本文基于 Netty 4.1.112.Final 版本进行讨论
在之前的 Netty 系列中,笔者是以 4.1.56.Final 版本为基础和大家讨论的,那么从本文开始,笔者将用最新版本 4.1.112.Final 对 Netty 的相关设计展开解析,之所以这么做的原因是 Netty 的内存池设计一直在不断地演进优化。
在 4.1.52.Final 之前 Netty 内存池是基于 jemalloc3 的设计思想实现的,由于在该版本的实现中,内存规格的粒度设计的比较粗,可能会引起比较严重的内存碎片问题。所以为了近一步降低内存碎片,Netty 在 4.1.52.Final 版本中重新基于 jemalloc4 的设计思想对内存池进行了重构,通过将内存规格近一步拆分成更细的粒度,以及重新设计了内存分配算法尽量将内存碎片控制在比较小的范围内。
随后在 4.1.75.Final 版本中,Netty 为了近一步降低不必要的内存消耗,将 ChunkSize 从原来的 16M 改为了 4M 。而且在默认情况下不在为普通的用户线程提供内存池的 Thread Local 缓存。在兼顾性能的前提下,将不必要的内存消耗尽量控制在比较小的范围内。
Netty 在后续的版本迭代中,针对内存池这块的设计,仍然会不断地伴随着一些小范围的优化,由于这些优化点太过细小,琐碎,笔者就不在一一列出,所以干脆直接以最新版本 4.1.112.Final 来对内存池的设计与实现展开剖析。
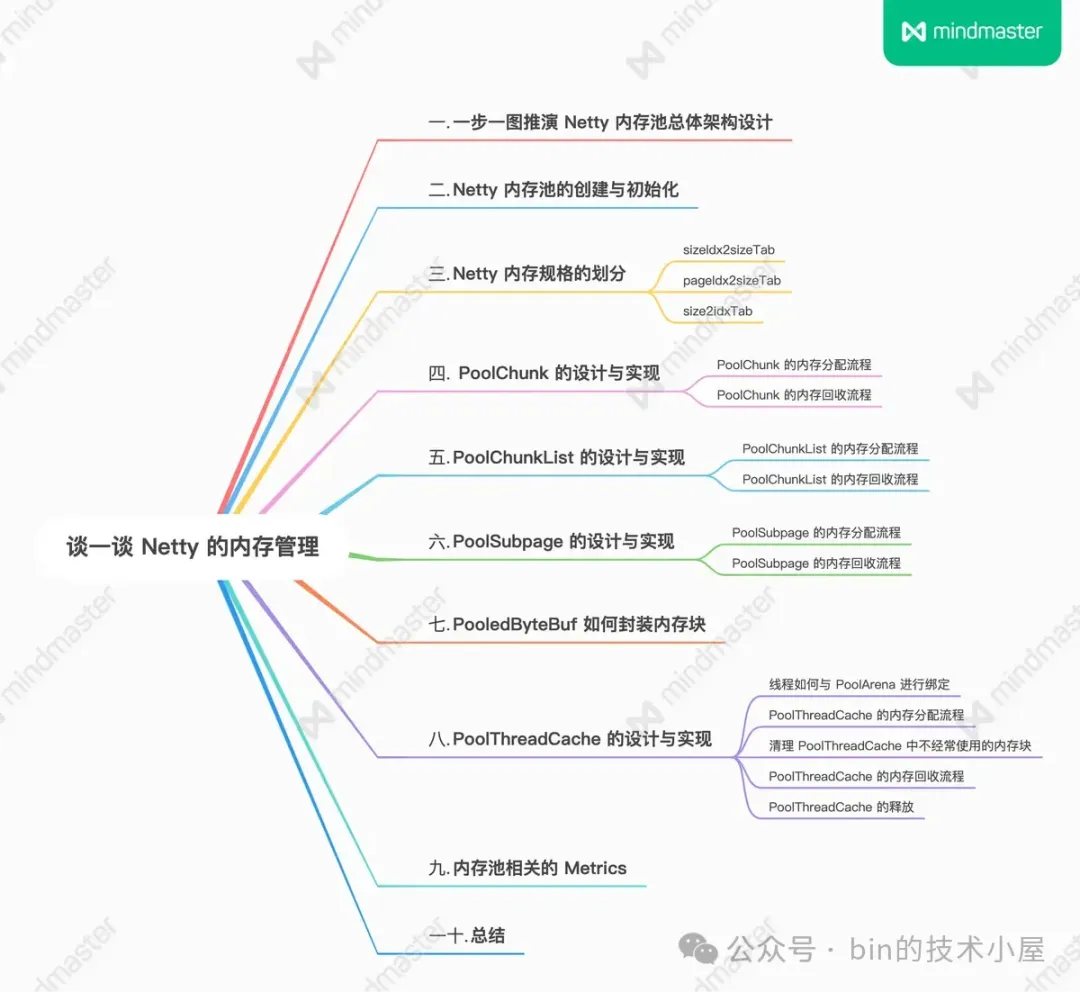
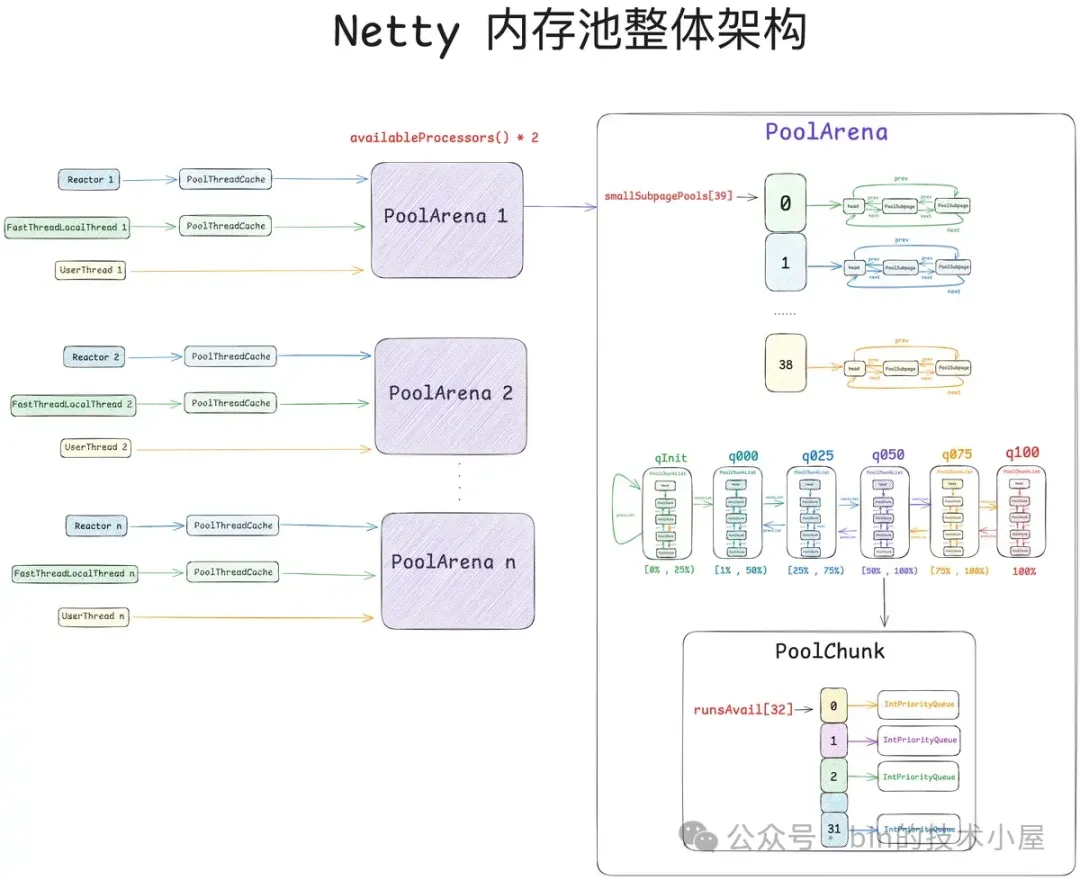
1. 一步一图推演 Netty 内存池总体架构设计
Netty 内存池的整体设计相对来说还是有那么一点点的复杂,其中涉及到了众多概念模型,每种模型在架构层面上承担着不同的职责,模型与模型之间又有着千丝万缕的联系,在面对一个复杂的系统设计时,我们还是按照老套路,从最简单的设计开始,一步一步的演进,直到还原出内存池的完整样貌。
因此在本小节中,笔者的着墨重点是在总体架构设计层面上,先把内存池涉及到的这些众多概念模型为大家梳理清晰,但并不会涉及太复杂的源码实现细节,让大家有一个整体完整的认识。有了这个基础,在本文后续的小节中,我们再来详细讨论源码的实现细节。
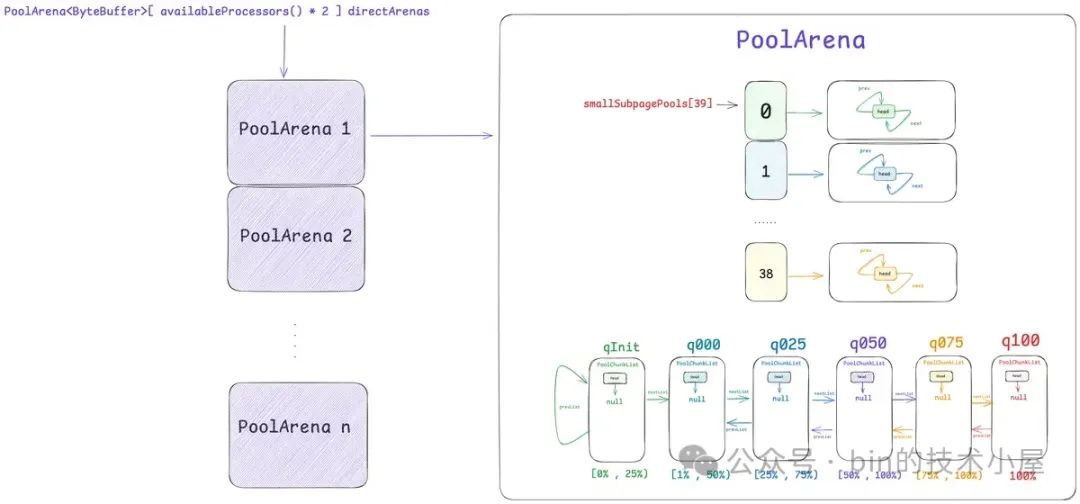
首先第一个登场的模型是 PoolArena , 它是内存池中最为重要的一个概念,整个内存管理的核心实现就是在这里完成的。
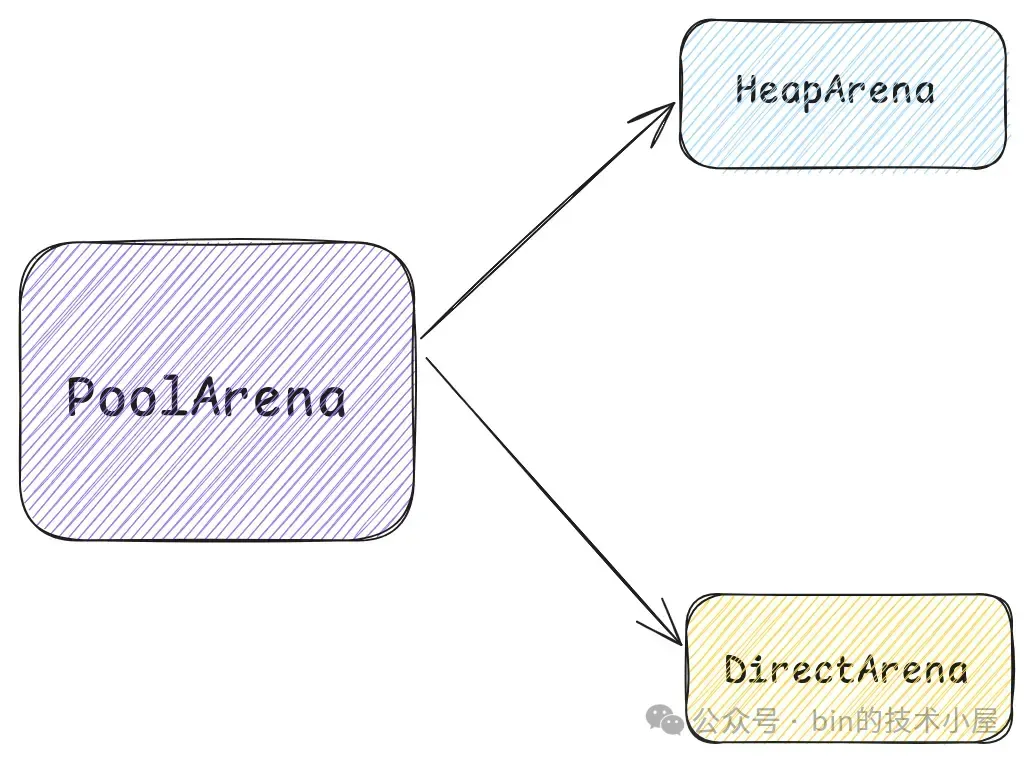
PoolArena 有两个实现,一个是 HeapArena,负责池化堆内内存,另一个是 DirectArena,负责池化堆外内存。和上篇文章一样,本文我们的重点还是在 Direct Memory 的池化管理上,后续相关的源码实现,笔者都是以 DirectArena 进行展开。
我们可以直接把 PoolArena 当做一个内存池来看待,当线程在申请 PooledByteBuf 的时候都会到 PoolArena 中去拿。这样一来就引入一个问题,就是系统中有那么多的线程,而内存的申请又是非常频繁且重要的操作,这就导致这么多的线程频繁的去争抢这一个 PoolArena,相关锁的竞争程度会非常激烈,极大的影响了内存分配的速度。
因此 Netty 设计了多个 PoolArena 来分摊线程的竞争,将线程与 PoolArena 进行绑定来降低锁的竞争,提高内存分配的并行度。
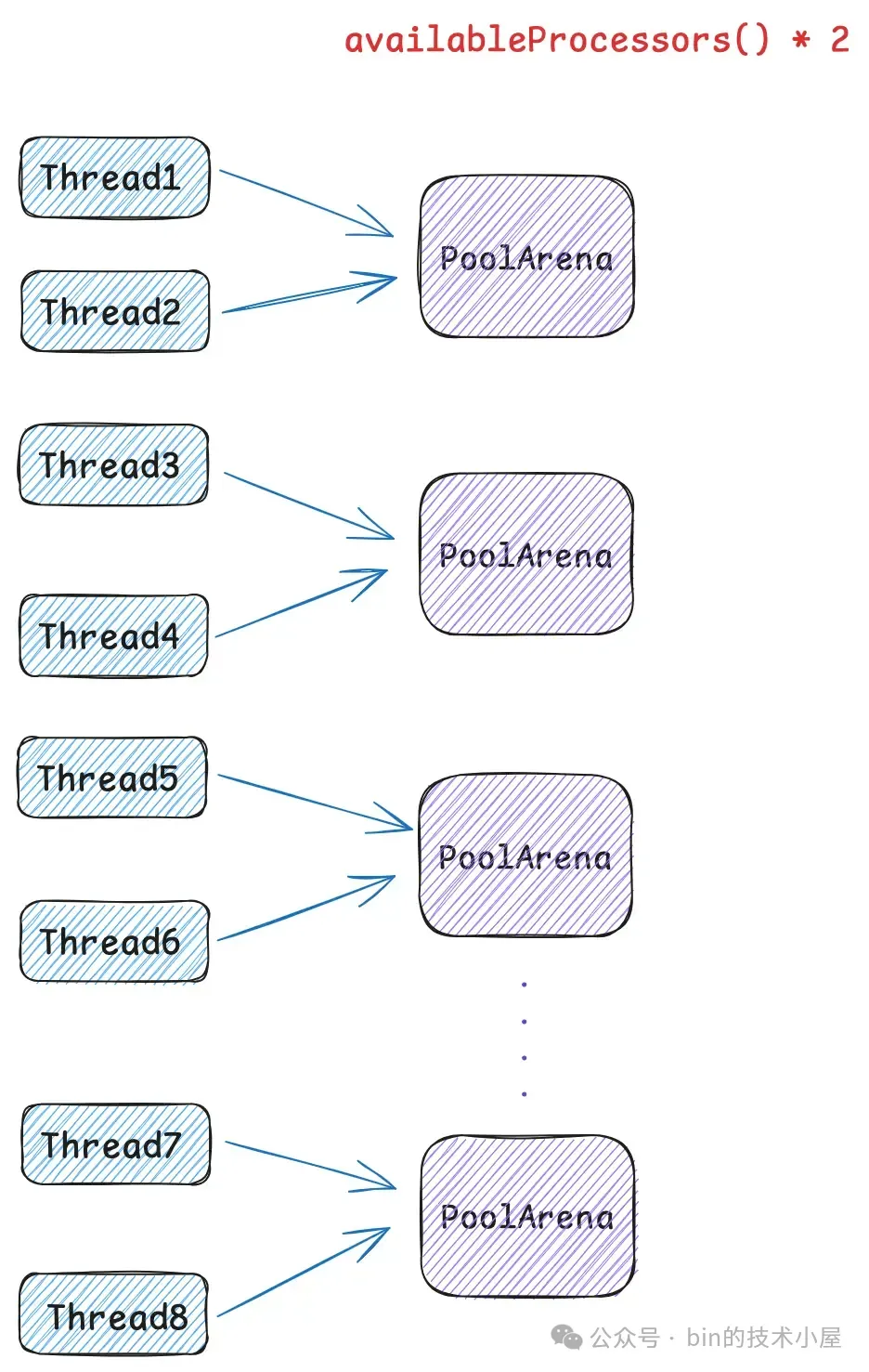
PoolArena 的默认个数为 availableProcessors * 2 , 因为 Netty 中的 Reactor 线程个数默认恰好也是 CPU 核数的两倍,而内存的分配与释放在 Reactor 线程中是一个非常高频的操作,所以这里将 Reactor 线程与 PoolArena 一对一绑定起来,避免 Reactor 线程之间的相互竞争。
除此之外,我们还可以通过 -Dio.netty.allocator.numHeapArenas 以及 -Dio.netty.allocator.numDirectArenas 来调整系统中 HeapArena 和 DirectArena 的个数。
public class PooledByteBufAllocator {
// 默认 HeapArena 的个数
private static final int DEFAULT_NUM_HEAP_ARENA;
// 默认 DirectArena 的个数
private static final int DEFAULT_NUM_DIRECT_ARENA;
static {
// PoolArena 的默认个数为 availableProcessors * 2
final int defaultMinNumArena = NettyRuntime.availableProcessors() * 2;
DEFAULT_NUM_HEAP_ARENA = Math.max(0,
SystemPropertyUtil.getInt(
"io.netty.allocator.numHeapArenas",
(int) Math.min(
defaultMinNumArena,
runtime.maxMemory() / defaultChunkSize / 2 / 3)));
DEFAULT_NUM_DIRECT_ARENA = Math.max(0,
SystemPropertyUtil.getInt(
"io.netty.allocator.numDirectArenas",
(int) Math.min(
defaultMinNumArena,
PlatformDependent.maxDirectMemory() / defaultChunkSize / 2 / 3)));
}
}
但事实上,系统中的线程不光只有 Reactor 线程这一种,还有 FastThreadLocalThread 类型的线程,以及普通 Thread 类型的用户线程,位于 Reactor 线程之外的 FastThreadLocalThread , UserThread 在运行起来之后会脱离 Reactor 线程自己单独向 PoolArena 来申请内存。
所以无论是什么类型的线程,在它运行起来之后,当第一次向内存池申请内存的时候,都会采用 Round-Robin 的方式与一个固定的 PoolArena 进行绑定,后续在线程整个生命周期中的内存申请以及释放等操作都只会与这个绑定的 PoolArena 进行交互。
所以线程与 PoolArena 的关系是多对一的关系,也就是说一个线程只能绑定到一个固定的 PoolArena 上,而一个 PoolArena 却可以被多个线程绑定。
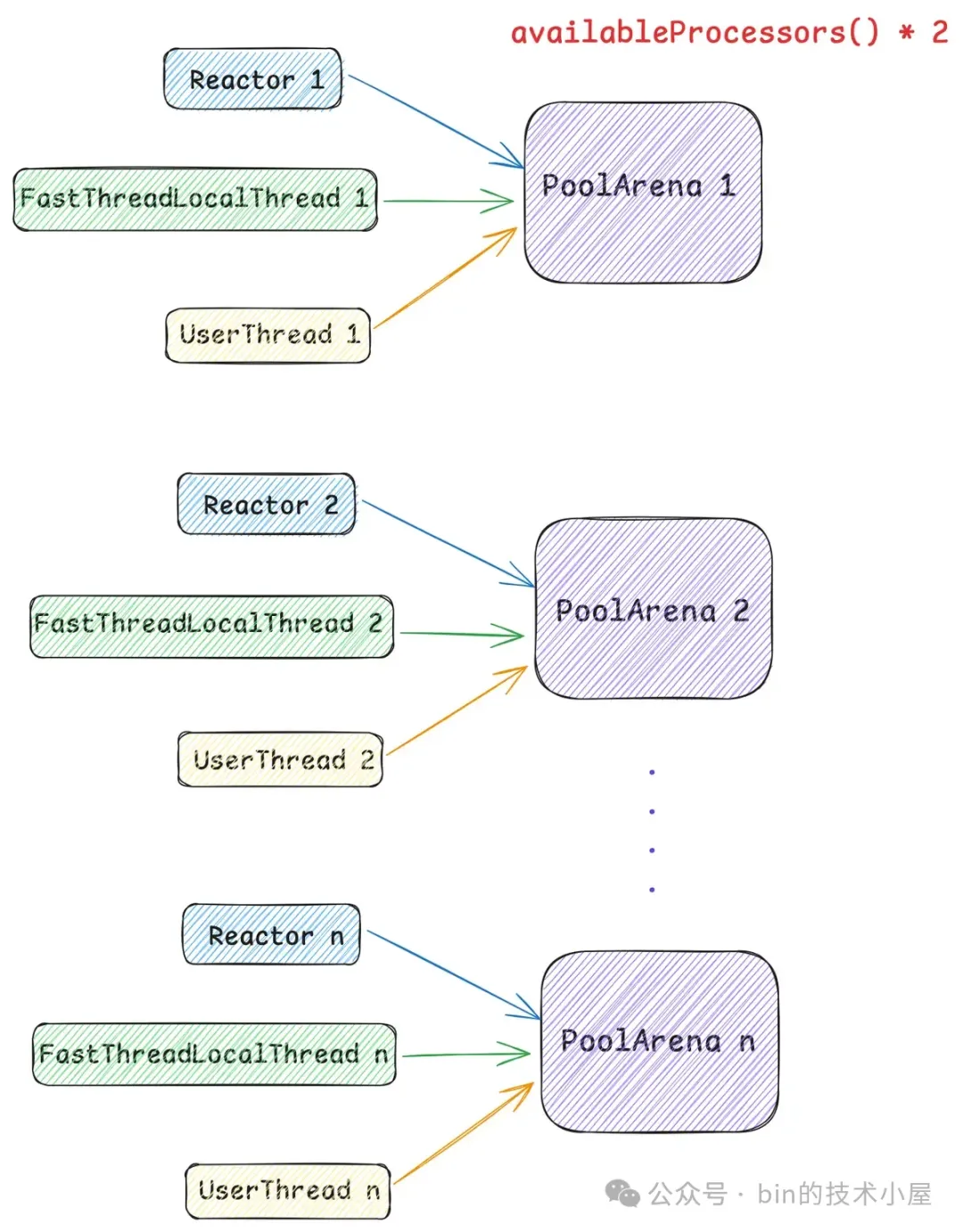
这样一来虽然线程与 PoolArena 产生了绑定,在很大程度上降低了竟争同一 PoolArena 的激烈程度,但仍然会存在竞争的情况。那这种微小的竞争会带来什么影响呢 ?
针对内存池的场景,比如现在有两个线程:Thread1 和 Thread2 ,它俩共同绑定到了同一个 PoolArena 上,Thread1 首先向 PoolArena 申请了一个内存块,并加载到运行它的 CPU1 L1 Cache 中,Thread1 使用完之后将这个内存块释放回 PoolArena。
假设此时 Thread2 向 PoolArena 申请同样尺寸的内存块,而且恰好申请到了刚刚被 Thread1 释放的内存块。注意,此时这个内存块已经在 CPU1 L1 Cache 中缓存了,运行 Thread2 的 CPU2 L1 Cache 中并没有,这就涉及到了 cacheline 的核间通信(MESI 协议相关),又要耗费几十个时钟周期。
为了极致的性能,我们能不能做到无锁化呢 ?近一步把 cacheline 核间通信的这部分开销省去。
这就需要引入内存池的第二个模型 —— PoolThreadCache ,作为线程的 Thread Local 缓存,它用于缓存线程从 PoolArena 中申请到的内存块,线程每次申请内存的时候首先会到 PoolThreadCache 中查看是否已经缓存了相应尺寸的内存块,如果有,则直接从 PoolThreadCache 获取,如果没有,再到 PoolArena 中去申请。同理,线程每次释放内存的时候,也是先释放到 PoolThreadCache 中,而不会直接释放回 PoolArena 。
这样一来,我们通过为每个线程引入 Thread Local 本地缓存 —— PoolThreadCache,实现了内存申请与释放的无锁化,同时也避免了 cacheline 在多核之间的通信开销,极大地提升了内存池的性能。
但是这样又会引来一个问题,就是内存消耗太大了,系统中有那么多的线程,如果每个线程在向 PoolArena 申请内存的时候,我们都为它默认创建一个 PoolThreadCache 本地缓存的话,这一部分的内存消耗将会特别大。
因此为了近一步降低内存消耗又同时兼顾内存池的性能,在 Netty 的权衡之下,默认只会为 Reactor 线程以及 FastThreadLocalThread 类型的线程创建 PoolThreadCache,而普通的用户线程在默认情况下将不再拥有本地缓存。
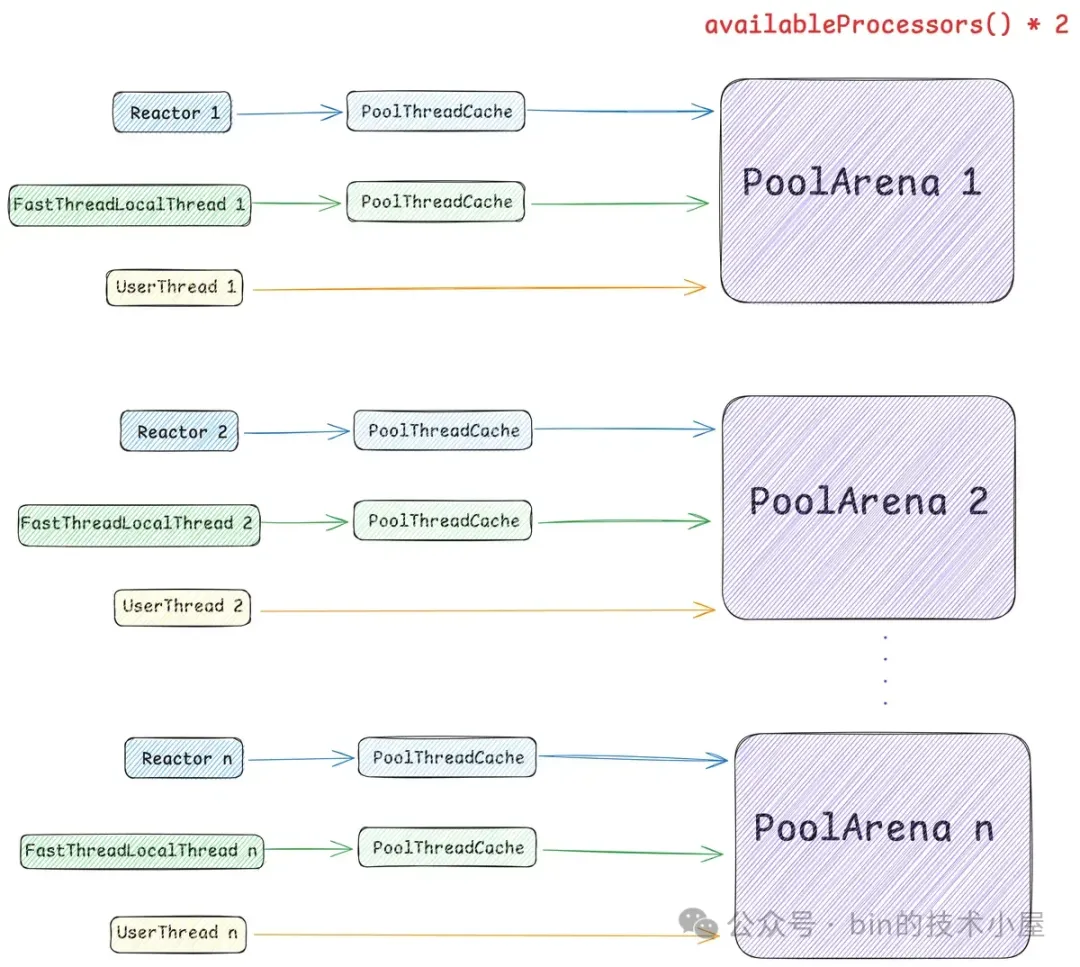
同时 Netty 也为此提供了一个配置选项 -Dio.netty.allocator.useCacheForAllThreads, 默认为 false 。如果我们将其配置为 true , 那么 Netty 默认将会为系统中的所有线程分配 PoolThreadCache 。
DEFAULT_USE_CACHE_FOR_ALL_THREADS = SystemPropertyUtil.getBoolean(
"io.netty.allocator.useCacheForAllThreads", false);
好了,现在我们已经清楚了内存池的线程模型,那么接下来大家一定很好奇这个 PoolArena 里面到底长什么样子。 PoolArena 是内存池的核心实现,它里面管理了各种不同规格的内存块,PoolArena 的整个数据结构设计都是围绕着这些内存块的管理展开的。所以在拆解 PoolArena 之前,我们需要知道 Netty 内存池究竟划分了哪些规格的内存块
于是就引入了内存池的第三个模型 —— SizeClasses ,Netty 的内存池也是按照内存页 page 进行内存管理的,不过与 OS 不同的是,在 Netty 中一个 page 的大小默认为 8k,我们可以通过 -Dio.netty.allocator.pageSize 调整 page 大小,但最低只能调整到 4k,而且 pageSize 必须是 2 的次幂。
// 8k
int defaultPageSize = SystemPropertyUtil.getInt("io.netty.allocator.pageSize", 8192);
// 4K
private static final int MIN_PAGE_SIZE = 4096;
Netty 内存池最小的管理单位是 page , 而内存池单次向 OS 申请内存的单位是 Chunk,一个 Chunk 的大小默认为 4M。Netty 用一个 PoolChunk 的结构来管理这 4M 的内存空间。我们可以通过 -Dio.netty.allocator.maxOrder 来调整 chunkSize 的大小(默认为 4M),maxOrder 的默认值为 9 ,最大值为 14。
// 9
int defaultMaxOrder = SystemPropertyUtil.getInt("io.netty.allocator.maxOrder", 9);
// 8196 << 9 = 4M
final int defaultChunkSize = DEFAULT_PAGE_SIZE << DEFAULT_MAX_ORDER;
// 1G
private static final int MAX_CHUNK_SIZE = (int) (((long) Integer.MAX_VALUE + 1) / 2);
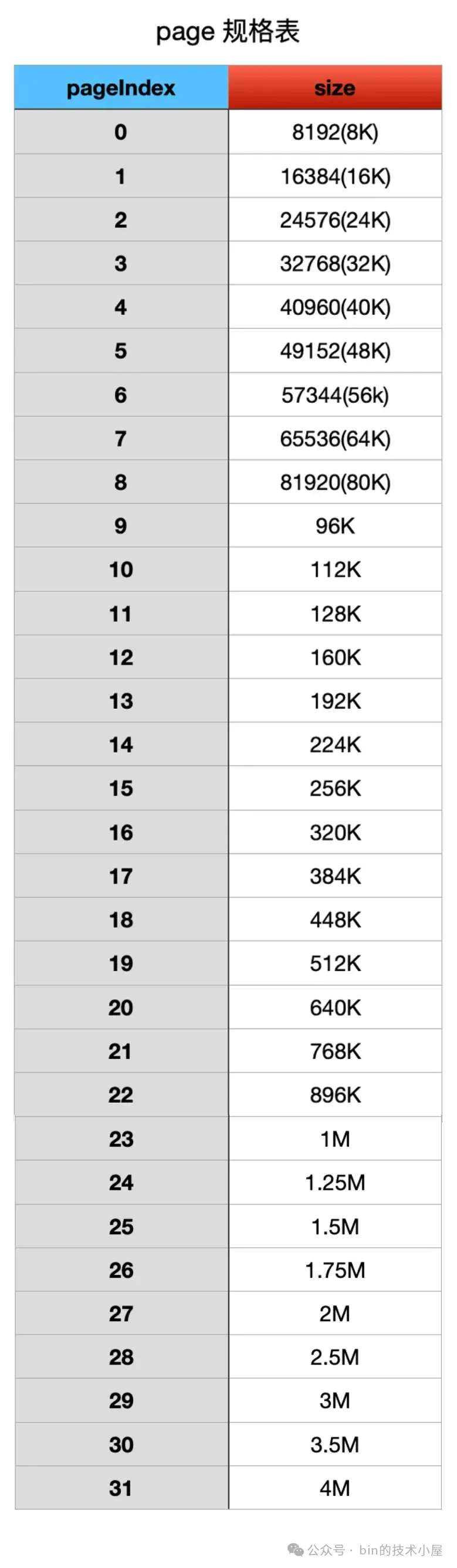
我们看到 ChunkSize 的大小是由 PAGE_SIZE 和 MAX_ORDER 共同决定的 —— PAGE_SIZE << MAX_ORDER,当 pageSize 为 8K 的时候,chunkSize 最大不能超过 128M,无论 pageSize 配置成哪种大小,最大的 chunkSize 不能超过 1G。
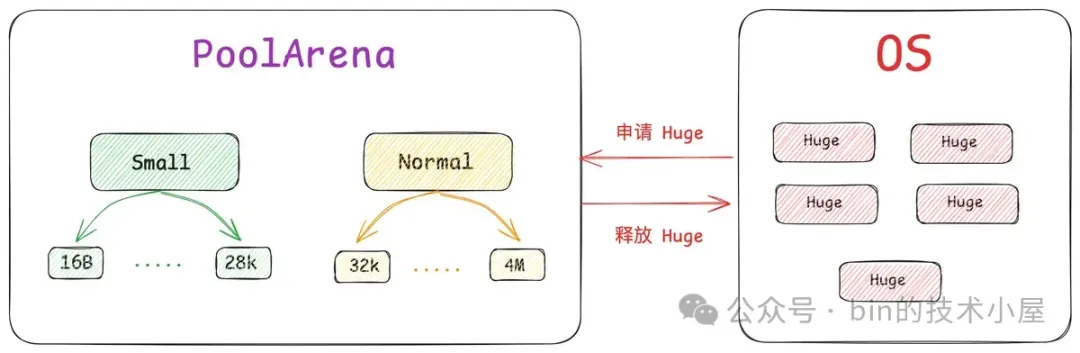
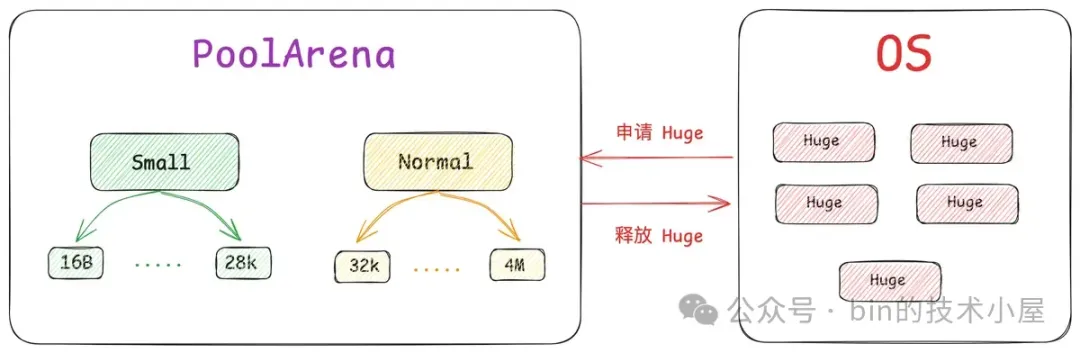
Netty 在向 OS 申请到一个 PoolChunk 的内存空间(4M)之后,会通过 SizeClasses 近一步将这 4M 的内存空间切分成 68 种规格的内存块来进行池化管理。其中最小规格的内存块为 16 字节,最大规格的内存块为 4M 。也就是说,Netty 的内存池只提供如下 68 种内存规格来让用户申请。

除此之外,Netty 又将这 68 种内存规格分为了三类:
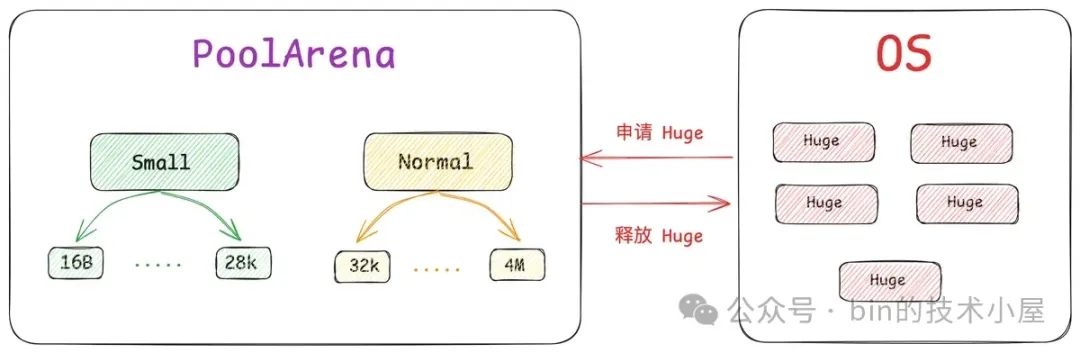
- [16B , 28K] 这段范围内的规格被划分为 Small 规格。
- [32K , 4M] 这段范围内的规格被划分为 Normal 规格。
- 超过 4M 的内存规格被划分为 Huge 规格。
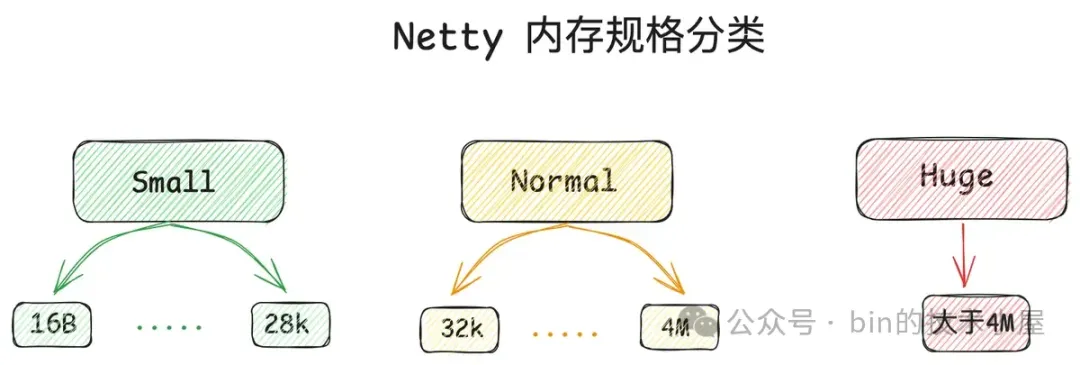
其中 Small 和 Normal 规格的内存块会被内存池(PoolArena)进行池化管理,Huge 规格的内存块不会被内存池管理,当我们向内存池申请 Huge 规格的内存块时,内存池是直接向 OS 申请内存,释放的时候也是直接释放回 OS ,内存池并不会缓存这些 Huge 规格的内存块。
abstract class PoolArena<T> {
enum SizeClass {
Small,
Normal
}
}
那么接下来的问题就是 Small 和 Normal 这两种规格的内存块在 PoolArena 中是如何被管理起来的呢 ?前面我们提到,在 Netty 内存池中,内存管理的基本单位是 Page , 一个 Page 的内存规格是 8K ,这个是内存管理的基础,而 Small , Normal 这两种规格是在这个基础之上进行管理的。
所以我们首先需要弄清楚 Netty 是如何管理这些以 Page 为粒度的内存块的,这就引入了内存池的第四个模型 —— PoolChunk 。PoolChunk 的设计参考了 Linux 内核中的伙伴系统,在内核中,内存管理的基本单位也是 Page(4K),这些 Page 会按照伙伴的形式被内核组织在伙伴系统中。
内核中的伙伴指的是大小相同并且在物理内存上连续的两个或者多个 page(个数必须是 2 的次幂)。
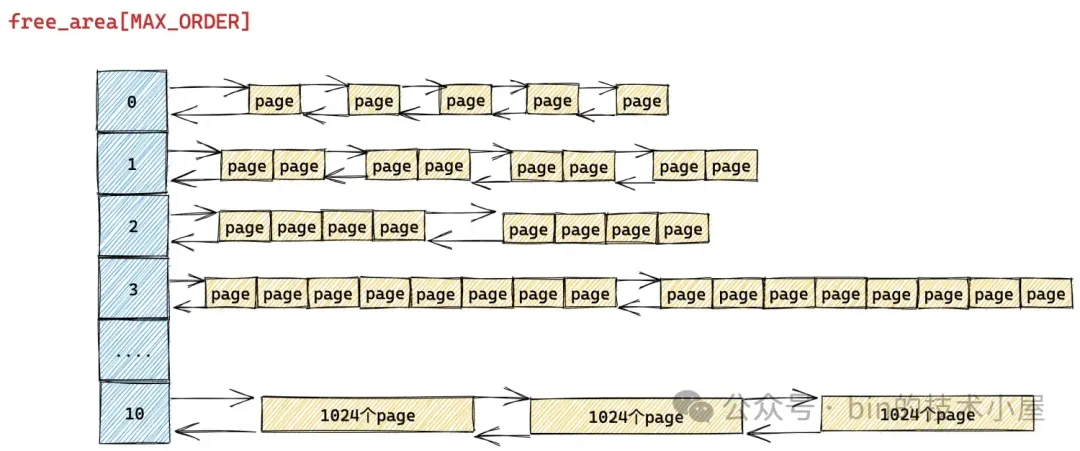
如上图所示,内核中伙伴系统的核心数据结构就是这个 struct free_area 类型的数组 —— free_area[MAX_ORDER]。
struct zone {
// 伙伴系统的核心数据结构
struct free_area free_area[MAX_ORDER];
}
数组 free_area[MAX_ORDER] 中的索引表示的是分配阶 order,这个 order 用于指定对应 free_area 结构中组织管理的内存块包含多少个 page。比如 free_area[0] 中管理的内存块都是一个一个的 Page , free_area[1] 中管理的内存块尺寸是 2 个 Page , free_area[10] 中管理的内存块尺寸为 1024 个 Page。
这些相同尺寸的内存块在 struct free_area 结构中是通过 struct list_head 结构类型的双向链表统一组织起来的。
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
};
struct list_head {
// 双向链表
struct list_head *next, *prev;
};
当我们向内核申请 2 ^ order 个 Page 的时候,内核首先会到伙伴系统中的 free_area[order] 对应的双向链表 free_list 中查看是否有空闲的内存块,如果有则从 free_list 将内存块摘下并分配出去,如果没有,则继续向上到 free_area[order + 1] 中去查找,反复这个过程,直到在 free_area[order + n] 中的 free_list 链表中找到空闲的内存块。
但是此时我们在 free_area[order + n] 链表中找到的空闲内存块的尺寸是 2 ^ (order + n) 大小,而我们需要的是 2 ^ order 尺寸的内存块,于是内核会将这 2 ^ (order + n) 大小的内存块逐级减半分裂,将每一次分裂后的内存块插入到相应的 free_area 数组里对应的 free_list 链表中,并将最后分裂出的 2 ^ order 尺寸的内存块分配给进程使用。
假设我们现在要向下图中的伙伴系统申请一个 Page (对应的分配阶 order = 0),那么内核会在伙伴系统中首先查看 order = 0 对应的空闲链表 free_area[0] 中是否有空闲内存块可供分配。
如果没有,内核则会根据前边介绍的内存分配逻辑,继续升级到 free_area[1] , free_area[2] 链表中寻找空闲内存块,直到查找到 free_area[3] 发现有一个可供分配的内存块。这个内存块中包含了 8 个 连续的空闲 page。
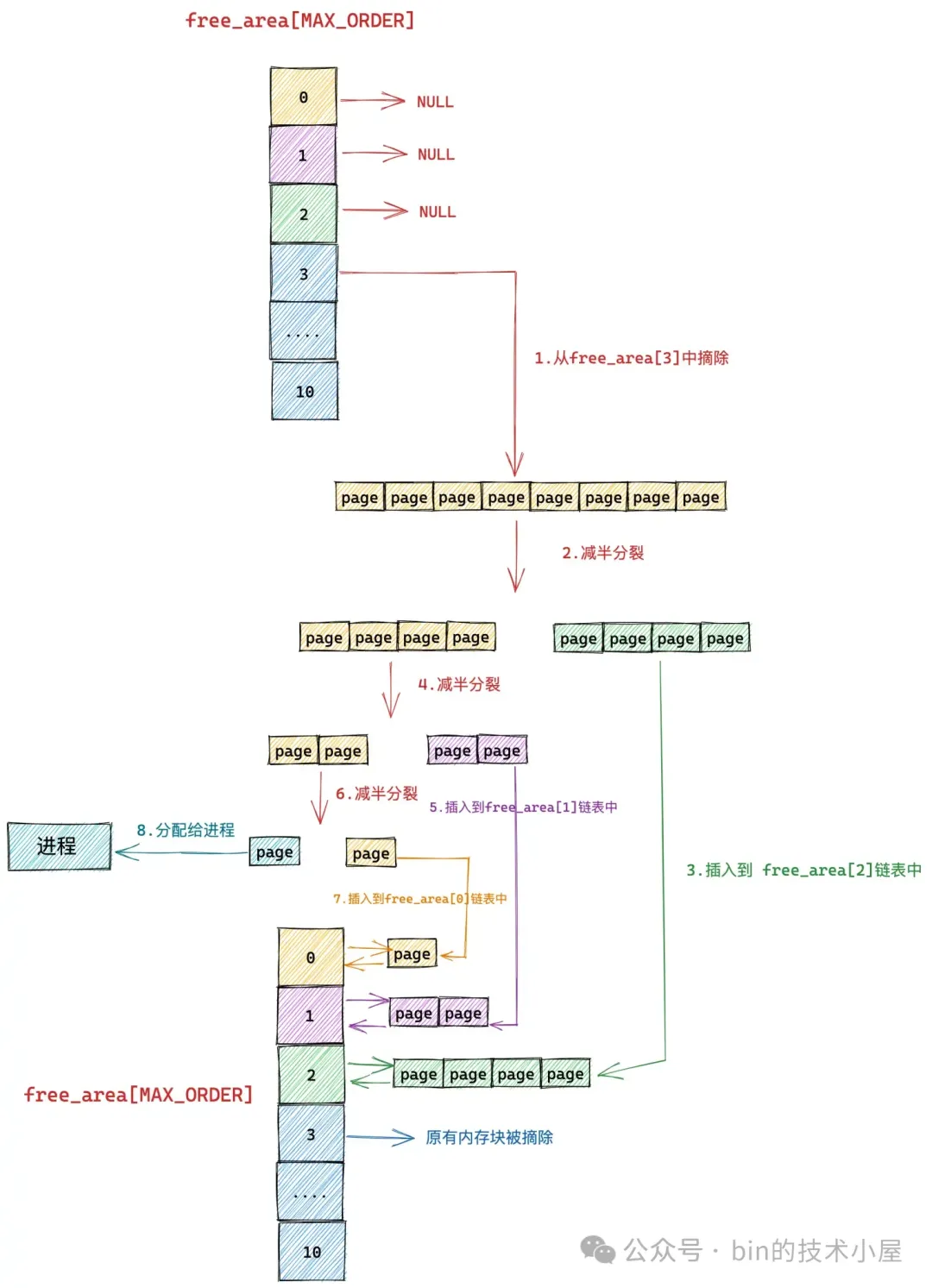
随后内核会将 free_area[3] 中的这个空闲内存块从链表中摘下,然后减半分裂成两个内存块,分裂出来的这两个内存块分别包含 4 个 page(分配阶 order = 2)。将第二个内存块(图中绿色部分,order = 2),插入到 free_rea[2] 链表中。
第一个内存块(图中黄色部分,order = 2)继续减半分裂,分裂出来的这两个内存块分别包含 2 个 page(分配阶 order = 1)。如上图中第 4 步所示,前半部分为黄色,后半部分为紫色。同理按照前边的分裂逻辑,内核会将后半部分内存块(紫色部分,分配阶 order = 1)插入到 free_area[1] 链表中。
前半部分(图中黄色部分,order = 1)在上图中的第 6 步继续减半分裂,分裂出来的这两个内存块分别包含 1 个 page(分配阶 order = 0),前半部分为青色,后半部分为黄色。后半部分插入到 frea_area[0] 链表中,前半部分返回给进程,以上就是内核中伙伴系统的内存分配过程。
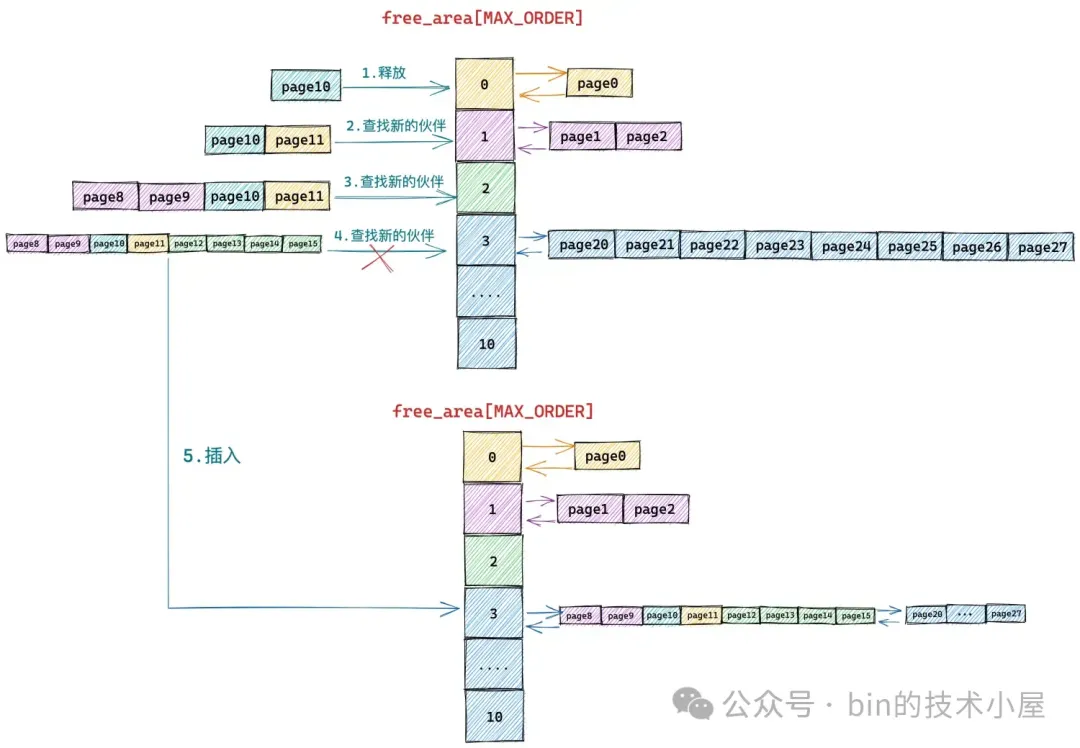
下面我们继续来回顾一下内核伙伴系统的内存回收过程,当我们向内核释放 2 ^ order 个 Page 的时候,内核首先会检查 free_area[order] 对应的 free_list 中是否有与我们要释放的内存块在内存地址上连续的空闲内存块,如果有地址连续的内存块,则将两个内存块进行合并,然后在到上一级 free_area[order + 1] 中继续查找是否有空闲内存块与合并之后的内存块在地址上连续,如果有则继续重复上述过程向上合并,如果没有,则将合并之后的内存块插入到 free_area[order + 1] 中。
假设我们现在需要将一个编号为 10 的 Page 释放回下图所示的伙伴系统中,连续的编号表示内存地址连续。首先内核会在 free_area[0] 中发现有一个空闲的内存块 page11 与要释放的 page10 连续,于是将两个连续的内存块合并,合并之后的内存块的分配阶 order = 1。
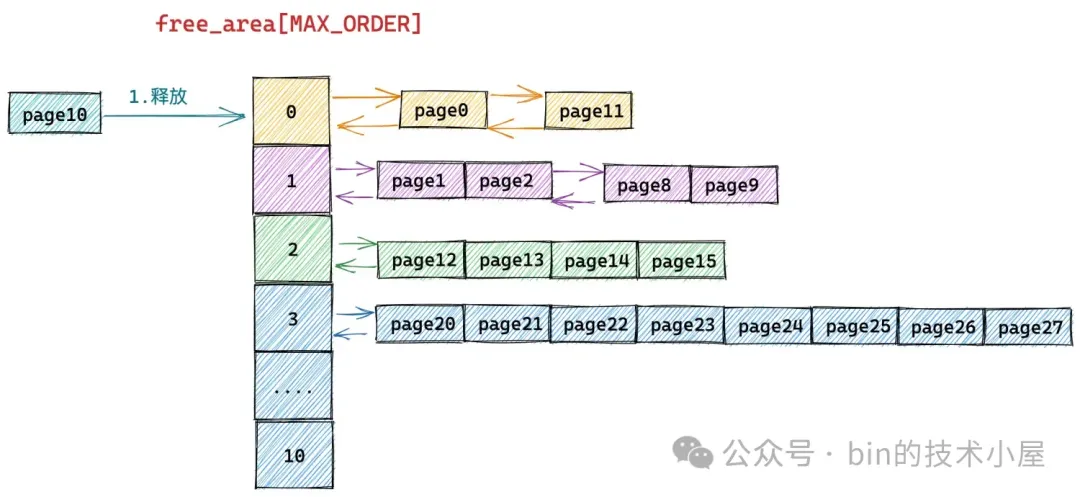
随后内核在 free_area[1] 中发现 page8 和 page9 组成的内存块与 page10 和 page11 合并后的内存块是伙伴,于是继续将这两个内存块(分配阶 order = 1)继续合并成一个新的内存块(分配阶 order = 2)。随后内核会在 free_area[2] 中查找新合并后的内存块伙伴。
接着内核在 free_area[2] 中发现 page12,page13,page14,page15 组成的内存块与 page8,page9,page10,page11 组成的新内存块是伙伴,于是将它们从 free_area[2] 上摘下继续合并成一个新的内存块(分配阶 order = 3),随后内核会在 free_area[3] 中查找新内存块的伙伴。
但在 free_area[3] 中的内存块(page20 到 page 27)与新合并的内存块(page8 到 page15)虽然大小相同但是物理上并不连续,所以它们不是伙伴,不能在继续向上合并了。于是内核将 page8 到 pag15 组成的内存块(分配阶 order = 3)插入到 free_area[3] 中,整个伙伴系统回收内存的过程如下如所示:
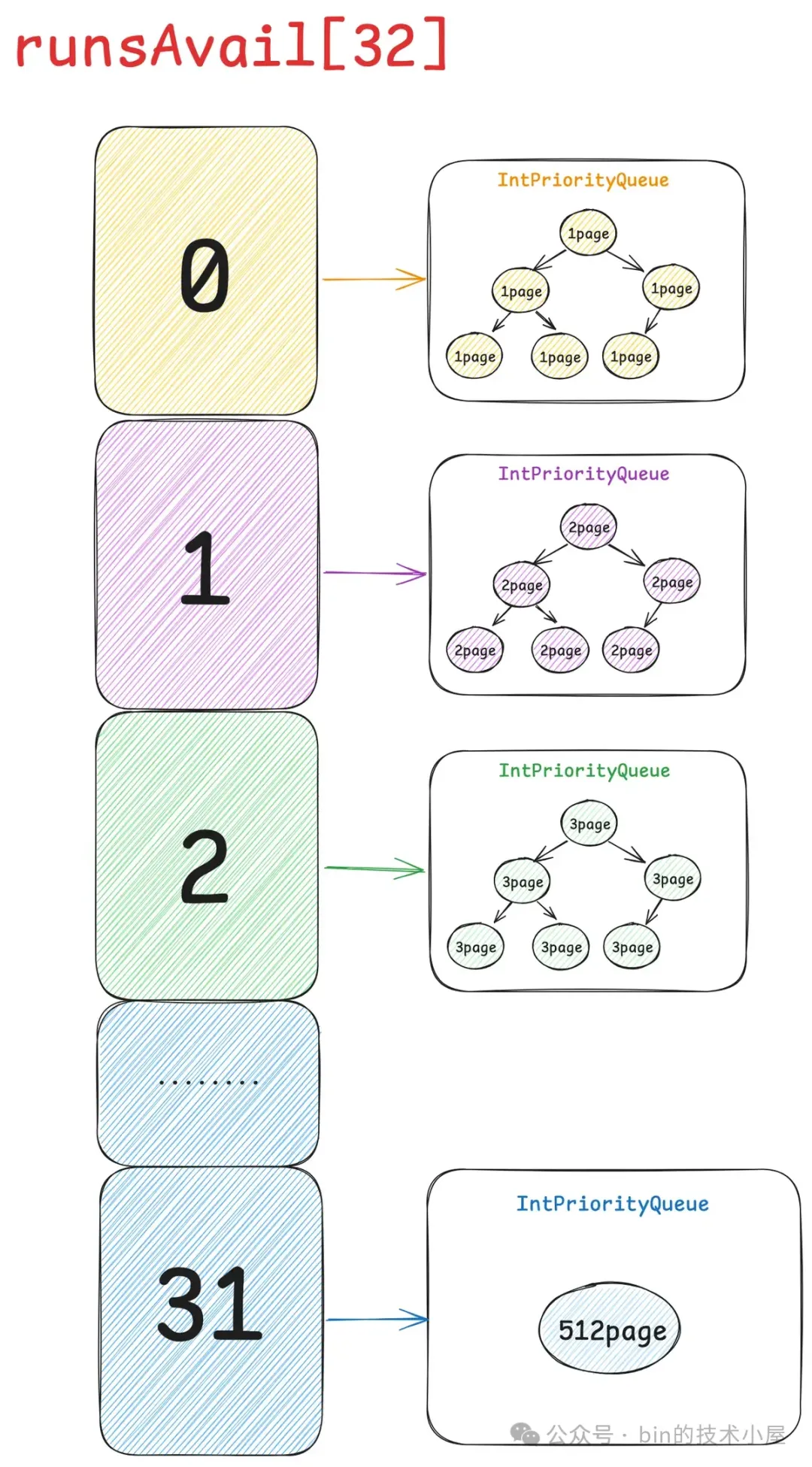
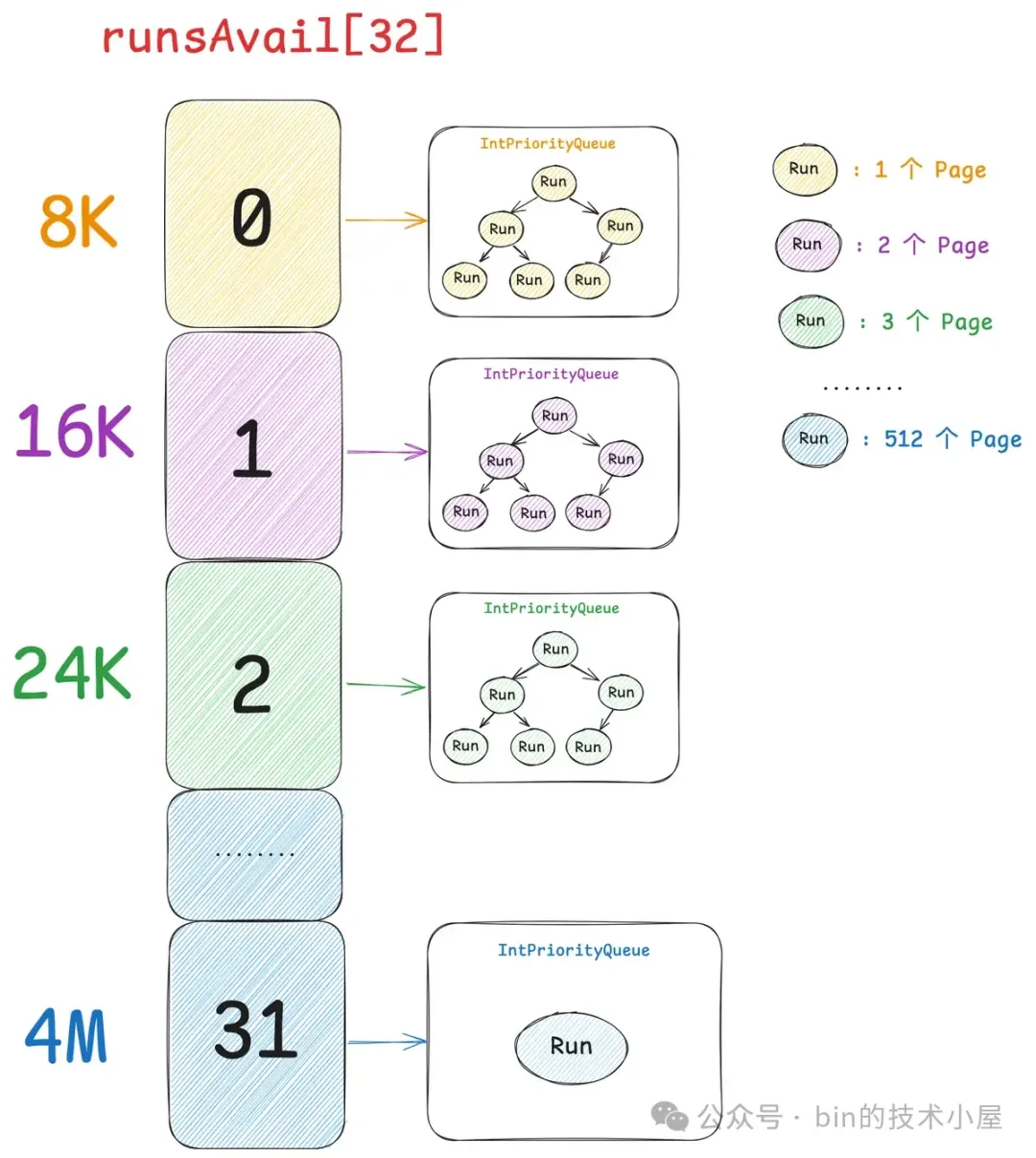
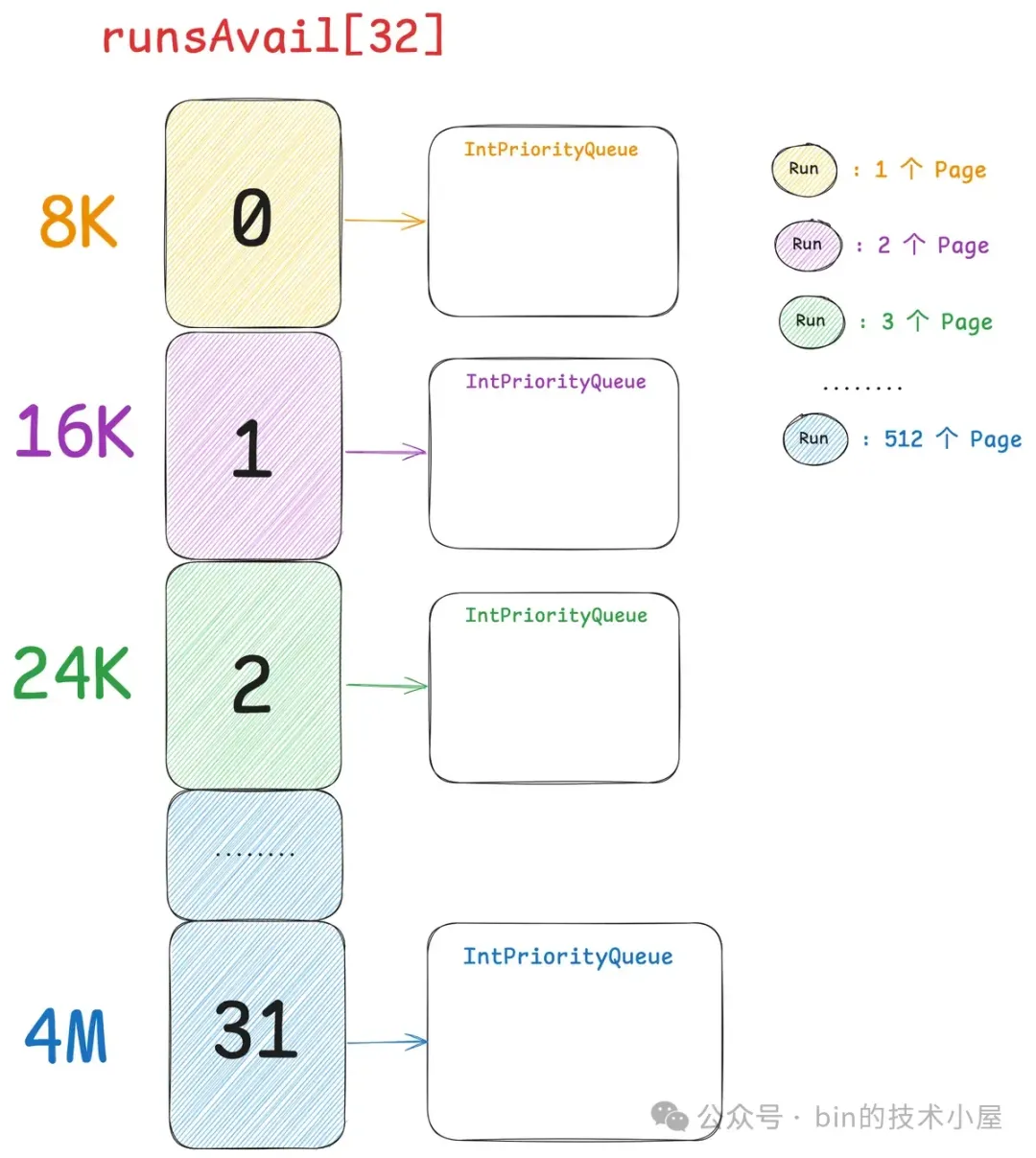
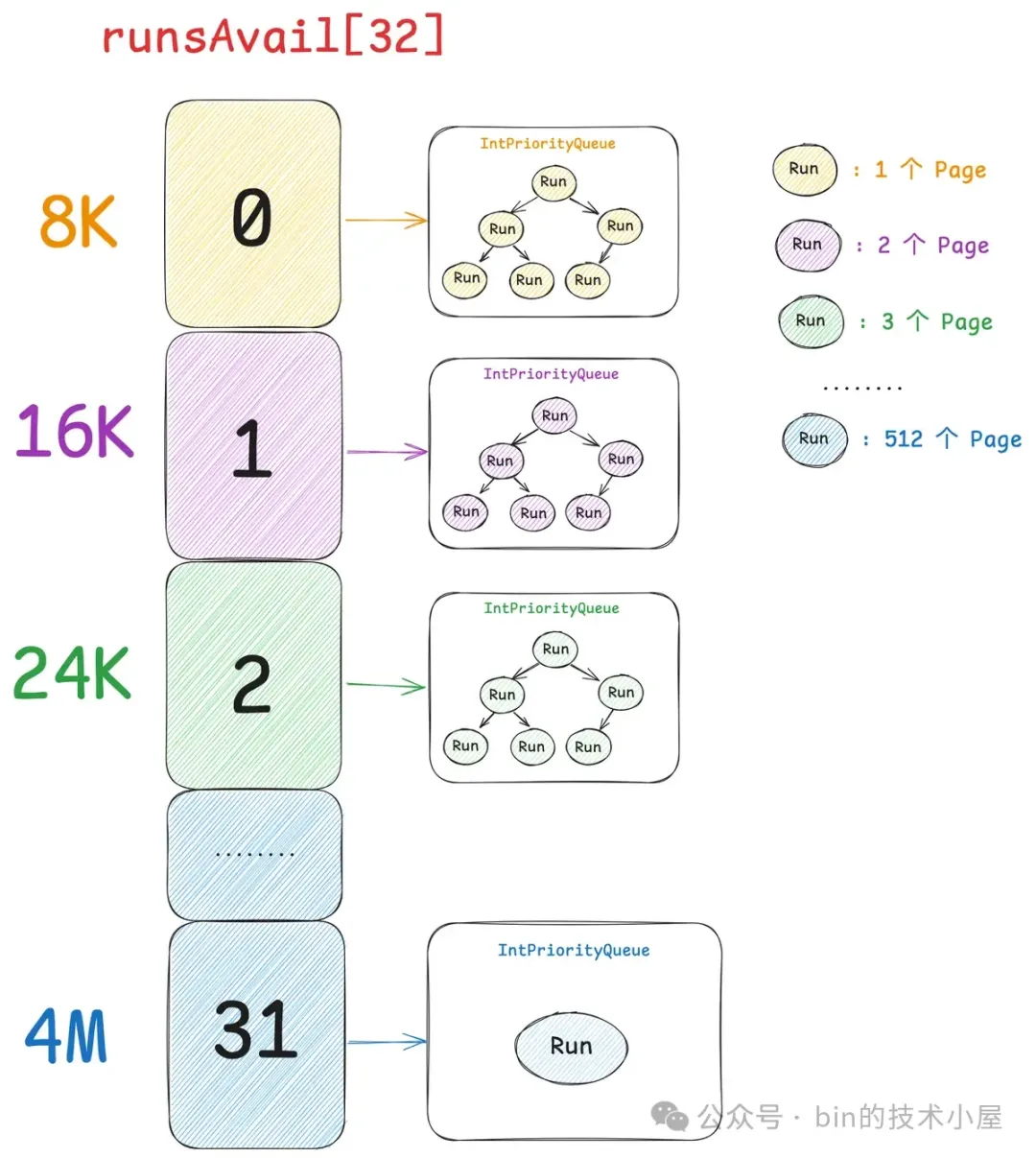
现在我们已经清楚了伙伴系统在 Linux 内核中的实现,那么同样是对 Page 的管理,Netty 中的 PoolChunk 也是一样,它的实现和内核中的伙伴系统非常相似。PoolChunk 也有一个数组 runsAvail。
final class PoolChunk<T> implements PoolChunkMetric {
// Netty 的伙伴系统结构
private final IntPriorityQueue[] runsAvail;
}
和内核中的 free_area 数组一样,它们里面都保存了不同 Page 级别的内存块,不一样的是内核中的伙伴系统一共只有 11 个 Page 级别的内存块尺寸,分别是: 1 个 Page , 2 个 Page , 4 个 Page,8 个 Page 一直到 1024 个 Page。内存块的尺寸必须是 2 的次幂个 Page。
Netty 中的伙伴系统一共有 32 个 Page 级别的内存块尺寸,这一点我们可以从前面介绍的 SizeClasses 计算出来的内存规格表看得出来。PoolChunk 中管理的这些 Page 级别的内存块尺寸只要是 Page 的整数倍就可以,而不是内核中要求的 2 的次幂个 Page。
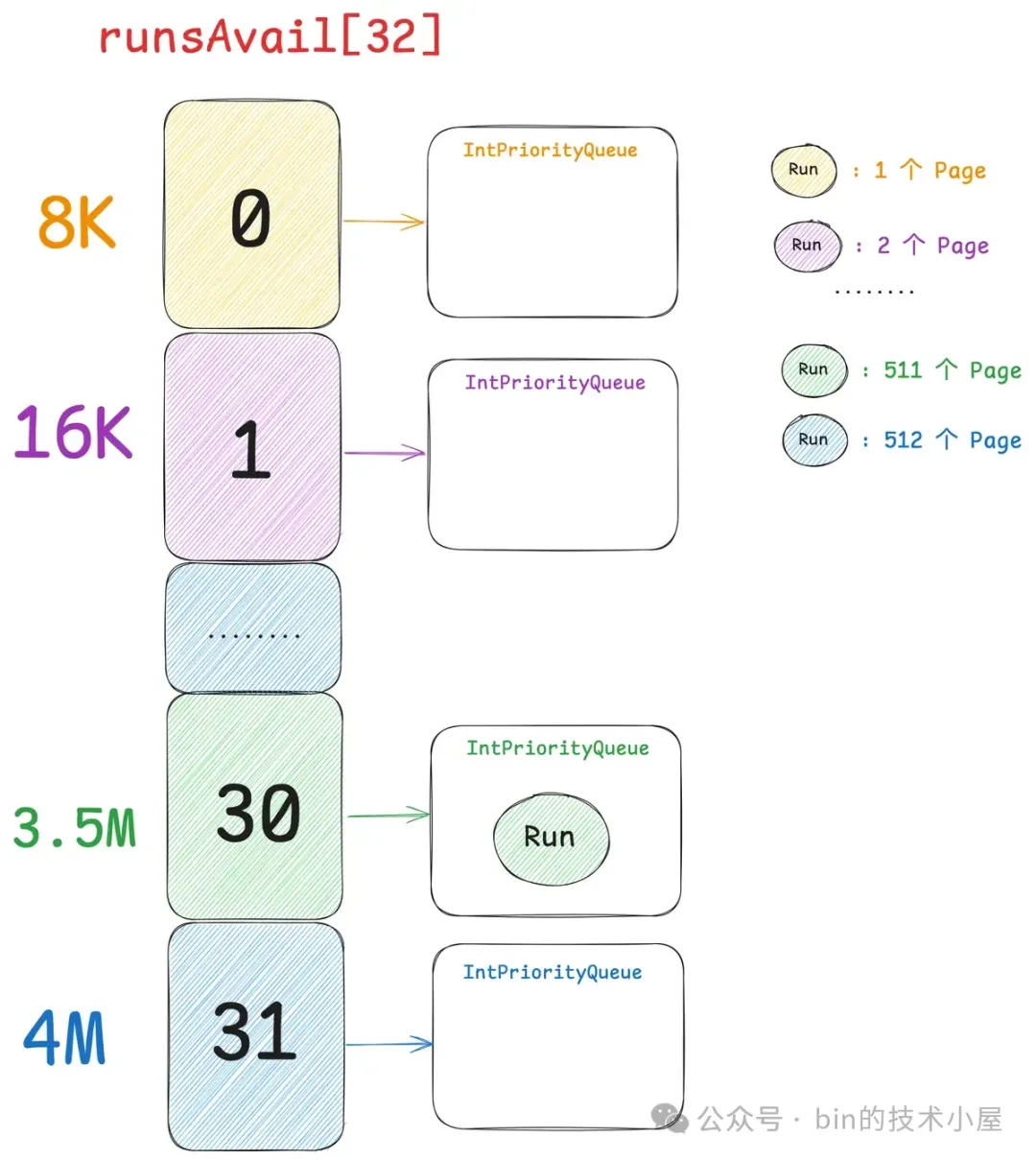
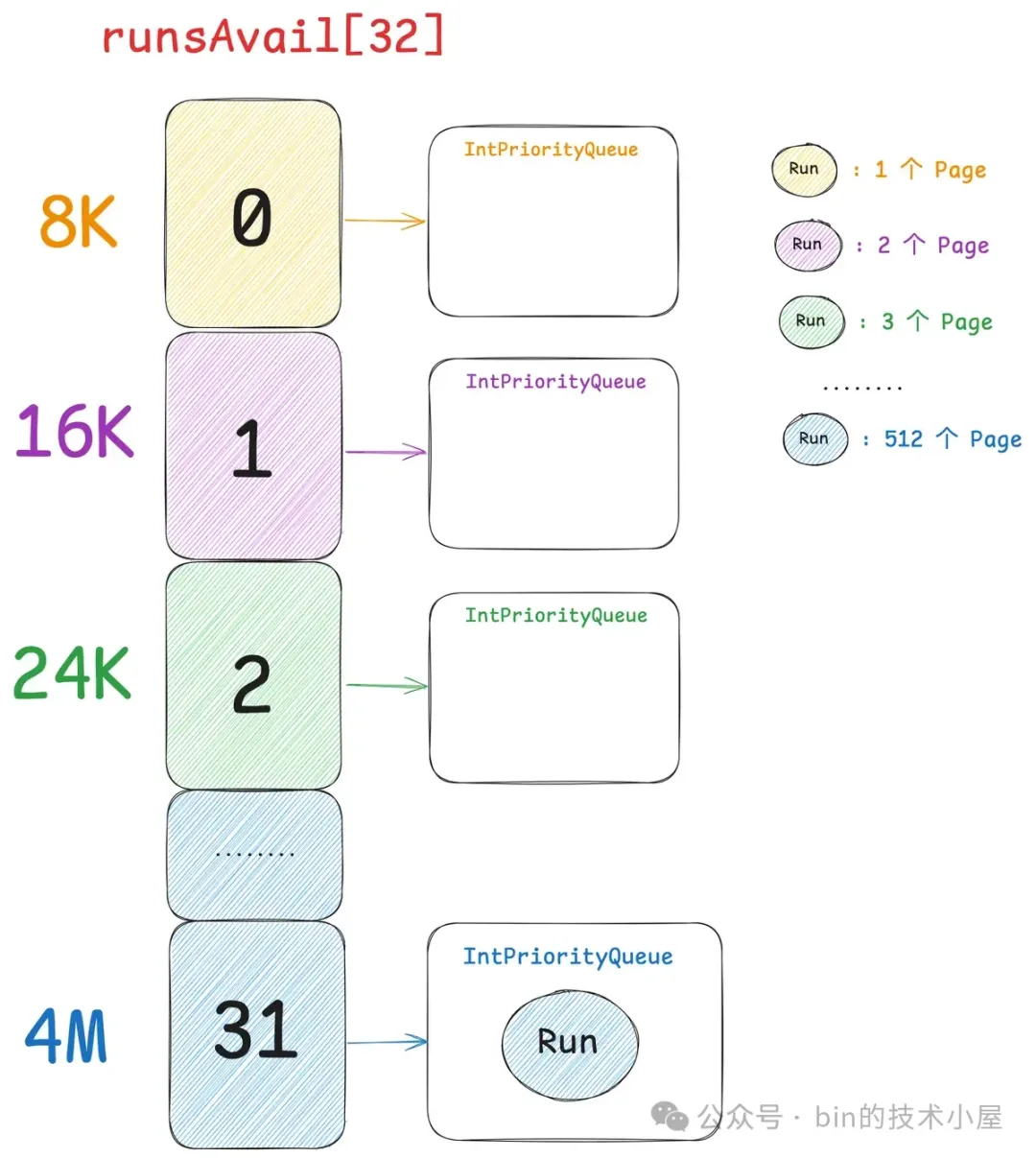
因此 runsAvail 数组中一共有 32 个元素,数组下标就是上图中的 pageIndex , 数组类型为 IntPriorityQueue(优先级队列),数组中的每一项存储着所有相同 size 的内存块,这里的 size 就是上图中 pageIndex 对应的 size 。
比如 runsAvail[0] 中存储的全部是单个 Page 的内存块,runsAvail[1] 中存储的全部是尺寸为 2 个 Page 的内存块,runsAvail[2] 中存储的全部是尺寸为 3 个 Page 的内存块,runsAvail[31] 中存储的是尺寸为 512 个 Page 的内存块。
Netty 中的一个 Page 是 8k
PoolChunk 可以看做是 Netty 中的伙伴系统,内存的申请和释放过程和内核中的伙伴系统非常相似,当我们向 PoolChunk 申请 Page 级别的内存块时,Netty 首先会从上面的 Page 规格表中获取到内存块尺寸对应的 pageIndex,然后到 runsAvail[pageIndex] 中去获取对应尺寸的内存块。
如果没有空闲内存块,Netty 的处理方式也是和内核一样,逐级向上去找,直到在 runsAvail[pageIndex + n] 中找到内存块。然后从这个大的内存块中将我们需要的内存块尺寸切分出来分配,剩下的内存块直接插入到对应的 runsAvail[剩下的内存块尺寸 index]中,并不会像内核那样逐级减半分裂。
PoolChunk 的内存块回收过程则和内核一样,回收的时候会将连续的内存块合并成更大的,直到无法合并为止。最后将合并后的内存块插入到对应的 runsAvail[合并后内存块尺寸 index] 中。
Netty 这里还有一点和内核不一样的是,内核的伙伴系统是使用 struct free_area 结构来组织相同尺寸的内存块,它是一个双向链表的结构,每次向内核申请 Page 的时候,都是从 free_list 的头部获取内存块。释放的时候也是讲内存块插入到 free_list 的头部。这样一来我们总是可以获取到刚刚被释放的内存块,局部性比较好。
但 Netty 的伙伴系统采用的是 IntPriorityQueue ,一个优先级队列来组织相同尺寸的内存块,它会按照内存地址从低到高组织这些内存块,我们每次从 IntPriorityQueue 中获取的都是内存地址最低的内存块。Netty 这样设计的目的主要还是为了降低内存碎片,牺牲一定的局部性。
这里牺牲掉局部性是 OK 的,因为在 PoolChunk 的设计中,Netty 更加注重内存碎片的大小,PoolChunk 主要提供 Page 级别内存块的申请,Normal 规格 —— [32K , 4M] 的内存块就是从 PoolChunk 中直接申请的。为了使 PoolChunk 这段 4M 的内存空间中内存碎片尽量的少,所以我们每次向 PoolChunk 申请 Page 级别内存块的时候,总是从低内存地址开始有序的申请。
而在 Netty 的应用场景中,往往频繁申请的都是那些小规格的内存块,针对这种频繁使用的 Small 规格的内存块,Netty 在设计上就必须要保证局部性,因为这块是热点,所以性能的考量是首位。
而 Normal 规格的大内存块,往往不会那么频繁的申请,所以在 PoolChunk 的设计上,内存碎片的考量是首位。
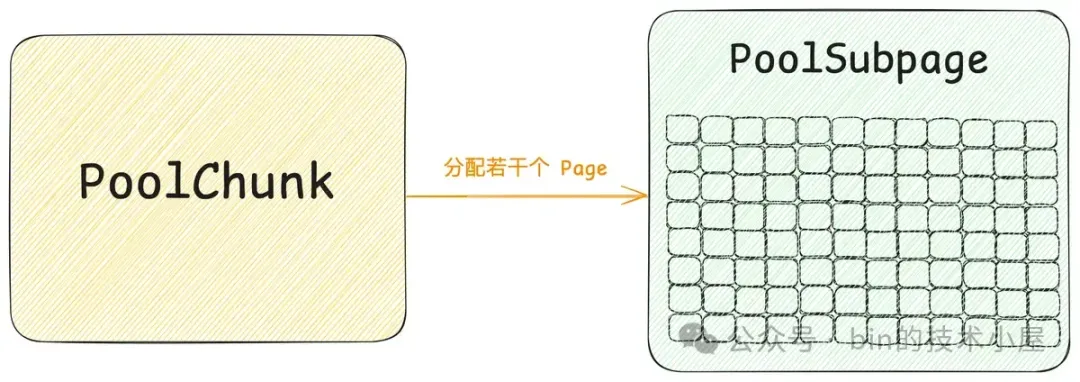
现在我们知道了 Normal 规格的内存块是在 PoolChunk 中管理的,而 PoolChunk 的模型设计我们也清楚了,那 Small 规格的内存块在哪里管理呢 ?这就需要引入内存池的第五个模型 —— PoolSubpage 。
还是一样的套路,遇事不决问内核!! 由于都是针对 Page 级别内存块的管理,所以 PoolChunk 的设计参考了内核的伙伴系统,那么针对小内存块的管理,PoolSubpage 自然也会参考内核中的 slab cache 。所以 PoolSubpage 可以看做是 Netty 中的 slab 。
对内核 slab 的设计实现细节感兴趣的读者可以回看下笔者之前专门介绍 slab 的文章 —— 《细节拉满,80 张图带你一步一步推演 slab 内存池的设计与实现》。由于篇幅的关系,笔者这里就不再详细介绍内核中的 slab 了,我们直接从 PoolSubpage 这个模型的设计开始聊起,思想都是一样的。
通过前面的介绍我们知道,PoolChunk 承担的是 Page 级别内存块的管理工作,在 Netty 内存池的整个架构设计上属于最底层的模型,它是一个基座,为整个内存池提供最基础的内存分配能力,分配粒度按照 Page 进行。
但在 Netty 的实际应用场景中,往往使用最频繁的是 Small 规格的内存块 —— [16B , 28K] 。我们不可能每申请一个 Small 规格的内存块(比如 16 字节)都要向 PoolChunk 去获取一个 Page(8K),这样内存资源的浪费是非常可观的。
所以 Netty 借鉴了 Linux 内核中 Slab 的设计思想,当我们第一次申请一个 Small 规格的内存块时,Netty 会首先到 PoolChunk 中申请一个或者若干个 Page 组成的大内存块(Page 粒度),这个大内存块在 Netty 中的模型就是 PoolSubpage 。然后按照对应的 Small 规格将这个大内存块切分成多个尺寸相同的小内存块缓存在 PoolSubpage 中。
每次申请这个规格的内存块时,Netty 都会到对应尺寸的 PoolSubpage 中去获取,每次释放这个规格的内存块时,Netty 会直接将其释放回对应的 PoolSubpage 中。而且每次申请 Small 规格的内存块时,Netty 都会优先获取刚刚释放回 PoolSubpage 的内存块,保证了局部性。当 PoolSubpage 中缓存的所有内存块全部被释放回来后,Netty 就会将整个 PoolSubpage 重新释放回 PoolChunk 中。
比如当我们首次向 Netty 内存池申请一个 16 字节的内存块时,首先会从 PoolChunk 中申请 1 个 Page(8K),然后包装成 PoolSubpage 。随后会将 PoolSubpage 中的这 8K 内存空间切分成 512 个 16 字节的小内存块。 后续针对 16 字节小内存块的申请和释放就都只会和这个 PoolSubpage 打交道了。
当我们第一次申请 28K 的内存块时,由于它也是 Small 规格的尺寸,所以按照相同的套路,Netty 会首先从 PoolChunk 中申请 7 个 Pages(56K), 然后包装成 PoolSubpage。随后会将 PoolSubpage 中的这 56K 内存空间切分成 2 个 28K 的内存块。
PoolSubpage 的尺寸是内存块的尺寸与 PageSize 的最小公倍数。
每当一个 PoolSubpage 分配完之后,Netty 就会重新到 PoolChunk 中申请一个新的 PoolSubpage 。这样一来,慢慢的,针对某一种特定的 Small 规格,就形成了一个 PoolSubpage 链表,这个链表是一个双向循环链表,如下图所示:
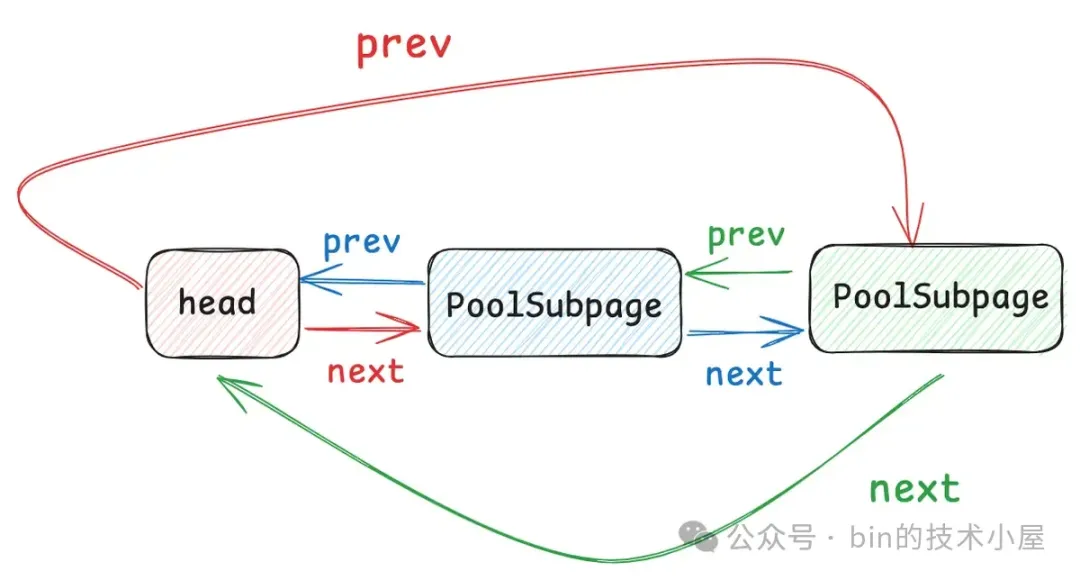
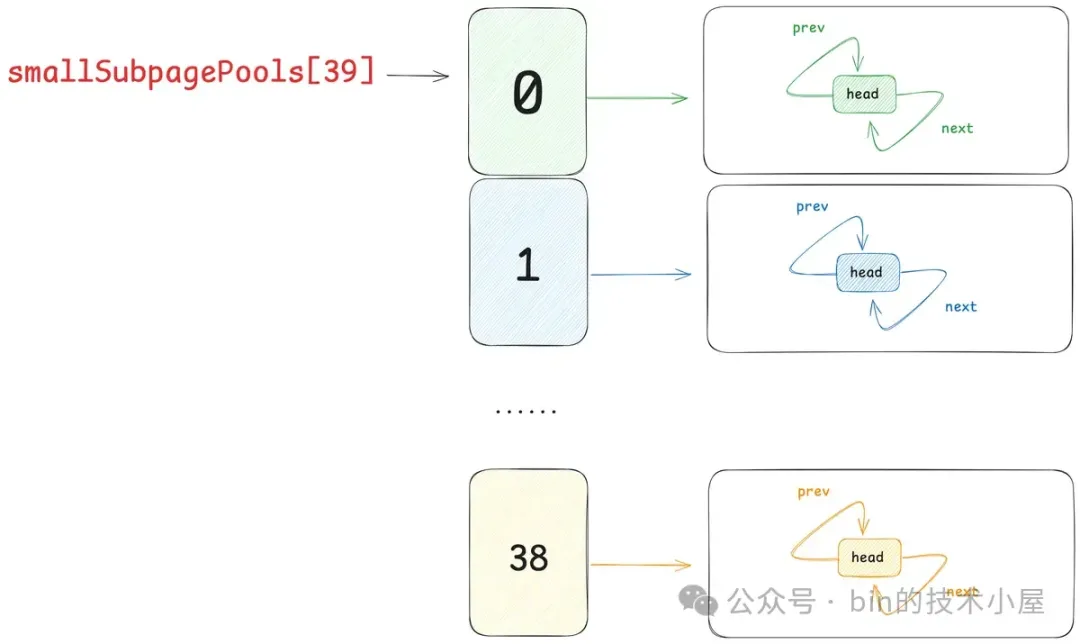
在 Netty 中,每一个 Small 规格尺寸都会对应一个这样的 PoolSubpage 双向循环链表,内存池中一共设计了 39 个 Small 规格尺寸 —— [16B , 28k],所以也就对应了 39 个这样的 PoolSubpage 双向循环链表,形成一个 PoolSubpage 链表数组 —— smallSubpagePools,它是内存池中管理 Small 规格内存块的核心数据结构。
abstract class PoolArena<T> {
// 管理 Small 规格内存块的核心数据结构
final PoolSubpage<T>[] smallSubpagePools;
}
smallSubpagePools 数组的下标就是对应的 Small 规格在 SizeClasses 内存规格表中的 index 。
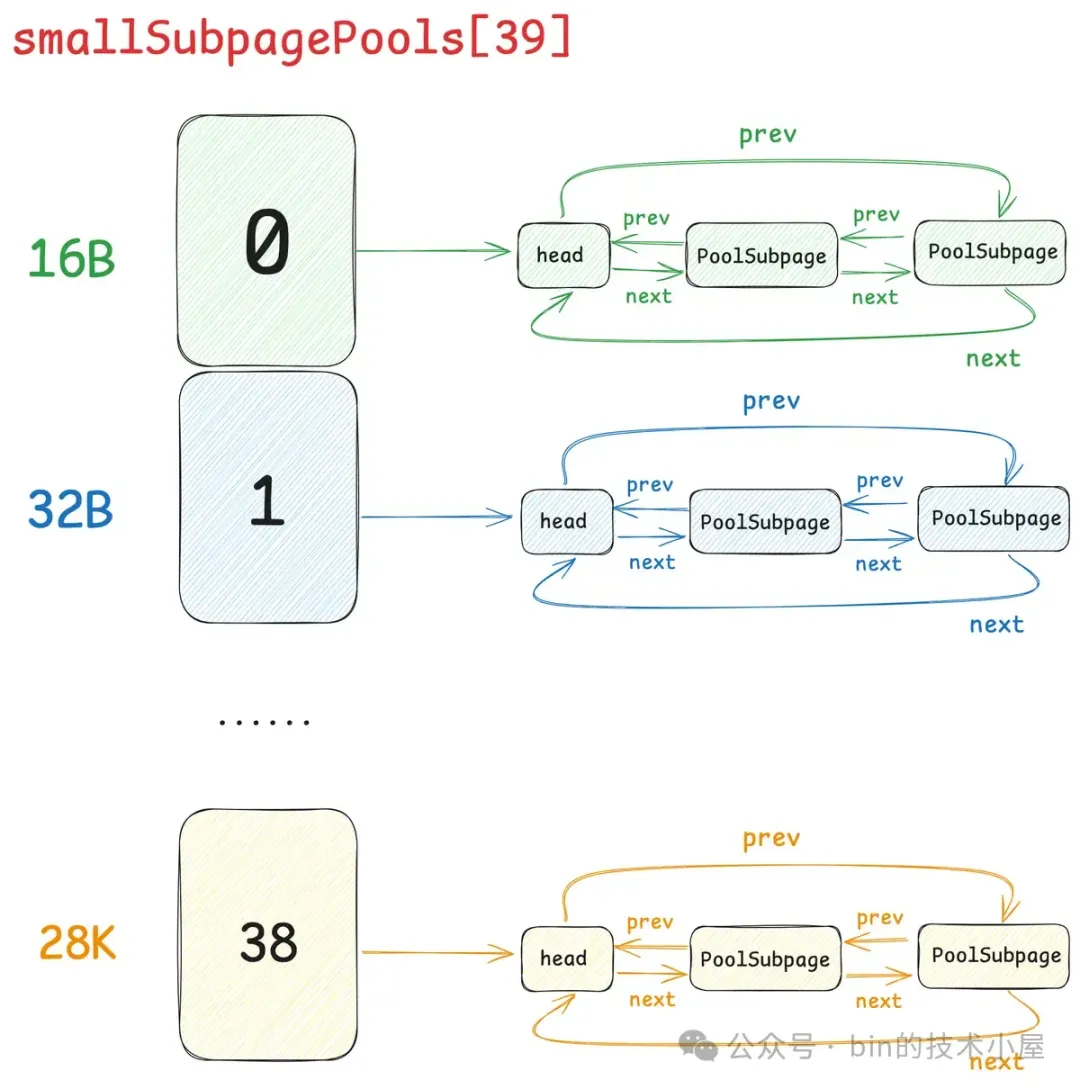
这个设计也是参考了内核中的 kmalloc 体系,内核中的 kmalloc 也是用一个数组来组织不同尺寸的 slab , 只不过和 Netty 不同的是,kmalloc 支持的小内存块尺寸在 8 字节到 8K 之间。
struct kmem_cache *
kmalloc_caches[NR_KMALLOC_TYPES][KMALLOC_SHIFT_HIGH + 1];
这里的 smallSubpagePools 就相当于是内核中的 kmalloc,关于 kmalloc 的设计与实现细节感兴趣的读者可以回看下笔者之前的文章 —— 《深度解读 Linux 内核级通用内存池 —— kmalloc 体系》。
好了,到现在我们已经清楚了,Netty 内存池是如何管理 Small 规格以及 Normal 规格的内存块了。根据目前我们掌握的信息和场景可以得出内存池 —— PoolArena 的基本骨架,如下图所示:
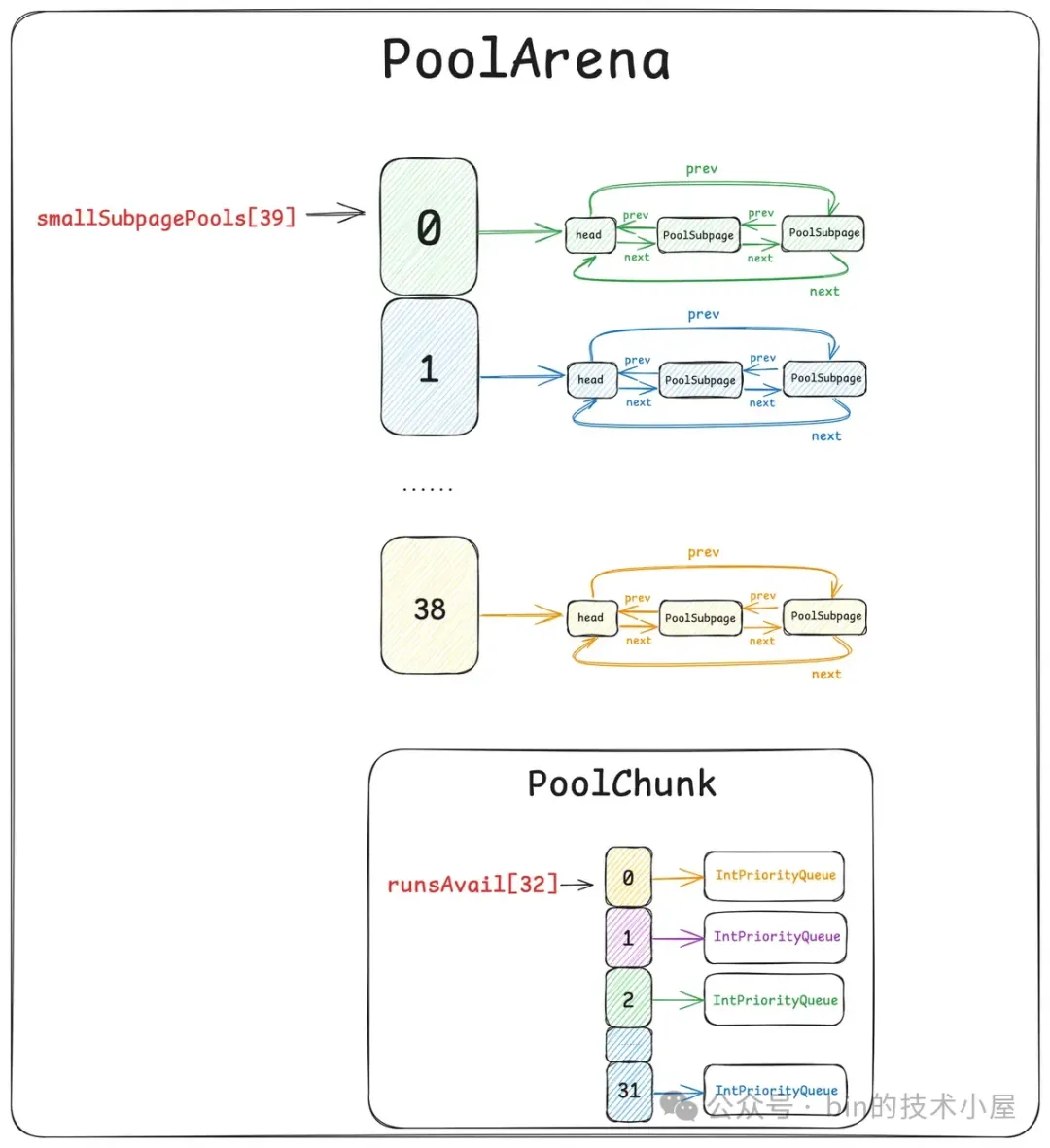
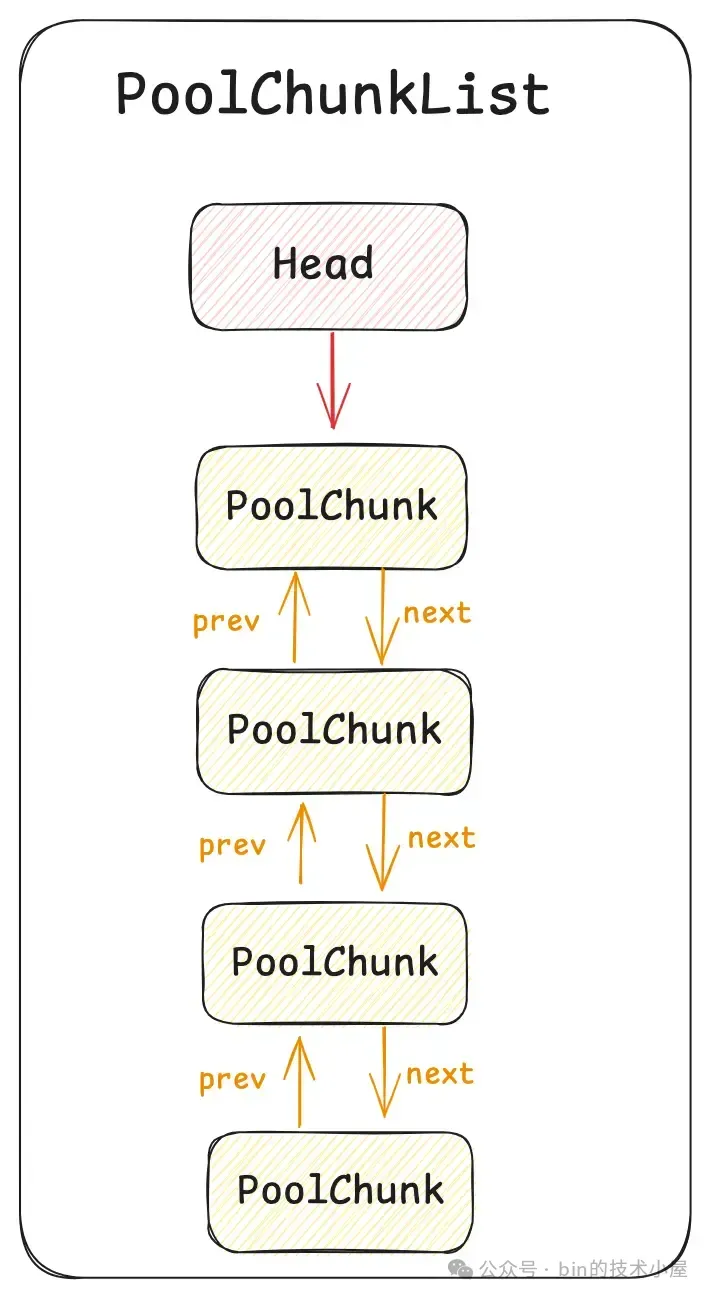
但这还不是 PoolArena 的完整样貌,如果 PoolArena 中只有一个 PoolChunk 的话肯定是远远不够的,因为 PoolChunk 总会有全部分配完毕的那一刻,这时 Netty 就不得不在次向 OS 申请一个新的 PoolChunk (4M),这样一来,随着时间的推移 ,PoolArena 中就会有多个 PoolChunk,那么这些 PoolChunk 在内存池中是如何被组织管理的呢 ? 这就引入了内存池的第六个模型 —— PoolChunkList 。
PoolChunkList 是一个双向链表的数据结构,它用来组织和管理 PoolArena 中的这些 PoolChunk。
但事实上,对于 PoolArena 中的这些众多 PoolChunk 来说,可能不同 PoolChunk 它们的内存使用率都是不一样的,于是 Netty 又近一步根据 PoolChunk 的内存使用率设计出了 6 个 PoolChunkList 。每个 PoolChunkList 管理着内存使用率在一定范围内的 PoolChunk。
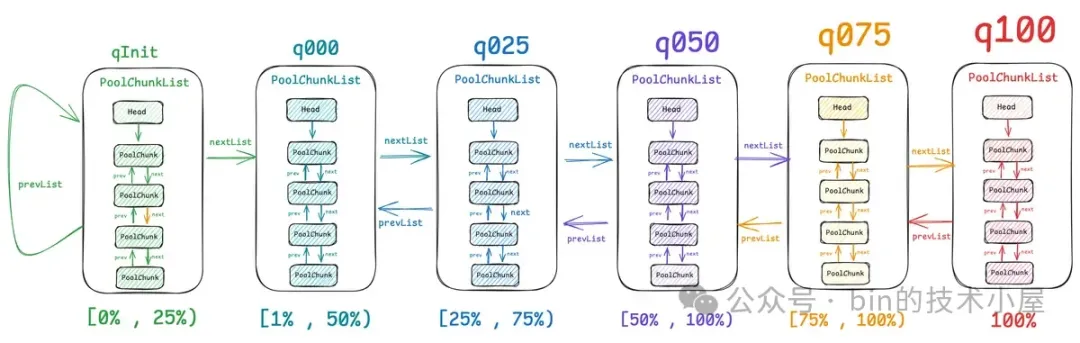
如上图所示,PoolArena 中一共有 6 个 PoolChunkList,分别是:qInit,q000,q025,q050,q075,q100。它们之间通过一个双向链表串联在一起,每个 PoolChunkList 管理着内存使用率在相同范围内的 PoolChunk :
-
qInit 顾名思义,当一个新的 PoolChunk 被创建出来之后,它就会被放到 qInit 中,该 PoolChunkList 管理的 PoolChunk 内存使用率在 [0% , 25%) 之间,当里边的 PoolChunk 内存使用率大于等于 25% 时,就会被向后移动到下一个 q000 中。
-
q000 管理的 PoolChunk 内存使用率在 [1% , 50%) 之间,当里边的 PoolChunk 内存使用率大于等于 50% 时,就会被向后移动到下一个 q025 中。当里边的 PoolChunk 内存使用率小于 1% 时,PoolChunk 就会被重新释放回 OS 中。因为 ChunkSize 是 4M ,Netty 内存池提供的最小内存块尺寸为 16 字节,当 PoolChunk 内存使用率小于 1% 时, 其实内存使用率已经就是 0% 了,对于一个已经全部释放完的 Empty PoolChunk,就需要释放回 OS 中。
-
q025 管理的 PoolChunk 内存使用率在 [25% , 75%) 之间,当里边的 PoolChunk 内存使用率大于等于 75% 时,就会被向后移动到下一个 q050 中。当里边的 PoolChunk 内存使用率小于 25% 时,就会被向前移动到上一个 q000 中。
-
q050 管理的 PoolChunk 内存使用率在 [50% , 100%) 之间,当里边的 PoolChunk 内存使用率小于 50% 时,就会被向前移动到上一个 q025 中。当里边的 PoolChunk 内存使用率达到 100% 时,直接移动到 q100 中。
-
q075 管理的 PoolChunk 内存使用率在 [75% , 100%) 之间,当里边的 PoolChunk 内存使用率小于 75% 时,就会被向前移动到上一个 q050 中。当里边的 PoolChunk 内存使用率达到 100% 时,直接移动到 q100 中。
-
q100 管理的全部都是内存使用率 100 % 的 PoolChunk,当有内存释放回 PoolChunk 之后,才会向前移动到 q075 中。
从以上内容中我们可以看出,PoolArena 中的每一个 PoolChunkList 都规定了其中 PoolChunk 的内存使用率的上限和下限,当某个 PoolChunkList 中的 PoolChunk 内存使用率低于规定的下限时,Netty 首先会将其从当前 PoolChunkList 中移除,然后移动到前一个 PoolChunkList 中。
当 PoolChunk 的内存使用率达到规定的上限时,Netty 会将其移动到下一个 PoolChunkList 中。但这里有一个特殊的设计不知大家注意到没有,就是 q000 它的 prevList 指向 NULL , 也就是说当 q000 中的 PoolChunk 内存使用率低于下限 —— 1% 时,这个 PoolChunk 并不会向前移动到 qInit 中,而是会释放回 OS 中。

qInit 的 prevList 指向的是它自己,也就是说,当 qInit 中的 PoolChunk 内存使用率为 0 % 时,这个 PoolChunk 并不会释放回 OS , 反而是继续留在 qInit 中。那为什么 q000 中的 PoolChunk 内存使用率低于下限时会释放回 OS ?而 qInit 中的 PoolChunk 反而要继续留在 qInit 中呢 ?
PoolArena 中那些刚刚新被创建出来的 PoolChunk 首先会被 Netty 添加到 qInit 中,如果该 PoolChunk 的内存使用率一直稳定在 0% 到 25% 之间的话,那么它将会一直停留在 qInit 中,直到内存使用率达到 25% 才会被移动到下一个 q000 中。
如果内存使用不那么频繁,PoolChunk 的内存使用率会慢慢的降到 0% , 但是此时我们不能释放它,而是应该让它继续留在 qInit 中,因为如果一旦释放,下一次需要内存的时候还需要在重新创建 PoolChunk,所以为了避免 PoolChunk 的重复创建,我们需要保证内存池 PoolArena 中始终至少有一个 PoolChunk 可用。
如果内存使用比较频繁,q000 中的 PoolChunk 内存使用率会慢慢达到 50% ,随后它会被移动到下一个 q025 中,随着内存使用率越来越高,达到 75% 之后,它又会被移动到 q050 中,随着内存继续的频繁申请,最终 PoolChunk 被移动了 q100 中。
在内存频繁使用的场景下,这个 PoolChunk 大概率会一直停留在 q050 或者 q075 中,但如果随着内存使用的热度降低,PoolChunk 会慢慢的向前移动直到进入到 q000 , 这时如果内存还在持续释放,那么这个 PoolChunk 的内存使用率慢慢的就会低于 1% 。
这种情况下,Netty 就会认为此时内存的申请并不频繁,没必要让它一直停留在内存池中,直接将它释放回 OS 就好。用的多了我就多存点,用的少了我就少存点,减少内存池带来的不必要内存消耗。
以上是笔者要为大家介绍的 Netty 针对 PoolChunkList 的第一个设计,下面我们继续来看第二个设计,当我们向内存池 PoolArena 申请内存的时候,进入到 PoolArena 内部之后,就会发现,我们同时面对的是 5 个都可提供内存分配的 PoolChunkList,它们分别是 qInit [0% , 25%) ,q000 [1% , 50%),q025 [25% , 75%),q050 [50% , 100%) ,q075 [75% , 100%) 。那我们到底该选择哪个 PoolChunkList 进行内存分配呢 ? 也就是说这五个 PoolChunkList 的优先级我们该如何抉择 ?
Netty 选择的内存分配顺序是:q050 > q025 > q000 > qInit > q075 , 那为什么这样设计呢 ?
abstract class PoolArena<T> {
// 分配 Page 级别的内存块
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) {
assert lock.isHeldByCurrentThread();
// PoolChunkList 内存分配的优先级:q050 > q025 > q000 > qInit > q075
if (q050.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q025.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q000.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
qInit.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q075.allocate(buf, reqCapacity, sizeIdx, threadCache)) {
return;
}
// 5 个 PoolChunkList 中没有可用的 PoolChunk,重新向 OS 申请一个新的 PoolChunk(4M)
PoolChunk<T> c = newChunk(sizeClass.pageSize, sizeClass.nPSizes, sizeClass.pageShifts, sizeClass.chunkSize);
// 从新的 PoolChunk 中分配内存
boolean success = c.allocate(buf, reqCapacity, sizeIdx, threadCache);
assert success;
// 将刚刚创建的 PoolChunk 加入到 qInit 中
qInit.add(c);
}
}
这里有四点核心设计原则需要考虑:
-
Netty 需要尽量控制内存的消耗,尽可能用少量的 PoolChunk 满足大量的内存分配需求,避免创建新的 PoolChunk,提高每个 PoolChunk 的内存使用率。
-
而对于现有的 PoolChunk 来说,Netty 则需要尽量避免将其回收,让它的服务周期尽可能长一些。
-
在此基础之上,Netty 需要兼顾内存分配的性能。
-
Netty 需要在内存池的整个生命周期中,从总体上做到让 PoolArena 中的这些 PoolChunk 尽量均衡地承担内存分配的工作,做到雨露均沾。
那么 Netty 采用这样的分配顺序 —— q050 > q025 > q000 > qInit > q075 ,如何保证上述四点核心设计原则呢 ?
首先前面我们已经分析过了,在内存频繁使用的场景中,内存池 PoolArena 中的 PoolChunks 大概率会集中停留在 q050 和 q075 这两个 PoolChunkList 中。由于 q050 和 q075 中集中了大量的 PoolChunks,所以我们肯定会先从这两个 PoolChunkList 查找,一下子就能找到一个 PoolChunk,保证了第三点原则 —— 内存分配的性能。
而 q075 中的 PoolChunk 内存使用率已经很高了,在 75% 到 100% 之间,很可能容量不能满足内存分配的需求导致申请内存失败,所以我们优先从 q050 开始。
由于 q050 [50% , 100%) 中同样集中了大量的 PoolChunks,优先从 q050 开始分配可以做到尽可能的使用现有的 PoolChunk,避免了这些 PoolChunk 由于长期不被使用而被释放回 OS , 保证了第二点设计原则。
当 q050 中没有 PoolChunk 时,同样是根据第二点设计原则,Netty 需要尽量优先选择内存使用率高的 PoolChunk,所以优先从 q025 [25% , 75%) 进行分配。q025 中没有则优先从 q000 [1% , 50%) 中分配,尽量避免 PoolChunk 的回收。
当 q000 中没有 PoolChunk 时,那说明此时内存池中的内存容量已经不太够了,但是根据第一点设计原则,在这种情况下,仍然需要避免创建新的 PoolChunk,所以下一个优先选择的 PoolChunkList 应该是 qInit [0% , 25%) ,而前面我们也介绍过了,Netty 设计 qInit 的目的就是为了避免频繁创建不必要的 PoolChunk。
当 qInit 没有 PoolChunk 时,仍然不会贸然创建新的 PoolChunk,而是到 q075 中去寻找 PoolChunk 。之所以最后才轮到 q075,这是为了保证第四点设计原则,因为 q075 中的内存使用率已经很高了,为了总体上保证 PoolChunk 均衡地承担内存分配的工作,所有优先到其他内存使用率相对较低的 PoolChunkList 中分配。
以上是笔者要为大家介绍的 Netty 针对 PoolChunkList 的第二个设计,下面我们接着来看第三个设计。大家可能注意到,PoolArena 中的这六个 PoolChunkList 在内存使用率区间的设计上有很多重叠的部分,比如内存使用率是 30% 的 PoolChunk 既可以在 q000 中也可以在 q025 中,55% 既可以在 q025 中也可以在 q050 中,Netty 为什么要将 PoolChunkList 的内存使用率区间设计成这么多的重叠区间 ? 为什么不设计成恰好连续衔接的区间呢 ?
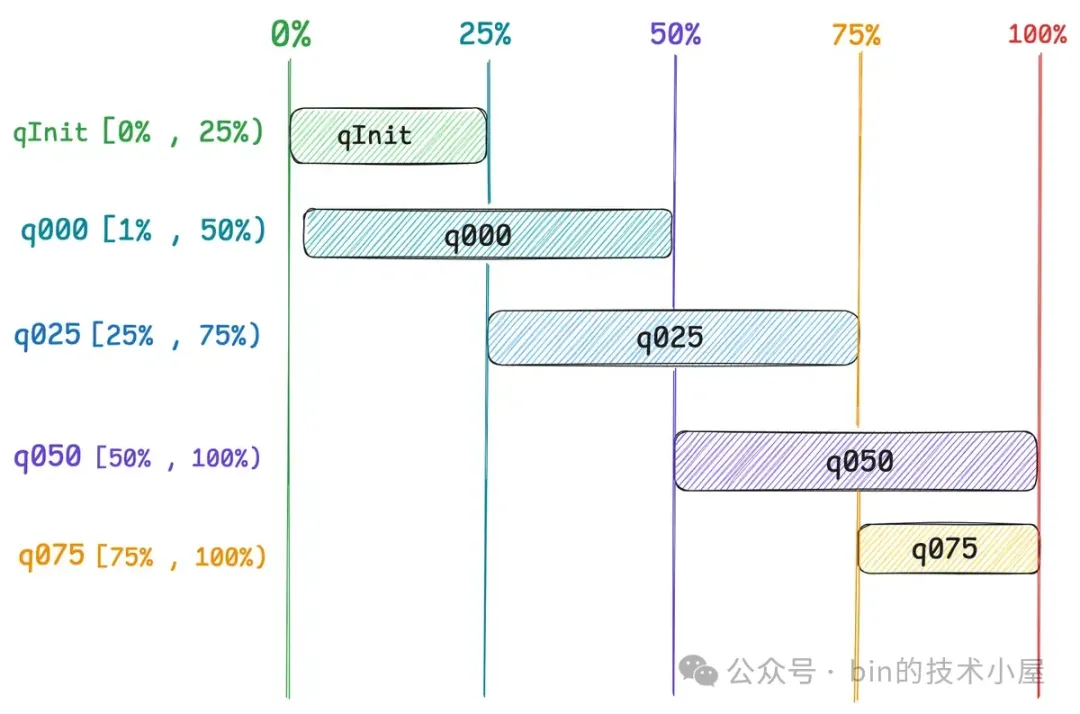
我们可以反过来思考一下,假如 Netty 将 PoolChunkList 的内存使用率区间设计成恰好连续衔接的区间,那么会发生什么情况 ?
我们现在拿 q025 和 q050 这两个 PoolChunkList 举例说明,假设现在我们将 q025 的内存使用率区间设计成 [25% , 50%) , q050 的内存使用率区间设计成 [50% , 75%),这样一来,q025 , q050 , q075 这三个 PoolChunkList 的内存使用率区间的上限和下限就是恰好连续衔接的了。
那么随着 PoolChunk 中内存的申请与释放,会导致 PoolChunk 的内存使用率在不断的发生变化,假设现在有一个 PoolChunk 的内存使用率是 45% ,当前停留在 q025 中,当分配内存之后,内存使用率上升至 50% ,那么该 PoolChunk 就需要立即移动到 q050 中。
当释放内存之后,这个刚刚移动到 q050 中的 PoolChunk,它的内存使用率下降到 49% ,那么又会马不停蹄地移动到 q025 ,也就是说只要这个 PoolChunk 的内存使用率在 q025 与 q050 的交界处 50% 附近来回徘徊的话,每次的内存申请与释放都会导致这个 PoolChunk 在 q025 与 q050 之间不停地来回移动。
同样的道理,只要一个 PoolChunk 的内存使用率在 75% 左右来回徘徊的话,那么每次内存的申请与释放也都会导致这个 PoolChunk 在 q050 与 q075 之间不停地来回移动,这样会造成一定的性能下降。
但是如果各个 PoolChunkList 之间的内存使用率区间设计成重叠区间的话,那么 PoolChunk 的可调节范围就会很广,不会频繁地在前后不同的 PoolChunkList 之间来回移动。
我们还是拿 q025 [25% , 75%) 和 q050 [50% , 100%) 来举例说明,现在 q025 中有一个内存使用率为 45% 的 PoolChunk , 当分配内存之后,内存使用率上升至 50% ,该 PoolChunk 仍然会继续停留在 q025 中,后续随着内存分配的不断进行,当内存使用率达到 75% 的时候才会移动到 q050 中。
还是这个 PoolChunk , 当释放内存之后,PoolChunk 的使用率下降到了 70%,那么它仍然会停留在 q050 中,后续随着内存释放的不断进行,当内存使用率低于 50% 的时候才会移动到 q025 中。这种重叠区间的设计有效的避免了 PoolChunk 频繁的在两个 PoolChunkList 之间来回移动。
好了,到现在为止,我们已经明白了内存池所有的核心组件设计,基于本小节中介绍的 6 个模型:PoolArena,PoolThreadCache,SizeClasses,PoolChunk ,PoolSubpage,PoolChunkList 。我们可以得出内存池的完整架构如下图所示:

2. Netty 内存池的创建与初始化
在清楚了内存池的总体架构设计之后,本小节我们就来看一下整个内存池的骨架是如何被创建出来的,Netty 将整个内存池的实现封装在 PooledByteBufAllocator 类中。
public class PooledByteBufAllocator {
public static final PooledByteBufAllocator DEFAULT =
new PooledByteBufAllocator(PlatformDependent.directBufferPreferred());
}
创建内存池所需要的几个核心参数我们需要提前了解下:
-
preferDirect 默认为 true , 用于指定该 Allocator 是否偏向于分配 Direct Memory,其值由
PlatformDependent.directBufferPreferred()方法决定,相关的判断逻辑可以回看下 《聊一聊 Netty 数据搬运工 ByteBuf 体系的设计与实现》 一文中的第三小节。 -
nHeapArena , nDirectArena 用于指定内存池中包含的 HeapArena , DirectArena 个数,它们分别用于池化 Heap Memory 以及 Direct Memory 。默认个数分别为
availableProcessors * 2, 可由参数-Dio.netty.allocator.numHeapArenas和-Dio.netty.allocator.numDirectArenas指定。 -
pageSize 默认为 8K ,用于指定内存池中的 Page 大小。可由参数
-Dio.netty.allocator.pageSize指定,但不能低于 4K 。 -
maxOrder 默认为 9 , 用于指定内存池中 PoolChunk 尺寸,默认 4M ,由
pageSize << maxOrder计算得出。可由参数-Dio.netty.allocator.maxOrder指定,但不能超过 14 。 -
smallCacheSize 默认 256 , 可由参数
-Dio.netty.allocator.smallCacheSize指定,用于表示每一个 small 内存规格尺寸可以在 PoolThreadCache 中缓存的 small 内存块个数。 -
normalCacheSize 默认 64 , 可由参数
-Dio.netty.allocator.normalCacheSize指定,用于表示每一个 Normal 内存规格尺寸可以在 PoolThreadCache 中缓存的 Normal 内存块个数。 -
useCacheForAllThreads 默认为 false , 可由参数
-Dio.netty.allocator.useCacheForAllThreads指定。用于表示是否为所有线程创建 PoolThreadCache。 -
directMemoryCacheAlignment 默认为 0 ,可由参数
-Dio.netty.allocator.directMemoryCacheAlignment指定 , 用于表示内存池中内存块尺寸的对齐粒度。
private final PoolThreadLocalCache threadCache;
private final int smallCacheSize;
private final int normalCacheSize;
private final int chunkSize;
// 保存所有 DirectArena
private final PoolArena<ByteBuffer>[] directArenas;
public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder,
int smallCacheSize, int normalCacheSize,
boolean useCacheForAllThreads, int directMemoryCacheAlignment) {
// 默认偏向于分配 Direct Memory
super(preferDirect);
// 创建 PoolThreadLocalCache ,后续用于将线程与 PoolArena 绑定
// 并为线程创建 PoolThreadCache
threadCache = new PoolThreadLocalCache(useCacheForAllThreads);
// PoolThreadCache 中,针对每一个 Small 规格的尺寸可以缓存 256 个内存块
this.smallCacheSize = smallCacheSize;
// PoolThreadCache 中,针对每一个 Normal 规格的尺寸可以缓存 64 个内存块
this.normalCacheSize = normalCacheSize;
// PoolChunk 的尺寸
// pageSize << maxOrder = 4M
chunkSize = validateAndCalculateChunkSize(pageSize, maxOrder);
// 13 , pageSize 为 8K
int pageShifts = validateAndCalculatePageShifts(pageSize, directMemoryCacheAlignment);
// 依次创建 nDirectArena 个 DirectArena(省略 HeapArena)
if (nDirectArena > 0) {
// 创建 PoolArena 数组,个数为 2 * processors
directArenas = newArenaArray(nDirectArena);
// 划分内存规格,建立内存规格索引表
final SizeClasses sizeClasses = new SizeClasses(pageSize, pageShifts, chunkSize,
directMemoryCacheAlignment);
// 初始化 PoolArena 数组
for (int i = 0; i < directArenas.length; i ++) {
// 创建 DirectArena
PoolArena.DirectArena arena = new PoolArena.DirectArena(this, sizeClasses);
// 保存在 directArenas 数组中
directArenas[i] = arena;
}
} else {
directArenas = null;
}
}
当我们明白了内存池的总体架构之后,再来看内存池的创建过程就会觉得非常简单了,核心点主要有三个:
首先会创建 PoolThreadLocalCache,它是一个 FastThreadLocal 类型的成员变量,主要作用是用于后续实现线程与 PoolArena 之间的绑定,并为线程创建本地缓存 PoolThreadCache。
private final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
private final boolean useCacheForAllThreads;
PoolThreadLocalCache(boolean useCacheForAllThreads) {
this.useCacheForAllThreads = useCacheForAllThreads;
}
@Override
protected synchronized PoolThreadCache initialValue() {
实现线程与 PoolArena 之间的绑定
为线程创建本地缓存 PoolThreadCache
}
}
其次是根据 nDirectArena 的个数,创建 PoolArena 数组,用于保存内存池中所有的 PoolArena。
private static <T> PoolArena<T>[] newArenaArray(int size) {
return new PoolArena[size];
}
随后会创建 SizeClasses , Netty 内存规格的划分就是在这里进行的,上一小节中展示的 Netty 内存规格索引表就是在这里创建的。这一块的内容比较多,笔者放在下一小节中介绍。
最后根据 SizeClasses 创建 nDirectArena 个 PoolArena 实例,并依次保存在 directArenas 数组中。内存池的创建核心关键在于创建 PoolArena 结构,PoolArena 中管理了 Small 规格的内存块与 PoolChunk。其中管理 Small 规格内存块的数据结构是 smallSubpagePools 数组,管理 PoolChunk 的数据结构是六个 PoolChunkList ,分别按照不同的内存使用率进行划分。
abstract class PoolArena<T> {
// Small 规格的内存块组织在这里,类似内核的 kmalloc
final PoolSubpage<T>[] smallSubpagePools;
// 按照不同内存使用率组织 PoolChunk
private final PoolChunkList<T> q050; // [50% , 100%)
private final PoolChunkList<T> q025; // [25% , 75%)
private final PoolChunkList<T> q000; // [1% , 50%)
private final PoolChunkList<T> qInit; // [0% , 25%)
private final PoolChunkList<T> q075; // [75% , 100%)
private final PoolChunkList<T> q100; // 100%
protected PoolArena(PooledByteBufAllocator parent, SizeClasses sizeClass) {
// PoolArena 所属的 PooledByteBufAllocator
this.parent = parent;
// Netty 内存规格索引表
this.sizeClass = sizeClass;
// small 内存规格将会在这里分配 —— 类似 kmalloc
// 每一种 small 内存规格都会对应一个 PoolSubpage 链表(类似 slab)
smallSubpagePools = newSubpagePoolArray(sizeClass.nSubpages);
for (int i = 0; i < smallSubpagePools.length; i ++) {
// smallSubpagePools 数组中的每一项是一个带有头结点的 PoolSubpage 结构双向链表
// 双向链表的头结点是 SubpagePoolHead
smallSubpagePools[i] = newSubpagePoolHead(i);
}
// 按照不同内存使用率范围划分 PoolChunkList
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, sizeClass.chunkSize);// [100 , 2147483647]
q075 = new PoolChunkList<T>(this, q100, 75, 100, sizeClass.chunkSize);
q050 = new PoolChunkList<T>(this, q075, 50, 100, sizeClass.chunkSize);
q025 = new PoolChunkList<T>(this, q050, 25, 75, sizeClass.chunkSize);
q000 = new PoolChunkList<T>(this, q025, 1, 50, sizeClass.chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, sizeClass.chunkSize);// [-2147483648 , 25]
// 双向链表组织 PoolChunkList
// 其中比较特殊的是 q000 的前驱节点指向 NULL
// qInit 的前驱节点指向它自己
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
}
}
首先就是创建 smallSubpagePools 数组,数组中的每一个元素是一个带有头结点的 PoolSubpage 类型的双向循环链表结构,PoolSubpage 类似内核中的 slab ,其中管理着对应 Small 规格的小内存块。
Netty 内存池中一共设计了 39 个 Small 规格尺寸 —— [16B , 28k],所以 smallSubpagePools 数组的长度就是 39 (sizeClass.nSubpages),数组中的每一项负责管理一种 Small 规格的内存块。
private PoolSubpage<T>[] newSubpagePoolArray(int size) {
return new PoolSubpage[size];
}
smallSubpagePools 数组中保存就是对应 Small 规格尺寸的 PoolSubpage 链表的头结点 SubpagePoolHead。在内存池刚被创建出来的时候,链表中还是空的,只有一个头结点。
private PoolSubpage<T> newSubpagePoolHead(int index) {
PoolSubpage<T> head = new PoolSubpage<T>(index);
head.prev = head;
head.next = head;
return head;
}
随后 Netty 会按照 PoolChunk 的不同内存使用率范围划分出六个 PoolChunkList :qInit [0% , 25%) ,q000 [1% , 50%),q025 [25% , 75%),q050 [50% , 100%) ,q075 [75% , 100%),q100 [100%]。它们分别管理着不同内存使用率的 PoolChunk。由于现在内存池刚刚被创建出来,所以这些 PoolChunkList 中还是空的,
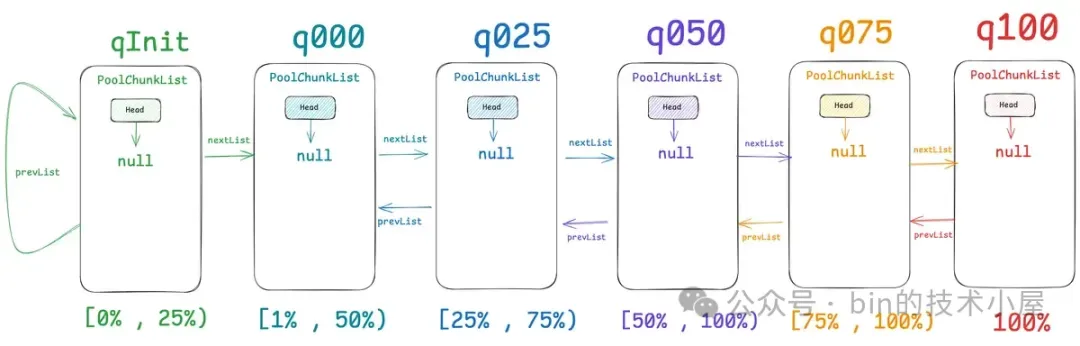
这些 PoolChunkLists 通过双向链表的结构相互串联起来,其中比较特殊的是 q000 和 qInit。 q000 它的前驱节点 prevList 指向 NULL ,目的是当 q000 中的 PoolChunk 内存使用率低于 1% 时,Netty 就会将其释放回 OS , 不会继续向前移动到 qInit 中,减少不必要的内存消耗。
qInit 它的前驱节点 prevList 指向它自己,这么做的目的是,使得内存使用率低于 25% 的 PoolChunk 能够一直停留在 qInit 中,避免后续需要内存的时候还需要在重新创建 PoolChunk。
现在一个完整的内存池就被我们创建出来了,但此时它还只是一个基本的骨架,内存池里面的 PoolArena 还没有和任何线程进行绑定,线程中的本地缓存 PoolThreadCache 还是空的。PoolArena 中的 smallSubpagePools 以及六个 PoolChunkLists 里也都是空的。
在后面的小节中,笔者将基于这个基本的骨架,让内存池动态地运转起来,一步一步丰满填充里面的内容。但内存池运转的核心是围绕着对 Small 规格以及 Normal 规格内存块的管理进行的。
所以在核心内容开始之前,我们需要知道 Netty 究竟是如何划分这些不同规格尺寸的内存块的。
3. Netty 内存规格的划分
如上图所示,Netty 的内存规格从 16B 到 4M 一共划分成了 68 种规格,内存规格表在 Netty 中使用了一个二维数组来存储。
short[][] sizeClasses
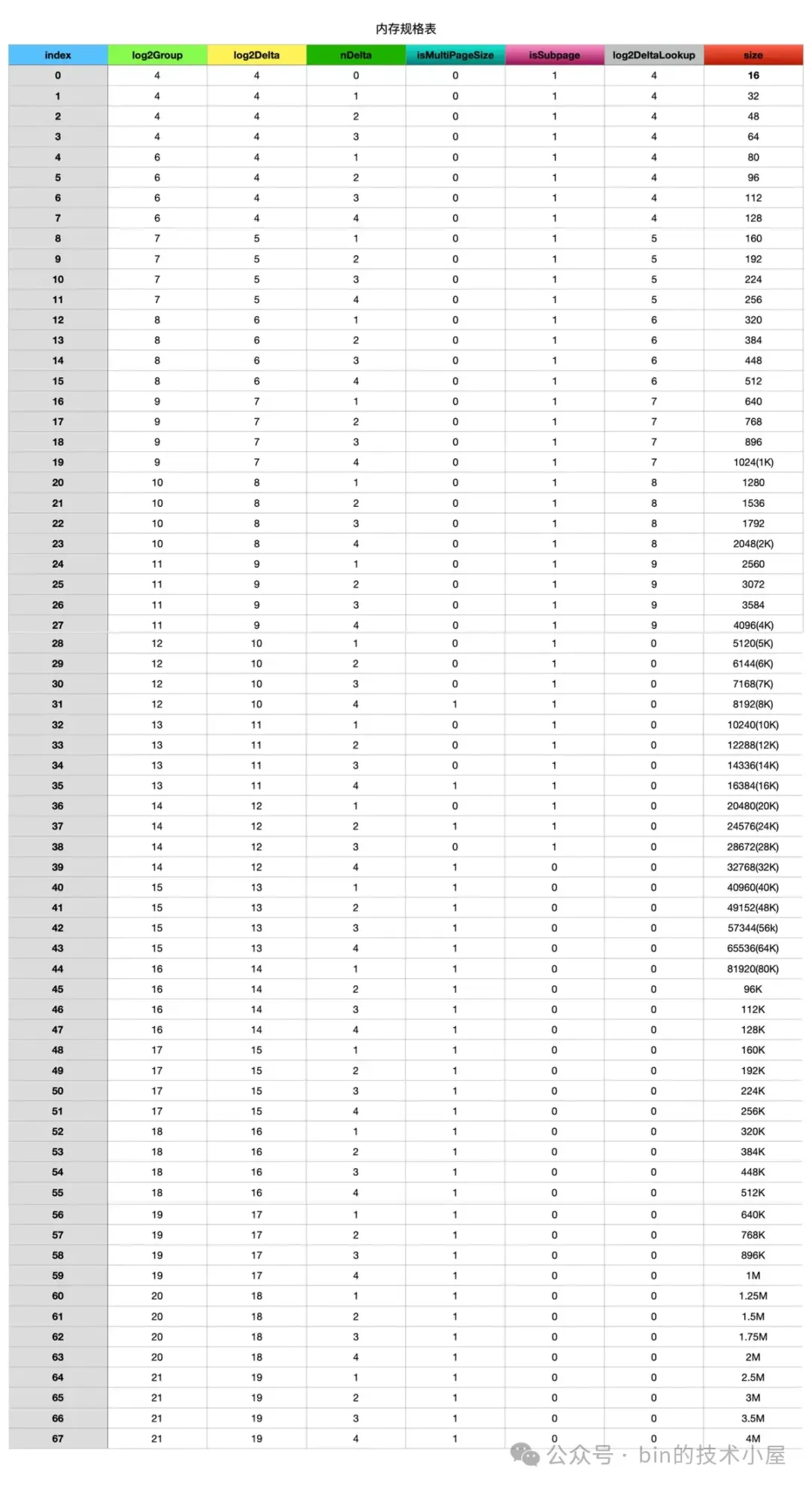
其中第一维是按照内存规格的粒度来存储每一种内存规格,一共有 68 种规格,一维数组的大小也是 68 。第二维存储的是每一种内存规格的详细信息,一共有 7 列,分别是 index,log2Group,log2Delta,nDelta,isMultiPageSize,isSubpage,log2DeltaLookup。
private static final int LOG2GROUP_IDX = 1;
private static final int LOG2DELTA_IDX = 2;
private static final int NDELTA_IDX = 3;
private static final int PAGESIZE_IDX = 4;
private static final int SUBPAGE_IDX = 5;
private static final int LOG2_DELTA_LOOKUP_IDX = 6;
其中 index 表示每一种内存规格在 sizeClasses 中的索引,从 0 到 67 表示 68 种内存规格。
后面的 log2Group ,log2Delta,nDelta 都是为了计算对应的内存规格 size 而设计的,计算公式如下:
private static int calculateSize(int log2Group, int nDelta, int log2Delta) {
return (1 << log2Group) + (nDelta << log2Delta);
}
Netty 按照 log2Group 将内存规格表中的 68 种规格一共分成了 17 组,每组 4 个规格,log2Group 用于表示在同一个内存规格组内的 4 个规格的基准 size —— base size 的对数, 后续规格 size 将会在 base size (1 << log2Group)的基础上进行扩充。
那么如何扩充呢 ?这就用到了 log2Delta 和 nDelta,每一个内存规格与其上一个规格的差值为 1 << log2Delta,同一个内存规格组内的规格相当于是一个等差数列(log2Delta 都是相同的)。Netty 会按照 log2Delta 的倍数对内存规格进行扩充,那么扩充多少倍呢 ? 这个就是 nDelta。
所以一个内存规格 size 的计算方式就是基准 size (1 << log2Group) 加上扩充的大小(nDelta << log2Delta)。下面笔者用第一个内存规格组 [16B, 32B, 48B , 64B] 进行具体说明:

首先第一个内存规格组的 log2Group 为 4 ,它的基准 size = 1 << log2Delta = 16B。log2Delta 为 4 ,表示组内的 4 个内存规格之间的差值为 1 << log2Delta = 16B。
好了,接下来我们看第一个内存规格组内每一种规格的计算方式,Netty 内存池的第一个内存规格是 16B , 由于它是第一个规格,所以 nDelta 为 0 ,我们通过公式 (1 << log2Group) + (nDelta << log2Delta) = (1 << 4) + (0 << 4) 得出第一个内存规格 size 为 16B。
后续其他内存规格组内第一个规格的 nDelta 均是为 1 。
第二个内存规格是 32B , 它对应的 nDelta 为 1,规格 size = (1 << 4) + (1 << 4) = 32。
第三个内存规格是 48B , 它对应的 nDelta 为 2,规格 size = (1 << 4) + (2 << 4) = 48。
第四个内存规格是 64B , 它对应的 nDelta 为 3,规格 size = (1 << 4) + (3 << 4) = 64。
每一个内存规格组内的最后一个规格 size 恰好都是 2 的次幂 。同时它也是下一个内存规格组的 log2Group = log2(size) 。
sizeClasses 中的 isMultiPageSize 表示该内存规格是否是 Page(8k) 的倍数,用于后续索引 Page 级别的内存规格。isSubpage 表示该内存规格的内存块是否由 PoolSubpage 进行管理,从内存规格表 sizeClasses 中我们可以看出,Small 规格 [16B , 28k] 范围内的内存规格,它们的 isSubpage 全都是 true 。
log2DeltaLookup 的用处不大,这里大家可以忽略,4K 以下的内存规格,它们的 log2DeltaLookup 就是 log2Delta, 4K 以上的内存规格,它们的 log2DeltaLookup 都是 0 。这个设计主要是后面用来建立内存规格 size 与其对应的 index 之间的映射索引表 —— size2idxTab。
它的作用就是给定一个内存尺寸 size ,返回其对应的内存规格 index 。内存尺寸在 4K 以下直接查找 size2idxTab,4K 以上通过计算得出。这里大家只做简单了解即可,后面笔者会介绍这部分的计算逻辑。
好了,现在我们已经看懂了这张 SizeClasses 内存规格表,接下来我们就来看一下 SizeClasses 是如何被构建出来的。
final class SizeClasses {
// 第一种内存规格的基准 size —— 16B
// 以及第一个内存规格增长间距 —— 16B
static final int LOG2_QUANTUM = 4;
// 每个内存规格组内,规格的个数 —— 4 个
private static final int LOG2_SIZE_CLASS_GROUP = 2;
// size2idxTab 中索引的最大内存规格 —— 4K
private static final int LOG2_MAX_LOOKUP_SIZE = 12;
}
我们在内存规格表中看到的第一组内存规格基准 size —— 16B , 以及第一种内存规格的增长间隔 —— 16B ,就是由 LOG2_QUANTUM 常量决定的。
内存规格表中一共分为了 17 组内存规格,每组包含的规格个数由 LOG2_SIZE_CLASS_GROUP 决定。
// 22 - 4 -2 + 1 = 17
int group = log2(chunkSize) - LOG2_QUANTUM - LOG2_SIZE_CLASS_GROUP + 1;
size2idxTab 中索引的最大内存规格是由 LOG2_MAX_LOOKUP_SIZE 决定的,如果给定的内存尺寸小于等于 1 << LOG2_MAX_LOOKUP_SIZE,那么直接查找 size2idxTab 获取其对应的内存规格 index。内存尺寸大于 1 << LOG2_MAX_LOOKUP_SIZE,则通过计算得出对应的 index , 不会建立这部分索引。
SizeClasses(int pageSize, int pageShifts, int chunkSize, int directMemoryCacheAlignment) {
// 一共分为 17 个内存规格组
int group = log2(chunkSize) - LOG2_QUANTUM - LOG2_SIZE_CLASS_GROUP + 1;
// 创建内存规格表 sizeClasses
// 每个内存规格组内有 4 个规格,一共 68 个内存规格,一维数组长度为 68
// 二维数组的长度为 7
// 保存的内存规格信息为:index, log2Group, log2Delta, nDelta, isMultiPageSize, isSubPage, log2DeltaLookup
short[][] sizeClasses = new short[group << LOG2_SIZE_CLASS_GROUP][7];
int normalMaxSize = -1;
// 内存规格 index , 初始为 0
int nSizes = 0;
// 内存规格 size
int size = 0;
// 第一组内存规格的基准 size 为 16B
int log2Group = LOG2_QUANTUM;
// 第一组内存规格之间的间隔为 16B
int log2Delta = LOG2_QUANTUM;
// 每个内存规格组内限定为 4 个规格
int ndeltaLimit = 1 << LOG2_SIZE_CLASS_GROUP;
// 初始化第一个内存规格组 [16B , 64B],nDelta 从 0 开始
for (int nDelta = 0; nDelta < ndeltaLimit; nDelta++, nSizes++) {
// 初始化对应内存规格的 7 个信息
short[] sizeClass = newSizeClass(nSizes, log2Group, log2Delta, nDelta, pageShifts);
// nSizes 为该内存规格的 index
sizeClasses[nSizes] = sizeClass;
// 通过 sizeClass 计算该内存规格的 size ,然后将 size 向上对齐至 directMemoryCacheAlignment 的最小整数倍
size = sizeOf(sizeClass, directMemoryCacheAlignment);
}
// 每个内存规格组内的最后一个规格,往往是下一个内存规格组的基准 size
// 比如第一个内存规格组内最后一个规格 64B , 它是第二个内存规格组的基准 size
// 4 + 2 = 6,第二个内存规格组的基准 size 为 64B
log2Group += LOG2_SIZE_CLASS_GROUP;
// 初始化剩下的 16 个内存规格组
// 后一个内存规格组的 log2Group,log2Delta 比前一个内存规格组的 log2Group ,log2Delta 多 1
for (; size < chunkSize; log2Group++, log2Delta++) {
// 每个内存规格组内的 nDelta 从 1 到 4 ,最大内存规格不能超过 chunkSize(4M)
for (int nDelta = 1; nDelta <= ndeltaLimit && size < chunkSize; nDelta++, nSizes++) {
// 初始化对应内存规格的 7 个信息
short[] sizeClass = newSizeClass(nSizes, log2Group, log2Delta, nDelta, pageShifts);
// nSizes 为该内存规格的 index
sizeClasses[nSizes] = sizeClass;
size = normalMaxSize = sizeOf(sizeClass, directMemoryCacheAlignment);
}
}
// 最大内存规格不能超过 chunkSize(4M)
// 超过 4M 就是 Huge 内存规格,直接分配不进行池化管理
assert chunkSize == normalMaxSize;
...... 省略 ......
}
本小节一开始贴出来的那张内存规格表就是通过上面这段代码创建出来的,创建逻辑不算太复杂。首先创建一个空的二维数组 —— sizeClasses,后续用它来保存内存规格信息。
Netty 将 chunkSize(4M)一共分为了 17 组,每组 4 个规格,一共 68 种内存规格,所以 sizeClasses 的一维数组大小就是 68,保存每一个内存规格信息。二维数组大小是 7, 也就是上面笔者介绍的 7 种具体的内存规格信息。
short[][] sizeClasses = new short[group << LOG2_SIZE_CLASS_GROUP][7];
首先在第一个 for 循环中初始化第一个内存规格组,它的起始 log2Group,log2Delta 为 4,也就是说第一个内存规格组内的基准 size 为 16B , 组内规格之间的差值为 16B ,由于是第一组内存规格,所以 nDelta 从 0 开始递增。

接着在第二个双重 for 循环中初始化剩下的 16 组内存规格,从 80B 一直到 4M 。Netty 在划分内存规格的时候有一个特点,就是每个内存规格组内最后一个规格 size 一定是 2 的次幂,同时它也是下一个内存规格组的基准 size 。
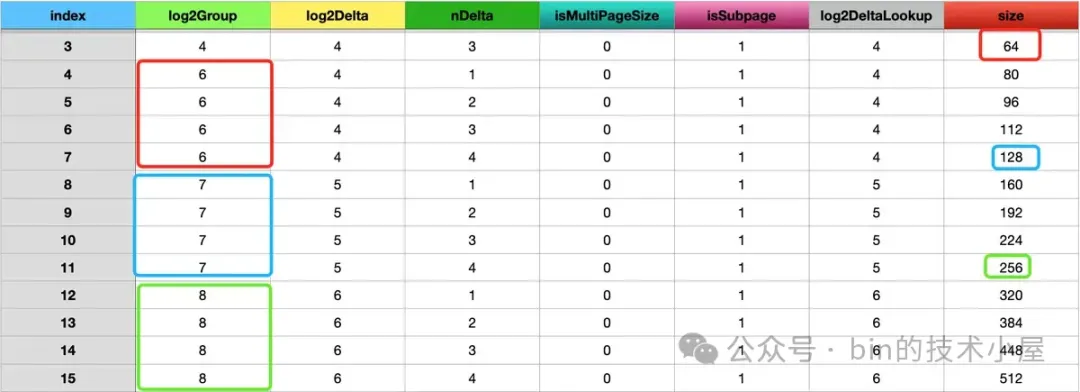
比如第一个内存规格组内最后一个规格为 64B , 那么第二个内存规格组的 log2Group 就应该是 6 。也就是从基准 size —— 64B 开始扩充组内的规格。
// 4 + 2 = 6
log2Group += LOG2_SIZE_CLASS_GROUP;
除去第一组内存规格之外,我们看到剩下的 16 组内存规格,后一个内存规格组内的 log2Group 往往比前一个内存规格组的 log2Group 多 1 。也就是说内存规格组的基准 size 是按照 2 倍递增。以 64B , 128B , … ,1M , 2M 这样递增。
同时后一个内存规格组内的 log2Delta 往往比前一个内存规格组的 log2Delta 多 1 。也就是不同内存规格组内规格之间的差值也是按照 2 倍递增。规格之间的间距分别按照 16B , 32B , 64B ,… , 0.25M , 0.5M 这样递增。但同一内存规格组内的差值永远都是相同的。
现在我们已经清楚了内存规格组的划分逻辑,那么具体的内存规格信息是如何初始化的呢 ?这部分逻辑在 newSizeClass 函数中实现。
private static short[] newSizeClass(int index, int log2Group, int log2Delta, int nDelta, int pageShifts) {
// 判断规格尺寸是否是 Page 的整数倍
short isMultiPageSize;
if (log2Delta >= pageShifts) {
// 尺寸按照 Page 的倍数递增了,那么一定是 Page 的整数倍
isMultiPageSize = yes;
} else {
int pageSize = 1 << pageShifts;
// size = 1 << log2Group + nDelta * (1 << log2Delta)
int size = calculateSize(log2Group, nDelta, log2Delta);
// 是否能被 pagesize(8k) 整除
isMultiPageSize = size == size / pageSize * pageSize? yes : no;
}
// 规格尺寸小于 32K ,那么就属于 Small 规格,对应的内存块会被 PoolSubpage 管理
short isSubpage = log2Size < pageShifts + LOG2_SIZE_CLASS_GROUP? yes : no;
// 如果内存规格 size 小于等于 MAX_LOOKUP_SIZE(4K),那么 log2DeltaLookup 为 log2Delta
// 如果内存规格 size 大于 MAX_LOOKUP_SIZE(4K),则为 0
// Netty 只会为 4K 以下的内存规格建立 size2idxTab 索引
int log2DeltaLookup = log2Size < LOG2_MAX_LOOKUP_SIZE ||
log2Size == LOG2_MAX_LOOKUP_SIZE && remove == no
? log2Delta : no;
// 初始化内存规格信息
return new short[] {
(short) index, (short) log2Group, (short) log2Delta,
(short) nDelta, isMultiPageSize, isSubpage, (short) log2DeltaLookup
};
}
现在整个内存规格表就算初始化完了,后面的工作比较简单,就是遍历内存规格表,初始化一些统计信息,比如:
-
nPSizes,表示 Page 级别的内存规格个数,一共有 32 个 Page 级别的内存规格。
-
nSubpages , 表示 Small 内存规格的个数,从 16B 到 28K 一共 39 个
。 -
smallMaxSizeIdx ,最大的 Small 内存规格对应的 index 。 Small 内存规格中的最大尺寸为 28K ,对应的 sizeIndex = 38。
-
lookupMaxSize , 表示 size2idxTab 中索引的最大尺寸为 4K 。
// Small 规格中最大的规格尺寸对应的 index (38)
int smallMaxSizeIdx = 0;
// size2idxTab 中最大的 lookup size (4K)
int lookupMaxSize = 0;
// Page 级别内存规格的个数(32)
int nPSizes = 0;
// Small 内存规格的个数(39)
int nSubpages = 0;
// 遍历内存规格表 sizeClasses,统计 nPSizes , nSubpages,smallMaxSizeIdx,lookupMaxSize
for (int idx = 0; idx < nSizes; idx++) {
short[] sz = sizeClasses[idx];
// 只要 size 可以被 pagesize 整除,那么就属于 MultiPageSize
if (sz[PAGESIZE_IDX] == yes) {
nPSizes++;
}
// 只要 size 小于 32K 则为 Subpage 的规格
if (sz[SUBPAGE_IDX] == yes) {
nSubpages++;
// small 内存规格中的最大尺寸 28K ,对应的 sizeIndex = 38
smallMaxSizeIdx = idx;
}
// 内存规格小于等于 4K 的都属于 lookup size
if (sz[LOG2_DELTA_LOOKUP_IDX] != no) {
// 4K
lookupMaxSize = sizeOf(sz, directMemoryCacheAlignment);
}
}
// 38
this.smallMaxSizeIdx = smallMaxSizeIdx;
// 4086(4K)
this.lookupMaxSize = lookupMaxSize;
// 32
this.nPSizes = nPSizes;
// 39
this.nSubpages = nSubpages;
// 68
this.nSizes = nSizes;
// 8192(8K)
this.pageSize = pageSize;
// 13
this.pageShifts = pageShifts;
// 4M
this.chunkSize = chunkSize;
// 0
this.directMemoryCacheAlignment = directMemoryCacheAlignment;
现在 Netty 中所有的内存规格尺寸就已经全部确定下来了,包括 68 种内存规格,8K 的 PageSize , 4M 的 ChunkSize。接下来最后一项任务就是根据原始的内存规格表 sizeClasses 建立相关的索引表。
// sizeIndex 与 size 之间的映射
this.sizeIdx2sizeTab = newIdx2SizeTab(sizeClasses, nSizes, directMemoryCacheAlignment);
// 根据 sizeClass 生成 page 级的内存规格表
// pageIndex 到对应的 size 之间的映射
this.pageIdx2sizeTab = newPageIdx2sizeTab(sizeClasses, nSizes, nPSizes, directMemoryCacheAlignment);
// 4k 之内,给定一个 size 转换为 sizeIndex
this.size2idxTab = newSize2idxTab(lookupMaxSize, sizeClasses);
3.1 sizeIdx2sizeTab
sizeIdx2sizeTab 主要是建立内存规格 index 到对应规格 size 之间的映射,这里的 index 就是内存规格表 sizeClasses 中的 index 。
private static int[] newIdx2SizeTab(short[][] sizeClasses, int nSizes, int directMemoryCacheAlignment) {
// 68 种内存规格,映射条目也是 68
int[] sizeIdx2sizeTab = new int[nSizes];
// 遍历内存规格表,建立 index 与规格 size 之间的映射
for (int i = 0; i < nSizes; i++) {
short[] sizeClass = sizeClasses[i];
// size = 1 << log2Group + nDelta * (1 << log2Delta)
sizeIdx2sizeTab[i] = sizeOf(sizeClass, directMemoryCacheAlignment);
}
return sizeIdx2sizeTab;
}

3.2 pageIdx2sizeTab
pageIdx2sizeTab 建立的是 Page 级别内存规格的索引表,pageIndex 到对应 Page 级内存规格 size 之间的映射。这里的 pageIndex 从 0 开始一直到 31。
private static int[] newPageIdx2sizeTab(short[][] sizeClasses, int nSizes, int nPSizes,
int directMemoryCacheAlignment) {
// page 级的内存规格,个数为 32
int[] pageIdx2sizeTab = new int[nPSizes];
int pageIdx = 0;
// 遍历内存规格表,建立 pageIdx 与对应 Page 级内存规格 size 之间的映射
for (int i = 0; i < nSizes; i++) {
short[] sizeClass = sizeClasses[i];
if (sizeClass[PAGESIZE_IDX] == yes) {
pageIdx2sizeTab[pageIdx++] = sizeOf(sizeClass, directMemoryCacheAlignment);
}
}
return pageIdx2sizeTab;
}
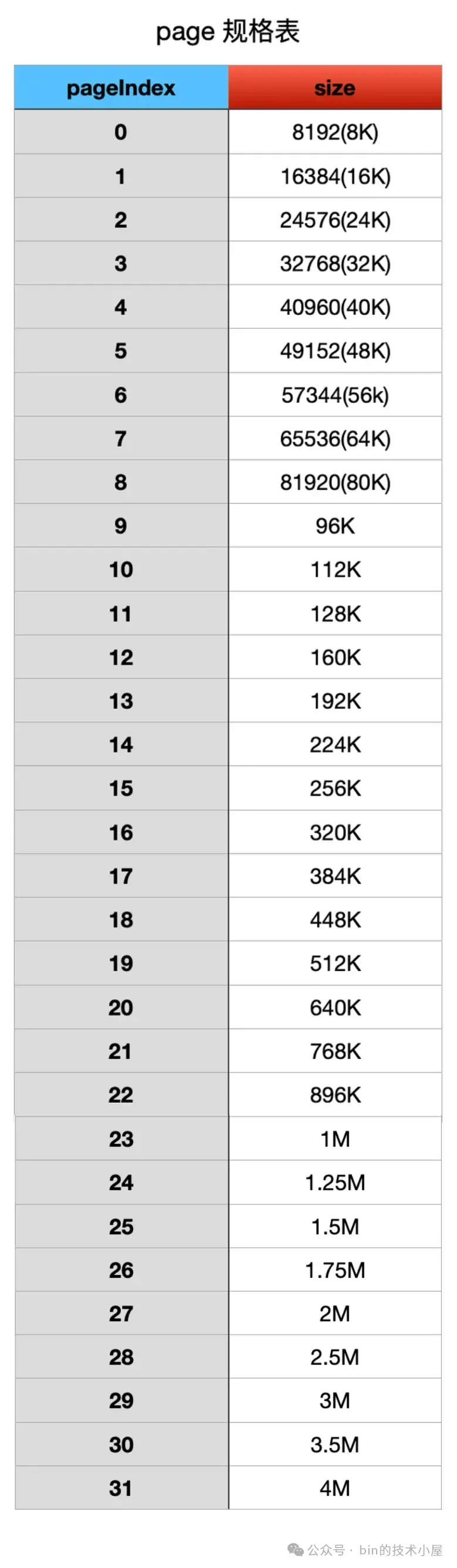
3.3 size2idxTab
size2idxTab 是建立 request size 与内存规格 index 之间的映射关系,那什么是 request size 呢 ? 注意这里的 request size 并不是内存规格表中固定的规格 size , 因为内存规格表是 Netty 提前规划好的,对于用户来说,可能并不知道 Netty 究竟划分了哪些固定的内存规格,用户不一定会按照 Netty 规定的 size 进行内存申请,申请的内存尺寸可能是随意的。
比如,内存规格表中的前两个规格是 16B , 32B。但用户实际申请的可能是 6B ,8B , 29B , 30B 这样子的尺寸。

当用户向内存池申请 6B 或者 8B 的内存块时,那么 Netty 就需要找到与其最接近的内存规格,也就是 16B,对应的规格 index 是 0。当用户申请 29B 或者 30B 的内存块时,与其最接近的内存规格就是 32B , 对应的规格 index 是 1 。
针对上面的例子来说,用户实际申请的内存尺寸就是 request size,在 size2idxTab 中的概念是 lookup size 。而 size2idxTab 的作用就是建立 lookup size 与其对应内存规格 index 之间的映射。这样一来,Netty 就可以通过任意一个 lookup size 迅速找到与其最接近的内存规格了。
那么这个映射如何建立呢 ?我们看到 size2idxTab 的结构只是一个 int 型的数组,怎么存放 lookup size 与内存规格 index 的映射关系呢 ?
int[] size2idxTab
说起映射,我们很容易想起 Hash 表对吧,我们可以将内存规格 index 存储在 size2idxTab 数组 , size2idxTab 数组的 index 我们可以设计成 lookup size 的 hash code 。这样一来,给定一个任意的 lookup size,我们通过一个哈希函数计算出它的 hash code,这个 hash code 也就是 size2idxTab 数组的 index,从而通过 size2idxTab[index] 找到映射的内存规格 index。
那么我们该如何设计一个这样的哈希函数呢 ? 能不能从 Netty 的内存规格表中找找规律,看看有没有什么灵感、我们知道 Netty 的基础内存规格为 16B ,从 16B 开始先是按照 16B 这样的间隔开始慢慢扩充内存规格,随后依次按照 32B ,64B, 128B , 256B , … , 0.5M 这样 2 的次幂的倍数间隔逐渐慢慢扩充成 68 种内存规格。
// 基础内存规格
static final int LOG2_QUANTUM = 4;
这 68 种内存规格都是在 16B 的基础上扩充而来的,规格之间的差值也都是 16 的倍数,因此任何一种内存规格一定是 16 的倍数。根据这个特点,我们将 4M 的内存空间按照 16B 这样的间隔将 lookup size 的尺寸切分为,16B , 32B , 48B , 64B , 80B , … 等等这样的 lookup 尺寸,它们之间的间隔都是 16B,不会像内存规格那样 2 倍 2 倍的递增。
如果 lookup size 在(0 , 16B] 范围内,那么对应的规格 index 就是 0 ,内存规格为 16B , 如果 lookup size 在(16B , 32B] 范围内,那么对应的规格 index 就是 1 , 内存规格为 32B,如下图所示这样以此类推:
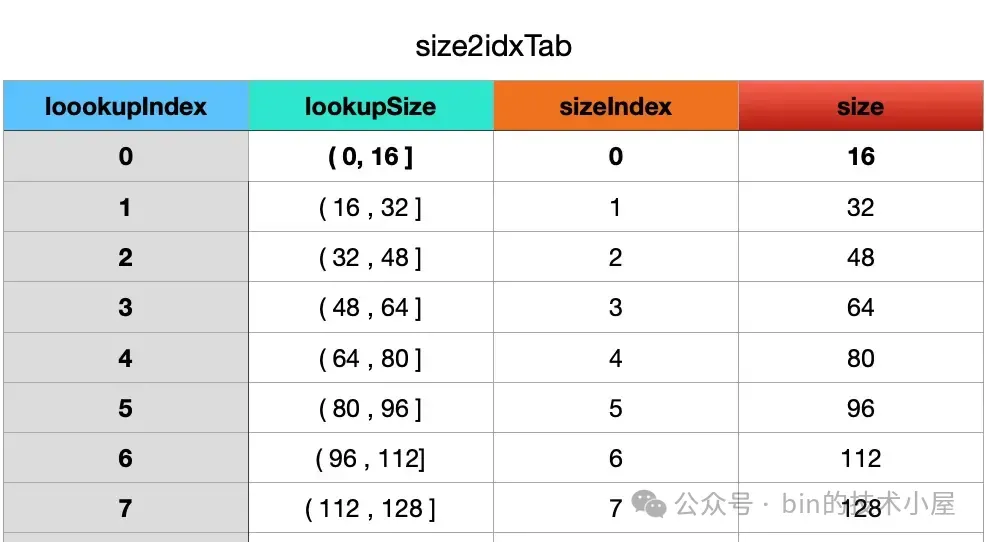
按照这样的规律,我们就可以设计一个这样的哈希函数:
lookupSize - 1 >> LOG2_QUANTUM
比如,9B 通过上面的哈希函数计算出来的就是 0 ,恰好是内存规格 16B 的 index (0) , 31B 计算出来的就是 1 ,恰好是内存规格 32B 的 index(1),100B 计算出来的就是 6 ,恰好是内存规格 112B 的 index (6) 。
但如果我们像这样将 ChunkSize(4M) 按照 16B 的间隔进行划分,就会划分出 262144 个 lookup size 尺寸,这样就会导致 size2idxTab 这张索引表非常的大,而且也没这必要。
其实我们只需要为那些使用频率最高的内存规格范围建立索引就好了,剩下低频使用的内存规格我们直接通过计算得出,不走索引。那么究竟为哪些内存规格建立 lookup 索引呢 ?
这就用到了前面介绍的 lookupMaxSize(4K),Netty 只会为 4K 以下的内存规格建立索引,4K 按照 16 的间隔可以划分出 256 个 lookup size 尺寸,大小刚好合适,而且都是高频使用的内存规格。
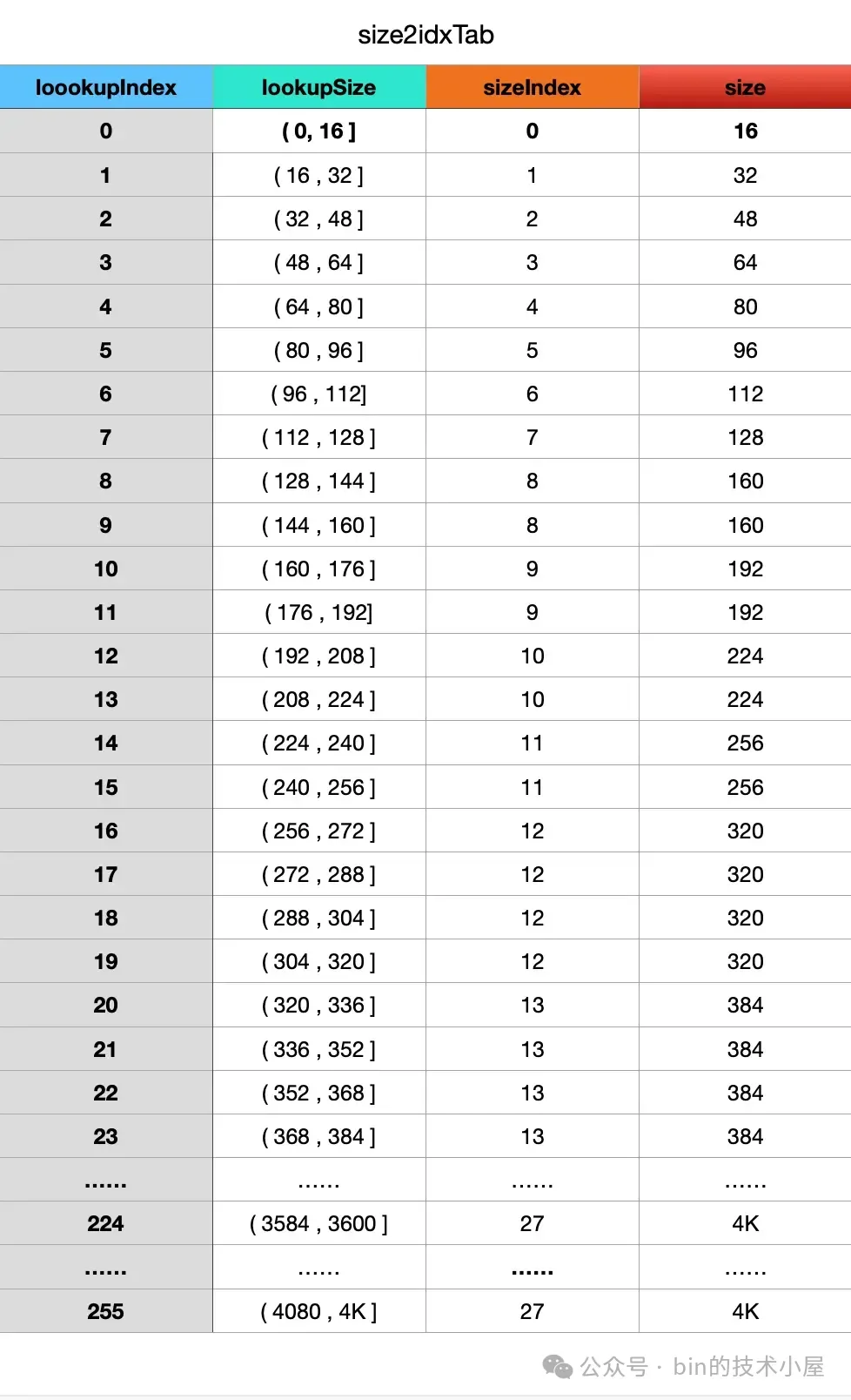
这样一来,只要是 4K 以下的任意 lookupSize,Netty 都可以通过 size2idxTab 索引表在 O(1) 的复杂度下迅速找到与其最接近的内存规格。
但在构建 size2idxTab 索引的时候有一个特殊的点需要注意,在内存规格表中,规格 index 7 之后的内存规格之间的差值并不是恰好是 16 ,而是 16 的 2 的次幂倍数。
比如 sizeIndex 7 和 8 对应的内存规格之间差值是 32 (2 * 16),sizeIndex 11 和 12 对应的内存规格之间差值是 64 (4 * 16),sizeIndex 26 和 27 对应的内存规格之间差值是 512 (32 * 16)。
而 size2idxTab 中规划的 lookupSize 尺寸是按照 16 递增的,所以在 sizeIndex 7 和 8 之间,我们需要划分出两个 lookupSize:144 , 160 , 对应的 lookupIndex 是 8 , 9 ,它们对应的内存规格都是 160B(sizeIndex = 8)。
同样的道理, sizeIndex 11 和 12 之间,我们需要划分出四个 lookupSize:272 , 288 , 304 , 320 。对应的 lookupIndex 是 16 , 17 , 18 , 19 。它们对应的内存规格都是 320B(sizeIndex = 12)。
sizeIndex 26 和 27 之间需要划分出 32 个 lookupSize,对应的内存规格都是 4K (sizeIndex = 27)。
private static int[] newSize2idxTab(int lookupMaxSize, short[][] sizeClasses) {
// size2idxTab 中的 lookupSize 按照 16 依次递增,最大为 4K
// 因此 size2idxTab 大小为 4K / 16
int[] size2idxTab = new int[lookupMaxSize >> LOG2_QUANTUM];
// lookupIndex
int idx = 0;
// lookupSize
int size = 0;
// 遍历 4K 以下的内存规格表 sizeClasses,建立 size2idxTab
for (int i = 0; size <= lookupMaxSize; i++) {
int log2Delta = sizeClasses[i][LOG2DELTA_IDX];
// 计算规格之间的差值是 16 的几倍
// 比如 sizeIndex 7 和 8 对应的内存规格之间差值是 32 (2 * 16)
// 那么这两个内存规格之间就需要划分出 times 个 lookupSize
int times = 1 << log2Delta - LOG2_QUANTUM;
// 构建 size2idxTab
while (size <= lookupMaxSize && times-- > 0) {
// lookupIndex 与 sizeIndex 之间的映射
size2idxTab[idx++] = i;
// lookupSize 按照 16 依次递增
size = idx + 1 << LOG2_QUANTUM;
}
}
return size2idxTab;
}
好了,现在 lookupSize 在 4K 以下,我们可以通过 size2idxTab 找到与其最接近的内存规格,那么 5K 到 4M 之间的 lookupSize,我们又该如何查找其对应的内存规格呢 ?
前面笔者提到过,Netty 将 68 种内存规格划分成了 17 个内存规格组,内存规格组编号从 0 到 16 。每个内存规格组内有四个规格。给定一个任意的 lookupSize,我们首先的思路是不是要确定这个 lookupSize 到底是属于哪一个内存规格组 ?然后在确定这个 lookupSize 最接近组内第几个规格 ?
现在思路有了,下面我们来看第一个问题,如何确定 lookupSize 究竟属于哪一个内存规格组 ?
还记不记得笔者之前反复强调过的一个特性 —— 每个内存规格组内最后一个规格都是 2 的次幂,第 0 个内存规格组最后一个规格是 64B,第 1 个内存规格组最后一个规格是 128B , 第 2 个是 256B , 第 3 个是 512B,第 4 个是 1K, … ,第 16 个是 4M 。
我们根据每组最后一个规格的尺寸,就可以得到这样一个数列 —— 64 , 128 , 256 , 512 , 1K , … , 4M。这个数列有一个特点就是从 64 开始逐渐按照 2 的次幂倍数增长。因此,我们将数列中的每项除以 64 就得到一个新的数列 —— 2^0 , 2^1 , 2^2 , 2^3 , 2^4 , 2^5 …。而新数列中,每一项的对数就是内存规格组的编号了。
这个逻辑明确之后,剩下的实现就很简单了,首先我们需要找到 lookupSize 所在内存规格组的最后一个规格 , 直接对 lookupSize 向上取最接近的 2 的次幂。
// 组内最后一个内存规格的对数
int x = log2((lookupSize << 1) - 1);
在组内最后一个内存规格现在明确了,我们将它除以 64 ,然后取商的对数就得到了 shift —— 内存规格组编号。
// lookupSize 所在内存规格组编号
int shift = x - (LOG2_SIZE_CLASS_GROUP + LOG2_QUANTUM)
有了 shift 之后,我们很容易就能确定出组内第一个规格的 index , 每个内存规格组内有 4 个规格,现在我们是第 shift 个内存规格组,该组第一个规格的 index 就是 shift * 4 。
// 组内第一个规格的 index
int group = shift << LOG2_SIZE_CLASS_GROUP;
而每个内存规格组内,规格之间的间隔都是相同的,通过 x - LOG2_SIZE_CLASS_GROUP - 1 获取组内间隔 log2Delta。
// 组内规格间隔
int log2Delta = x - LOG2_SIZE_CLASS_GROUP - 1;
在有了 group 和 log2Delta 之后,我们很容易就能确定这个 lookupSize 最接近组内第几个规格 —— lookupSize - 1 >> log2Delta & 3
int mod = lookupSize - 1 >> log2Delta & (1 << LOG2_SIZE_CLASS_GROUP) - 1;
最后 group + mod 就是该 lookupSize 对应的内存规格 index 。下面笔者用一个具体的例子进行说明,假设我们现在要向内存池申请 5000B 的内存块。

5000B 所在内存规格组最后一个规格是 8K,8K 除以 64 得到商的对数就是 7 ,说明 5000B 这个内存尺寸位于第 7 个内存规格组内。组内第一个规格 index
是 28 ,组内间距 log2Delta = 10 。计算出的 mod 恰好是 0 。也就是说与 5000B 最贴近的内存规格是 5K , 对应的规格 index 是 28 。
final class SizeClasses {
@Override
public int size2SizeIdx(int size) {
if (size == 0) {
return 0;
}
// Netty 只会池化 4M 以下的内存块
if (size > chunkSize) {
return nSizes;
}
// 将 lookupSize 与 Alignment 进行对齐
size = alignSizeIfNeeded(size, directMemoryCacheAlignment);
// lookupSize 在 4K 以下直接去 size2idxTab 中去查
if (size <= lookupMaxSize) {
return size2idxTab[size - 1 >> LOG2_QUANTUM];
}
// 向上取 size 最接近的 2 的次幂,目的是获取所属内存规格组的最后一个规格尺寸
int x = log2((size << 1) - 1);
// size 所在内存规格组编号,最后一个规格尺寸除以 64 得到商的对数
int shift = x < LOG2_SIZE_CLASS_GROUP + LOG2_QUANTUM + 1
? 0 : x - (LOG2_SIZE_CLASS_GROUP + LOG2_QUANTUM);
// 内存规格组内第一个规格 index
int group = shift << LOG2_SIZE_CLASS_GROUP;
// 组内规格之间的间隔
int log2Delta = x < LOG2_SIZE_CLASS_GROUP + LOG2_QUANTUM + 1
? LOG2_QUANTUM : x - LOG2_SIZE_CLASS_GROUP - 1;
// size 最贴近组内哪一个规格
int mod = size - 1 >> log2Delta & (1 << LOG2_SIZE_CLASS_GROUP) - 1;
// 返回对应内存规格 index
return group + mod;
}
}
4. PoolChunk 的设计与实现
如上图所示,PoolChunk 在整个内存池的架构设计中是属于最基础的数据结构,负责管理 Page 级别的内存块,Netty 中一个 Page 大小为 8K ,一个 PoolChunk 的大小为 4M , 也就是说,一个 PoolChunk 管理着 512 个 Page 。
static final class DirectArena extends PoolArena<ByteBuffer> {
@Override
protected PoolChunk<ByteBuffer> newChunk(int pageSize, int maxPageIdx,
int pageShifts, int chunkSize) {
if (sizeClass.directMemoryCacheAlignment == 0) {
// 分配一个 4M 大小的 DirectByteBuffer
ByteBuffer memory = allocateDirect(chunkSize);
// 创建 PoolChunk,管理这 4M 的内存空间
return new PoolChunk<ByteBuffer>(this, memory, memory, pageSize, pageShifts,
chunkSize, maxPageIdx);
}
// 如果是需要按照指定的 Alignment 对齐的话
// 则申请 4M + directMemoryCacheAlignment 大小的 DirectByteBuffer
final ByteBuffer base = allocateDirect(chunkSize + sizeClass.directMemoryCacheAlignment);
// 将 DirectByteBuffer 的 position 位置与 directMemoryCacheAlignment 对齐
final ByteBuffer memory = PlatformDependent.alignDirectBuffer(base, sizeClass.directMemoryCacheAlignment);
// 地址对齐之后,创建 PoolChunk
return new PoolChunk<ByteBuffer>(this, base, memory, pageSize,
pageShifts, chunkSize, maxPageIdx);
}
}
在创建 PoolChunk 的时候,Netty 首先会向 OS 申请一段 4M 大小的内存空间,然后由 JDK 将这 4M 的内存空间包装成 DirectByteBuffer,封装在 PoolChunk 的 base , memory 字段中。
final class PoolChunk<T> {
// PoolChunk 底层依赖的这 4M 内存空间用 JDK 的 ByteBuffer 包装
final Object base;
// 内存地址对齐之后的 ByteBuffer
final T memory;
}
有了这基础的 4M 内存空间之后,Netty 会在这个基础之上近一步建立核心的管理结构,比如第一小节中介绍的核心数据结构 runsAvail ,来组织不同 Page 级别的内存块。
private final IntPriorityQueue[] runsAvail;
除此之外,Netty 还定义了一些概念用于从不同的角度上来描述内存块,并在此基础上设计了一些辅助管理结构。下面我们先将这些基础概念一一梳理清楚:
-
Page 这个概念我们前面已经多次提到了,它是内存池的基本管理单位,PoolChunk 就是按照 Page 为粒度来管理内存的。一个 Page 尺寸为 8K 。
-
Run 指的是一个或者多个 Page , 它是 PoolChunk 的基本管理单位,可以用来分配 Normal 规格的内存块,以及分配 Subpage。
-
Subpage 本质上也是一个 Run,内部包含了一个或者多个 Page , 负责管理 Small 规格的内存块,对应的管理结构就是第一小节中介绍的 PoolSubpage,沿袭了内核中的 slab 设计思想,将一个 Run 按照 Small 规格切分成多个小内存块。
-
Handle 用于描述一个内存块,其实 Run , Subpage 也表示的是内存块,只不过它们是在内存管理的角度上对内存块的描述,而 Handle 特指的是从内存池中分配出去的内存块,对于 Normal 规格的内存块来说,这个 Handle 其实就是一个 Run , 对于 Small 规格的内存块来说,这个 Handle 就是从 Subpage 中分配出去的一个小内存块。Netty 会将 Handle 转换成 PooledByteBuf 返回给用户使用。
PoolChunk 中的 4M 内存空间布局如下图所示:
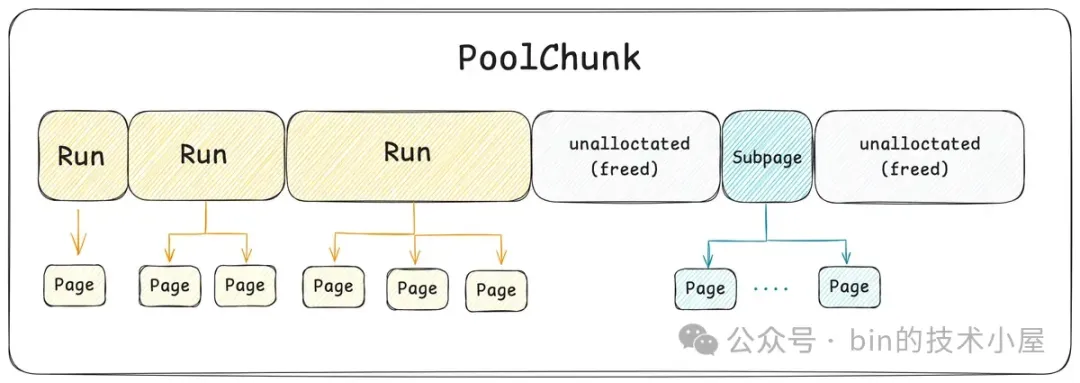
Run 和 Subpage 究其本质而言其实都是一个内存块,Netty 用一个叫做 Handle 的结构来描述所有不同尺寸的内存块,那么这个 Handle 到底是一个什么样的数据结构呢 ? 其实很简单,它就是一个 long 型的整数,其 64 位 bit 布局如下图所示:
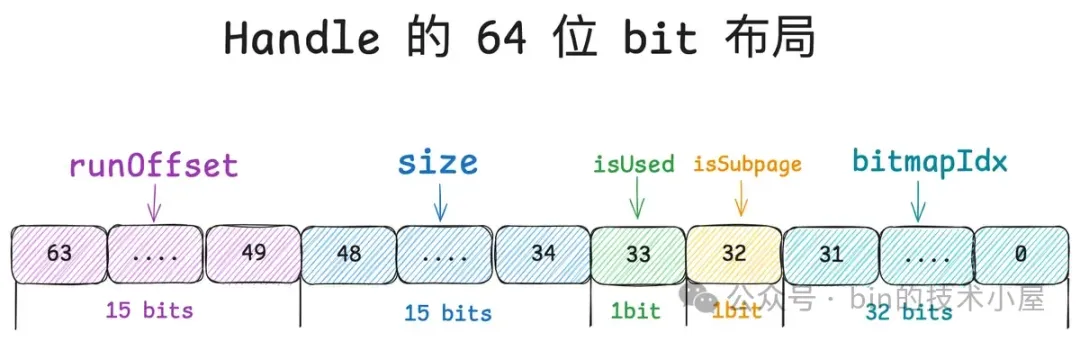
Handle 的这 64 位 bit 分别描述了内存块的五个信息,笔者从高位到低位依次介绍一下它们的含义:
首先 PoolChunk 是按照 Page 为粒度来管理内存的,而 Run 用于描述一个或者多个 Page,因此 PoolChunk 中内存管理的基本单位是 Run 。
其次 Normal 内存规格以及 Small 内存规格的内存块全部来自于 PoolChunk,对于 Normal 规格来说其实就是 PoolChunk 中的一个 Run , 对于 Small 规格来说就是 PoolSubpage 中的一个小内存块,而 PoolSubpage 本身也是一个 Run。
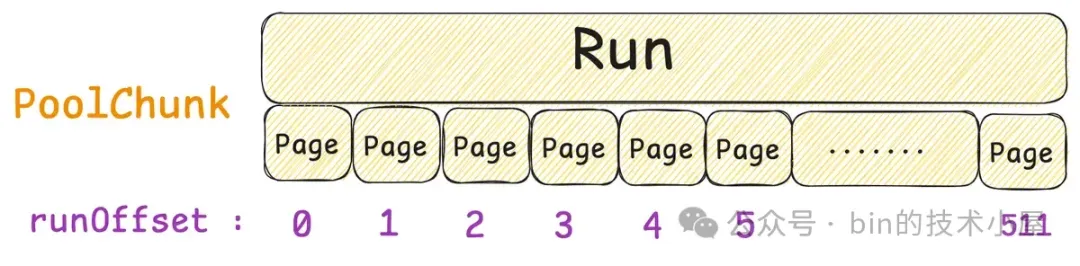
所以对于一个内存块来说,我们首先需要清楚它是来自于 PoolChunk 中的哪一个 Run , 这就用到了 Handle 中的 runOffset,用第 49 到 63 位共 15 个 bits 表示。runOffset 指的是该内存块在 PoolChunk 中的偏移,注意这里的偏移单位是 Page 。
第 34 到 48 位共 15 个 bits 表示 size , size 指的是该内存块包含的 Page 个数。
private static final int SIZE_BIT_LENGTH = 15;
第 33 位共 1 个 bit 表示该内存块是否已经被分配了(isUsed)。
private static final int INUSED_BIT_LENGTH = 1;
第 32 位共 1 个 bit 表示该内存块是否作为 PoolSubpage 来管理 Small 内存规格 。
private static final int SUBPAGE_BIT_LENGTH = 1;
到目前为止,这些信息就足够表示一个 Normal 规格的内存块了。有了 runOffset,我们可以知道这个内存块的起始位置,也就是内存块中第一个 Page 在 PoolChunk 中的偏移。有了 size ,我们就可以知道这个内存块包含的 Page 个数。
那么对于 Small 规格的内存块来说,Handle 结构又该如何表示呢 ? 我们知道 Small 规格的内存块是被 PoolSubpage 管理的,PoolSubpage 会将一个完整的 Run 按照 Small 规格的尺寸切分成多个大小相等的小内存块。
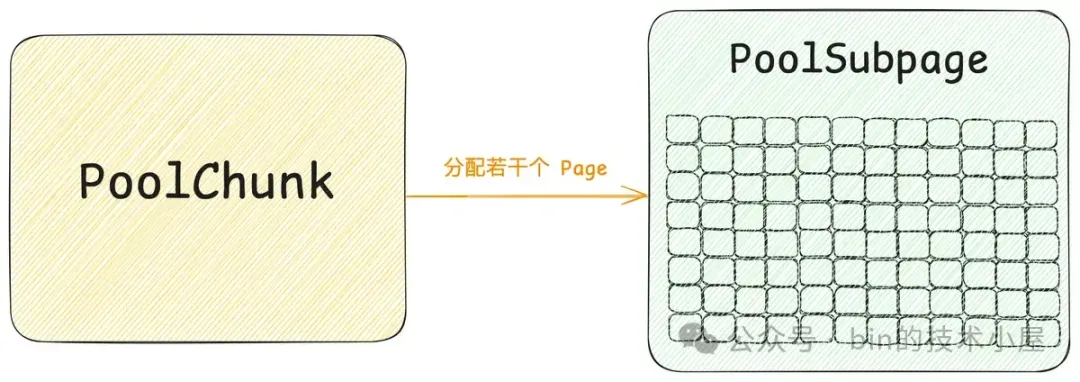
这些小内存块在 PoolSubpage 中用一个 bitmap 来描述,因此当我们用 Handle 结构来描述 Small 规格的内存块时,我们需要知道这个 Handle 具体表示的是 PoolSubpage 中哪一个小内存块,所以我们需要将这个小内存块在 bitmap 中的 index 记录在 Handle 结构中。
Handle 中的第 0 到 31 位共 32 个 bits 就是用来记录 bitmapIdx 的, 对于 Normal 规格的内存块来说(isSubpage = false), 这 32 位 bit 全部是零。
private static final int BITMAP_IDX_BIT_LENGTH = 32;
为了快速地从 Handle 的 64 位 bits 中提取上述五种信息,Netty 定义了相关的 SHIFT 偏移。
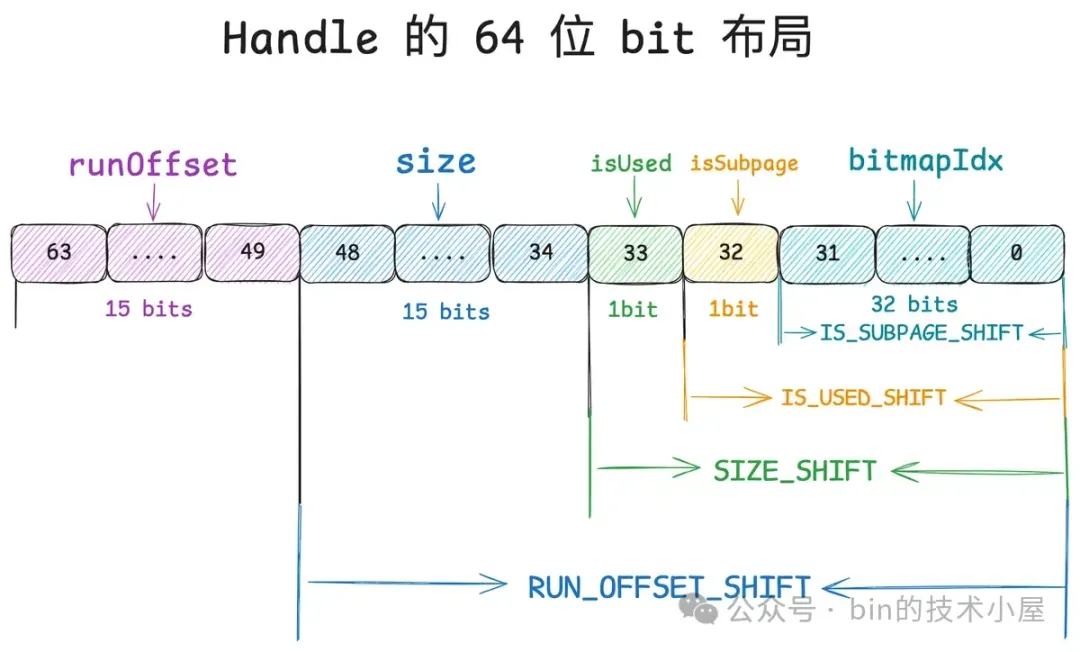
static final int IS_SUBPAGE_SHIFT = BITMAP_IDX_BIT_LENGTH;
static final int IS_USED_SHIFT = SUBPAGE_BIT_LENGTH + IS_SUBPAGE_SHIFT;
static final int SIZE_SHIFT = INUSED_BIT_LENGTH + IS_USED_SHIFT;
static final int RUN_OFFSET_SHIFT = SIZE_BIT_LENGTH + SIZE_SHIFT;
将 handle 右移相关的 SHIFT 位就得到了相应的内存块信息:
static int runOffset(long handle) {
return (int) (handle >> RUN_OFFSET_SHIFT);
}
static int runPages(long handle) {
return (int) (handle >> SIZE_SHIFT & 0x7fff);
}
static boolean isUsed(long handle) {
return (handle >> IS_USED_SHIFT & 1) == 1L;
}
static boolean isSubpage(long handle) {
return (handle >> IS_SUBPAGE_SHIFT & 1) == 1L;
}
static int bitmapIdx(long handle) {
return (int) handle;
}
当我们从 PoolChunk 中申请一个 Run 时(Normal 规格的内存块),Netty 会通过 toRunHandle 将 Run 信息转换为 Handle 。
private static long toRunHandle(int runOffset, int runPages, int inUsed) {
return (long) runOffset << RUN_OFFSET_SHIFT
| (long) runPages << SIZE_SHIFT
| (long) inUsed << IS_USED_SHIFT;
}
当我们从 PoolSubpage 中申请一个 Small 规格的内存块时,Netty 会通过 toHandle 将小内存块信息转换为 Handle。
private long toHandle(int bitmapIdx) {
// subPage 中包含的 page 个数
int pages = runSize >> pageShifts;
// 低 32 位保存 bitmapIdx
return (long) runOffset << RUN_OFFSET_SHIFT
| (long) pages << SIZE_SHIFT
| 1L << IS_USED_SHIFT
| 1L << IS_SUBPAGE_SHIFT
| bitmapIdx;
}
好了,现在 Run 的概念我们清楚了,它的本质就是 PoolChunk 这 4M 的内存空间中由一个或者多个 Page 组成的内存块,PoolChunk 中管理了多个不同尺寸的 Run。同时我们也明白了如何用 Handle 结构来表示一个 Run。那么接下来 PoolChunk 是如何管理这些 Run 呢 ? 这就用到了第一小节中我们介绍的 runsAvail 数组,它是 Netty 中的伙伴系统实现。
private final IntPriorityQueue[] runsAvail;
在第三小节介绍 Netty 内存规格划分的时候,我们看到 Netty 一共划分了 32 种不同 Page 级别的内存块尺寸,当然了,现在我们应该用 Run 这个概念来描述这些内存块。相关的索引建立在 pageIdx2sizeTab 中。Run 的尺寸分别为:1 个 Page , 2 个 Page , … , 512 个 Page,共 32 种 Run 尺寸。
runsAvail 数组的大小也是 32 ,很容易理解,数组中的每一个 IntPriorityQueue 用于组织相同尺寸的 Run,而且这些 Run 是按照内存地址从低到高的顺序组织在这个 IntPriorityQueue 中。这样我们每次向 PoolChunk 申请的 Run 都是从低地址开始。runsAvail 的下标对应的就是 pageIdx2sizeTab 中的 pageIndex 。
// 参数 size 就是 SizeClasses 中计算出的 nPSizes,共 32 种 Run 尺寸
private static IntPriorityQueue[] newRunsAvailqueueArray(int size) {
IntPriorityQueue[] queueArray = new IntPriorityQueue[size];
for (int i = 0; i < queueArray.length; i++) {
queueArray[i] = new IntPriorityQueue();
}
return queueArray;
}
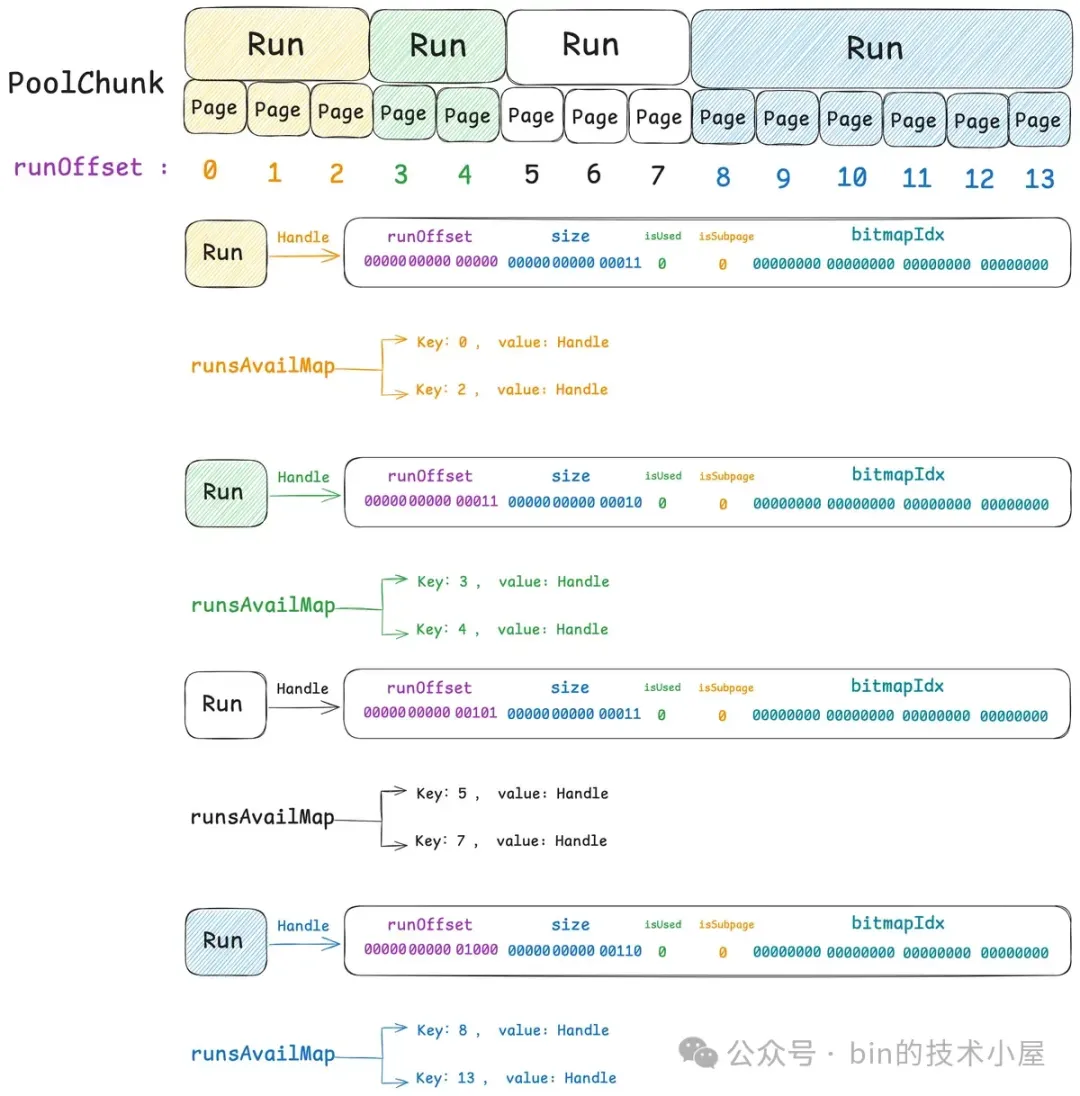
除此之外,Netty 还设计了一个辅助性的数据结构 —— runsAvailMap,runsAvail 我们知道,它是 Netty 中的伙伴系统,用于组织管理 PoolChunk 中不同大小尺寸的 Run 。而 runsAvailMap 则是建立 Run 在 PoolChunk 中的 Page 偏移索引。Key 是 runOffset , Value 则是 Run 对应的 Handle 结构。
private final LongLongHashMap runsAvailMap;
每当一个新的 Run 被加入到 runsAvail 之后,Netty 都会将这个 Run 中第一个 Page 的 runOfffset 以及最后一个 Page 的 runOfffset 添加到 runsAvailMap 中。也就是说 PoolChunk 中的任意一个 Run, 对应到 runsAvailMap 中都会有相应的两条索引。
- key : 第一个 Page 的 runOffset ,value : Run 对应的 Handle 结构
- key : 最后一个 Page 的 runOffset ,value : Run 对应的 Handle 结构
这里的 runOffset 就是相关 Page 在 PoolChunk 中的偏移。
Netty 这里设计这个 runsAvailMap 的目的是用来做什么的呢 ? 经过第一小节的内容介绍我们知道,当我们将一个内存块 Run 释放回 PoolChunk 的时候会涉及到连续内存块合并的过程,内核中的伙伴系统也是这样。
private long collapseRuns(long handle) {
// 在 PoolChunk 中首先不断地向前合并与 handle 内存连续的 Run
// 然后在不断地向后合并内存连续的 Run,最终形成一个更大的 Run 存储到 runsAvail 中
return collapseNext(collapsePast(handle));
}
那 Netty 如何判断哪些内存块是连续的呢 ?这就用到了 runsAvailMap,因为它索引了每个内存块的 first page runOffset 和 last page runOffset , 这样 Netty 就可以用 O(1) 的复杂度迅速找到在 PoolChunk 中连续的内存块 Run 了。
比如说,我们现在要将下图中白色的 Run 释放回 PoolChunk,那么 Netty 就需要找到所有与白色 Run 连续的 Run。很明显,绿色的 Run 与白色 Run 前面连续,蓝色的 Run 与白色 Run 后面连续。

首先 Netty 会在 collapsePast 中不断的向前合并与白色 Run 连续的 Run,白色 Run 的 runOffset 我们可以通过前面介绍的 runOffset(handle) 获得,如果白色 Run 前面有连续的 Run , 那么这个 Run 的 last page runOffset 一定是 runOffset - 1 。这时我们就可以通过 runOffset - 1 到 runsAvailMap 中去查找是否有这条索引。
int runOffset = runOffset(handle);
long pastRun = getAvailRunByOffset(runOffset - 1);
比如,白色 Run 的 runOffset 是 5 , 我们通过 4 去 runsAvailMap 中一下就找到了绿色 Run 的 Handle 结构,然后我们将白色 Run 与绿色 Run 合并成一个更大的 Run。合并之后的 runOffset 就是绿色 Run 的 runOffset (3) , 合并之后的 size 就是原来白色 Run 和绿色 Run 的 size 之和(5)。

// 白色 Run 的 size (包含 Page 的个数)
int runPages = runPages(handle);
// 绿色 Run 的 runOffset
int pastOffset = runOffset(pastRun);
// 绿色 Run 的 size
int pastPages = runPages(pastRun);
if (pastRun != handle && pastOffset + pastPages == runOffset) {
// 清除绿色 Run 在 runsAvailMap 中的相关索引
removeAvailRun(pastRun);
// 白色,绿色合并成一个更大的 Run,
// 新的 runOffset 为绿色 Run 的 runOffset
// 新的 size 为两者之和
handle = toRunHandle(pastOffset, pastPages + runPages, 0);
}
当第一轮合并结束之后,我们还需要继续向前不断的合并,因为有可能还存在与新的 Run 内存连续的 Run(黄色),于是重复上述合并过程,用新的 runOffset - 1 (2) 再去 runsAvailMap 中查找,发现有一个黄色的 Run。继续合并,直到前面完全没有连续的 Run 为止。

private long collapsePast(long handle) {
// 不断地向前合并内存连续的 Run
for (;;) {
// 释放内存块的 runOffset
int runOffset = runOffset(handle);
// 释放内存块 size (包含 Page 的个数)
int runPages = runPages(handle);
// 查看该内存块前面是否有连续的 Run
// 如果有 pastRun 中的 lastPageOffset 一定是 runOffset - 1
long pastRun = getAvailRunByOffset(runOffset - 1);
if (pastRun == -1) {
// 前面不存在连续的 Run 则停止向前合并
return handle;
}
// 连续内存块的 runOffset
int pastOffset = runOffset(pastRun);
// 连续内存块的 size
int pastPages = runPages(pastRun);
// is continuous
if (pastRun != handle && pastOffset + pastPages == runOffset) {
// 将 pastRun 在 runsAvailMap 中的相关索引删除
removeAvailRun(pastRun);
// 重新合并成一个更大的 Run
handle = toRunHandle(pastOffset, pastPages + runPages, 0);
} else {
// 前面没有连续的 Run , 停止向前合并
return handle;
}
}
}
当向前合并的过程结束之后,Netty 紧接着就会向后继续合并,如果后面存在连续的 Run, 那么这个 nextRun 的 runOffset 一定是待合并 Run 的 runOffset 加上 runPages。比如上图中展示的白色 Run , 它的 runOffset = 0 , runPages = 8。蓝色 Run 与它连续,runOffset 为 8 。
当白色 Run 与蓝色 Run 合并之后,就形成了一个新的更大的 Run,它的 runOffset 就是白色 Run 的 runOffset (0) , 它的 size 就是两者之和。

private long collapseNext(long handle) {
// 这里的 handle 就是向前合并之后新的 Run
// 不断的向后合并连续的 Run
for (;;) {
int runOffset = runOffset(handle);
int runPages = runPages(handle);
// 向后查找内存连续的 Run, nextRun 的 firstPageOffset = runOffset + runPages
long nextRun = getAvailRunByOffset(runOffset + runPages);
if (nextRun == -1) {
// 后面不存在内存连续的 Run
return handle;
}
int nextOffset = runOffset(nextRun);
int nextPages = runPages(nextRun);
//is continuous
if (nextRun != handle && runOffset + runPages == nextOffset) {
//remove next run
removeAvailRun(nextRun);
handle = toRunHandle(runOffset, runPages + nextPages, 0);
} else {
return handle;
}
}
}
当所有连续的 Run 全部合并之后,Netty 就会将这个更大的 Run 放入 runsAvail 中缓存起来。
以上就是 PoolChunk 关于 Run 管理的核心内容,但 PoolChunk 除了负责分配 Run 之外,还会分配 PoolSubpage。由这个 PoolChunk 分配出去的所有 PoolSubpage 都会被组织在 subpages 数组中。
/**
* manage all subpages in this chunk
*/
private final PoolSubpage<T>[] subpages;
而 subpages 数组中的索引就是对应 PoolSubpage 的 runOffset ,一个 PoolChunk 中一共有 512 个 Page , 相应的 runOffset 就会有 512 种,所以 subpages 数组的长度为 512 。
subpages = new PoolSubpage[chunkSize >> pageShifts];

那么 Netty 设计这个 subpages 数组的目的又是什么呢 ?我们都知道 PoolSubpage 主要是负责分配 Small 规格的小内存块的,那么当我们要释放一个 Small 规格的小内存回内存池的时候,我们该如何判断这个小内存块到底属于哪个 PoolSubpage 呢 ?
这就用到了这里的 subpages 数组,经过前面的介绍我们知道,Netty 中所有尺寸的内存块都会用一个 Handle 结构来描述,我们可以通过 runOffset(long handle) 找到该内存块在 PoolChunk 中的 runOffset,有了 runOffset 就可以到 subpages 数组中找到对应的 PoolSubpage 了。然后将这个小内存块释放回对应的 PoolSubpage 中。
现在 PoolChunk 的整个管理架构笔者就介绍完了,除去整个架构之外,这里要额外提一点的是 PoolChunk 还有一个 cachedNioBuffers 缓存结构,它里面缓存的是 ByteBuffer。
private final Deque<ByteBuffer> cachedNioBuffers;
默认情况下,cachedNioBuffers 可以缓存 1023 个 ByteBuffer,我们可以通过 -Dio.netty.allocator.maxCachedByteBuffersPerChunk 参数来进行调节。
DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK = SystemPropertyUtil.getInt(
"io.netty.allocator.maxCachedByteBuffersPerChunk", 1023);
那么这里的 cachedNioBuffers 是干什么的 ? 它里面缓存的这些 ByteBuffer 又是什么呢 ?
在本小节的开始,笔者介绍过,当我们创建一个 PoolChunk 的时候,Netty 首先会向 OS 申请一段 4M 大小的内存空间,随后由 JDK 将这 4M 的内存空间封装成 DirectByteBuffer,保存在 PoolChunk 的 memory 字段中。也就是说,PoolChunk 中的这 4M 内存空间是由 JDK 的 ByteBuffer 来描述的。
final class PoolChunk<T> {
// PoolChunk 底层依赖的这 4M 内存空间用 JDK 的 ByteBuffer 包装
// memory 就是 PoolChunk 底层的 ByteBuffer(4M)
final T memory;
}
当我们向 PoolChunk 申请到一个 Run (下图绿色部分)之后,注意,这个 Run 现在的表现形式只是一个 Handle 结构,我们需要将其包装 PooledByteBuf 返回给用户使用。
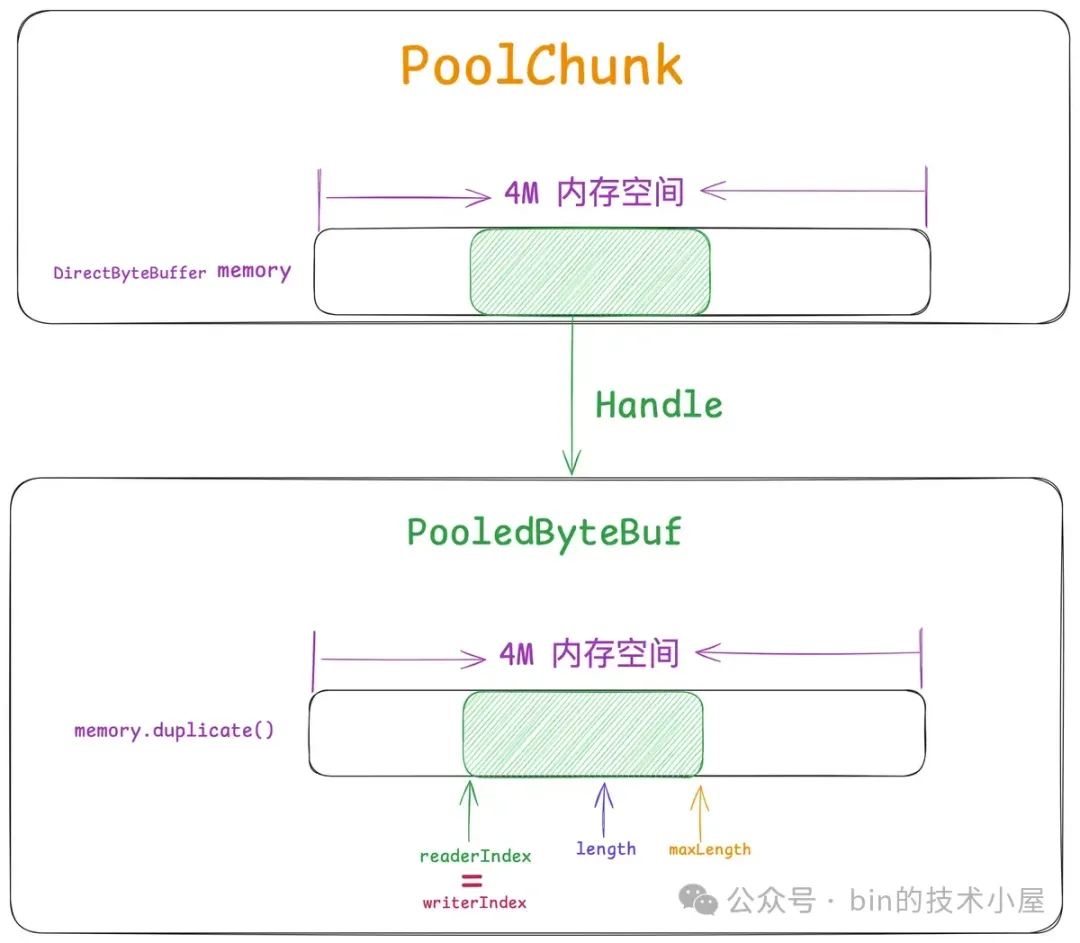
而这个 PooledByteBuf 其实直接操作的是 PoolChunk 中的 memory(ByteBuffer),只不过 PooledByteBuf 拥有自己独立的相关 index , 这些 index 将这个 PooledByteBuf 的可操作内存范围控制在上图中 readerIndex 到 length 之间。
abstract class PooledByteBuf<T> {
int readerIndex;
int writerIndex;
// 我们向内存池请求的内存大小 , 其实就是 ByteBuf 的 capacity
protected int length;
// 内存池实际分配给我们的内存大小
int maxLength;
// PoolChunk 中 memory 的 duplicate 视图
ByteBuffer tmpNioBuf;
}
因此每一个 PooledByteBuf 都需要依赖一个 tmpNioBuf,这个 tmpNioBuf 正是 PoolChunk 中 memory 的 duplicate 视图,其底层依赖的 4M 内存空间和 PoolChunk 是一模一样的。
@Override
protected ByteBuffer newInternalNioBuffer(ByteBuffer memory) {
return memory.duplicate();
}
当内存池创建 PooledByteBuf 的时候都需要传入一个完整的 PoolChunk 内存视图(memory.duplicate) ,这些内存视图就缓存在 cachedNioBuffers 中,里面的 ByteBuffer 正是 PoolChunk 中 memory 的 duplicate 视图。
好了,到现在为止,PoolChunk 中所有的核心组件设计,笔者就全部介绍完了,但目前的 PoolChunk 只是刚刚被创建出来,还是一个空的 PoolChunk,其内部伙伴系统 runsAvail 中没有任何的 Run 。
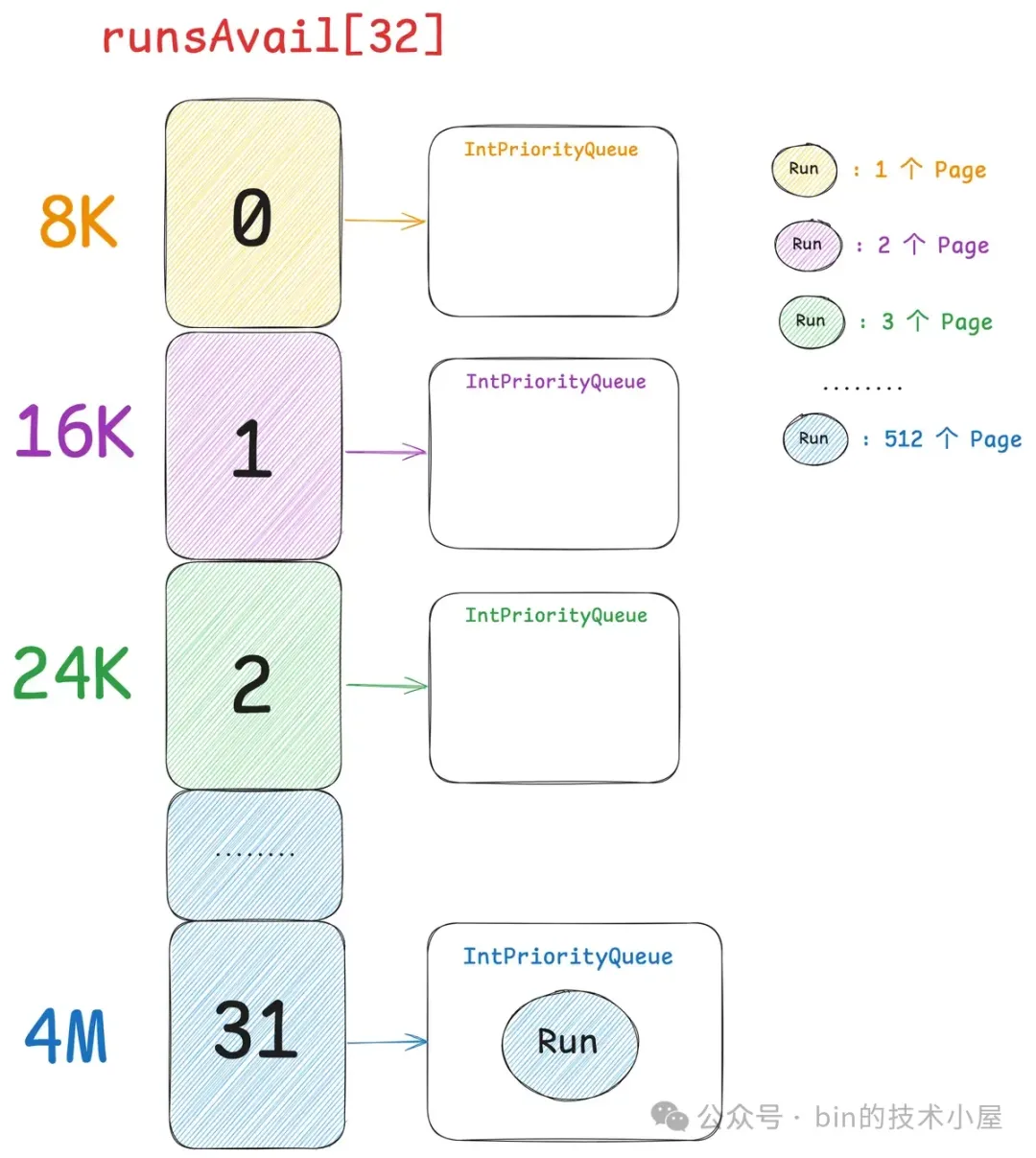
那么在初始状态下,Netty 会将 PoolChunk 的这 4M 内存空间组装成一个大的 Run,放入到 runsAvail 中。
该 Run (initHandle)的 runOffset = 0 , size = 512 , isUsed = 0 , isSubpage = 0 , bitmapIdx = 0。
int pages = chunkSize >> pageShifts;
long initHandle = (long) pages << SIZE_SHIFT;
// 插入到 runsAvail 中
insertAvailRun(0, pages, initHandle);
随后通过 insertAvailRun 方法将 initHandle 插入到中 runsAvail 中,但在插入之前我们需要知道这个 initHandle 应该插入到哪一个 IntPriorityQueue 中。
initHandle 的尺寸 size 是 512 个 Page (4M) , 在第三小节介绍的 Page 规格表 pageIdx2sizeTab 中,我们可以看到 4M 对应的 pageIndex 为 31。所以这个 initHandle 最终会被插入到 runsAvail[31] 中。
private void insertAvailRun(int runOffset, int pages, long handle) {
// 512 个 Page 在 Page 规格表中对应的 pageIdx 为 31
int pageIdxFloor = arena.sizeClass.pages2pageIdxFloor(pages);
IntPriorityQueue queue = runsAvail[pageIdxFloor];
// 将 4M 的 Run 插入到 runsAvail[31] 中
queue.offer((int) (handle >> BITMAP_IDX_BIT_LENGTH));
// 将 Run 中第一个 Page 的 runOffset 以及最后一个 Page 的 runOffset 插入到 runsAvailMap 中
insertAvailRun0(runOffset, handle);
if (pages > 1) {
insertAvailRun0(lastPage(runOffset, pages), handle);
}
}
每当向 runsAvail 中插入一个 Run 之后,Netty 都会将该 Run 中第一个 Page 的 runOffset (0) 以及最后一个 Page 的 runOffset (511) 插入到 runsAvailMap 中。
private void insertAvailRun0(int runOffset, long handle) {
long pre = runsAvailMap.put(runOffset, handle);
assert pre == -1;
}
现在一个完整的 PoolChunk 就被初始化好了,下面是 PoolChunk 的完整创建过程:
PoolChunk(PoolArena<T> arena, Object base, T memory, int pageSize, int pageShifts, int chunkSize, int maxPageIdx) {
// 只对 4M 的 PoolChunk 进行池化
unpooled = false;
// PoolChunk 所属的 PoolArena
this.arena = arena;
// PoolChunk 底层依赖的 JDK ByteBuffer (4M)
this.base = base;
this.memory = memory;
// 8K
this.pageSize = pageSize;
// 13
this.pageShifts = pageShifts;
// 4M
this.chunkSize = chunkSize;
// PoolChunk 剩余的内存空间,初始为 4M
freeBytes = chunkSize;
// 创建 runsAvail 数组,Netty 中的伙伴系统
// index 为 PageIndex
runsAvail = newRunsAvailqueueArray(maxPageIdx);
runsAvailLock = new ReentrantLock();
// runsAvail 中所有 Run 的 first page runOffset 以及 last page runOffset
runsAvailMap = new LongLongHashMap(-1);
// 负责组织所有由这个 PoolChunk 分配出去的 PoolSubpage
// index 为 PoolSubpage 的 runOffset
subpages = new PoolSubpage[chunkSize >> pageShifts];
// PoolChunk 在初始状态下只有一个 Run
// size 为 512 个 Page(4M)
int pages = chunkSize >> pageShifts;
// 初始run : runOffset = 0 (15 bit) , size = 512(15 bits) , isUsed = 0 (1bit) , isSubpage = 0 (1bit), bitmapIdx = 0 (32bits)
long initHandle = (long) pages << SIZE_SHIFT;
// 将初始 run 插入到 runsAvail 数组中
insertAvailRun(0, pages, initHandle);
// 可缓存 1023 个 memory 的 duplicate 视图
cachedNioBuffers = new ArrayDeque<ByteBuffer>(8);
}
PoolChunk 里面还有一个 unpooled 属性,用来指定该 PoolChunk 是否加入到内存池中管理。
final boolean unpooled;
一个普通的 PoolChunk 大小为 4M , 负责分配 PoolSubpage(管理 Small 规格的内存块)以及 Normal 规格的内存块,那么这种类型的 PoolChunk 肯定是要被内存池管理的(unpooled = false)。
但除了 Small 规格和 Normal 规格之外,Netty 还有一种 Huge 规格(超过 4M),而内存池并不会管理 Huge 规格的内存块,当我们申请的内存超过 4M 的时候,Netty 会直接向 OS 进行申请,并不会经过内存池。释放的时候也是直接释放回 OS 中。
abstract class PoolArena<T> {
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 获取 reqCapacity 在 sizeIdx2sizeTab 中的 index(对应的内存规格 index)
final int sizeIdx = sizeClass.size2SizeIdx(reqCapacity);
// [16B , 28K] 之间是 small 规格的内存
if (sizeIdx <= sizeClass.smallMaxSizeIdx) {
tcacheAllocateSmall(cache, buf, reqCapacity, sizeIdx);
} else if (sizeIdx < sizeClass.nSizes) {
// [32K , 4M] 之间是 normal 规格的内存
tcacheAllocateNormal(cache, buf, reqCapacity, sizeIdx);
} else {
// 超过 4M 就是 Huge 规格
int normCapacity = sizeClass.directMemoryCacheAlignment > 0
? sizeClass.normalizeSize(reqCapacity) : reqCapacity;
// huge 内存规格直接向操作系统申请,不会被内存池管理
allocateHuge(buf, normCapacity);
}
}
}
对于 Huge 规格的内存块的来说,Netty 也会用 PoolChunk 这个结构来描述,但很明显 Huge 规格并不会被内存池管理,所以在 allocateHuge 方法分配 Huge 规格的 PoolChunk 时,这里的 unpooled 就会指定为 true。
/** Creates a special chunk that is not pooled. */
PoolChunk(PoolArena<T> arena, Object base, T memory, int size) {
// Huge 规格的内存块不会被内存池管理
unpooled = true;
this.arena = arena;
this.base = base;
this.memory = memory;
pageSize = 0;
pageShifts = 0;
runsAvailMap = null;
runsAvail = null;
runsAvailLock = null;
subpages = null;
chunkSize = size;
cachedNioBuffers = null;
}
4.1 PoolChunk 的内存分配流程
PoolChunk 在内存池中的作用主要是负责分配 Page 级别的内存规格尺寸(Run),其中包括 Normal 规格的内存块,以及负责组织管理 Small 规格内存块的 PoolSubpage。
每一种 Run 尺寸,在 PoolChunk 中都会有一个专门的 IntPriorityQueue 来组织管理,Netty 一共划分了 32 种不同的 Run 尺寸,分别是:1 个 Page , 2 个 Page , … , 512 个 Page。每一种 Run 尺寸都会对应一个 pageIndex , 也就是第三小节中,笔者介绍的 Page 规格表 —— pageIdx2sizeTab。
32 种 Run 尺寸就对应 32 个 IntPriorityQueue,它们组织在 PoolChunk 中的 runsAvail 数组中,数组的 index 就是对应的 pageIndex。
当我们向 PoolChunk 申请一个 Run 的时候,我们就需要先到 pageIdx2sizeTab 中找到该 Run 尺寸对应的 pageIndex。比如,当我们申请 8K 的内存块时,对应的 pageIndex 就是 0 。
随后 Netty 就会根据这个 pageIndex 到 runsAvail 中找到对应 Run 尺寸的 IntPriorityQueue —— runsAvail[pageIndex] , 这个 IntPriorityQueue 中管理的全部是相同尺寸的 Run 。剩下的事情就好办了,我们直接从 IntPriorityQueue 中获取一个内存地址最低的 Run 分配出去就好了。
如果不巧 runsAvail[pageIndex] 是空的,那我们就继续到上一层 runsAvail[pageIndex+1] 中去找,如果还是空的,那就继续逐级向上去找,直到找到一个不为空的 IntPriorityQueue。
private int runFirstBestFit(int pageIdx) {
// 如果该 PoolChunk 是一个全新的,那么直接就到 runsAvail[31] 中去找
// 因为此时 PoolChunk 中只会包含一个 Run (大小为 4M)
if (freeBytes == chunkSize) {
return arena.sizeClass.nPSizes - 1;
}
// 按照伙伴查找算法,先从 pageIdx 规格开始查找对应的 IntPriorityQueue 是否有内存块
// 如果没有就一直向后查找,直到找到一个不为空的 IntPriorityQueue
for (int i = pageIdx; i < arena.sizeClass.nPSizes; i++) {
IntPriorityQueue queue = runsAvail[i];
if (queue != null && !queue.isEmpty()) {
return i;
}
}
// 如果 chunk 全部分配出去了,则返回 -1
return -1;
}
但是这样一来,我们在 runsAvail[pageIndex + n] 中获取到的 Run 尺寸一定大于我们请求的 runSize,所以需要近一步将这个 Run 进行切分,切出一个 runSize 然后分配出去,剩下的重新归还到 runsAvail 中。
下面我们来一个具体的例子来说明 PoolChunk 的内存分配逻辑,假设现在有一个刚刚被初始化好的 PoolChunk,如下图所示。现在我们要向这个 PoolChunk 申请一个 8K 大小(runSize)的内存块。
首先我们要去 Page 规格表中找到 8K 对应的 pageIndex(0):
// runSize 为 8K ,一个 Page 大小
int pages = runSize >> pageShifts; // 1
// 8K 对应在 pageIdx2sizeTab 中的 pageIdx 为 0
int pageIdx = arena.sizeClass.pages2pageIdx(pages);
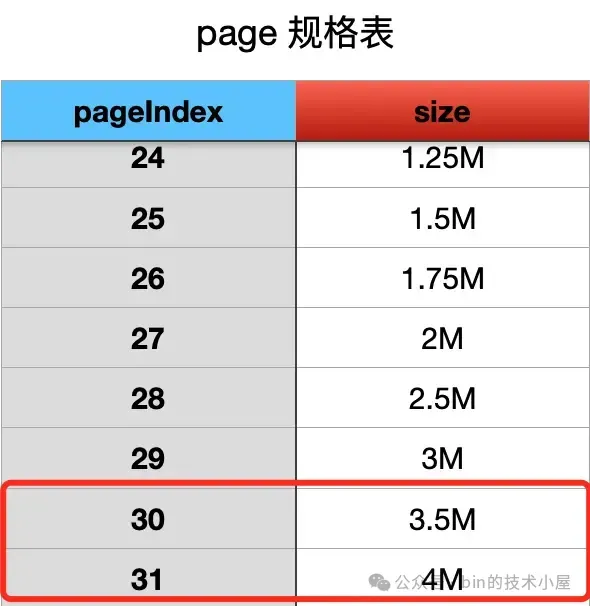
由于现在的 PoolChunk 刚刚被初始化好,所以 runsAvail[0] 中一定是空的,我们直接到 runsAvail[31] 中查找,发现对应的 IntPriorityQueue 中只有一个 Run,大小为 4M,一共 512 个 Page 。
但我们只需要 1 个 Page,所以需要将这个 4M 的 Run 分裂成两个小的 Run , 第一个 Run 下图绿色部分,大小恰好 1 个 Page,分配出去。第二个 Run 下图黄色部分,大小为 511 个 Page ,重新归还回 PoolChunk。
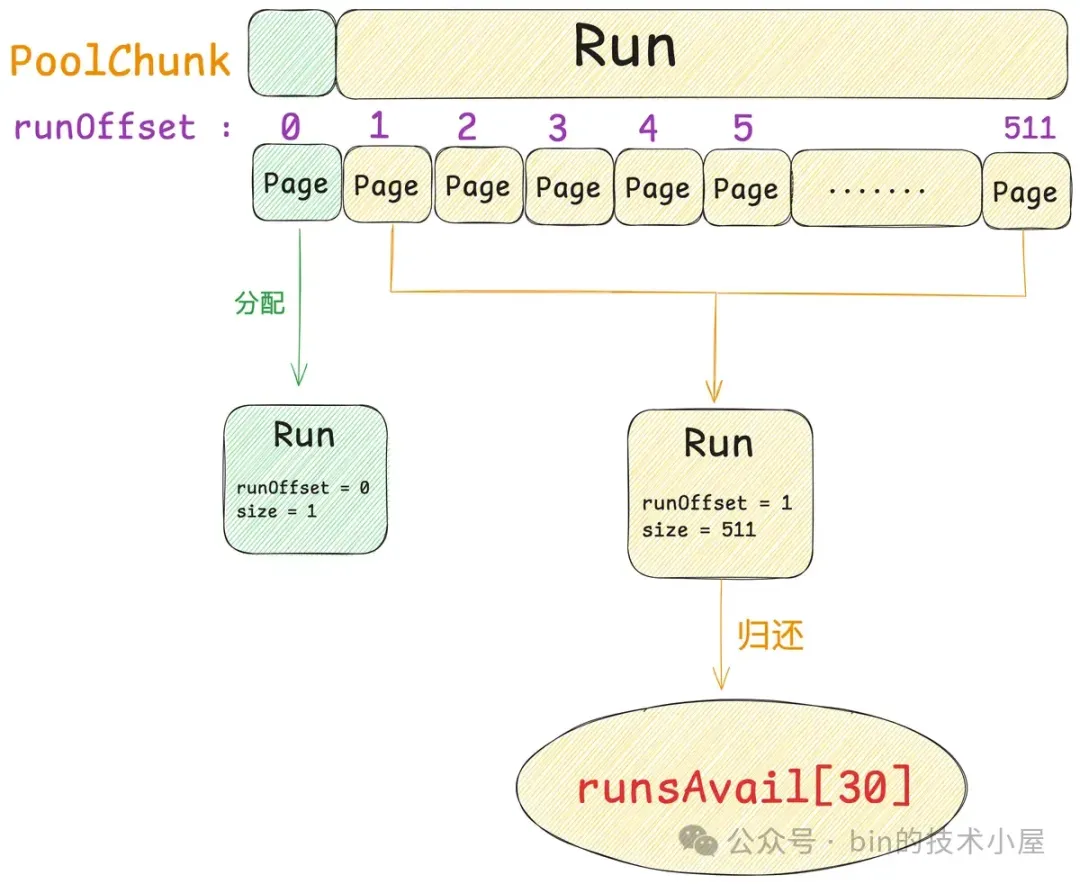
由于 511 个 Page 恰好在 3.5M 规格与 4M 规格之间,所以我们需要将黄色的 Run 归还到 runsAvail[30] 中。
下面是内存块分裂的实现逻辑:
// handle 表示即将要被分裂的 Run (4M)
// needPages 表示我们要申请的 Page 规格(8K)
private long splitLargeRun(long handle, int needPages) {
assert needPages > 0;
// handle 中包含的 pages 个数(512)
int totalPages = runPages(handle);
// 剩余 511 个 Page
int remPages = totalPages - needPages;
if (remPages > 0) {
// handle 的 runOffset 为 0
int runOffset = runOffset(handle);
// 获取剩余内存块在 chunk 中的 runOffset (1)
// [runOffset , availOffset - 1] 这段内存将会被分配出去
int availOffset = runOffset + needPages; // 1
// 将剩余的内存块重新包装成 Run,runOffset = 1 ,size = 511
long availRun = toRunHandle(availOffset, remPages, 0);
// 将剩余的 run, 重新放回到伙伴系统 runsAvail 中
// 注意这里并不会向内核那样减半分裂,而是直接将 run 放回到 remPages 内存规格对应的 runsAvail 数组中
insertAvailRun(availOffset, remPages, availRun);
// 将 needPages 分配出去
return toRunHandle(runOffset, needPages, 1);
}
// mark it as used
handle |= 1L << IS_USED_SHIFT;
return handle;
}
PoolChunk 内存分配的总体逻辑如下:
// runSize 为申请的内存大小
private long allocateRun(int runSize) {
// 计算 runSize 包含多少个 pages
int pages = runSize >> pageShifts;
// 获取该 pages 尺寸对应在 pageIdx2sizeTab 中的 pageIdx
int pageIdx = arena.sizeClass.pages2pageIdx(pages);
runsAvailLock.lock();
try {
// 按照伙伴算法,从 pageIdx 开始在 runsAvail 数组中查找第一个不为空的 IntPriorityQueue
int queueIdx = runFirstBestFit(pageIdx);
// chunk 已经没有剩余内存了,返回 -1
if (queueIdx == -1) {
return -1;
}
// 获取 queueIdx 对应内存规格的 IntPriorityQueue
IntPriorityQueue queue = runsAvail[queueIdx];
// 获取内存地址最低的一个 run, 内存尺寸为 pageIdx2sizeTab[queueIdx]
long handle = queue.poll();
assert handle != IntPriorityQueue.NO_VALUE;
// runOffset(15bits) , size(15bits) , isUsed(1bit), isSubPapge(1bit) , bitmapIndex(32bits)
handle <<= BITMAP_IDX_BIT_LENGTH;
assert !isUsed(handle) : "invalid handle: " + handle;
// 从 runsAvailMap 中删除该 run 的 offset 信息
removeAvailRun0(handle);
// 如果该 run 尺寸恰好和我们请求的 runSize 一致,那么就直接分配
// 如果该 run 尺寸大于我们请求的 runSize , 就需要将剩余的内存块放入到对应规格的 runsAvail 中
handle = splitLargeRun(handle, pages);
int pinnedSize = runSize(pageShifts, handle);
// 相应减少 chunk 的剩余内存统计
freeBytes -= pinnedSize;
return handle;
} finally {
runsAvailLock.unlock();
}
}
4.2 PoolChunk 的内存回收流程
经过上一小节的内存分配流程之后,现在 PoolChunk 的结构如下图所示,只有一个大小为 511 个 Page 的 Run , 保存在 runsAvail[30] 中。
现在我们将刚刚申请到的这个 8K 的内存块重新释放回 PoolChunk 中,8K 在 Netty 的 Page 规格表中的 pageIndex 为 0 ,但和内存分配流程不同的是,这 8K 的内存块不能直接释放回 runsAvail[0] 中。
而是首先需要根据前面我们介绍的 runsAvailMap,在整个 PoolChunk 中不断的向前,向后查找与其连续的 Run ,然后将所有连续的 Run 合并成一个更大的 Run 释放到相应规格的 runsAvail 中。
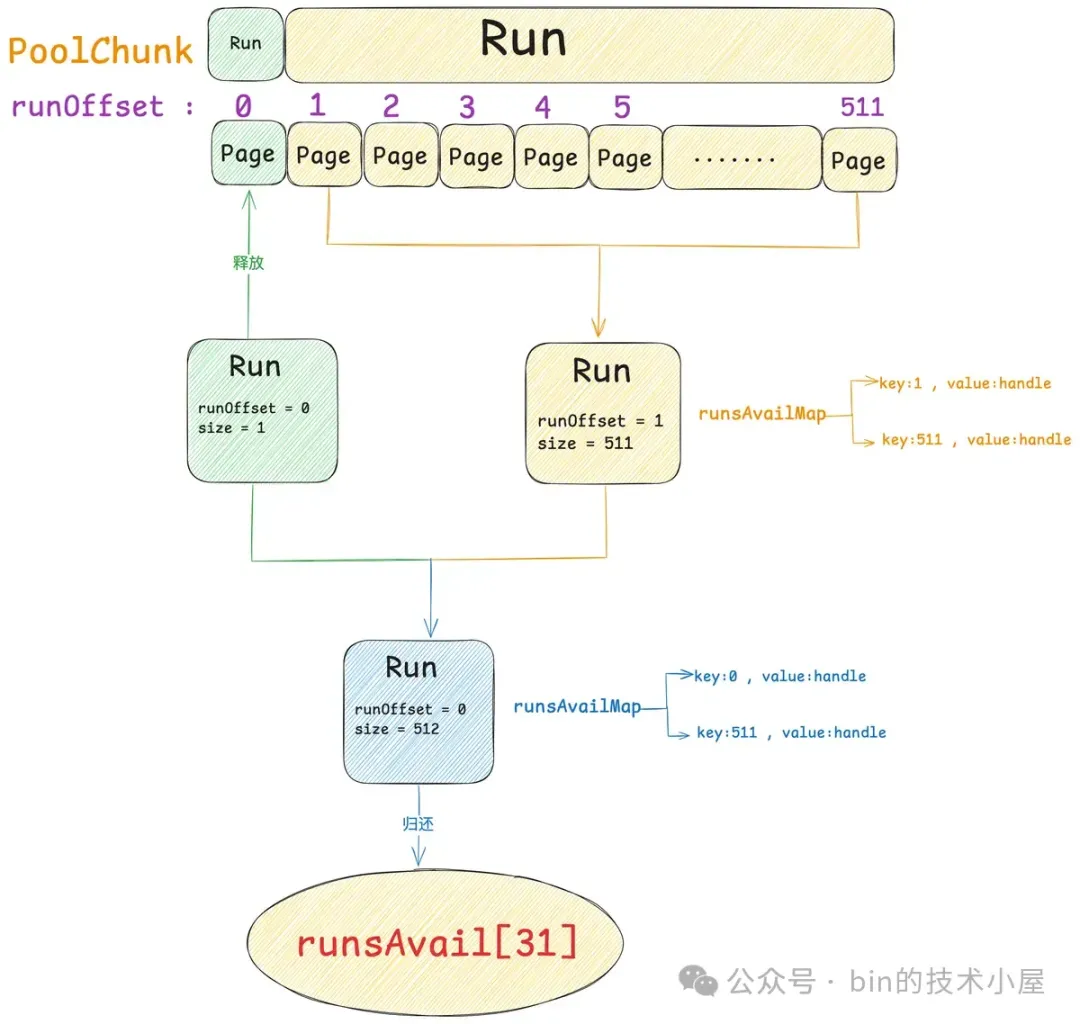
上图中绿色 Run 是我们要释放的 8K 内存块,因为它的 runOffset 为 0 ,是整个 PoolChunk 中第一个 Run ,所以无法向前合并。但此时 PoolChunk 有一个黄色的 Run 与其紧紧相邻,所以绿色 Run 需要与黄色的 Run 合并成一个更大的蓝色 Run。
这样一来就重新合并成了一个 4M 的 Run,归还到 runsAvail[31] , 一切又回到了最初的起点。
// handle 表示要释放的内存块
// nioBuffer 是 PooledByteBuf 底层依赖的 PoolChunk 中 memory 的 duplicate 视图
// PooledByteBuf 用于包装 handle 给用户使用
void free(long handle, int normCapacity, ByteBuffer nioBuffer) {
// 获取要释放内存块大小,字节为单位
int runSize = runSize(pageShifts, handle);
// start free run
runsAvailLock.lock();
try {
// 在 PoolChunk 不断的向前,向后合并连续的 Run
long finalRun = collapseRuns(handle);
// 重置 isUsed 位 = 0
finalRun &= ~(1L << IS_USED_SHIFT);
// 重置 isSubpage 位 = 0
finalRun &= ~(1L << IS_SUBPAGE_SHIFT);
// 将合并后的 finalRun 重新插入到伙伴系统中
insertAvailRun(runOffset(finalRun), runPages(finalRun), finalRun);
// 更新 PoolChunk 剩余内存的统计计数
freeBytes += runSize;
} finally {
runsAvailLock.unlock();
}
// 将 nioBuffer 缓存到 cachedNioBuffers 中
if (nioBuffer != null && cachedNioBuffers != null &&
cachedNioBuffers.size() < PooledByteBufAllocator.DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK) {
// 默认可以缓存 1023 个 nioBuffer(全部都是 PoolChunk 的 duplicates 视图)
cachedNioBuffers.offer(nioBuffer);
}
}
5. PoolChunkList 的设计与实现
内存池中的 PoolChunk 并不是一个一个孤立存在的,而是被 PoolArena 按照内存使用率的不同组织在六个 PoolChunkList 中。
abstract class PoolArena<T> {
// 按照不同内存使用率组织 PoolChunk
private final PoolChunkList<T> q050; // [50% , 100%)
private final PoolChunkList<T> q025; // [25% , 75%)
private final PoolChunkList<T> q000; // [1% , 50%)
private final PoolChunkList<T> qInit; // [0% , 25%)
private final PoolChunkList<T> q075; // [75% , 100%)
private final PoolChunkList<T> q100; // 100%
}
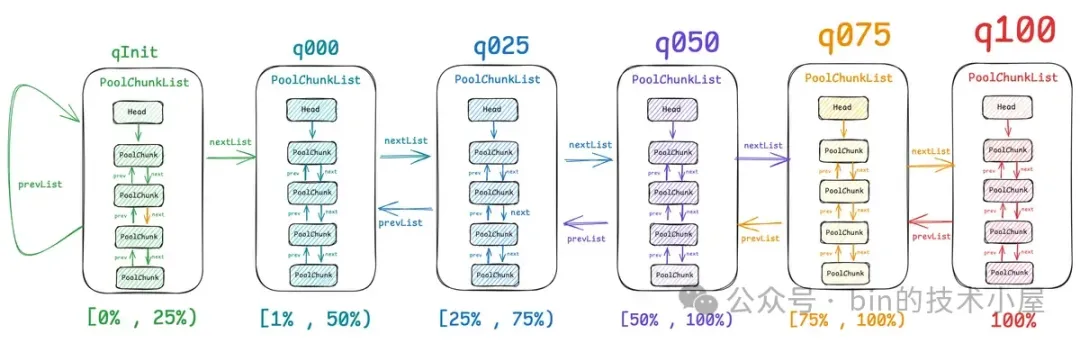
这六个 PoolChunkList 通过一个双向链表相互关联起来。
final class PoolChunkList<T> {
// 头指针,指向 List 中第一个 PoolChunk
private PoolChunk<T> head;
// 指向前一个 PoolChunkList
private PoolChunkList<T> prevList;
// 指向后一个 PoolChunkList
private final PoolChunkList<T> nextList;
}
每一个 PoolChunkList 都规定了被其管理的 PoolChunk 内存使用率的上限和下限,随着内存分配的不断进行,PoolChunk 的内存使用率会越来越高,当达到上限时,就会被移动到下一个 PoolChunkList 中。而随着内存释放的不断进行,PoolChunk 的内存使用率会越来越低,当低于下限时,就会被移动到前一个 PoolChunkList 中。
这里比较特殊的两个 PoolChunkList 是 qInit 和 q000 , q000 的前驱节点指向 null , 也就是说 q000 中的 PoolChunk 内存利用率只要低于 1% 就会被 Netty 释放回 OS , 这里设计 q000 的目的就是使得那些内存申请不那么频繁的 PoolChunk 能够被及时的释放掉,既然这些 PoolChunk 中内存使用的并不频繁,那么低于 1% 直接释放就好了,没必要继续停留在内存池中,增加不必要的内存消耗。
protected PoolArena(PooledByteBufAllocator parent, SizeClasses sizeClass) {
// 按照不同内存使用率范围划分 PoolChunkList
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, sizeClass.chunkSize);// [100 , 2147483647]
q075 = new PoolChunkList<T>(this, q100, 75, 100, sizeClass.chunkSize);
q050 = new PoolChunkList<T>(this, q075, 50, 100, sizeClass.chunkSize);
q025 = new PoolChunkList<T>(this, q050, 25, 75, sizeClass.chunkSize);
q000 = new PoolChunkList<T>(this, q025, 1, 50, sizeClass.chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, sizeClass.chunkSize);// [-2147483648 , 25]
// 双向链表组织 PoolChunkList
// 其中比较特殊的是 q000 的前驱节点指向 NULL
// qInit 的前驱节点指向它自己
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
}
qInit 的前驱节点指向它自己,也就是说 qInit 中的 PoolChunk 内存利用率低于 0% 时,仍然会继续留在 qInit 中,不会被释放。这里设计 qInit 的目的就是始终让内存池至少有一个 PoolChunk,避免不必要的重复创建 PoolChunk。
// minUsage 为 PoolChunkList 中内存使用率的下限,单位是百分比
// maxUsage 为 PoolChunkList 中内存使用率的上限,单位是百分比
PoolChunkList(PoolArena<T> arena, PoolChunkList<T> nextList, int minUsage, int maxUsage, int chunkSize) {
// 所属 PoolArena
this.arena = arena;
// 下一个 PoolChunkList
this.nextList = nextList;
// 该 PoolChunkList 中的 PoolChunk 内存占用率在 [minUsage , maxUsage)
// 当 PoolChunk 中的内存占用率低于 minUsage 则将它移动到前一个 PoolChunkList 中 (prevList)
// 当 PoolChunk 中的内存占用率达到 maxUsage 则将它移动到后一个 PoolChunkList 中 (nextList)
this.minUsage = minUsage;
this.maxUsage = maxUsage;
// 计算该 PoolChunkList 中的 PoolChunk 可以分配出去的最大内存容量 ,单位为 byte
// chunkSize * (100L - minUsage) / 100L)
maxCapacity = calculateMaxCapacity(minUsage, chunkSize);
// 将内存使用率的上限和下限转换成对应的阈值
// PoolChunk 停留在 PoolChunkList 中的剩余内存最低阈值,达到该阈值则向后移动到 nextList
freeMinThreshold = (maxUsage == 100) ? 0 : (int) (chunkSize * (100.0 - maxUsage + 0.99999999) / 100L);
// PoolChunk 停留在 PoolChunkList 中的剩余内存最高阈值,高于该阈值则向前移动到 prevList
freeMaxThreshold = (minUsage == 100) ? 0 : (int) (chunkSize * (100.0 - minUsage + 0.99999999) / 100L);
}
这里我们需要将 PoolChunkList 的内存使用率上下限转换为对应的具体阈值,比如,maxUsage 表示的是 PoolChunkList 的内存使用率上限,PoolChunk 的内存使用率达到上限之后,就会被向后移动到下一个 PoolChunkList 。
但在具体的程序实现上,我们不可能直接用百分比来做这个判断,所以需要将 maxUsage 转换为 PoolChunk 停留在 PoolChunkList 中的剩余内存最低阈值 freeMinThreshold,当 PoolChunk 的剩余内存达到 freeMinThreshold 时,就会被向后移动到下一个 PoolChunkList。
同样的道理,这里也需要将 minUsage 转换为 PoolChunk 停留在 PoolChunkList 中的剩余内存最高阈值 freeMaxThreshold,当 PoolChunk 的剩余内存高于 freeMaxThreshold 时,就会被向前移动到上一个 PoolChunkList。
5.1 PoolChunkList 的内存分配流程
当我们向内存池申请 Normal 规格的内存块或者 PoolSubpage 的时候,Netty 首先会从 q050 中选择一个 PoolChunk 来分配内存,如果 q050 是空的,或者我们申请的内存尺寸太大,q050 中的 PoolChunk 无法满足,则继续按照 q025 > q000 > qInit > q075 这样的顺序来选择 PoolChunkList 分配内存。这么设计的目的,笔者在第一小节中已经介绍过了,核心就是为了让每个 PoolChunk 的服务周期更长一些。
如果这 6 个 PoolChunkList 全都无法满足本次内存的申请,那么 Netty 就会重新向 OS 申请一个 PoolChunk 分配内存,最后将这个新的 PoolChunk 加入到 qInit 中。
abstract class PoolArena<T> {
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) {
if (q050.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q025.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q000.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
qInit.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q075.allocate(buf, reqCapacity, sizeIdx, threadCache)) {
return;
}
// Add a new chunk.
PoolChunk<T> c = newChunk(sizeClass.pageSize, sizeClass.nPSizes, sizeClass.pageShifts, sizeClass.chunkSize);
boolean success = c.allocate(buf, reqCapacity, sizeIdx, threadCache);
qInit.add(c);
}
}
在进入 PoolChunkList 分配内存之前,我们首先需要判断该 PoolChunkList 中的 PoolChunk 能够提供的最大内存容量 maxCapacity —— chunkSize * (100L - minUsage) / 100L) 是否能够满足本次内存的申请。
如果连 maxCapacity 都无法满足,那么就按照 PoolChunkList 的分配顺序到下一个 PoolChunkList 去申请。
final class PoolChunkList<T> {
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) {
int normCapacity = arena.sizeClass.sizeIdx2size(sizeIdx);
if (normCapacity > maxCapacity) {
// 申请的内存尺寸太大,本 PoolChunkList 无法满足
return false;
}
// 挨个遍历 PoolChunkList 中的 PoolChunk,直到内存分配成功
for (PoolChunk<T> cur = head; cur != null; cur = cur.next) {
if (cur.allocate(buf, reqCapacity, sizeIdx, threadCache)) {
// PoolChunk 的剩余内存达到最小阈值,则向后移动
if (cur.freeBytes <= freeMinThreshold) {
remove(cur);
nextList.add(cur);
}
return true;
}
}
// 内存分配失败
return false;
}
}
如果 maxCapacity 可以满足,则从 PoolChunkList 的头结点开始挨个遍历,直到找到一个 PoolChunk 能够完成本次的内存分配任务。当内存分配成功之后,PoolChunk 中的内存使用率会近一步上升,如果剩余内存容量达到了最小阈值 —— freeMinThreshold,也就是说 PoolChunk 中的内存使用率达到了上限,那么就会将该 PoolChunk 从当前的 PoolChunkList 中移除。
private void remove(PoolChunk<T> cur) {
if (cur == head) {
head = cur.next;
if (head != null) {
head.prev = null;
}
} else {
PoolChunk<T> next = cur.next;
cur.prev.next = next;
if (next != null) {
next.prev = cur.prev;
}
}
}
然后将 PoolChunk 向后移动到下一个 PoolChunkList 中,但 nextList 也有自己的内存使用率范围限制,所以还需要再次判断 PoolChunk 的内存使用率是否达到了 nextList 的上限,如果达到,则继续向后移动,直到移动到 q100 为止。
void add(PoolChunk<T> chunk) {
if (chunk.freeBytes <= freeMinThreshold) {
nextList.add(chunk);
return;
}
add0(chunk);
}
如果 PoolChunk 的内存使用率在 nextList 的限定范围内,那么就将 PoolChunk 加入到 nextList 中(头插法)。
void add0(PoolChunk<T> chunk) {
chunk.parent = this;
if (head == null) {
head = chunk;
chunk.prev = null;
chunk.next = null;
} else {
chunk.prev = null;
chunk.next = head;
head.prev = chunk;
head = chunk;
}
}
5.2 PoolChunkList 的内存回收流程
当一个 Run 被释放回 PoolChunk 的时候,那么随着内存释放的不断进行,这个 PoolChunk 中的内存使用率会不断的降低,当内存使用率低于其所在 PoolChunkList 的下限时,也就是说 PoolChunk 中的剩余内存容量高于了最大阈值 —— freeMaxThreshold,那么这个 PoolChunk 就需要向前移动到上一个 prevList 中。
final class PoolChunkList<T> {
boolean free(PoolChunk<T> chunk, long handle, int normCapacity, ByteBuffer nioBuffer) {
// 内存块 handle 释放回 PoolChunk
chunk.free(handle, normCapacity, nioBuffer);
// PoolChunk 中的内存使用率低于该 PoolChunkList 的下限
if (chunk.freeBytes > freeMaxThreshold) {
remove(chunk);
// 将 PoolChunk 移动到前一个 PoolChunkList 中
return move0(chunk);
}
return true;
}
}
但如果该 PoolChunk 原本所在的 PoolChunkList 是 q000 ,当 PoolChunk 的内存使用率低于 1% 之后,那么这个 PoolChunk 将不会继续向前移动,而是直接被 Netty 释放回 OS 中。
private boolean move0(PoolChunk<T> chunk) {
// 该 PoolChunkList 是 q000 的情况
if (prevList == null) {
// 返回 false, 后续 Netty 会将该 PoolChunk 释放回 OS
return false;
}
// 其他情况下,PoolChunk 则向前移动
return prevList.move(chunk);
}
这里还有一种特殊情况是,如果该 PoolChunk 原本所在的 PoolChunkList 是 qInit,那么即使这个 PoolChunk 的内存使用率低于 0% 了,Netty 仍然会让它继续停留在 qInit 中,但会将这个 PoolChunk 重新调整到 qInit 中的头结点处。
剩下的情况, PoolChunk 将会向前移动,但 prevList 也有自己的内存使用率范围限制,如果这个 PoolChunk 的内存使用率仍然低于 prevList 的下限,那么将会继续向前移动,直到移动到 q000 中。
private boolean move(PoolChunk<T> chunk) {
if (chunk.freeBytes > freeMaxThreshold) {
// PoolChunk 的内存使用率仍然低于 prevList 的下限,继续向前移动
return move0(chunk);
}
// PoolChunk fits into this PoolChunkList, adding it here.(头插法)
add0(chunk);
return true;
}
6. PoolSubpage 的设计与实现
经过前面第一小节的介绍,我们多多少少已经对 PoolSubpage 的设计有了一定的了解,PoolSubpage 在内存池中主要负责分配 Small 规格的内存块,其本质其实还是一个 Run ,内部包含了一个或者多个 Page 。
其核心设计思想是首先向 PoolChunk 申请到一个 Run , 然后按照 Small 规格将这个 Run 划分成多个大小相等的小内存块,每次申请时从 PoolSubpage 获取一个小内存块,每次释放时,将小内存块释放回对应的 PoolSubpage 中。
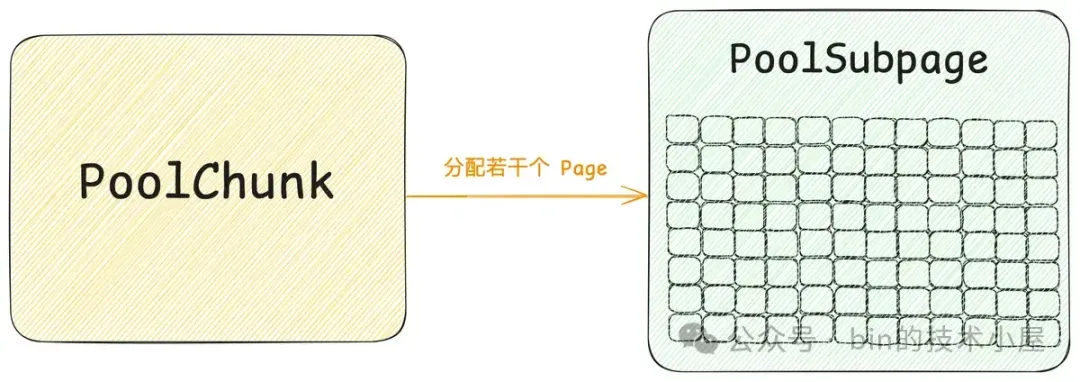
每一种 Small 内存规格在内存池中都会对应一个 PoolSubpage 的双向循环链表,链表中的 PoolSubpage 组织管理的全部都是对应 Small 规格的小内存块。
final class PoolSubpage<T> {
PoolSubpage<T> prev;
PoolSubpage<T> next;
}
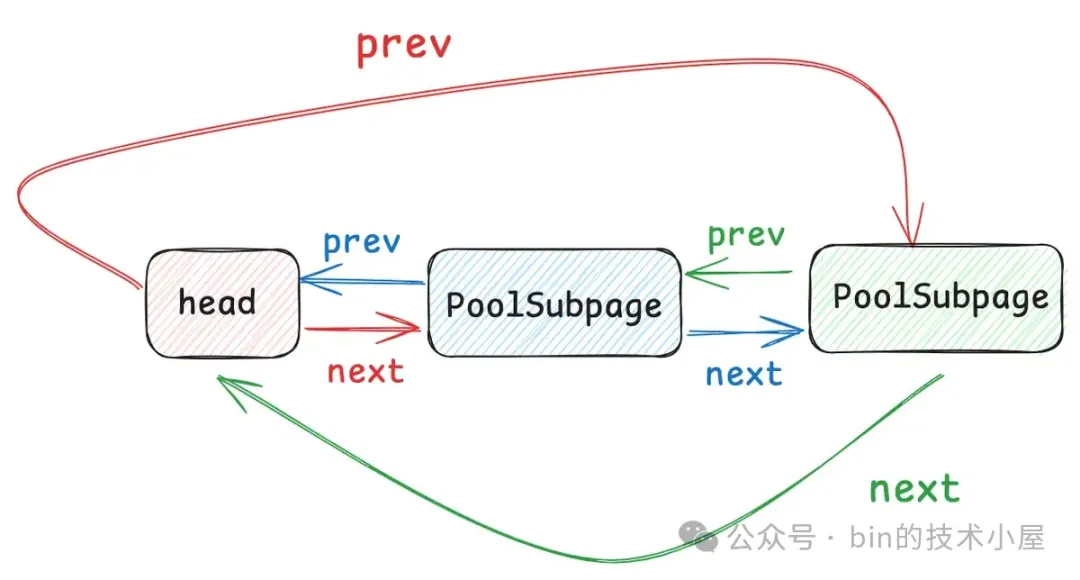
Netty 一共设计了 39 种 Small 规格尺寸 —— [16B , 28k] , 所以内存池中也就对应了 39 个 PoolSubpage 的双向循环链表,每个链表负责管理对应 Small 规格的内存块,这些链表被 PoolArena 组织在 smallSubpagePools 数组中, 数组的下标就是对应的 Small 规格在 SizeClasses 内存规格表中的 index 。
abstract class PoolArena<T> {
// 管理 Small 规格内存块的核心数据结构
final PoolSubpage<T>[] smallSubpagePools;
}
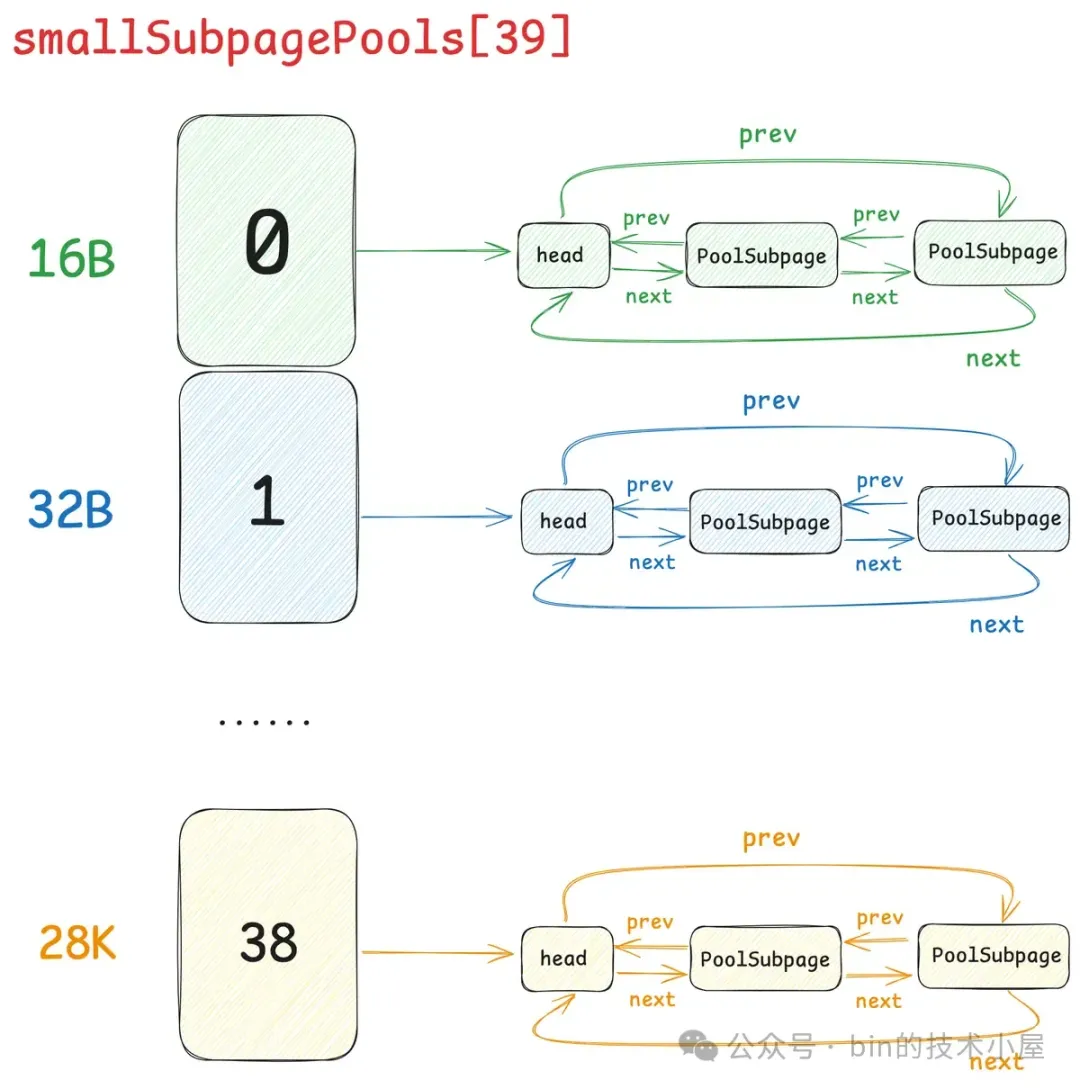
当内存池刚刚被创建出来的时候,smallSubpagePools 数组中的链表都还是空的,只包含一个头结点,没有任何的 PoolSubpage。
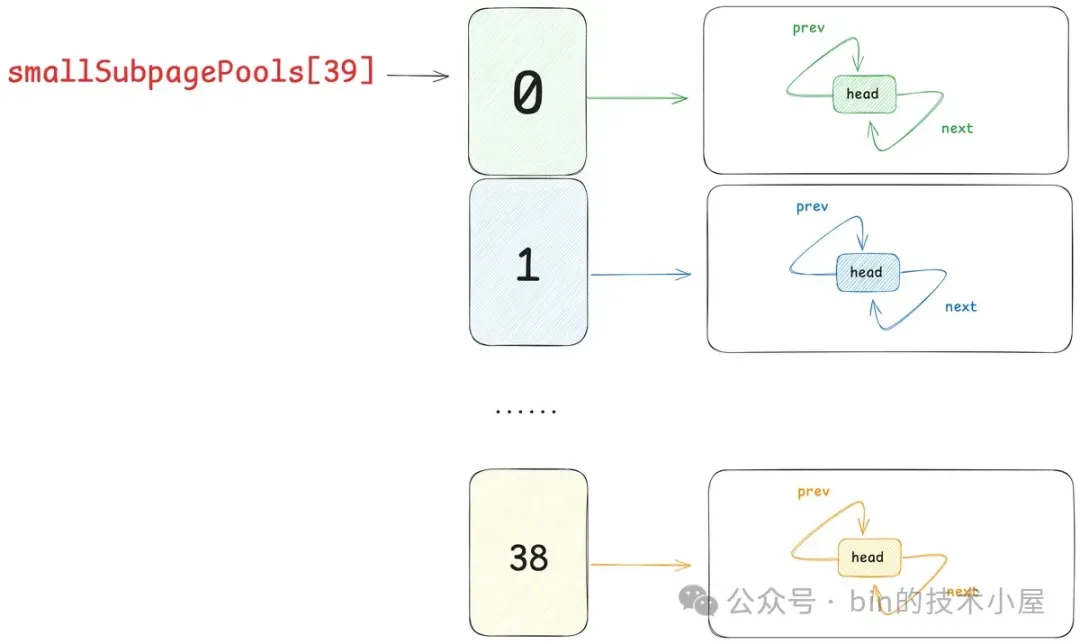
所以当我们第一次向内存池申请 Small 规格内存块的时候,首先需要到 PoolChunk 中申请一个 PoolSubpage 出来,那么我们究竟该申请多大的 PoolSubpage 呢 ?
Netty 会取 Small 规格尺寸与 PageSize 的最小公倍数来作为 PoolSubpage 的尺寸。比如,我们申请一个 16 字节的内存块,那么对应的 PoolSubpage 大小就是 1 个 Page,里面可以容纳 512 个 16B 的小内存块 Element。
// Small 规格对应的 sizeIdx(规格 sizeIndex)
private int calculateRunSize(int sizeIdx) {
// 一个 page 最大可以容纳多少个内存块(Element)
// pageSize / 16(最小内存块尺寸)
int maxElements = 1 << pageShifts - SizeClasses.LOG2_QUANTUM;
int runSize = 0;
int nElements;
// sizeIdx 对应的内存规格,PoolSubpage 将会按照 elemSize 进行切分
final int elemSize = arena.sizeClass.sizeIdx2size(sizeIdx);
// 查找 pageSize 与 elemSize 的最小公倍数
do {
runSize += pageSize;
nElements = runSize / elemSize;
} while (nElements < maxElements && runSize != nElements * elemSize);
// PoolSubpage 切分出的内存块个数不能超过 maxElements(512)
while (nElements > maxElements) {
// runSize 太大了,缩减到 nElements <= maxElements
runSize -= pageSize;
nElements = runSize / elemSize;
}
// PoolSubpage 的最终尺寸
return runSize;
}
随后 Netty 会向 PoolChunk 申请一个 runSize 大小的 Run,然后封装成 PoolSubpage,并从 PoolSubpage 中分配一个小内存块出来。
final class PoolChunk {
private long allocateSubpage(int sizeIdx, PoolSubpage<T> head) {
// 计算 PoolSubpage 的尺寸,取对应的 Small 规格与 PageSize 的最小公倍数
int runSize = calculateRunSize(sizeIdx);
// 从 PoolChunk 申请一个 runSize 大小的 PoolSubpage
long runHandle = allocateRun(runSize);
if (runHandle < 0) {
return -1;
}
int runOffset = runOffset(runHandle);
// 对应的 Small 内存规格
int elemSize = arena.sizeClass.sizeIdx2size(sizeIdx);
// 根据 runHandle 创建 PoolSubpage
PoolSubpage<T> subpage = new PoolSubpage<T>(head, this, pageShifts, runOffset,
runSize(pageShifts, runHandle), elemSize);
// 将 PoolSubpage 保存在 PoolChunk 的 subpages 数组中
subpages[runOffset] = subpage;
// 从 PoolSubpage 分配一个小内存块出去
return subpage.allocate();
}
}
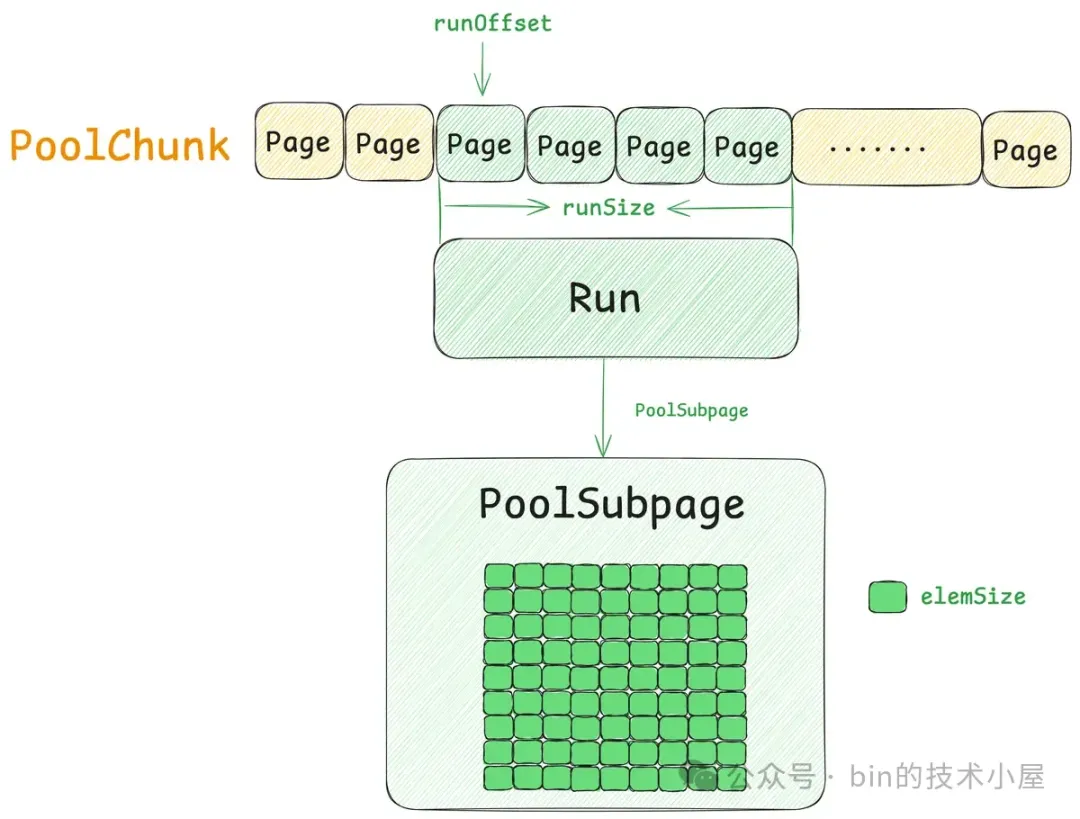
final class PoolSubpage {
// head 表示该 PoolSubpage 在 smallSubpagePools 对应规格链表的头结点
// 每个 PoolSubpage 链表都对应一个头结点
// elemSize 表示需要被管理的 Small 规格尺寸
PoolSubpage(PoolSubpage<T> head, PoolChunk<T> chunk, int pageShifts, int runOffset, int runSize, int elemSize) {
// 该 PoolSubpage 管理的 elemSize 对应的 sizeIndex
// 比如 16B 对应的 sizeIndex 是 0
this.headIndex = head.headIndex;
// PoolSubpage 所属的 PoolChunk
this.chunk = chunk;
// 13
this.pageShifts = pageShifts;
// PoolSubpage 在 PoolChunk 中的起始偏移( page 粒度)
this.runOffset = runOffset;
// PoolSubpage 大小(字节单位)
this.runSize = runSize;
// PoolSubpage 管理的 Small 规格内存块大小
this.elemSize = elemSize;
doNotDestroy = true;
// PoolSubpage 管理的内存块个数
maxNumElems = numAvail = runSize / elemSize;
// 创建一个 bitmap ,用于管理 PoolSubpage 中所有小内存块的状态
// 以及索引这些小内存块在 PoolSubpage 中的位置
int bitmapLength = maxNumElems >>> 6;
if ((maxNumElems & 63) != 0) {
bitmapLength ++;
}
this.bitmapLength = bitmapLength;
bitmap = new long[bitmapLength];
// 下一个可用内存块对应的 bitmapIndex,初始为 0
nextAvail = 0;
// 将该 Subpage 采用头插法插入到对应规格的 smallSubpagePools 中
addToPool(head);
}
}
PoolSubpage 最为核心的一个数据结构就是这个 bitmap , PoolSubpage 的主要职责就是负责组织管理众多 Small 规格的小内存块,而每一个小内存块的分配状态及其在 PoolSubpage 的位置偏移,就要靠这里的 bitmap 来标识。
final class PoolSubpage {
private final long[] bitmap;
private final int bitmapLength;
}
我们看到 PoolSubpage 中的这个 bitmap 是一个 long 型的数组,Netty 用 1 个 bit 来标识小内存块的分配状态:0 表示未分配, 1 表示已分配。也就是说 Netty 用 1 个 bit 来表示 PoolSubpage 中的一个小内存块。
这样一来 bitmap 数组中的一个元素(long)就可以表示 64 个小内存块,那么这个 bitmap 数组的长度应该设置多少呢 ?
一个 PoolSubpage 的大小为 runSize , 其中的小内存块尺寸为 elemSize,我们可以通过 numAvail = runSize / elemSize 计算出 PoolSubpage 中一共可以管理 numAvail 个小内存块。
bitmap 数组中的一个元素可以表示 64 个小内存块,那么整个 bitmap 数组的长度就是 bitmapLength = maxNumElems >>> 6。这样一来,PoolSubpage 中的每一个小内存块都会对应一个唯一的 bitmapIndex 。
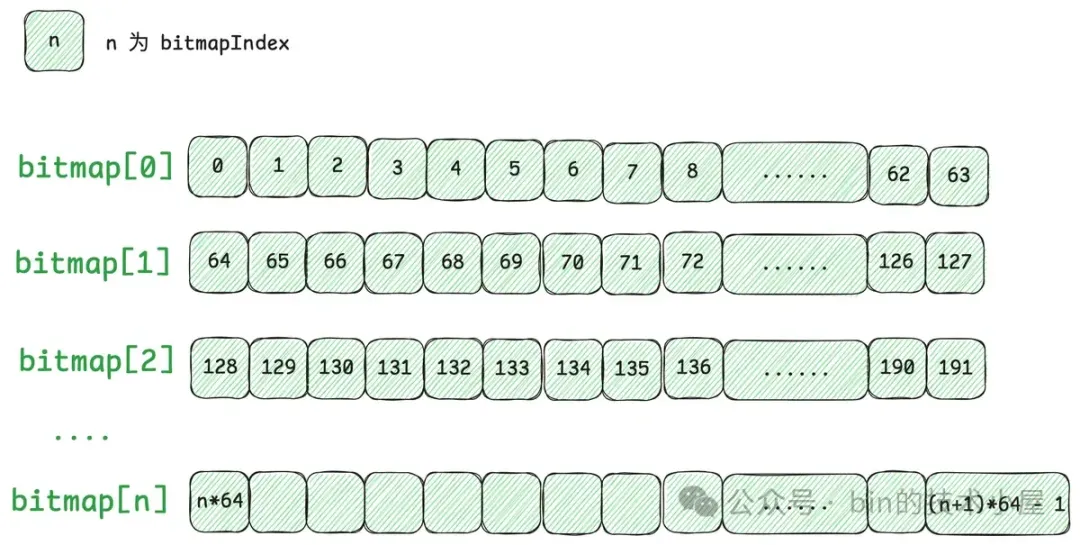
当我们从 PoolSubpage 中分配一个小内存块出去的时候,这个小内存块对应的 handle 结构低 32 位存储的就是内存块的 bitmapIndex。
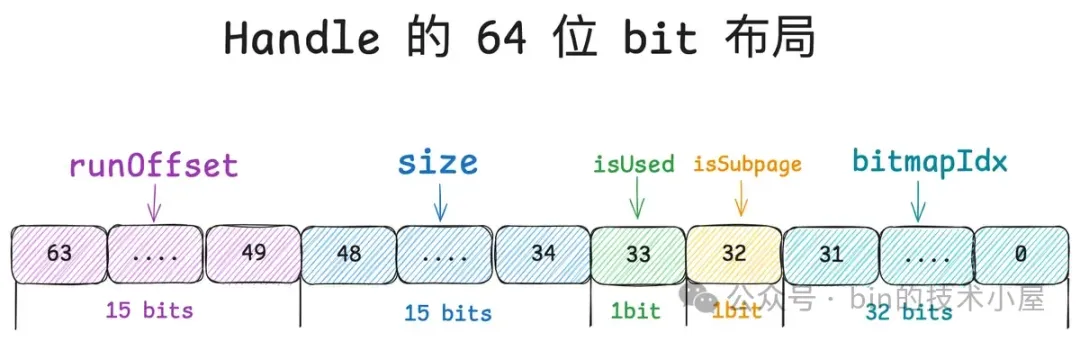
runOffset 表示的就是这个小内存块所在的 PoolSubpage 在 PoolChunk 中的偏移,size 表示的是这个 PoolSubpage 包含的 Page 个数,bitmapIndex 表示它是 PoolSubpage 中第几个内存块。
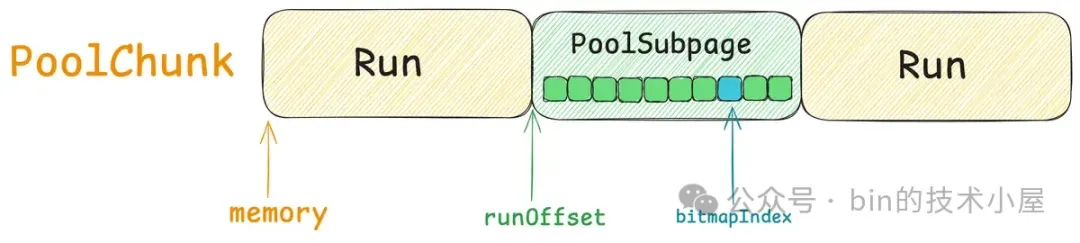
而 PoolChunk 的起始内存地址我们是知道的,就是前面提到的 memory , PoolSubpage 在 PoolChunk 中的 runOffset 也有了,那么 PoolSubpage 的起始内存地址我们也就知道了 ——memory + (runOffset << pageShifts)。
Small 规格的内存块在 PoolSubpage 中的 bitmapIndex 也有,那么这个小内存块的起始内存地址也就知道了 —— memory + (runOffset << pageShifts) + bitmapIdx * elemSize。
现在 Small 规格内存块的起始内存地址有了,大小 elemSize 也有了,那么对应的 PooledByteBuf 相关的 index 就可以设置了,随后将这个 PooledByteBuf 返回给用户就可以直接使用了。
6.1 PoolSubpage 的内存分配流程
当一个新的 PoolSubpage 创建出来之后,它就会被加入到 smallSubpagePools 对应规格的 PoolSubpage 链表中(头插法)。
final class PoolSubpage {
private void addToPool(PoolSubpage<T> head) {
prev = head;
next = head.next;
next.prev = this;
head.next = this;
}
}
比如 16B 在内存规格表中的 index 是 0 ,那么其对应的 PoolSubpage 在刚被创建出来之后,就会插入到 smallSubpagePools[0] 中,如下图所示:
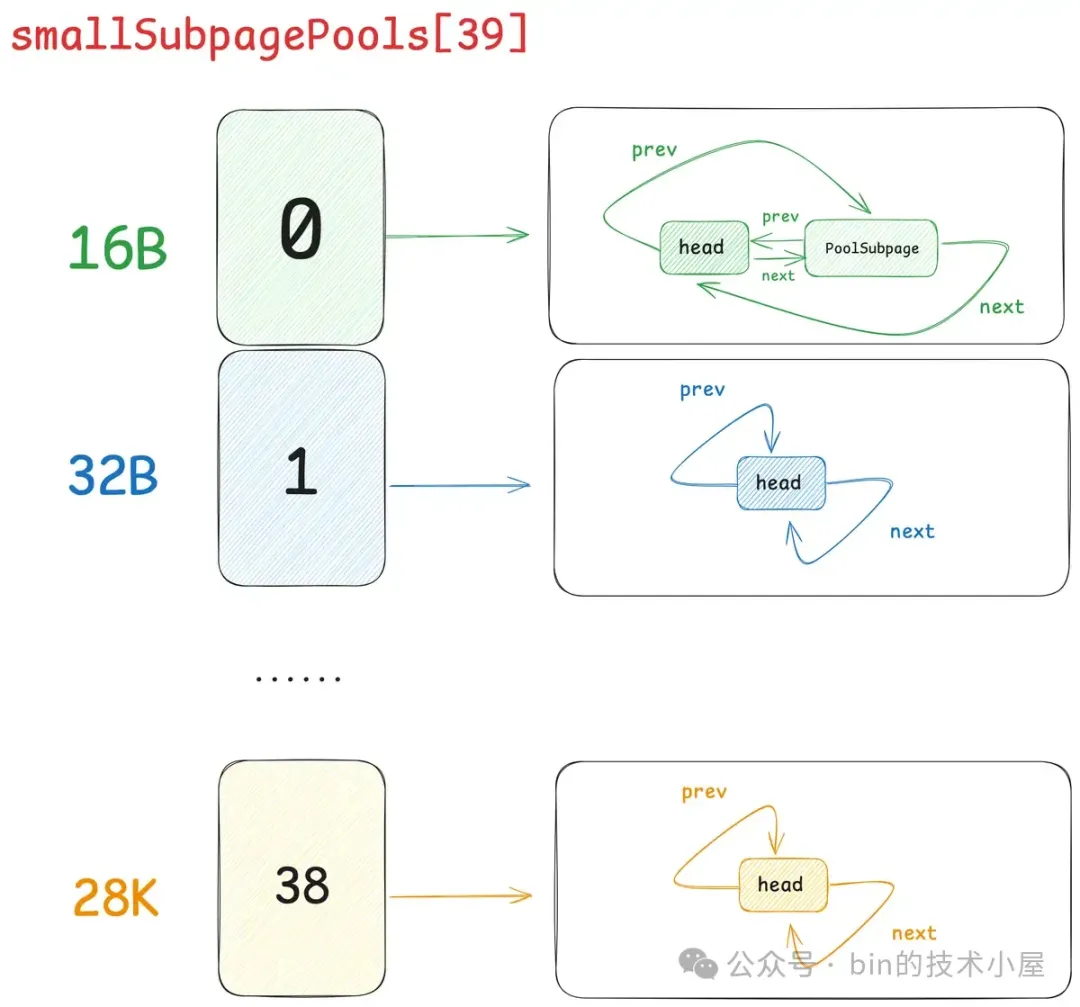
当我们向内存池申请 Small 规格的内存块时,内存池走的是 smallSubpagePools 来分配。首先我们需要到内存规格表中获取对应 Small 规格的 sizeIndex , 然后到 smallSubpagePools[sizeIndex] 中获取链表中第一个 PoolSubpage 来分配小内存块。
比如我们要向内存池申请一个 16B 大小的内存块,而 16B 在内存规格表中的 sizeIndex 是 0 ,那么我们就到 smallSubpagePools[0] 去获取对应的 PoolSubpage,然后从这个 PoolSubpage 中获取一个 16B 大小的内存块。
final class PoolChunk {
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache cache) {
// 待分配内存块
final long handle;
// 分配 Small 规格的内存块走 smallSubpagePools
if (sizeIdx <= arena.sizeClass.smallMaxSizeIdx) {
final PoolSubpage<T> nextSub;
// 获取对应规格 PoolSubpage 链表的头结点
PoolSubpage<T> head = arena.smallSubpagePools[sizeIdx];
head.lock();
try {
nextSub = head.next;
// 如果链表为空,那么 head.next 指向的是自己
if (nextSub != head) {
// 始终从链表中第一个 PoolSubpage 开始分配
handle = nextSub.allocate();
// 将对应 Small 规格的内存块封装成 PooledByteBuffer 返回
nextSub.chunk.initBufWithSubpage(buf, null, handle, reqCapacity, cache);
return true;
}
// 链表为空,则到 PoolChunk 中重新申请一个 PoolSubpage
// 然后加入到 smallSubpagePools 对应规格的链表中
handle = allocateSubpage(sizeIdx, head);
if (handle < 0) {
return false;
}
assert isSubpage(handle);
} finally {
head.unlock();
}
} else {
...... 分配 Normal 规格内存块走 PoolChunk ......
}
// 获取 PoolChunk 的 memory.duplicate() 视图缓存
ByteBuffer nioBuffer = cachedNioBuffers != null? cachedNioBuffers.pollLast() : null;
// nioBuffer 为 null 的话,后续访问 PooledByteBuffer 的时候通过 memory.duplicate() 创建
// 将 handle 封装成 PooledByteBuffer 返回
initBuf(buf, nioBuffer, handle, reqCapacity, cache);
return true;
}
}
那么如何从 PoolSubpage 中获取内存块呢 ?首先 PoolSubpage 的本质其实就是 PoolChunk 中的一个 Run ,里边包含了一个或者若干个 Page ,然后 Netty 会把这个 Run 按照对应的 Small 规格尺寸切分成多个大小相同的内存块组织在这个 PoolSubpage 中。
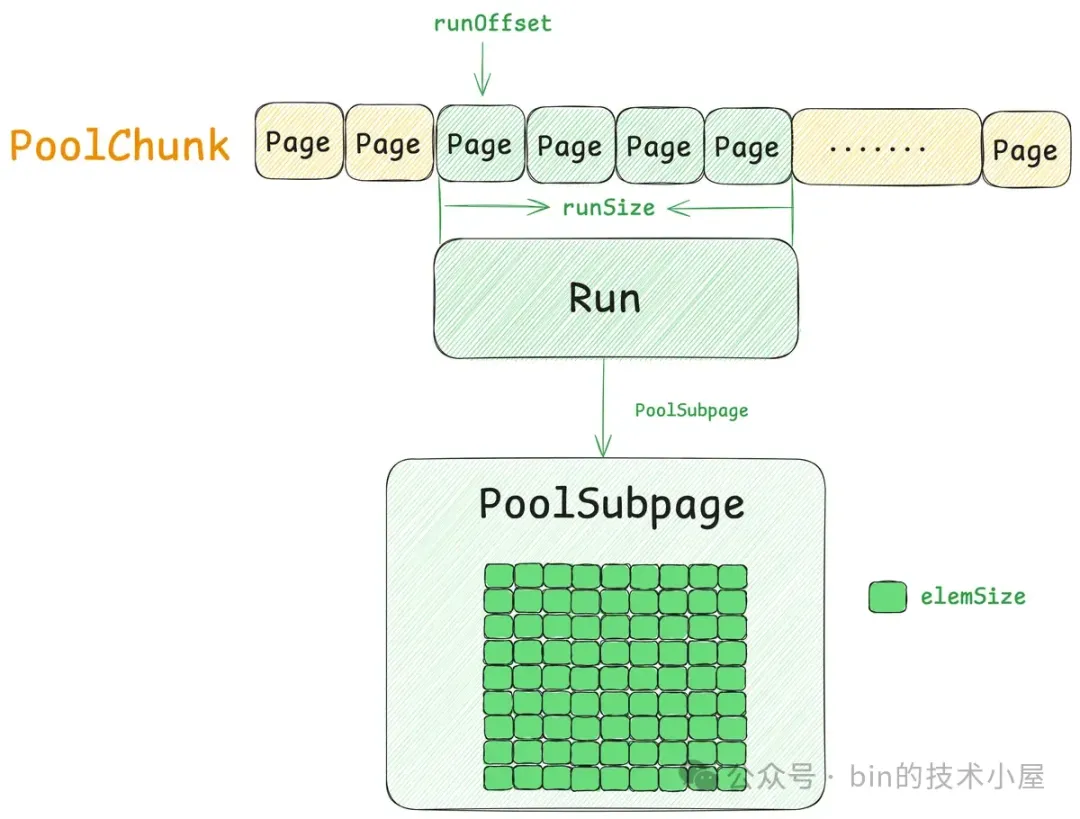
PoolSubpage 中每一个小内存块都会对应一个 bitmapIndex,用于标识其是 PoolSubpage 的第几个内存块。PoolSubpage 在 nextAvail 字段中缓存了下一个可供分配内存块的 bitmapIndex 。
在 PoolSubpage 的初始状态下,nextAvail 为 0 ,也就是说首先从 PoolSubpage 中的第一个内存块开始分配。除此之外,Netty 为了保证局部性,总是偏向于分配最近刚刚被释放的内存块,如果一个内存块刚被释放回 PoolSubpage ,那么 nextAvail 就会被设置成这个刚刚被释放内存块的 bitmapIndex 。下次分配的时候直接从 nextAvail 中获取即可。
final class PoolSubpage {
private int nextAvail;
private int getNextAvail() {
// 初始为 0
int nextAvail = this.nextAvail;
if (nextAvail >= 0) {
this.nextAvail = -1;
return nextAvail;
}
// nextAvail 为 -1 ,表示此时没有刚被释放的内存块
// 那么就需要遍历 bitmap , 找到第一个为 0 的内存块 bitmapIndex
return findNextAvail();
}
}
nextAvail 缓存 bitmapIndex 的情况一个是初始状态下,另一个是有内存块刚刚被释放,剩下的情况 nextAvail 的值为 -1,这时我们就需要遍历 PoolSubpage 的 bitmap ,找到第一个为 0 的 bitmapIndex。
bitmapIndex 在 bitmap 中对应的 bit 位设置为 0 表示该内存块未分配,设置为 1 表示该内存块已经被分配出去了。
那么如何高效的遍历 bitmap 查找第一个为 0 的 bitmapIndex ? 我们知道 PoolSubpage 中的 bitmap 是一个 long 型数组结构,bitmap 中的每一个元素都是一个 long 型的整数,表示 64 个内存块,每个内存块用一个 bit 位来标识它的分配状态。
如果 bitmap 某一个元素,它的 64 位 bit 全为 1 ,对其取反,那么这个 long 型整数就是 0 ,表示对应的 64 个内存块已经全部被分配出去了。我们从 bitmap[0] 开始遍历,挨个对其取反,如果为 0 ,则表示 bitmap[0] 中的 64 个内存块已经全部分配了,我们就不用看了,继续对 bitmap[1] , bitmap[2] , … , bitmap[bitmapLength - 1] 执行取反操作,直到找到第一个取反后,值不为 0 的 bitmap 元素。那么就说明这个元素中一定至少有一个 bit 为 0 ,也就是说至少有一个内存块未被分配。
假设我们现在从下图所示的一个 PoolSubpage 中查找空闲内存块,该 PoolSubpage 只有一个空闲内存块,它的 bitmapIndex 为 67。
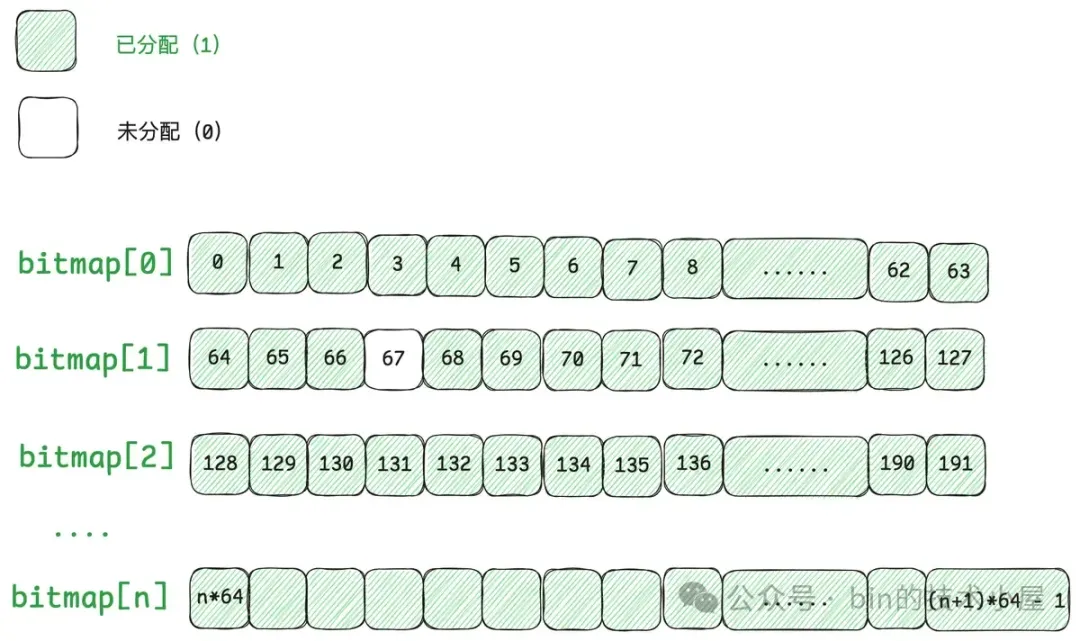
首先我们对 bitmap[0] 进行取反,由于 bitmap[0] 的 64 位 bit 全为 1 ,所以取反之后值为 0 ,我们就知道了,bitmap[0] 所表示的这 64 个内存块已经全部分配出去了。
于是我们继续对 bitmap[1] 进行取反,由于该 long 型整数的第 4 位 bit 为 0 ,所以对其取反之后,值肯定不是 0 。

这样我们就知道了,bitmap[1] 中肯定至少有一个 bit 为 0 , 也就是至少还有一个内存块未被分配。
private int findNextAvail() {
// 遍历 bitmap , 在 bitmap 中查找第一个还未全部分配出去的内存块 bitmapIndex
for (int i = 0; i < bitmapLength; i ++) {
long bits = bitmap[i];
// ~bits = 0 表示这个 long 表示的 64 个内存块已经全部分配出去了
// ~bits != 0 表示这个 long 中还有未被分配出去的内存块
if (~bits != 0) {
// 找出 bits 中具体哪一位为 0 ,也就是说具体哪一个内存块未被分配
return findNextAvail0(i, bits);
}
}
// subPage 中无内存块可用
return -1;
}
那么 bitmap[1] 中具体是哪一个 bit 为 0 呢 ?很简单,我们直接从 bitmap[1] 的最低位开始暴力遍历,挨个查看每一个 bit 是否为 0 —— (bit & 1) == 0,如上图所示,经过一通遍历之后,我们知道了原来是第 3 个 bit 为 0 (从 0 开始遍历计数)。1 * 64 + 3 就是这个内存块的 bitmapIndex (67) 。
private int findNextAvail0(int i, long bits) {
// i 表示 bitmap 数组的 index,也就是第几个 long,注意 i 并不是 bitmapIndex
// i * 64
final int baseVal = i << 6;
// 从 bitmap[i] 中第一个 bit 开始遍历查找
for (int j = 0; j < 64; j ++) {
// 检查 bits 的第一个 bit 是否为 0
if ((bits & 1) == 0) {
// j 表示现在检查到 bits 中的第几个 bit
// baseVal + j 表示该内存块的 bitmapIndex
int val = baseVal | j;
}
// 最低位 bit 检查完之后,右移一位,开始检查下一个 bit 是否为 0
bits >>>= 1;
}
return -1;
}
当我们找到了 PoolSubpage 第一个空闲内存块的 bitmapIndex 之后,就将其对应在 bitmap 中的 bit 位设置为 1 ,表示已被分配。当一个 PoolSubpage 中所有的内存块全部被分配出去之后,这个 PoolSubpage 就需要从 smallSubpagePools 中移除。
final class PoolSubpage {
long allocate() {
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
// 获取 subPage 下一个可用内存块的 bitmapIdx
final int bitmapIdx = getNextAvail();
// -1 表示 subPage 中所有内存块都已经被分配出去了(没有空闲内存块)
if (bitmapIdx < 0) {
// subPage 全部分配完之后,就从 smallSubpagePools 中删除
removeFromPool();
}
// 第几个 long
int q = bitmapIdx >>> 6;
// long 中的第几个 bit
int r = bitmapIdx & 63;
// 内存块必须是空闲的
assert (bitmap[q] >>> r & 1) == 0;
// 设置内存块在 bitmap 中对应的 bit 位为 1 (已分配)
bitmap[q] |= 1L << r;
if (-- numAvail == 0) {
// subPage 全部分配完之后,就从 smallSubpagePools 中删除
removeFromPool();
}
// 组装成 handle 结构返回
return toHandle(bitmapIdx);
}
}
6.2 PoolSubpage 的内存回收流程
当一个内存块要被释放回内存池的时候,我们需要判断这个内存块到底是 Small 规格的呢还是 Normal 规格的,如果是 Normal 规格的则直接释放回 PoolChunk,如果是 Small 规格的则是释放回 smallSubpagePools 中。
那我们如何判断一个内存块是 Small 规格还是 Normal 规格的呢 ?这就用到了之前我们介绍的 handle 结构,内存池用它来描述所有内存块。
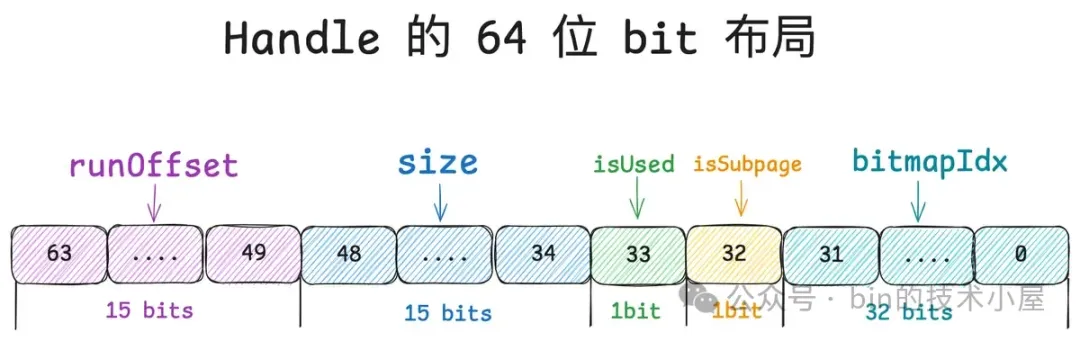
Small 规格内存块的 handle 结构有一个特点,就是它的 runOffset 是其所在 PoolSubpage 在 PoolChunk 中的 Page 偏移,size 为该 PoolSubpage 包含的 Page 个数,isUsed 用于表示该内存块是否被分配,被释放内存块的 isUsed 这里肯定是 1 。
和 Normal 规格最大的不同是,Small 规格内存块的 isSubpage 在被分配出去的时候会被设置为 1 ,表示其受到 PoolSubpage 的管理,bitmapIdx 会被设置为其在 PoolSubpage 中的 bitmapIndex。而 Normal 规格这两项全部是 0 。
private long toHandle(int bitmapIdx) {
// PoolSubpage 中包含的 page 个数
int pages = runSize >> pageShifts;
// 低 32 位保存 bitmapIdx
return (long) runOffset << RUN_OFFSET_SHIFT
| (long) pages << SIZE_SHIFT
| 1L << IS_USED_SHIFT
| 1L << IS_SUBPAGE_SHIFT
| bitmapIdx;
}
我们可以通过 isSubpage 方法来判断一个内存块的 Handle 结构对应的 isSubpage 位是否为 1 。如果为 1 ,那么这个内存块就是 Small 规格的,否则就是 Normal 规格的。
static boolean isSubpage(long handle) {
return (handle >> IS_SUBPAGE_SHIFT & 1) == 1L;
}
如果是 Small 规格的内存块,那么 Netty 就要把它释放回其所在的 PoolSubpage 中,现在的问题是我们如何通过一个内存块来查找它的 PoolSubpage 呢 ?也就是说内存块与 PoolSubpage 的映射关系在哪里 ?
这就用到了我们前面介绍 PoolChunk 时提到的 subpages 数组,subpages 数组中存放的全部是由该 PoolChunk 分配出去的所有 PoolSubpage 。
final class PoolChunk {
/**
* manage all subpages in this chunk
*/
private final PoolSubpage<T>[] subpages;
}
subpages 数组的索引就是每个 PoolSubpage 的 runOffset ,那么这个 runOffset 保存在哪里呢 ?其实就在 Small 规格内存块的 handle 结构中,我们可以通过 runOffset 方法来提取。
static int runOffset(long handle) {
return (int) (handle >> RUN_OFFSET_SHIFT);
}
有了这个 runOffset ,我们就可以从 subpages[runOffset] 中将内存块对应的 PoolSubpage 获取到,剩下的事情就很简单了,直接将这个内存块释放回 PoolSubpage 就可以了。
subpage.free(head, bitmapIdx(handle))
随着内存块的释放,有可能会导致 PoolSubpage 变为一个 Empty PoolSubpage,也就是说 PoolSubpage 中的内存块全部空闲。对于一个 Empty PoolSubpage , Netty 会将其从 smallSubpagePools 中移除,并将 PoolSubpage 背后的内存释放回 PoolChunk。
final class PoolChunk {
void free(long handle, int normCapacity, ByteBuffer nioBuffer) {
// Small 规格内存块的释放
if (isSubpage(handle)) {
// 获取内存块所在 PoolSubpage 的 runOffset
int sIdx = runOffset(handle);
PoolSubpage<T> subpage = subpages[sIdx];
// 获取 PoolSubpage 所在 smallSubpagePools 对应规格链表头结点
PoolSubpage<T> head = subpage.chunk.arena.smallSubpagePools[subpage.headIndex];
head.lock();
try {
assert subpage.doNotDestroy;
// 将内存块释放回 PoolSubpage 中
// true 表示 PoolSubpage 还是一个 Partial PoolSubpage(部分空闲) , 继续留在 smallSubpagePools 中
// false 表示 PoolSubpage 变成了一个 Empty PoolSubpage(全部空闲),从 smallSubpagePools 链表中移除
if (subpage.free(head, bitmapIdx(handle))) {
// the subpage is still used, do not free it
return;
}
// Empty PoolSubpage 从 PoolChunk subpages 数组中移除
subpages[sIdx] = null;
} finally {
head.unlock();
}
}
........ 释放 Normal 规格内存块或者 Empty PoolSubpage ......
} finally {
runsAvailLock.unlock();
}
}
}
内存块释放回 PoolSubpage 的逻辑也是非常简单,只需要将其 bitmapIdx 在 bitmap 中对应的 bit 位重新设置为 0 就可以了,正好和内存块的申请互为相反的操作。
那么如何通过 bitmapIdx 定位到 bitmap 中与其对应具体的 bit 呢 ? 我们还是以上个小节的例子进行说明,假设现在我们将 bitmapIdx 为 67 的内存块释放回 PoolSubpage 。
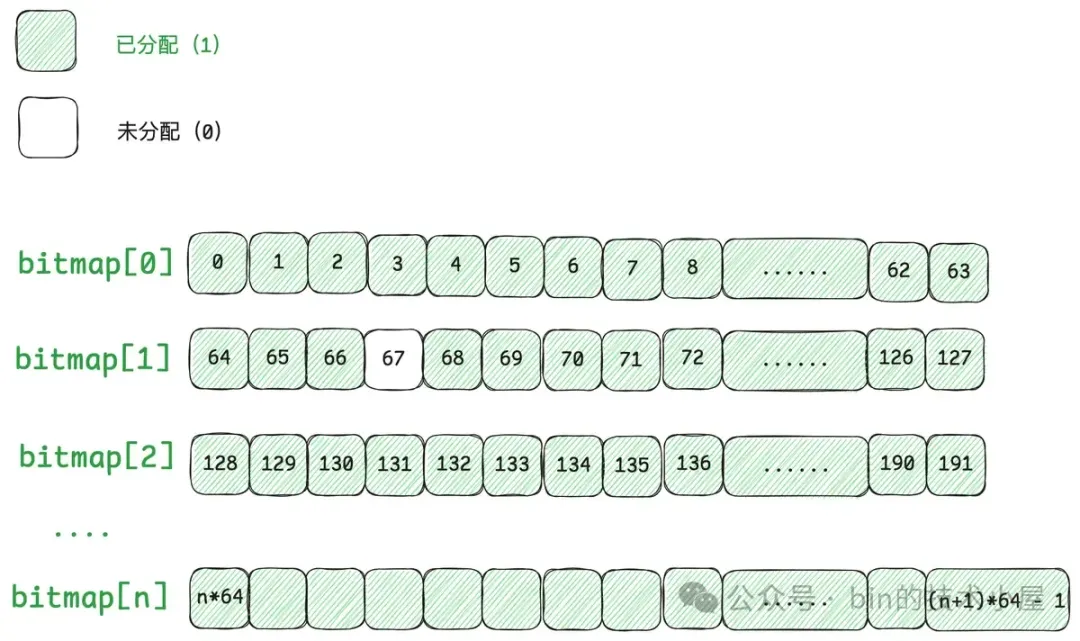
首先我们需要知道的是,bitmapIdx 具体是落在哪一个 bitmap 数组元素中,我们可以通过 bitmapIdx / 64 来获取,对应到上图中,bitmapIdx(67)是落在 bitmap[1] 中。
int q = bitmapIdx >>> 6;
接下来我们就需要知道,这个 bitmapIdx 具体是 bitmap[q] 的第几个 bit ,我们可以通过 bitmapIdx & 63 来获取,对应到上图中,bitmapIdx(67)是 bitmap[1] 的第 3 个 bit (从 0 开始计数)。
int r = bitmapIdx & 63;
具体的 bit 定位到了,剩下的事情就很简单了,我们只需要将 bitmapIdx 对应的 bit 重新设置为 0 就可以了。
bitmap[q] ^= 1L << r;
而 Netty 往往更加倾向于分配刚刚被释放的内存块,从上一小节 PoolSubpage 的分配过程可以看出,Netty 会优先选择缓存在 nextAvail 字段上的 bitmapIdx,所以当一个内存块被释放之后,需要将它的 bitmapIdx 缓存在 nextAvail 字段中。
final class PoolSubpage {
private void setNextAvail(int bitmapIdx) {
nextAvail = bitmapIdx;
}
}
PoolSubpage 的内存分配和释放,都会伴随着 smallSubpagePools 的调整,随着内存分配的不断进行,PoolSubpage 中的内存块会慢慢地全部分配出去,也就是说当一个 PoolSubpage 变为 Full PoolSubpage 的时候,那么就需要将 Full PoolSubpage 从 smallSubpagePools 中移除。
那么当这个 Full PoolSubpage 中的内存块被释放回来之后,这个被移除的 Full PoolSubpage 就会变为 Partial PoolSubpage(部分空闲),那么我们就需要将这个 PoolSubpage 重新添加回 smallSubpagePools 。
随着内存释放的不断进行,Partial PoolSubpage 中的内存块会慢慢的全部释放回来,也就是说当一个 PoolSubpage 变为 Empty PoolSubpage (全部空闲)的时候,Netty 就需要将这个 Empty PoolSubpage 从 smallSubpagePools 中删除,并将 Empty PoolSubpage 释放回 PoolChunk 。
但如果这个 Empty PoolSubpage 是 smallSubpagePools 对应规格 PoolSubpage 链表中的唯一元素,那么就让这个 Empty PoolSubpage 继续停留在 smallSubpagePools 中,始终保证 smallSubpagePools 对应规格的 PoolSubpage 链表中至少有一个 PoolSubpage 。
这个调整 PoolSubpage 的过程和内核中的 slab 非常相似,感兴趣的读者朋友可以回看下笔者之前介绍 slab 的文章 —— 《深度解析 slab 内存池回收内存以及销毁全流程》
final class PoolSubpage {
boolean free(PoolSubpage<T> head, int bitmapIdx) {
// bitmap 中第几个元素
int q = bitmapIdx >>> 6;
// long 型整数的具体第几个 bit
int r = bitmapIdx & 63;
// 将内存块在 bitmap 中对应的 bit 设置为 0
bitmap[q] ^= 1L << r;
// 设置 nextAvail,下一次申请的时候优先分配刚刚被释放的内存块
setNextAvail(bitmapIdx);
// Full PoolSubpage 恰好变为 Partial PoolSubpage
if (numAvail ++ == 0) {
// 将这个 PoolSubpage 重新添加到 smallSubpagePools 中
addToPool(head);
// 确保 PoolSubpage 现在是一个 Partial PoolSubpage
// 如果 maxNumElems = 1,那么这里的 PoolSubpage 会立即变为一个 Empty PoolSubpage(全部空闲)
if (maxNumElems > 1) {
// 返回 true 表示 PoolSubpage 是一个 Partial PoolSubpage
// 需要保留在 smallSubpagePools 中
return true;
}
}
// numAvail = maxNumElems 说明 PoolSubpage 此时变为一个 Empty PoolSubpage(全部空闲)
if (numAvail != maxNumElems) {
// Partial PoolSubpage 继续停留在 smallSubpagePools
return true;
} else {
// 对于一个 Empty PoolSubpage 来说,Netty 需要将其从 smallSubpagePools 中删除,并释放 PoolSubpage 回 PoolChunk
// 如果该 PoolSubpage 是 smallSubpagePools 对应规格链表中的唯一元素,那么就让它继续停留
if (prev == next) {
// 始终保证 smallSubpagePools 对应规格的 PoolSubpage 链表中至少有一个 PoolSubpage
return true;
}
// 如果对应的 PoolSubpage 链表中还有多余的 PoolSubpage
// 那么就将这个 Empty PoolSubpage 释放掉
doNotDestroy = false;
// 将该 Empty PoolSubpage 从 smallSubpagePools 中删除
removeFromPool();
return false;
}
}
}
7. PooledByteBuf 如何封装内存块
无论是从 PoolChunk 分配出来的 Normal 规格内存块,还是从 PoolSubpage 分配出来的 Small 规格内存块,内存池都会返回一个内存块的 handle 结构。
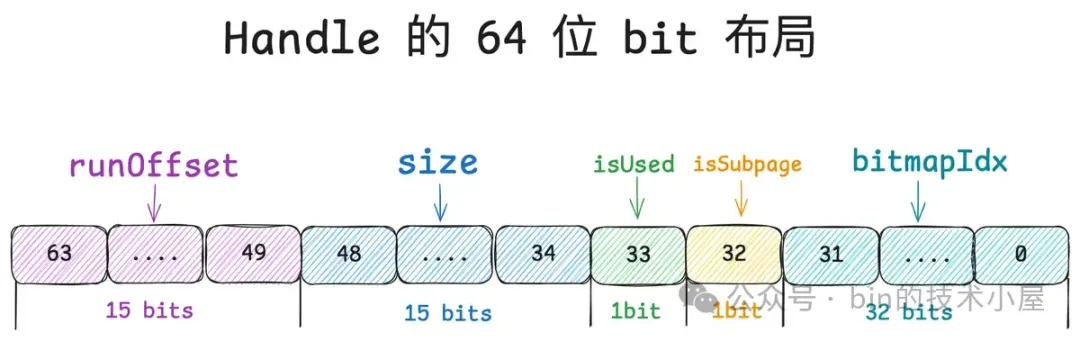
而我们拿到这个 handle 结构是无法直接使用的,因为这个 handle 并不是真正的内存,他只是用来描述内存块在 PoolChunk 中的位置信息,而真正的内存是 4M 的 PoolChunk。所以我们需要将内存块的 handle 结构转换成可以直接使用的 PooledByteBuf。
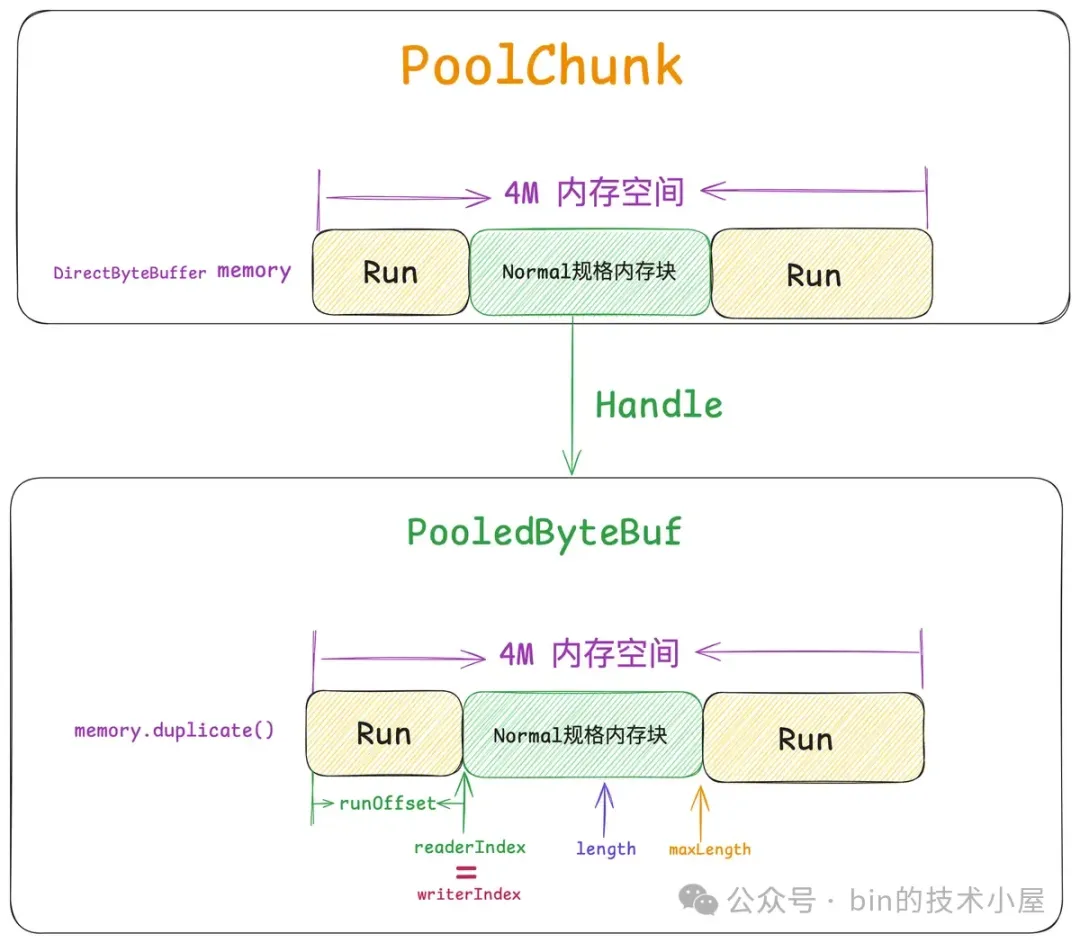
站在 PooledByteBuf 的内部视角来看,用户并不会关心 PooledByteBuf 底层的内存来自于哪里,用户只会关心 PooledByteBuf 提供的是一段从位置 0 开始,大小为 length 的内存块。在 PooledByteBuf 这个局部视角上,它的 readerIndex , writerIndex 初始均为 0 。
但我们站在整个内存池的全局视角上来看的话,PooledByteBuf 底层的内存其实是来自于 PoolChunk,笔者之前在 《聊一聊 Netty 数据搬运工 ByteBuf 体系的设计与实现》 中的第 2.7 小节中介绍过 ByteBuf 视图的概念。我们可以将 PooledByteBuf 看做是 PoolChunk 的某一段局部 slice 视图。
PooledByteBuf 的本质其实是 PoolChunk 中的某一段内存区域,对于 Normal 规格的内存块来说,这段区域的起始内存地址是 memory + runOffset << pageShifts , 也就是说 PooledByteBuf 相对于 PoolChunk 的起始内存地址的 offset 偏移是 runOffset << pageShifts, 这一点是我们站在整个内存池的全局视角上观察到的。
final class PoolChunk {
void initBuf(PooledByteBuf<T> buf, ByteBuffer nioBuffer, long handle, int reqCapacity,
PoolThreadCache threadCache) {
if (isSubpage(handle)) {
// Small 规格的 handle 转换为 PooledByteBuf
initBufWithSubpage(buf, nioBuffer, handle, reqCapacity, threadCache);
} else {
// Normal 规格的 handle 转换为 PooledByteBuf
int maxLength = runSize(pageShifts, handle);
// PooledByteBuf 中的 offset 偏移为 runOffset(handle) << pageShifts
buf.init(this, nioBuffer, handle, runOffset(handle) << pageShifts,
reqCapacity, maxLength, arena.parent.threadCache());
}
}
}
但在 PooledByteBuf 的内部视角里,用户看到的起始内存地址偏移是 0 (相对于自己),初始状态下 PooledByteBuf 的 readerIndex = writerIndex = 0。所以要想通过 PooledByteBuf 的相关 index 访问到背后真正的内存(相对于 PoolChunk),我们就需要在每次获取 index 的时候加上一个偏移 offset —— runOffset << pageShifts。
protected final int idx(int index) {
return offset + index;
}
@Override
protected byte _getByte(int index) {
return memory.get(idx(index));
}
@Override
protected void _setByte(int index, int value) {
memory.put(idx(index), (byte) value);
}
这个就是 PooledByteBuf 最核心的内容,剩下的就和普通的 ByteBuf 一模一样了。而对于 Small 规格的内存块来说, 其 handle 结构对应的 PooledByteBuf 相对于 PoolChunk 的起始内存地址的 offset 偏移则是 (runOffset << pageShifts) + bitmapIdx * elemSize。
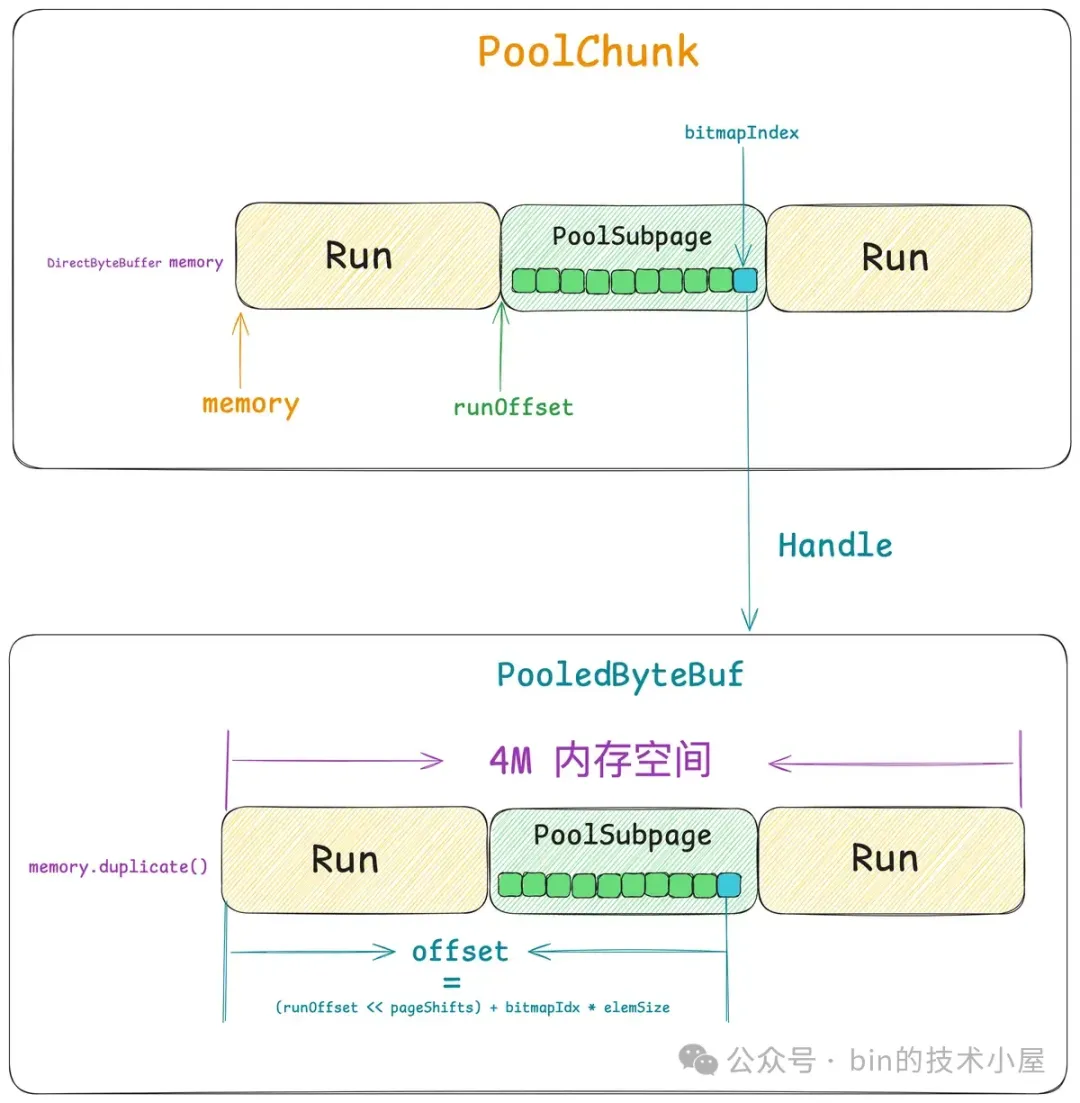
final class PoolChunk {
void initBufWithSubpage(PooledByteBuf<T> buf, ByteBuffer nioBuffer, long handle, int reqCapacity,
PoolThreadCache threadCache) {
int runOffset = runOffset(handle);
int bitmapIdx = bitmapIdx(handle);
PoolSubpage<T> s = subpages[runOffset];
// PooledByteBuf 中的 offset 偏移
int offset = (runOffset << pageShifts) + bitmapIdx * s.elemSize;
buf.init(this, nioBuffer, handle, offset, reqCapacity, s.elemSize, threadCache);
}
}
那么 PooledByteBuf 中究竟封装了哪些内存池的相关信息呢 ?我们来看下 PooledByteBuf 的初始化逻辑。
abstract class PooledByteBuf {
private void init0(PoolChunk<T> chunk, ByteBuffer nioBuffer,
long handle, int offset, int length, int maxLength, PoolThreadCache cache) {
// 该 PooledByteBuf 所属的 PoolChunk
this.chunk = chunk;
// PoolChunk 底层依赖的 ByteBuffer (4M)
memory = chunk.memory;
// PoolChunk memory 的 duplicate 视图
// 对于 PooledByteBuf 的 read ,write 操作最终都会落在 tmpNioBuf 上
tmpNioBuf = nioBuffer;
// PooledByteBuf 背后的内存池 —— PooledByteBufAllocator
allocator = chunk.arena.parent;
// 所属的 PoolThreadCache (线程本地缓存)
this.cache = cache;
// PooledByteBuf 底层依赖的内存块 handle 结构
this.handle = handle;
// PooledByteBuf 相对于 PoolChunk 起始内存地址的偏移,以字节为单位
this.offset = offset;
// 用户本来请求的内存尺寸
this.length = length;
// 内存池实际分配的内存尺寸
this.maxLength = maxLength;
}
}
PooledByteBuf 中的 tmpNioBuf,其实就是来自于 PoolChunk 中 cachedNioBuffers 里缓存的 memory duplicate 视图。
final class PoolChunk {
private final Deque<ByteBuffer> cachedNioBuffers;
}
内存池分配一个内存块出来之后,都会从 cachedNioBuffers 中取出一个 PoolChunk memory duplicate 视图传递进 PooledByteBuf 中初始化。
final class PoolChunk {
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache cache) {
..... 省略分配 handle 的逻辑 ......
ByteBuffer nioBuffer = cachedNioBuffers != null? cachedNioBuffers.pollLast() : null;
initBuf(buf, nioBuffer, handle, reqCapacity, cache);
return true;
}
}
后续对于 PooledByteBuf 的读写操作最终都会落到 tmpNioBuf 中进行。当我们使用完 PooledByteBuf 随后调用 release() 方法准备释放回内存池的时候,如果 PooledByteBuf 的引用计数为 0 ,那么就会在 deallocate() 方法中,将其底层依赖的内存块 handle 释放回内存池中,同时 PooledByteBuf 这个 Java 实例也会被回收至对象池中。
abstract class PooledByteBuf {
@Override
protected final void deallocate() {
if (handle >= 0) {
final long handle = this.handle;
this.handle = -1;
memory = null;
// 释放 PooledByteBuf 背后的内存块回内存池中
chunk.arena.free(chunk, tmpNioBuf, handle, maxLength, cache);
tmpNioBuf = null;
chunk = null;
cache = null;
// 释放 PooledByteBuf 这个 Java 实例回对象池中
this.recyclerHandle.unguardedRecycle(this);
}
}
}
8. PoolThreadCache 的设计与实现
到目前为止,内存池的整个内部实现笔者就为大家剖析完了,现在让我们把视角从内存池的内部重新转移到整个架构层面上来俯瞰一下整个内存池的全貌。
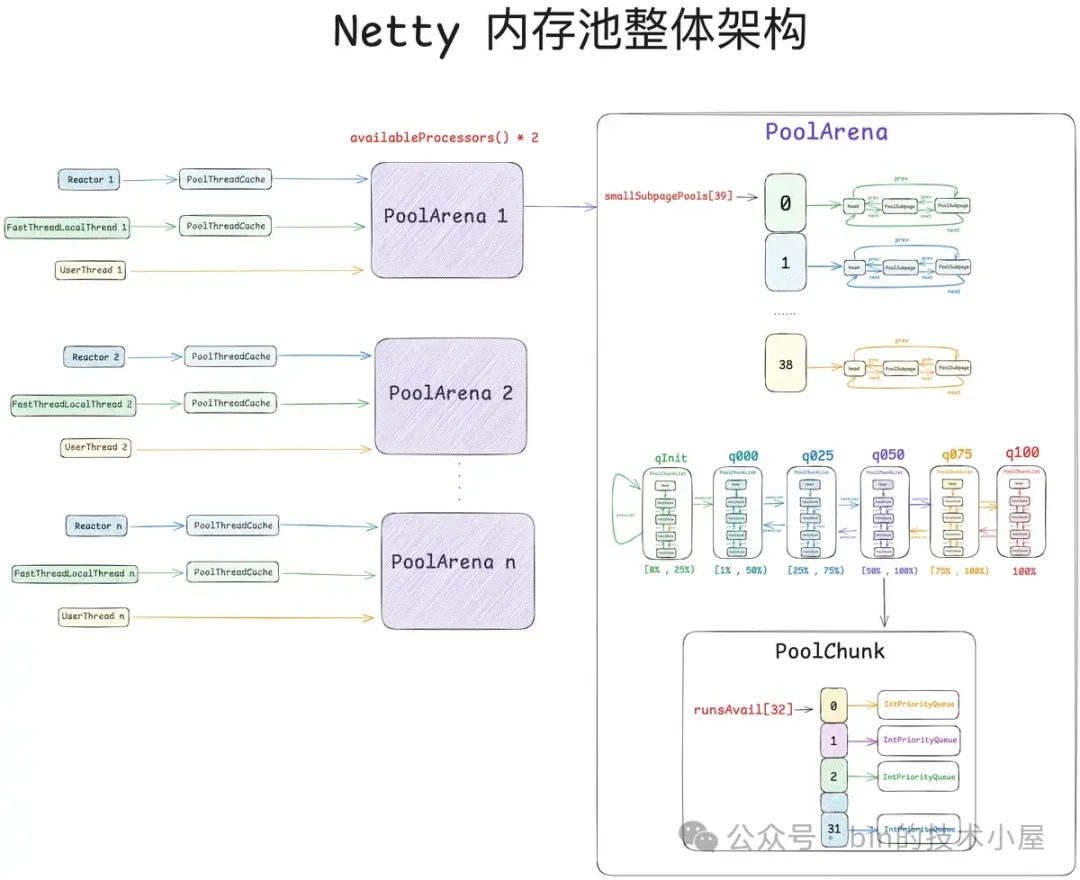
笔者在本文第一小节介绍内存池的架构设计时提到过,Netty 为了降低多线程并发向内存池申请内存的竞争激烈程度,从而设计了多个 PoolArena,默认个数为 availableProcessors * 2,我们可以通过 -Dio.netty.allocator.numDirectArenas 参数进行调整。
当线程第一次向内存池申请内存的时候,都会采用 Round-Robin 的方式与一个固定的 PoolArena 进行绑定,后续在线程整个生命周期中的内存申请以及释放等操作只会与这个绑定的 PoolArena 进行交互。
一个线程只能绑定到一个固定的 PoolArena 上,而一个 PoolArena 却可以被多个线程绑定。
同时为了省去 cacheline 核间通信的这部分开销,实现内存申请,释放的无锁化,最大化提升内存池的性能。Netty 为每个线程引入了本地缓存 —— PoolThreadCache 。
考虑到这部分本地缓存的内存占用,默认情况下,Netty 只会为 Reactor 线程以及 FastThreadLocalThread 类型的线程提供 PoolThreadCache,而普通的用户线程要想启用 PoolThreadCache ,则需要设置 -Dio.netty.allocator.useCacheForAllThreads 为 true 。
PoolThreadCache 提供了 Small 规格以及 Normal 规格的线程本地缓存,其核心属性如下:
final class PoolThreadCache {
// 与线程绑定的 PoolArena
final PoolArena<ByteBuffer> directArena;
// 本地缓存线程申请过的 Small 规格内存块
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
// 本地缓存线程申请过的 Normal 规格内存块
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
}
每一种内存规格的本地缓存都对应一个 MemoryRegionCache 结构,所以 smallSubPageDirectCaches 以及 normalDirectCaches 都是一个 MemoryRegionCache 结构的数组。
比如 smallSubPageDirectCaches 是用来缓存 Small 规格的内存块,而 Netty 一共定义了 39 种 Small 规格尺寸 —— [16B , 28K] ,Netty 会为每一种 Small 规格提供一个 MemoryRegionCache 缓存。smallSubPageDirectCaches 数组的 index 就是对应 Small 规格尺寸在内存规格表中的 sizeIndex ,数组大小为 39 。
// numCaches 表示有多少种 Small 规格尺寸(39)
// cacheSize 表示每一种 Small 规格尺寸可以缓存多少个内存块(256)
private static <T> MemoryRegionCache<T>[] createSubPageCaches(
int cacheSize, int numCaches) {
if (cacheSize > 0 && numCaches > 0) {
// 为每一个 small 内存规格创建 MemoryRegionCache 本地缓存结构
// cacheIndex 就是对应的 small 内存规格的 sizeIndex
MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches];
for (int i = 0; i < cache.length; i++) {
// 初始化 smallSubPageDirectCaches 数组
cache[i] = new SubPageMemoryRegionCache<T>(cacheSize);
}
return cache;
} else {
return null;
}
}
private static final class SubPageMemoryRegionCache<T> extends MemoryRegionCache<T> {
SubPageMemoryRegionCache(int size) {
super(size, SizeClass.Small);
}
}
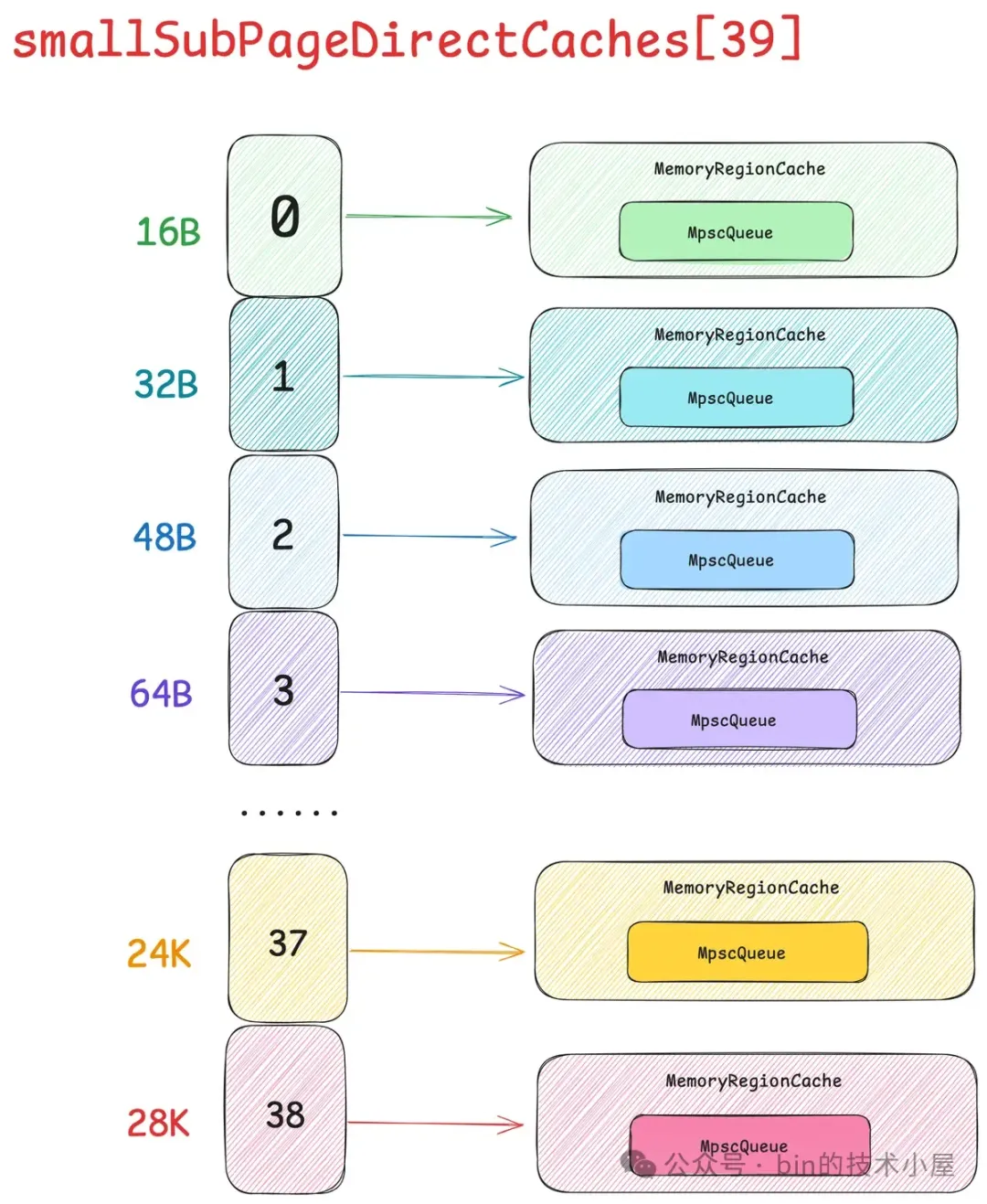
每个 MemoryRegionCache 结构中都有一个 MpscQueue,用于缓存对应尺寸的内存块,Netty 根据不同的内存规格分类限定了 MpscQueue 的大小。
对于 Small 规格的线程本地缓存来说,每一种 Small 规格可以缓存的内存块个数默认为 256 ,我们可以通过 -Dio.netty.allocator.smallCacheSize 进行调节。
对于 Normal 规格的线程本地缓存来说,每一种 Normal 规格可以缓存的内存块个数默认为 64 ,我们可以通过 -Dio.netty.allocator.normalCacheSize 进行调节。
private abstract static class MemoryRegionCache<T> {
// queue 中缓存内存块的个数上限
private final int size;
// 用于缓存线程本地内存块的 MpscQueue
private final Queue<Entry<T>> queue;
// 内存块是 Small 规格还是 Normal 规格 ?
private final SizeClass sizeClass;
// 从该缓存中分配内存块的次数
private int allocations;
MemoryRegionCache(int size, SizeClass sizeClass) {
// 表示每一个 MemoryRegionCache 中,queue 中可以缓存的内存块个数
// 每种 Small 规格尺寸默认可以缓存 256 个内存块
// 每种 Normal 规格尺寸默认可以缓存 64 个内存块
this.size = MathUtil.safeFindNextPositivePowerOfTwo(size);
queue = PlatformDependent.newFixedMpscQueue(this.size);
this.sizeClass = sizeClass;
}
}
而对于 normalDirectCaches 来说,Netty 一共定义了 29 种 Normal 规格尺寸 —— [32K , 4M],但 Netty 并不会为每一种 Normal 规格提供本地缓存 MemoryRegionCache。其中的原因,一是 Netty 经常使用的是 Small 规格尺寸而不是 Normal 规格尺寸,二是 Normal 规格尺寸太大了,不可能为大尺寸并且不经常使用的内存块提供缓存。
默认情况下 ,Netty 只会为 32K 这一个 Normal 规格提供本地缓存 MemoryRegionCache,不过我们可以通过 -Dio.netty.allocator.maxCachedBufferCapacity 参数进行调整(单位为字节,默认 32 * 1024),该参数表示 Netty 可以缓存的最大的 Normal 规格尺寸。maxCachedBufferCapacity 以下的 Normal 规格会缓存,超过 maxCachedBufferCapacity 的 Normal 规格则不会被缓存。
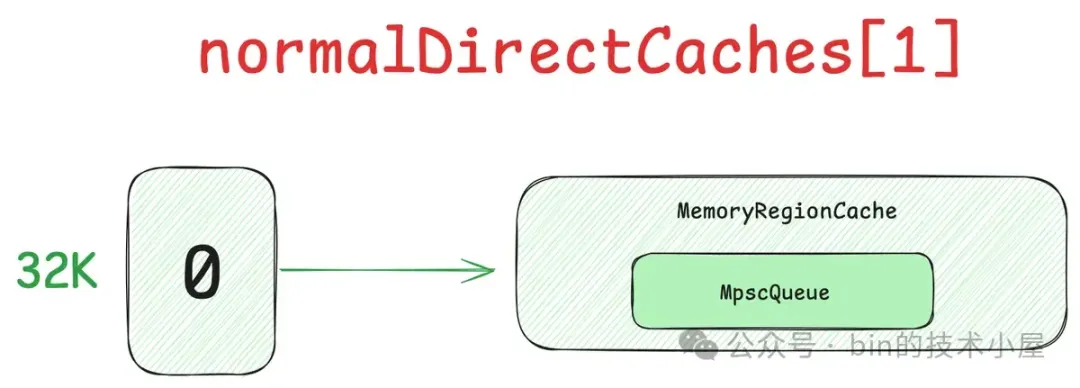
// cacheSize 表示每一种 Normal 规格尺寸可以缓存多少个内存块(64)
// maxCachedBufferCapacity 表示可缓存的最大 Normal 规格尺寸(32K)
// maxCachedBufferCapacity 以下的 Normal 规格会缓存,超过 maxCachedBufferCapacity 的 Normal 规格则不会被缓存
// PoolArena 表示与线程绑定的内存池
private static <T> MemoryRegionCache<T>[] createNormalCaches(
int cacheSize, int maxCachedBufferCapacity, PoolArena<T> area) {
if (cacheSize > 0 && maxCachedBufferCapacity > 0) {
// 最大可缓存的 Normal 规格
int max = Math.min(area.sizeClass.chunkSize, maxCachedBufferCapacity);
// 创建 normalDirectCaches
List<MemoryRegionCache<T>> cache = new ArrayList<MemoryRegionCache<T>>() ;
for (int idx = area.sizeClass.nSubpages; idx < area.sizeClass.nSizes &&
area.sizeClass.sizeIdx2size(idx) <= max; idx++) {
// 为 maxCachedBufferCapacity 以下的 Normal 规格创建本地缓存 MemoryRegionCache
cache.add(new NormalMemoryRegionCache<T>(cacheSize));
}
// 返回 normalDirectCaches (转换成数组)
return cache.toArray(new MemoryRegionCache[0]);
} else {
return null;
}
}
private static final class NormalMemoryRegionCache<T> extends MemoryRegionCache<T> {
NormalMemoryRegionCache(int size) {
super(size, SizeClass.Normal);
}
}
normalDirectCaches 数组的 index 就是对应 Normal 规格在内存规格表中的 sizeIndex - 39 , 因为第一个 Normal 规格(32K)的 sizeIndex 就是 39 。
8.1 线程如何与 PoolArena 进行绑定
当线程第一次向内存池申请内存的时候,Netty 会将线程与一个固定的 PoolArena 进行绑定,从此之后,在线程整个生命周期中的内存申请以及释放等操作只会与这个绑定的 PoolArena 进行交互。
public class PooledByteBufAllocator {
// 线程本地缓存
private final PoolThreadLocalCache threadCache;
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 获取线程本地缓存,线程第一次申请内存的时候会在这里与 PoolArena 进行绑定
PoolThreadCache cache = threadCache.get();
// 获取与当前线程绑定的 PoolArena
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
// 从固定的 PoolArena 中申请内存
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
// 申请非池化内存
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
}
Netty 会在当前内存池所有的 PoolArena 中,选出一个目前绑定线程数最少的 PoolArena 来与当前线程进行绑定。
private final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
private static final int CACHE_NOT_USED = 0;
private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas) {
// 内存池中第一个 PoolArena
PoolArena<T> minArena = arenas[0];
// PoolArena 中的 numThreadCaches 表示目前有多少线程与当前 PoolArena 进行绑定
if (minArena.numThreadCaches.get() == CACHE_NOT_USED) {
// 当前内存池还没有绑定过线程,那么就从第一个 PoolArena 开始绑定
return minArena;
}
// 选取当前绑定线程数最少的 PoolArena 进行绑定
for (int i = 1; i < arenas.length; i++) {
PoolArena<T> arena = arenas[i];
// 一个 PoolArena 会被多个线程绑定
if (arena.numThreadCaches.get() < minArena.numThreadCaches.get()) {
minArena = arena;
}
}
return minArena;
}
}
当线程与一个固定的 PoolArena 绑定好之后,接下来 Netty 就会为该线程创建本地缓存 PoolThreadCache,后续线程的内存申请与释放都会先走 PoolThreadCache。
private final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
@Override
protected synchronized PoolThreadCache initialValue() {
// 选取目前线程绑定数最少的 PoolArena 与当前线程进行绑定
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
// 获取当前线程
final Thread current = Thread.currentThread();
// 判断当前线程是否是 Reactor 线程 —— executor != null
final EventExecutor executor = ThreadExecutorMap.currentExecutor();
// 如果当前线程是 FastThreadLocalThread 或者是 Reactor,那么无条件使用 PoolThreadCache
// 除此之外的普通线程再向内存池申请内存的时候,是否使用 PoolThreadCache 是由 useCacheForAllThreads 决定的(默认 false)
if (useCacheForAllThreads ||
current instanceof FastThreadLocalThread ||
executor != null) {
// 为当前线程创建 PoolThreadCache,并与 PoolArena 进行绑定
final PoolThreadCache cache = new PoolThreadCache(
heapArena, directArena, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL, useCacheFinalizers(current));
// 默认不开启定时清理
if (DEFAULT_CACHE_TRIM_INTERVAL_MILLIS > 0) {
if (executor != null) {
// Reactor 线程会定时清理其 PoolThreadCache 中空闲的内存块,将他们释放回 PoolChunk 中
executor.scheduleAtFixedRate(trimTask, DEFAULT_CACHE_TRIM_INTERVAL_MILLIS,
DEFAULT_CACHE_TRIM_INTERVAL_MILLIS, TimeUnit.MILLISECONDS);
}
}
return cache;
}
// useCacheForAllThreads = false , 则当前线程只与 PoolArena 进行绑定,但没有 PoolThreadCache(空的)
return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, false);
}
}
Netty 设计了一个 ThreadExecutorMap 用于缓存 Reactor 线程与其对应的 Executor 之间的映射关系。
public final class ThreadExecutorMap {
// 缓存 Reactor 线程与其对应的 Executor 之间的映射关系
private static final FastThreadLocal<EventExecutor> mappings = new FastThreadLocal<EventExecutor>();
}
在 Reactor 线程启动之后,会将 Reactor 线程所属的 SingleThreadEventExecutor 设置到 ThreadExecutorMap 中,建立 Reactor 线程与其所属 SingleThreadEventExecutor 之间的映射关系。
private static void setCurrentEventExecutor(EventExecutor executor) {
mappings.set(executor);
}
当我们在某一个线程上下文中调用 ThreadExecutorMap.currentExecutor() 获取到的 executor 不为空的时候,那么恰巧说明当前线程其实就是 Reactor 线程。
public static EventExecutor currentExecutor() {
return mappings.get();
}
如果当前线程是 Reactor 线程或者是一个 FastThreadLocalThread ,那么 Netty 就会无条件为该线程创建本地缓存 PoolThreadCache,并将 PoolArena 绑定到它的 PoolThreadCache 中。
如果当前线程是一个普通的用户线程,默认情况下,Netty 不会为其创建本地缓存,除非 useCacheForAllThreads 设置为 true 。
final class PoolThreadCache {
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena,
int smallCacheSize, int normalCacheSize, int maxCachedBufferCapacity,
int freeSweepAllocationThreshold, boolean useFinalizer) {
// 该阈值表示当该 PoolThreadCache 分配了多少次内存块之后,触发清理缓存中空闲的内存
this.freeSweepAllocationThreshold = freeSweepAllocationThreshold;
// 线程与 PoolArena 在这里进行绑定
this.directArena = directArena;
if (directArena != null) {
// 创建 Small 规格的缓存结构
// smallCacheSize = DEFAULT_SMALL_CACHE_SIZE = 256 , 表示每一个 small 内存规格对应的 MemoryRegionCache 可以缓存的内存块个数
smallSubPageDirectCaches = createSubPageCaches(smallCacheSize, directArena.sizeClass.nSubpages);
// 创建 Normal 规格的缓存结构
// normalCacheSize = DEFAULT_NORMAL_CACHE_SIZE = 64 , 每一个 normal 内存规格的 MemoryRegionCache 可以缓存的内存块个数
normalDirectCaches = createNormalCaches(normalCacheSize, maxCachedBufferCapacity, directArena);
// PoolArena 中线程绑定计数加 1
directArena.numThreadCaches.getAndIncrement();
} else {
// No directArea is configured so just null out all caches
smallSubPageDirectCaches = null;
normalDirectCaches = null;
}
// 当线程终结时是否使用 Finalizer 清理 PoolThreadCache
freeOnFinalize = useFinalizer ? new FreeOnFinalize(this) : null;
}
}
在 PoolThreadCache 的构造函数中,主要是将线程与 PoolArena 进行绑定,然后创建 Small 规格的线程本地缓存结构 —— smallSubPageDirectCaches,以及 Normal 规格的线程本地缓存结构 —— normalDirectCaches。
除此之外,Netty 还设计了两个关于清理 PoolThreadCache 的参数:freeSweepAllocationThreshold 和 useFinalizer 。
对于那些在 PoolThreadCache 中不经常被使用的缓存来说,我们需要及时地将它们释放回 PoolChunk 中,否则就会导致不必要的额外内存消耗。对此,Netty 设置了一个阈值 freeSweepAllocationThreshold , 默认为 8192 , 我们可以通过 -Dio.netty.allocator.cacheTrimInterval 进行调整。
它的语义是当 PoolThreadCache 分配内存的次数达到了阈值 freeSweepAllocationThreshold 之后,Netty 就会无条件清理 PoolThreadCache 中缓存的所有空闲内存块。这种情况下,仍然还没有被分配出去的内存块,Netty 认为它们就是不经常被使用了,没必要继续停留在 PoolThreadCache 中。
useFinalizer 则是用于当线程终结的时候,是否采用 Finalizer 来释放 PoolThreadCache 中的内存块,因为 PoolThreadCache 是一个 Thread Local 变量,当线程终结的时候,PoolThreadCache 这个实例会被 GC 回收,但是它里面缓存的内存块就没法释放了,这就导致了内存泄露。
相似的情况还有 JDK 中的 DirectByteBuffer ,GC 只是回收 PoolThreadCache ,DirectByteBuffer 这些 Java 实例,它们内部引用的 Native Memory 则不会被回收,需要我们使用额外的机制来保证这些 Native Memory 及时回收。
useFinalizer 默认为 true , 我们可以通过参数 -Dio.netty.allocator.disableCacheFinalizersForFastThreadLocalThreads 进行调整。
disableCacheFinalizersForFastThreadLocalThreads 设置为 false (默认),则 useFinalizer 为 true , 那么所有线程的 PoolThreadCache 在线程退出的时候将会被 Finalizer 进行清理。
如果 useFinalizer 为 false , 那么当线程退出的时候,它的本地缓存 PoolThreadCache 将不会由 Finalizer 来清理。这种情况下,我们就需要特别注意,一定要通过 FastThreadLocal.removeAll() 或者 PoolThreadLocalCache.remove(PoolThreadCache) 来手动进行清理。否则就会造成内存泄露。
8.2 PoolThreadCache 的内存分配流程
当线程与一个固定的 PoolArena 绑定好之后,后续线程的内存申请与释放就都和这个 PoolArena 打交道了,在进入 PoolArena 之后,首先我们需要从对象池中取出一个 PooledByteBuf 实例,因为后续从内存池申请的内存块我们还无法直接使用,需要包装成一个 PooledByteBuf 实例返回。Netty 针对 PooledByteBuf 实例也做了池化管理。
对 Netty 对象池具体实现细节感兴趣的读者朋友可以回看下笔者之前的文章 《详解 Recycler 对象池的精妙设计与实现》
abstract class PoolArena {
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// 从对象池中获取一个 PooledByteBuf 对象,这里设置 maxCapacity
PooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 从内存池中申请内存块并初始化 PooledByteBuf 返回
allocate(cache, buf, reqCapacity);
return buf;
}
}
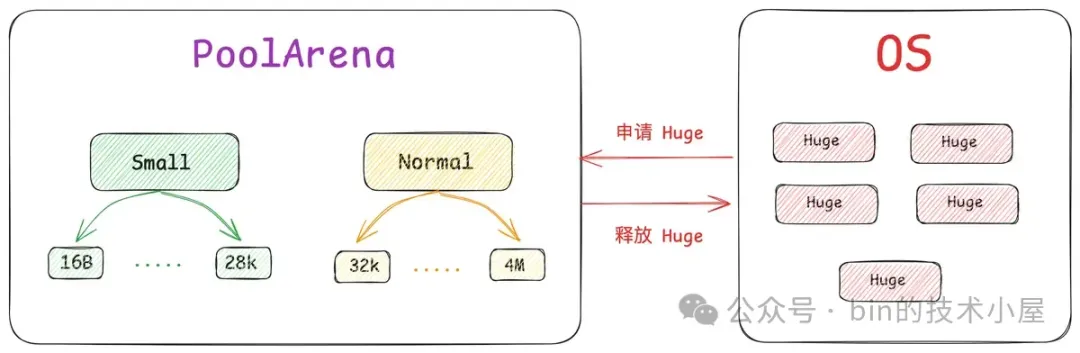
- 对于 Small 内存规格来说,走 tcacheAllocateSmall 进行分配。
- 对于 Normal 内存规格来说,走 tcacheAllocateNormal 进行分配。
- 对于 Huge 内存规格来说,则直接向 OS 申请,不会走内存池。
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 获取 reqCapacity 在内存规格表中的 sizeIndex
final int sizeIdx = sizeClass.size2SizeIdx(reqCapacity);
// [16B , 28K] 之间是 small 规格的内存
if (sizeIdx <= sizeClass.smallMaxSizeIdx) {
tcacheAllocateSmall(cache, buf, reqCapacity, sizeIdx);
} else if (sizeIdx < sizeClass.nSizes) {
// [32K , 4M] 之间是 normal 规格的内存
tcacheAllocateNormal(cache, buf, reqCapacity, sizeIdx);
} else {
// 超过 4M 就是 Huge 规格
int normCapacity = sizeClass.directMemoryCacheAlignment > 0
? sizeClass.normalizeSize(reqCapacity) : reqCapacity;
// Huge 内存规格直接向操作系统申请,不经过 cache 也不经过内存池
allocateHuge(buf, normCapacity);
}
Small 规格内存块的申请首先会尝试从线程本地缓存 PoolThreadCache 中去获取,如果缓存中没有,则到 smallSubpagePools 中申请。
abstract class PoolArena {
private void tcacheAllocateSmall(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity,
final int sizeIdx) {
// 首先尝试从线程本地缓存 PoolThreadCache 申请 Small 规格
if (cache.allocateSmall(this, buf, reqCapacity, sizeIdx)) {
return;
}
...... 通过 smallSubpagePools 分配 Small 规格内存块 .......
}
}
PoolThreadCache 中的 smallSubPageDirectCaches 是用来缓存 Small 规格的内存块,一共 39 种规格,smallSubPageDirectCaches 数组的 index 就是对应 Small 规格尺寸在内存规格表中的 sizeIndex。
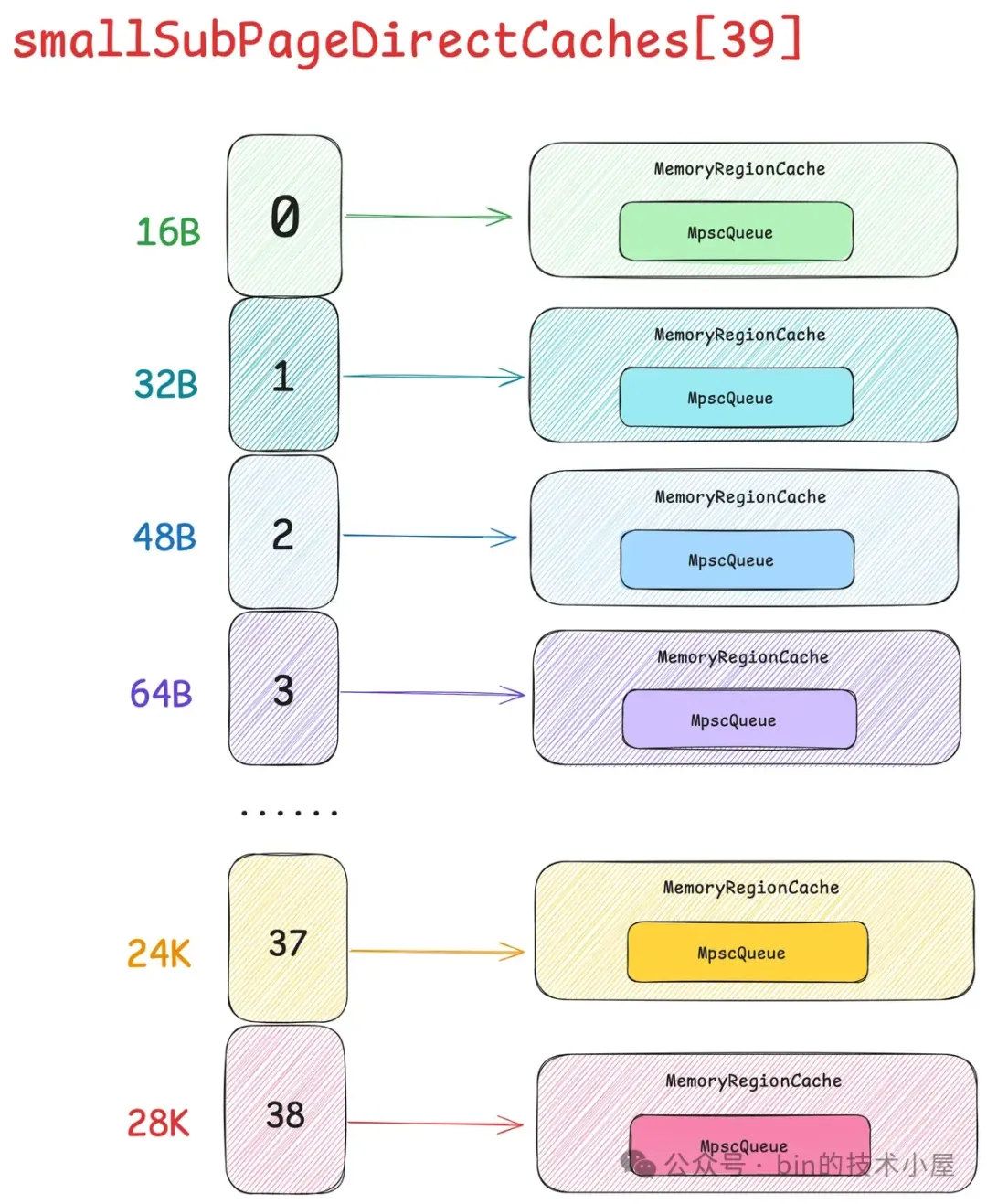
我们可以通过请求的内存尺寸对应在内存规格表中的 sizeIndex ,到 smallSubPageDirectCaches 中获取对应的 MemoryRegionCache 。
private static <T> MemoryRegionCache<T> cache(MemoryRegionCache<T>[] cache, int sizeIdx) {
if (cache == null || sizeIdx > cache.length - 1) {
return null;
}
return cache[sizeIdx];
}
MemoryRegionCache 中有一个 MpscQueue ,里面缓存了对应规格的内存块,内存块信息用一个 Entry 结构描述。
static final class Entry<T> {
// 内存块所属的 PoolChunk
PoolChunk<T> chunk;
// PoolChunk 中 memory 的 duplicate 视图
ByteBuffer nioBuffer;
// 内存块对应的 handle 结构
long handle = -1;
// 内存块大小,单位为字节
int normCapacity;
}
我们从 MpscQueue 中拿出一个 Entry,利用里面封装的内存块信息初始化成一个 PooledByteBuf 返回。
final class MemoryRegionCache {
public final boolean allocate(PooledByteBuf<T> buf, int reqCapacity, PoolThreadCache threadCache) {
// 从 MemoryRegionCache 中获取内存块
Entry<T> entry = queue.poll();
if (entry == null) {
return false;
}
// 封装成 PooledByteBuf
initBuf(entry.chunk, entry.nioBuffer, entry.handle, buf, reqCapacity, threadCache);
// 回收 entry 实例
entry.unguardedRecycle();
// MemoryRegionCache 的分配次数加 1
++ allocations;
return true;
}
}
随后 MemoryRegionCache 中的 allocations 加 1 ,每一次从 MemoryRegionCache 中成功申请到一个内存块,allocations 都会加 1 。
同时 PoolThreadCache 中的 allocations 计数也会加 1 , 当 PoolThreadCache 的 allocations 计数达到阈值 freeSweepAllocationThreshold 的时候,Netty 就会将 PoolThreadCache 中缓存的所有空闲内存块重新释放回 PoolChunk 中。这里表达的语义是,都已经分配了这么多次了,仍然空闲的内存块那就是不经常使用的了,对于不经常使用的内存块就没必要缓存了。
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {
if (cache == null) {
// no cache found so just return false here
return false;
}
// true 表示分配成功,false 表示分配失败(缓存没有了)
boolean allocated = cache.allocate(buf, reqCapacity, this);
// PoolThreadCache 中的 allocations 计数加 1
if (++ allocations >= freeSweepAllocationThreshold) {
allocations = 0;
// 清理 PoolThreadCache,将缓存的内存块释放回 PoolChunk
trim();
}
return allocated;
}
同样的道理,Normal 规格内存块的申请首先也会尝试从线程本地缓存 PoolThreadCache 中去获取,如果缓存中没有,则到 PoolChunk 中申请。
private void tcacheAllocateNormal(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity,
final int sizeIdx) {
// 首先尝试从线程本地缓存 PoolThreadCache 申请 Normal 规格
if (cache.allocateNormal(this, buf, reqCapacity, sizeIdx)) {
return;
}
lock();
try {
// 到 PoolChunk 中申请 Normal 规格的内存块
allocateNormal(buf, reqCapacity, sizeIdx, cache);
++allocationsNormal;
} finally {
unlock();
}
}
PoolThreadCache 中的 normalDirectCaches 是用来缓存 Normal 规格的内存块,但默认情况下只会缓存一种 Normal 规格 —— 32K , 超过 32K 还是需要到 PoolChunk 中去申请。
normalDirectCaches 数组的 index 就是对应 Normal 规格在内存规格表中的 sizeIndex - 39 , 因为第一个 Normal 规格(32K)的 sizeIndex 就是 39 。
private MemoryRegionCache<?> cacheForNormal(PoolArena<?> area, int sizeIdx) {
// sizeIdx - 39
int idx = sizeIdx - area.sizeClass.nSubpages;
// 获取 normalDirectCaches[idx]
return cache(normalDirectCaches, idx);
}
当我们获取到 Normal 规格对应的 MemoryRegionCache 之后,剩下的流程就都是一样的了,从 MemoryRegionCache 获取一个 Entry 实例,根据里面封装的内存块信息包装成 PooledByteBuf 返回。
8.3 清理 PoolThreadCache 中不经常使用的内存块
Netty 清理 PoolThreadCache 缓存有两个时机,一个是主动清理,当 PoolThreadCache 分配内存块的次数 allocations (包括 Small 规格,Normal 规格的分配次数)达到阈值 freeSweepAllocationThreshold (8192)时 , Netty 将会把 PoolThreadCache 中缓存的所有 Small 规格以及 Normal 规格的内存块全部释放回 PoolSubpage 中。
void trim() {
// 释放 Small 规格缓存
trim(smallSubPageDirectCaches);
// 释放 Normal 规格缓存
trim(normalDirectCaches);
}
private static void trim(MemoryRegionCache<?>[] caches) {
if (caches == null) {
return;
}
for (MemoryRegionCache<?> c: caches) {
trim(c);
}
}
挨个释放 smallSubPageDirectCaches 以及 normalDirectCaches 中的 MemoryRegionCache 。
private abstract static class MemoryRegionCache<T> {
// MemoryRegionCache 中可缓存的最大内存块个数
private final int size;
// MemoryRegionCache 已经分配出去的内存块个数
private int allocations;
public final void trim() {
// 计算最大剩余的内存块个数
int free = size - allocations;
allocations = 0;
// 将剩余的内存块全部释放回内存池中
if (free > 0) {
free(free, false);
}
}
}
释放缓存在 MpscQueue 中的所有内存块。
private int free(int max, boolean finalizer) {
int numFreed = 0;
for (; numFreed < max; numFreed++) {
Entry<T> entry = queue.poll();
if (entry != null) {
freeEntry(entry, finalizer);
} else {
// all cleared
return numFreed;
}
}
return numFreed;
}
从 MpscQueue 中获取 Entry,根据 Entry 结构中封装的内存块信息,将其释放回内存池中。
private void freeEntry(Entry entry, boolean finalizer) {
PoolChunk chunk = entry.chunk;
long handle = entry.handle;
ByteBuffer nioBuffer = entry.nioBuffer;
int normCapacity = entry.normCapacity;
// finalizer = false , 表示由 Netty 主动释放
if (!finalizer) {
// 回收 entry 实例
entry.recycle();
}
// 释放内存块回内存池中
chunk.arena.freeChunk(chunk, handle, normCapacity, sizeClass, nioBuffer, finalizer);
}
另一种清理 PoolThreadCache 缓存的时机是定时被动清理,定时清理机制默认是关闭的。但我们可以通过 -Dio.netty.allocator.cacheTrimIntervalMillis 参数进行开启,该参数默认为 0 , 单位为毫秒,用于指定定时清理 PoolThreadCache 的时间间隔。
// 默认不开启定时清理
if (DEFAULT_CACHE_TRIM_INTERVAL_MILLIS > 0) {
if (executor != null) {
// Reactor 线程会定时清理其 PoolThreadCache 中空闲的内存块,将他们释放回内存池中
executor.scheduleAtFixedRate(trimTask, DEFAULT_CACHE_TRIM_INTERVAL_MILLIS,
DEFAULT_CACHE_TRIM_INTERVAL_MILLIS, TimeUnit.MILLISECONDS);
}
}
8.4 PoolThreadCache 的内存回收流程
当 PooledByteBuf 的引用计数为 0 时,Netty 就会将 PooledByteBuf 背后引用的内存块释放回内存池中,并且将 PooledByteBuf 这个实例释放回对象池。
abstract class PooledByteBuf {
@Override
protected final void deallocate() {
if (handle >= 0) {
final long handle = this.handle;
this.handle = -1;
memory = null;
// 将内存释放回内存池中
chunk.arena.free(chunk, tmpNioBuf, handle, maxLength, cache);
tmpNioBuf = null;
chunk = null;
cache = null;
// 回收 PooledByteBuf 实例
this.recyclerHandle.unguardedRecycle(this);
}
}
}
如果内存块是 Huge 规格的,那么直接释放回 OS , 如果内存块不是 Huge 规格的,那么就根据内存块 handle 结构中的 isSubpage bit 位判断该内存块是 Small 规格的还是 Normal 规格的。
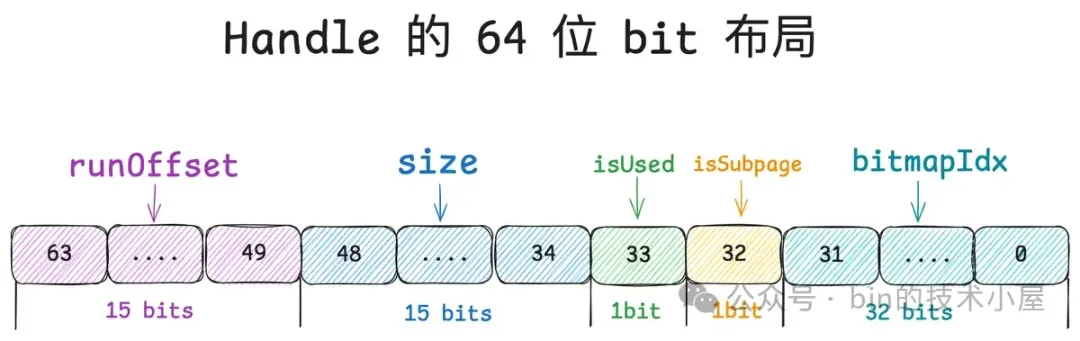
Small 规格 handle 结构 isSubpage bit 位设置为 1 ,Normal 规格 handle 结构 isSubpage bit 位设置为 0 。
private static SizeClass sizeClass(long handle) {
return isSubpage(handle) ? SizeClass.Small : SizeClass.Normal;
}
然后根据内存块的规格释放回对应的 MemoryRegionCache 中。
abstract class PoolArena {
void free(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle, int normCapacity, PoolThreadCache cache) {
// Huge 规格的内存块直接释放回 OS,非池化管理
if (chunk.unpooled) {
int size = chunk.chunkSize();
// 直接将 chunk 的内存释放回 OS
destroyChunk(chunk);
} else {
// 获取内存块的规格 small ? normal ?
SizeClass sizeClass = sizeClass(handle);
// 先释放回对应的 PoolThreadCache 中
// cache.add 返回 false 表示缓存添加失败
if (cache != null && cache.add(this, chunk, nioBuffer, handle, normCapacity, sizeClass)) {
return;
}
// 如果缓存添加失败,则释放回内存池
freeChunk(chunk, handle, normCapacity, sizeClass, nioBuffer, false);
}
}
}
这里缓存添加失败的情况有三种:
-
对应规格的 MemoryRegionCache 已经满了,对于 Small 规格来说,其对应的 MemoryRegionCache 缓存结构最多可以缓存 256 个内存块,对于 Normal 规格来说,则最多可以缓存 64 个。
-
PoolThreadCache 并没有提供对应规格尺寸的 MemoryRegionCache 缓存。比如默认情况下,Netty 只会提供 32K 这一种 Normal 规格的缓存,如果释放 40K 的内存块则只能释放回内存池中。
-
线程对应的本地缓存 PoolThreadCache 已经被释放。比如线程已经退出了,那么其对应的 PoolThreadCache 则会被释放,这时内存块就只能释放回内存池中。
final class PoolThreadCache {
// PoolThreadCache 是否已经被释放
private final AtomicBoolean freed = new AtomicBoolean();
boolean add(PoolArena<?> area, PoolChunk chunk, ByteBuffer nioBuffer,
long handle, int normCapacity, SizeClass sizeClass) {
// 获取要释放内存尺寸大小 normCapacity 对应的内存规格 sizeIndex
int sizeIdx = area.sizeClass.size2SizeIdx(normCapacity);
// 获取 sizeIndex 对应内存规格的 MemoryRegionCache
MemoryRegionCache<?> cache = cache(area, sizeIdx, sizeClass);
if (cache == null) {
return false;
}
// true 表示 PoolThreadCache 已被释放
if (freed.get()) {
return false;
}
// 将内存块释放回对应的 MemoryRegionCache 中
return cache.add(chunk, nioBuffer, handle, normCapacity);
}
}
将内存块释放回对应规格尺寸的 MemoryRegionCache 中。
public final boolean add(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle, int normCapacity) {
// 根据内存块相关的信息封装 Entry 实例
Entry<T> entry = newEntry(chunk, nioBuffer, handle, normCapacity);
// 将 Entry 实例添加到 MpscQueue 中
boolean queued = queue.offer(entry);
if (!queued) {
// 缓存失败,回收 Entry 实例
entry.unguardedRecycle();
}
// true 表示缓存成功
// false 表示缓存满了,添加失败
return queued;
}
8.5 PoolThreadCache 的释放
PoolThreadCache 是线程的本地缓存,里面缓存了内存池中 Small 规格的内存块以及 Normal 规格的内存块。
final class PoolThreadCache {
// 本地缓存线程申请过的 Small 规格内存块
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
// 本地缓存线程申请过的 Normal 规格内存块
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
}
当线程终结的时候,其对应的 PoolThreadCache 也随即会被 GC 回收,但这里需要注意的是 GC 回收的只是 PoolThreadCache 这个 Java 实例,其内部缓存的这些内存块 GC 是管不着的,因为 GC 并不知道这里还有一个内存池的存在。
同样的道理类似于 JDK 中的 DirectByteBuffer,GC 只负责回收 DirectByteBuffer 这个 Java 实例,其背后引用的 Native Memory ,GC 是管不着的,所以我们需要使用额外的机制来保证这些 Native Memory 被及时回收。
对于 JDK 中的 DirectByteBuffer,JDK 使用了 Cleaner 机制来回收背后的 Native Memory ,而对于 PoolThreadCache 来说,Netty 这里则是用了 Finalizer 机制会释放。
对 Cleaner 以及 Finalizer 背后的实现细节感兴趣的读者朋友可以回看下笔者之前的文章 《以 ZGC 为例,谈一谈 JVM 是如何实现 Reference 语义的》。
PoolThreadCache 中有一个 freeOnFinalize 字段:
final class PoolThreadCache {
// 利用 Finalizer 释放 PoolThreadCache
private final FreeOnFinalize freeOnFinalize;
}
当 useFinalizer 为 true 的时候,Netty 会创建一个 FreeOnFinalize 实例:
freeOnFinalize = useFinalizer ? new FreeOnFinalize(this) : null;
FreeOnFinalize 对象再一次循环引用了 PoolThreadCache , FreeOnFinalize 重写了 finalize() 方法,当 FreeOnFinalize 对象创建的时候,JVM 会为其创建一个 Finalizer 对象(FinalReference 类型),Finalizer 引用了 FreeOnFinalize ,但这种引用关系是一种 FinalReference 类型。
private static final class FreeOnFinalize {
// 待释放的 PoolThreadCache
private volatile PoolThreadCache cache;
private FreeOnFinalize(PoolThreadCache cache) {
this.cache = cache;
}
@Override
protected void finalize() throws Throwable {
try {
super.finalize();
} finally {
PoolThreadCache cache = this.cache;
this.cache = null;
// 当 FreeOnFinalize 实例要被回收的时候,触发 PoolThreadCache 的释放
if (cache != null) {
cache.free(true);
}
}
}
}
与 PoolThreadCache 相关的对象引用关系如下图所示:
当线程终结的时候,那么 PoolThreadCache 与 FreeOnFinalize 对象将会被 GC 回收,但由于 FreeOnFinalize 被一个 FinalReference(Finalizer) 引用,所以 JVM 会将 FreeOnFinalize 对象再次复活,由于 FreeOnFinalize 对象也引用了 PoolThreadCache,所以 PoolThreadCache 也会被复活。
随后 JDK 中的 2 号线程 —— finalizer 会执行 FreeOnFinalize 对象的 finalize() 方法,释放 PoolThreadCache。
Thread finalizer = new FinalizerThread(tg);
finalizer.setPriority(Thread.MAX_PRIORITY - 2);
finalizer.setDaemon(true);
finalizer.start();
但如果有人不想使用 Finalizer 来释放的话,则可以通过将 -Dio.netty.allocator.disableCacheFinalizersForFastThreadLocalThreads 设置为 true , 那么 useFinalizer 就会变为 false 。
这样一来当线程终结的时候,它的本地缓存 PoolThreadCache 将不会由 Finalizer 来清理。这种情况下,我们就需要特别注意,一定要通过 FastThreadLocal.removeAll() 或者 PoolThreadLocalCache.remove(PoolThreadCache) 来手动进行清理。否则就会造成内存泄露。
private final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
@Override
protected void onRemoval(PoolThreadCache threadCache) {
threadCache.free(false);
}
}
下面是 PoolThreadCache 的释放流程:
final class PoolThreadCache {
// PoolThreadCache 是否已经被释放
private final AtomicBoolean freed = new AtomicBoolean();
private final FreeOnFinalize freeOnFinalize;
// finalizer = true ,表示释放流程由 finalizer 线程执行
// finalizer = false ,表示释放流程由用户线程执行
void free(boolean finalizer) {
// 我们需要保证 free 操作只能执行一次
// 因为这里有可能会被 finalizer 线程以及用户线程并发执行
if (freed.compareAndSet(false, true)) {
if (freeOnFinalize != null) {
// 如果用户线程先执行 free 流程,那么尽早的断开 freeOnFinalize 与 PoolThreadCache 之间的引用
// 这样可以使 PoolThreadCache 尽早地被回收,不会被后面的 Finalizer 复活
freeOnFinalize.cache = null;
}
// 将 PoolThreadCache 缓存的所有内存块释放回内存池中
// 释放流程与 8.3 小节的内容一致
int numFreed = free(smallSubPageDirectCaches, finalizer) +
free(normalDirectCaches, finalizer) ;
if (directArena != null) {
// PoolArena 的线程绑定计数减 1
directArena.numThreadCaches.getAndDecrement();
}
}
}
9. 内存池相关的 Metrics
为了更好的监控内存池的运行状态,Netty 为内存池中的每个组件都设计了一个对应的 Metrics 类,用于封装与该组件相关的 Metrics。

其中内存池 PooledByteBufAllocator 提供的 Metrics 如下:
public final class PooledByteBufAllocatorMetric implements ByteBufAllocatorMetric {
private final PooledByteBufAllocator allocator;
PooledByteBufAllocatorMetric(PooledByteBufAllocator allocator) {
this.allocator = allocator;
}
// 内存池一共有多少个 PoolArenas
public int numDirectArenas() {
return allocator.numDirectArenas();
}
// 内存池中一共绑定了多少线程
public int numThreadLocalCaches() {
return allocator.numThreadLocalCaches();
}
// 每一种 Small 规格最大可缓存的个数,默认为 256
public int smallCacheSize() {
return allocator.smallCacheSize();
}
// 每一种 Normal 规格最大可缓存的个数,默认为 64
public int normalCacheSize() {
return allocator.normalCacheSize();
}
// 内存池中 PoolChunk 的尺寸大小,默认为 4M
public int chunkSize() {
return allocator.chunkSize();
}
// 该内存池目前一共向 OS 申请了多少内存(包括 Huge 规格)单位为字节
@Override
public long usedDirectMemory() {
return allocator.usedDirectMemory();
}
PoolArena 提供的 Metrics 如下:
abstract class PoolArena<T> implements PoolArenaMetric {
// 一共有多少线程与该 PoolArena 进行绑定
@Override
public int numThreadCaches() {
return numThreadCaches.get();
}
// 一共有多少种 Small 规格尺寸,默认为 39
@Override
public int numSmallSubpages() {
return smallSubpagePools.length;
}
// 该 PoolArena 中一共包含了几个 PoolChunkList
@Override
public int numChunkLists() {
return chunkListMetrics.size();
}
// 该 PoolArena 总共分配内存块的次数(包含 Small 规格,Normal 规格,Huge 规格)
// 一直累加,内存块释放不递减
long numAllocations();
// PoolArena 总共分配 Small 规格的次数,一直累加,释放不递减
long numSmallAllocations();
// PoolArena 总共分配 Normal 规格的次数,一直累加,释放不递减
long numNormalAllocations();
// PoolArena 总共分配 Huge 规格的次数,一直累加,释放不递减
long numHugeAllocations();
// 该 PoolArena 总共回收内存块的次数(包含 Small 规格,Normal 规格,Huge 规格)
// 一直累加
long numDeallocations();
// PoolArena 总共回收 Small 规格的次数,一直累加
long numSmallDeallocations();
// PoolArena 总共回收 Normal 规格的次数,一直累加
long numNormalDeallocations();
// PoolArena 总共释放 Huge 规格的次数,一直累加
long numHugeDeallocations();
// PoolArena 当前净内存分配次数
// 总 Allocations 计数减去总 Deallocations 计数
long numActiveAllocations();
// 同理,PoolArena 对应规格的净内存分配次数
long numActiveSmallAllocations();
long numActiveNormalAllocations();
long numActiveHugeAllocations();
// 该 PoolArena 目前一共向 OS 申请了多少内存(包括 Huge 规格)单位为字节
long numActiveBytes();
}
PoolSubpage 提供的 Metrics 如下:
final class PoolSubpage<T> implements PoolSubpageMetric {
// 该 PoolSubpage 一共可以切分出多少个对应 Small 规格的内存块
@Override
public int maxNumElements() {
return maxNumElems;
}
// 该 PoolSubpage 当前还剩余多少个未分配的内存块
int numAvailable();
// PoolSubpage 管理的 Small 规格尺寸
int elementSize();
// 内存池的 pageSize,默认为 8K
int pageSize();
}
PoolChunkList 提供的 Metrics 如下:
final class PoolChunkList<T> implements PoolChunkListMetric {
// 该 PoolChunkList 中管理的 PoolChunk 内存使用率下限,单位百分比
@Override
public int minUsage() {
return minUsage0(minUsage);
}
// 该 PoolChunkList 中管理的 PoolChunk 内存使用率上限,单位百分比
@Override
public int maxUsage() {
return min(maxUsage, 100);
}
}
PoolChunk 提供的 Metrics 如下:
final class PoolChunk<T> implements PoolChunkMetric {
// 当前 PoolChunk 的内存使用率,单位百分比
int usage();
// 默认 4M
int chunkSize();
// 当前 PoolChunk 中剩余内存容量,单位字节
int freeBytes();
}
总结
到现在为止,关于 Netty 内存池的整个设计与实现笔者就为大家剖析完了,从整个内存池的设计过程来看,我们见到了许多 OS 内核的影子,Netty 也是参考了很多 OS 内存管理方面的设计,如果对 OS 内存管理这块内容感兴趣的读者朋友可以扩展看一下笔者之前写的相关文章:
-
《深度剖析 Linux 伙伴系统的设计与实现》
-
《细节拉满,80 张图带你一步一步推演 slab 内存池的设计与实现》
-
《深度解读 Linux 内核级通用内存池 —— kmalloc 体系》
好了,今天的内容就到这里,我们下篇文章见~~~