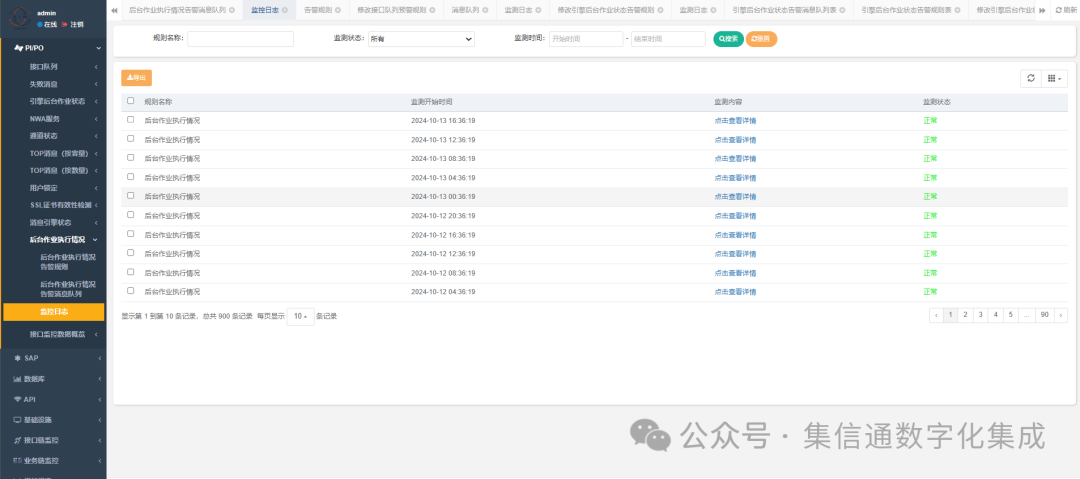
优质博文:IT-BLOG-CN
数据库出海流程
【1】业务出海:1)数据库出海;2)应用出海;3)流量分发;
【2】数据库出海:涉及业务方、信安、DBA和框架组。
数据库出海,流量在国内 --> 应用出海,流量在国内 --> 公有云,灰度流量[GateWay] --> 完成灰度,流量切分完成

注意事项:
【1】若出海的数据分散在多个库,先汇总到一个集群,统一出海;
【2】双向复制时,需要做好流量切分,避免数据复制出现冲突;
【3】保留流量切分到上海的能力,防止复制中断影响业务;
【4】如果相同的数据存在多个更新场景,在并发的情况下还容易产生数据冲突的问题,也需要通过单元化部署避免;
数据同步方案
方案一:手工触发数据迁移,将海外数据迁移到AWS的DB。然后将海外流量从上海机房切换到AWS;

备注 : 灰度过程中一般会分为多个批次进行,每个批次对应的数据和流量,都是重复上述操作;
优点: 流程简单,容易操作,因为操作失误而导致出错的几率极低
缺点1. 增量数据可能丢失:数据迁移的操作,是需要一定的时间才能完成的,而在这一段时间内,可能有用户写入新数据或者修改数据,若修改时间点正好是这条数据已经完成迁移但又在流量切换之前,导致AWS上的数据不是最新数据,即增量数据在AWS上丢失了。问题场景的时序如下:

【1】用户A下单,订单ID=10001,订单状态为S ,此时流量和数据都只是在上海机房;
【2】执行数据迁移,流量仍然指向上海机房,迁移完成后上海机房和AWS的DB都有ID=10001的订单,且订单状态都是S;
【3】用户进行退票操作,由于流量指向上海机房,所以操作后上海机房的DB中订单状态被值为C,而AWS上订单状态还是S;
【4】进行流量切换,将用户A的流量切换到AWS,双边的数据各自保持不变,仍然不一致;
【5】用户进行查询操作,由于流量指向AWS,读取AWS的DB的数据,看到订单状态S。退票操作差生的S-->C的增量变更丢失了;
缺点2. 数据迁移的分批策略需要与流量切换的分批逻辑保持一致:分批多次切换的过程中,每次切换都涉及流量切换和数据迁移,二者的分批逻辑必须保持严格一致。再加上我们的数据多样化,会有多种切换维度和策略,会导致数据迁移工具的实现难度和工作量很大。
缺点3. 无法回切流量到上海机房:数据单向同步到AWS,即灰度过程中AWS上会有全量的数据,但上海机房的AWS数据,会随着切换比例逐渐减少,上海机房将无法处理历史数据的变更,也就无法支持全部的AWS流量。当云上的应用出现流程或者环境问题时,只能是尽量快速解决AWS上的问题,而不能将AWS流量回切到上海。由于上云项目涉及的应用和开发组非常多,大家对公有云的运维经验较少,上线初期出现问题的几率较高,解决问题的速度也可能比较慢,无法将流量回切上海,带来的风险和影响较大。
改进方案一:实时同步数据到AWS
灰度过程中,启用数据同步,将上海的AWS数据全部同步到AWS机房,时间跨度是从灰度开始一直持续到灰度结束。由于增量数据会持续的同步到AWS,AWS上始终是全量的最新数据,避免缺点1的问题;数据同步是同步所有的海外数据,不依赖与流量切换的分批维度,可以直接使用公司通用的数据同步工具,避免缺点2的问题。

缺点: 由于数据同步只是单向的从上海到AWS,仍然无法保证上海是全量的最新数据,缺点3的问题仍然存在,即无法回切流量到上海机房。
改进方案二:双向实时数据同步
灰度过程中,同时启用两个方向的数据同步,不仅将海外数据同步到AWS,也将AWS的海外数据全部同步到上海机房,时间跨度是从灰度开始一直持续到灰度结束。这样,上海机房和AWS机房都有全量的海外数据,可以随时将海外流量切换到AWS,也可以随时回切流量到上海,避免缺点3

缺点 : 双向数据同步可能产生数据冲突,必须对数据写入逻辑进行严格控制,避免冲突。
海外订单号数据库独立部署
目的:海外订单号中存放Location信息,通过订单号就能确定是那个Region的订单,方便保障订单的处理。 产生订单号的数据库,在海外独立部署,和国内订单号数据库不关联。订单号分配逻辑保留海外的可扩展性。
订单号分配基本原则:
【1】全局唯一性:不能出现重复订单号;
【2】趋势递增:有序的主键,保证写入性能;
【3】单调递增:下一个ID一定大于上一个ID;
【4】信息安全:避免让竞争对手获取单量;
数据库多IDC扩展性: 引入RegionCode插入用户数据时增加记录机房标识RegionCode。根据RegionCode确定数据所在Region,使得常用的数据查询或业务处理操作可以在单个节点上执行,以达到数据单元化处理和数据合规策略动态调整的效果,从而避免跨节点带来额外性能消耗和数据跨境合规问题。