文章目录
- 前言
- 一、安装MMSegmentation
- 二、数据集转换
- 1.labelme标签数据转化为voc数据
- 三、训练设置
- 1.建立数据集文件,并存入数据集
- 2.设置训练配置文件
- 四、使用官方权重
- 1、选择预测的方法
- 2、查看方法支持的预训练数据集和权重
- 权重位置
- 找到对应的数据集
- 下载权重
- 3、使用代码进行预测
前言
mmsegmentation
labelme
中文博客:labelme的使用
一、安装MMSegmentation
步骤 0.从官方网站下载并安装 miniconda(https://docs.conda.io/en/latest/miniconda.html)
步骤 1.创建 conda 环境并激活它。
conda create --name openmmlab python=3.8 -y
conda activate openmmlab
步骤 2。按照官方说明安装 PyTorch,例如在 GPU 平台上:
conda install pytorch torchvision -c pytorch
在 CPU 平台上:
conda install pytorch torchvision cpuonly -c pytorch
二、数据集转换
1.labelme标签数据转化为voc数据
可以修改custom_colors 中的颜色,自定义自己的颜色顺序。可以复制替换
labelme:github

#!/usr/bin/env python
# 导入未来模块中的print_function,确保即使在Python 2.x环境下也能使用Python 3.x的print函数特性
from __future__ import print_function
# 导入必要的库
import argparse # 用于解析命令行参数
import glob # 用于查找符合特定规则的文件路径名
import os # 提供了一种方便的使用操作系统功能的方式
import os.path as osp # os.path模块主要用于路径操作
import sys # 提供对一些变量和函数,这些变量和函数与Python解释器紧密相关
import imgviz # 一个用于图像可视化的库
import numpy as np # 用于进行科学计算的基础库
import labelme # 一个图形图像注释工具,用于图像分割等任务
import PIL.Image
custom_colors = {
1: (0, 0, 0), # 黑色 背景色
2: (255, 0, 0), # 红色 第一个类别
3: (0, 255, 0), # 绿色 第二个类别
4: (0, 0, 255), # 蓝色 第三个类别
5: (255, 255, 0), # 黄色
6: (255, 255, 255), # 白色
7: (128, 128, 0), # 黄褐色
8: (0, 255, 255), # 青色(蓝绿色)
9: (255, 0, 255), # 品红色(洋红色)
10: (128, 0, 0), # 深红色(棕色)
11: (0, 128, 0), # 深绿色(橄榄绿)
12: (0, 0, 128), # 深蓝色(海军蓝)
}
def main():
# 创建一个ArgumentParser对象,用于处理命令行参数
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter # 使用帮助信息格式化器
)
# 添加命令行参数
parser.add_argument("input_dir", help="输入注释目录")
parser.add_argument("output_dir", help="输出数据集目录")
parser.add_argument(
"--labels", help="标签文件或逗号分隔的文本", required=True # 必填参数
)
parser.add_argument(
"--noobject", help="不生成对象标签的标志", action="store_true" # 布尔标志
)
parser.add_argument(
"--nonpy", help="不生成.npy文件的标志", action="store_true" # 布尔标志
)
parser.add_argument(
"--noviz", help="禁用可视化的标志", action="store_true" # 布尔标志
)
# 解析命令行参数
args = parser.parse_args()
# 检查输出目录是否存在,如果存在则退出程序
if osp.exists(args.output_dir):
print("输出目录已存在:", args.output_dir)
sys.exit(1)
# 创建必要的目录结构
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
if not args.nonpy:
os.makedirs(osp.join(args.output_dir, "SegmentationClassNpy"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "SegmentationClassVisualization"))
if not args.noobject:
os.makedirs(osp.join(args.output_dir, "SegmentationObject"))
if not args.nonpy:
os.makedirs(osp.join(args.output_dir, "SegmentationObjectNpy"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "SegmentationObjectVisualization"))
print("正在创建数据集:", args.output_dir)
# 读取标签文件或解析标签字符串
if osp.exists(args.labels):
with open(args.labels) as f:
labels = [label.strip() for label in f if label]
else:
labels = [label.strip() for label in args.labels.split(",")]
# 处理标签,生成类名和类ID的映射
class_names = []
class_name_to_id = {}
for i, label in enumerate(labels):
class_id = i - 1 # 类ID从-1开始
class_name = label.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__" # 忽略标签
continue
elif class_id == 0:
assert class_name == "_background_" # 背景标签
class_names.append(class_name)
class_names = tuple(class_names)
print("类名:", class_names)
print("id:", class_name_to_id)
# 提取字典的值(颜色元组的列表)
colors_list = list(custom_colors.values())
# 将颜色列表转换为NumPy数组,指定数据类型为uint8
colormap = np.array(colors_list, dtype=np.uint8)
#colormap = np.array(custom_colors, dtype=np.uint8)
# 保存类名到文件
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("已保存类名:", out_class_names_file)
# 遍历输入目录中的每个JSON文件
for filename in sorted(glob.glob(osp.join(args.input_dir, "*.json"))):
print("正在从:", filename, "生成数据集")
# 加载LabelFile对象
label_file = labelme.LabelFile(filename=filename)
# 提取文件名和生成输出文件的路径
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_clsp_file = osp.join(args.output_dir, "SegmentationClass", base + ".png")
if not args.nonpy:
out_cls_file = osp.join(
args.output_dir, "SegmentationClassNpy", base + ".npy"
)
if not args.noviz:
out_clsv_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
if not args.noobject:
out_insp_file = osp.join(
args.output_dir, "SegmentationObject", base + ".png"
)
if not args.nonpy:
out_ins_file = osp.join(
args.output_dir, "SegmentationObjectNpy", base + ".npy"
)
if not args.noviz:
out_insv_file = osp.join(
args.output_dir,
"SegmentationObjectVisualization",
base + ".jpg",
)
# 加载图像数据
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
# 将形状转换为标签
cls, ins = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
ins[cls == -1] = 0 # 将忽略标签的实例标签设置为0
print("cls:" ,cls)
# 保存类标签
#labelme.utils.lblsave(out_clsp_file, cls)
if osp.splitext(out_clsp_file)[1] != ".png":
out_clsp_file += ".png"
# Assume label ranses [-1, 254] for int32,
# and [0, 255] for uint8 as VOC.
if cls.min() >= -1 and cls.max() < 255:
lbl_pil = PIL.Image.fromarray(cls.astype(np.uint8), mode="P")
#colormap = imgviz.label_colormap()
lbl_pil.putpalette(colormap.flatten())
lbl_pil.save(out_clsp_file)
else:
raise ValueError(
"[%s] Cannot save the pixel-wise class label as PNG. "
"Please consider using the .npy format." % filename
)
if not args.nonpy:
np.save(out_cls_file, cls)
if not args.noviz:
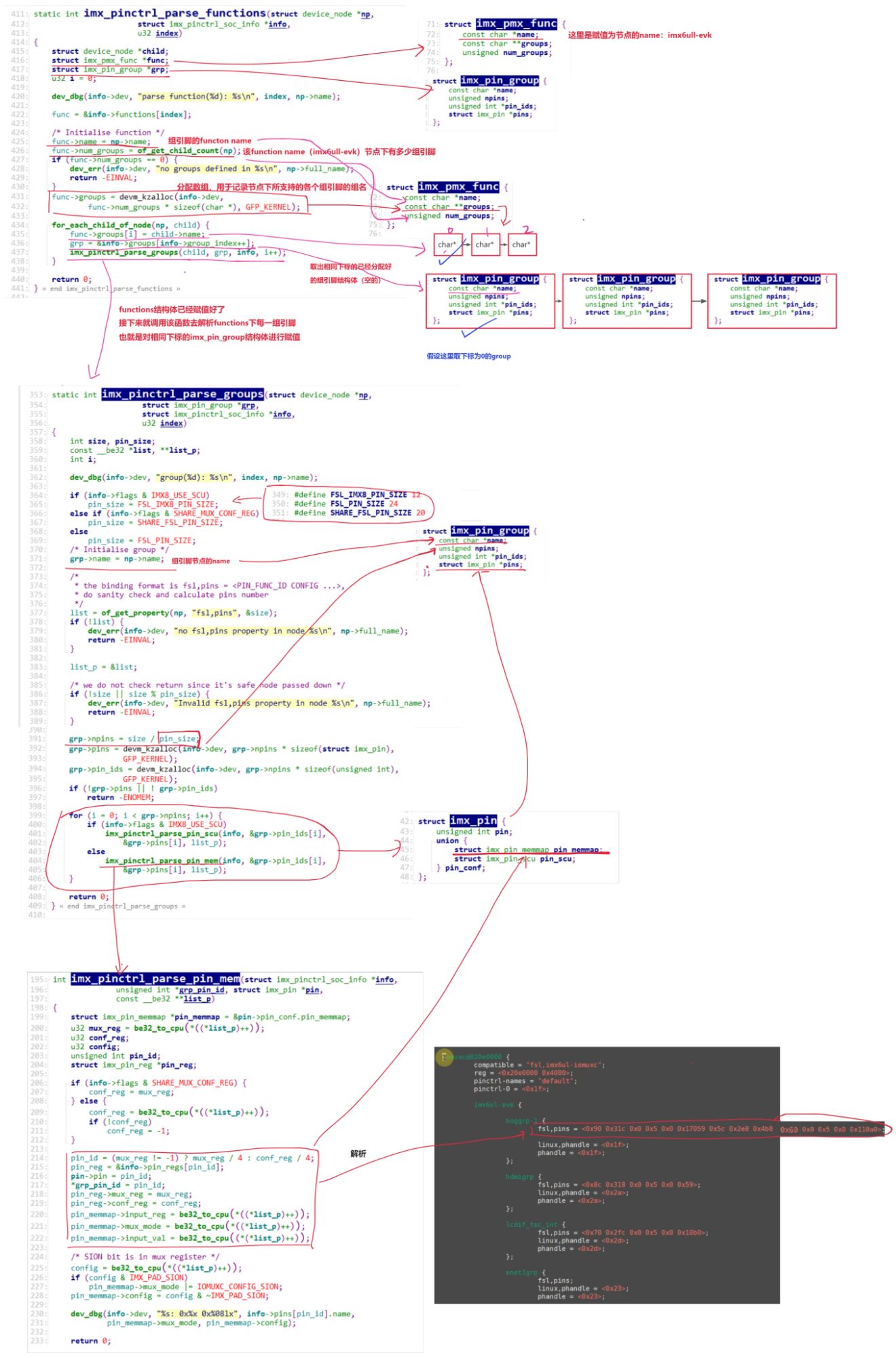
# 可视化类标签
clsv = imgviz.label2rgb(
cls,
imgviz.rgb2gray(img),
label_names=class_names,
colormap=colormap,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_clsv_file, clsv)
if not args.noobject:
# 保存实例标签
labelme.utils.lblsave(out_insp_file, ins)
if not args.nonpy:
np.save(out_ins_file, ins)
if not args.noviz:
# 可视化实例标签
instance_ids = np.unique(ins)
instance_names = [str(i) for i in range(max(instance_ids) + 1)]
insv = imgviz.label2rgb(
ins,
imgviz.rgb2gray(img),
label_names=instance_names,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_insv_file, insv)
if __name__ == "__main__":
main()
执行指令:
python labelme2voc.py br brvoc --labels labels.txt
labelme2voc.py为以上这个python文件
br为自己使用labelme打过标签的数据集
brvoc为VOC数据集格式,需要生成的格式
labels.txt为标签文件
这里我的标签文件

结果:


三、训练设置
1.建立数据集文件,并存入数据集
这里选择以ADE数据集的格式训练DeepLabV3+。
新建一个data文件,二级目录如下,用于存放训练的数据集
mmsegmentation
├── mmseg
├── tools
├── configs
├── data
│ ├── ade
│ │ ├── ADEChallengeData2016
│ │ │ ├── annotations
│ │ │ │ ├── training
│ │ │ │ ├── validation
│ │ │ ├── images
│ │ │ │ ├── training
│ │ │ │ ├── validation
将刚才打过标签的文件分为训练集和测试集

- annotations放的是segmentationclass,分别是训练集和测试集,自己按照自己的需求将训练集分为训练集和测试集


- images放的是原始图片,分别是训练集和测试集


2.设置训练配置文件
选择以下模型文件,该模型文件的位置:

从文件名字可以看出,选择了训练80k次的DeepLabV3+的ADE数据集

这里主要是四个文件:

分别打开这几个文件:
- models/deeplabv3plus_r50-d8.py文件

-
- /schedules/schedule_160k.py文件
可以适当修改总轮数,和保存的参数文件的次数,根据自己的样本调整

- /schedules/schedule_160k.py文件
-
类别颜色设置

将原来的注释掉,更改为自己的颜色和类别:
b5a83fecb908689e.png) -
开始训练,并记住这个位置


修改部分:

点击运行。
四、使用官方权重
1、选择预测的方法
官方支持的方法:github

比如我这里选择DeepLabV3+
2、查看方法支持的预训练数据集和权重
权重位置
找到configs下具体的方法,这里我选择的是DeepLabV3+。

找到对应的数据集

下载权重
这里选择ade20k-512*512的权重

建立一个文件夹存放下载的文件,位置自定义,记住位置就行。命令行执行以下语句,首先的激活你的虚拟环境并安装 mmsegmentation.
conda activate openmmlab
mim download mmsegmentation --config deeplabv3plus_r50-d8_4xb4-160k_ade20k-512x512 --dest .
这里会生成两个文件:

3、使用代码进行预测

这里我填写的位置:

点击运行。