通过一段时间的刷题,感觉自己的sql能力逐渐上去,所以不会像前三道题一样讲那么详细了,这里主要会讲到一些特殊的知识点和方法。另外,我的建议是做完一个题有好的想法赶紧记录下来,不要想着最后汇总,不然会懒得整理,也会忘记一些当时才发现的知识点。
------------------------------------------------------------------------------------------------------------------------
1. 不用if的sum
这里的sum(order_date= customer_pref_delivery_date),没有用到if也能用聚集函数sum把满足order_date= customer_pref_delivery_date条件的行数加起来。说明有的时候可以不用if,用if的话还要设置两个正确与否的值,通常是1和0.
select
round(sum(order_date= customer_pref_delivery_date)/count(*)*100,2) immediate_percentage
from
delivery
where
(customer_id,order_date)
in
(select
customer_id, min(order_date)
from
delivery
group by
customer_id);2. 多个列名的in
上面代码的where后面是判断某一行中两列对应的值能否另一个表(这里是个子查询)对上。我们之前往往用到的都是只有一个列,比如where id in (201,203),这里可以很好的扩展思维,个人认为很有用的知识点。
3. datediff的误区
select
activity_date day , count(distinct user_id) active_users
from
activity
where
datediff('2019-07-27',activity_date)<29
group by
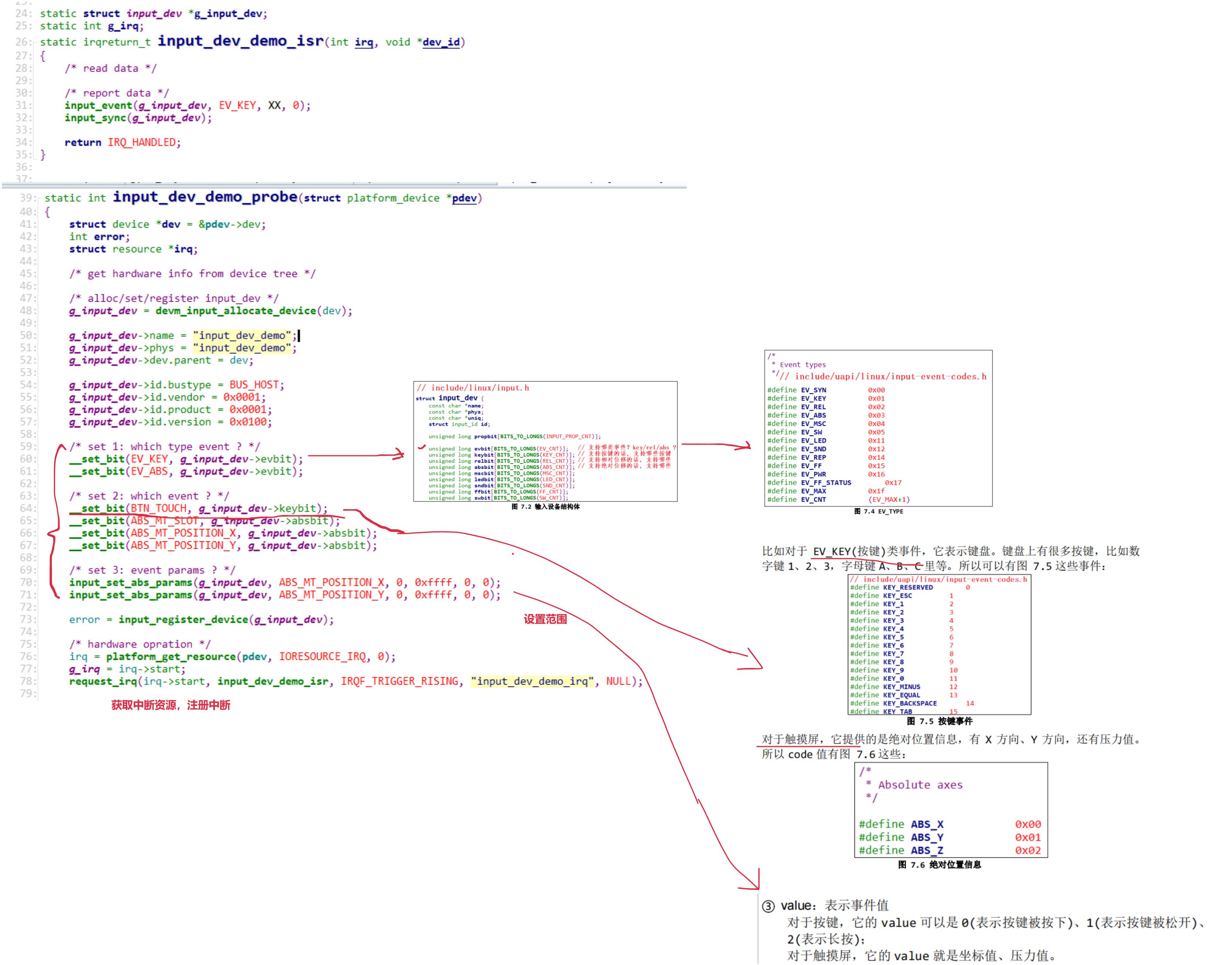
activity_date;这里我想找出activity_date在’2019-07-27’近 30 天的日期,但是后面我发现这是错的,因为没有限制 activity_date 不能超出‘2019-07-27’。这会导致某些未来的日期(如 2019-08-25 和 2021-08-25)也符合条件(做差后为负数,也小于29)。
所以解决这一问题的方法就是用between。between也有两种用法:
activity_date BETWEEN DATE_SUB('2019-07-27', INTERVAL 29 DAY) AND '2019-07-27'
DATEDIFF('2019-07-27', activity_date) BETWEEN 1 AND 29以上两种都可以实现找到近 30 天日期的作用。
******值得一提的是,题目要求近30天,而上面的代码输入的关键字都是29,这点需要注意,因为DATEDIFF() 的结果是天数差,不包括起始日期的那一天。
4. min()求最小日期
MIN()函数:会返回某个列中的最小值,在时间数据上,它返回最早的日期。
select MIN(activity_date) from activity;5. lag()窗口函数
刷题的时候用到了一下,感觉特别好用,再次讲解一下,这次还用到了“PARTITION BY”
LAG() 是 SQL 中的一种窗口函数,用于获取当前行的前一行的值,而无需在查询中自连接。这在需要对比相邻记录(如日期、订单、活动等)时非常有用。
语法如下:
LAG(column_name, [offset], [default_value])
OVER (PARTITION BY partition_column ORDER BY order_column)
实际用例:
| user_id | activity_date | activity_type |
|---|---|---|
| 1 | 2019-07-20 | open_session |
| 1 | 2019-07-21 | send_message |
| 1 | 2019-07-22 | end_session |
| 2 | 2019-07-21 | open_session |
| 2 | 2019-07-23 | end_session |
SELECT
user_id,
activity_date,
activity_type,
LAG(activity_date) OVER (PARTITION BY user_id ORDER BY activity_date) AS previous_activity_date
FROM
activity;
结果:
| user_id | activity_date | activity_type | previous_activity_date |
|---|---|---|---|
| 1 | 2019-07-20 | open_session | NULL |
| 1 | 2019-07-21 | send_message | 2019-07-20 |
| 1 | 2019-07-22 | end_session | 2019-07-21 |
| 2 | 2019-07-21 | open_session | NULL |
| 2 | 2019-07-23 | end_session | 2019-07-21 |
有的时候还是能发挥一定的作用。
6.筛选部分组内数据满足条件的分组
例题:编写解决方案,报告 2019年春季 才售出的产品。即 仅 在 2019-01-01 (含)至 2019-03-31 (含)之间出售的商品。
输入: Product table: +------------+--------------+------------+ | product_id | product_name | unit_price | +------------+--------------+------------+ | 1 | S8 | 1000 | | 2 | G4 | 800 | | 3 | iPhone | 1400 | +------------+--------------+------------+ table: +-----------+------------+----------+------------+----------+-------+ | seller_id | product_id | buyer_id | sale_date | quantity | price | +-----------+------------+----------+------------+----------+-------+ | 1 | 1 | 1 | 2019-01-21 | 2 | 2000 | | 1 | 2 | 2 | 2019-02-17 | 1 | 800 | | 2 | 2 | 3 | 2019-06-02 | 1 | 800 | | 3 | 3 | 4 | 2019-05-13 | 2 | 2800 | +-----------+------------+----------+------------+----------+-------+ 输出: +-------------+--------------+ | product_id | product_name | +-------------+--------------+ | 1 | S8 | +-------------+--------------+
刚开始我写的代码如下:
select
p.product_id, p.product_name
from
product p
join
sales s
on
p.product_id = s.product_id
and
date(s.sale_date) between '2019-01-01' and '2019-03-31'; 上面代码利用简单联结找出sale_date在2019-01-01到2019-03-31,这样会返回错误的结果,因为产品2不仅在这个区间里出售了,在其他区间也出售了,没有实现“仅”的目的。
后面使用分组(group by+having)的办法,比较巧妙的解决了这一问题,即对该组内所有数据都进行验证,排除这种有的满足、有的不满足的数据,却加入了要求所有数据满足的分组里面。
# Write your MySQL query statement below
select
p.product_id, p.product_name
from
product p
join
sales s
on
p.product_id = s.product_id
group by
p.product_id, p.product_name
having
min(sale_date) >= '2019-01-01' and max(sale_date) <= '2019-03-31';即GROUP BY + HAVING:适用于简单的按组汇总,并进行唯一性判断。
7. distinct在多列上的的使用
DISTINCT 是 SQL 中的关键字,用于去除查询结果中的重复行,返回唯一值。它通常用于 SELECT 语句中,确保查询的结果集中不包含重复的数据。
这里DISTINCT 不仅可以应用于单列,也可以用于多个列(放在多个列名的最前面),它会返回这些列的组合的唯一值。
SELECT DISTINCT product_id FROM sales;
SELECT DISTINCT product_id, buyer_id FROM sales;
---------------------------------------------------------------------------------------------------------------------------------例题: 一个员工可以属于多个部门。当一个员工加入超过一个部门的时候,他需要决定哪个部门是他的直属部门。请注意,当员工只加入一个部门的时候,那这个部门将默认为他的直属部门,虽然表记录的值为'N'.
输入: Employee table: +-------------+---------------+--------------+ | employee_id | department_id | primary_flag | +-------------+---------------+--------------+ | 1 | 1 | N | | 2 | 1 | Y | | 2 | 2 | N | | 3 | 3 | N | | 4 | 2 | N | | 4 | 3 | Y | | 4 | 4 | N | +-------------+---------------+--------------+ 输出: +-------------+---------------+ | employee_id | department_id | +-------------+---------------+ | 1 | 1 | | 2 | 1 | | 3 | 3 | | 4 | 3 | +-------------+---------------+
这题我写了很长串,思路是先把有“Y”的分一组,然后其他没“Y”就是只有一行的分一组,然后拼起来。我觉得太长,而gpt给出了两种方法,可以来学习一下。(gpt懂得太多了,有能借鉴而且实用的才拿出来记录下。)
8. max()配合case求出分组中某个符合条件的值
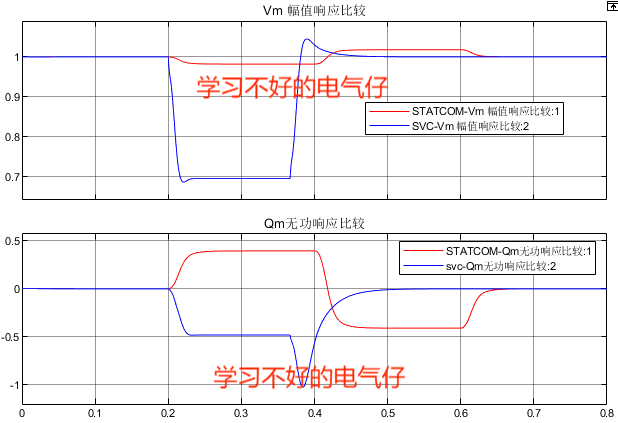
如图所示,下面是上一题的更优解,这里用到了一些配合。
SELECT
employee_id,
COALESCE(
MAX(CASE WHEN primary_flag = 'Y' THEN department_id ELSE NULL END),
MAX(department_id)
) AS department_id
FROM
employee
GROUP BY
employee_id;首先来个错误示范(我写的):
SELECT
employee_id,
if(primary_flag='Y',department_id,null) department_id
FROM
employee
GROUP BY
employee_id;代码意思好像要求把分组后primary_flag='Y'的department_id值打印出来,结果如图:

employee_id为1和3返回null正常,它们没有符合primary_flag='Y'条件的行,但employee_id为4有满足条件的行,但也返回null,说明语法还是有问题,貌似这里只会判断每一组的第一行是否满足rimary_flag='Y'条件,所有2有返回值,4返回null
这里就要配合max()函数了,MAX(CASE WHEN primary_flag = 'Y' THEN department_id ELSE NULL END),这里if和case差别不大,作用都一样,条件语句把每一组的每一行判断条件后每一行都会得到要么是一个数值,要么是null,用max()比较数值和null后,就能让那个合适的返回值返回出来了。
这里加上max()函数后,2和4就能正常返回正确的department_id值了,但1和3依旧返回null,因为它们压根没有primary_flag='Y'条件的行啊。为了满足题意,即只有一行时,不管primary_flag='Y'条件是否成立,都返回其department_id,那还要配合COALESCE()。
9.COALESCE()
COALESCE() 是 SQL 中的一个非常实用的空值处理函数,用于返回第一个非 NULL 的值。它的主要作用是提供一个默认值,避免返回 NULL 结果。这个函数在处理缺失数据、替代空值、进行多层判断时非常有用。coalesce(合并的意思)
COALESCE(value1, value2, ..., valueN)
下面的代码当employee_id的1、3的max()配合case依然返回null后,直接返回其department_id,这个不是null,直接返回。
COALESCE(
MAX(CASE WHEN primary_flag = 'Y' THEN department_id ELSE NULL END),
department_id
)
8、9的总结:希望能很好地帮助到以后对某个列分组后求另外一个列符合条件的值。
10. ROW_NUMBER()
依然是刚才那题,看一下另一种思路:
WITH ranked_departments AS (
SELECT
employee_id,
department_id,
ROW_NUMBER() OVER (
PARTITION BY employee_id
ORDER BY primary_flag DESC
) AS rn
FROM
employee
)
SELECT
employee_id,
department_id
FROM
ranked_departments
WHERE
rn = 1;
这些代码的思路大概是:用到了一个类似子表的东西,同时自己设置了一列,这一列是利用ROW_NUMBER(),根据employee_id分区,然后通过primary_flag这一列来排序最终设计得到,最后在新表中根据新得到的这一列,取出新列中所有编号为1的employee_id, department_id.
这里的语法和之前的lag()函数一样。
ROW_NUMBER() 是 SQL 中的一个窗口函数,用于为查询结果中的每一行分配一个唯一的编号,这个编号通常按某种顺序排列(如时间、ID等)。它常用于需要按某种顺序进行排序、排名或者找出每个分组的第一条或最后一条记录的场景。
ROW_NUMBER() OVER (PARTITION BY partition_column ORDER BY order_column)
这种编号后提取指定编号的思维值得学习。









![[论文笔记]ColPali: Efficient Document Retrieval with Vision Language Models](https://img-blog.csdnimg.cn/img_convert/a32b7de4368bf36a9efefed05da80b82.png)