一. 计数器概述
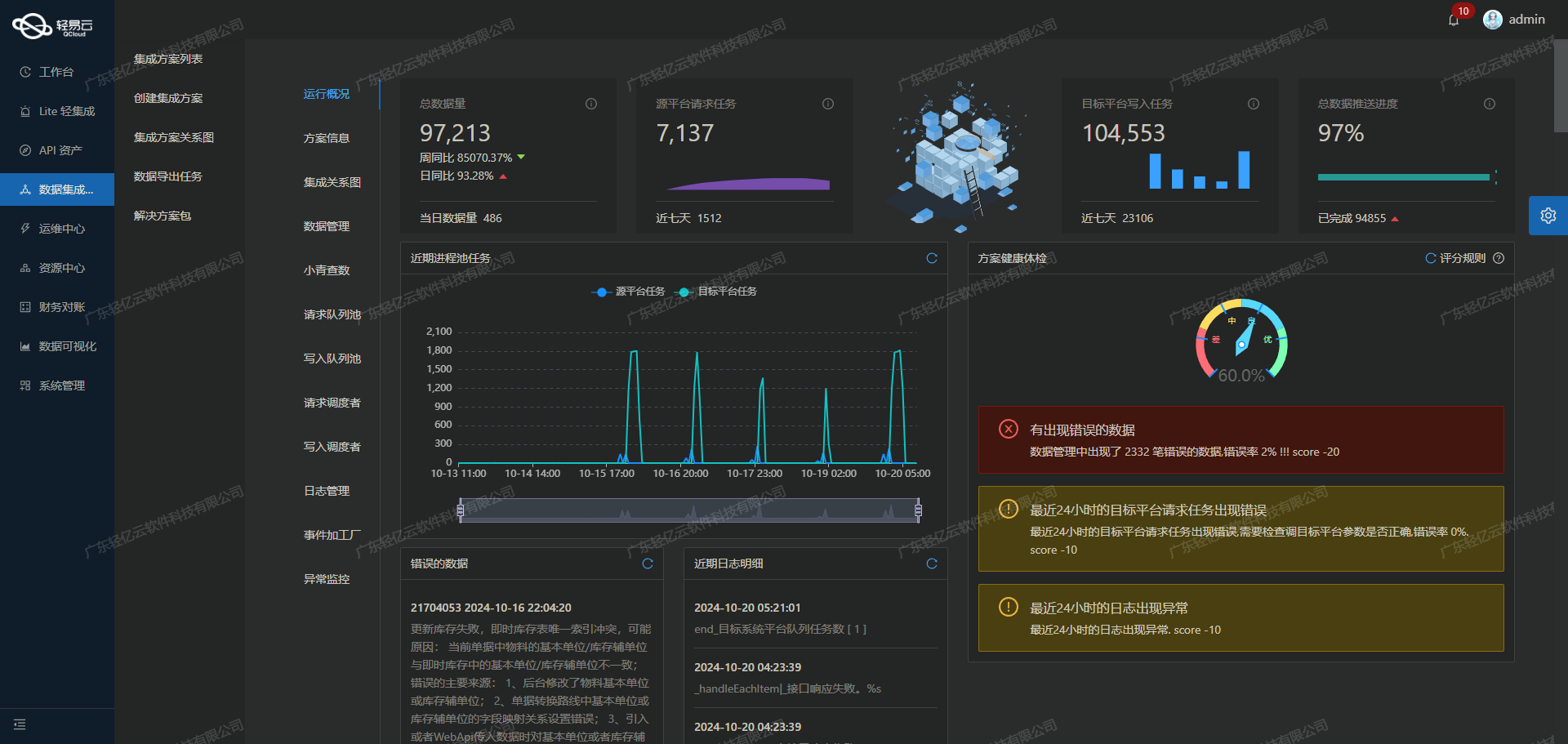
在执行MapReduce程序时,控制台的输出中一般会包含如下内容。

这些输出就是MapReduce的全局计数器的输出信息。计数器是用来记录job的执行进度和状态的,它的作用可以理解为日志,方便用户了解任务的执行状况,辅助用户诊断故障。
常见内置计数器
-
File System Counters:跟踪作业读写的文件系统操作,如HDFS读写字节数。

-
Job Counters:作业相关的统计,如作业的提交数量、耗费的时间。

-
MapReduce Task Counters:Map和Reduce任务的统计,如map/reduce任务的输入输出记录数。

-
File Input | Output Format Counters:跟踪FilelnputFormat读取的字节数或FileOutputFormat输出的字节数。

二. MapReduce自定义计数器
尽管hadoop内置了很多常见的计数器,但是针对一些特定场景,MapReduce也提供了自定义计数器。
自定义计数器的使用分为以下两部:
-
首先通过context.getCounter方法获取一个全局计数器,创建的时候需要指定计数器所属的组名和计数器的名字。

-
在程序中需要使用计数器的地方,调用 counter 提供的方法即可

需求
在wordcount的案例中使用计数器输出文件的行数。
代码实现
package mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMRCounter {
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 从程序上下文对象获取一个全局计数器,并指定计数器组和计数器名字
Counter counter = context.getCounter("own_counter", "line Counter");
String[] words = value.toString().split(" ");
for (String word: words) {
context.write(new Text(word), new IntWritable(1));
}
// 处理完1行,计数器加1
counter.increment(1);
}
}
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountMRCounter.class);
job.setJobName("WordCount");
// 设置输入,输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置Mapper
job.setMapperClass(WordCountMRCounter.WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer
job.setReducerClass(WordCountMRCounter.WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(1);
boolean waitFor = job.waitForCompletion(true);
System.exit(waitFor ? 0 : 1);
}
}
运行结果

# 查看输入文件,恰好也是3行
[root@hadoop1 ~]# hdfs dfs -text /test/a.txt
hello world
name hello
world




![[Linux关键词]unmask,mv,dev/pts,stdin stdout stderr,echo](https://i-blog.csdnimg.cn/direct/6bcaaed367ae416893157b056dcedf28.png)