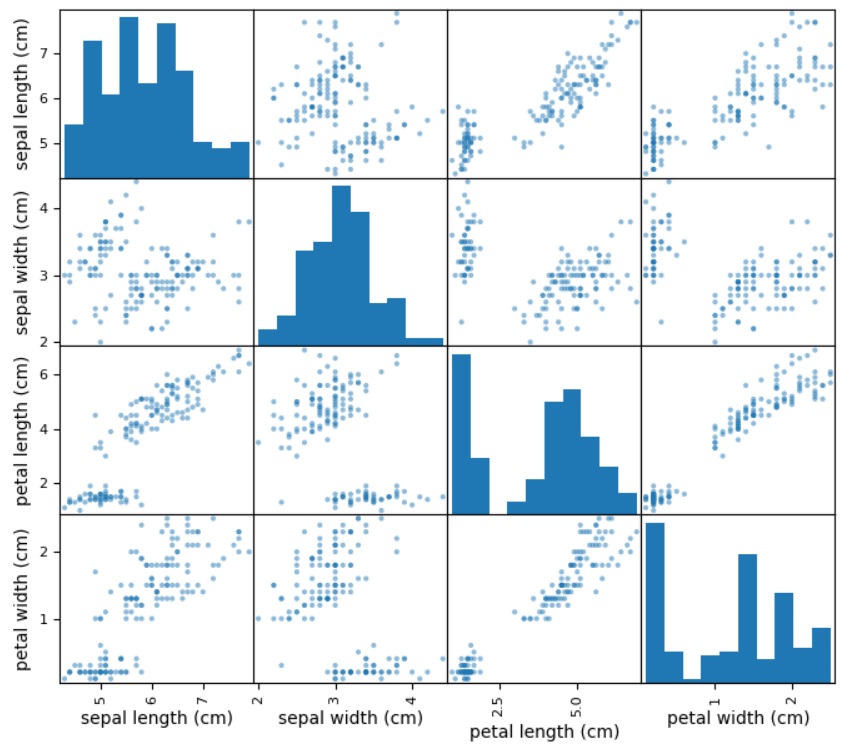


好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!