李宏毅深度强化学习 笔记
课程主页:NTU-MLDS18
视频:youtube B站
参考资料: 作业代码参考 纯numpy实现非Deep的RL算法 OpenAI tutorial
文章目录
- 李宏毅深度强化学习 笔记
- 1. Introduction
- 2. Policy Gradient
- 2.1 Origin Policy Gradient
- 2.2 PPO
- 3. Q - Learning
- 3.1 Q-learning
- 3.2 Tips of Q-learning
- 3.3 Q-learning in continuous actions
- 4. Actor Critic
- 4.1 Advantage Actor-Critic (A2C)
- 4.2 Asynchronous Advantage Actor-Critic (A3C)
- 4.3 Pathwise Derivative Policy Gradient (PDPG)
- 5. Sparse Reward
- 5.1 Reward Shaping
- 5.2 Curiosity
- 5.3 Curriculum Learning
- 5.4 Hierarchical RL
- 6. Imitation Learning
- 6.1 Behavior Cloning
- 6.2 Inverse RL
1. Introduction
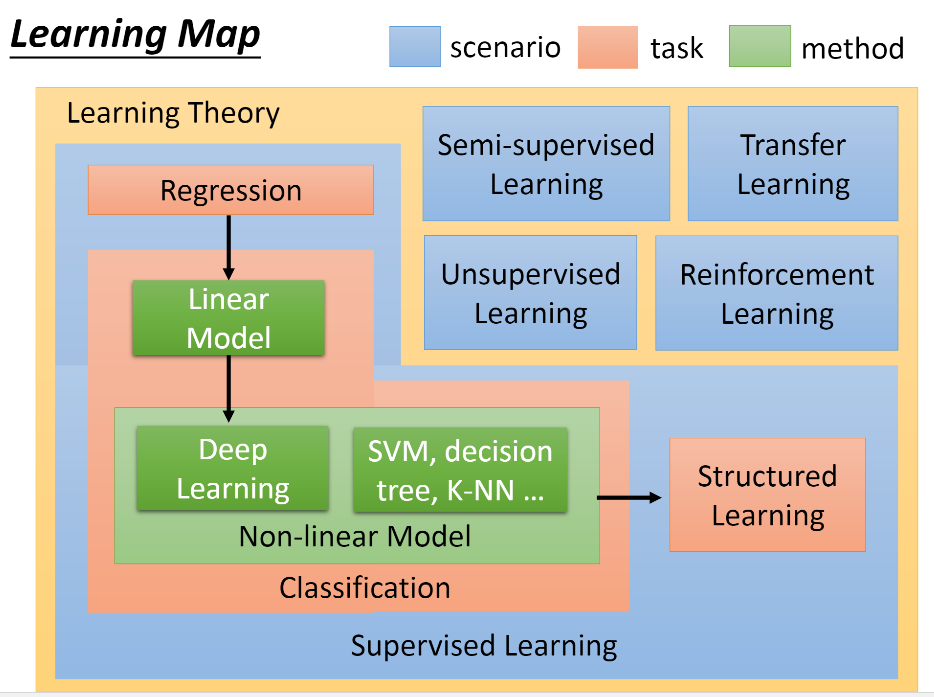
这门课的学习路线如上,强化学习是作为单独一个模块介绍。李宏毅老师讲这门课不是从MDP开始讲起,而是从如何获得最大化奖励出发,直接引出Policy Gradient(以及PPO),再讲Q-learning(原始Q-learning,DQN,各种DQN的升级),然后是A2C(以及A3C, DDPG),紧接着介绍了一些Reward Shaping的方法(主要是Curiosity,Curriculum Learning ,Hierarchical RL),最后介绍Imitation Learning (Inverse RL)。比较全面的展现了深度强化学习的核心内容,也比较直观。
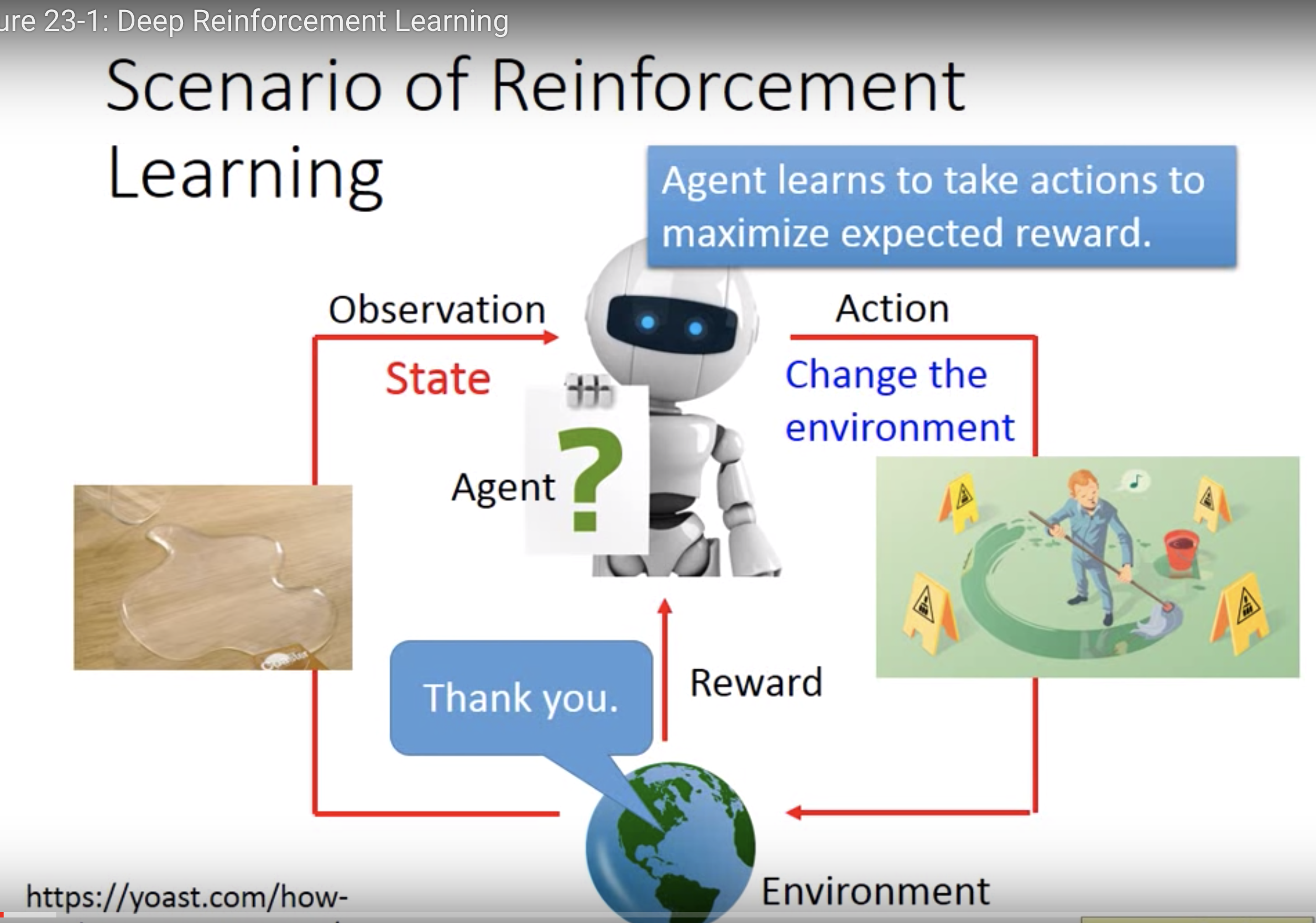
首先强化学习是一种解决序列决策问题的方法,他是通过与环境交互进行学习。首先会有一个Env,给agent一个state,agent根据得到的state执行一个action,这个action会改变Env,使自己跳转到下一个state,同时Env会反馈给agent一个reward,agent学习的目标就是通过采取action,使得reward的期望最大化。
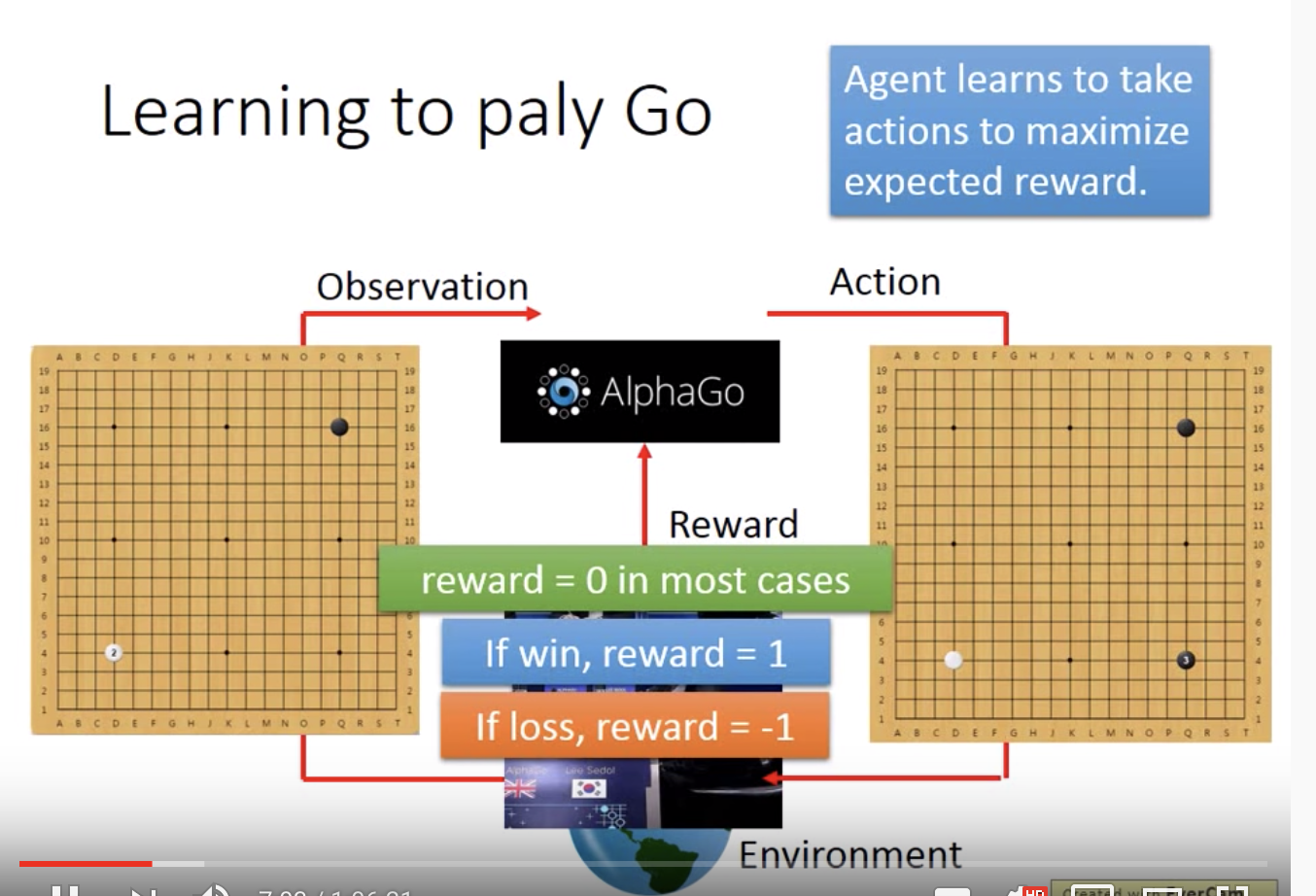
在alpha go的例子中,state(又称observation)为所看到的棋盘,action就是落子,reward通过围棋的规则给出,如果最终赢了,得1,输了,得-1。
下面从2个例子中看强化学习与有监督学习的区别。RL不需要给定标签,但需要有reward。

实际上alphgo是从提前收集的数据上进行有监督学习,效果不错后,再去做强化学习,提高水平。
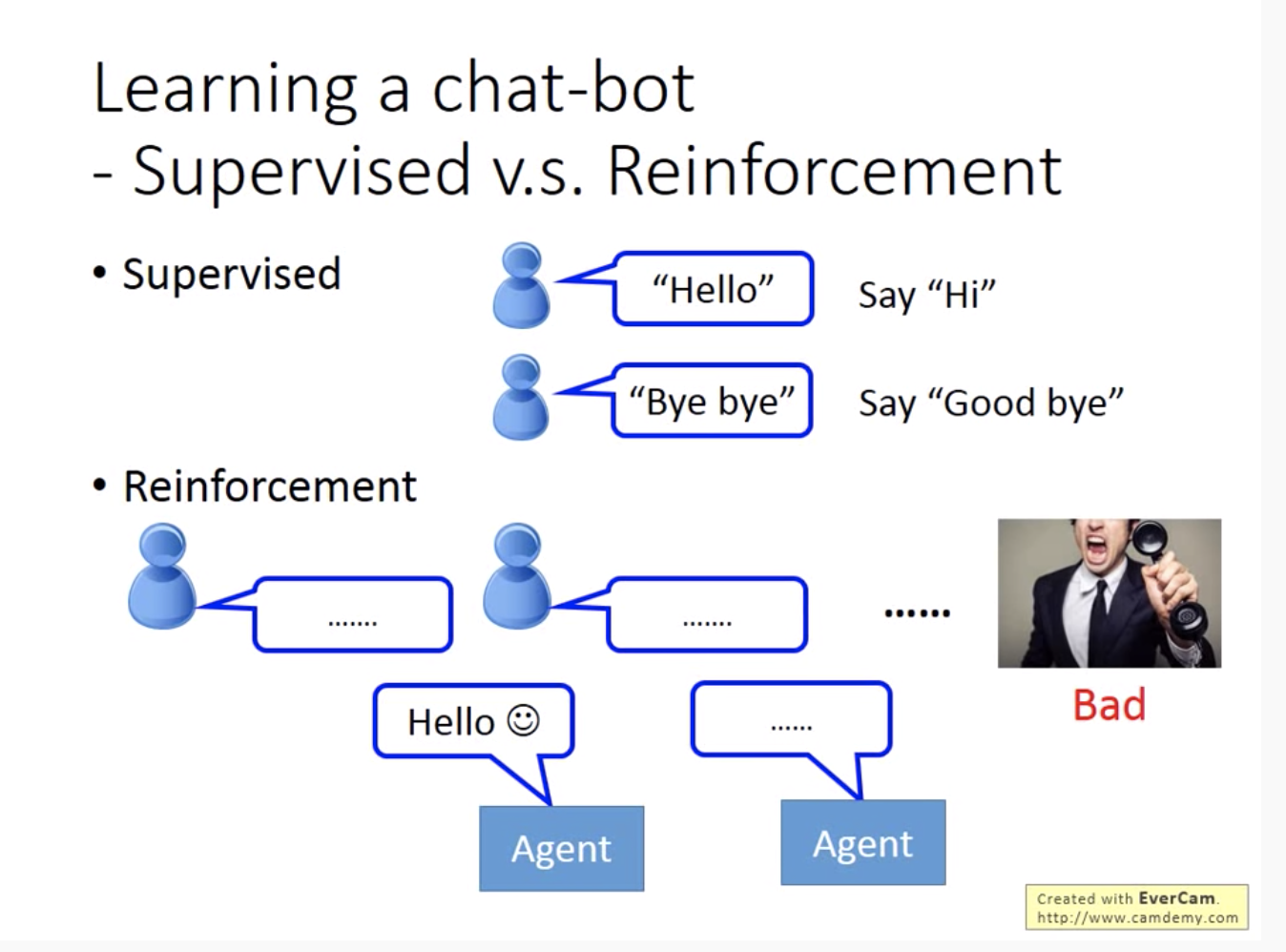
人没有告诉机器人具体哪里说错了,机器需要根据最终的评价自己总结,一般需要对话好多次。所以通常训练对话模型会训练2个agent互相对话


一个难点是怎么判断对话的效果,一般会设置一些预先定义的规则。

强化学习还有很多成功的应用,凡是序列决策问题,大多数可以用RL解决。
2. Policy Gradient
2.1 Origin Policy Gradient
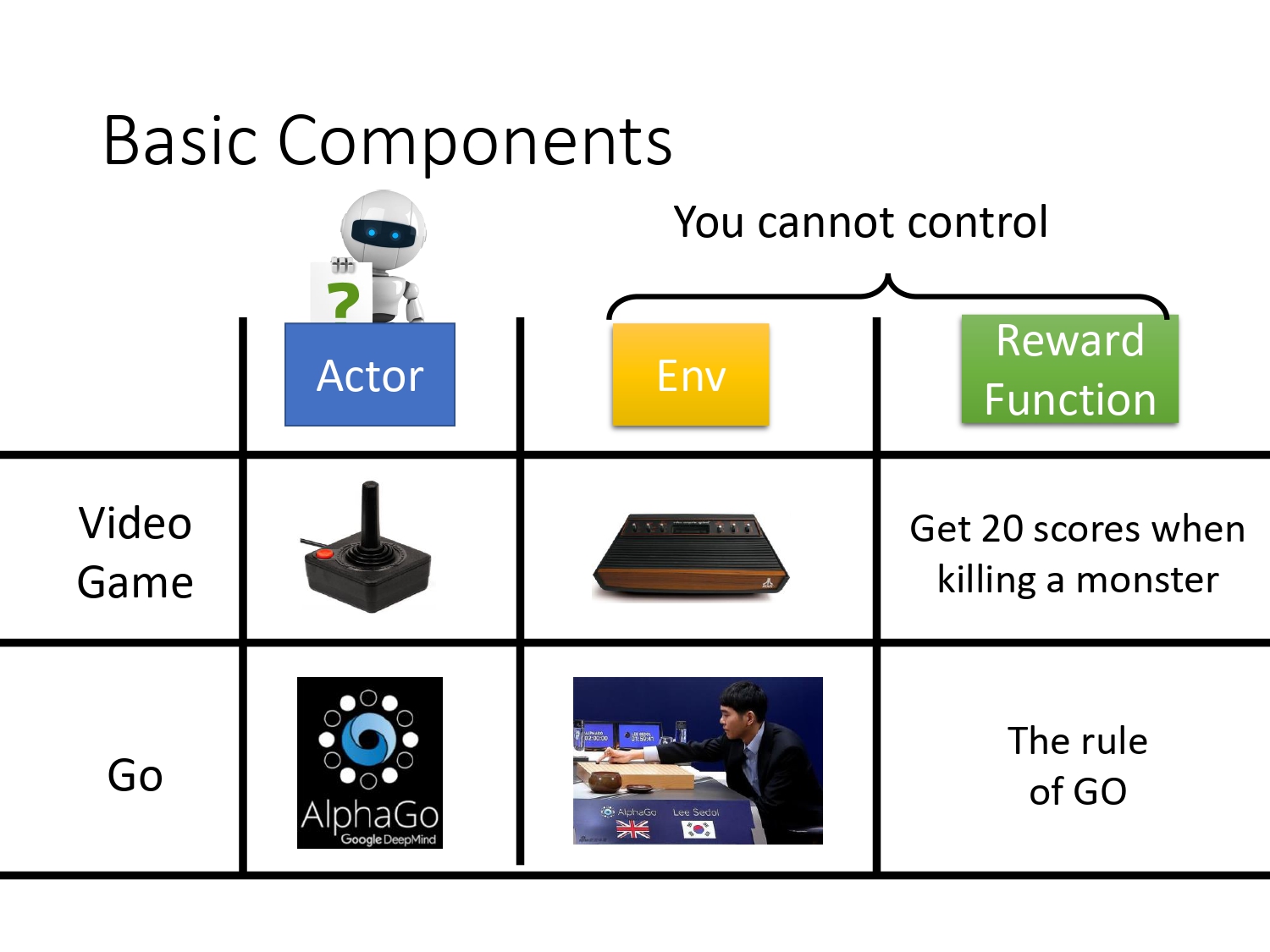
在alpha go场景中,actor决定下哪个位置,env就是你的对手,reward是围棋的规则。强化学习三大基本组件里面,env和reward是事先给定的,我们唯一能做的就是通过调整actor,使得到的累积reward最大化。
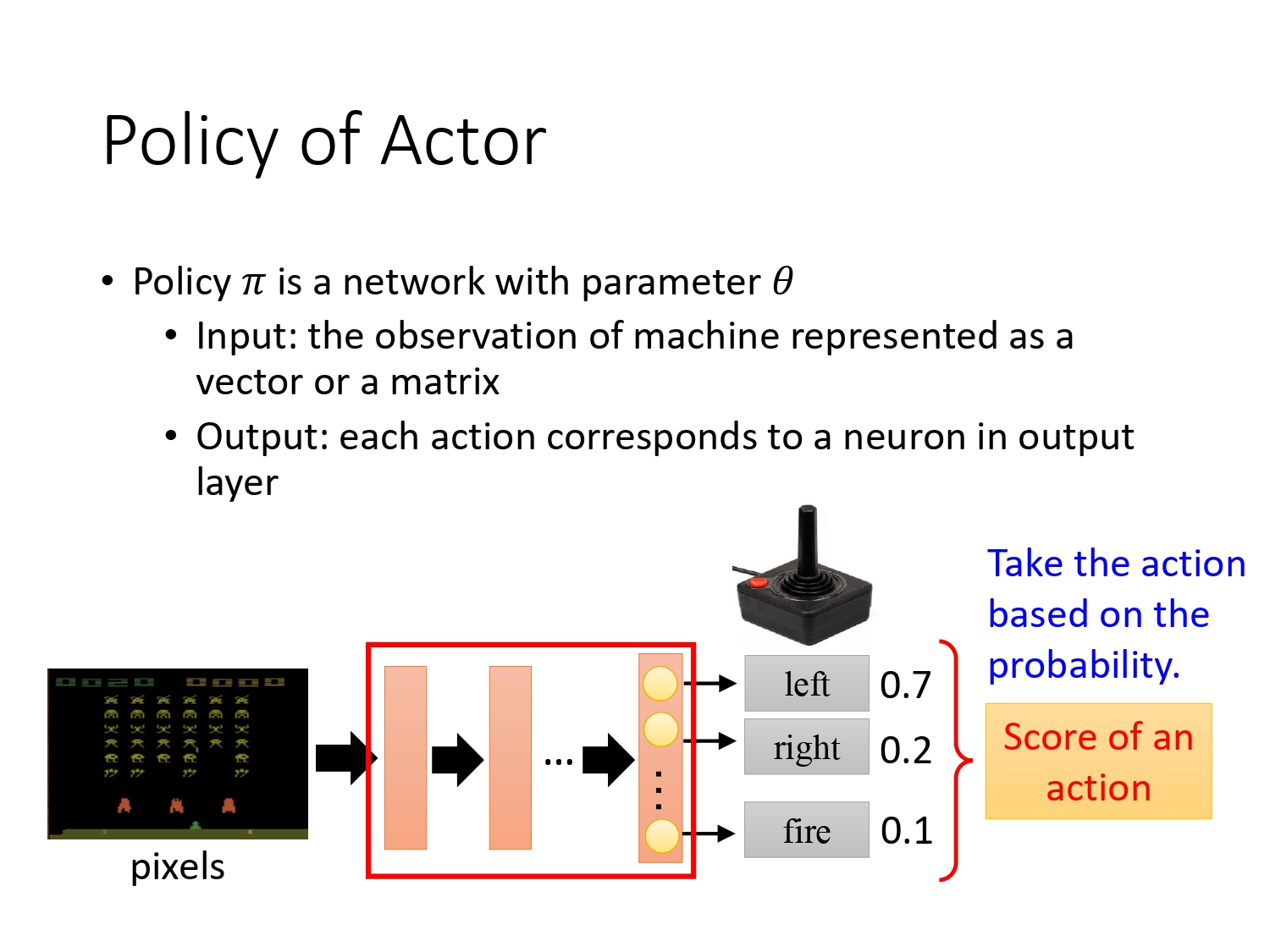
一般把actor的策略定义成Policy,数学符号为 π \pi π,参数是 θ \theta θ,本质是一个NN(神经网络)。
那么针对Atari游戏:输入游戏的画面,Policy π \pi π输出各个动作的概率,agent根据这个概率分布采取行动。通过调整 θ \theta θ, 我们就可以调整策略的输出。
 _page-0007)
_page-0007)
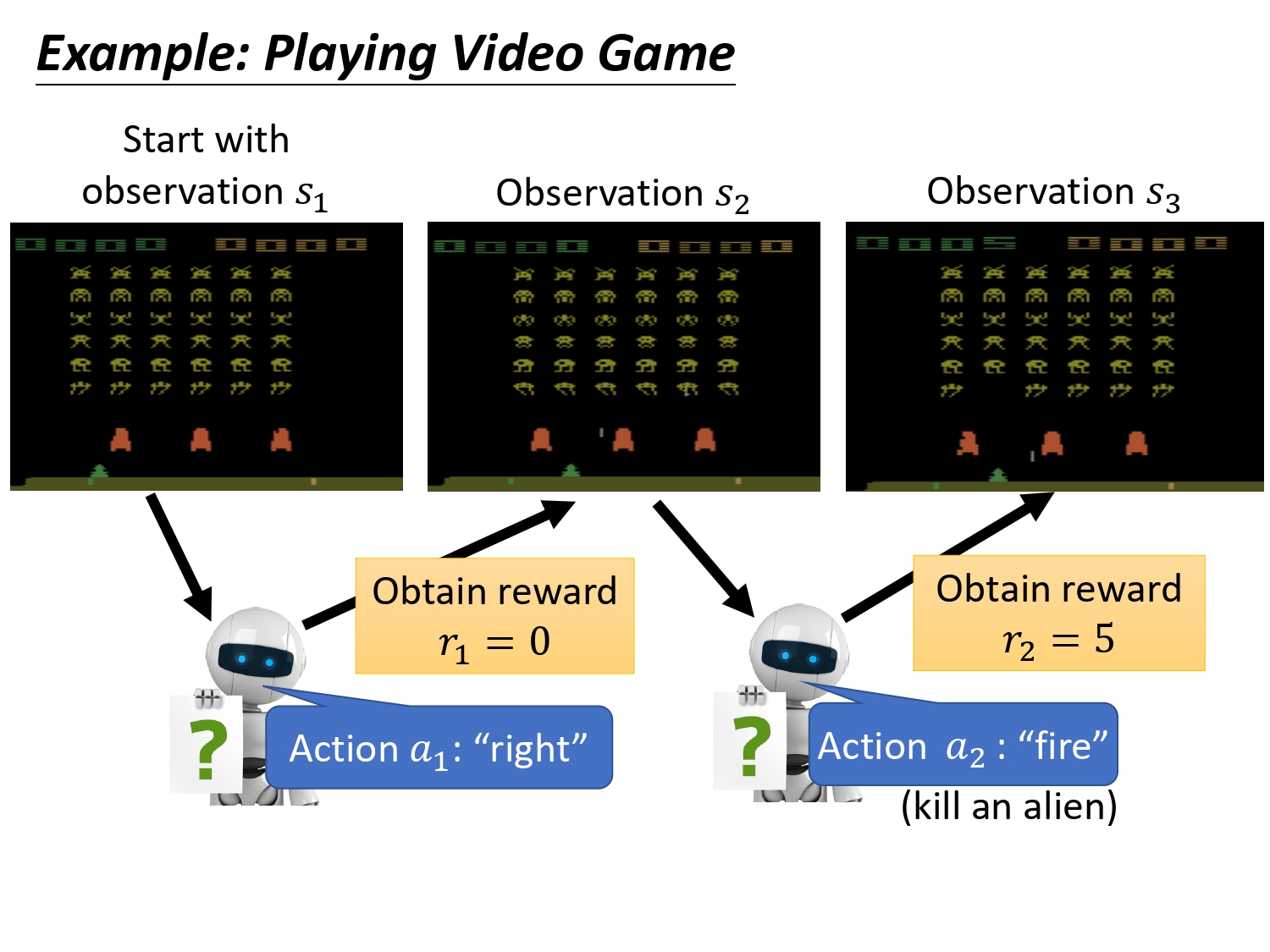
每次采取一个行动会有一个reward
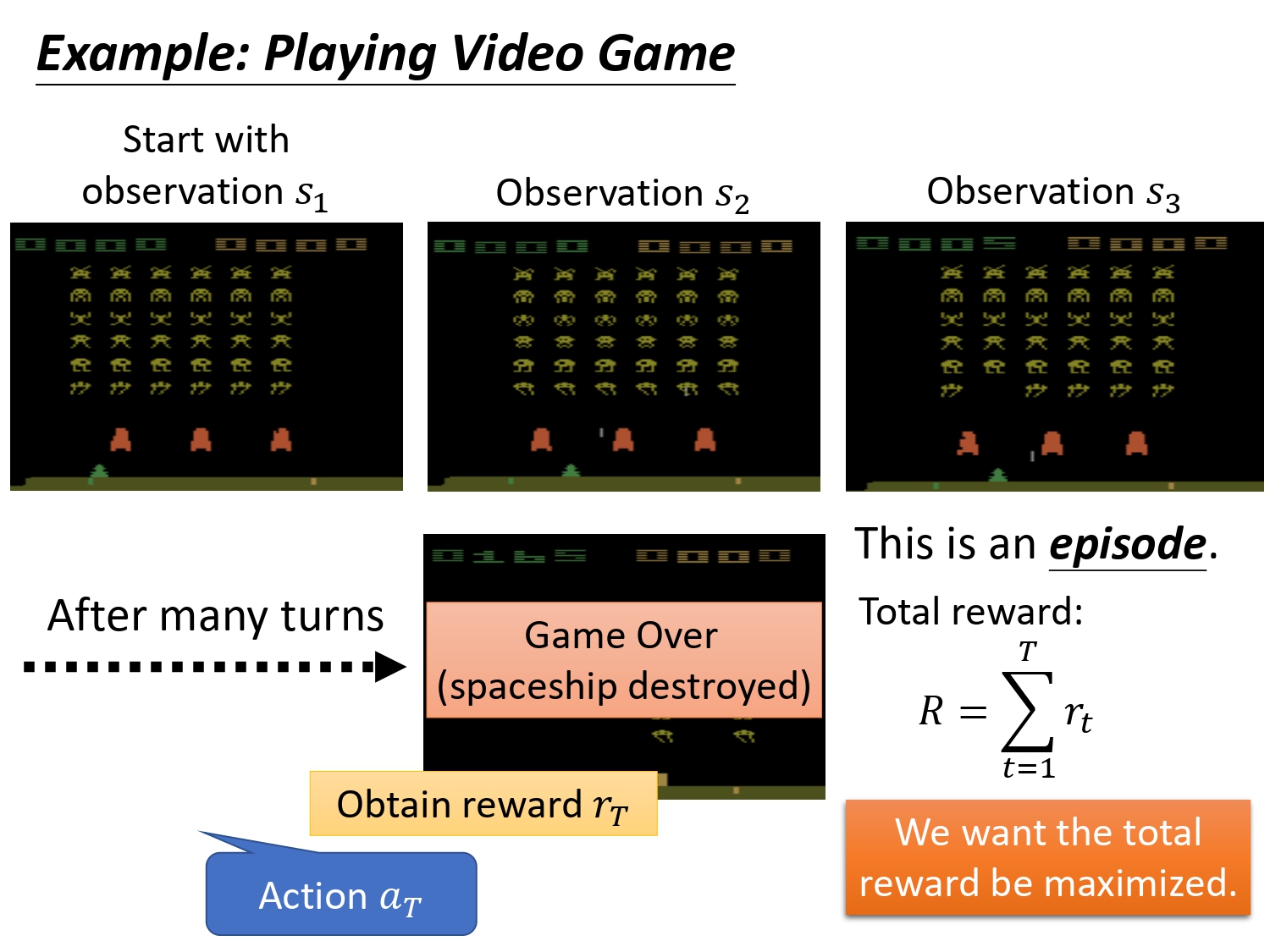
玩一场游戏叫做一个episode,actor存在的目的就是最大化所能得到的return,这个return指的是每一个时间步得到的reward之和。注意我们期望最大化的是return,不是一个时刻的reward。
如果max的目标是当下时刻的reward,那么在Atari游戏中如果agent在某个s下执行开火,得到了较大的reward,那么可能agent就会一直选择开火。并不代表,最终能够取得游戏的胜利。
那么,怎么得到这个actor呢?
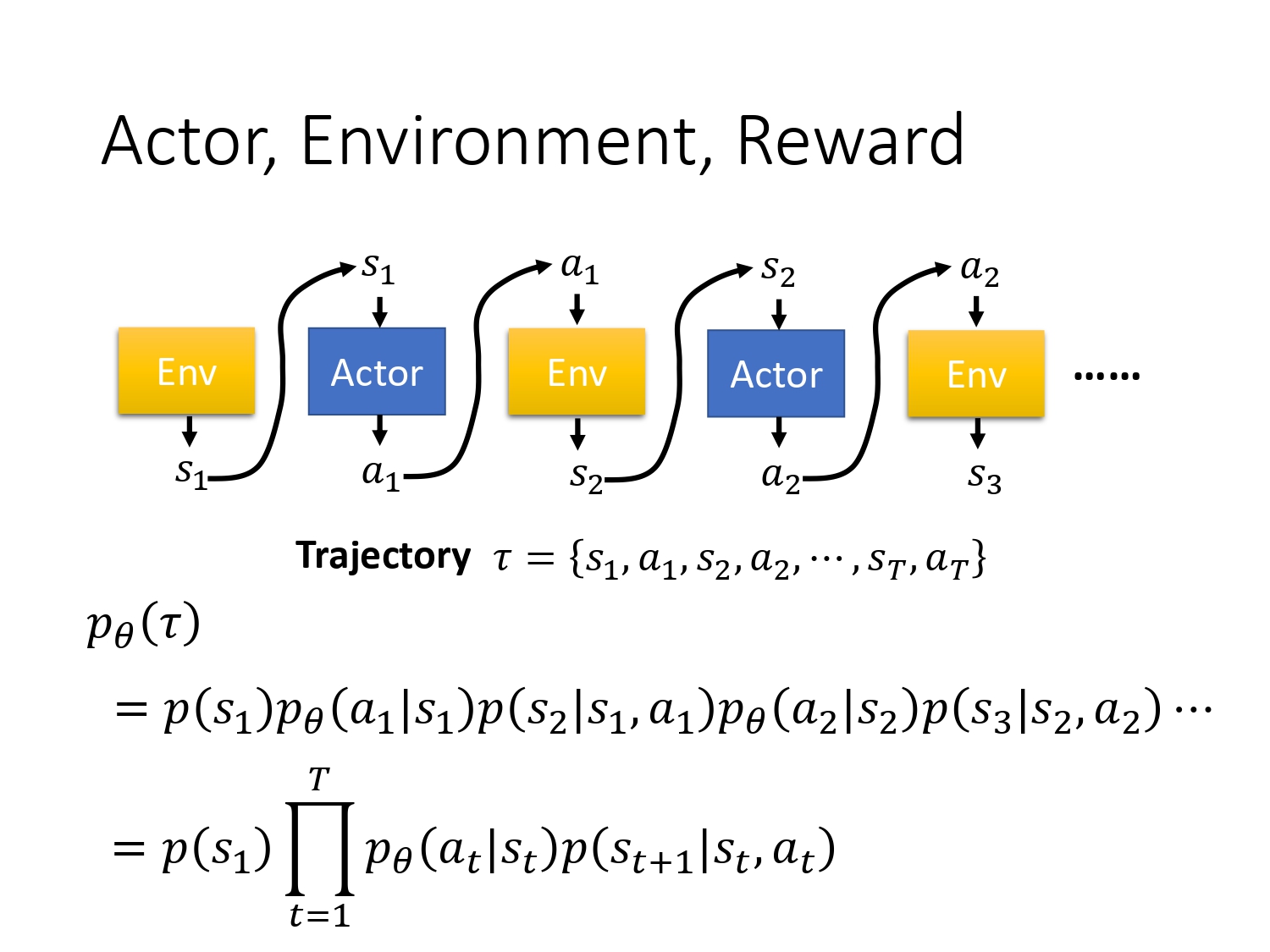
先定义玩一次游戏,即一个episode的游戏记录为trajectory τ \tau τ,内容如图所示,是s-a组成的序列对。
假设actor的参数 θ \theta θ已经给定,则可以得到每个 τ \tau τ出现的概率。这个概率取决于两部分, p ( s t + 1 ∣ s t , a t ) p\left(s_{t+1} | s_{t}, a_{t}\right) p(st+1∣st,at)部分由env的机制决定,actor没法控制,我们能控制的是 p θ ( a t ∣ s t ) p_{\theta}\left(a_{t} | s_{t}\right) pθ(at∣st) 由 π \pi π的参数 θ \theta θ决定。
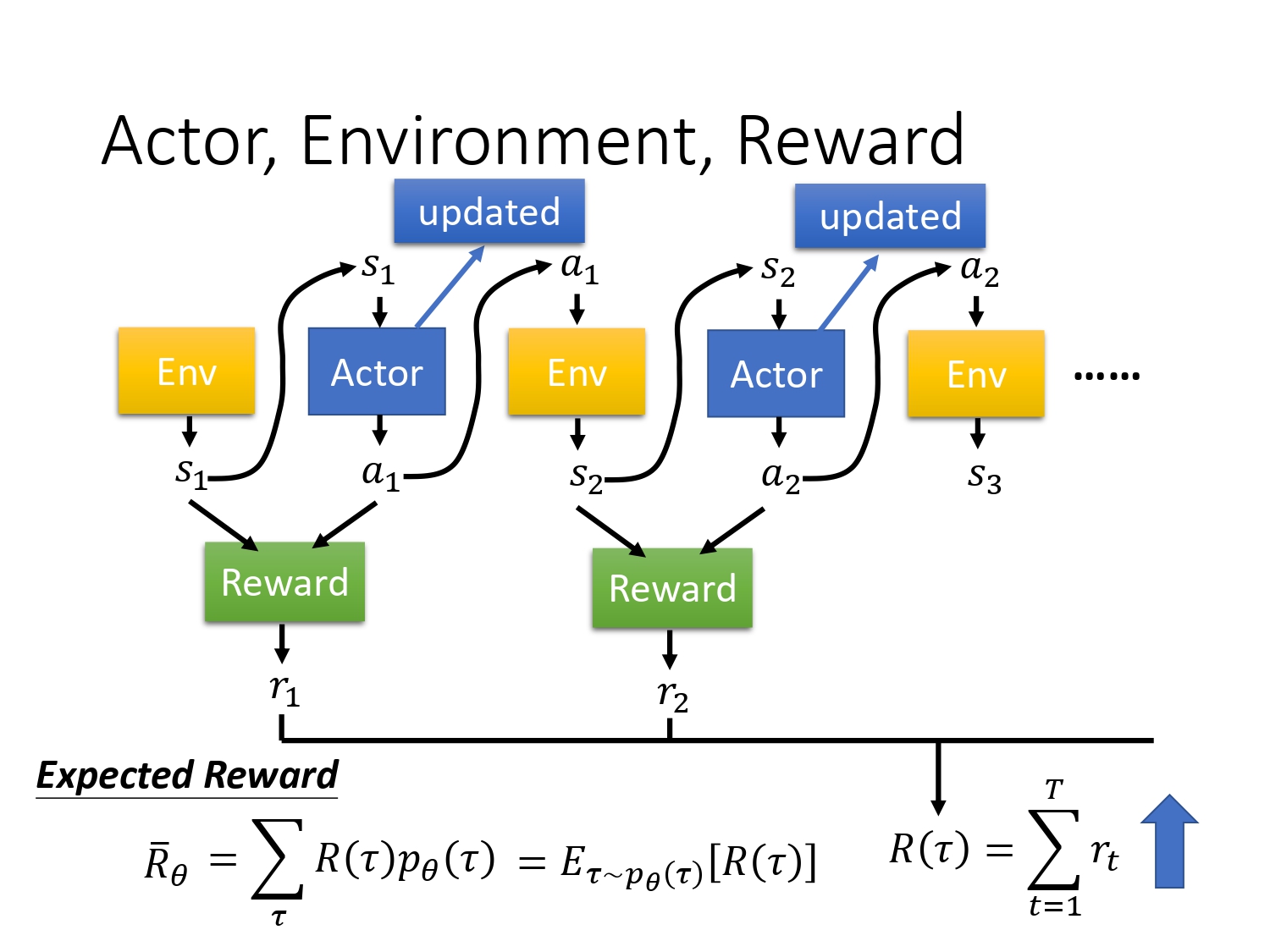
定义 R ( τ ) R(\tau) R(τ) 为一个episode的总的reward,即每个时间步下的即时reward相加,我习惯表述为return。
定义 R ˉ θ \bar{R}_{\theta} Rˉθ 为 R ( τ ) R(\tau) R(τ)的期望,等价于将每一个轨迹 τ \tau τ出现的概率乘与其return,再求和。
由于 R ( τ ) R(\tau) R(τ)是一个随机变量,因为actor本身在给定同样的state下会采取什么行为具有随机性,env在给定行为下输出什么state,也是随机的,所以只能算 R ( τ ) R(\tau) R(τ)的期望。
我们的目标就变成了最大化Expected Reward,那么如何最大化?

优化算法是梯度更新,首先我们先计算出 R ˉ θ \bar{R}_{\theta} Rˉθ 对 θ \theta θ的梯度。
从公式中可以看出 R ( τ ) R(\tau) R(τ)可以是不可微的,因为与参数无关,不需要求导。
第一个改写(红色部分):将加权求和写成期望的形式。
第二个近似:实际上没有办法把所有可能的轨迹(游戏记录)都求出来,所以一般是采样N个轨迹
第三个改写:将 p θ ( τ n ) p_{\theta}\left(\tau^{n}\right) pθ(τn)的表达式展开(前2页slide),去掉跟 θ \theta θ无关的项(不需要求导),则可达到最终的简化结果。具体如下:首先用actor采集一个游戏记录

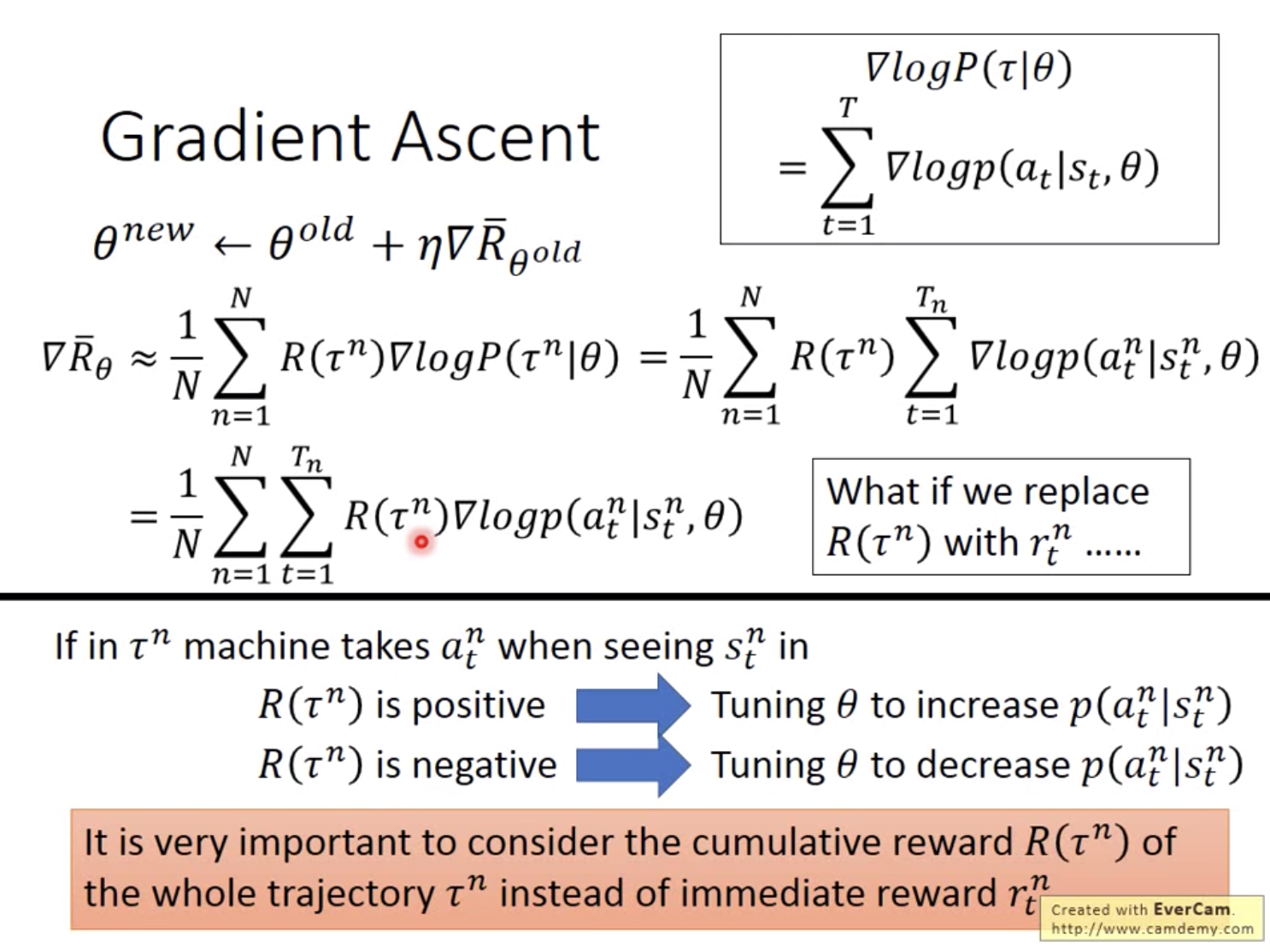
最终得到的公式相当的直觉,在s下采取了a导致最终结果赢了,那么return就是正的,也就是会增加相应的s-a出现的概率P。
上面的公式推导中可能会有疑问,为什么要引入log?再乘一个概率除一个概率?原因非常的直觉,如下:如果动作b本来出现的次数就多,那么在加权平均所有的episode后,参数会偏好执行动作b,而实际上动作b得到的return比a低,所以除掉自身出现的概率,以降低其对训练的影响。
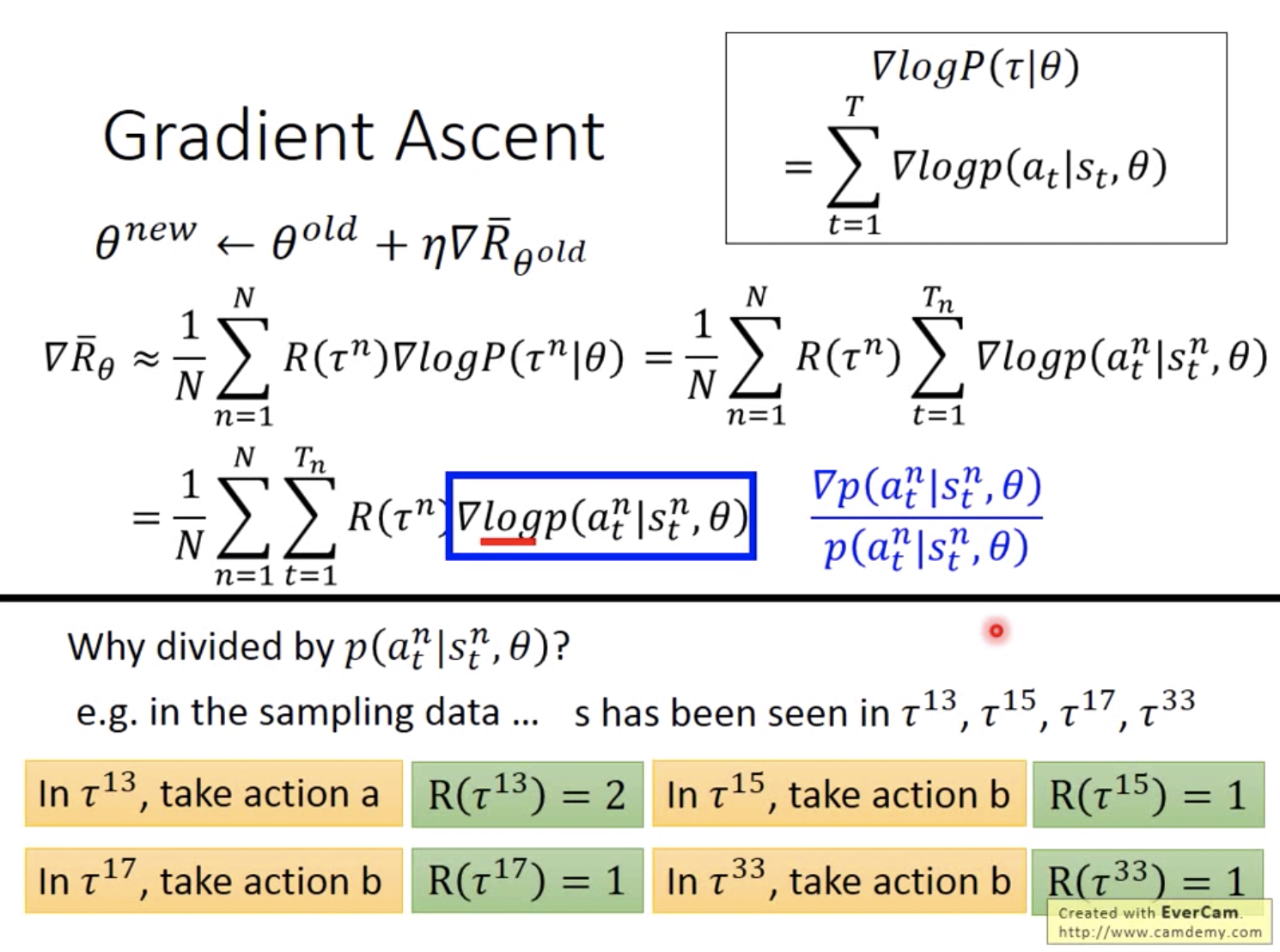
那么,到底是怎么更新参数的呢?
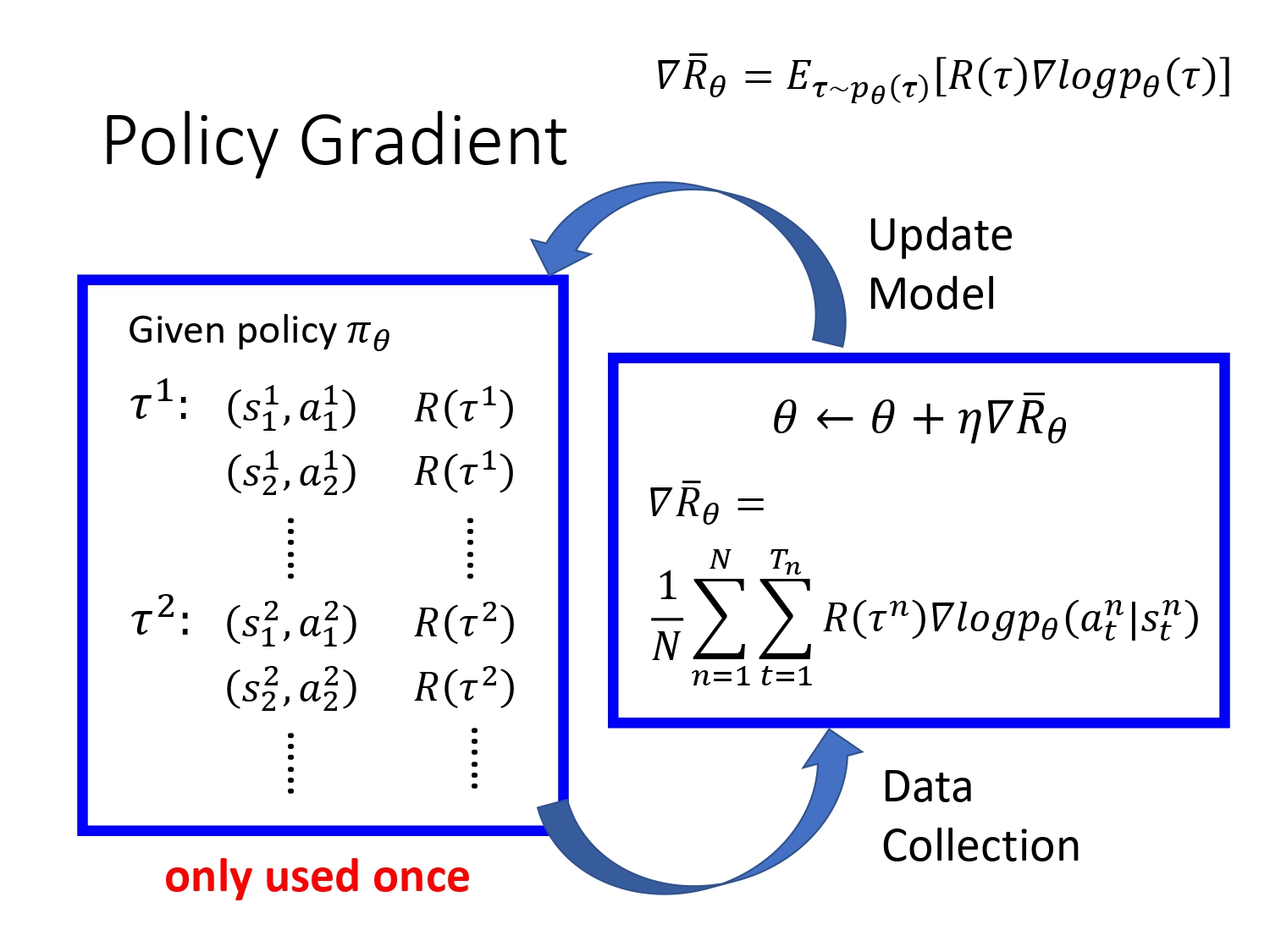
首先会拿agent跟环境互动,收集大量游戏记录,然后把每一个游戏记录拿到右边,计算一个参数theta的更新值,更新参数后,再拿新的actor去收集游戏记录,不断循环。
注意:一般采样的数据只会用一次,用完就丢弃
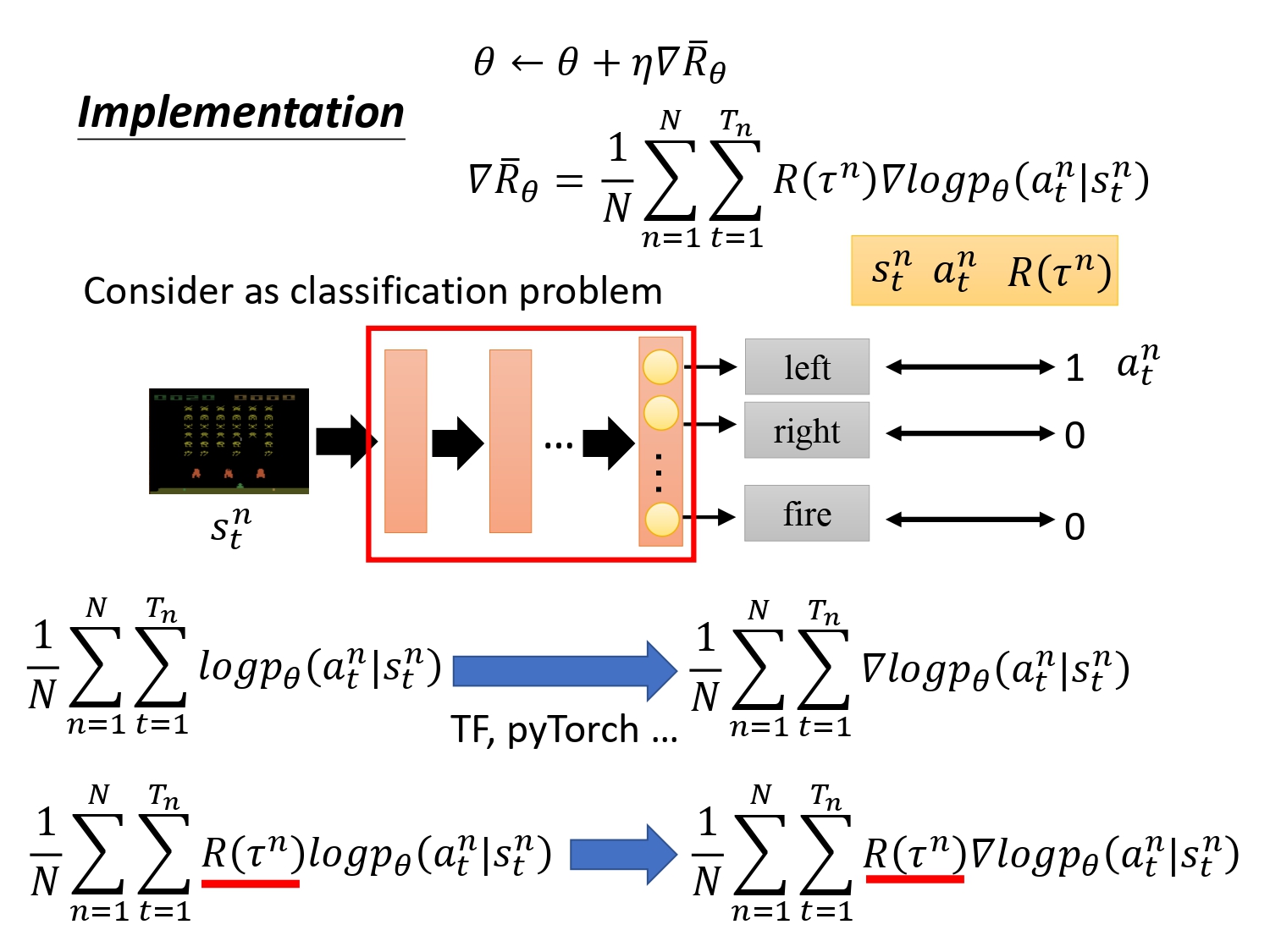
具体实现:可当成一个分类任务,只是分类的结果不是识别object,是给出actor要执行的动作。
如何构建训练集? 采样得到的a,作为ground truth。然后去最小化loss function。
一般的分类问题loss function是交叉熵,在强化学习里面,只需要在前面乘一个weight,即交叉熵乘一个return。
实现的过程中还有一些tips可以提高效果:
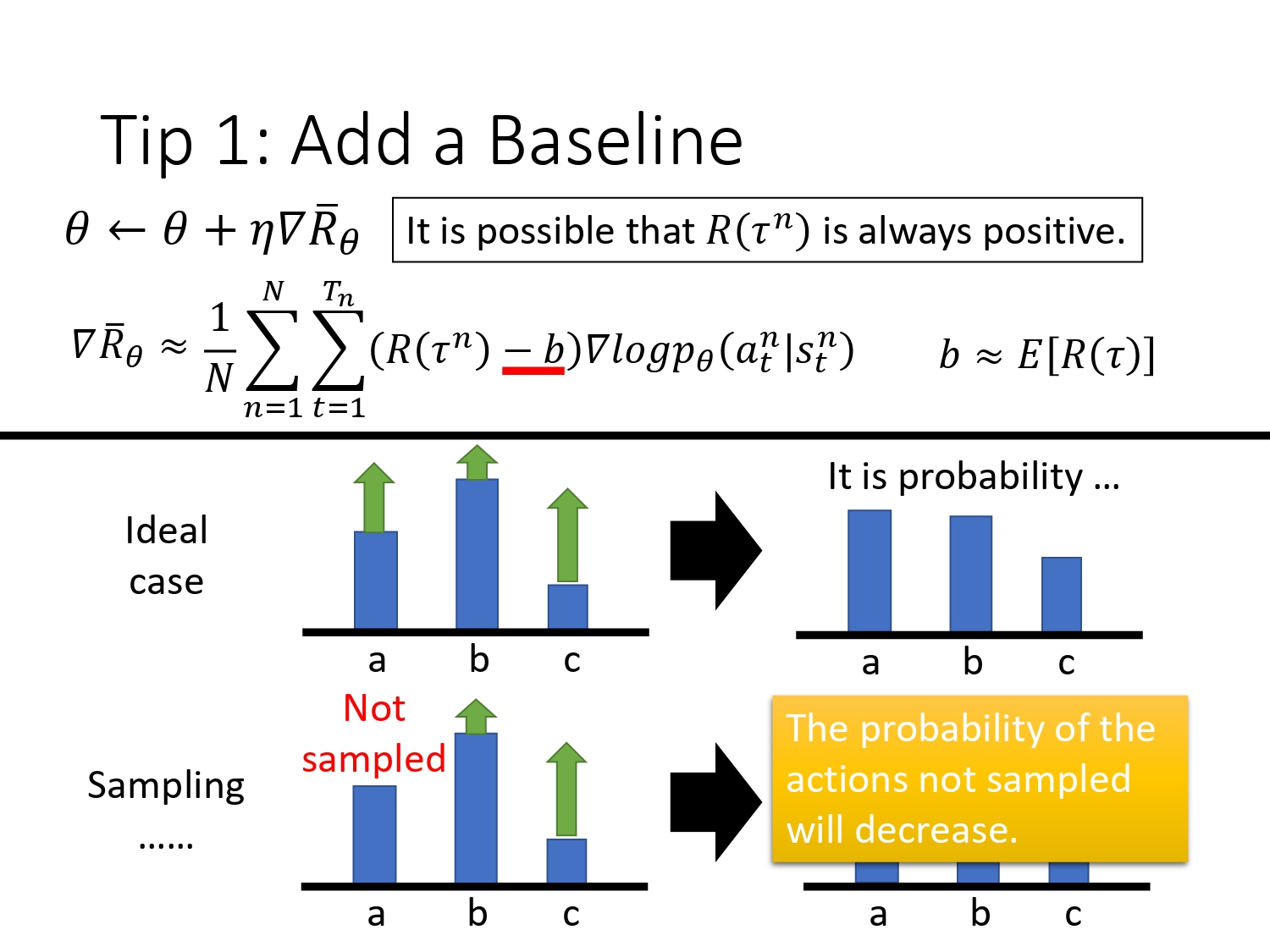
如果 reward都是正的,那么理想的情况下:reward从大到小 b>a>c, 出现次数 b>a>c, 经过训练以后,reward值高的a,c会提高出现的概率,b会降低。但如果a没有采样到,则a出现的概率最终可能会下降,尽管a的reward高。
解决方法:增加一个baseline,用r-b作为新的reward,让其有正有负。最简单的做法是b取所有轨迹的平均回报。
一般r-b叫做优势函数Advantage Functions。我们不需要描述一个行动的绝对好坏,而只需要知道它相对于平均水平的优势。

在这个公式里面,对于一个轨迹,每一个s-a的pair都会乘同一个weight,显然不公平,因为一局游戏里面往往有好的pair,有对结果不好的pair。所以我们希望给每一个pair乘不同的weight。整场游戏结果是好的,不代表每一个pair都是好的。如果sample次数够多,则不存在这个问题。
解决思路:在执行当下action之前的事情跟其没有关系,无论得到多少功劳都跟它没有关系,只考虑在当下执行pair之后的reward,这才是它真正的贡献。把原来的总的return,换成未来的return。
如图:对于第一组数据,在( s a s_a sa, a 1 a_1 a1)时候总的return是+3,那么如果对每一个pair都乘3,则( s b s_b sb, a 2 a_2 a2)会认为是有效的,但如果使用改进的思路,将其乘之后的return,即-2,则能有效抑制该pair对结果的贡献。
再改进:加一个折扣系数,如果时间拖得越长,对于越之后的reward,当下action的功劳越小。
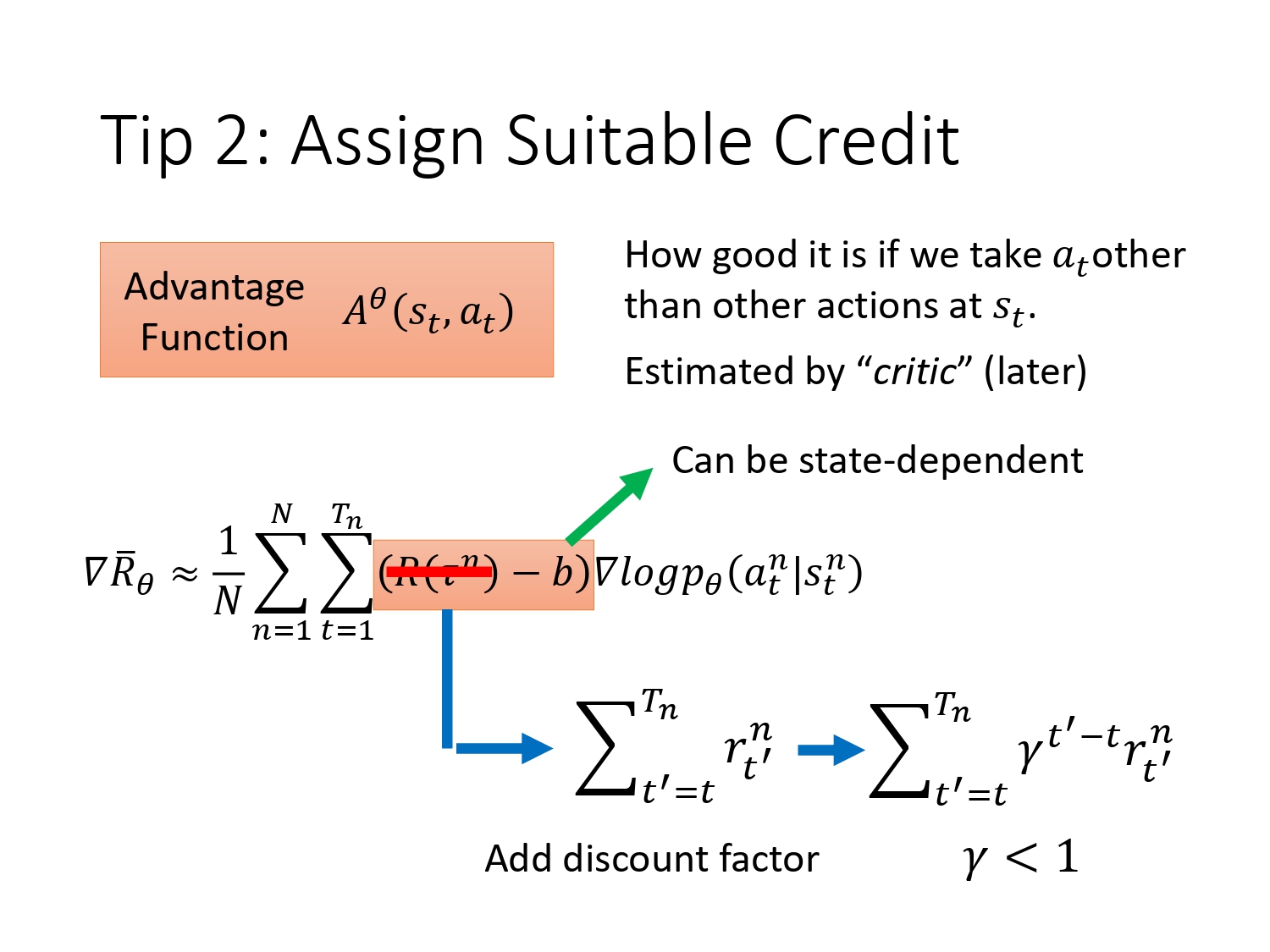
我们将R-b 记为 A,意义就是评价当前s执行动作a,相比于采取其他的a,它有多好。之后我们会用一个critic网络来估计这个评价值。
2.2 PPO
PPO算法是PG算法的变形,目的是把在线的学习变成离线的学习。
核心的idea是对每一条经验(又称轨迹,即一个episode的游戏记录)不止使用一次。
简单理解:在线学习就是一边玩一边学,离线学习就是先看着别人玩进行学习,之后再自己玩


Motivation:每次用 π θ \pi_\theta πθ去采样数据之后, π θ \pi_\theta πθ都会更新,接下来又要采样新的数据。以至于PG算法大部分时间都在采样数据。那么能不能将这些数据保存下来,由另一个 π θ ′ \pi_{\theta'} πθ′去更新参数?那么策略 π θ \pi_\theta πθ采样的数据就能被 π θ ′ \pi_{\theta'} πθ′多次利用。引入统计学中的经典方法:
重要性采样:如果想求一个函数的期望,但无法积分,则可以通过采样求平均的方法来近似,但是如果p分布不知道(无法采样),我们知道q分布,则如上图通过一个重要性权重,用q分布来替代p分布进行采样。这个重要性权重的作用就是修正两个分布的差异。

存在的问题:如果p跟q的差异比较大,则方差会很大
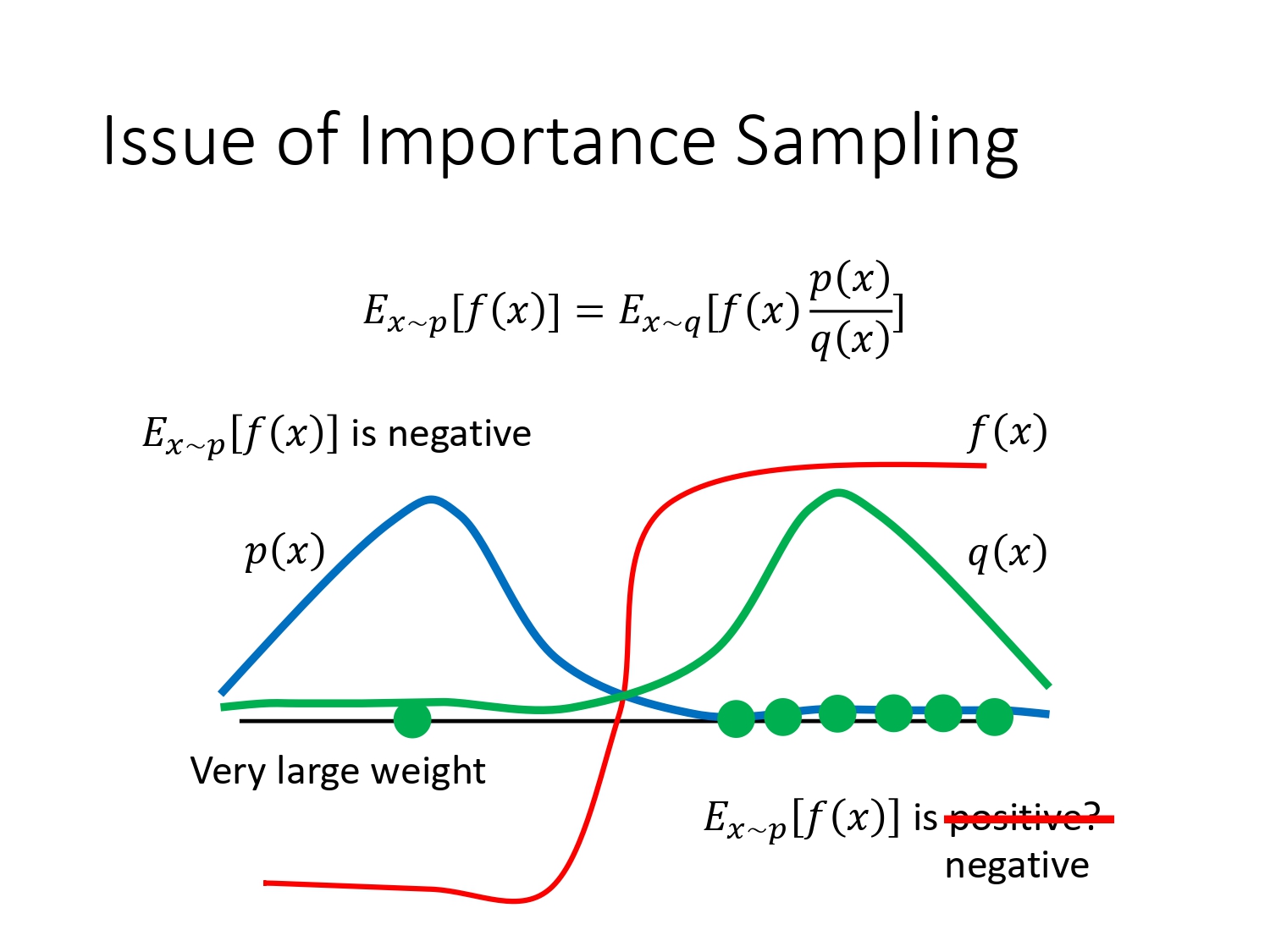
如果sample的次数不够多,比如按原分布p进行采样,最终f的期望值是负数(大部分概率都在左侧,左侧f是负值),如果按q分布进行sample,只sample到右边,则f就一直是正的,严重偏离原来的分布。当然采样次数够多的时候,q也sample到了左边,则p/q这个负weight非常大,会平衡掉右边的正值,会导致最终计算出的期望值仍然是负值。但实际上采样的次数总是有限的,出现这种问题的概率也很大。
先忽略这个问题,加入重要性采样之后,训练变成了离线的

离线训练的实现:用另一个policy2与环境做互动,采集数据,然后在这个数据上训练policy1。尽管2个采集的数据分布不一样,但加入一个重要性的weights,可以修正其差异。等policy1训练的差不多以后,policy2再去采集数据,不断循环。

由于我们得到的 A θ ( s t , a t ) A^{\theta}\left(s_{t}, a_{t}\right) Aθ(st,at)(执行当下action后得到reward-baseline)是由policy2采集的数据观察得到的,所以 A θ ( s t , a t ) A^{\theta}\left(s_{t}, a_{t}\right) Aθ(st,at)的参数得修正为 θ ′ \theta' θ′
根据 ∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla f(x)=f(x) \nabla \log f(x) ∇f(x)=f(x)∇logf(x)反推目标函数 J J J,注意要优化的参数是 θ \theta θ , θ ’ \theta’ θ’只负责采集数据。
利用 θ ’ \theta’ θ’采集的数据来训练 θ \theta θ,会不会有问题?(虽然有修正,但毕竟还是不同) 答案是我们需要保证他们的差异尽可能的小,那么在刚刚的公式里再加入一些限制保证其差异足够小,则诞生了 PPO算法。

引入函数KL,KL衡量两个分布的距离。注意:不是参数上的距离,是2个 π \pi π给同样的state之后基于各自参数输出的action space的距离
加入KL的公式直觉的理解:如果我们学习出来的 θ \theta θ跟 θ ′ \theta' θ′越像,则KL越小,J越大。我们的学习目标还是跟原先的PG算法一样,用梯度上升训练,最大化J。这个操作有点像正则化,用来解决重要性采样存在的问题。
TRPO是PPO是前身,把KL这个限制条件放在优化的目标函数外面。对于梯度上升的优化过程,这种限制比较难处理,使优化变得复杂,一般不用。

实现过程:初始化policy参数,在每一个迭代里面,用 t h e t a k theta^k thetak采集很多数据,同时计算出奖励A值,接着train这个数据,更新 θ \theta θ优化J。由于是离线训练,可以多次更新后,再去采集新的数据。
有一个trick是KL的权重beta也可以调整,使其更加的adaptive。
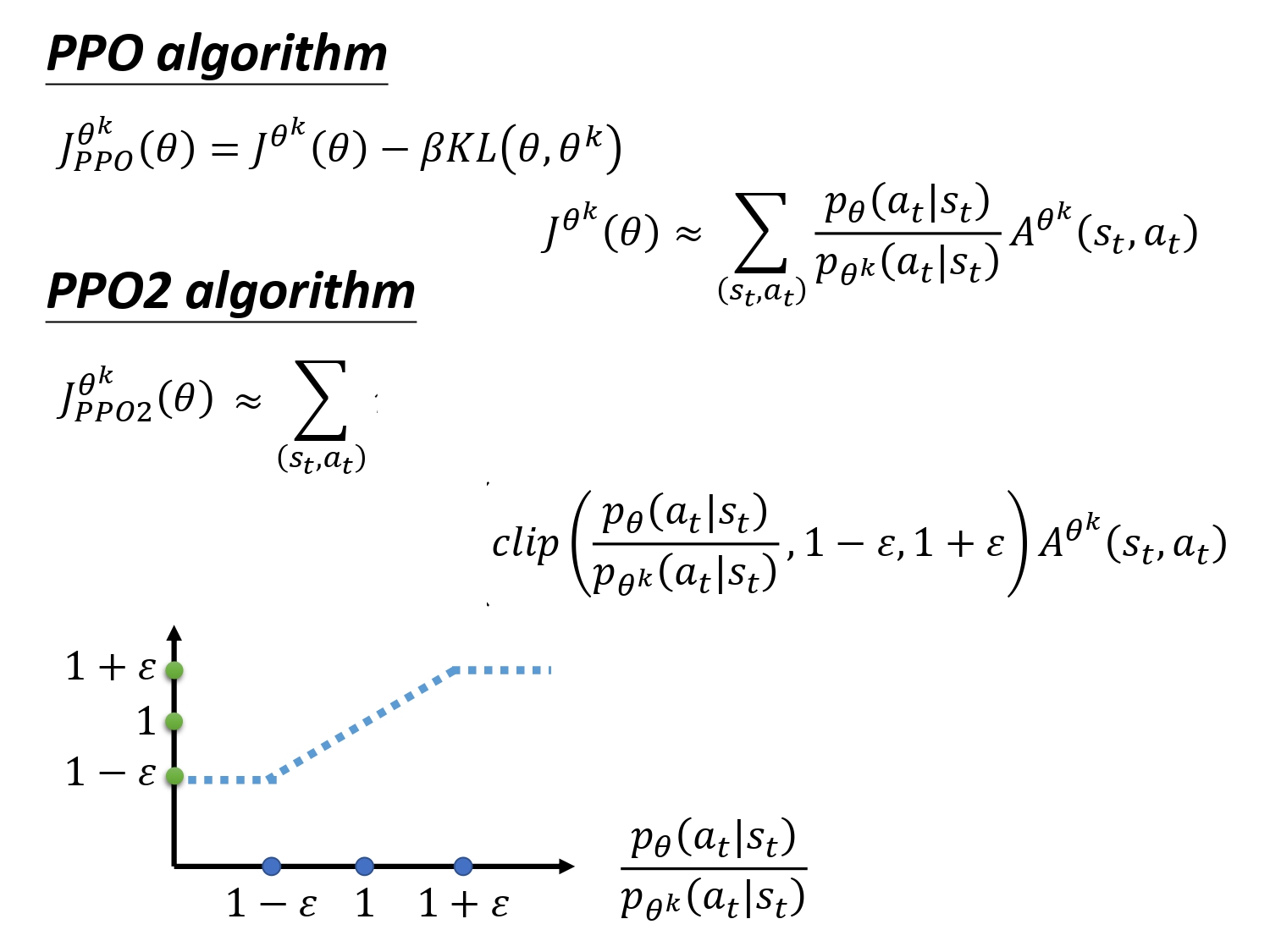
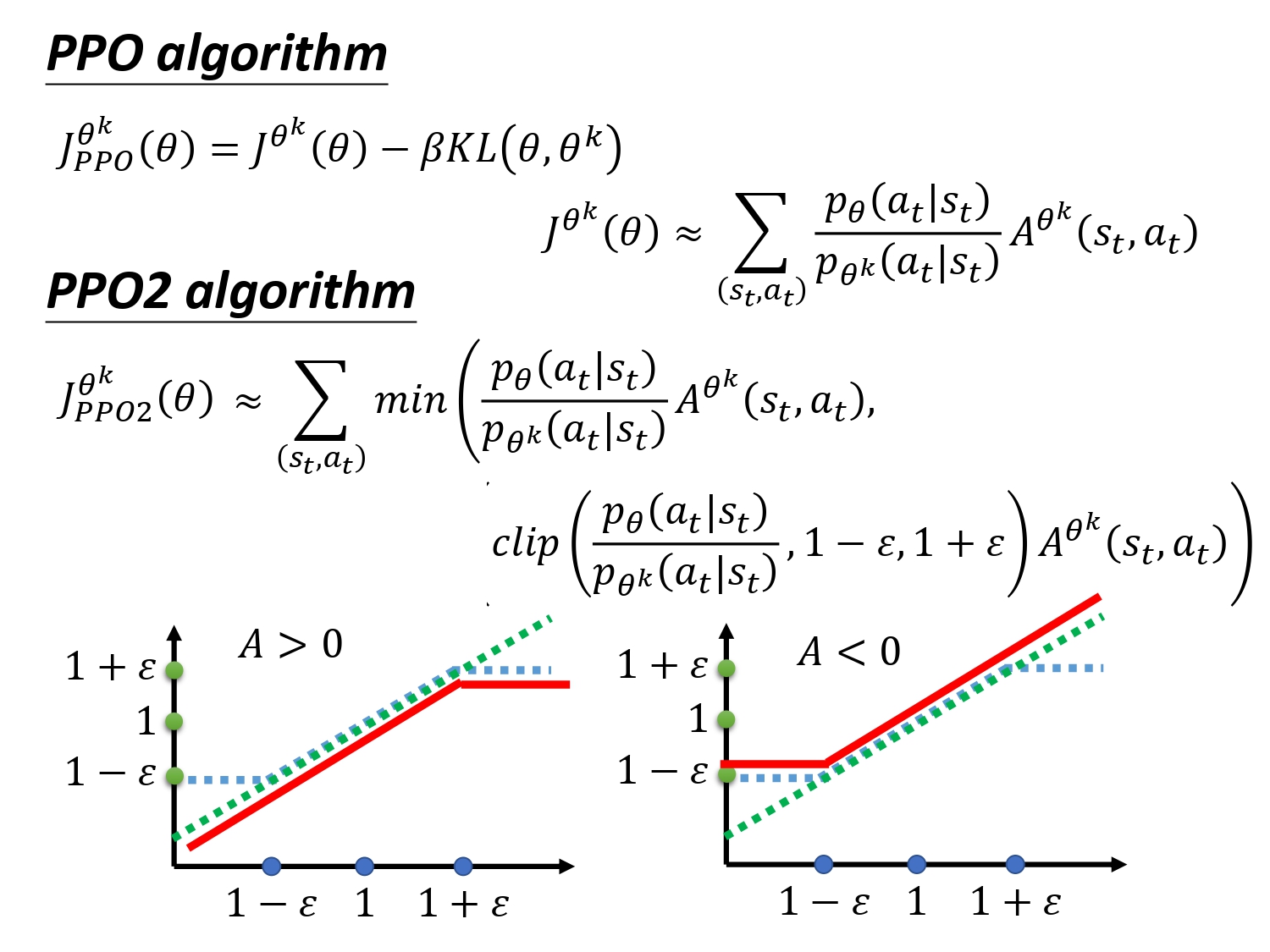
实际上KL也是比较难计算的,所以有了PPO2算法,不计算KL,通过clip达到同样效果。
clip(a, b, c): if a<b => b If a>c => c If b<a<c => a
看图:绿色:min里面的第一项,蓝色:min里面的第二项,红色 min的输出
这个公式的直觉理解:希望 θ \theta θ与 θ k \theta^k θk在优化之后不要差距太大。如果A>0,即这个state-action是好的,所以需要增加这个pair出现的几率,所以在max J的过程中会增大 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_{\theta}\left(a_{t} | s_{t}\right)}{p_{\theta^{k}}\left(a_{t} | s_{t}\right)} pθk(at∣st)pθ(at∣st), 但最大不要超过1+eplison,如果A<0,不断减小,小到1-eplison,始终不会相差太大。
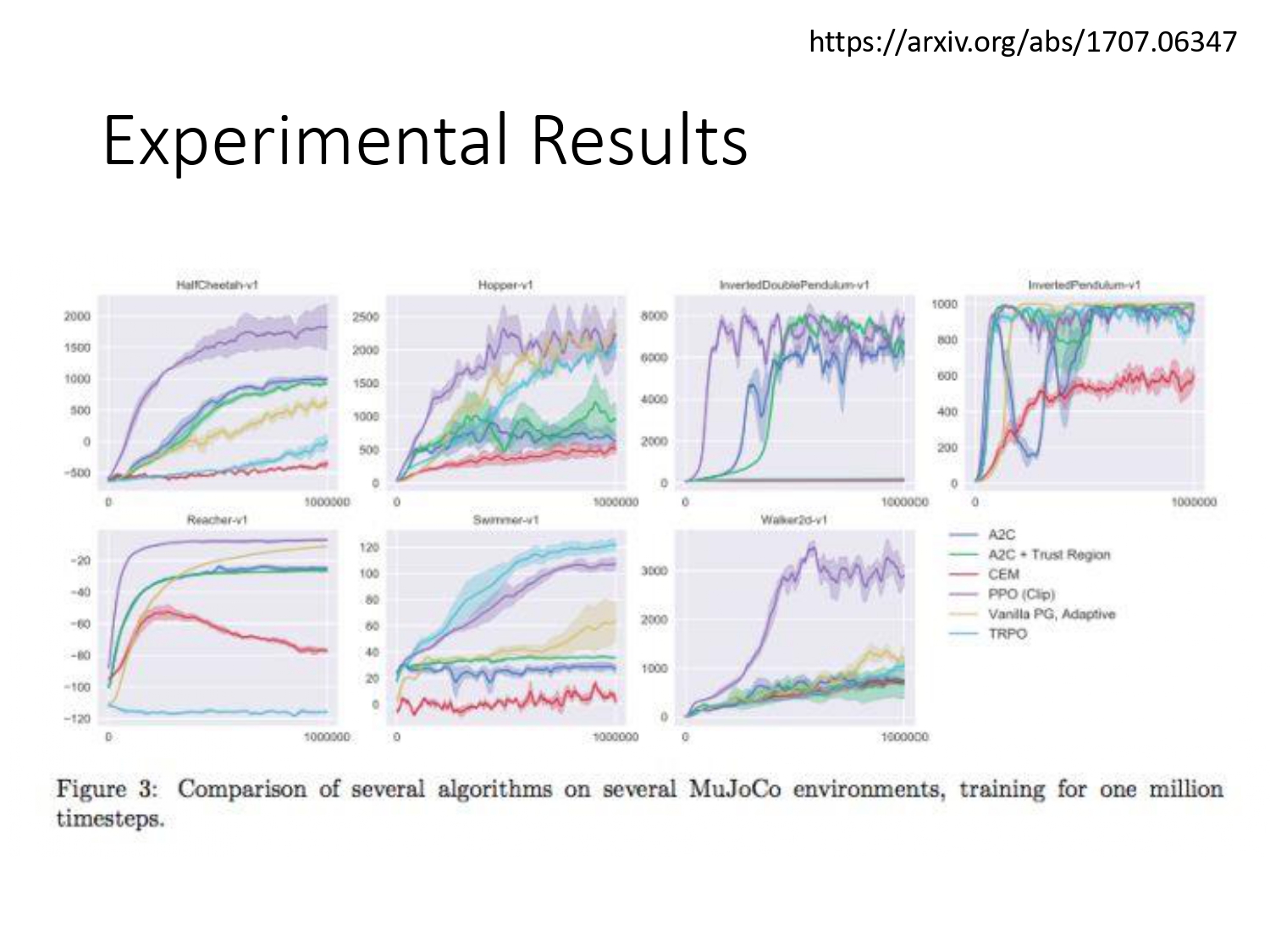
PG算法效果非常不稳定,自从有了PPO,PG的算法可以在很多任务上work。
3. Q - Learning
3.1 Q-learning
在之前的policy-based算法里,我们的目标是learn 一个actor,value-based的强化学习算法目标是learn一个critic。
定义一个Critic,也就是状态值函数 V π ( s ) V^{\pi}(s) Vπ(s),它的值是:当使用策略 π \pi π进行游戏时,在观察到一个state s之后,环境输出的累积的reward值的期望。注意取决于两个值,一个是state s,一个是actor π \pi π。
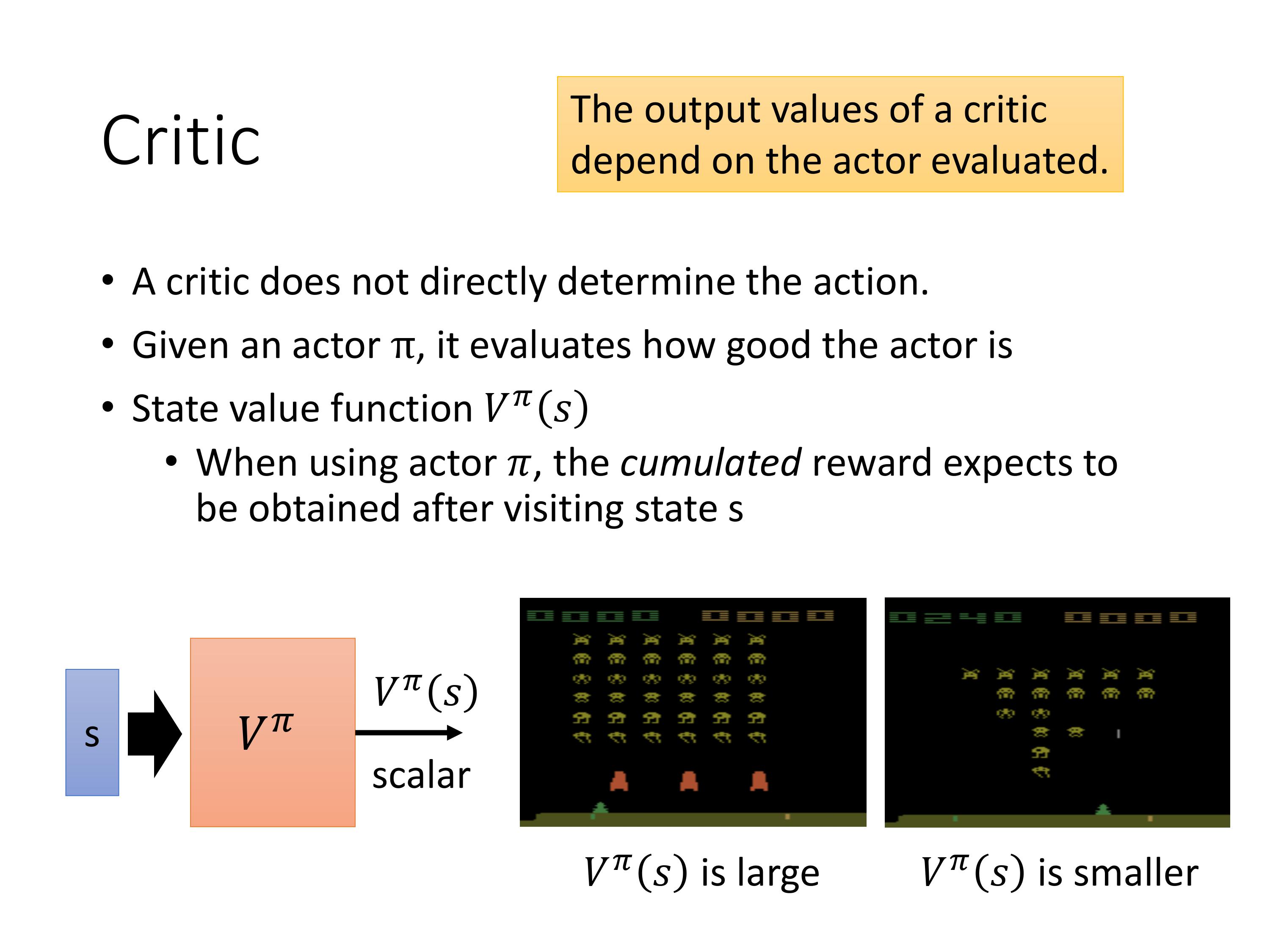
如果是不同的actor,在同样的state下,critic给出的值也是不同的。那么怎么估计出这个函数V呢?
主要有MC和TD的方法,实际上还有DP的方法,但是用DP求解需要整个环境都是已知的。而在强化学习的大部分任务里,都是model-free的,需要agent自己去探索环境。
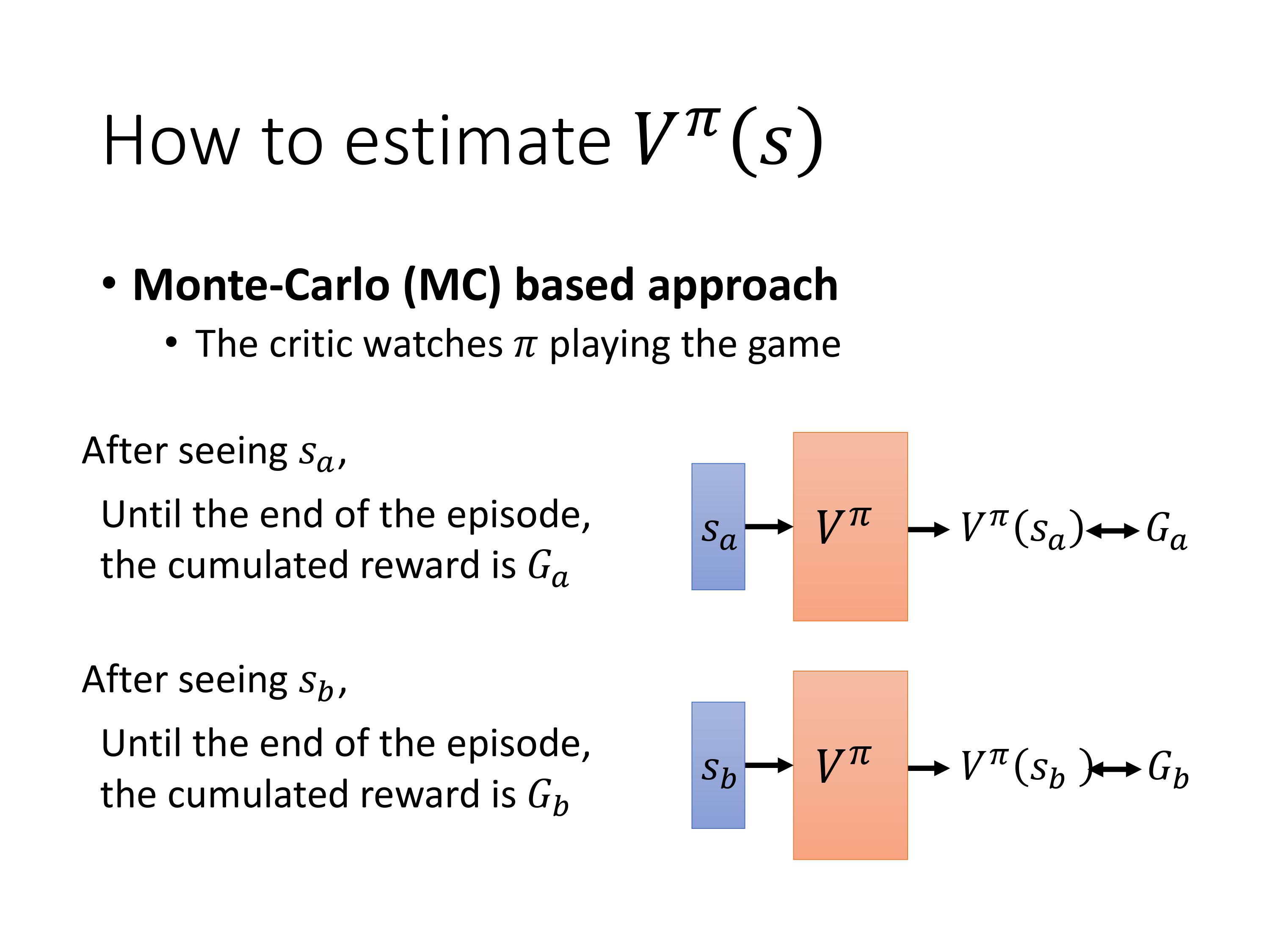
MC:直接让agent与环境互动,统计计算出在 S a S_a Sa之后直到一个episode结束的累积reward作为 G a G_a Ga。
训练的目标就是让 V π ( s ) V^{\pi}(s) Vπ(s)的输出尽可能的接近 G a G_a Ga。

MC每次必须把游戏玩到结束,TD不需要把游戏玩到底,只需要玩了一次游戏,有一个状态的变化。
那么训练的目标就是让 V π ( s t ) V^{\pi}(s_t) Vπ(st) 和 V π ( s t + 1 ) V^{\pi}(s_t+1) Vπ(st+1)的差接近 r t r_t rt
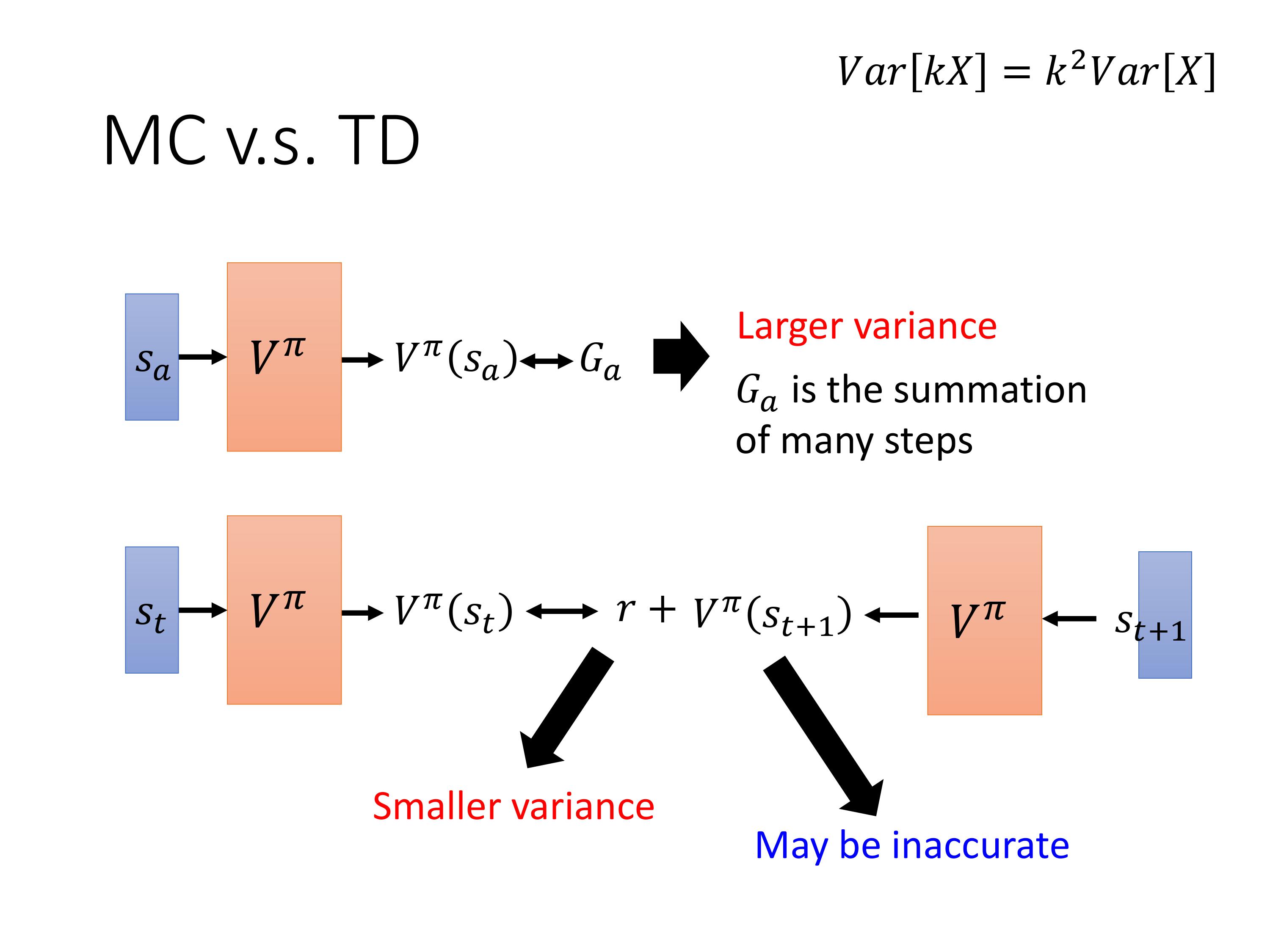
MC方差大,因为 r r r是一个随机变量,MC方法中的 G G G是 r r r之和,而TD方法只有 r r r是随机变量,r的方差比G小。但TD方法的 V π V^{\pi} Vπ有可能估计的不准。

用MC和TD估计的结果不一样
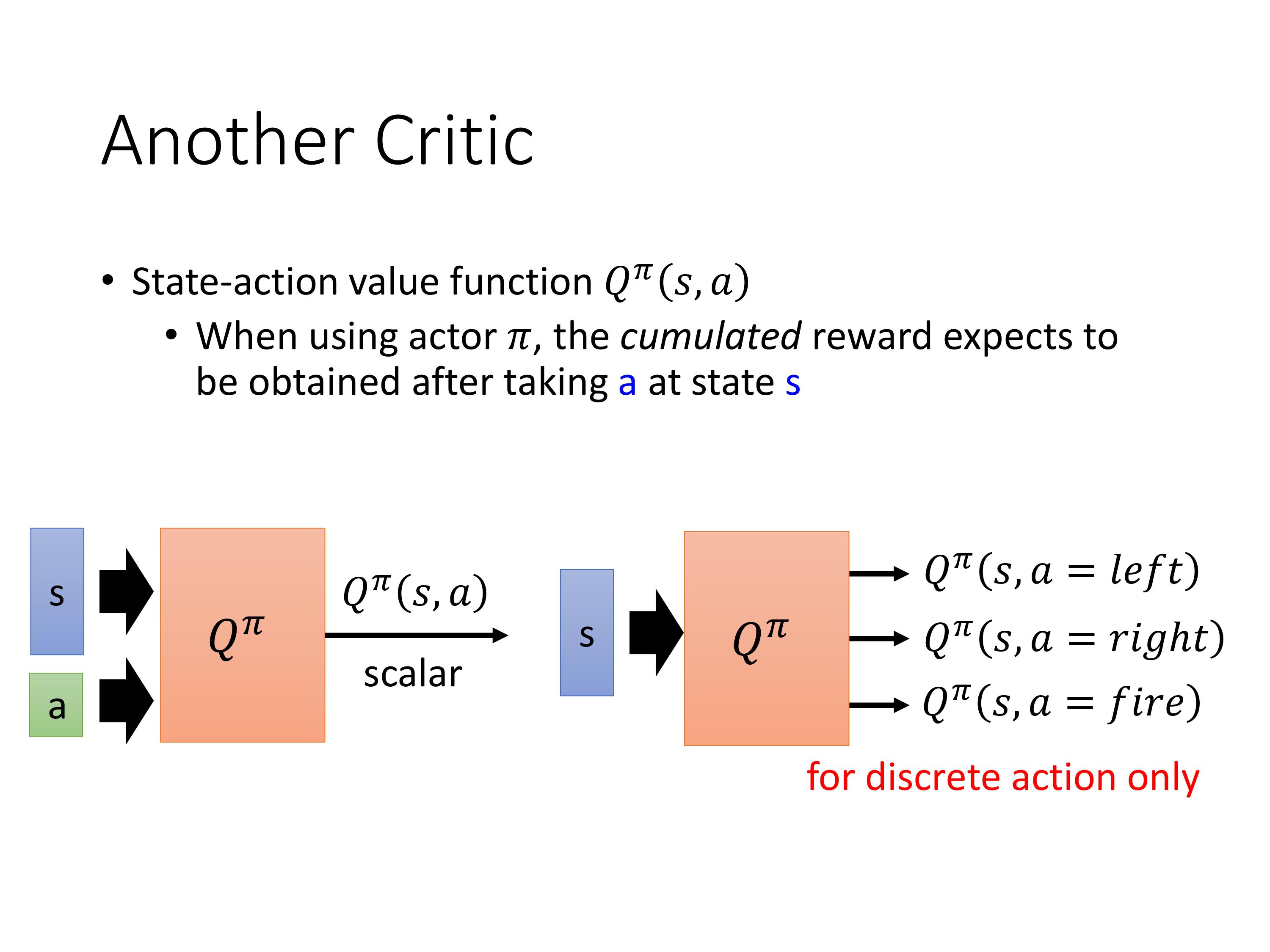
定义另一种Critic,状态-动作值函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a),有的地方叫做Q-function,输入是一个pair ( s , a ) (s,a) (s,a),意思是用 π \pi π玩游戏时,在s状态下强制执行动作a(策略 π \pi π在s下不一定会执行a),所得到的累积reward。
有两种写法,输入pair,输出Q,此时的Q是一个标量。
另一种是输入s,输出所有可能的action的Q值,此时Q是一个向量。
那么Critic到底怎么用呢?
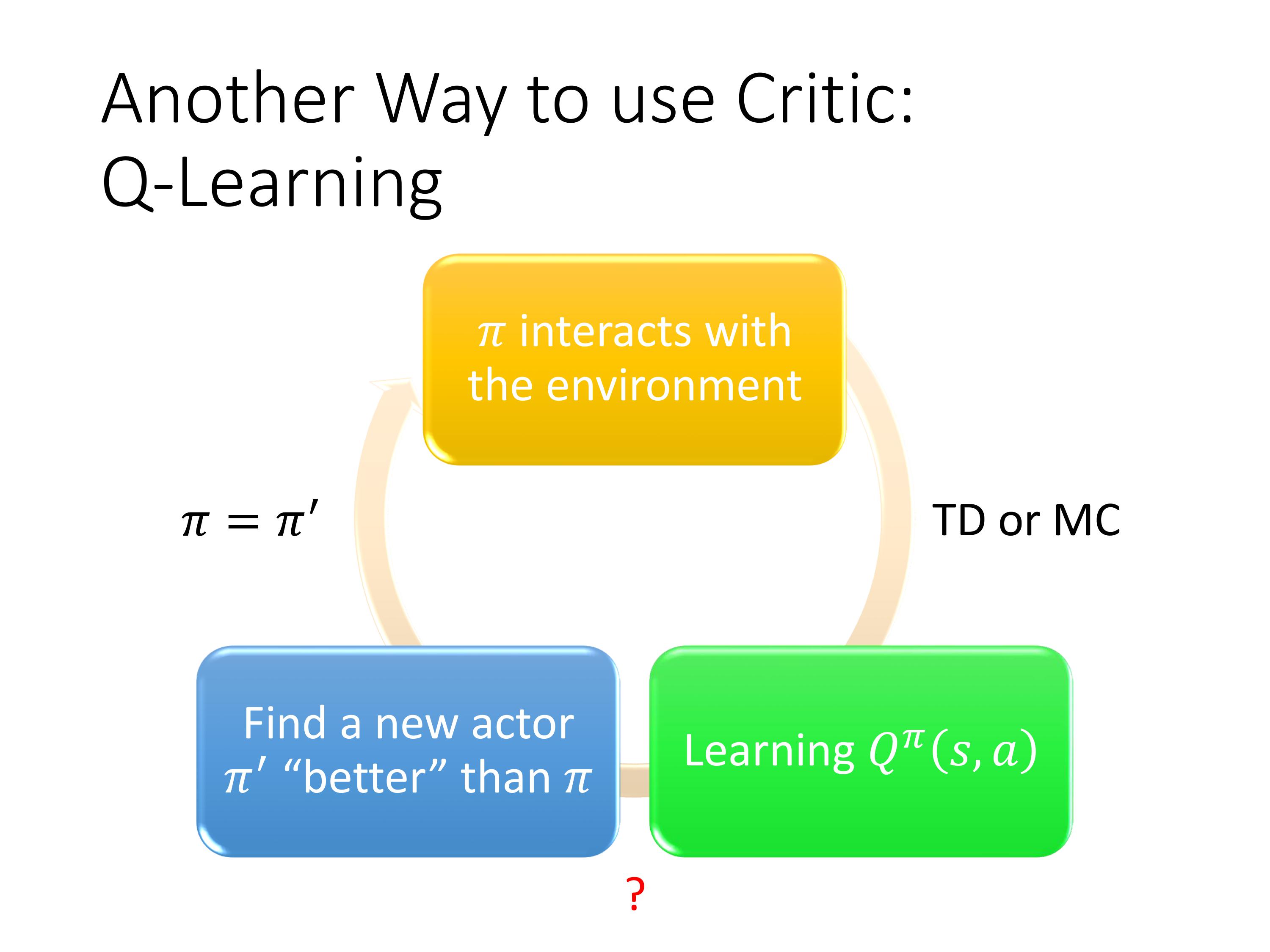
Q-learning的过程:
初始化一个actor π \pi π去收集数据,然后learn一个基于$ \pi 的 Q − f u n c t i o n ,接着寻找一个新的比原来的 的Q-function,接着寻找一个新的比原来的 的Q−function,接着寻找一个新的比原来的\pi 要好 a c t o r , 找到后更新 要好actor , 找到后更新 要好actor,找到后更新\pi$,再去寻找新的Q-function,不断循环,得到更好的policy。
可见Q-learning的核心思想是先找到最优的Q-function,再通过这个Q-function得出最优策略。而Policy-based的算法是直接去学习策略。这是本质区别。
那么,怎么样才算比原来的好?

定义好的策略:对所有可能的s而言, V π ( s ) V_\pi(s) Vπ(s)一定小于 V π ′ ( s ) V_\pi'(s) Vπ′(s),则 V π ′ ( s ) V_\pi'(s) Vπ′(s)就是更好的策略。
π ′ ( s ) \pi'(s) π′(s)的本质:假设已经学习到了一个actor π \pi π的Q-function,给一个state,把所有可能的action都代入Q,执行那个可以让Q最大的action。
注意:实际上,给定一个s,$ \pi$不一定会执行a,现在的做法是强制执行a,计算执行之后玩下去得到的reward进行比较。
在实现的时候 π ′ \pi' π′没有额外的参数,依赖于Q。并且当动作是连续值的时候,无法进行argmax。
那么, 为什么actor π ’ \pi’ π’能被找到?

上面是为了证明:只要你估计出了一个actor的Q-function,则一定可以找到一个更好的actor。
核心思想:在一个episode中某一步把 π \pi π换成了$ \pi’$比完全follow $ \pi$,得到的奖励期望值会更大。
注意 r t + 1 r_{t+1} rt+1指的是在执行当下 a t a_t at得到的奖励,有的文献也会写成 r t r_t rt
训练的时候有一些Tips可以提高效率:
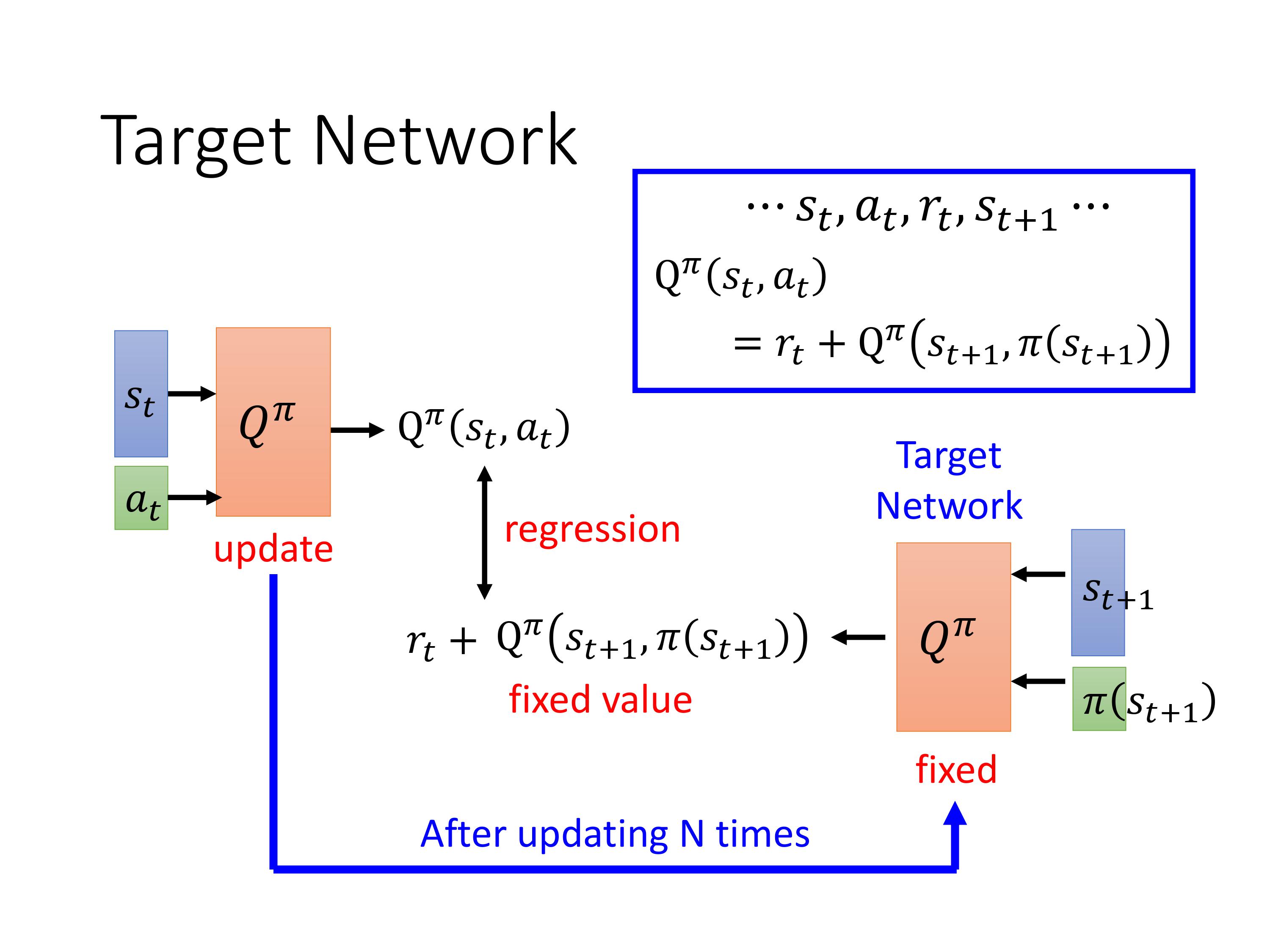
Tips 1 引入target网络
训练的时候,每次需要两个Q function(两个的输入不同)一起更新,不稳定。 一般会固定一个Q作为Target,产生回归任务的label,在训练N次之后,再更新target的参数。回归任务的目标,让 Q π ( s t , a t ) Q^\pi(s_t,a_t) Qπ(st,at)与 Q π ( s t + 1 , π ( s t + 1 ) ) ) + r \mathrm{Q}^{\pi}\left(s_{t+1}, \pi\left(s_{t+1}\right)\right))+r Qπ(st+1,π(st+1)))+r越来越接近,即降低mse。最终希望训练得到的 Q π Q^\pi Qπ能直接估计出这个 ( s t , a t ) (s_t,a_t) (st,at)未来的一个累积奖励。
注意:target网络的参数不需要训练,直接每隔N次复制Q的参数。训练的目标只有一个 Q。

Tips2 改进探索机制
PG算法,每次都会sample新的action,随机性比较大,大概率会尽可能的覆盖所有的动作。而之前的Q-learning,策略的本质是绝对贪婪策略,那么如果有的action没有被sample到,则可能之后再也不会选择这样的action。这种探索的机制(收集数据的方法)不好,所以改进贪心算法,让actor每次会 ε \varepsilon ε的概率执行随机动作。
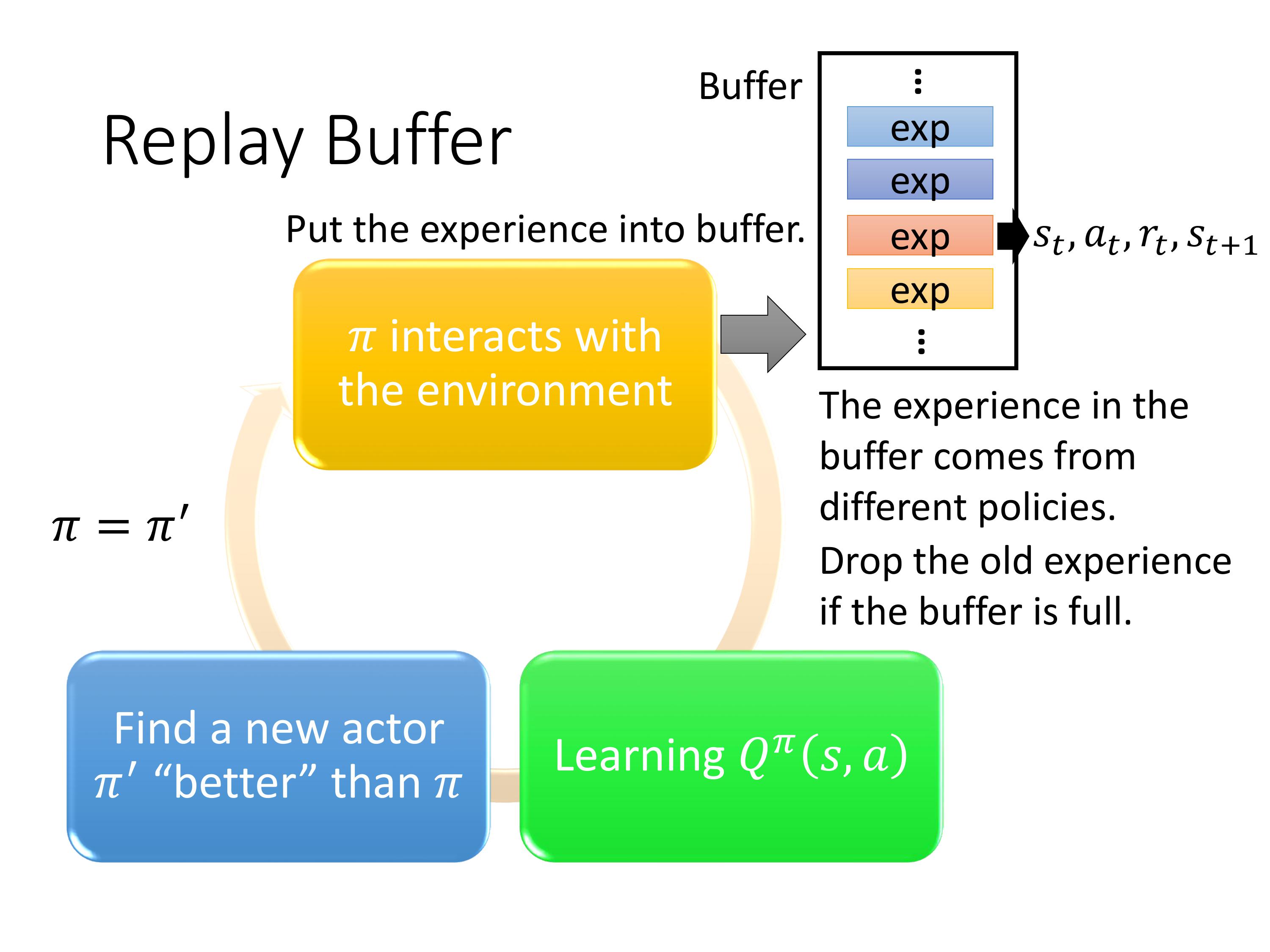
Tips 3 引入记忆池机制
将采集到的一些数据收集起来,放入replay buffer。好处:
1.可重复使用过去的policy采集的数据,降低agent与环境互动的次数,加快训练效率 。
2.replay buffer里面包含了不同actor采集的数据,这样每次随机抽取一个batch进行训练的时候,每个batch内的数据会有较大的差异(数据更加diverse),有助于训练。
那么,当我们训练的目标是$ \pi 的 Q − f u n c t i o n ,训练数据混杂了 的Q-function,训练数据混杂了 的Q−function,训练数据混杂了\pi’ , , ,\pi’‘ , , ,\pi’’' 采集的数据有没有问题呢?没有,不是因为这些 采集的数据 有没有问题呢?没有,不是因为这些 采集的数据有没有问题呢?没有,不是因为这些 \pi 很像,主要原因是我们采样的不是一个轨迹,只是采样了一笔 e x p e r i e n c e ( 很像,主要原因是我们采样的不是一个轨迹,只是采样了一笔experience( 很像,主要原因是我们采样的不是一个轨迹,只是采样了一笔experience(s_t,a_t,r_t,s_{t+1}$)。这个理论上证明是没有问题的,很难解释…

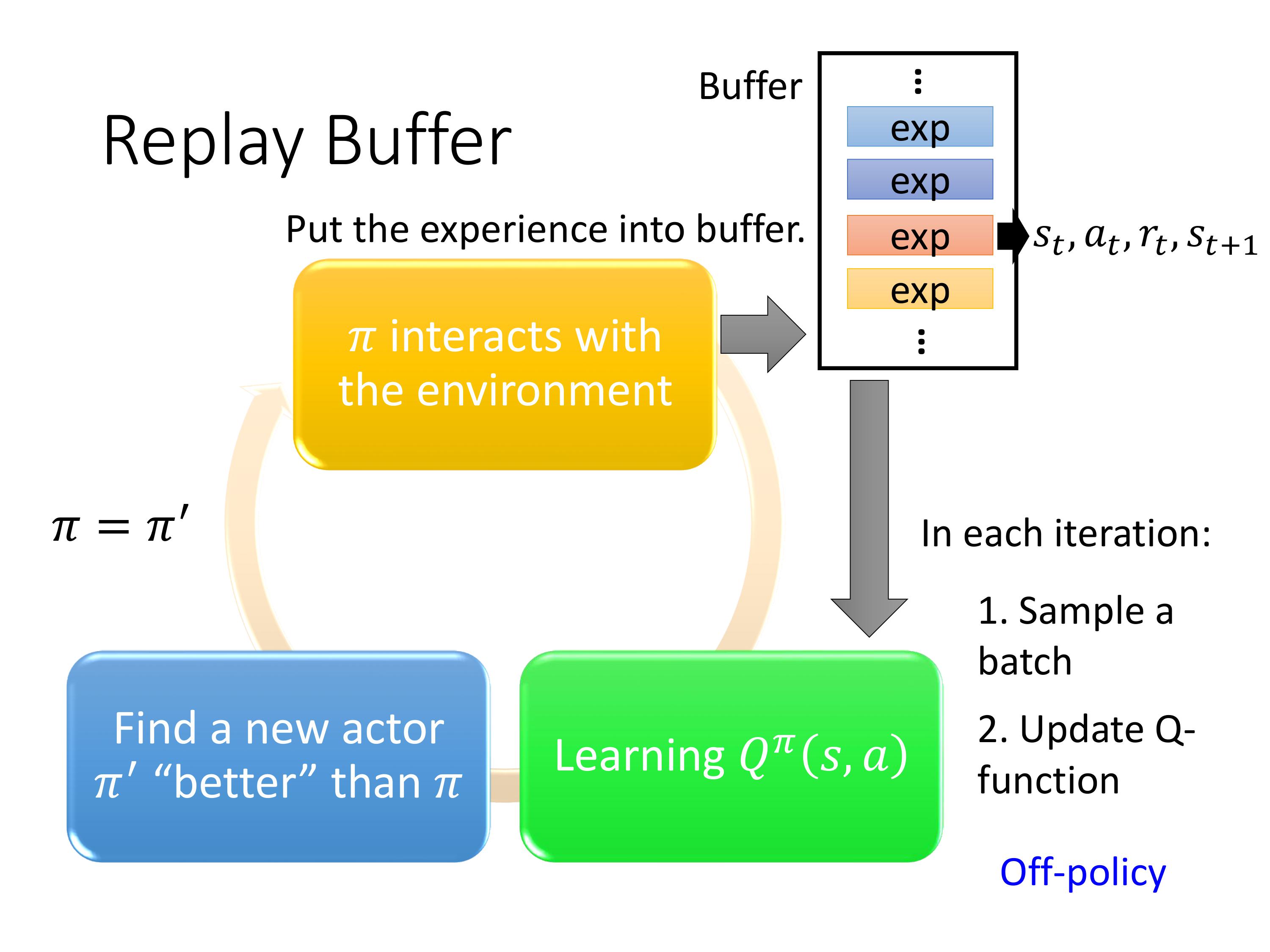
采用了3个Tips的Q-learning训练过程如图:
注意图中省略了一个循环,即存储了很多笔experience之后才会进行sample。相比于原始的Q-learning,每次sample是从replay buff里面随机抽一个batch,然后计算用绝对贪心策略得到Q-target的值作为label,接着在回归任务中更新Q的参数。每训练多步后,更新Q-target的参数。
3.2 Tips of Q-learning
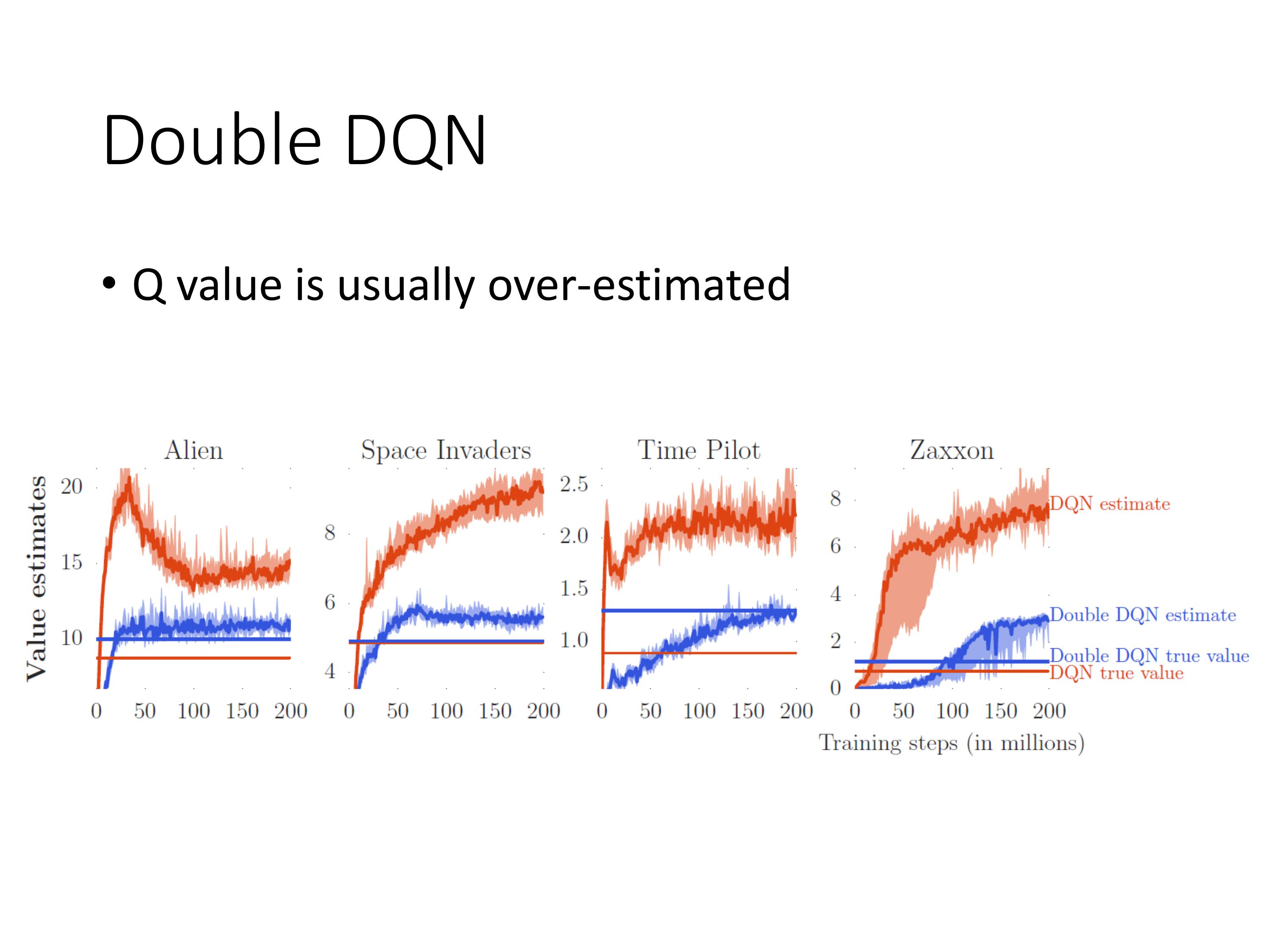
DQN估计出的值一般都高于实际的值,double DQN估计出的值与实际值比较接近。

Q是一个估计值,被高估的越多,越容易被选择。

Double的思想有点像行政跟立法分权。
用要训练的Q-network去选择动作,用固定不动的target-network去做估计,相比于DQN,只需要改一行代码!
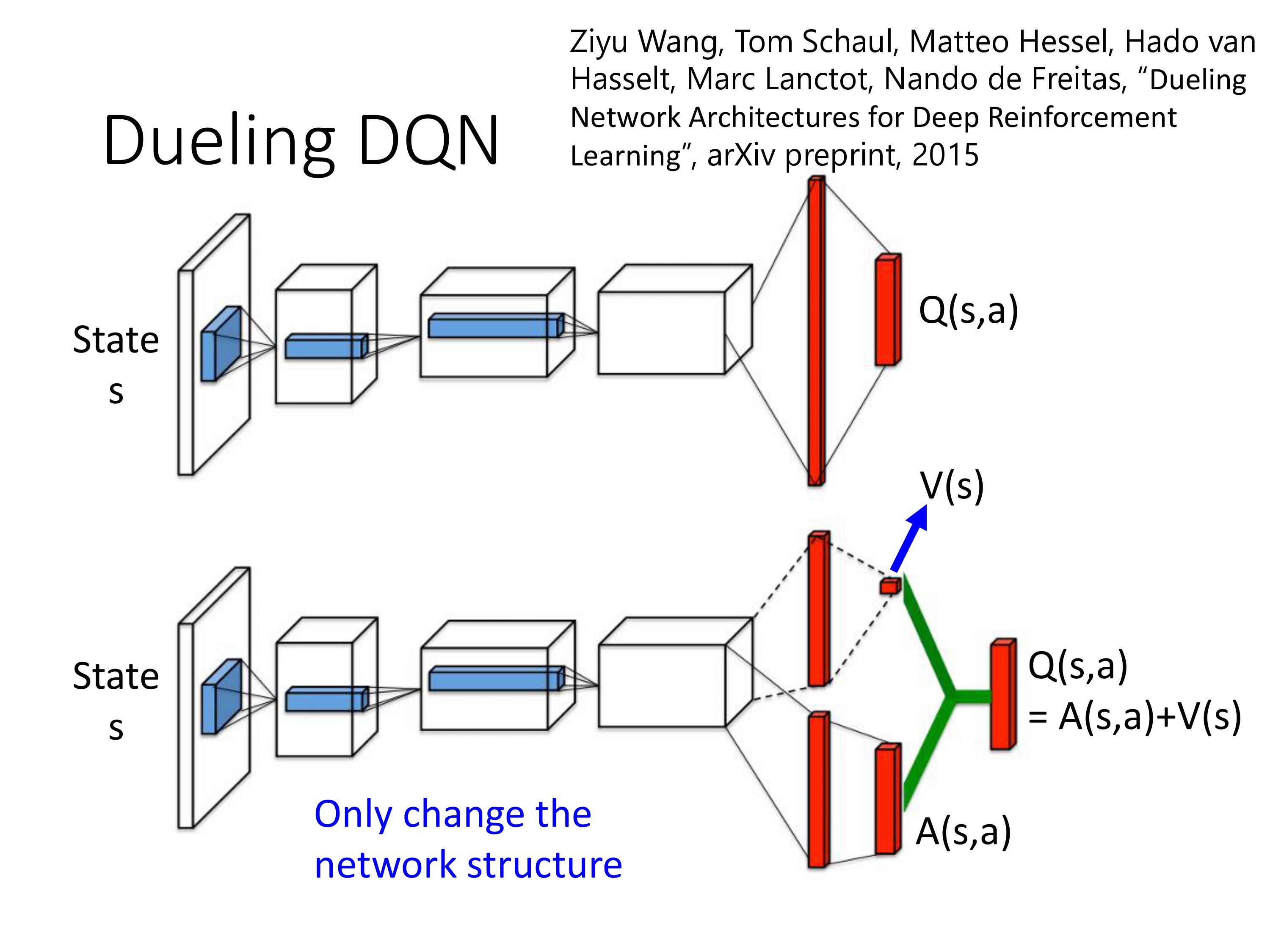
改了network架构,其他没动。每个网络结构的输出是一个标量+一个向量
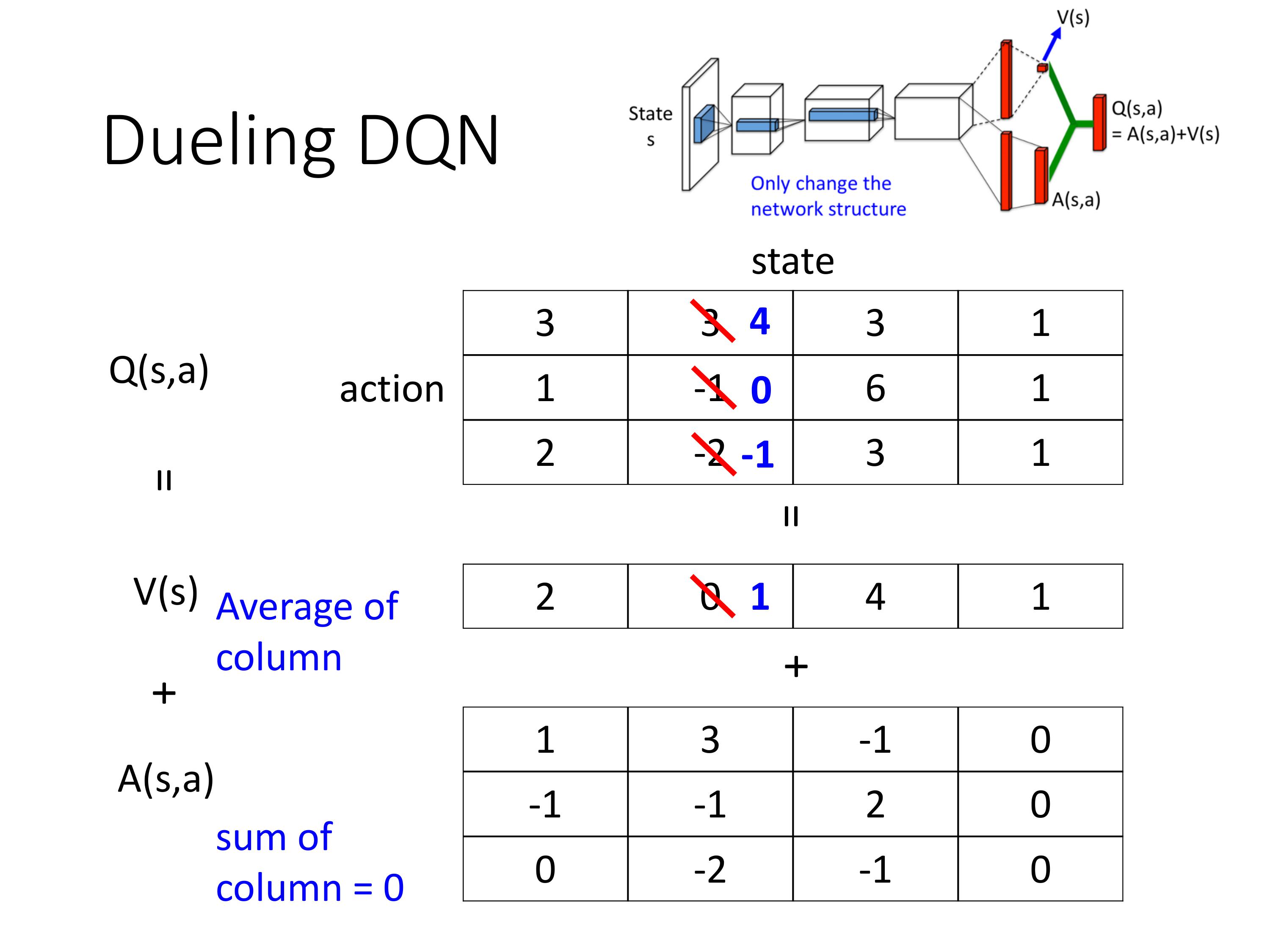
比如下一时刻,我们需要把3->4, 0->-1,那么Dueling结构里会倾向于不修改A,只调整V来达到目的,这样只需要把V中 0->1, 如果Q中的第三行-2没有被sample到,也进行了更新,提高效率,减少训练次数。
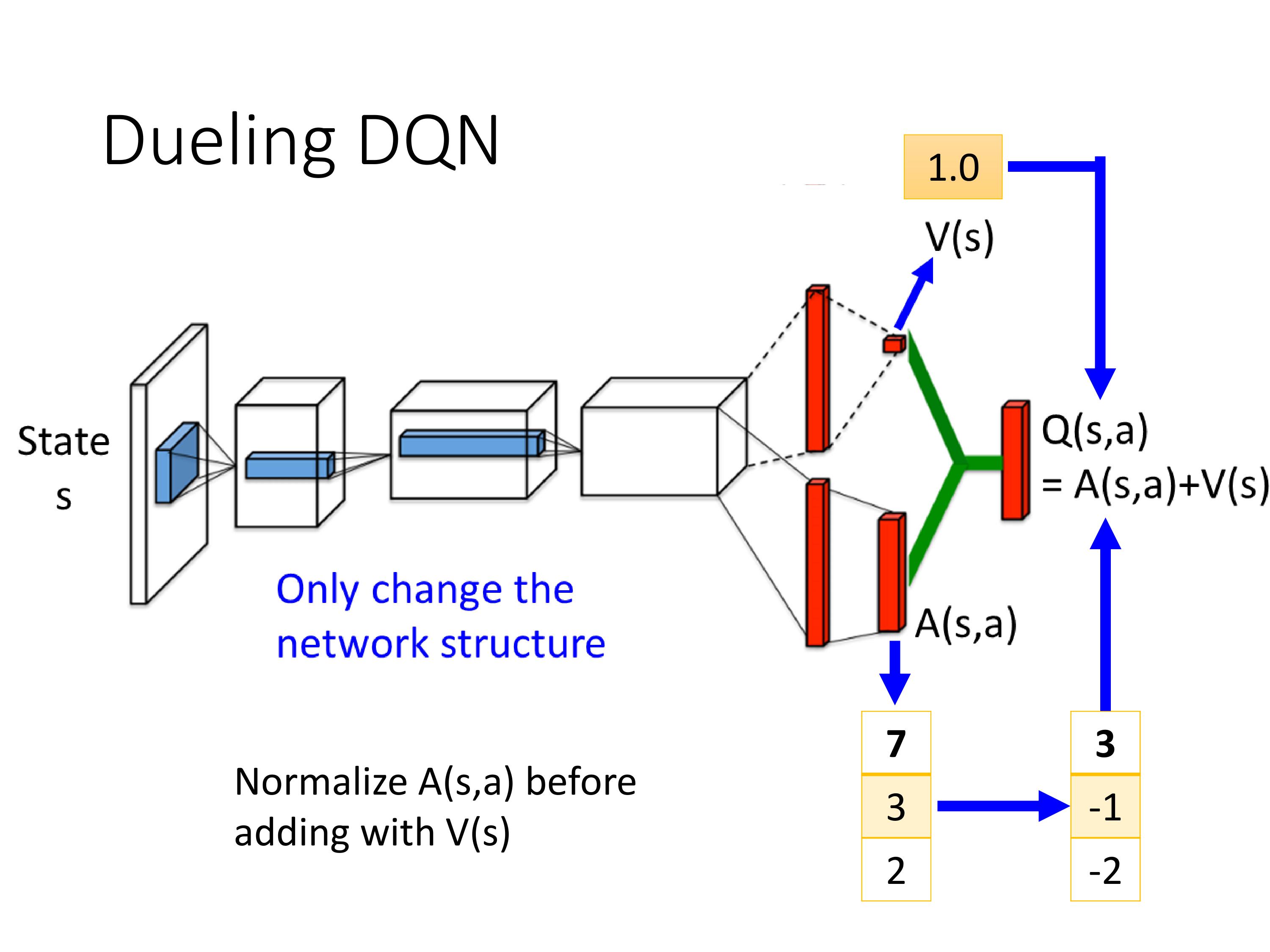
实际实现的时候,通过添加了限制条件,也就是把A normalize,使得其和为0,这样只会更新V。
这种结构让DQN也能处理连续的动作空间。
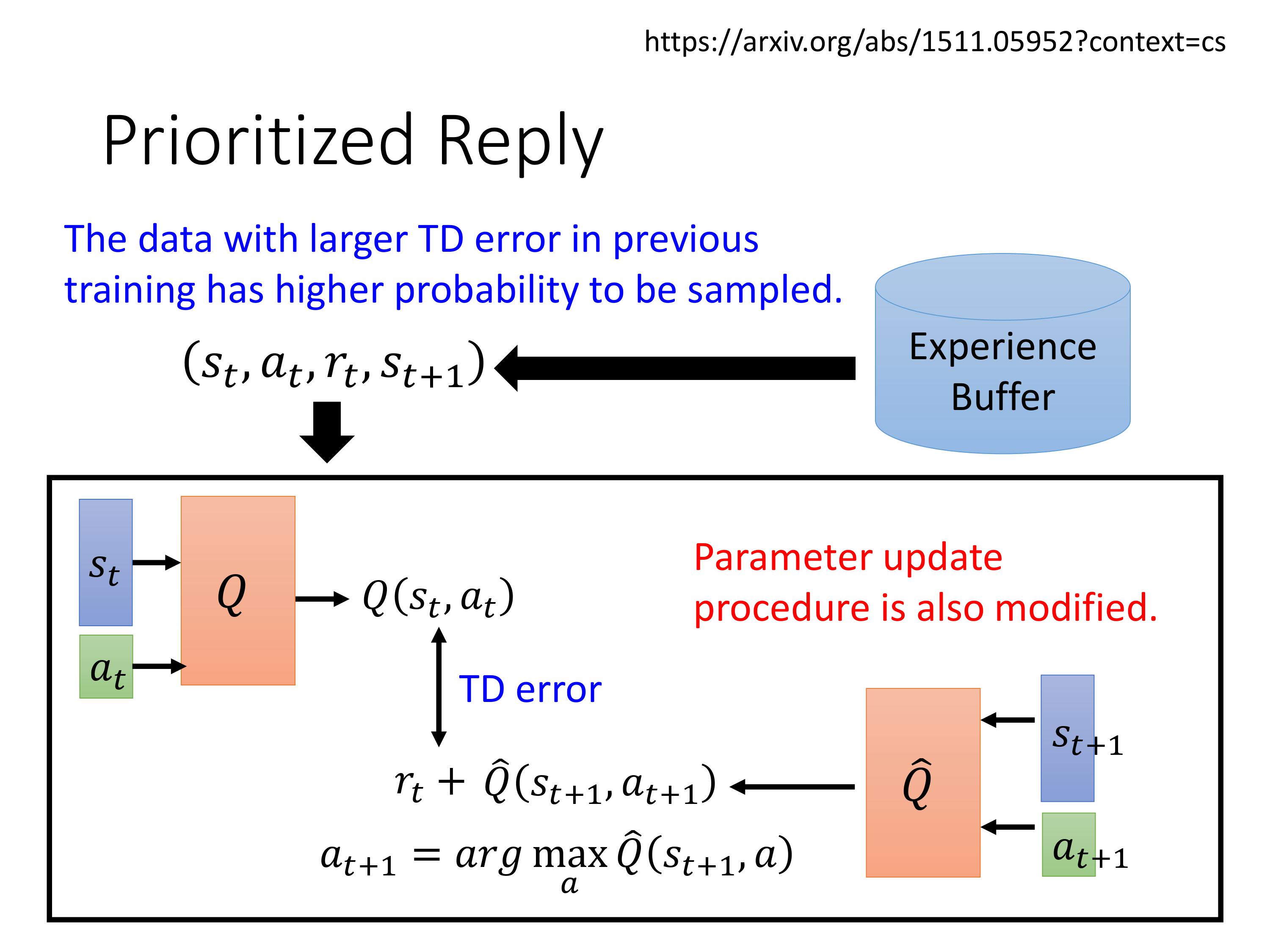
加入权重的replay buffer
motivation:TD error大的数据应该更可能被采样到
注意论文原文实现的细节里,也修改了参数更新的方法
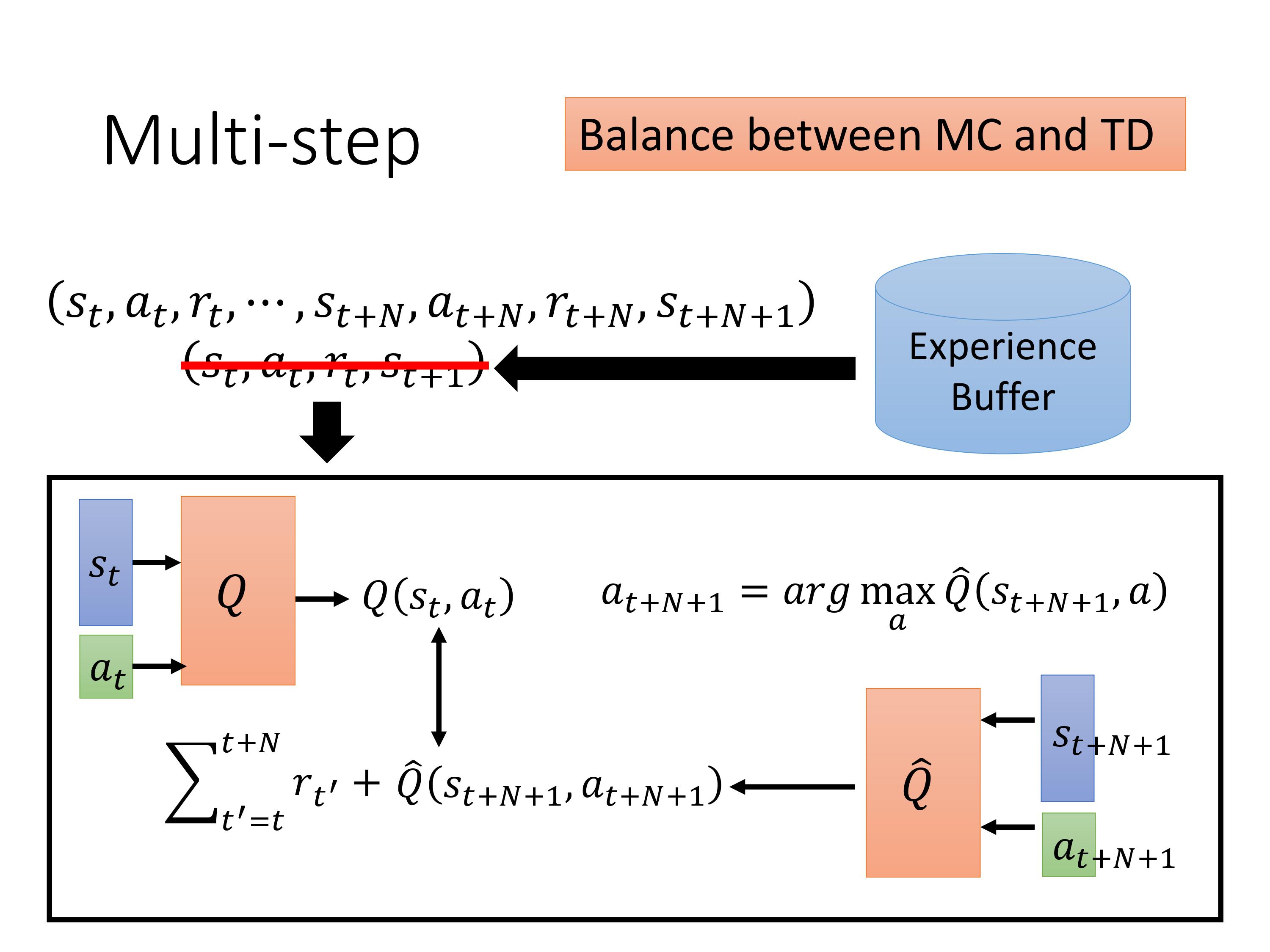
原来收集一条experience是执行一个step,现在变成执行N个step。相比TD的好处:之前只sample一个 ( s t , a t ) (s_t,a_t) (st,at)pair,现在sample多个才估测Q值,估计的误差会更小。坏处,与MC一样,reward的项数比较多,相加的方差更大。 调N就是一个trade-off的过程。

在Q-function的参数空间上+noise
比较有意思的是,OpenAI DeepMind几乎在同一个时间发布了Noisy Net思想的论文。

在同一个episode里面,在动作空间上加噪声,会导致相同state下执行的action不一样。而在参数空间加噪声,则在相同或者相似的state下,会采取同一个action。 注意加噪声只是为了在不同的episode的里面,train Q的时候不会针对特定的一个state永远只执行一个特定的action。
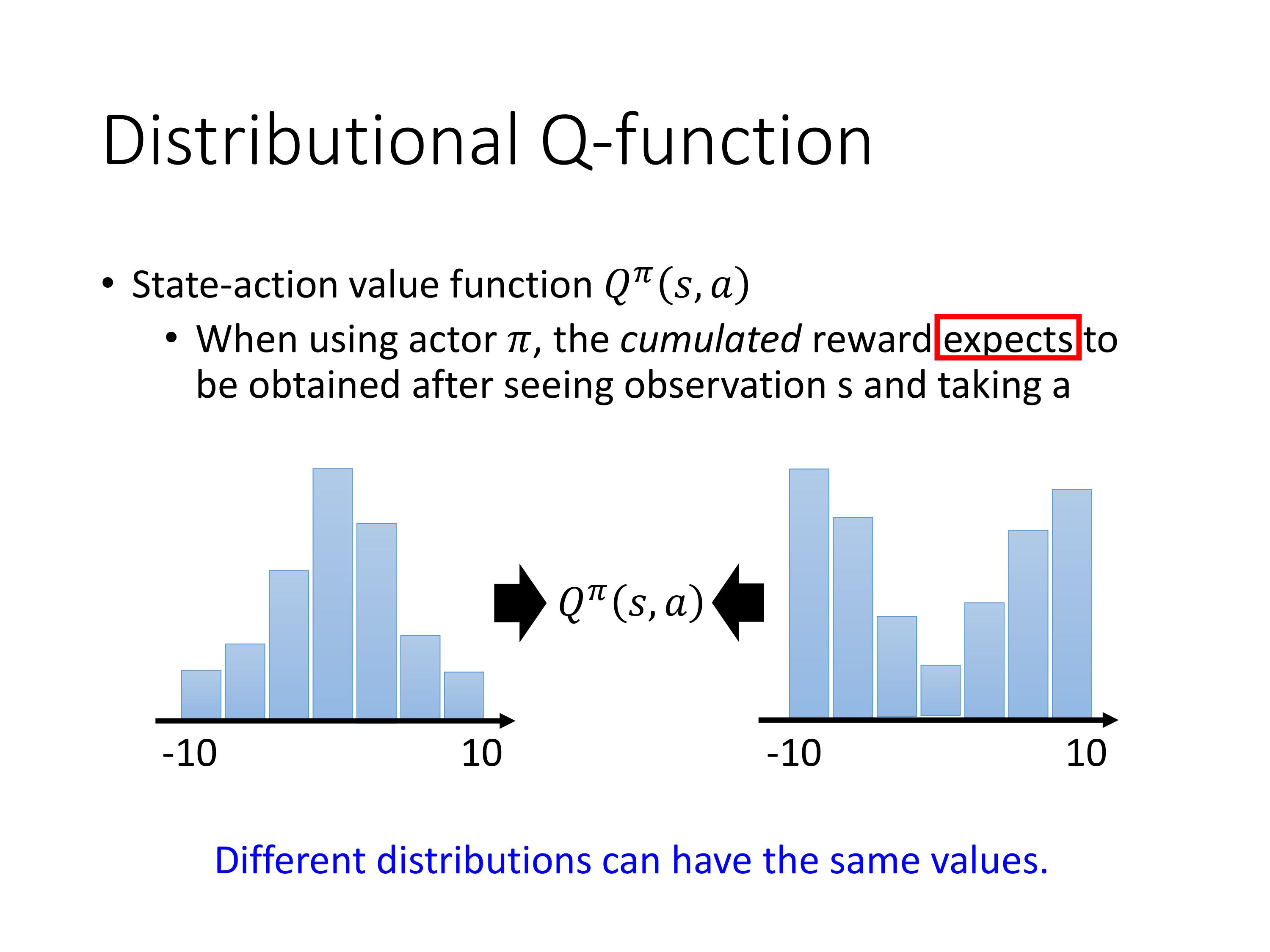
带分布的Q-function
Motivation:原来计算Q-function的值是通过累积reward的期望,也就是均值,但实际上累积的reward可能在不同的分布下会得到相同的Q值。
注意:每个Q-function的本质都是一个概率分布。
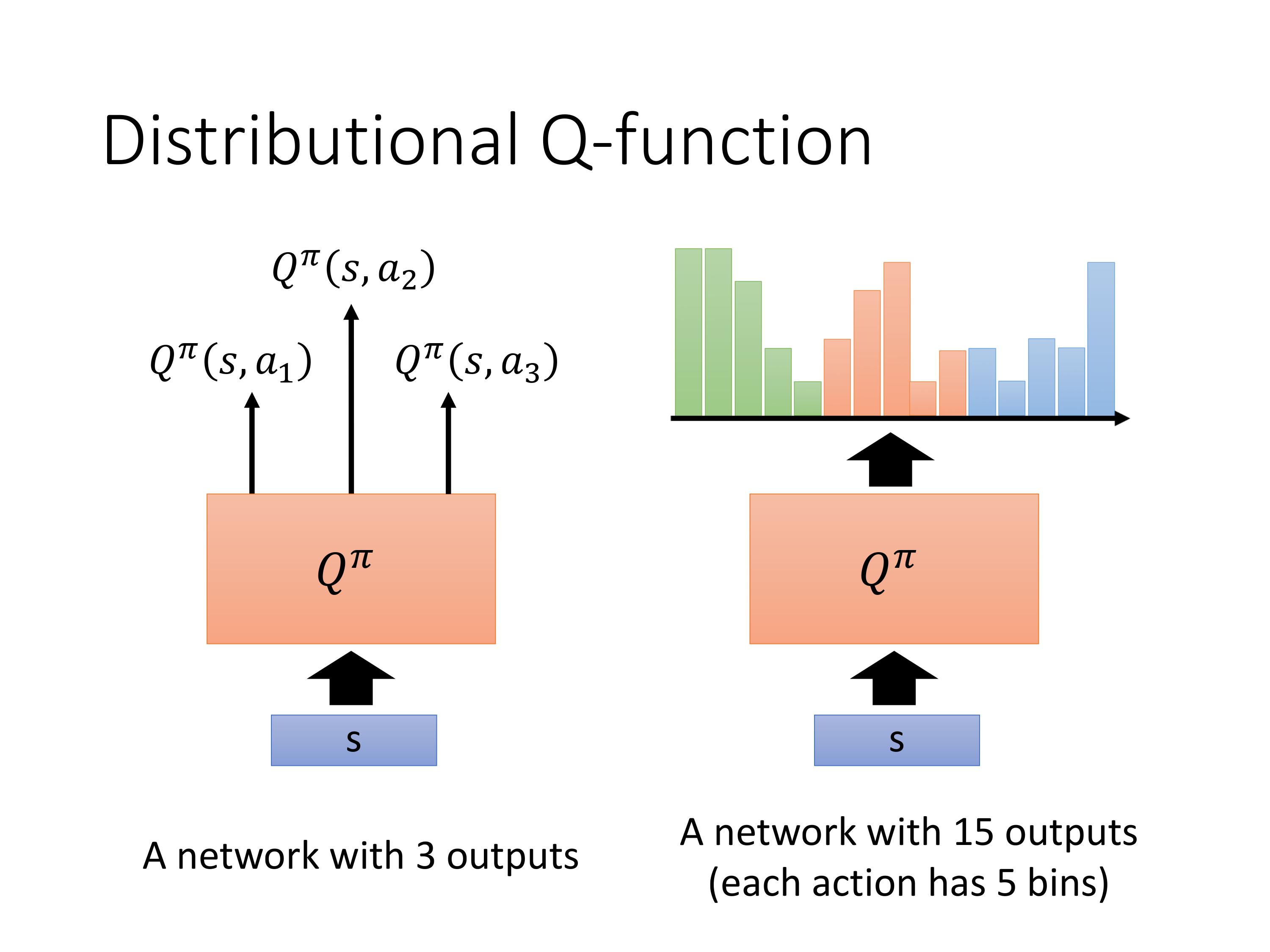
让 Q π Q^ \pi Qπ直接输出每一个Q-function的分布,但实际上选择action的时候还是会根据mean值大的选。不过拥有了这个分布,可以计算方差,这样如果有的任务需要在追求回报最大的同时降低风险,则可以利用这个分布。
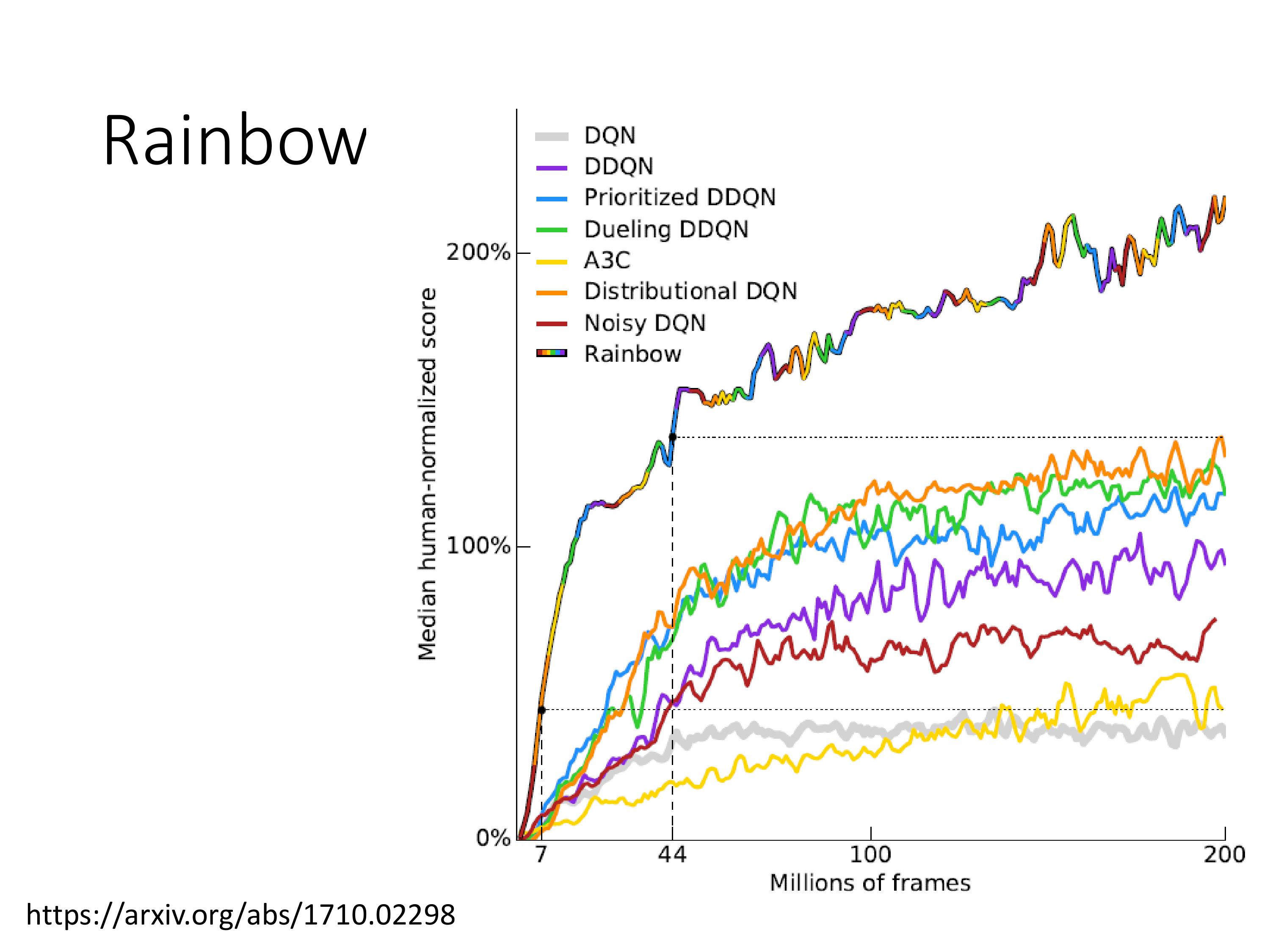
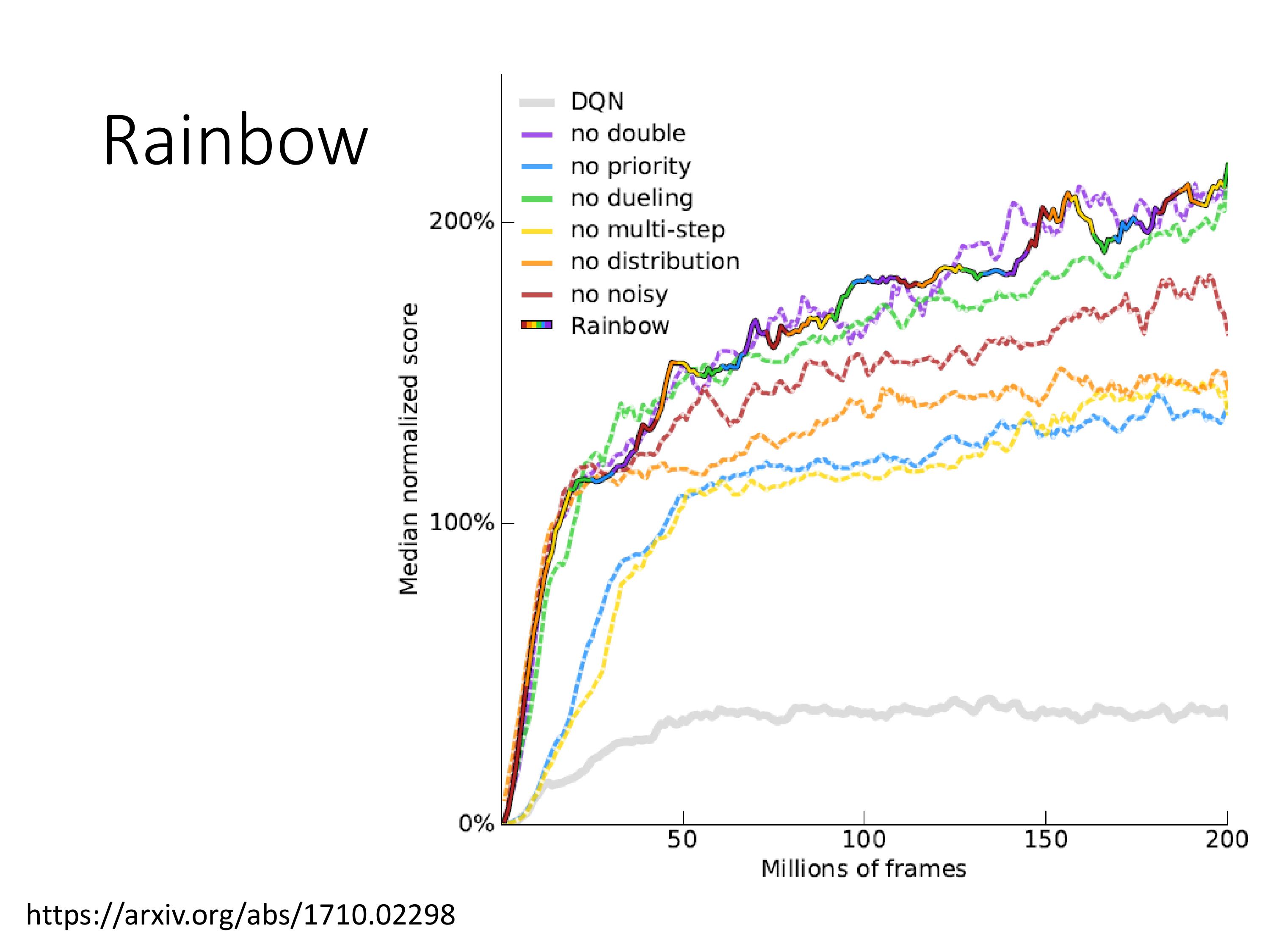
Rainbow:集成了7种升级技术的DQN
上图是一个一个改进拿掉之后的效果,看紫色似乎double 没啥用,实际上是因为有Q-function的分布存在,一般不会过高估计Q值,所以double 意义不大。
直觉的理解:使用分布DQN,即时Q值被高估很多,由于最终只会映射到对应的分布区间,所以最终的输出值也不会过大。
3.3 Q-learning in continuous actions
在出现PPO之前, PG的算法非常不稳定。DQN 比较稳定,也容易train,因为DQN是只要估计出Q-function,就能得到好的policy,而估计Q-function就是一个回归问题,回归问题比较容易判断learn的效果,看mse。问题是Q-learning不太容易处理连续动作空间。比如汽车的速度,是一个连续变量。

当动作值是连续时,怎么解argmax:
-
通过映射,强行离散化
-
使用梯度上升解这个公式,这相当于每次train完Q后,在选择action的时候又要train一次网络,比较耗时间。
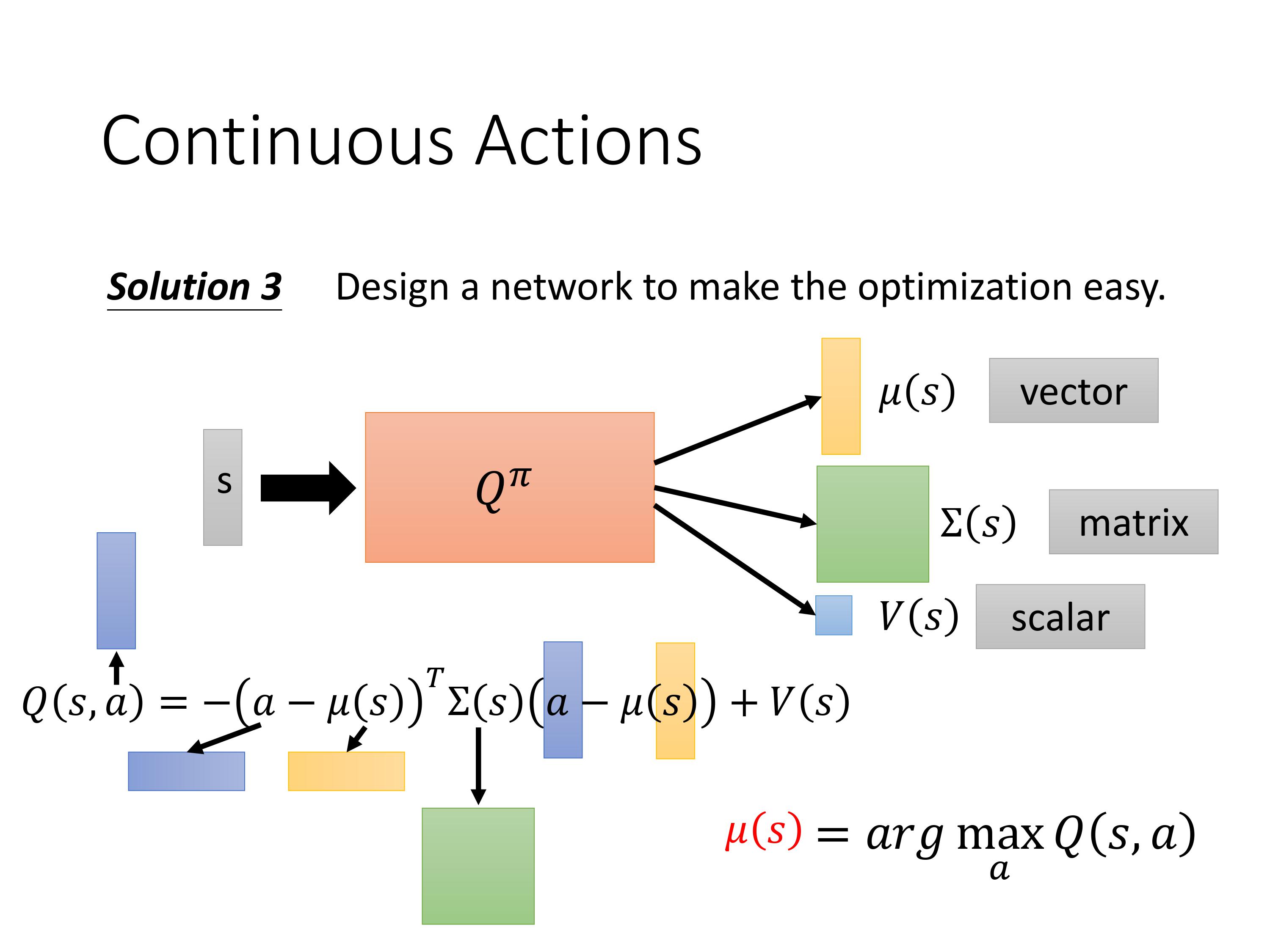
- 设计特定的网络,使得输出还是一个标量。
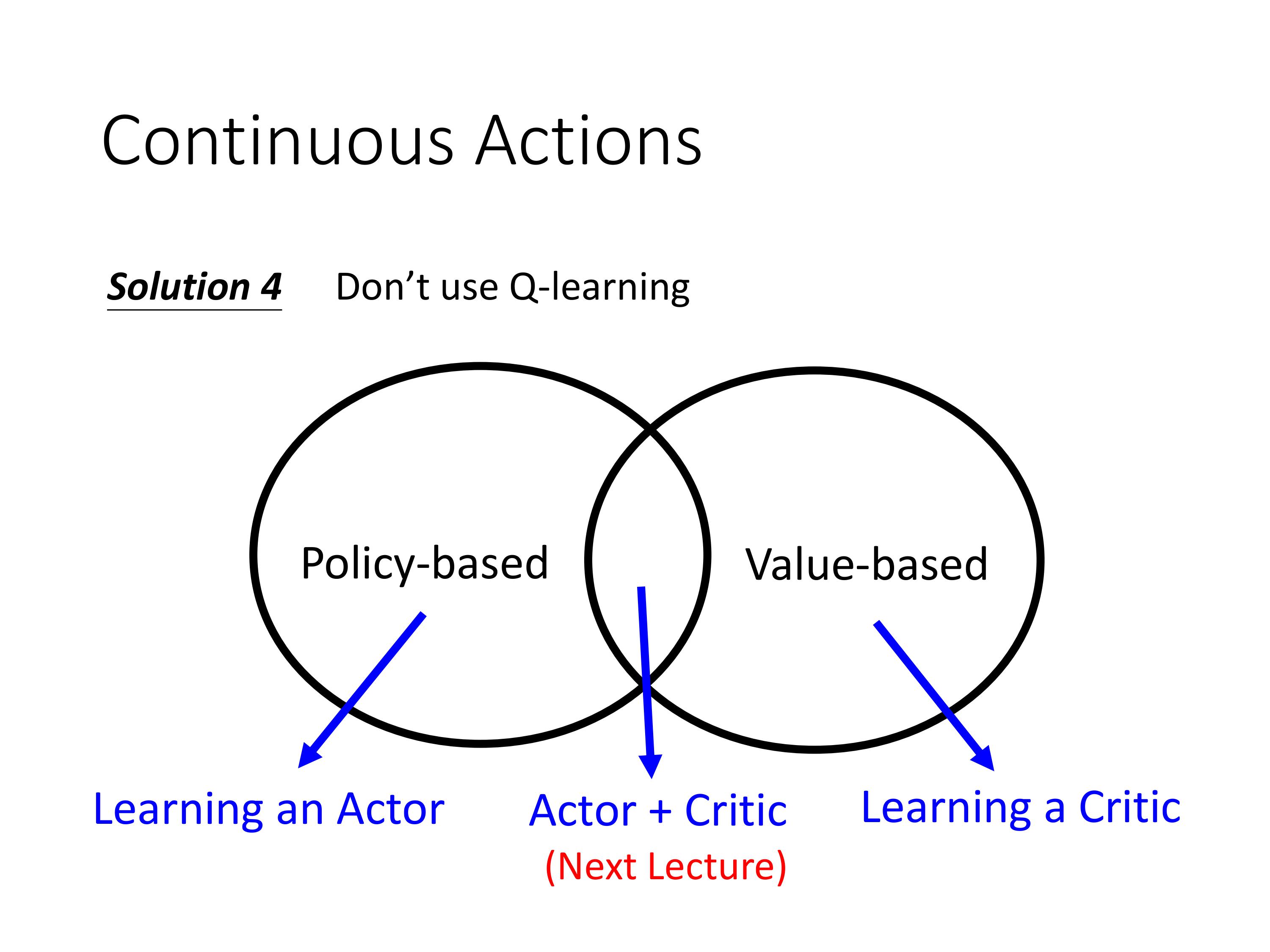
最有效的解决方法是,针对连续动作空间,不要使用Q-learning。使用AC算法!
4. Actor Critic
4.1 Advantage Actor-Critic (A2C)
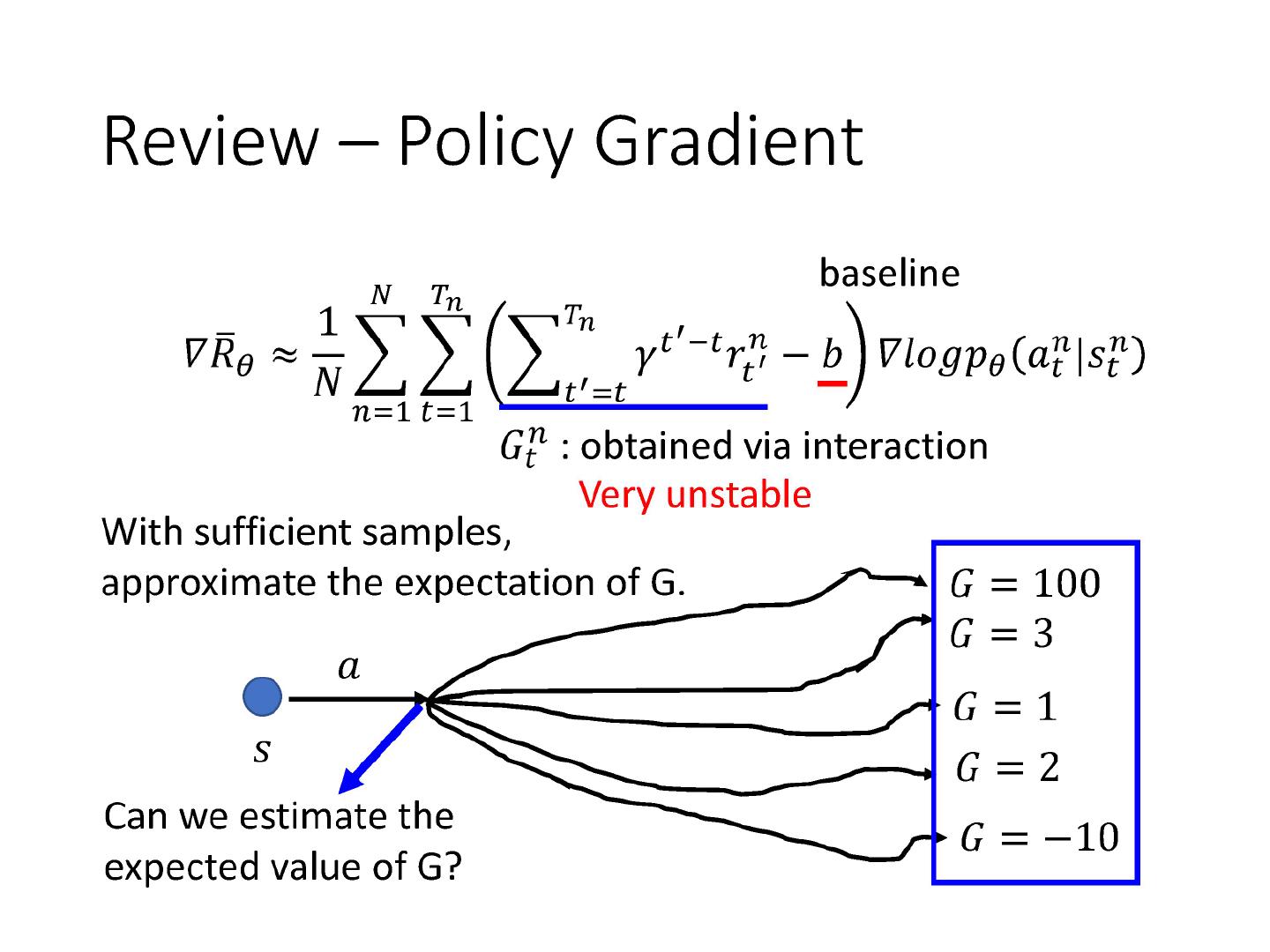
由于每次在执行PG算法之前,一般只能采样少量的数据,导致对于同一个 ( s t , a t ) (s_t,a_t) (st,at),得到的 G G G的值方差很大,不稳定。那么能不能直接估计出期望值,来替代采样的结果?
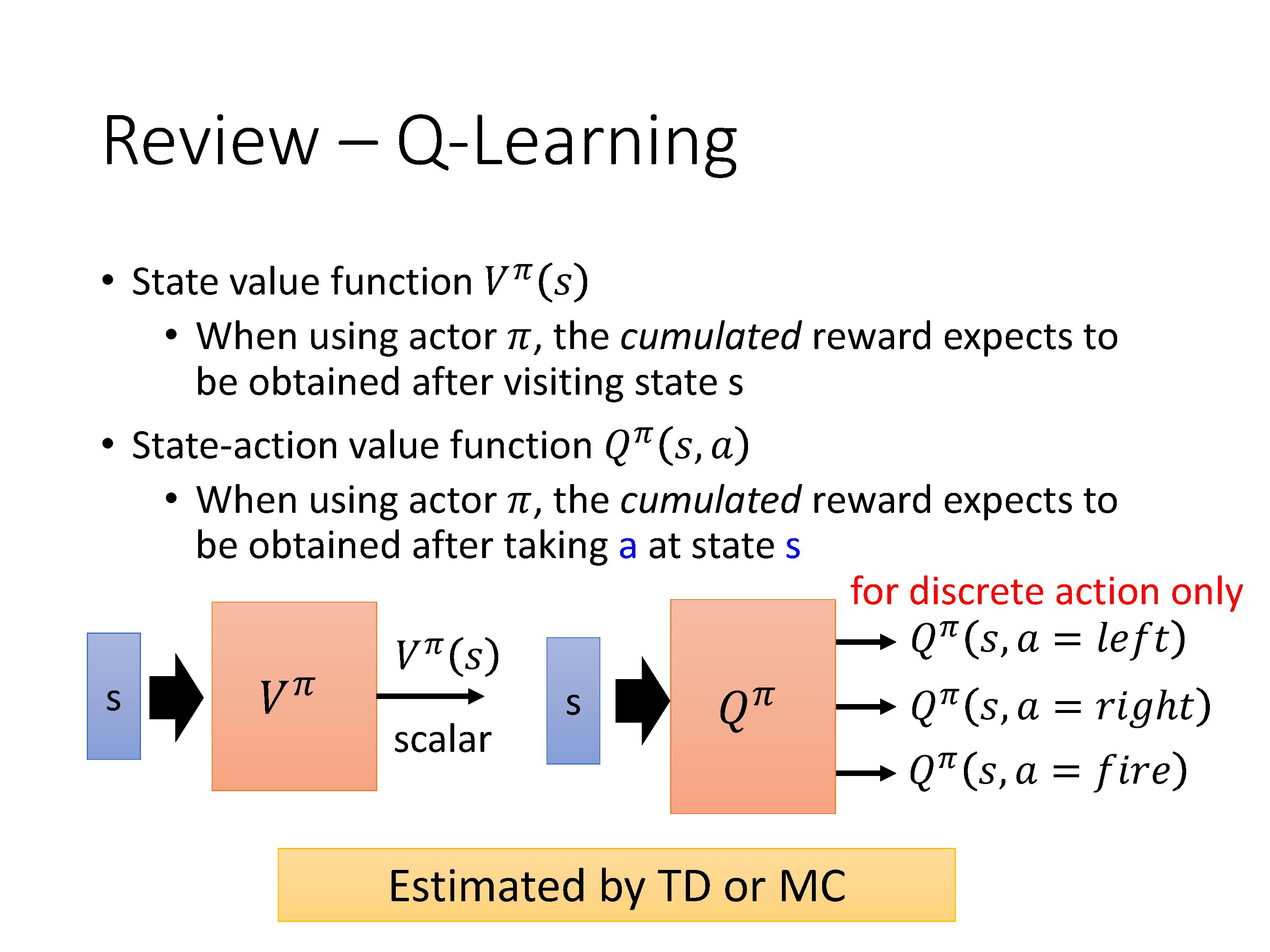
回顾下Q-learning中的定义,我们发现:
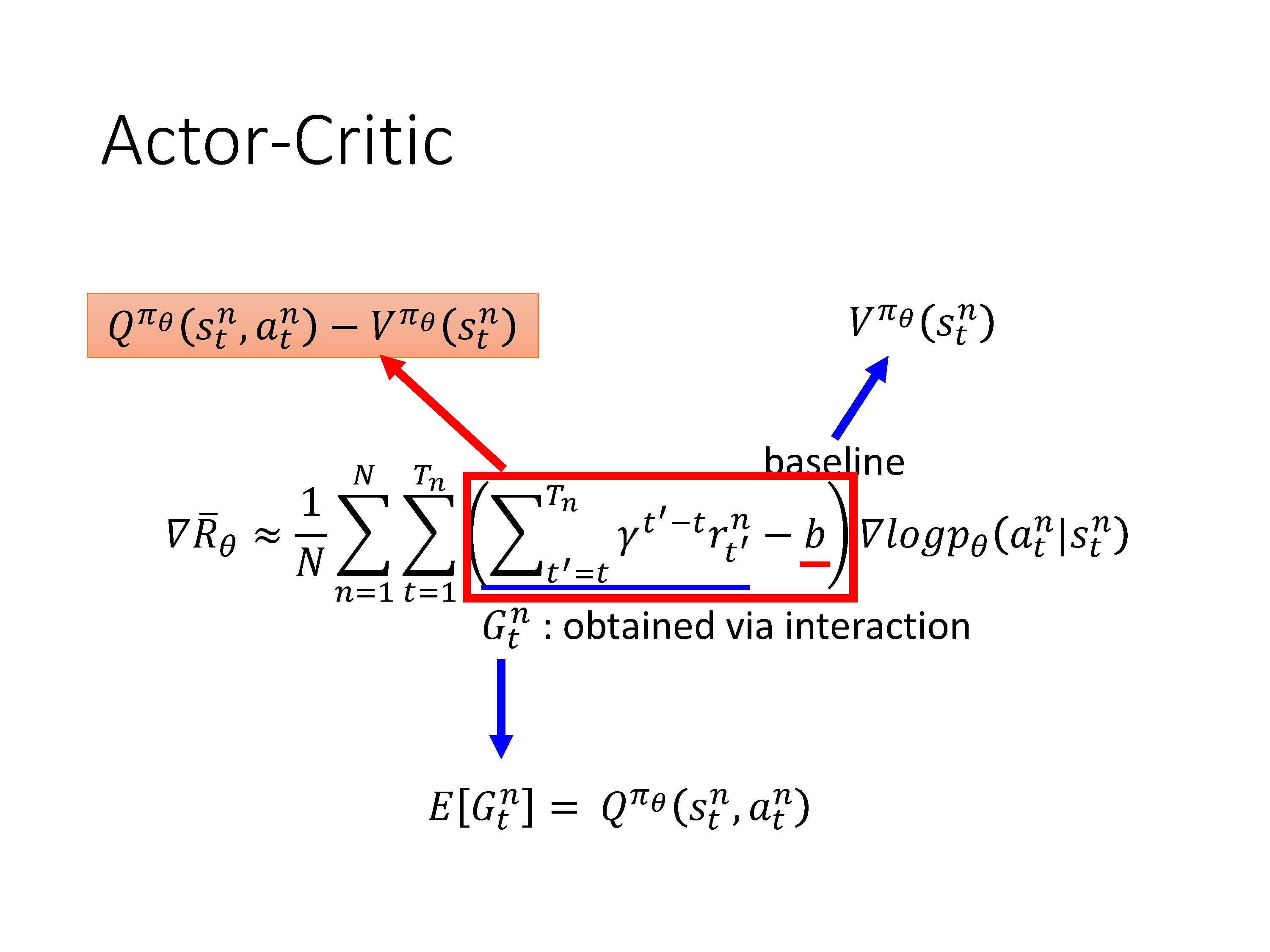
PG算法中G的期望的定义恰好也是Q-learning算法中 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a)的定义: 假设现在的policy是$ \pi$的情况下,在某一个s,采取某一个a以后得到的累积reward的期望值。
因此在这里将Q-learning引入到预估reward中,也即policy gradient和q-learning的结合,叫做Actor-Critic。
把原来的reward和baseline分别替换,PG算法中的减法就变成了 Q π θ ( s t n , a t n ) − V π θ ( s t n ) Q^{\pi_{\theta}}\left(s_{t}^{n}, a_{t}^{n}\right)-V^{\pi_{\theta}}\left(s_{t}^{n}\right) Qπθ(stn,atn)−Vπθ(stn)。似乎我们需要训练2个网络?

实际上Q与V可以互相转化,我们只需要训练V。转化公式中为什么要加期望?在s下执行a得到的$ r_t 和 和 和s_{t+1}$是随机的。
实际将Q变成V的操作中,我们会去掉期望,使得只需要训练(估计)状态值函数 V π V^\pi Vπ,这样会导致一点偏差,但比同时估计两个function导致的偏差要好。(A3C原始paper通过实验验证了这一点)。
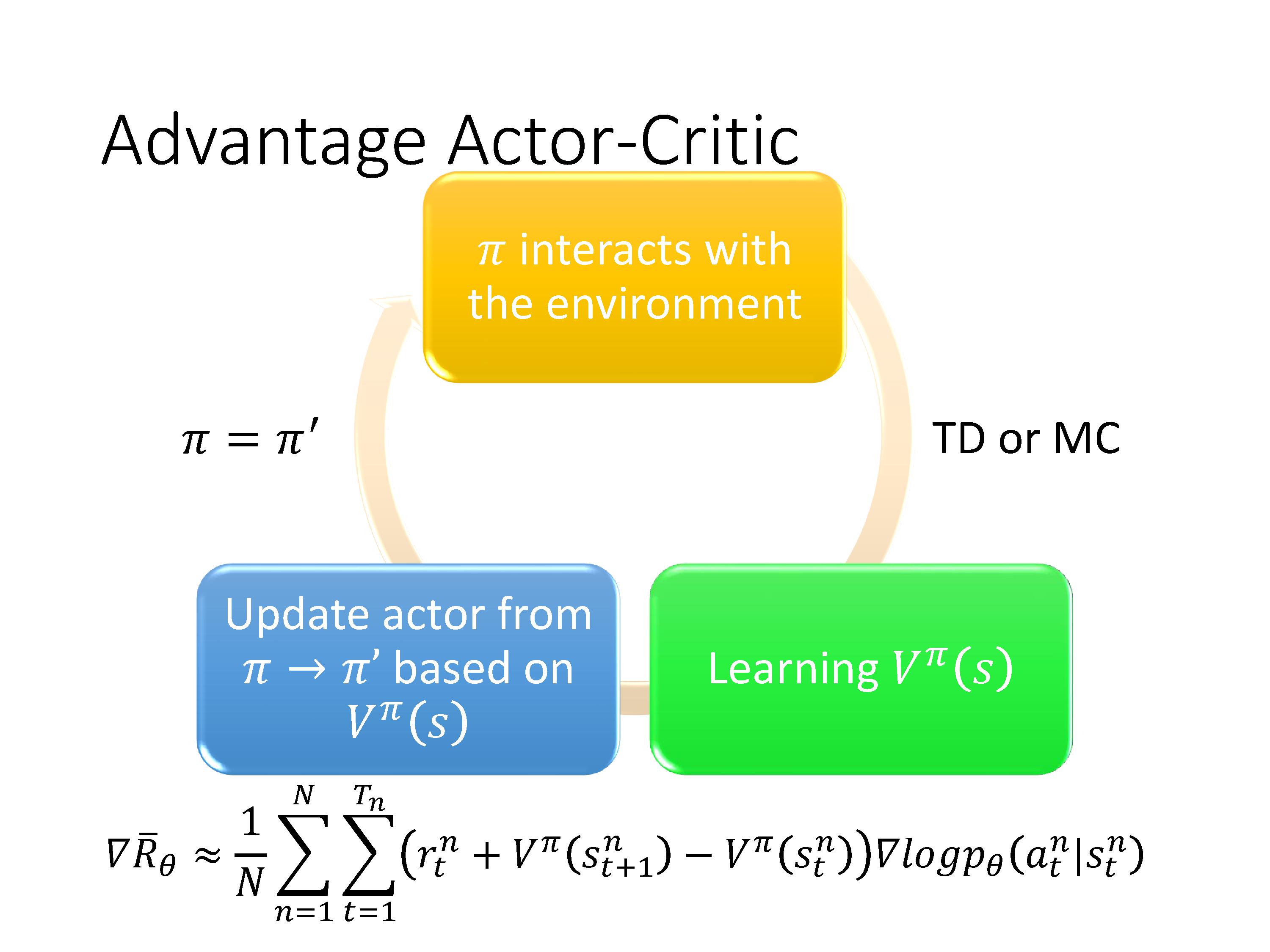
A2C的训练流程:收集数据,估计出状态值函数 V π ( s ) V^\pi(s) Vπ(s),套用公式更新策略 π \pi π,再利用新的 π \pi π与环境互动收集新的数据,不断循环。
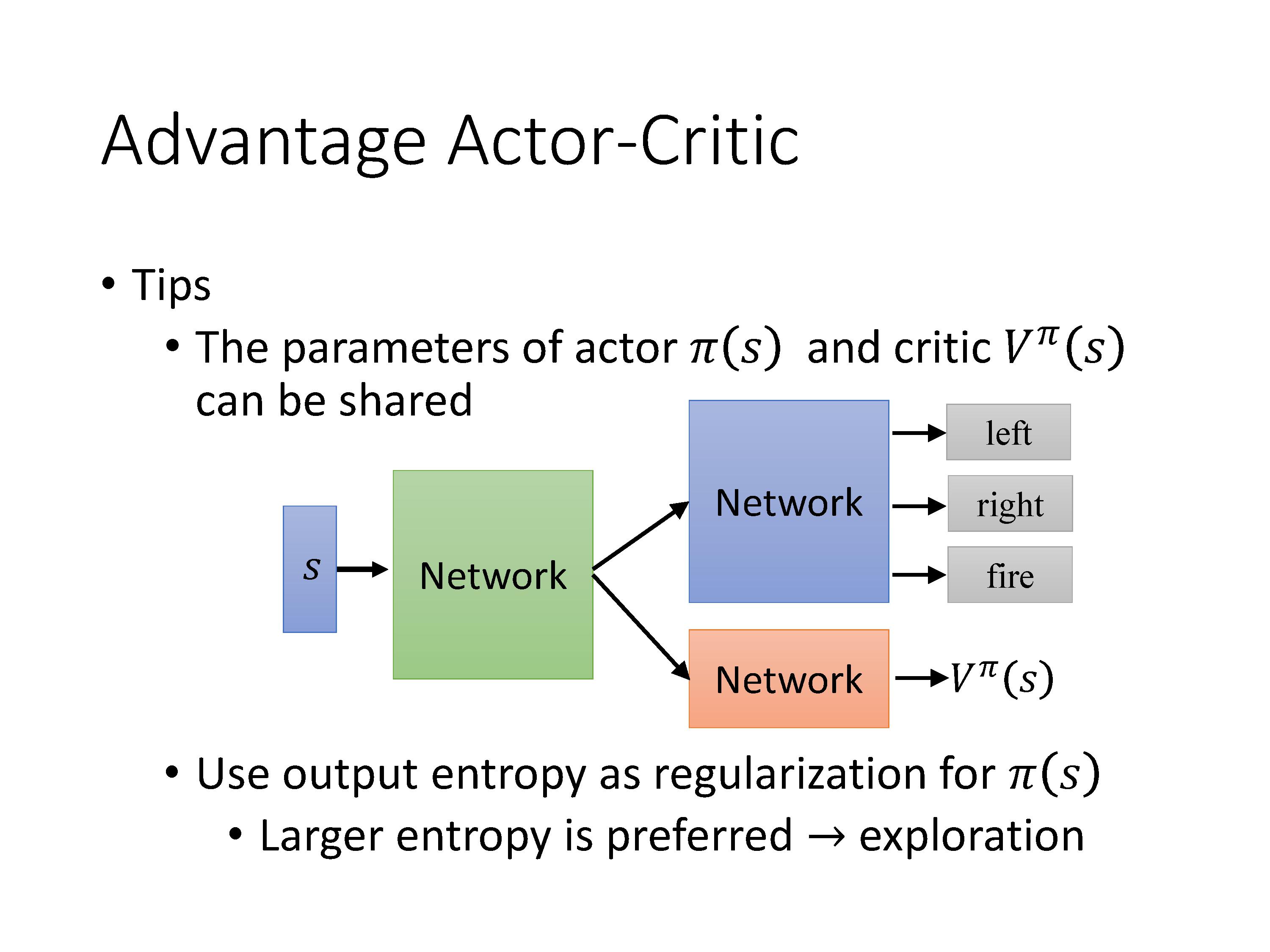
训练过程中的2个Tips:
- Actor与Critic的前几层一般会共用参数,因为输入都是state
- 正则化:让采用不同action的概率尽量平均,希望有更大的entropy,这样能够探索更多情况。
4.2 Asynchronous Advantage Actor-Critic (A3C)

A3C算法的motivation:开分身学习~
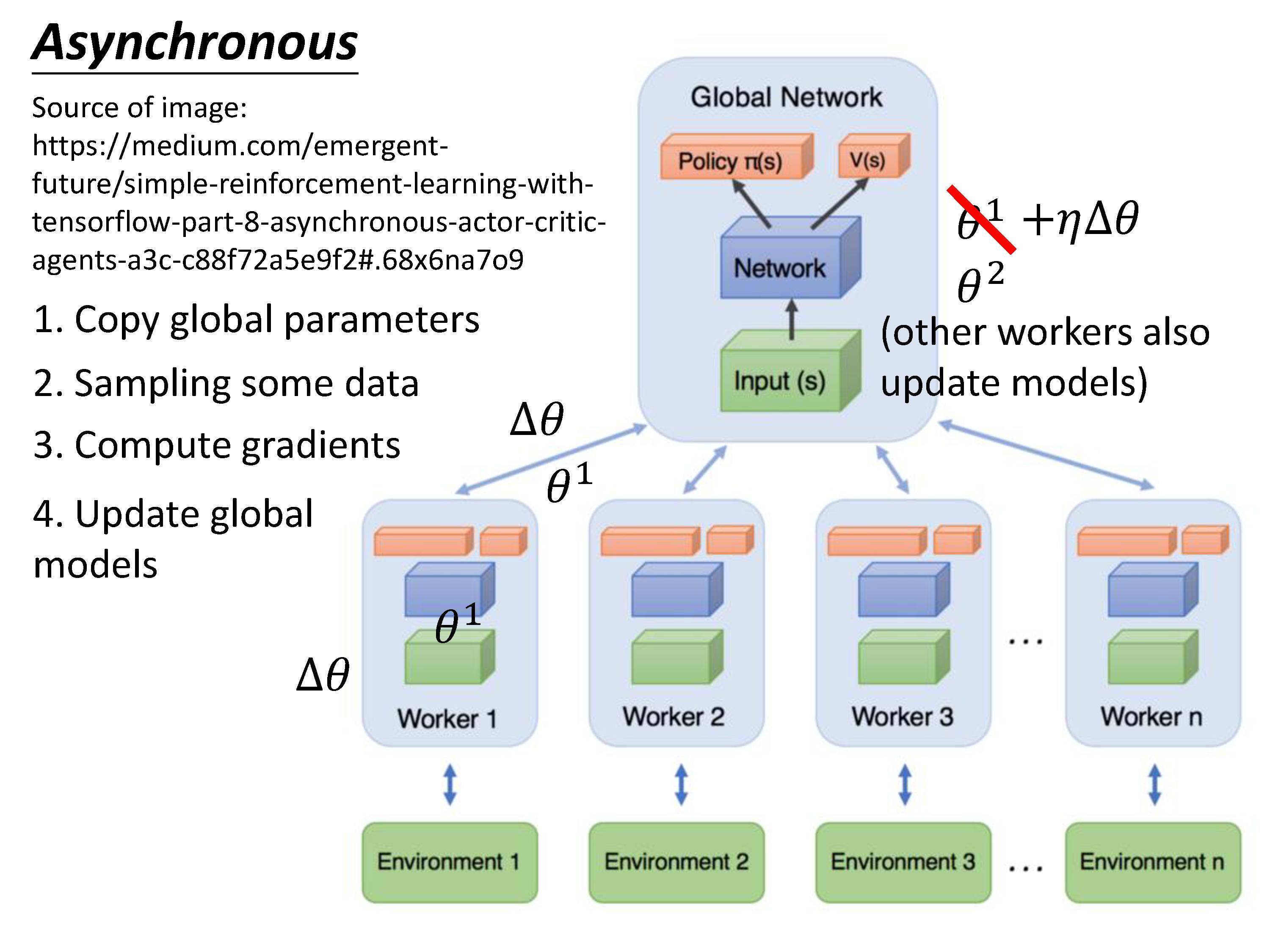
训练过程:每个agent复制一份全局参数,然后各自采样数据,计算梯度,更新这份全局参数,然后将结果传回,复制一份新的参数。
注意:
-
初始条件会尽量的保证多样性(Diverse),让每个agent探索的情况更加不一样。
-
所有的actor都是平行跑的,每个worker把各自的参数传回去然后复制一份新的全局参数。此时可能这份全局参数已经发生了改变,没有关系。
4.3 Pathwise Derivative Policy Gradient (PDPG)
在之前Actor-Critic框架里,Critic的作用是评估agent所执行的action好不好?那么Critic能不能不止给出评价,还给出指导意见呢?即告诉actor要怎样做才能更好?于是有了DPG算法:
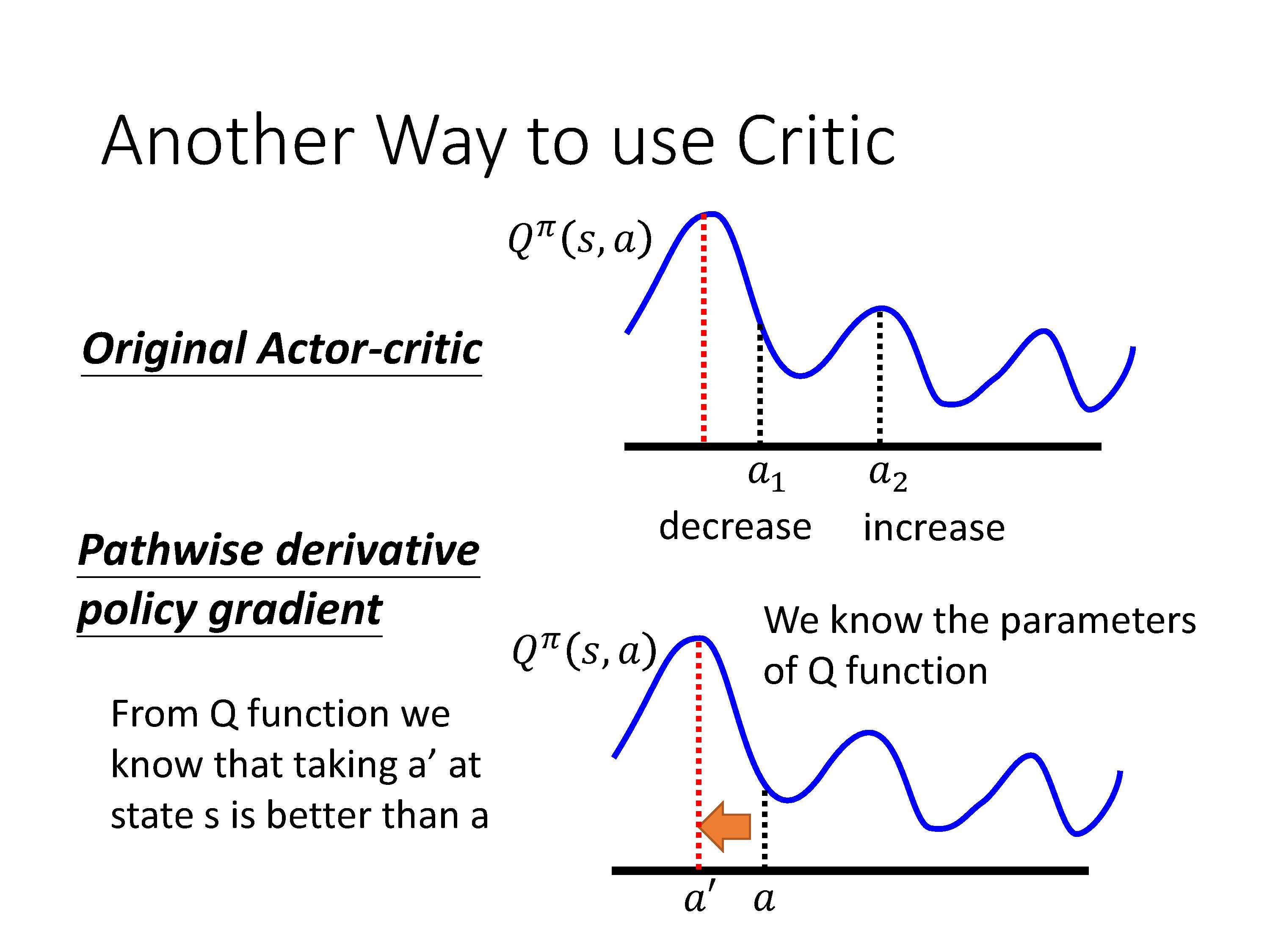
在上面介绍A2C算法的motivation,主要是从改进PG算法引入。那么从Q-learning的角度来看,PDPG相当于learn一个actor,来解决argmax这个优化问题,以处理连续动作空间,直接根据输入的状态输出动作。
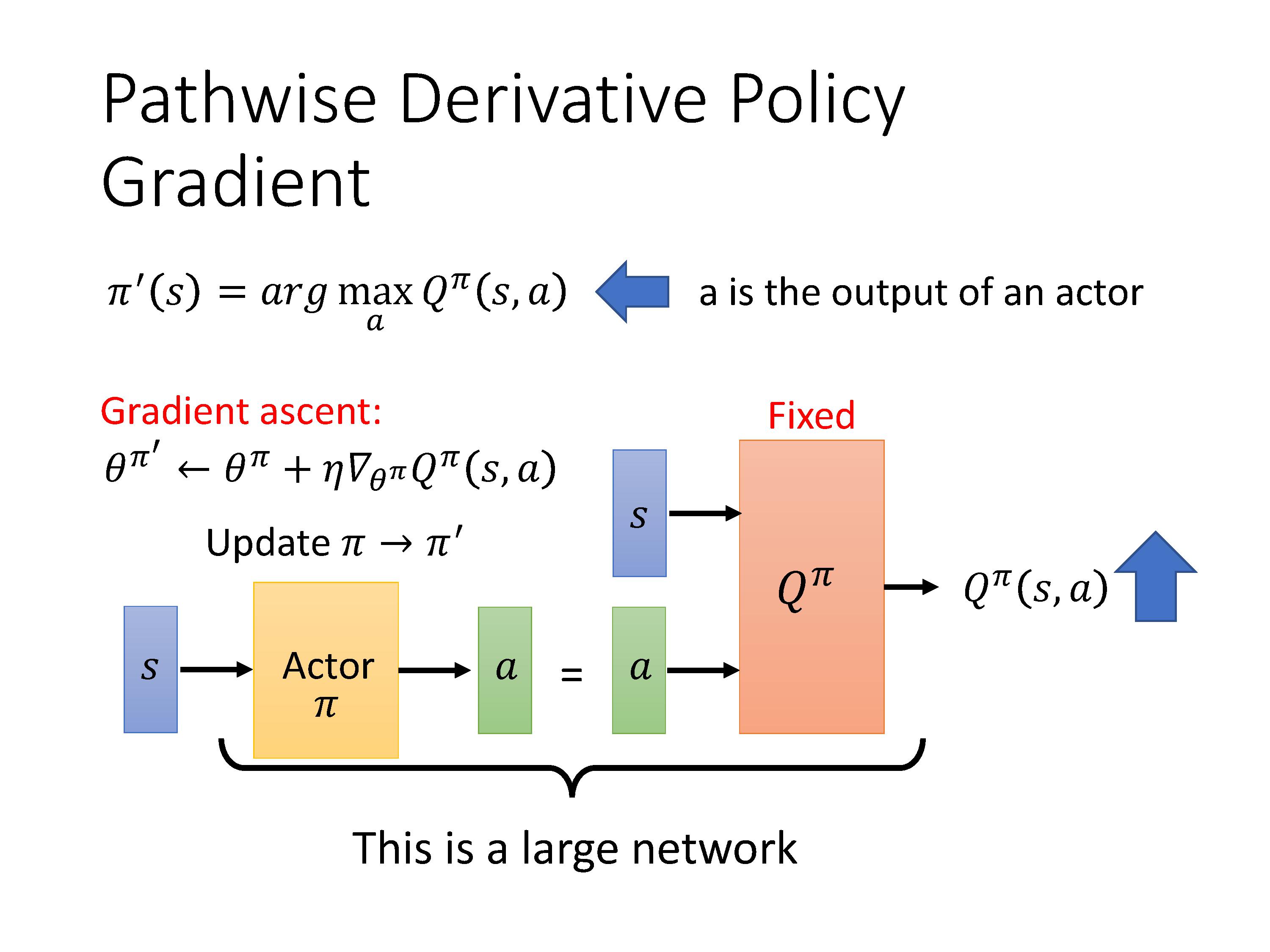
Actor+Critic连成一个大的网络,训练过程中也会采取TD-target的技巧,固定住Critic π ′ \pi' π′,使用梯度上升优化Actor
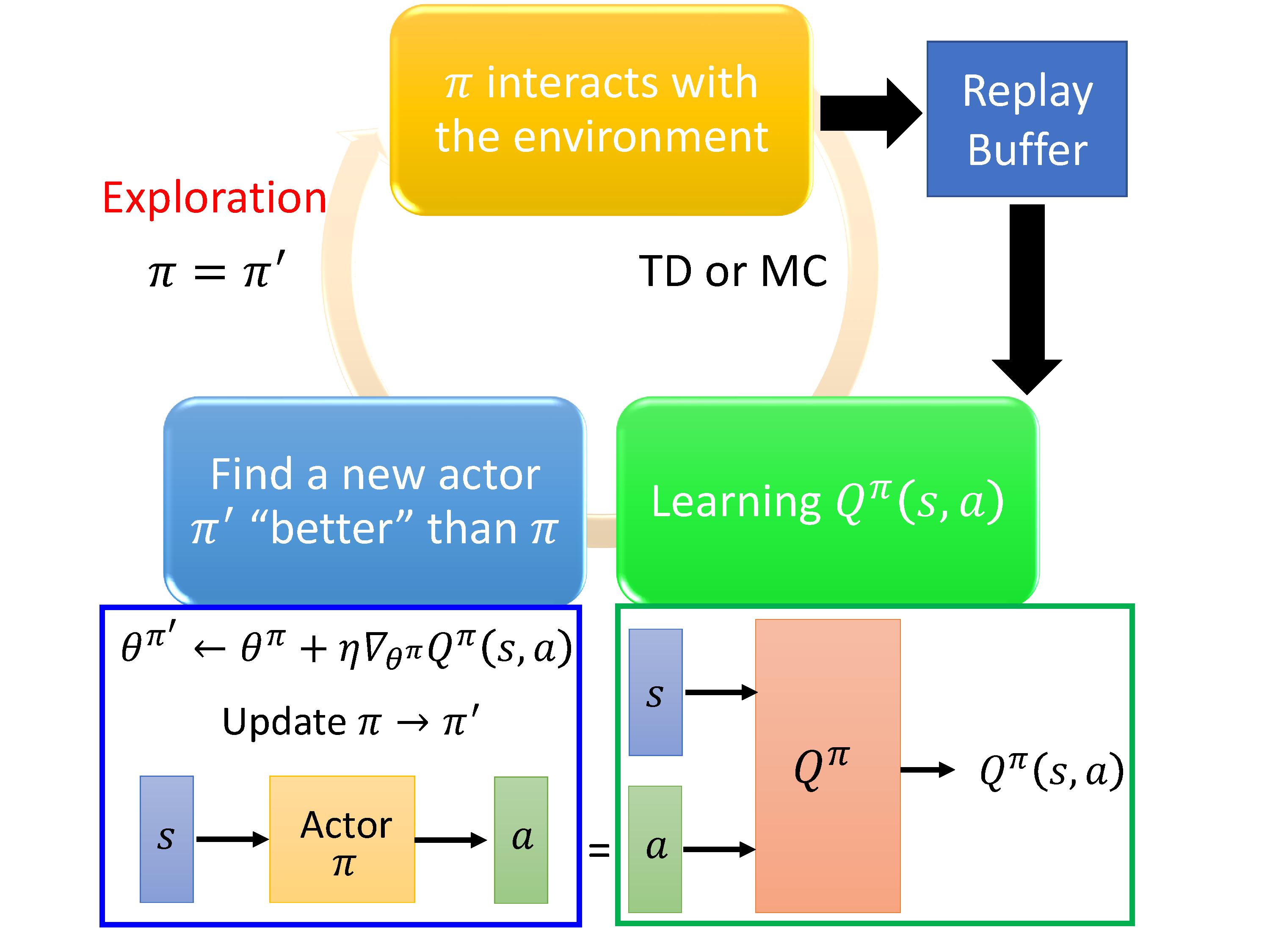
训练过程:Actor会学到策略 π \pi π,使基于策略 π \pi π,输入s可以获得能够最大化Q的action,天然地能够处理continuous的情况。当actor生成的 Q π Q^\pi Qπ效果比较好时,重新采样生成新的Q。有点像GAN中的判别器与生成器。
注意:从算法的流程可知,Actor 网络和 Critic 网络是分开训练的,但是两者的输入输出存在联系,Actor 网络输出的 action 是 Critic 网络的输入,同时 Critic 网络的输出会被用到 Actor 网路进行反向传播。
由于Critic模块是基于Q-learning算法,所以Q learning的技巧,探索机制,回忆缓冲都可以用上。


与Q-learning相比的改进:
- 不通过Q-function输出动作,直接用learn一个actor网络输出动作(Policy-based的算法的通用特性)。
- 对于连续变量,不好解argmax的优化问题,转化成了直接选择
π
−
t
a
r
g
e
t
\pi-target
π−target 输出的动作,再基于Q-target得出y。
- 引入 π − t a r g e t \pi-target π−target,也使得actor网络不会频繁更新,会通过采样一批数据训练好后再更新,提高训练效率。
总结下:最基础的 Policy Gradient 是回合更新的,通过引入 Critic 后变成了单步更新,而这种结合了 policy 和 value 的方法也叫 Actor-Critic,Critic 有多种可选的方法。A3C在A2C的基础上引入了多个 agent 对网络进行异步更新。对于输出动作为连续值的情形,原始的输出动作概率分布的PG算法不能解决,同时Q-learning算法也不能处理这类问题,因此提出了 DPG 。
5. Sparse Reward
大多数RL的任务中,是没法得到reward,reward=0,导致reward空间非常的sparse。
比如我们需要赢得一局游戏才能知道胜负得到reward,那么玩这句游戏的很长一段时间内,我们得不到reward。比如如果机器人要将东西放入杯子才能得到一个reward,尝试了很多动作很有可能都是0。
但是人可以在非常sprse的环境下进行学习,所以这一章节提出的很多算法与人的一些学习机制比较类似。
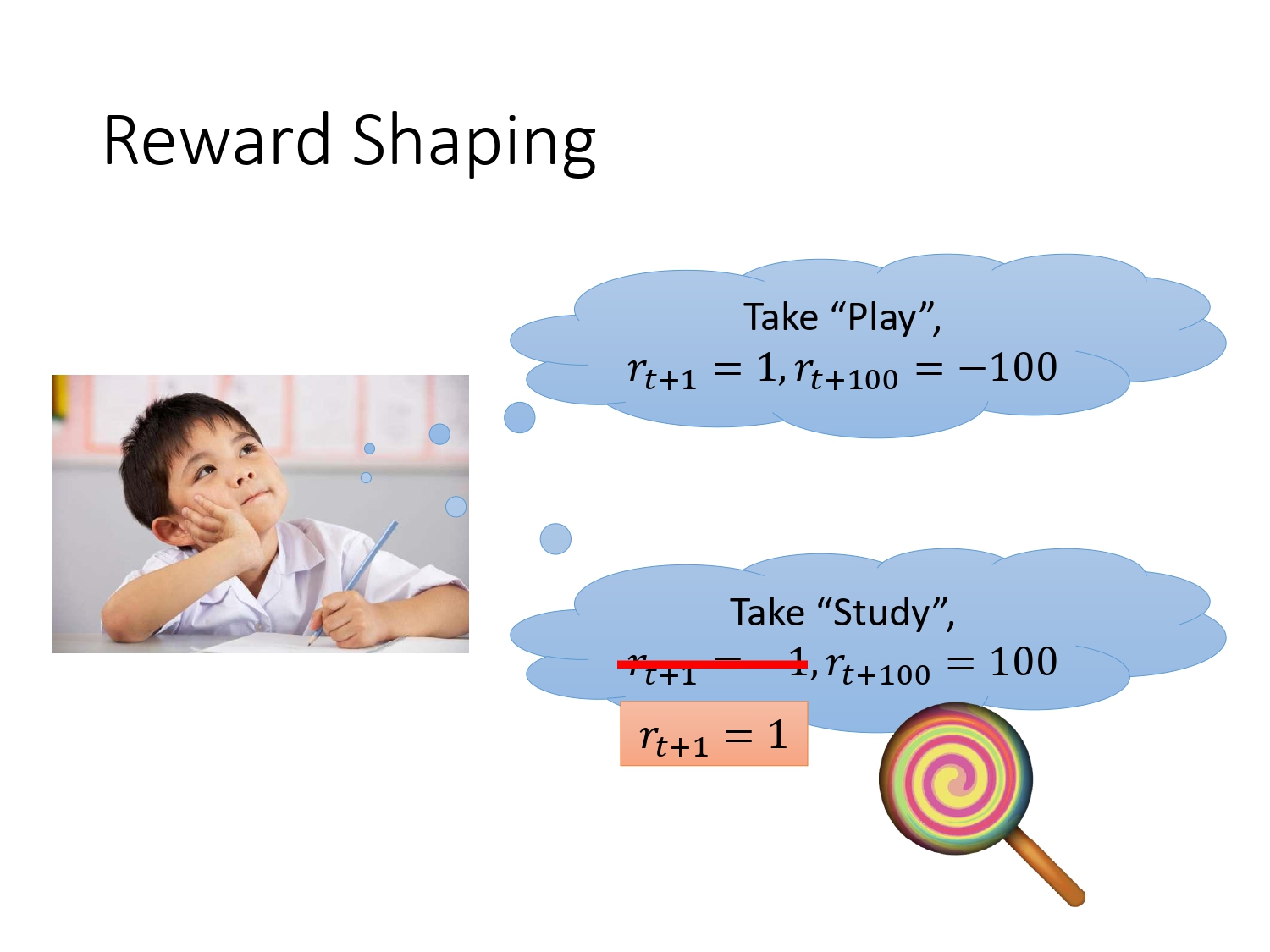
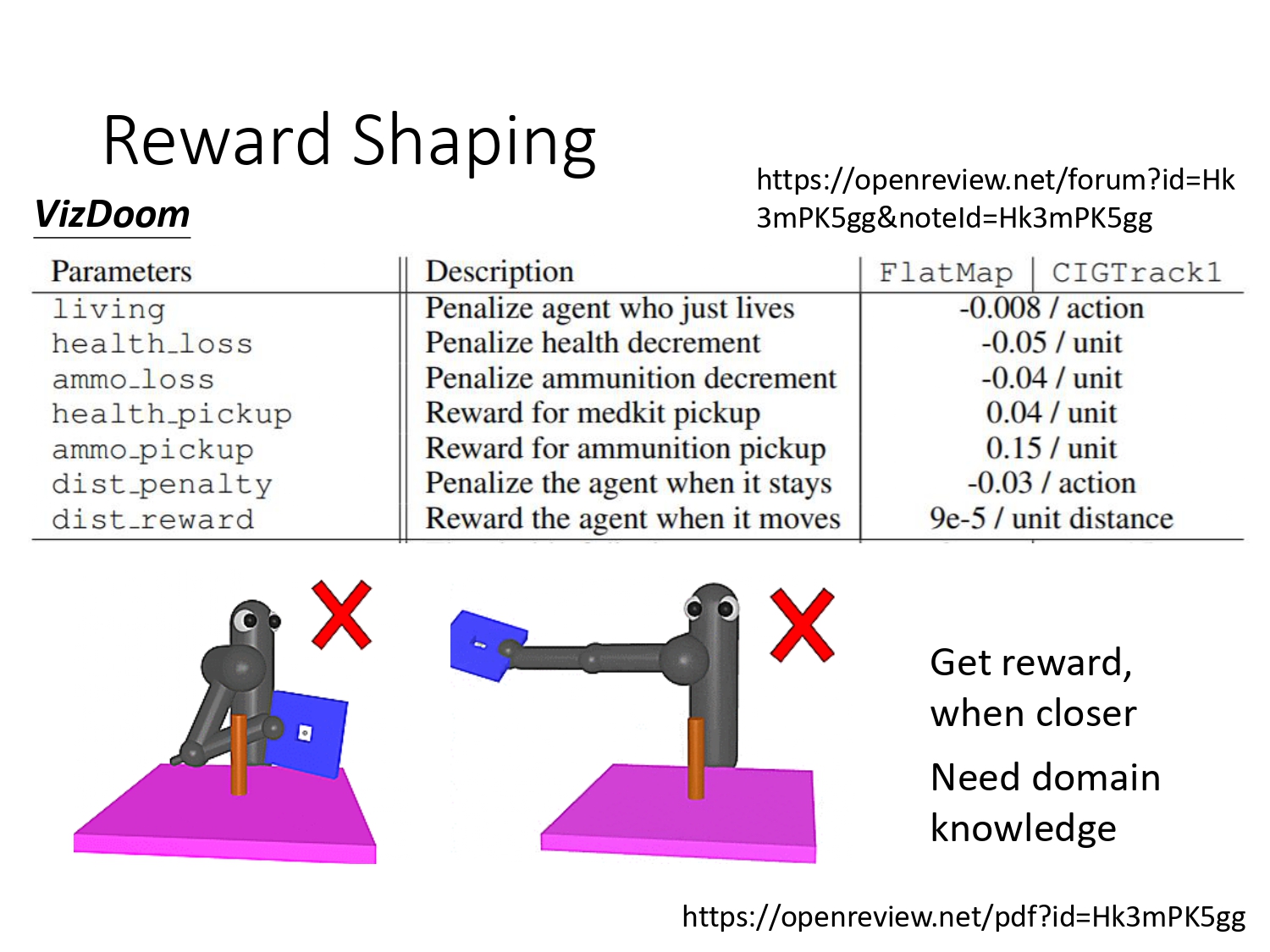
5.1 Reward Shaping
手动设计新的reward,让agent做的更好。但有些比较复杂的任务,需要domain knowledge去设计新的reward。
5.2 Curiosity
好奇心机制非常的直觉,也非常的强大。有个案例:Happy Bird
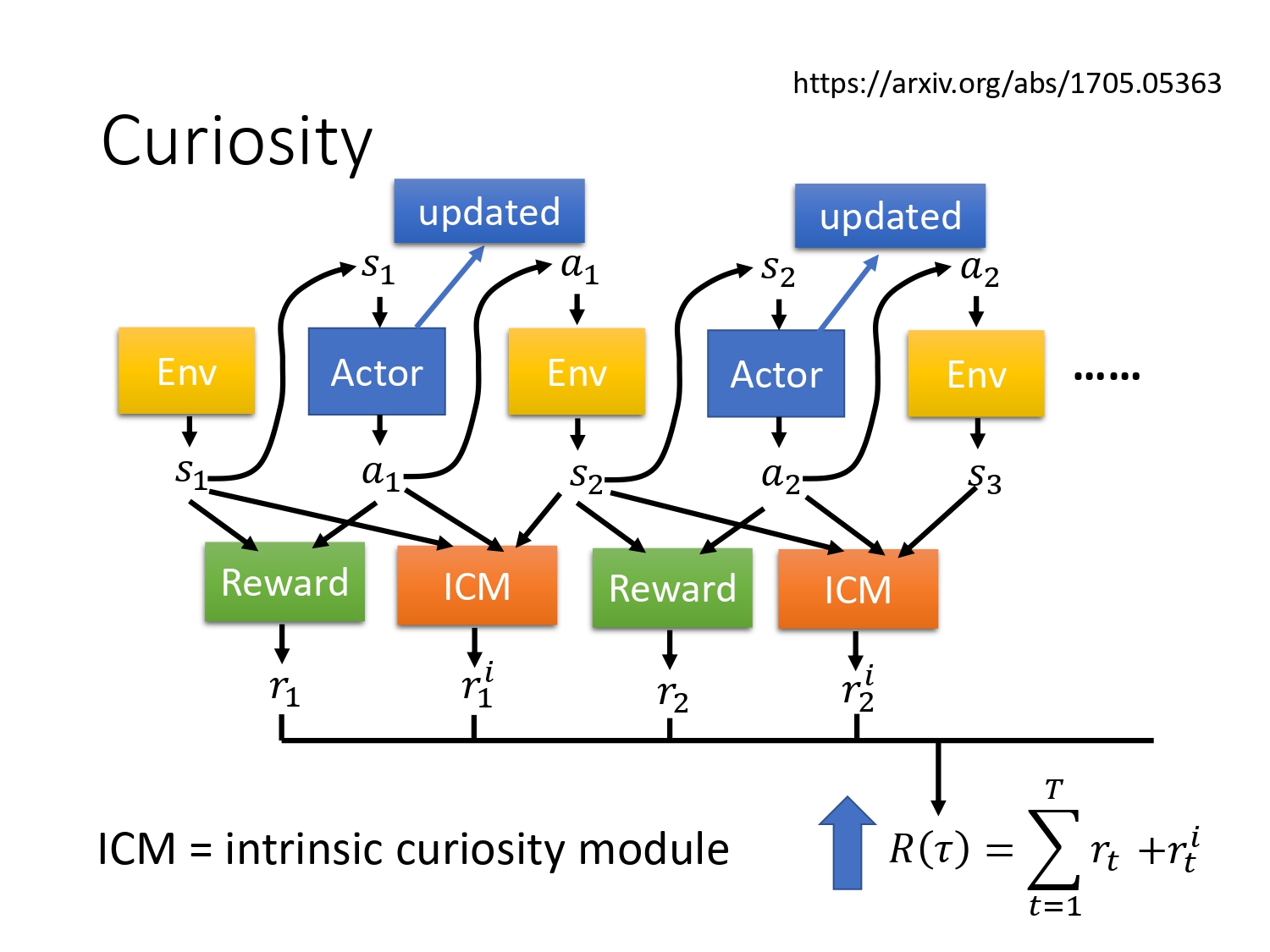
好奇心也是reward shaping的一种,引入一个新的reward :ICM,同时优化2个reward。如何设计一个ICM模块,使agent拥有好奇心?
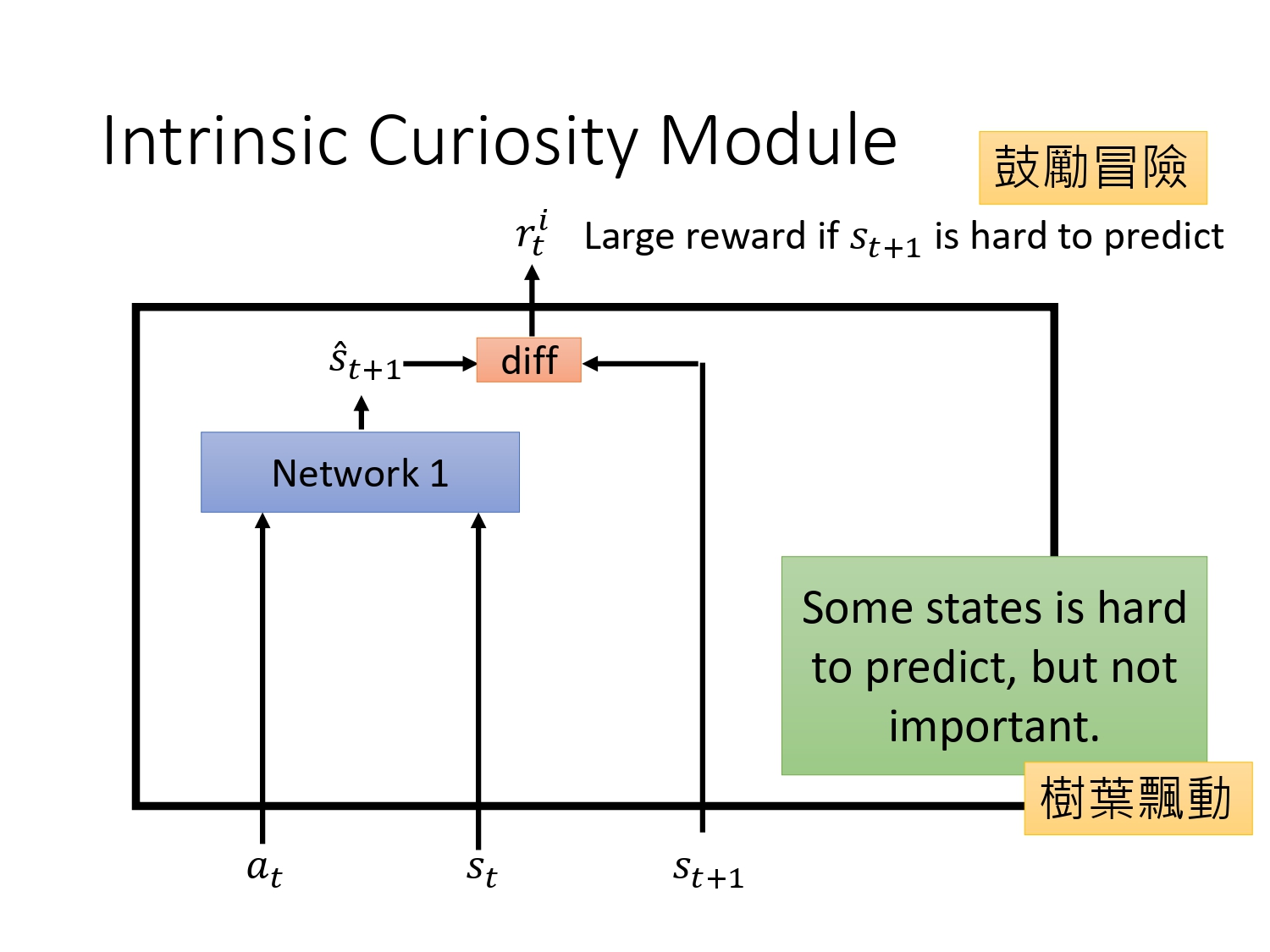
单独训练一个状态估计的模型,如果在某个state下采取某个action得到的下一个state难以预测,则鼓励agent进行尝试这个action。 不过有的state很难预测,但不重要。比如说某个游戏里面背景是树叶飘动,很难预测,接下来agent一直不动看着树叶飘动,没有意义。
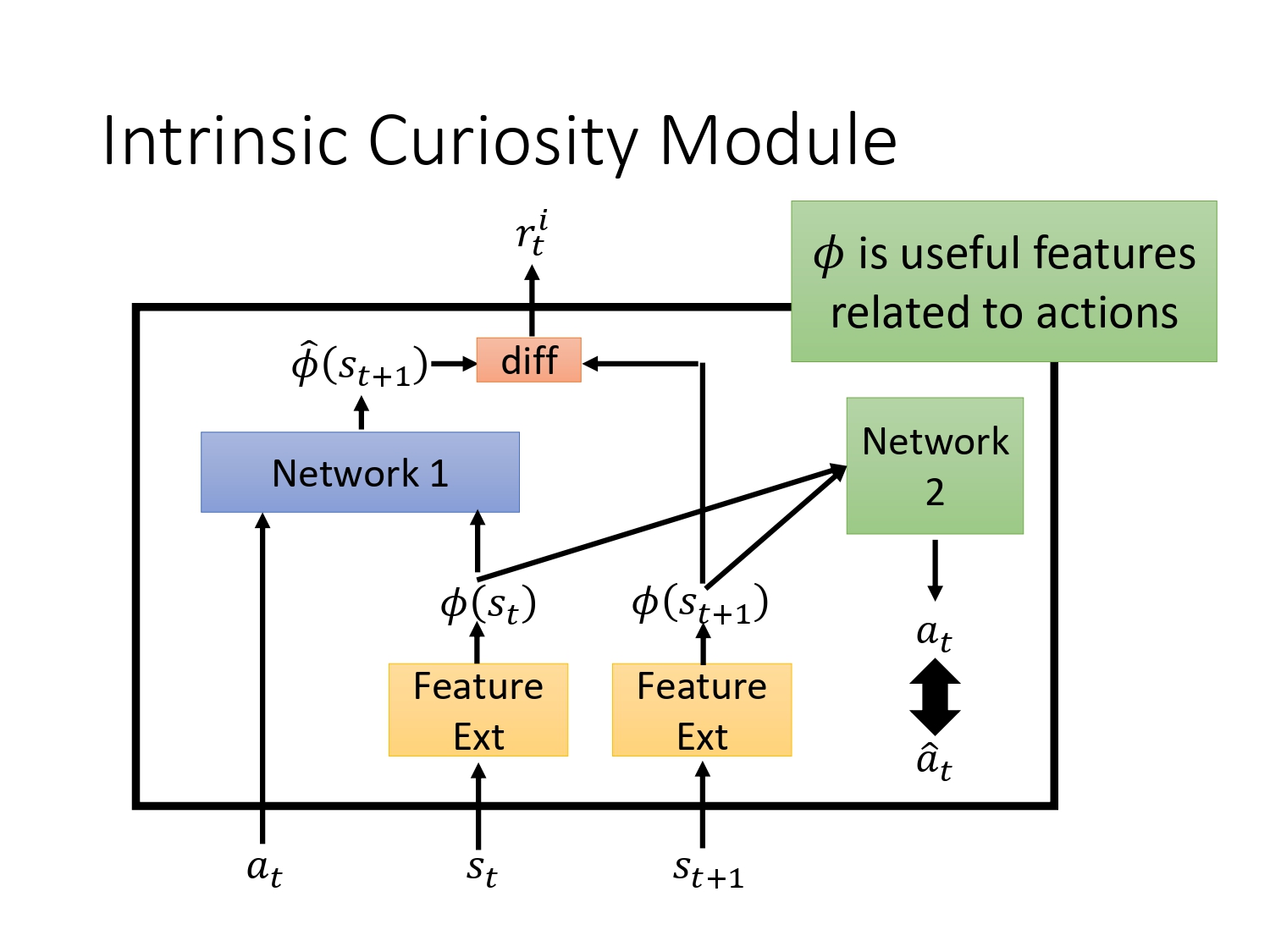
再设计一个moudle,判断环境中state的重要性:learn一个feature ext的网络,去掉环境中与action关系不大的state。
原理:输入两个处理过的state,预测action,使逼近真实的action。这样使得处理之后的state都是跟agent要采取的action相关的。
5.3 Curriculum Learning
课程学习:为learning做规划,通常由易到难。
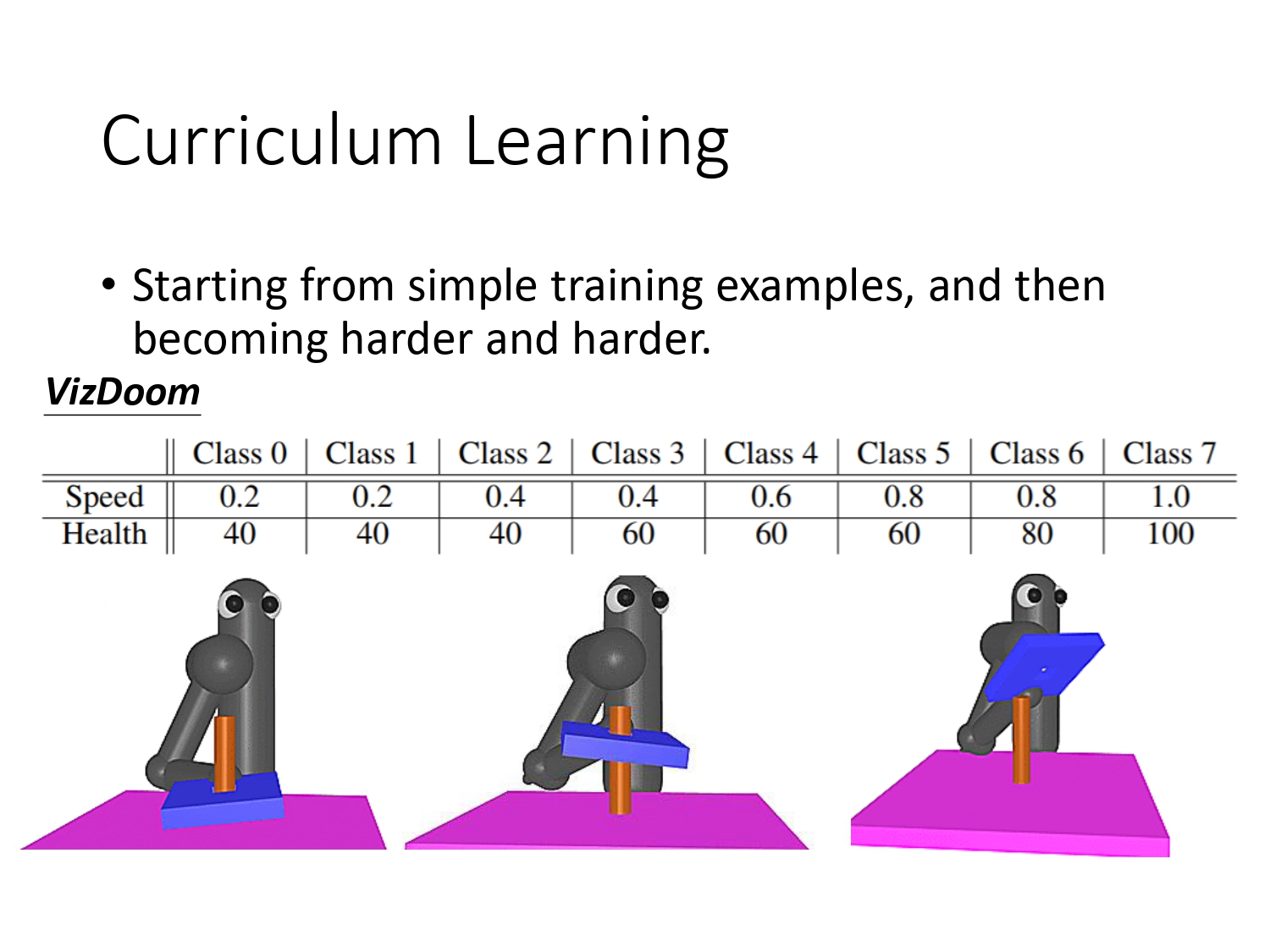
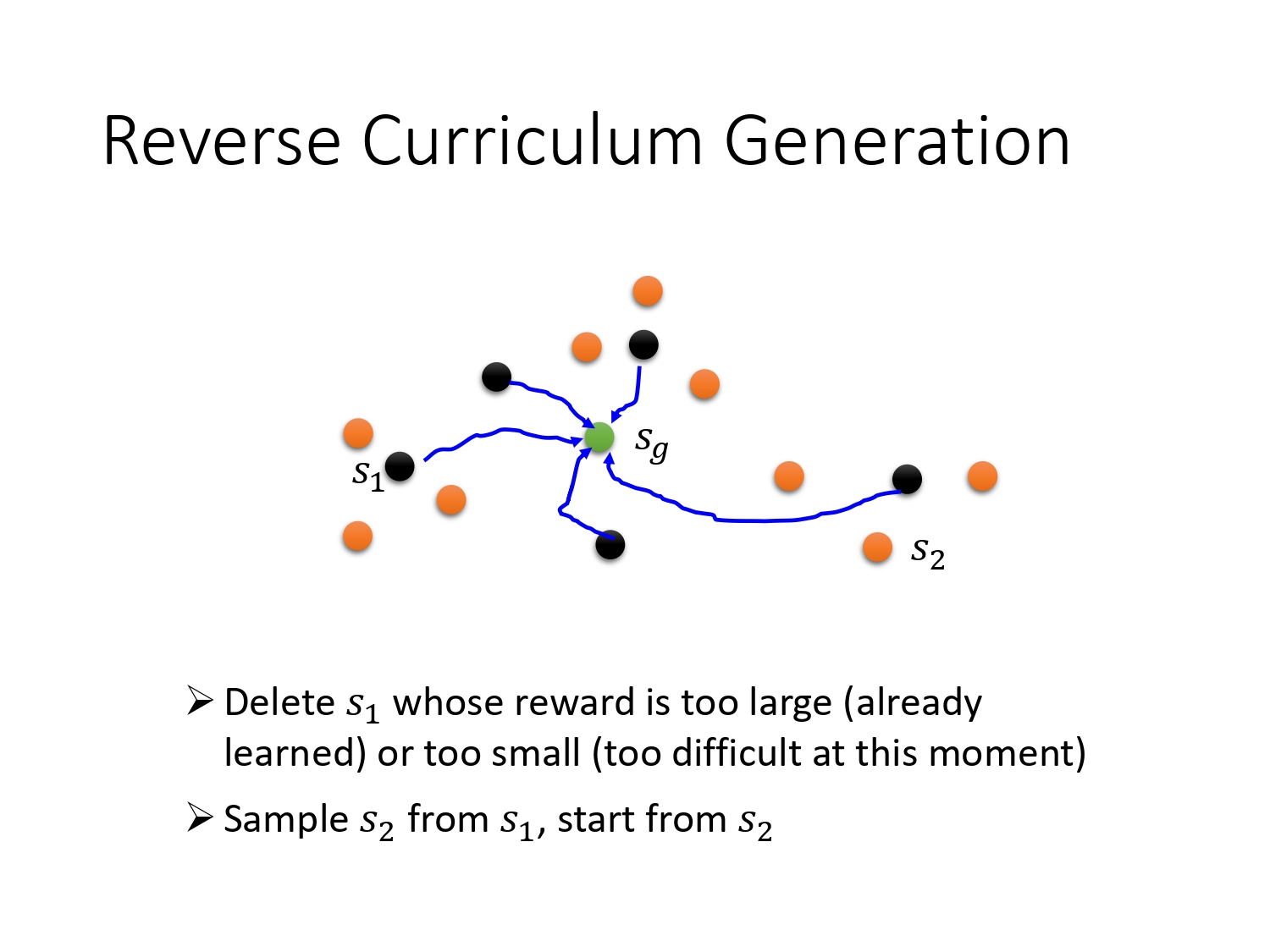
设计不同难度的课程,一开始直接把板子放入柱子,则agent只要把板子压下去就能获得reward,接着把板子的初始位置提高一些,agent有可能把板子抽出则无法获得reward,接着更general的情况,把板子放倒柱子外面,再让agent去学习。
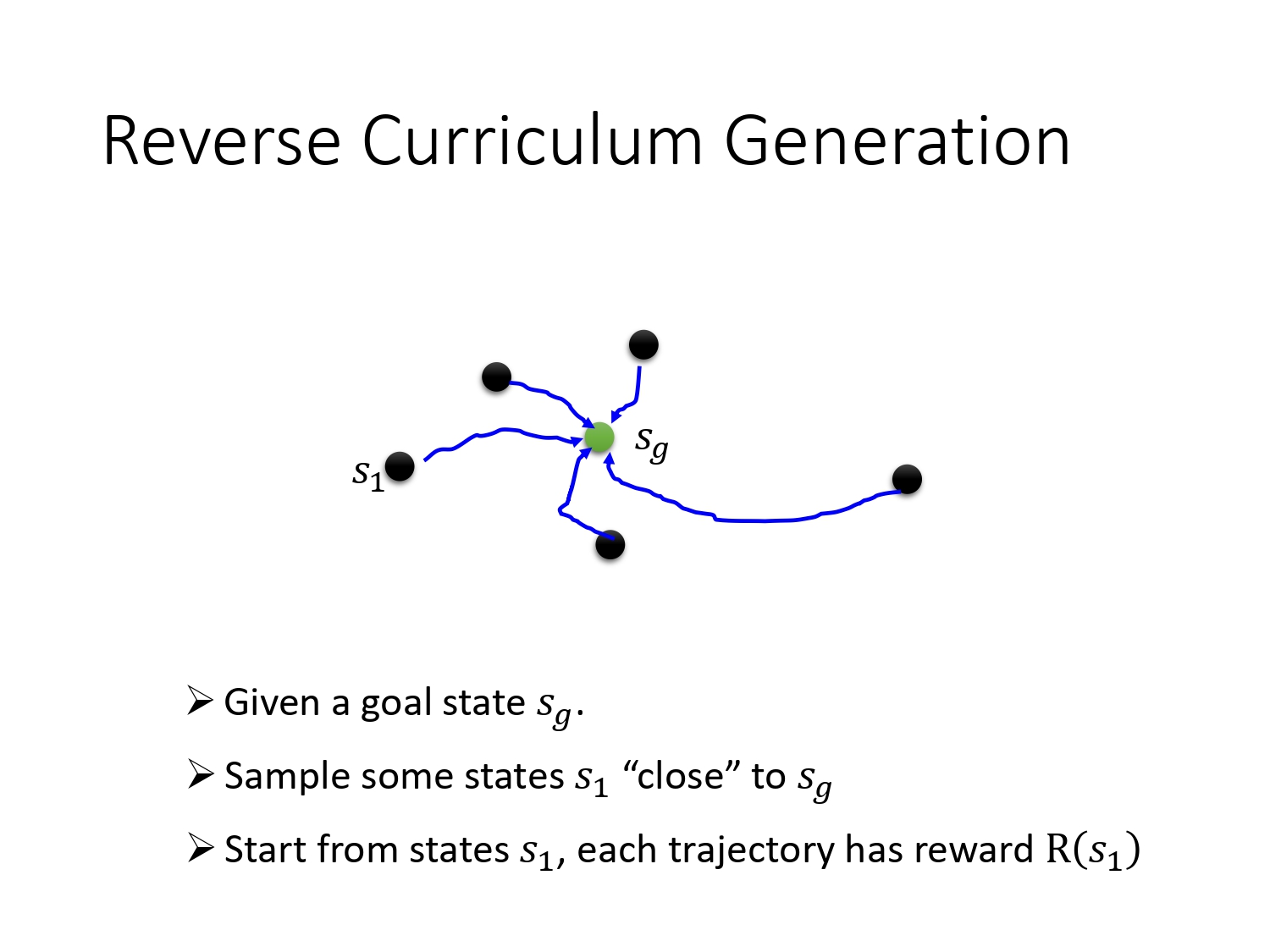
生成课程的方法通常如下:从目标反推,越靠近目标的state越简单,不断生成难度更高的state。
5.4 Hierarchical RL
分层学习:把大的任务拆解成小任务

上层的agent给下层的agent提供一个愿景,如果下层的达不到目标,会获得惩罚。如果下层的agent得到的错误的目标,那么它会假设最初的目标也是错的。
6. Imitation Learning
模仿学习,又叫学徒学习,反向强化学习
之前介绍的强化学习都有一个reward function,但生活中大多数任务无法定义reward,或者难以定义。但是这些任务中如果收集很厉害的范例(专家经验)比较简单,则可以用模仿学习解决。

6.1 Behavior Cloning
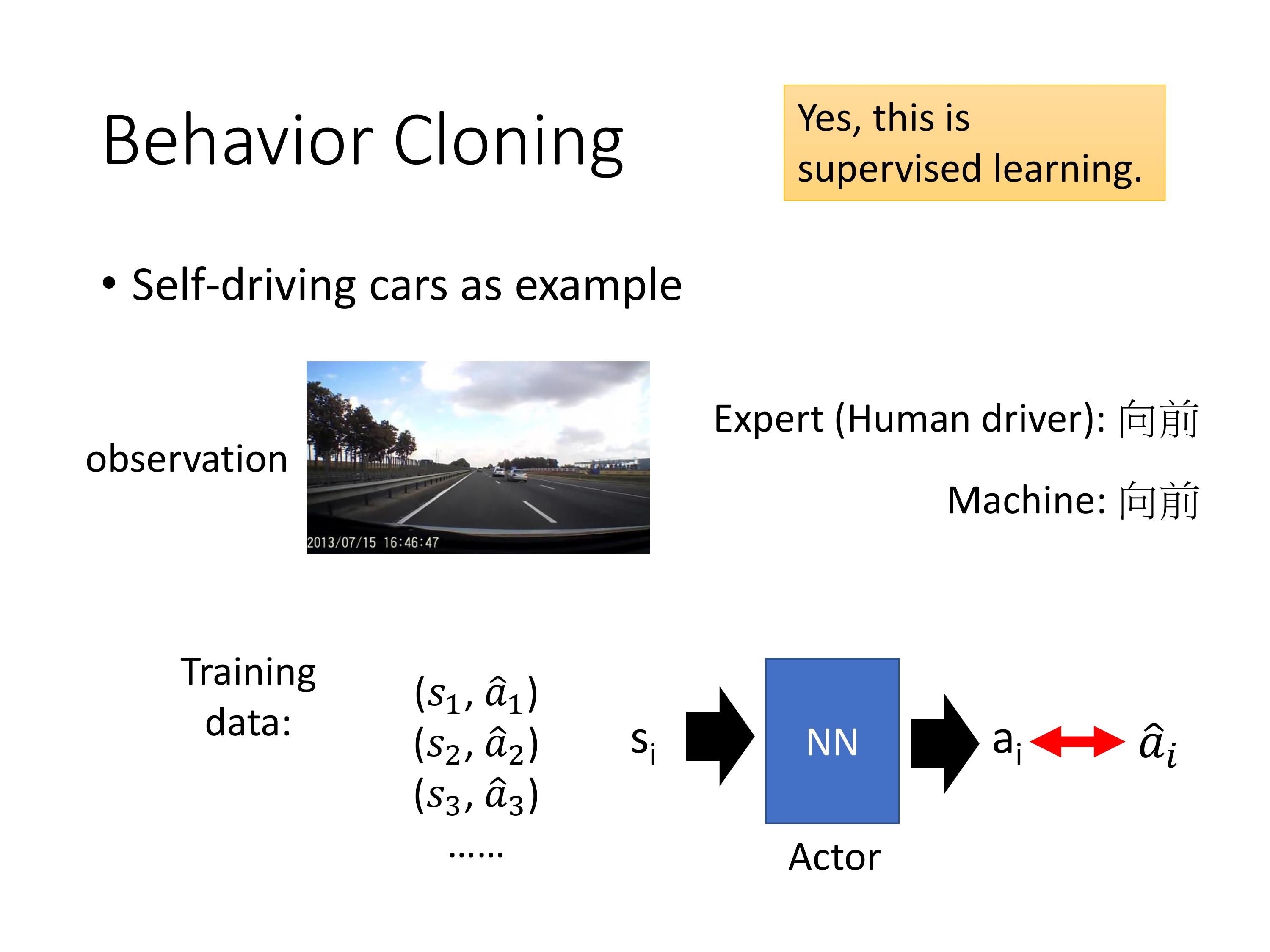
本质是有监督学习
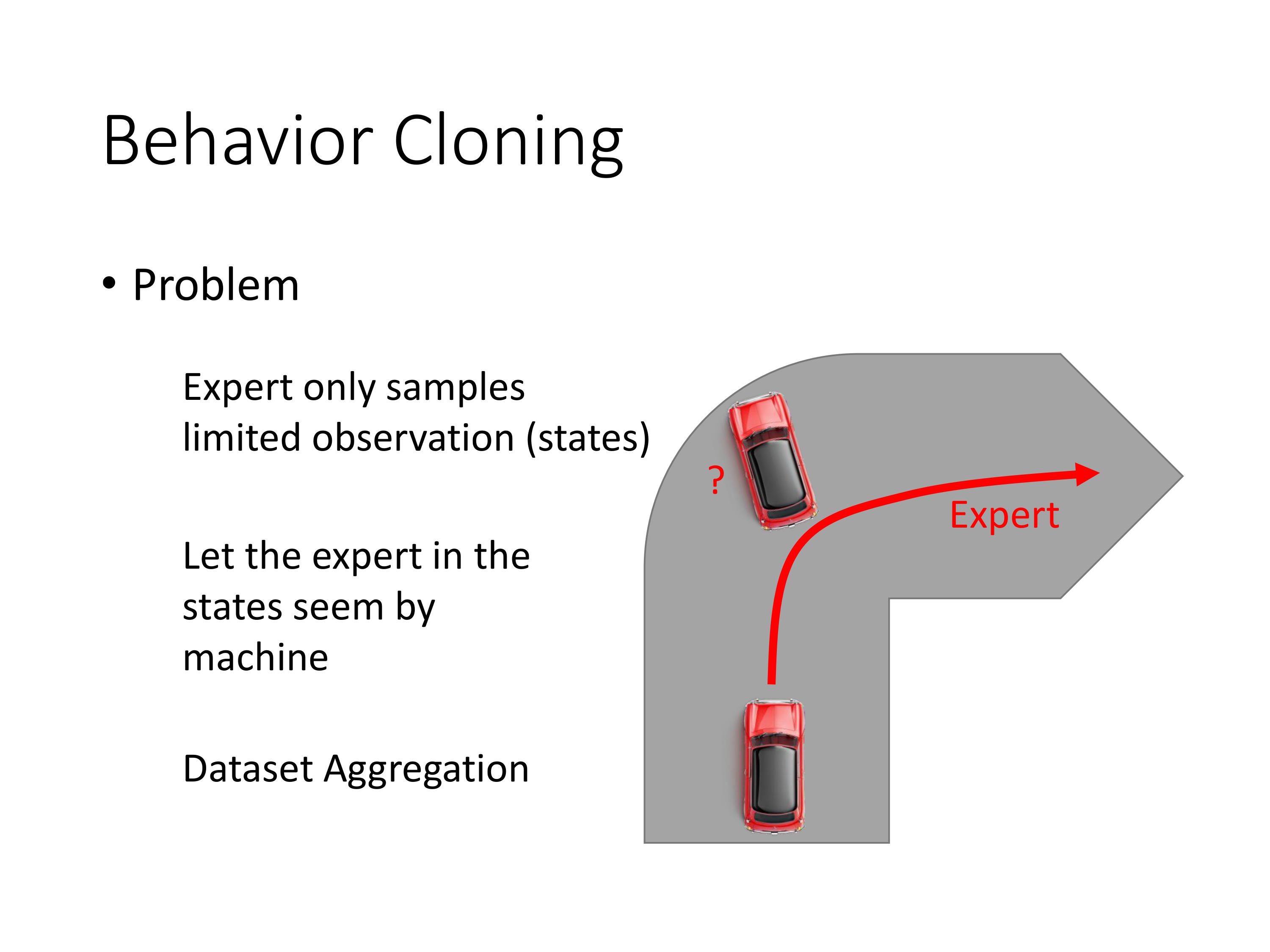
存在问题:training data里面没有撞墙的case,则agent遇到这种情况不知如何决策
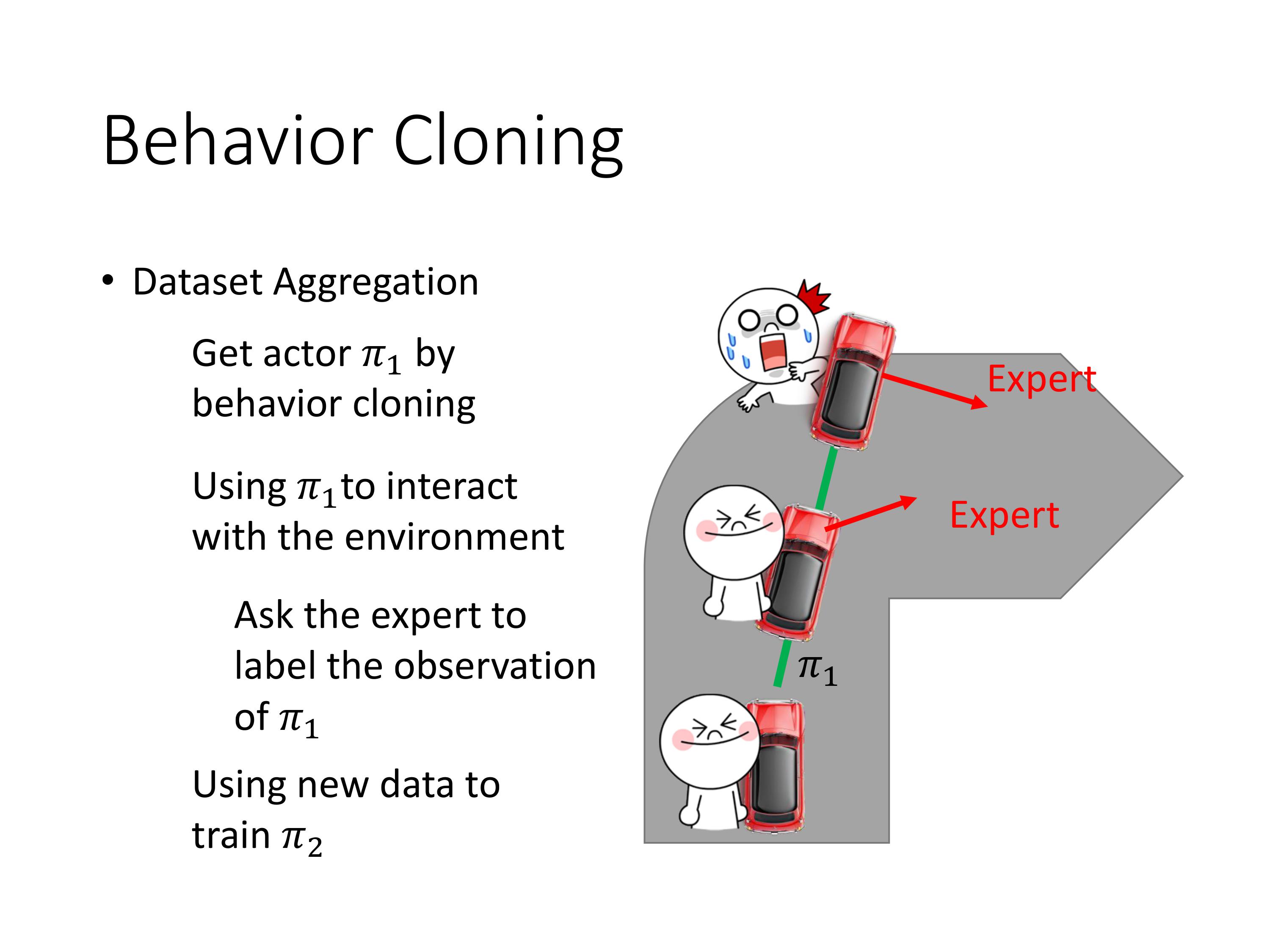
一个直觉的解决方法是数据增强:每次通过牺牲一个专家,学会了一种新的case,策略 π \pi π得到了增强。
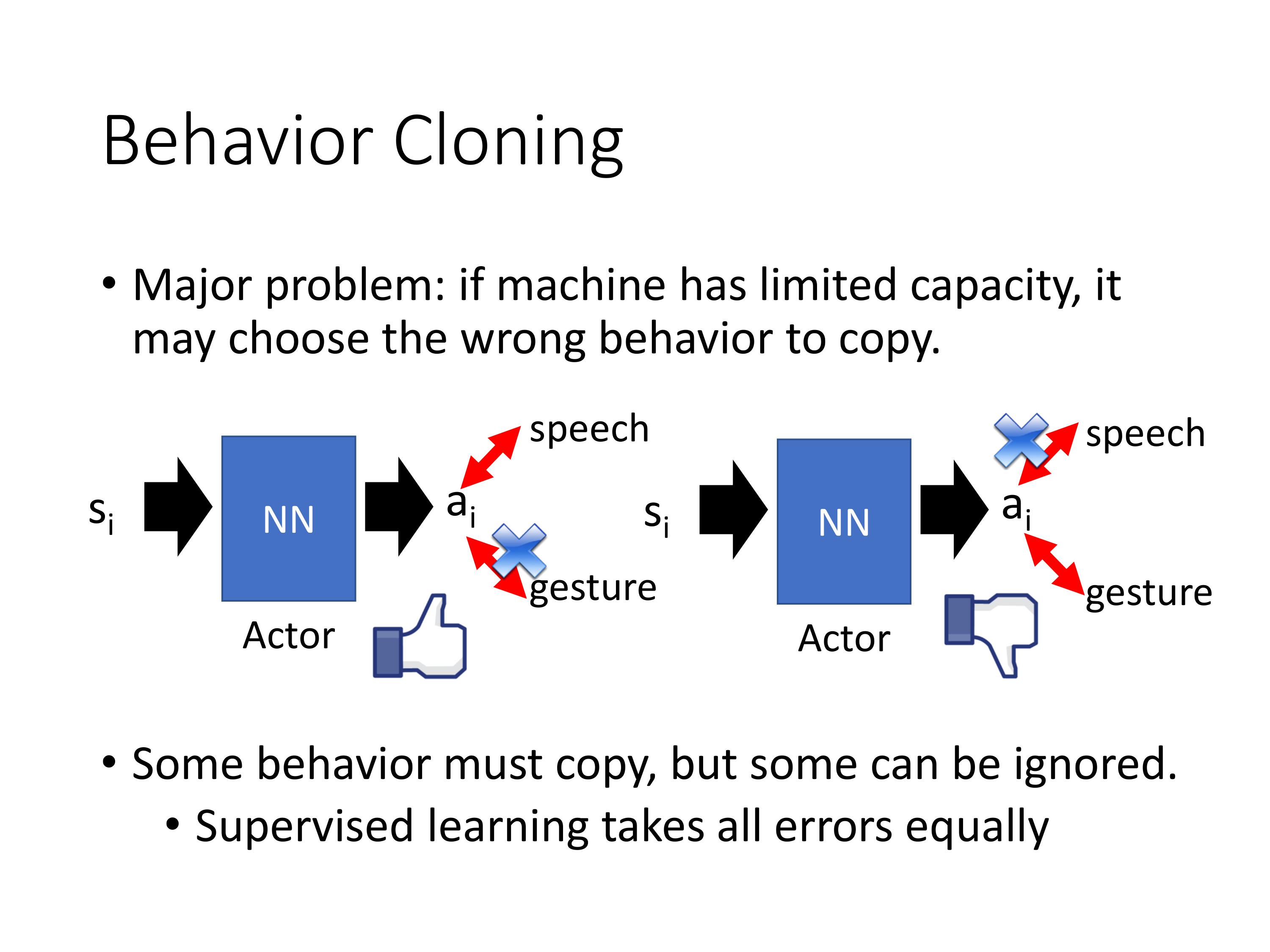
行为克隆还存在一个关键问题:agent不知道哪些行为对结局重要,哪些不重要。由于是采样学习,有可能只记住了多余的无用的行为。

同时也由于RL的训练数据不是独立同分布,当下的action会影响之后的state,所以不能直接套用监督学习的框架。
为了解决这些问题,就有了反向强化学习,现在一般说模仿学习指的就是反向强化学习。
6.2 Inverse RL
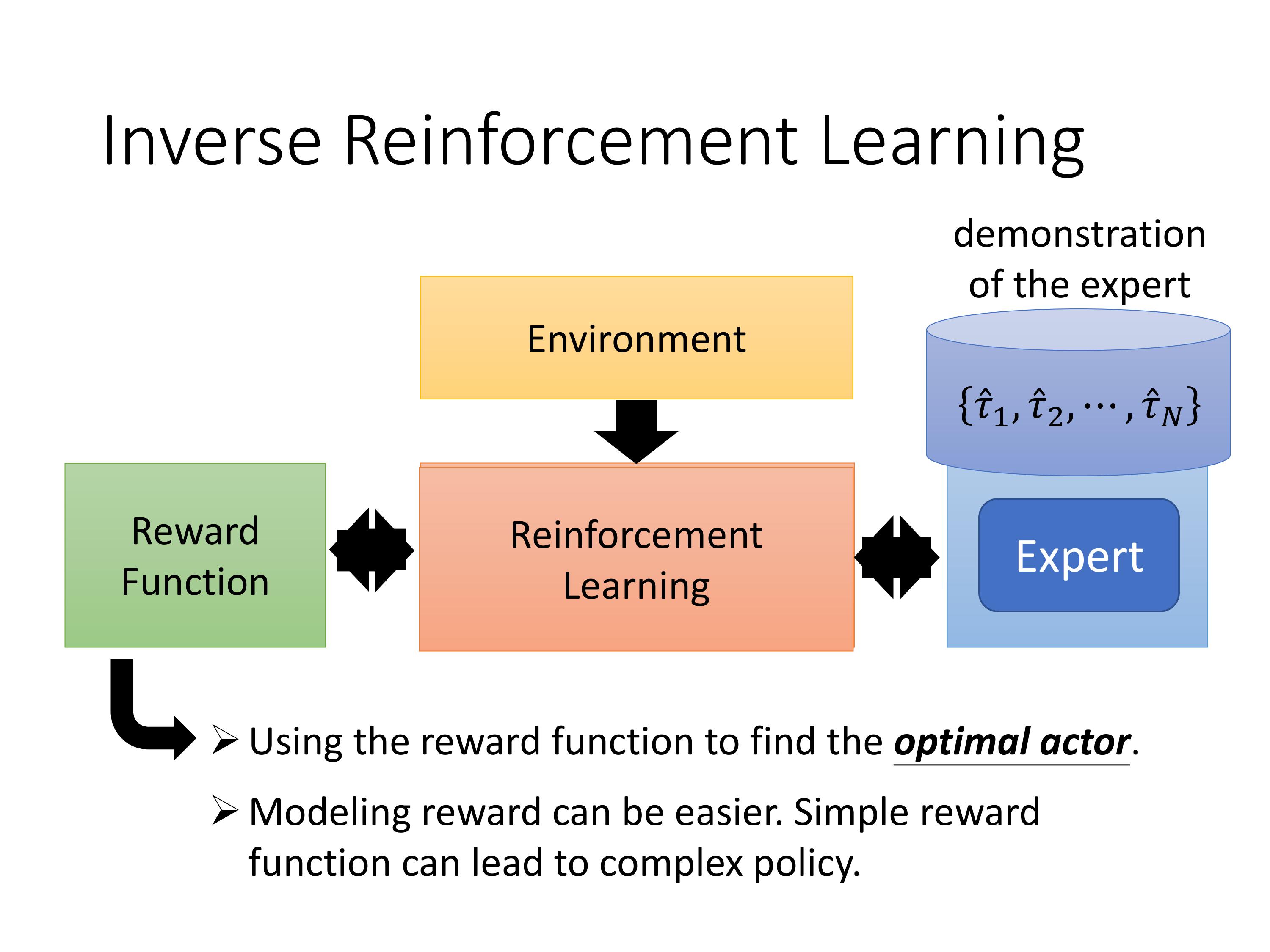
之前的强化学习是reard和env通过RL 学到一个最优的actor。
反向强化学习是,假设有一批expert的数据,通过env和IRL推导expert因为什么样子的reward function才会采取这样的行为。
好处:也许expert的行为复杂但reward function很简单。拿到这个reward function后我们就可以训练出好的agent。
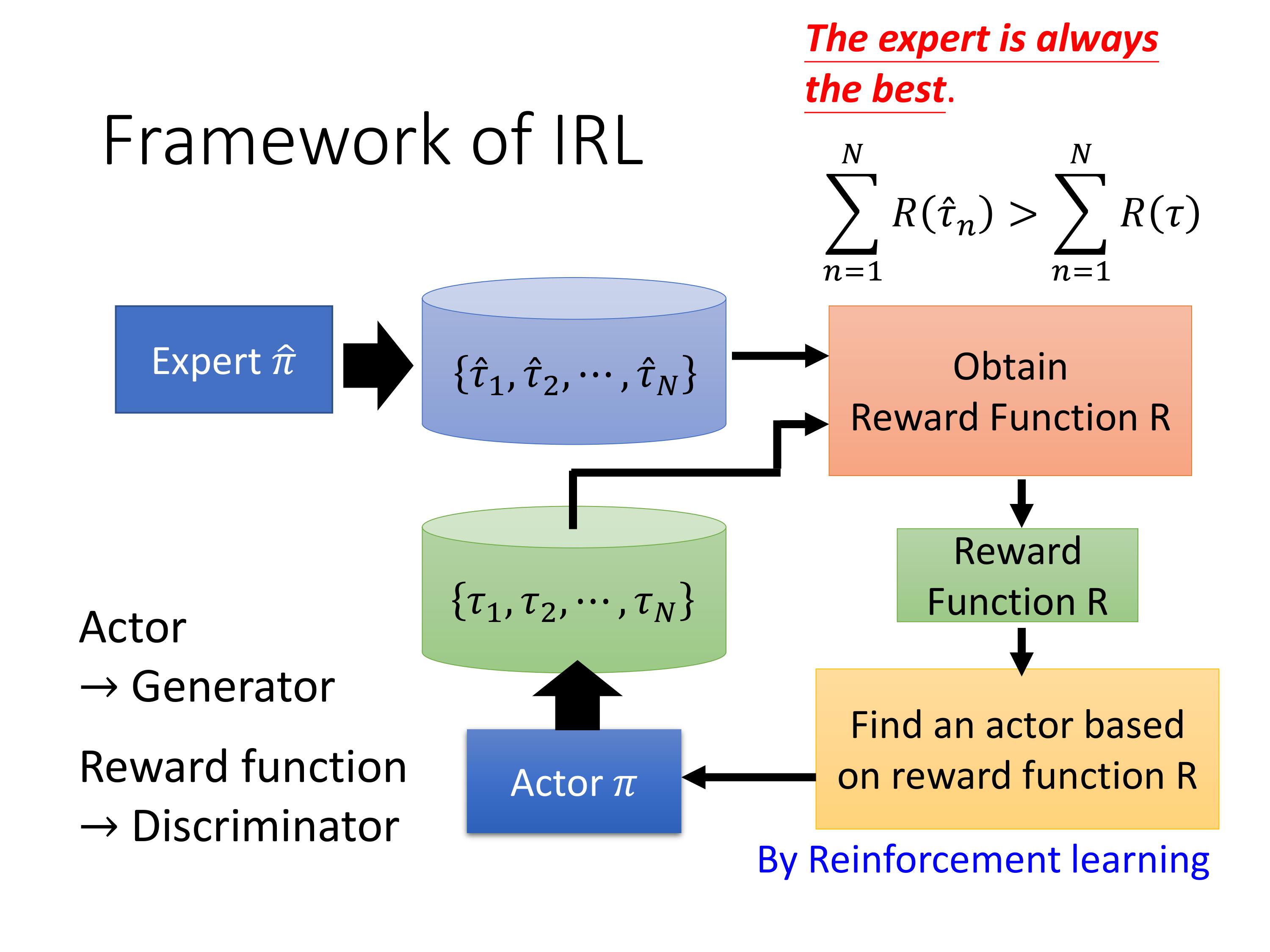
IRL的框架:先射箭 再画靶。
具体过程:
Expert先跟环境互动,玩N场游戏,存储记录,我们的actor $ \pi$也去互动,生成N场游戏记录。接下来定义一个reward function R R R,保证expert的 R R R比我们的actor的 R R R大就行。再根据定义的的 R R R用RL的方法去学习一个新的actor ,这个过程也会采集新的游戏记录,等训练好这个actor,也就是当这个actor可以基于 R R R获得高分的时候,重新定义一个新的reward function R ′ R' R′,让expert的 R ′ R' R′大于agent,不断循环。
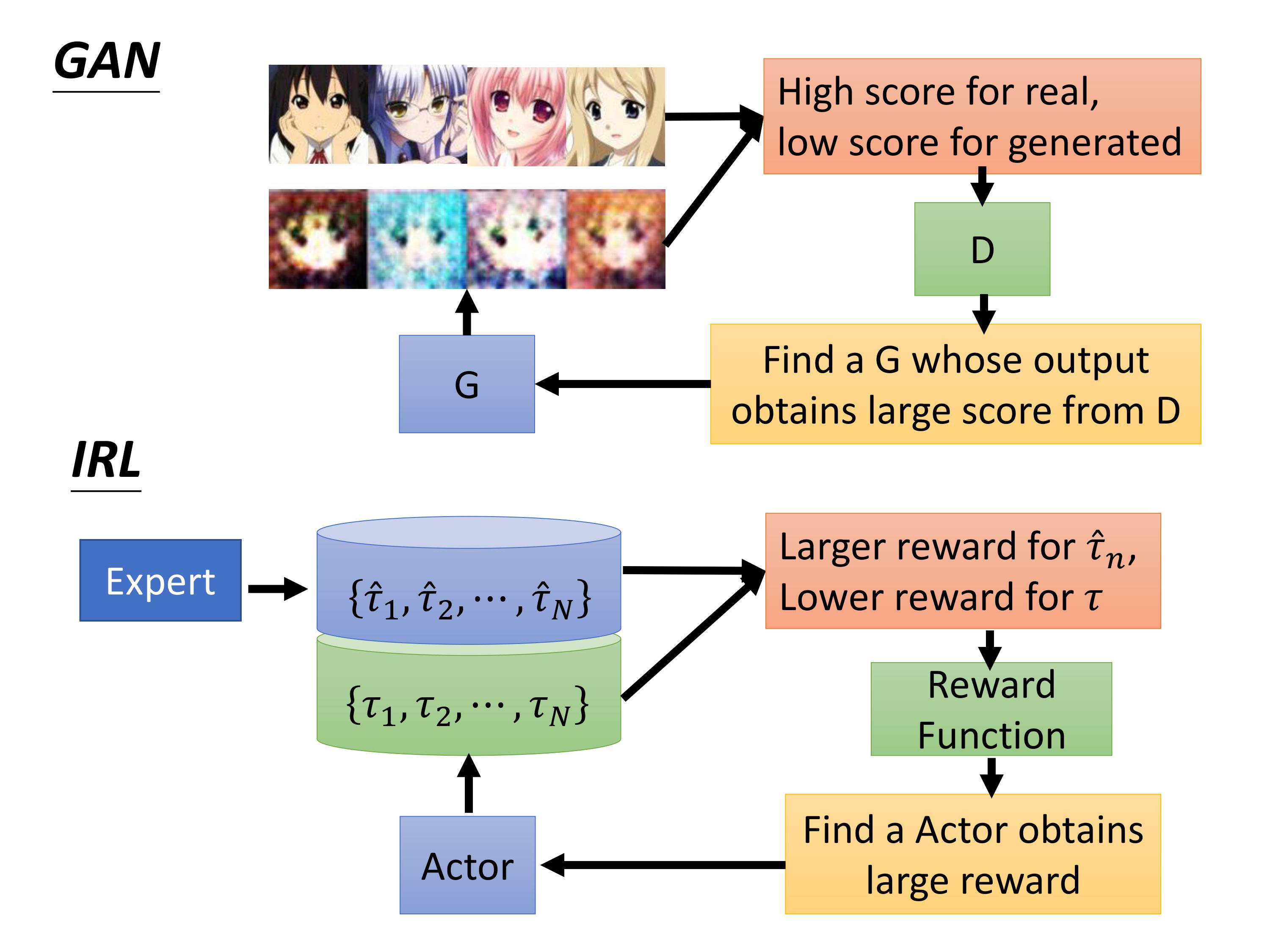
IRL与GAN的框架是一样的,学习 一个 reward function相当于学习一个判别器,这个判别器给expert高分,给我们的actor低分。
一个有趣的事实是给不同的expert,我们的agent最终也会学会不同的策略风格。如下蓝色是expert的行为,红色是学习到的actor的行为。
针对训练robot的任务:
IRL有个好处是不需要定义规则让robot执行动作,人给robot示范一下动作即可。但robot学习时候的视野跟它执行该动作时候的视野不一致,怎么把它在第三人称视野学到的策略泛化到第一人称视野呢?

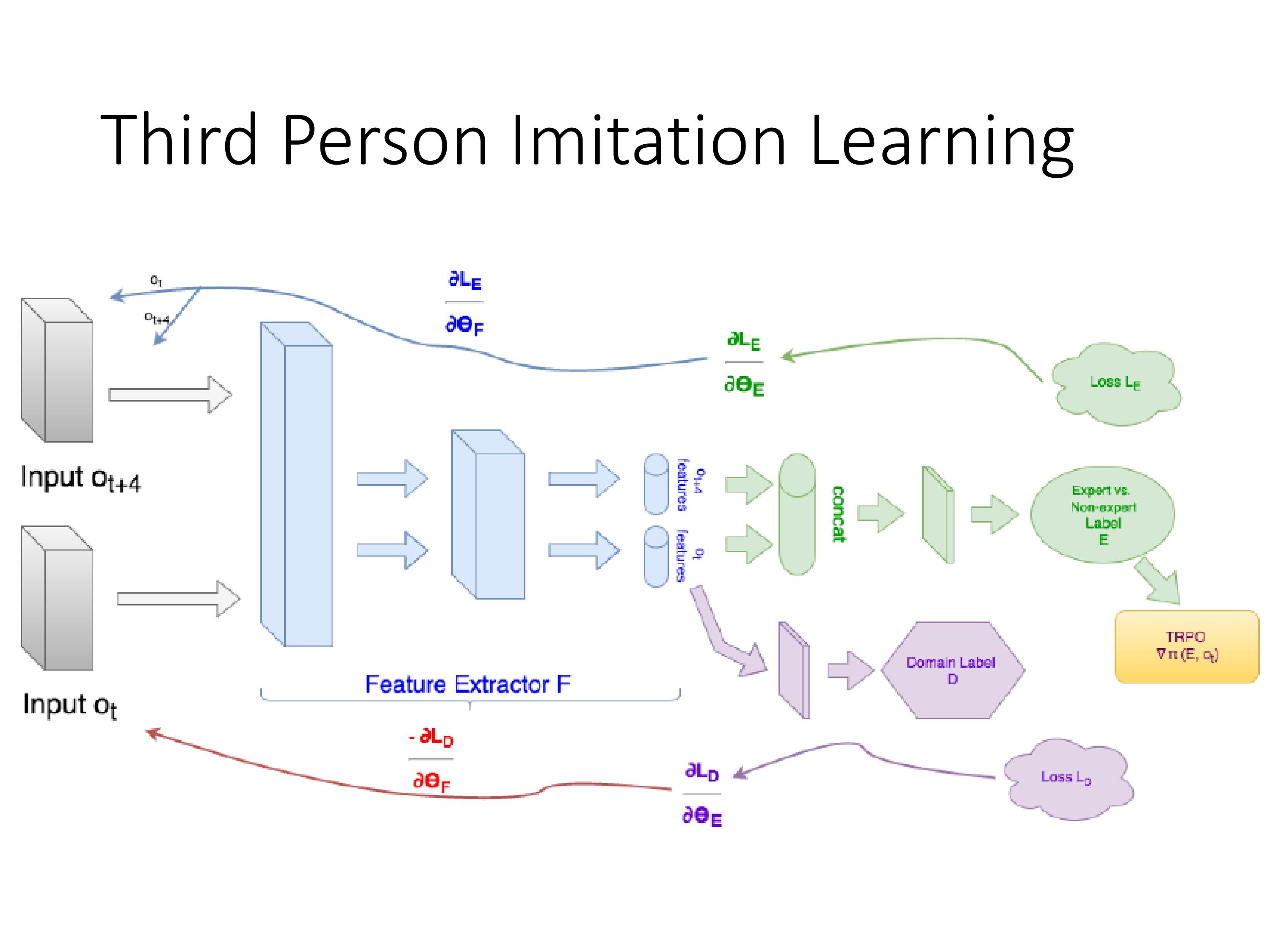
解决思路跟好奇心机制类似,抽出视野中不重要的因素,让第一人称和第三人称视野中的state都是有用的,与action强相关的。


![[学习笔记]线段树(全)](https://i-blog.csdnimg.cn/direct/f6ba796612d54bee9ecfb80f62c8ce6b.png#pic_center)