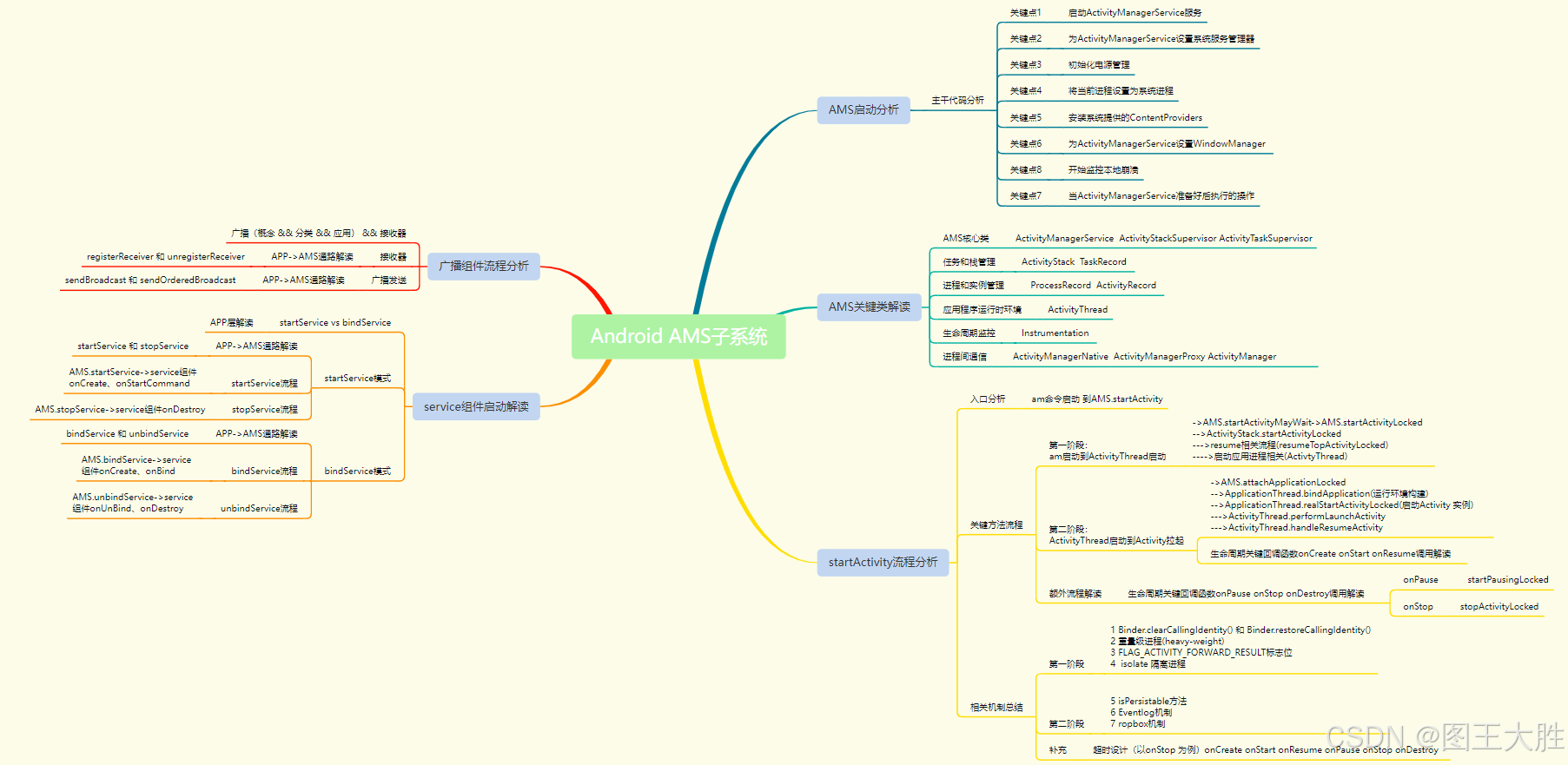
目录
一、单表查询
1. 简单的数据查询
(1)选择表中若干列
(2)选择表中若干行(元祖)
2. 聚合函数与分组查询
聚集函数
GROUP BY分组查询
二、联接查询
1、连接概述
2. 内联接(INNER JOIN)
3. 左外联接(LEFT JOIN 或 LEFT OUTER JOIN)
4. 右外联接(RIGHT JOIN 或 RIGHT OUTER JOIN)
5. 全外联接(FULL JOIN 或 FULL OUTER JOIN)
6. 连接两个以上的表
7.交叉连接(Cross Join)
8. 自联接(Self-Join)
三、集合查询
并集(UNION)
交集(INTERSECT)
差集(EXCEPT)
四、子查询
1.子查询介绍
2. 嵌套子查询
(1) 返回单个值
(2) 返回一个值列表
3.把子查询作为派生表
4. 相关子查询
5. 使用EXISTS操作符
带有EXISTS谓词的子查询
不同形式的查询间的替换
用EXISTS/NOT EXISTS实现全称量词∀(难点)
用EXISTS/NOT EXISTS实现逻辑蕴涵(难点)
五、在查询的基础上创建新表
数据查询操作select语句的格式【总结】
数据查询的语句格式(先大概知道一下要学的整体内容)
SELECT [ALL|DISTINCT] <目标列表达式> [别名], -- 选择列,ALL 所有,DISTINCT 返回唯一记录
[, <目标列表达式> [别名]] … -- 可以选择多个列,并可为每列指定别名
FROM <表名或视图名> [别名], -- 指定数据来源的表或视图,给表/视图起别名
[, <表名或视图名> [别名]] … -- 可从多个表/视图中选择数据,使用逗号分隔
| (<SELECT语句>) [AS] <别名> -- 在 FROM 子句中嵌套其他 SELECT 查询,并为其指定别名
[WHERE <条件表达式>]
-- 可选,用于筛选符合特定条件的记录
[GROUP BY <列名1> [HAVING <条件表达式>]] -- 可选,按指定列进行分组,HAVING 用于对分组后的结果进行筛选
[ORDER BY <列名2> [ASC|DESC]] -- 可选,用于对结果进行排序,ASC 表示升序,DESC 表示降序
LIMIT <行数1> [OFFSET <行数2>]; -- 限制返回的记录数量,OFFSET 指定从哪条记录开始返回SELECT语句:指定要显示的属性列
FROM子句:指定查询对象(基本表或视图)
WHERE子句:指定查询条件
GROUP BY子句:结果按照<列名1>的值进行分组,该属性列值相等的元组为一个组,通常在每组中作用聚集函数。
HAVING短语:只有满足指定条件的组才予以输出
ORDER BY子句:对查询结果表按<列名1>的值的升序或降序排序
LIMIT子句:限制SELECT语句查询结果的数量为<行数1>行,OFFSET <行数2>,表示在计算<行数1>行前忽略<行数2>行
上面内容会在后文详细讲解
一、单表查询
1. 简单的数据查询
(1)选择表中若干列
检索表中的指定列
SELECT 列名1, 列名2, 列名3 -- 选择指定的列
FROM 表名; -- 从指定的表中查询
检索表中的所有列
SELECT * FROM 表名;星号(*)表示选择所有字段
使用计算列
SELECT 列名, 计算表达式 AS 别名 FROM 表名;在SELECT语句中进行计算并为结果指定一个别名
在
SELECT子句中,目标列表达式不仅限于列名,还可以是:
算术表达式:比如
列名1 + 列名2,可以用来进行简单的数学计算。字符串常量:例如,你可以使用字符串直接显示特定信息,如
SELECT 'Hello, World!' AS 问候;。函数:例如聚合函数
COUNT(),SUM(),AVG()等,可以用于数据汇总。
LOWER():字符串函数,接受一个字符串参数并返回该字符串的全部小写形式
GetDate()获取当前日期和时间的函数
(2)选择表中若干行(元祖)
DISTINCT消除重复行
SELECT DISTINCT 列名1, 列名2, ...
FROM 表名;
如果指定了多个列,只有所有列的组合都是相同的,才会被视为重复。DISTINCT 确保查询结果的唯一性。
SELECT ALL:这是SQL查询的默认行为,表示查询结果将包括所有行,不会去除重复的记录。
SELECT DISTINCT:明确要求去除结果中的重复行
TOP n/ TOP n percent限制返回的行数
返回结果集中前 n 行数据
SELECT TOP n 列名1, 列名2, ...
FROM 表名;
返回结果集中前 n 百分比的行数据
SELECT TOP n PERCENT 列名1, 列名2, ...
FROM 表名;
TOP 关键字是能够快速限制结果集的大小,根据需要灵活地获取数据。
ORDER BY 对查询结果排序
SELECT 列名1, 列名2, ...
FROM 表名
ORDER BY 列名1 [ASC|DESC], 列名2 [ASC|DESC], ...;
-
ASC:按升序排序(默认) -
DESC:按降序排序
ORDER BY 子句必须在 SELECT 查询的最后部分
查询满足条件的行
WHERE 子句:用于指定条件,从而筛选出符合条件的行
SELECT 列名1, 列名2, ...
FROM 表名
WHERE 条件;
常用的查询条件
| 查询条件 | 谓词 |
| 比较 | =,>,<,>=,<=,!=,<>,!>,!<;NOT+上述比较运算符 |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE,NOT LIKE |
| 空值 | IS NULL,IS NOT NULL |
| 多重条件 (逻辑运算) | AND,OR,NOT |
比较条件
示例:查询工资大于5000的员工
SELECT *
FROM Employee
WHERE Salary > 5000;
筛选数值范围【BETWEEN ... AND .../NOT BETWEEN ... AND ...】
SELECT 列名1, 列名2, ...
FROM 表名
WHERE 列名 (NOT) BETWEEN 值1 AND 值2;
选择在 (不在)指定范围内的记录,包括边界值
确定集合【IN /NOT IN】
SELECT 列名1, 列名2, ...
FROM 表名
WHERE 列名 (NOT) IN (值1, 值2, ...);
模式匹配【LIKE/NOT LIKE】
SELECT 列名1, 列名2, ...
FROM 表名
WHERE 列名 (NOT) LIKE '匹配串';
匹配串:用于定义搜索模式的字符串,可以是固定字符串,也可以包含通配符
固定字符串:如
DB_Design,表示完全匹配这个字符串。含通配符的字符串:如
DB%或DB_,表示匹配以DB开头的任意字符串,或者是DB后面有一个任意字符的字符串。
通配符

使用换码字符转义通配符
当匹配串中需要包含通配符(如 % 或 _)作为普通字符时,可以使用换码字符(ESCAPE)进行转义
示例 :查询以 DB_ 开头,且倒数第三个字符为 i 的课程的详细情况
SELECT *
FROM Course
WHERE Cname LIKE 'DB\_%i__' ESCAPE '\';
-
第一个
_前面的\将其转义为普通字符,所以这里表示DB_后面可以有任意长度的字符。 -
i后面的两个_没有换码字符,仍作为通配符,表示后面可以有任意单个字符
涉及空值的查询 【 IS NULL/IS NOT NULL】
检查某列的值是否为 NULL。NULL 表示缺失或未知的值
--[例] 查所有有成绩的学生学号和课程号
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;
IS不能用=代替:在 SQL 中,使用=来比较 NULL 值会导致错误,因为 NULL 不是一个具体的值,而是一个表示缺失的状态。因此,应该使用IS NULL或IS NOT NULL。
逻辑运算符
-
AND:返回满足所有条件的行
-
OR:返回满足任一条件的行
-
NOT:返回不满足指定条件的行
求值顺序是:首先计算 NOT 表达式的值,然后计算 AND 表达式的值,最后计算 OR 表达式的值。
2. 聚合函数与分组查询
聚集函数
用于对一组值进行计算,并返回单个值
常见的聚集函数包括:
| 聚集函数 | 说明 | 示例用法 |
| COUNT(*) | 统计结果集中所有元组(行)的个数 | SELECT COUNT(*) FROM 表名; |
| COUNT(DISTINCT 列名) | 统计某列中不同值的个数 | SELECT COUNT(DISTINCT 列名) FROM 表名; |
| COUNT(列名) | 统计某列中所有值的个数 | SELECT COUNT(列名) FROM 表名; |
| SUM(列名) | 计算数值列的总和 | SELECT SUM(列名) FROM 表名; |
| AVG(列名) | 计算数值列的平均值 | SELECT AVG(列名) FROM 表名; |
| MAX(列名) | 求数值列中的最大值 | SELECT MAX(列名) FROM 表名; |
| MIN(列名) | 求数值列中的最小值 | SELECT MIN(列名) FROM 表名; |
GROUP BY分组查询
GROUP BY 子句用于将查询结果按指定的一列或多列的值进行分组。值相等的记录将被归为一组
如果没有使用
GROUP BY,聚集函数将作用于整个查询结果;使用
GROUP BY后,聚集函数将作用于每一个组
SELECT 列名1, 聚集函数(列名2)
FROM 表名
WHERE 条件
GROUP BY 列名1;
只生成一条记录:对于每一组,GROUP BY 子句只返回一条记录,通常是聚集函数的结果。这意味着在结果集中,你无法看到每个组的详细信息,只能看到聚合后的结果
空值作为单独的组:如果对包含空值的字段使用 GROUP BY,NULL 值会被视为一个独立的组。这可能会导致结果中包含意外的组
HAVING 分组结果过滤
HAVING 子句用于对 GROUP BY 分组后的结果进行过滤。它类似于 WHERE 子句,但 HAVING 是在数据分组之后进行过滤的,因此通常与聚集函数一起使用。
SELECT 列名1, 聚集函数(列名2)
FROM 表名
WHERE 条件
GROUP BY 列名1
HAVING 聚集函数(列名2) 过滤条件;
-
HAVING子句用于筛选分组后的结果集,常与聚集函数(如SUM、AVG、COUNT等)一起使用 -
HAVING可以用于那些在WHERE中无法使用的聚集函数
HAVING短语与WHERE子句的区别:
WHERE子句作用于基表或视图,从中选择满足条件的元组。它在聚合操作之前进行筛选。
HAVING短语作用于组,从中选择满足条件的组。它在聚合操作之后进行筛选。
LIMIT子句
LIMIT 子句用于限制查询结果的行数
[LIMIT [number] [OFFSET number]];-
LIMIT:指定要返回的行数
-
OFFSET:可选,指定要忽略的行数
LIMIT n:返回前 n 行结果
SELECT * FROM table_name
LIMIT 10 OFFSET 5; -- 跳过前 5 行,返回接下来的 10 行

【在 SQL Server 中,LIMIT 子句无法直接使用,因为 LIMIT 是 MySQL 等数据库管理系统中的用法,要在 SQL Server 中实现类似的功能,可以使用 TOP 子句或结合 OFFSET 和 FETCH 语句来实现限制返回行数的效果】
二、联接查询
同时涉及两个以上的表的查询
1、连接概述
从多个表中选择指定的字段,将相关数据结合在一起,生成一个单一的结果集。
关键字 JOIN:JOIN 关键字用于指定要连接的表及其连接方式
关键字 ON:ON 关键字用于指定连接条件,即定义如何将一个表中的记录与另一个表中的记录匹配
连接查询可以生成一个包含两个或多个表数据的单个结果集
注意:
所有连接的表必须共同拥有某些字段,这些字段的数据类型必须相同或兼容。确保连接条件能够有效匹配记录
如果连接的表中有相同的字段名,在查询中引用这些字段时必须指定表名,以避免歧义,如:
SELECT a.column_name, b.column_name
FROM table_a a
JOIN table_b b ON a.id = b.id;
连接类型
- 交叉连接:CrossJoin(不太用)
交叉连接返回两个表的笛卡尔积,即每一行来自第一个表都会与每一行来自第二个表相结合,生成所有可能的组合
SELECT *
FROM 表1
CROSS JOIN 表2;
- 内连接: [Inner] Join ( 最常用)
- 外连接:
- 左外连接: Left [Outer] Join
- 右外连接: Right [Outer] Join
- 完全连接: Full [Outer] Join
- 自连接: Self Join
2. 内联接(INNER JOIN)
比较被连接的表共同拥有的字段,将多个表连接起来
SELECT 列名列表
FROM 表名1 [INNER] JOIN 表名2
ON 表名1.列名 <比较运算符> 表名2.列名;
注意事项
-
INNER 可以省略:在 SQL 中,
INNER关键字是可选的,可以直接使用JOIN进行内连接 -
比较运算符:可用的比较运算符包括:
=:等于;>:大于;<:小于;<>:不等于;其他常见运算符(如>=、<=等)
使用 JOIN:
SELECT Student.sno, Student.sname, Sc.cno, Sc.grade
FROM Student
JOIN Sc ON Student.sno = Sc.sno;
如果不使用 JOIN 关键字,可以通过逗号分隔表名并使用 WHERE 子句来进行连接:
SELECT Student.sno, Student.sname, Sc.cno, Sc.grade
FROM Student, Sc
WHERE Student.sno = Sc.sno;
这两个查询在逻辑上是等效的
3. 左外联接(LEFT JOIN 或 LEFT OUTER JOIN)
左外联接返回左表的所有记录以及右表中满足联接条件的记录。右表中没有匹配的记录时,结果中相应的字段将为 NULL。
左连接可以显示左表中所有记录
左连接显示左表中所有的记录,无论其是否在右表中有对应的记录
LEFT OUTER JOIN可以简写为LEFT JOIN,两者功能相同
语法:
SELECT 列名列表
FROM 表名1 LEFT JOIN 表名2
ON 表名1.列名 = 表名2.列名;
示例
数据表结构如下,请查询学生的学号、姓名,所选课 程的课程号和成绩信息(没有选课的学生也显示出来)
Student(sno,sname,ssex,sage,sdept) Sc(sno,cno,grade) Course(cno,cname,cpnoccredit)
将 Student 表和 Sc 表进行左外连接,连接条件为学生的学号
SELECT Student.sno, Student.sname, Sc.cno, Sc.grade
FROM Student LEFT JOIN Sc
ON Student.sno = Sc.sno
- 该查询将返回所有学生的学号和姓名,以及他们所选课程的课程号和成绩。
- 对于没有选课记录的学生,
Sc.cno和Sc.grade将显示为NULL,以表示该学生没有选课
4. 右外联接(RIGHT JOIN 或 RIGHT OUTER JOIN)
用于从两个表中返回符合连接条件的记录,同时也返回右表中不符合条件的记录
右连接可以显示右表中所有记录
右外连接返回右表中的所有记录以及左表中符合连接条件的记录。
对于不满足连接条件的右表记录,左表中的相应字段将显示为空值(NULL)
RIGHT OUTER JOIN可以简写为RIGHT JOIN,两者功能相同。
语法:
SELECT 列名列表
FROM 表名1 RIGHT JOIN 表名2
ON 表名1.列名 = 表名2.列名;
例:数据表结构如下,请用右外连接查询学生的学号、姓名,所选课程的课程号和成绩信息。
Student( sno, sname, ssex, sage, sdept)
Sc( sno, cno, grade)
Course( cno, cname, cpno, ccredit)
select Student. sno, Student. sname, sc. cno, sc. grade
from Student right join Sc
on Student. sno= Sc. sno
内连接与几种外连接的对比
返回结果
内连接(INNER JOIN):
只返回两个表中满足连接条件的记录。
结果集中只包含那些在两个表中都有的匹配行。
左外连接(LEFT JOIN):
返回左表中的所有记录和右表中符合连接条件的记录。
如果左表中的记录在右表中没有匹配,右表的相关字段将显示为
NULL。右外连接(RIGHT JOIN):
返回右表中的所有记录和左表中符合连接条件的记录。
如果右表中的记录在左表中没有匹配,左表的相关字段将显示为
NULL。内连接的结果行数通常不大于外连接的结果行数,因为内连接只返回匹配的记录,而外连接会返回所有记录,包括未匹配的记录
例题:
现有客户表 customers (主键: 客户编号 cid) , 包含10行数据,订单表 orders (外键: 客户编号 cid) , 包含6条数据。执行 sql语句: select* from customers right outer join orders on customers. cid= orders. cid。最多返回 ( ) 条记录。
A 10
B 6
C 4
D 0
5. 全外联接(FULL JOIN 或 FULL OUTER JOIN)
全外联接返回两个表中的所有记录,若没有匹配的记录,结果中相应的字段将为 NULL。
语法:
SELECT 列名
FROM 表1
FULL JOIN 表2 ON 表1.列名 = 表2.列名;
6. 连接两个以上的表
联接任意数目的表都有可能,通过使用共同拥有的字段,任何一个表都可以和其他表联接
为什么要联接两个以上的表
使用多重联接可以从多个表中得到彼此相关的信息
至少有一个表具有外键,把要联接的表按一定关系联系起来,组合键中的每一字段都必须由一个相应的ON子句引用,可以使用WHERE 子句限制结果集所返回的记录
示例:查询哪位顾客 (姓名) 购买了什么产品 (产品名) ,多少数量?
buyers ( buyer id, buyer name)
product( prod id, prod name)
sa les( buyer id , prod id, qty)
SELECT buyer name, prod name, qty FROM buyers
INNER JOIN sales
ON buyers. buyer id = sales. buyer id
INNER JOIN product
ON sales. prod id= product. prod id
7.交叉连接(Cross Join)
交叉连接返回两个表的笛卡尔积,即每一行来自第一个表都会与每一行来自第二个表相结合,生成所有可能的组合
SELECT *
FROM 表1
CROSS JOIN 表2;
8. 自联接(Self-Join)
指对同一个表进行联接操作,将该表的内容通过自身的不同记录进行匹配,通常用于表内的某些记录间需要关联的情况。
(没有SELF JOIN关键字,只需编写一个普通连接,其中连接中涉及的两个表都是同一个表)
自联接可以查询一个表中各记录之间的关系
在 SQL 中,自联接的实现方式是将同一个表分配不同的别名,以便将它视为两个独立的表,使用 JOIN 子句连接这些“虚拟表”。
引用表的两份副本时,必须使用表的别名
生成自联接时,表中每一行都和自身比较一下,并生成重复的记录,使用WHERE子句来消除这些重复记录
例:查询显示拥有相同产品的顾客号及产品号
buyers( buyer id, buyer name)
produce( prod id, prod name)
sales( buyer id, prod id, qty)
SELECT a.buyer_id AS buyer1,a.prod_id,b. buyer_id AS buyer2
FROM sales AS a
JOIN sales AS b
ON a. prod id=b. prod id
WHERE a. buyer_id>b. buyer_id三、集合查询
查询结果的结构完全一致时的两个查询,可以进行并(UNION)、交(INTERSECT)、差(EXCEPT)操作
并集(UNION)
UNION合并结果集
使用UNION语句可以把两个或两个以上的查询产生的结果集合并为一个结果集,去除重复记录。
-- UNION 操作,返回 table1 和 table2 的并集,去重
SELECT id, name FROM table1
UNION
SELECT id, name FROM table2;语法:SELECT ... FROM table1 UNION SELECT ... FROM table2;
如果希望保留重复记录,可以使用 UNION ALL
UNION 与UNION ALL的区别
UNION在进行表联接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。
UNION ALL只是简单的将两个结果合并后就返回。如果需要排序,则要在最后一个有UNION 的子句中使用ORDER BY, 以指定排序方式。
[例]查询计算机科学与技术专业的学生及年龄不大于19岁(包括等于19岁)的学生
SELECT *
FROM Student
WHERE Smajor = '计算机科学与技术'
UNION
SELECT *
FROM Student
WHERE (EXTRACT(YEAR FROM CURRENT_DATE) - EXTRACT(YEAR FROM Sbirthdate)) <= 19;
EXTRACT:一个 SQL 函数,用于从日期或时间值中提取特定部分(如年份、月份、日期等)。
EXTRACT(field FROM source),其中 field 是要提取的时间部分(例如 YEAR-提取年份, MONTH, DAY),source 是包含日期或时间的字段
CURRENT_DATE: SQL 函数,返回当前系统的日期(不包括时间)。常用于查询中获取当前日期,以便与数据库中的日期字段进行比较。
UNION和JOIN的区别
使用操作符 UNION,要求所引用的表必须具有相似的数据类型、相同的字段数,每个查询中的选择列表必须具有相同的顺序。
使用操作符JOIN,只要求联接的表共同拥有某些字段。
用UNION 分解复杂的查询会提高查询速度,而JOIN联接表越多,查询速度越慢。
交集(INTERSECT)
INTERSECT返回由INTERSECT运算符左侧和右侧的查询都返回的所有非重复值
【返回两个查询结果的共有部分,即同时出现在两个结果集中的记录】
语法:SELECT ... FROM table1 INTERSECT SELECT ... FROM table2;
-- INTERSECT 操作,返回 table1 和 table2 的交集
SELECT id, name FROM table1
INTERSECT
SELECT id, name FROM table2;差集(EXCEPT)
EXCEPT 运算符返回由 EXCEPT 运算符左侧的查询返回、而又不包含在右侧查询所返回的值中的所有非重复值
【返回第一个查询结果中存在,但在第二个查询结果中不存在的记录】
语法:SELECT ... FROM table1 EXCEPT SELECT ... FROM table2;
-- EXCEPT 操作,返回 table1 中存在但 table2 中不存在的记录
SELECT id, name FROM table1
EXCEPT
SELECT id, name FROM table2;使用EXCEPT 或INTERSECT比较的结果集必须具有相同的结构。它们的列数必须相同,并且列的数据类型必须兼容。
--【例】查询“Y71714001”号同学选修, “Y71714003”号同学未选的课程的课程号。
select cno
from Sc
where sno='Y71714001'
except
select cno
from Sc
where sno='Y71714003'
四、子查询
1.子查询介绍
子查询是指嵌套在其他 SQL 查询内部的查询,用于返回特定的数据给外部查询使用。
定义
当一个查询语句嵌套在 DML(数据操作语言)语句中时,这个查询语句称为子查询
何时使用
适用于复杂的数据查询场景,尤其是需要多个步骤来获得最终结果的情况
子查询可以帮助分解复杂查询任务
分类
嵌套子查询
相关子查询
SELECT-FROM-WHERE语句——查询块
在子查询的场景中,内部查询(子查询)嵌套在外部查询中,形成一个完整的查询块
子查询是指将一条SELECT语句作为另一条SELECT语句的一部分,外层的SELECT语句被称为外部查询,内层的SELECT语句被称为内部查询 (或子查询) 。
SELECT Sname -- 外部查询:选择学生姓名
FROM Student -- 数据来源:Student 表
WHERE Sno IN -- 条件:学生编号在内部查询的结果中
(SELECT Sno -- 内部查询:选择学生编号
FROM SC -- 数据来源:SC 表
WHERE Cno = '2'); -- 课程编号为 2 的条件
2. 嵌套子查询
———子查询的查询条件不依赖于父查询
嵌套子查询是指子查询的执行不依赖于外部查询的结果,子查询可以独立执行。
它通常在外层查询之前单独执行,然后将结果传递给外层查询使用。执行一次子查询并将结果值代入外部查询中进行评估【内层子查询执行完毕后,再执行外层查询】
(1) 返回单个值
当能确切知道内层查询返回单值时,可用比较运算符 (如: =、 !=、 <、 <=、 >、 >=)使用,该值可以是子查询中使用统计函数得到的值。
示例:查找工资高于公司平均工资的员工。
SELECT emp_name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
SELECT AVG(salary) FROM employees 是一个嵌套子查询,先执行并返回公司平均工资,再由外部查询将 salary 大于该平均工资的员工筛选出来
在 Transact-SQL中,所有使用表达式的地方,都可以使用子查询代替
【当子查询被用作表达式时,子查询可以认为是被当作一个表达式处理并计算】
查询名称为’数据库原理’的书与所有图书的平均价格的差价
SELECT
图书名,
(价格 - (SELECT AVG(价格) FROM 图书)) AS diff
FROM
图书
WHERE
图书名 = '数据库原理及应用';
(SELECT AVG(价格) FROM 图书):这是一个内部子查询,用于计算 图书 表中所有书籍的平均价格
(2) 返回一个值列表
返回一个值列表通常意味着查询需要返回多个行或多个字段的结果
SQL 比较运算符与聚合函数关系:
| 使用形式 | 等同形式 | 意义 |
| >ANY或>SOME | >MIN() | 大于集合中的某个值, 即大于集合中的最小值 |
| <ANY或>SOME | <MAX() | 小于集合中的某个值, 即小于集合中的最大值 |
| >ALL | >MAX() | 大于集合中的每一个, 即大于集合中的最大值 |
| <ALL | <MIN() | 小于集合中的每一个, 即小于集合中的最小值 |
示例
SELECT *
FROM 表名
WHERE 列名 > ANY (SELECT 列名 FROM 其他表);
等同于:
SELECT *
FROM 表名
WHERE 列名 > (SELECT MIN(列名) FROM 其他表);
示例: 查询成绩比“Y71714001”同学的任一门成绩都高的 同学的学号(不用同类科目比较)。
SELECT
sno AS '学号'
FROM
Sc
WHERE
grade > ANY (SELECT grade
FROM Sc
WHERE sno = 'Y71714001');
使用 ANY 使得查询可以检查多个成绩
INvs=:
- 使用
IN时,可以与多个值进行比较,适合子查询返回多个结果的情况。- 使用
=时,子查询只能返回一个结果。如果子查询返回多行,查询将会失败SELECT * FROM 交易 WHERE 股票代码 IN (SELECT 股票名称 FROM 股票 WHERE 交易所 = '上海');
总结:
不相关子查询(嵌套子查询)的执行顺序通常是子查询先执行,然后将结果用于父查询
不相关子查询是独立于父查询的,可以单独执行。它不依赖于父查询的任何列或值
不相关子查询在父查询的每一行中只执行一次,并且其结果在整个查询中保持不变。
不相关子查询可以使用 EXISTS 谓词
3.把子查询作为派生表
子查询不仅可以出现在WHERE子句中,还可以出现在FROM子句中,子查询生成的临时派生表(derived table)成为主查询的查询对象
将子查询作为派生表时,可以在 FROM 子句中嵌入子查询,并为该子查询起一个别名。这样,外层查询可以像操作普通表一样操作这个派生表
SELECT
s.sno AS '学号',
s.grade AS '成绩'
FROM
Sc AS s
JOIN
(SELECT grade
FROM Sc
WHERE sno = 'Y71714001') AS subquery
ON
s.grade > subquery.grade;
派生表的使用使得在同一个查询中可以灵活地引用子查询的结果,便于进行后续的条件筛选。
子查询返回“Y71714001”同学的所有成绩,作为一个临时表 subquery
必须使用别名:派生表一定要取一个别名!!!!
错误查询语句:
SELECT * FROM (SELECT * FROM stumarks WHERE score >= 60)这个查询在子查询中缺少别名。SQL 要求所有的子查询必须有别名
派生表是一个中间结果表,查询完成后派生表将被系统自动清除
4. 相关子查询
——子查询的查询条件依赖于父查询
相关子查询的执行依赖于外部查询的结果,子查询在外层查询的每一行都要执行一次。它们通常与外部查询一起逐行进行,适合需要逐行比较或过滤的场景。
[例]找出每个学生超过他选修的所有课程平均成绩的课程号

SELECT Sno, Cno
FROM SC x
WHERE Grade >=
(SELECT AVG(Grade)
FROM SC y
WHERE y.Sno = x.Sno);
SELECT Sno, Cno FROM SC x:主查询,从 SC 表中选择学生编号(Sno)和课程编号(Cno)
SQL 查询是逐行执行的,主查询会对
SC表中的每一行记录进行检查【SC表中的每一行代表一个学生选修某门课程的成绩】例如:
Sno
Cno
Grade
Y71714001
01
90
...
...
...
主查询会首先从
SC表中取出第一行记录(例如:Y71714001、01、90)
子查询的目的是计算当前学生(即 x 表示的学生)选修的所有课程的平均成绩
SELECT AVG(Grade) FROM SC y WHERE y.Sno = x.Sno:
子查询从 SC 表中选择数据,并用 y 作为别名。
WHERE y.Sno = x.Sno 确保这个子查询只计算和主查询中当前行对应的学生的成绩
主查询继续检查当前记录的 Grade 是否大于等于子查询的结果
条件成立将被选出
主查询接下来会取出第二行记录,子查询会再次计算
【主查询的每一行都会触发一次子查询,对于每一行 SC 表中的记录(对应某个学生选修的课程),查询会计算该学生的所有课程的平均成绩】
相关子查询的执行依赖于外部查询
多数情况下是子查询的WHERE子句中引用了外部查询的表
执行过程
(1)从外层查询中取出一个元组,将元组相关列的值传给内层查询
(2)执行内层查询,得到子查询操作的值
(3)外查询根据子查询返回的结果或结果集得到满足条件的行
(4)然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕
相关子查询:子查询使用了外部查询的列(x.Sno),这使得子查询可以针对每个学生计算其平均成绩。它依赖于外部查询的值
逐行处理:SQL 查询通常是逐行处理的
例:查询每个学生考的最好的那门课程情况,显示学号课程号、成绩
SELECT Sno, Cno, Grade
FROM SC s
WHERE Grade = (
SELECT MAX(Grade)
FROM SC
WHERE Sno = s.Sno
);
5. 使用EXISTS操作符
带有EXISTS谓词的子查询
和相关子查询一起使用,用于限制外部查询,使其结果集符合子查询的条件
EXISTS谓词是一种存在量词,用于判断子查询的结果是否存在数据
带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值"true或逻辑假值“false”
【EXISTS谓词返回的结果为TRUE或FALSE】
若内层查询结果非空,则外层的WHERE子句返回真值【EXISTS返回true】
若内层查询结果为空,则外层的WHERE子句返回假值【EXISTS返回false】
由EXISTS引出的子查询,其目标列表达式通常都用*,因为带EXISTS的子查询只返回真值或假值,EXISTS最终只关心结果的存在性而不是具体的数据内容,给出列名无实际意义【EXISTS谓词关注的只是子查询的结果是否为空】
例如:查询销售过“计算机”的售书网站的编号


SELECT 售书网站编号
FROM 售书
WHERE EXISTS (
SELECT *
FROM 图书
WHERE 图书.图书编号 = 售书.图书编号
AND 图书.书名 LIKE '%计算机%'
);
WHERE EXISTS:检查内层子查询是否返回记录
内层子查询:从图书表中查询,如果当前售书记录的图书编号在图书表中找到,并且对应书名包含“计算机”
例如:查询与“江宏”在同一个学院学习的学生
![]()
SELECT Sno, Sname, Sdept
FROM Student S1
WHERE EXISTS (
SELECT *
FROM Student S2
WHERE S2.Sdept = S1.Sdept
AND S2.Sname = '江宏'
);
在 Student 表中查找与 S1 表中学生相同学院 (Sdept) 且姓名为“江宏”的记录
NOT EXISTS与EXISTS返回的结果相反
NOT EXISTS谓词
若内层查询结果非空,则外层的WHERE子句返回假值
若内层查询结果为空,则外层的WHERE子句返回真值
不同形式的查询间的替换
所有带IN谓词、比较运算符、ANY和ALL谓词的子查询都能用带EXISTS谓词的子查询等价替换
然而,一些带EXISTS或NOTEXISTS谓词的子查询不能被其他形式的子查询等价替换 【EXISTS 和 NOT EXISTS 更关注子查询的结果是否存在,而不是具体的数据内容】
等价替换示例:
比较运算符与 EXISTS 替换
-- 使用比较运算符
SELECT Sno, Sname
FROM Student
WHERE Sage > (SELECT AVG(Sage) FROM Student);
-- 等价使用 EXISTS 的查询
SELECT Sno, Sname
FROM Student S1
WHERE EXISTS (
SELECT *
FROM Student S2
GROUP BY Sdept
HAVING AVG(S2.Sage) < S1.Sage
);
ANY/ALL 与 EXISTS 替换
-- 使用 ANY 的查询
SELECT Sno, Sname
FROM Student
WHERE Sage > ANY (SELECT Sage FROM Student WHERE Sdept = 'CS');
-- 等价使用 EXISTS 的查询
SELECT Sno, Sname
FROM Student S1
WHERE EXISTS (
SELECT *
FROM Student S2
WHERE S2.Sdept = 'CS' AND S1.Sage > S2.Sage
);
用EXISTS/NOT EXISTS实现全称量词∀(难点)
在 SQL 中,由于没有直接的全称量词(∀, for all),可以使用 EXISTS 和 NOT EXISTS 来间接实现全称量词的逻辑
可以把带有全称量词的谓词转换为等价的带有存在量词的谓词

关键在于将“所有”条件转换为“不存在不满足条件的记录”,这种方式可以通过 NOT EXISTS 来实现
[示例]查询选修了全部课程的学生姓名。

要查询选修了所有课程的学生姓名。
换句话说,需要找出那些没有缺失任何一门课程的学生
查询的逻辑没有一门课程不是他(学生)选修的
SELECT Sname
FROM Student
WHERE NOT EXISTS (
SELECT *
FROM Course
WHERE NOT EXISTS (
SELECT *
FROM SC
WHERE SC.Sno = Student.Sno
AND SC.Cno = Course.Cno
)
);
内层 NOT EXISTS 子查询
SELECT *
FROM SC
WHERE SC.Sno = Student.Sno
AND SC.Cno = Course.Cno
目的是验证学生是否选修了特定的课程。如果该学生在选课表 SC 中没有相应的记录,说明学生没有选修当前检查的课程
外层查询从
Student表开始,逐一检查每个学生。对于每个学生,第一层
NOT EXISTS子查询会尝试找出是否有课程没有被选修。对于每一门课程,内层
NOT EXISTS子查询会检查学生是否有选课记录。如果对某门课程,内层查询返回 没有记录(即学生未选修这门课程),则第一层
NOT EXISTS会返回 false,这意味着该学生没有选修所有课程,外层查询将不会返回该学生反之,如果该学生选修了所有课程,第一层
NOT EXISTS会返回 true,该学生的姓名会被包括在外层查询的结果中
用EXISTS/NOT EXISTS实现逻辑蕴涵(难点)
为了用 EXISTS 和 NOT EXISTS 实现逻辑蕴涵,需要利用谓词演算中的等价转换


¬p(p 为假)或 q(q 为真)至少要满足一个条件
在 SQL 中,我们可以使用 EXISTS 和 NOT EXISTS 来模拟这种逻辑关系。我们将把逻辑表达式 p 和 q 转换为对应的 SQL 语句
[示例]查询至少选修了学生201215122选修的全部课程的学生号码。
我们可以将其视为:
-
p: “学生20180002选修了课程y -
q: 学生x选修了课程y -
查询的逻辑表达为: ∀y (p→q)
通过等价变换,不存在这样的课程 y,使得学生 20180002 选修了 y,而学生 x 没有选修 y
SELECT Sno
FROM Student
WHERE NOT EXISTS (
SELECT *
FROM SC SCX
WHERE SCX.Sno = '20180002' -- 选定的学生
AND NOT EXISTS (
SELECT *
FROM SC SCY
WHERE SCY.Sno = Student.Sno -- 当前查询的学生
AND SCY.Cno = SCX.Cno -- 匹配课程
)
);
五、在查询的基础上创建新表
可以通过 SELECT INTO 语句在查询的基础上创建一个新表
SQL 语法格式:
SELECT 列
INTO 新表
FROM 源表
[WHERE 条件1]
[GROUP BY 表达式1]
[HAVING 条件2]
[ORDER BY 表达式2 [ASC | DESC]];
INTO 新表:指定新创建的表的名称。SELECT 查询的结果将被插入到这个新表中
【INTO NewTable】
SELECT StudentID, StudentName
INTO NewStudentsTable
FROM Students
WHERE Age >= 18
ORDER BY StudentName ASC;
从 Students 表中选择 StudentID 和 StudentName 列,只选入年龄大于或等于 18 岁的学生,创建的新表名为 NewStudentsTable,并按学生姓名升序排序
创建的新表结构将基于所选列的数据类型。
数据查询操作select语句的格式【总结】
SELECT [ALL | DISTINCT]
<目标列表达式> [别名] [, <目标列表达式> [别名]] ..
FROM
<表名或视图名> [别名] [, <表名或视图名> [别名]] ..
| (<SELECT语句>)[AS] <别名>
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]]
[ORDER BY <列名2> [ASC | DESC]];
SELECT [ALL | DISTINCT]:
ALL:默认值,表示返回所有记录,包括重复的记录。
DISTINCT:用于去除结果中的重复记录,只返回唯一值。
示例:SELECT DISTINCT column1。
<目标列表达式>:指定要查询的列,可以是单列或多列,甚至是计算表达式。
可以使用 * 选择所有列。
示例:SELECT column1, column2 或 SELECT *。
[别名](可选):为返回的列指定一个别名,使结果更加易读。使用 AS 关键字来定义别名。
示例:SELECT column1 AS Name。
FROM <表名或视图名> [别名]:指定查询的数据来源表或视图。可以为表或视图指定别名以简化查询。
示例:FROM Students AS S。
[, <表名或视图名> [别名]] ..(可选):允许在查询中指定多个表或视图,用逗号分隔,并为每个表或视图指定别名。
示例:FROM Students AS S, Courses AS C。
| (<SELECT语句>)[AS] <别名>(可选):可以在 FROM 子句中使用另一个 SELECT 语句,并为其结果指定别名。
示例:FROM (SELECT column1 FROM table2) AS T。
[WHERE <条件表达式>](可选):用于过滤结果集,只有满足条件的记录才会被返回。
示例:WHERE Age > 18。
[GROUP BY <列名1> [HAVING <条件表达式>]](可选):
GROUP BY 用于对结果集进行分组,通常与聚合函数(如 SUM、COUNT 等)一起使用。
HAVING 用于过滤分组后的结果集,通常与聚合函数结合使用。
示例:GROUP BY Major HAVING COUNT(*) > 1。
[ORDER BY <列名2> [ASC | DESC]](可选):用于对查询结果进行排序,ASC 表示升序,DESC 表示降序。
示例:ORDER BY Name ASC。
- 选用的列必须是数据表中存在的列。
- 使用
GROUP BY时,所有未在聚合函数中的列都必须在GROUP BY子句中列出