导航
- MockingBird仿生环境搭建
- selenium+chrome爬虫环境搭建
- 1.1 安装selenium
- 1.2 安装chrome driver
- 1.3 测试
- 1.4 常见问题
- 驱动不一致
- 原因
- 解决办法
- 最新版本获取
- 自动下载驱动
- NLTK环境搭建
- opencv环境搭建
- pytorch环境搭建
- pyspark环境搭建
- 1 安装环境
- 1.1 jdk下载安装
- 1.2 Scala下载安装
- 1.3 spark下载安装
- 1.4 Hadoop下载安装
- 1.5 pyspark下载安装
- 1.6 环境测试
- 2 问题解答
- 3 环境验证
- sublime插件安装markdown支持
- 安装
- 使用方法:
- sublime运行python
- sublime中安装anaconda,增加自动补全功能
- 修改sublime中python的默认解释器
- frp内网穿透搭建
- 服务端
- 创建frps.service文件
- 启动frps服务
- 客户端
- 创建frpc.service文件
- 启动frpc服务
- frp配置推荐模板
- Expose a simple HTTP file server
- Only allowing certain ports on the server
- Port Reuse
- Bandwidth Limit
- For Each Proxy
- Require HTTP Basic Auth (Password) for Web Services
- squid代理环境搭建
- 1.安装squid
- 2.防火墙配置入站规则
- 3.查看配置文件
- 4. squid的功能
- 5.常用命令
- scrcpy电脑连接手机
- 介绍
- 无线投屏 (WIN 10/11)
- 窗口置顶
- 屏幕录制
- 投屏模糊
- 限制分辨率
- 调整码率
- 多设备连接的情况:
- 关闭手机屏幕
- 报错解决
- Scrcpy 一些实用的命令参数:
- 快捷键:
- 有线连接
- 常用命令
- Autojs开发环境搭建
- ASThook钩子环境搭建
- git环境安装
- Git 快速入门
- Git 安装
- Linux 平台上安装
- Debian/Ubuntu
- Centos/RedHat
- 源码安装
- Windows 平台上安装
- Mac 平台上安装
- Git 配置
- 用户信息
- 文本编辑器
- 差异分析工具
- 查看配置信息
- git clone报错解决
- git 报错fatal: unable to access ‘https://github.com/********.git/‘: OpenSSL SSL_read: Connection was reset
- git clone出现错误"fatal: unable to access 'https://github.com/XXX.git/': Failed to connect to github.com port 443: Timed out"解决办法
- Git 创建仓库
- git init
- 使用方法
- git clone
- 配置
- 目录共享服务器
- 1 导入server2.py文件
- 2 启动python http.server2服务
- 3 阿里云管理控制台添加安全组规则
- 4 常见问题
- nginx代理瓦片图
- 配置文件增加瓦片图路径
- nginx启动命令
MockingBird仿生环境搭建
创建虚拟环境:conda create -n auto_voice python=3.7
激活虚拟环境:activate auto_voice
注:在虚拟环境下安装python3.8,使用pip时会报参数错误的错误,conda remove后安装3.7即可
安装ffmpeg:解压添加环境变量
安装pytoch:
cpu版:conda install pytorch torchvision torchaudio cpuonly -c pytorch
安装依赖:pip install -r requirements.txt -i https://pypi.douban.com/simple
安装 webrtcvad: pip install webrtcvad-wheels -i https://pypi.douban.com/simple
进入项目目录,执行python web.py
启动工具箱:python demo_toolbox.py -d dataset
selenium+chrome爬虫环境搭建
1.1 安装selenium
pip install selenium==3.141.0 -i https://pypi.douban.com/simple
注意:selenium4对find_element有改动,安装selenium3.141.0版本
1.2 安装chrome driver
-
要去chromedriver的版本一定要与系统安装的chrome版本一致(最后一位可以不同),否则无法正常调用。
-
查看chrome版本:
chrome://version/
-
chromedriver下载地址(两个均可,版本一致,windows下载32位即可):
-
http://chromedriver.storage.googleapis.com/index.html
-
https://npm.taobao.org/mirrors/chromedriver/
-
-
将文件解压到任意目录
-
若解压到python解释器根目录,可以不用任何配置,程序中直接调用即可
-
若解压到其他地方,可以有两种方式调用:
-
(1)将该目录添加到path环境变量中。
-
(2)将该目录放入程序调用的参数executable_path中,注意这种方式需要添加文件。
path='D:\\workspace\\chromedriver.exe' driver=webdriver.Chrome(executable_path=path)
-
-
1.3 测试
from selenium import webdriver
path='D:\\workspace\\chromedriver.exe'
driver=webdriver.Chrome(executable_path=path)
driver.get('https://www.baidu.com')
print(driver.page_source)
driver.close()
1.4 常见问题
- selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 88
Current browser version is 90.0.4430.93 with binary path C:\Program Files (x86)\Google\Chrome\Application\chrome.exe- 这个错误是由于chrome和chrome driver版本不一致导致,下载同一版本即可
- selenium.common.exceptions.WebDriverException: Message: ‘chromedriver’ executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
- 这个错误是由于程序未在当前路径下和path中找到chrome driver文件,设置path环境变量或指定路径即可
驱动不一致
from selenium import webdriver
driver = webdriver.Chrome()
报错:
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 114 Current browser version is 117.0.5938.89 with binary path C:\Program Files\Google\Chrome\Application\chrome.exe
原因
没有与chrome匹配的chromedriver驱动文件。
解决办法
chrome的地址栏输入chrome://version,得到117.0.5938.89
于是去下载站找对应的驱动即可,比如https://registry.npmmirror.com/binary.html?path=chromedriver/。
最新版本获取
国内的镜像是定时同步国外的,先看源头
chromedriver官网:ChromeDriver - WebDriver for Chrome
下载页:ChromeDriver - WebDriver for Chrome - Downloads
官网最新也是114.0.5735.90/
但这里有这么一句

继续追溯https://chromedriver.chromium.org/downloads/version-selection
看到这样一句

找到第一个链接the Chrome for Testing (CfT) availability dashboard.
对应地址https://googlechromelabs.github.io/chrome-for-testing/

自动下载驱动
可以使用WebDriver-Manager自动更新驱动程序的版本。安装webdriver-manager:
pip install webdriver-manager
For Chrome:
# selenium 3
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
# selenium 4
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
编写文件时在jupyter notebook中效果更佳
NLTK环境搭建
pip install nltk
import nltk
nltk.download('words')
如果是初次使用nltk
先运行下列代码
import nltk
nltk.download()
双击Models中的punkt模块,进行安装
如果出现 [Error 11004]getaddrinfo failed错误
在 C:\Windows\System32\drivers\etc 路径下找到hosts文件,
打开文件并在文件最后添加 199.232.68.133 raw.githubusercontent.com,并保存
由于nltk的ip地址经常变化,所以上述操作中使用的ip地址不一定一直可行
所以需要打开ip查询网站
https://www.ipaddress.com/
输入如下代码
raw.githubusercontent.com
使用查询到的ip地址进行替换
opencv环境搭建
-
安装anaconda
-
创建虚拟环境
conda create -n opencv python=3.6
-
安装opencv-python
3.4.2后的版本部分模块存在版权问题无法使用,因此最好使用之前的版本,如3.4.1.15pip install opencv-python==3.4.1.15
在python命令行中,import cv2没有报错则安装成功
-
安装opencv-contrib-python
是opencv的扩展,需要与opencv版本保持一致
pip install opencv-contrib-python==3.4.1.15 -
安装matplotlib
pip install matplotlib
pytorch环境搭建
-
安装anaconda
-
创建虚拟环境
conda create -n pytorch python=3.6
- 安装pytorch: https://pytorch.org/
进入虚拟环境后安装,失败重复执行即可(下载包可以放到pkgs中,再安装就无需下载)
conda install pytorch torchvision torchaudio cpuonly -c pytorch

通过import验证即可,torch.cuda.is_available()可以检验是否可以使用cuda
dir()
help()
from torch.utils.data import Dataset
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
pass
def __getitem__(self,index):
pass
return img,label
def __len__(self):
return len(self.img_path)
-
安装tensorboard
pip install tensorboardwriter.add_image(“title”,img_array,step,dataformats=‘HWC’)要求第二个参数的格式为CHW,如果不是可以添加dataformats参数
writer.add_scalar(“title”,y,x)
writer.close()
add_image用于查看图片
add_scalar用于查看数据
from torch.utils.tensorboard import SummaryWriter writer=SummaryWriter("logs") for i in range(100): writer.add_scalar("y=x",i,i) writer.close()terminal运行指令即可在浏览器http://localhost:6006/ 查看
tensorboard --logdir=logs [--port=6007]–logdir指定目录
–port指定端口目录,不指定默认为6006
from torch.utils.tensorboard import SummaryWriter from PIL import Image import numpy as np writer=SummaryWriter("logs") img_PIL=Image.open("D:\\cache\\learn_pytorch\\tex.jpg") img_array=np.array(img_PIL) writer.add_image("train",img_array,1,dataformats='HWC') writer.close() -
安装opencv-python
3.4.2后的版本部分模块存在版权问题无法使用,因此最好使用之前的版本,如3.4.1.15
pip install opencv-python==3.4.1.15在python命令行中,import cv2没有报错则安装成功
-
安装opencv-contrib-python
是opencv的扩展,需要与opencv版本保持一致
pip install opencv-contrib-python==3.4.1.15
pyspark环境搭建
1 安装环境
在python中使用pyspark并不是单纯的导入pyspark包就可以实现的。需要由不同的环境共同搭建spark环境,才可以在python中使用pyspark。
搭建pyspark所需环境:python3,jdk,spark,Scala,Hadoop(可选)
1.1 jdk下载安装
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
安装后设置环境变量:
JAVA_HOME:C:\Program Files\Java\jdk1.8.0_181
CLASSPATH:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
在Path添加:%JAVA_HOME%\bin;
测试是否安装成功:cmd输入java -version
1.2 Scala下载安装
下载地址:https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.msi
安装后设置环境变量:
SCALA_HOME: C:\Program Files (x86)\scala
Path添加:;%SCALA_HOME%\bin;
测试是否安装成功:cmd输入scala -version
1.3 spark下载安装
下载地址:http://mirror.bit.edu.cn/apache/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
也可以选择下载指定版本:http://spark.apache.org/downloads.html
下载好之后解压到任意路径不含空格和中文的目录下即可,设置环境变量:
SPARK_HOME:D:\spark-2.2.0-bin-hadoop2.7
Path添加:%SPARK_HOME%\bin
测试是否安装成功:cmd输入spark-shell
1.4 Hadoop下载安装
如果需要去hdfs取数据的话,就应该先装hadoop。
下载地址:
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
下载好之后解压到任意路径不含空格和中文的目录下即可,设置环境变量:
HADOOP_HOME:D:\hadoop-2.7.7
Path添加:%HADOOP_HOME%\bin
测试是否安装成功:cmd输入hadoop
1.5 pyspark下载安装
python下安装pyspark,可以先去官网上将pyspark下载之后,再进行安装。避免超时
下载地址:https://pypi.tuna.tsinghua.edu.cn/packages/9a/5a/271c416c1c2185b6cb0151b29a91fff6fcaed80173c8584ff6d20e46b465/pyspark-2.4.5.tar.gz
下载之后使用pip install pyspark-2.4.5.tar.gz即可安装。
也可以通过镜像文件在线安装:pip install pyspark -i https://pypi.douban.com/simple
测试是否安装成功:pip list查看是否有pyspark包,也可以进入python,import pyspark不报错则安装成功
1.6 环境测试
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
counts = words.count()
print("Number of elements in RDD -> %i" % counts)
sc.stop()
2 问题解答
报警告:
WARN Shell: Did not find winutils.exe: {}
添加hadoop环境变量,重启IDE
报错:
py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.getPythonAuthSocketTimeout does not exist in the JVM
安装findspark模块,自动查找spark目录
pip install findspark -i https://pypi.douban.com/simple
在py文件开头,添加如下语句
import findspark
findspark.init()
注意:在jupyter中运行时,不要调用findspark,直接执行即可。
报错:org.apache.spark.SparkException: Python worker failed to connect back.
spark找不到Python的位置。设置个环境变量就可以了
import os
os.environ['PYSPARK_PYTHON'] = r"D:\anaconda\envs\spark//python.exe" #放Python的位置
3 环境验证
验证pyspark环境
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
counts = words.count()
print("Number of elements in RDD -> %i" % counts)
sc.stop()
sublime插件安装markdown支持
安装
-
调出命令窗口:ctrl+shit+p
-
输入install,点击package control:install package
-
安装md相关插件:
Markdown Editing MarkdownLivePreview Markdown Preview -
安装sublime自动保存插件:auto-save
-
配置markdownLivePreview:输入set mp,点击MarkdownLivePreview: Open Settings,将左侧的default复制到右侧user栏中,添加"markdown_live_preview_on_open": true。
已经安装的在ctrl+shit+p出入的框中输入;
未安装的进入命令窗口后在install package里边输入。
使用方法:
- sublime打开一个.md文件,在开头添加如下代码:
<meta http-equiv="refresh" content="5">; - ctrl+shift+p调出命令窗口,输入autosave,点击当前文件或者所有文件,开启自动保存;
- ctrl+shift+p调出命令窗口,输入mp,点击markdown preview:preview in browser,通过浏览器打开md文件进行预览。
以上过程可以满足使用sublime编写md文件并自动保存,使用浏览器进行实时查看效果。
sublime运行python
- 按ctrl+shift+p快捷键呼出一个输入框,输入Install Package,回车。
- 再次按ctrl+shift+p快捷键呼出一个输入框,输入Install Package,回车;等待一段时间出现 如下图界面,输入SublimeREPL进行安装。
- 点击Tools->sublimeREPL->python->python run current file,这时候就像IDLE一样,会弹出一个新的窗口,而且是可交互的,可以输入。
- 设置运行快捷键:点击preferences->key bindings
{ "keys":["f5"],
"caption": "SublimeREPL: Python - RUN current file",
"command": "run_existing_window_command",
"args": {"id": "repl_python_run","file": "config/Python/Main.sublime-menu"}
}
sublime中安装anaconda,增加自动补全功能
需要注意的是,Anaconda安装完成后,如果我们写的代码不符合PEP8标准(https://www.python.org/dev/peps/pep-0008/),插件会自动把不符合标准的代码用白色框标识出来,看上去较乱。可以通过下面的方法直接关闭Anaconda的这项提示:
进入菜单 Preferences > Package Settings > Anaconda > Settings User 中添加如下代码:
{“anaconda_linting”: false}
修改sublime中python的默认解释器
进入sublime安装路径:D:\programs\Sublime Text\Packages
找到python配置包:Python.sublime-package
使用解压软件打开,找到里边的Python.sublime-build文件,使用文本文件打开,将其中的cmd解释器路径修改为自己的:
{
"cmd": ["python", "-u", "$file"],
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
"selector": "source.python",
"env": {"PYTHONIOENCODING": "utf-8"},
"windows": {
"cmd": ["D:/programs/anaconda/python.exe", "-u", "$file"],
},
"variants":
[
{
"name": "Syntax Check",
"cmd": ["python", "-m", "py_compile", "$file"],
"windows": {
"cmd": ["D:/programs/anaconda/python.exe", "-m", "py_compile", "$file"],
}
}
]
}
替换压缩文件中的文件即可。
frp内网穿透搭建
1.根据linux架构下载不同的软件
uname -a
1
不是最直观的,但是也是一个不错的命令。
nvidia@tegra-ubuntu:~$ uname -a
Linux tegra-ubuntu 4.4.38-tegra #1 SMP PREEMPT Fri Jul 28 09:55:22 PDT 2017 aarch64 aarch64 aarch64 GNU/Linux
1
2
aarch64就是ARM架构
openwrt@ubuntu:~$ uname -a
Linux ubuntu 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
1
2
X86架构
root@IceCreamBox:~# uname -a
Linux DrogooBox 3.3.8 #33 Tue Mar 22 15:02:01 CST 2016 mips GNU/Linux
1
2
MIPS架构
————————————————
版权声明:本文为CSDN博主「奔狼的春晓」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lixuande19871015/article/details/90485929
| 386 | X86架构 |
|---|---|
| 386 | X86架构 |
| amd64 | amd架构 |
| arm | arm架构 |
| arm64 | 64位arm架构 |
| mips | mips架构 |
| mips64 | 64位mips架构 |
| mipsle | mipsle架构 |
| mips64le | 64位mipsle架构 |
2.配置server
frps.ini
[common]
enable_prometheus=true
bind_port = 7000
dashboard_port=7500
dashboard_user=admin
dashboard_pwd=config
#admin_addr=127.0.0.1
admin_addr=0.0.0.0
admin_port=7400
admin_user=admin
admin_pwd=config
代理web服务:
[common]
bind_port = 8888
vhost_http_port = 8080
enable_prometheus=true
dashboard_port=7500
dashboard_user=admin
dashboard_pwd=config
#admin_addr=127.0.0.1
admin_addr=0.0.0.0
admin_port=7400
admin_user=admin
admin_pwd=config
# frp日志配置
log_file = /usr/regentwan/log/frps.log
log_level = info
log_max_days = 3
3.启动server
./frps -c ./frps.ini
后台运行:./frps -c ./frps.ini &
配置server防火墙,开启端口
firewall-cmd --list-ports #查看端口开放情况
firewall-cmd --zone=public --add-port=7000/tcp --permanent #开放7000端口
firewall-cmd --zone=public --add-port=7500/tcp --permanent #开放7500端口
firewall-cmd --zone=public --add-port=8080/tcp --permanent #开放8080端口
#命令含义
--zone #作用域
--add-port=7000/tcp #添加端口,格式为:端口/通讯协议
--permanent #永久生效
systemctl restart firewalld.service #重启防火墙
云服务器的入站规则中添加相应访问端口
如果是代理web,则需要添加vhost_http_port,并在防火墙中添加该端口
4.配置client
[common]#server ip和端口
server_addr = 120.55.66.156
server_port = 7000
[ssh]#22端口穿透
type = tcp
local_ip = 127.0.0.1
local_port = 22
remote_port = 500
[share_file]#共享目录
type = tcp
remote_port = 5004
plugin = static_file
plugin_local_path = D:\software\develop\装机套餐
plugin_strip_prefix = share
plugin_http_user = admin
plugin_http_passwd = config
[python_server]#共享内网服务
type = tcp
local_ip = 127.0.0.1
local_port = 8000
remote_port = 5005
本地借助python共享目录:python -m http.server 8000
代理本地web服务:
[common]
server_addr = 123.60.104.207
server_port = 8888
[web]
type = http
local_port = 8000
custom_domains = 123.60.104.207
注意:custom_domains是公网ip或域名,而不是本地ip。使用123.60.104.207:8080访问
5.启动client
frpc.exe -c frpc.ini
可以在server和client同时添加口令进行验证
# 授权码,请改成更复杂的,客户端连接使用
token = 1234
6.添加服务开机自启
服务端
创建frps.service文件
vim /etc/systemd/system/frps.service
[Unit]
# 服务名称,可自定义
Description = frp server
After = network.target syslog.target
Wants = network.target
[Service]
Type = simple
# 启动frps的命令,需修改为刚才frp放置的地址
ExecStart = /usr/regentwan/software/frp_0.48.0_linux_386/frps -c /usr/regentwan/software/frp_0.48.0_linux_386/frps.ini
[Install]
WantedBy = multi-user.target
启动frps服务
# 启动frp
systemctl start frps
# 配置frps开机自启
systemctl enable frps
客户端
创建frpc.service文件
sudo vim /etc/systemd/system/frpc.service
[Unit]
# 服务名称,可自定义
Description = frp server
After = network.target syslog.target
Wants = network.target
[Service]
Type = simple
# 启动frpc的命令,需修改为刚才frp放置的地址
ExecStart = 安装路径/frpc -c 安装路径frpc.ini
[Install]
WantedBy = multi-user.target
启动frpc服务
# 启动frpc
systemctl start frpc
# 配置frpc开机自启
systemctl enable frpc
参考:https://cloud.tencent.com/developer/article/2183247
https://github.com/fatedier/frp
GitHub - fatedier/frp: A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet.GitHub - fatedier/frp: A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet.
frp配置推荐模板
以下配置适合0.10.0~0.16.1版本
frp客户端与服务端0.9.3及以下版本兼容,0.10.0~0.16.1版本兼容,使用时需要注意
0.18.0以上版本把配置中的“privilege_”字段去掉即可
1、frpc客户端
[common]
server_addr = www.yourdomain.com
#frps服务端地址
server_port = 7000
#frps服务端通讯端口,客户端连接到服务端内网穿透传输数据的端口
privilege_token = frp888
#特权模式密钥,客户端连接到FRPS服务端的验证密钥
log_file = frpc.log
#日志存放路径
log_level = info
#日志记录类别,可选:trace, debug, info, warn, error
log_max_days = 7
#日志保存天数
login_fail_exit = false
#设置为false,frpc连接frps失败后重连,默认为true不重连
protocol = kcp
#KCP协议在弱网环境下传输效率提升明显,但是对frps会有一些额外的流量消耗。服务端须先设置kcp_bind_port = 7000,www.yourdomain.com服务端已设置支持
[http_dsm]
#穿透服务名称,不能和其他已建立的相同,使用公共服务器的建议修改成复杂一点的名称,避免与其他人冲突,很多路由器内置frpc的默认服务名称为[web],很容易很其他人冲突
type = http
#穿透协议类型,可选:tcp,udp,http,https,stcp,xtcp,这个设置之前必须自行搞清楚应该是什么
local_ip = 192.168.1.2
#本地监听IP,可以是本机IP,也可以是本地的局域网内某IP,例如你的局域网是互通的,你可以在路由器上安装frpc,然后local_ip填的内网其他机器ip,这样也可以把内网其他机器穿透出去
local_port = 5000
#本地监听端口,通常有ssh端口22,远程桌面3389等等
use_compression = true
#对传输内容进行压缩,可以有效减小 frpc 与 frps 之间的网络流量,加快流量转发速度,但是会额外消耗一些 cpu 资源
use_encryption = true
#将 frpc 与 frps 之间的通信内容加密传输
custom_domains = dsm.yourdomain.com
#自定义域名访问穿透服务,一般域名设置了二级域名泛解析以后,这里填*.yourdomain.com即可,*自定义,如果不想用域名或者自行搭建frps没有域名,则穿透协议类型选择tcp,见以下tcp部分详解
#通过app访问的注意,DS file,DS video,DS audio,DS finder里地址栏默认都是5000端口,穿透后地址栏须填写为【穿透域名:80】,DS photo由于本地local_port为80,穿透后也为80的话直接写域名地址即可
[https_dsm]
type = https
local_ip = 192.168.1.2
local_port = 5001
use_compression = true
use_encryption = true
custom_domains = dsm.yourdomain.com
#以上https配置同http,注意开启https(默认5001端口),证书配置在客户端,无证书的注意浏览器访问时添加信任
[http_transmission]
type = http
local_ip = 192.168.1.2
local_port = 9091
use_compression = true
use_encryption = true
custom_domains = tr.yourdomain.com
#transmission下载客户端
[http_rutorrent]
type = http
local_ip = 192.168.1.2
local_port = 80
use_compression = true
use_encryption = true
custom_domains = rt.yourdomain.com
#rutorrent下载客户端,用Download Station的类似,注意端口
[http_blog]
type = http
local_ip = 192.168.1.2
local_port = 80
use_compression = true
use_encryption = true
custom_domains = blog.yourdomain.com
[http_plex]
type = http
local_ip = 192.168.1.2
local_port = 32400
use_compression = true
use_encryption = true
custom_domains = plex.yourdomain.com
#plex视频服务器
[https_feixun]
privilege_mode = true
type = http
local_ip = 192.168.1.1
#路由器ip
local_port = 80
use_compression = true
use_encryption = true
authentication_timeout = 0
custom_domains = feixun.yourdomain.com
#穿透路由器
[tcp_ssh]
#ssh连接
type = tcp
local_ip = 192.168.1.2
local_port = 22
use_compression = true
use_encryption = true
remote_port = 3463
#远程端口,一般tcp和udp需要设置,不需要设置custom_domain,访问时为【frps服务器地址+远程端口】,没有域名的用这种方式通过【frps服务器地址+远程端口】即可实现访问
[udp]
type = udp
local_ip = 192.168.1.2
local_port = 53
use_compression = true
use_encryption = true
remote_port = 3453
访问时为【frps服务器地址+远程端口】
2、frps服务端
自行搭建服务端配置参考(必须有公网ip)
[common]
bind_addr = 0.0.0.0
#服务器IP,0.0.0.0为服务器全局所有IP可用,假如你的服务器有多个IP则可以这样做,或者填写为指定其中的一个服务器IP,支持IPV6
bind_port = 7000
#通讯端口,用于和客户端内网穿透传输数据的端口,可自定义
bind_udp_port = 7001
#UDP通讯端口,用于点对点内网穿透
kcp_bind_port = 7000
#用于KCP协议UDP通讯端口,在弱网环境下传输效率提升明显,但是会有一些额外的流量消耗。设置后frpc客户端须设置protocol = kcp
vhost_http_port = 80
#http监听端口,注意可能和服务器上其他服务用的80冲突,比如centos有些默认有Apache,可自定义
vhost_https_port = 443
#https监听端口,可自定义
dashboard_port = 7500
#通过浏览器查看 frp 的状态以及代理统计信息展示端口,可自定义
dashboard_user = admin
#信息展示面板用户名
dashboard_pwd = admin
#信息展示面板密码
log_max_days = 7
#最多保存多少天日志
privilege_token = frp888
#特权模式认证密钥
privilege_allow_ports = 1-65535
#端口白名单,为了防止端口被滥用,可以手动指定允许哪些端口被使用
max_pool_count = 100
#每个内网穿透服务限制最大连接池上限,避免大量资源占用,可自定义
authentication_timeout = 0
#frpc 所在机器和 frps 所在机器的时间相差不能超过 15 分钟,因为时间戳会被用于加密验证中,防止报文被劫持后被其他人利用,单位为秒,默认值为 900,即 15 分钟。如果修改为 0,则 frps 将不对身份验证报文的时间戳进行超时校验。国外服务器由于时区的不同,时间会相差非常大,这里需要注意同步时间或者设置此值为0
log_file = frps.log
log_level = info
Expose a simple HTTP file server
Browser your files stored in the LAN, from public Internet.
Configure frps same as above.
- Start
frpcwith configuration:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[test_static_file]
type = tcp
remote_port = 6000
plugin = static_file
plugin_local_path = /tmp/files
plugin_strip_prefix = static
plugin_http_user = abc
plugin_http_passwd = abc
- Visit
http://x.x.x.x:6000/static/from your browser and specify correct user and password to view files in/tmp/fileson thefrpcmachine.
Only allowing certain ports on the server
allow_ports in frps.ini is used to avoid abuse of ports:
# frps.ini
[common]
allow_ports = 2000-3000,3001,3003,4000-50000
allow_ports consists of specific ports or port ranges (lowest port number, dash -, highest port number), separated by comma ,.
Port Reuse
vhost_http_port and vhost_https_port in frps can use same port with bind_port. frps will detect the connection’s protocol and handle it correspondingly.
We would like to try to allow multiple proxies bind a same remote port with different protocols in the future.
Bandwidth Limit
For Each Proxy
# frpc.ini
[ssh]
type = tcp
local_port = 22
remote_port = 6000
bandwidth_limit = 1MB
Set bandwidth_limit in each proxy’s configure to enable this feature. Supported units are MB and KB.
Require HTTP Basic Auth (Password) for Web Services
Anyone who can guess your tunnel URL can access your local web server unless you protect it with a password.
This enforces HTTP Basic Auth on all requests with the username and password specified in frpc’s configure file.
It can only be enabled when proxy type is http.
# frpc.ini
[web]
type = http
local_port = 80
custom_domains = test.example.com
http_user = abc
http_pwd = abc
Visit http://test.example.com in the browser and now you are prompted to enter the username and password.
squid代理环境搭建
1.安装squid
软件下载地址为http://squid.diladele.com/。傻瓜式安装完成即可。
2.防火墙配置入站规则
控制面板\系统和安全\Windows Defender 防火墙
点击高级设置、入站规则、新建规则(规则类型选择端口、规则应用于TCP、特定本地端口设置为3128),名称设置为Squid Server,点击完成即添加完入站规则。
3.查看配置文件
核心配置文件为安装目录下的etc/squid目录下的squid.conf.default。配置规则与路由器和交换机的配置类似。
#
# Recommended minimum configuration:
#
# Example rule allowing access from your local networks.
# Adapt to list your (internal) IP networks from where browsing
# should be allowed
acl localnet src 0.0.0.1-0.255.255.255 # RFC 1122 "this" network (LAN)
acl localnet src 10.0.0.0/8 # RFC 1918 local private network (LAN)
acl localnet src 100.64.0.0/10 # RFC 6598 shared address space (CGN)
acl localnet src 169.254.0.0/16 # RFC 3927 link-local (directly plugged) machines
acl localnet src 172.16.0.0/12 # RFC 1918 local private network (LAN)
acl localnet src 192.168.0.0/16 # RFC 1918 local private network (LAN)
acl localnet src fc00::/7 # RFC 4193 local private network range
acl localnet src fe80::/10 # RFC 4291 link-local (directly plugged) machines
acl SSL_ports port 443
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 # https
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl CONNECT method CONNECT
#
# Recommended minimum Access Permission configuration:
#
# Deny requests to certain unsafe ports
http_access deny !Safe_ports
# Deny CONNECT to other than secure SSL ports
http_access deny CONNECT !SSL_ports
# Only allow cachemgr access from localhost
http_access allow localhost manager
http_access deny manager
# We strongly recommend the following be uncommented to protect innocent
# web applications running on the proxy server who think the only
# one who can access services on "localhost" is a local user
#http_access deny to_localhost
#
# INSERT YOUR OWN RULE(S) HERE TO ALLOW ACCESS FROM YOUR CLIENTS
#
# Example rule allowing access from your local networks.
# Adapt localnet in the ACL section to list your (internal) IP networks
# from where browsing should be allowed
http_access allow localnet
http_access allow localhost
# And finally deny all other access to this proxy
http_access deny all
# Squid normally listens to port 3128
http_port 3128
# Uncomment and adjust the following to add a disk cache directory.
#cache_dir ufs /var/cache/squid 100 16 256
# Leave coredumps in the first cache dir
coredump_dir /var/cache/squid
#
# Add any of your own refresh_pattern entries above these.
#
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern -i (/cgi-bin/|\?) 0 0% 0
refresh_pattern . 0 20% 4320
可以从Squid Terminal或cmd进入根目录的命令行窗口,执行squid命令:
- 检查配置文件语法问题
squid -k parse
- 停止或启动squid
squid -z
在客户端设置代理为本机ip/端口为3128即可实现正向代理。
4. squid的功能
squid服务器的功能:
- 提供对HTTP和FTP协议的代理服务。
- 缓存代理的内容,提高客户端访问网站的速度,并能够节约出口网络流量。
- 对客户端地址进行访问控制,限制运行访问的squid服务器的客户机。
- 对目标地址进行访问控制,限制客户端允许访问的网站。
- 根据时间进行访问控制,限制客户端可以使用代理服务器的时间。
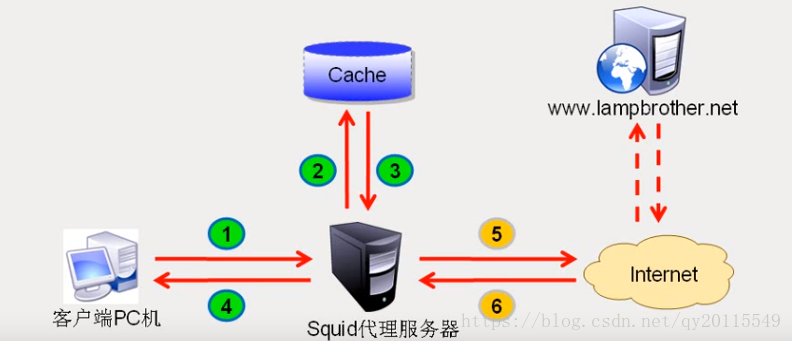
缓存代理的作用:
-
通过缓存机制,加速用户访问网站。(缓存池如果有客户端请求的文件,则直接提供给浏览器或客户端;即使缓存池有内容,代理服务器还是要想服务器取数据的–一般看数据是否过期、返回动态文件)。
-
对用户的网站访问进行过滤控制。
-
普通代理服务,即标准的的、传统的代理服务,需要客户机在浏览器中指定代理服务器的地址与端口。普通代理服务,在浏览器中进行设置就行了。非IT人员,可能会带来不必要的麻烦,如没办法上网。
-
透明代理服务,适用于企业的网关主机,客户机不需要指定代理服务器的地址、端口等信息。通过iptables将客户机的Web访问数据转交给代理服务器程序处理。
Directive ‘header_access’ is obsolete.
5.常用命令
-
squid -k parse 查看配置信息
-
squid start 启动服务,查看是否配置有问题(通过软件start的方式失败也不会报错,无法确定原因)
-
squid restart 重启服务
http_port 80 accel vhost allow-direct
设置透明代理后,不需要配置客户端的代理,只需要将代理服务器的ip作为客户端网关即可。
http_port 3128 transparent
结合iptables可以实现代理+网关+内容过滤+流量安全控制等完整的上网解决方案。
globalprotect实现国际网络访问
squid实现正向代理,其他设备可以设置该代理后通过该主机进行访问
frp实现内网穿透,通过一个公网ip指向局域网中主机,局域网中主机指定公网frps运行端口号(7000)与公网主机进行绑定,再在局域网中frpc中指定远程端口号用于访问使用
squid好像只能设置局域网代理,无法进行公网代理。
经试验仅可做局域网代理,无法在公网代理
scrcpy电脑连接手机
介绍
scrcpy 是免费开源的投屏软件,支持将安卓手机屏幕投放在 Windows、macOS、GNU/Linux 上,并可直接借助鼠标在投屏窗口中进行交互和录制。市面上主流的多屏协同软件都是基于 scrcpy,套层皮,bug 几乎没改,推荐直接使用 scrcpy。
https://github.com/Genymobile/scrcpy
电脑端完成配置后,我们还需要在手机端开启 开发者选项 及 USB 调试。然后使用数据线将手机和电脑连接并允许 USB 调试,双击解压得到的 scrcpy.exe 文件,即可进行有线投屏。如有报错,参考文章底部的说明。
无线投屏 (WIN 10/11)
确保 PC 和手机处于同一局域网中
打开 PowerShell (~ cmd),依次操作并输入代码
# a.将代码目录定位到 scrcpy 文件夹。
cd D:\Libraries\Desktop\scrcpy-win64-v1.24
# WIN11 在 scrcpy 文件夹中右键「在终端中打开」,将自动定位。
# b.在手机端开启「开发者选项」及「USB 调试」,然后使用数据线将手机和电脑连接并允许 USB 调试,开启手机端口
# 如果本行显示 no device 或未启动 adb,需检查「USB 调试」是否开启,或更换数据线。
# 此外,一些手机需选择「文件传输」模式方能使用 adb。
.\adb tcpip 5555
# c.拔出手机数据线,开始无线投屏。(192.168.2.15 为手机端的 WIFI 局域网 ip,需更改)
.\adb connect 192.168.2.15:5555
# d.启动 scrcpy.exe
.\scrcpy
# 如有报错或延迟较大,可启动低分辨率投屏
.\scrcpy -m 1024
# 连接多个设备,报错提示`failed to get feature set: more than one device/emulator`,则指定连接 tcpip 设备
.\scrcpy -e -m 1024
# 简化操作:合并步骤 c 和 d,保持屏幕常亮,使用 1024 分辨率
.\scrcpy --tcpip=192.168.2.15 -w -m 1024
窗口置顶
如果你想要电脑上的手机界面置顶在最上层,方便在进行其他操作时也可以看到手机画面,可以尝试这个命令:
scrcpy --always-on-top
scrcpy -T
屏幕录制
.\scrcpy -r filename.mp4
一种是投屏状态下录屏:(录屏会保存到当前的执行路径中)
scrcpy --record file.mp4
scrcpy -r file.mkv
一种是非投屏状态下录屏:
scrcpy --no-display --record file.mp4
scrcpy -Nr file.mkv
投屏模糊
如果屏幕设置了缩放比例,投屏界面会模糊。右键 scrcpy.exe,属性 - 兼容性 - 更改高 DPI 设置 - 勾选替代高 DPI 缩放行为,应用后,该问题可解决。
限制分辨率
设备分辨率越高,延迟越大,用这个命令可以限制分辨率大小,保证性能。
scrcpy --max-size 1024
scrcpy -m 1024 # 简短一点的命令,效果相同
调整码率
默认码率是 8M,码率越高,画质越好,同时延迟越大,可自行调整:
scrcpy --bit-rate 2M
scrcpy -b 2M # 简短一点的命令,效果相同
※ 通过限制分辨率和码率,可以减少延迟,尤其是无线连接手机时效果更佳。
多设备连接的情况:
如果有多个设备同时连接电脑,需要按照前面获取的 ID 号来操作打开 scrcpy:
scrcpy --serial d905c36
scrcpy -s e5a53d97
关闭手机屏幕
投屏操作下关闭手机屏幕,只在电脑上看到手机的亮屏状态,可以使用快捷键 Ctrl+O,或者尝试以下命令:
scrcpy --turn-screen-off
scrcpy -S
报错解决
- 报错检查:90% 的错误,都出在这三步。
核对有线连接步骤,开启 USB 调试-连接手机与电脑-启动 scrcpy;
检查手机的「本机 IP」是否正确;
更换数据线。
- ERROR: Exception on thread Thread[main,5,main] 此项错误多为手机不兼容 scrcpy 默认分辨率设置。解决方位为,按下方修改 scrcpy 启动代码,使用较低的分辨率。
# 三项设置,任选其一
.\scrcpy -m 1920
.\scrcpy -m 1024
.\scrcpy -m 800
Scrcpy 一些实用的命令参数:
这些参数可以多个自由组合使用,注意区分大小写。
关闭手机屏幕 scrcpy -S
限制画面分辨率 scrcpy -m 1024 (比如限制为 1024)
修改视频码率 scrcpy -b 4M (默认 8Mbps,改成 4Mbps)
裁剪画面 scrcpy -c 1224:1440:0:0
表示分辨率 1224x1440 并且偏移坐标为 (0,0)
多设备切换 scrcpy -s 设备ID (使用 adb devices 命令查看设备ID)
窗口置顶 scrcpy -T
显示触摸点击 scrcpy -t
在演示或录制教程时,可在画面上对应显示出点击动作
全屏显示 scrcpy -f
文件传输默认路径 scrcpy --push-target /你的/目录
将文件拖放到 scrcpy 可以传输文件,此命令指定默认保存目录
只读模式(仅显示不控制) scrcpy -n
屏幕录像 scrcpy -r 视频文件名.mp4 或 .mkv
屏幕录像 (禁用电脑显示) scrcpy -Nr 文件名.mkv
设置窗口标题 scrcpy --window-title ‘xxxxxx!’
同步传输声音
可借助 USBaudio 这个开源项目实现,但仅支持 Linux 系统
快捷键:
切换全屏模式 Ctrl+F
将窗口调整为1:1(完美像素) Ctrl+G
调整窗口大小以删除黑色边框 Ctrl+X | 双击黑色背景
设备 BACK 键 Ctrl+B | 鼠标右键
设备 HOME 键 Ctrl+H | 鼠标中键
设备 任务管理 键 (切换APP) Ctrl+S
设备 菜单 键 Ctrl+M
设备音量+键 Ctrl+↑
设备音量-键 Ctrl+↓
设备电源键 Ctrl+P
点亮手机屏幕 鼠标右键
复制内容到设备 Ctrl+V
启用/禁用 FPS 计数器(stdout) Ctrl+i
安装APK 将 apk 文件拖入投屏
传输文件到设备 将文件拖入投屏(非apk)
有线连接
手机连接电脑,开启调试模式,选择文件传输
输入adb devices查看设备
再输入scrcpy即可投屏,如果有多个设备则添加序列号
https://blog.csdn.net/j1451284189/article/details/116053027
常用命令
adb devices
adb -s 设备名 kill-server
adb tcpip port
adb connect ip:port
https://blog.csdn.net/SoIKnow/article/details/125469040
scrcpy
–window-borderless
–always-on-top
–stay-awake -w
–turn-screen-off -S
以上两个可以合并-Sw
scrcpy --tcpip=192.168.0.103:5555 --always-on-top -Sw
Autojs开发环境搭建
- 连接scrcpy后,投屏手机
- 在vscode中下载autojs插件(作者hyb1996)
- ctrl+shift+P调出命令,输入start启动服务
- 在手机端安装autojs4.0后开启相关权限,选择连接电脑,输入电脑ip
- 在vscode中编写脚本
- ctrl+shift+P调出命令,执行run,查看效果
帮助中切换到开发人员工具,可以查看控制台输出
Auto.js-Autox.js-VSCodeExtv1.109.0
aaron cheng
这个插件 运行用F5
ASThook钩子环境搭建
1.安装nodejs:node版本至少到14.0.0+,建议更新到最新的LTS版本。
2.安装工具
npm install anyproxy
3.安装证书
anyproxy ca
访问127.0.0.1:8002,点击RootCA下载证书并安装到受信任的根证书颁发机构。然后就可以关闭了。
4.下载ast-hook
https://github.com/CC11001100/ast-hook-for-js-RE
5.启动代理服务
启动:node src/proxy-server/proxy-server.js,运行在10086端口。
6.启动接口服务
node src/api-server/api-server.js
7.浏览器设置代理
127.0.0.1 10086
8.请求页面数据,在控制台搜索参数
hook.search('4DA6328ED82E464C7C1A9735C490F9E0')
9.测试地址
www.xiniudata.com/industry/newest?from=data
www.jizhy.com/44/rank/school
参考:https://blog.51cto.com/u_13599097/5437614?articleABtest=0
https://blog.csdn.net/weixin_46672080/article/details/126582359
git环境安装
Git 快速入门
本站也提供了 Git 快速入门版本,你可以点击 Git 简明指南 查看。
入门后建议通过本站详细学习 Git 教程。
Git 完整命令手册地址:http://git-scm.com/docs
PDF 版命令手册:github-git-cheat-sheet.pdf
Git 安装
各平台安装包下载地址为:http://git-scm.com/downloads
Linux 平台上安装
Git 的工作需要调用 curl,zlib,openssl,expat,libiconv 等库的代码,所以需要先安装这些依赖工具。
在有 yum 的系统上(比如 Fedora)或者有 apt-get 的系统上(比如 Debian 体系),可以用下面的命令安装:
各 Linux 系统可以使用其安装包管理工具(apt-get、yum 等)进行安装:
Debian/Ubuntu
Debian/Ubuntu Git 安装命令为:
$ apt-get install libcurl4-gnutls-dev libexpat1-dev gettext \
libz-dev libssl-dev
$ apt-get install git
$ git --version
git version 1.8.1.2
Centos/RedHat
如果你使用的系统是 Centos/RedHat 安装命令为:
$ yum install curl-devel expat-devel gettext-devel \
openssl-devel zlib-devel
$ yum -y install git-core
$ git --version
git version 1.7.1
源码安装
我们也可以在官网下载源码包来安装,最新源码包下载地址:https://git-scm.com/download
安装指定系统的依赖包:
########## Centos/RedHat ##########
$ yum install curl-devel expat-devel gettext-devel \
openssl-devel zlib-devel
########## Debian/Ubuntu ##########
$ apt-get install libcurl4-gnutls-dev libexpat1-dev gettext \
libz-dev libssl-dev
解压安装下载的源码包:
$ tar -zxf git-1.7.2.2.tar.gz
$ cd git-1.7.2.2
$ make prefix=/usr/local all
$ sudo make prefix=/usr/local install
Windows 平台上安装
在 Windows 平台上安装 Git 同样轻松,有个叫做 msysGit 的项目提供了安装包,可以到 GitHub 的页面上下载 exe 安装文件并运行:
安装包下载地址:https://gitforwindows.org/
官网慢,可以用国内的镜像:https://npm.taobao.org/mirrors/git-for-windows/。
完成安装之后,就可以使用命令行的 git 工具(已经自带了 ssh 客户端)了,另外还有一个图形界面的 Git 项目管理工具。
在开始菜单里找到"Git"->“Git Bash”,会弹出 Git 命令窗口,你可以在该窗口进行 Git 操作。
Mac 平台上安装
在 Mac 平台上安装 Git 最容易的当属使用图形化的 Git 安装工具,下载地址为:
http://sourceforge.net/projects/git-osx-installer/
Git 配置
Git 提供了一个叫做 git config 的工具,专门用来配置或读取相应的工作环境变量。
这些环境变量,决定了 Git 在各个环节的具体工作方式和行为。这些变量可以存放在以下三个不同的地方:
/etc/gitconfig文件:系统中对所有用户都普遍适用的配置。若使用git config时用--system选项,读写的就是这个文件。~/.gitconfig文件:用户目录下的配置文件只适用于该用户。若使用git config时用--global选项,读写的就是这个文件。- 当前项目的 Git 目录中的配置文件(也就是工作目录中的
.git/config文件):这里的配置仅仅针对当前项目有效。每一个级别的配置都会覆盖上层的相同配置,所以.git/config里的配置会覆盖/etc/gitconfig中的同名变量。
在 Windows 系统上,Git 会找寻用户主目录下的 .gitconfig 文件。主目录即 $HOME 变量指定的目录,一般都是C:\Users\runjun.wan。
此外,Git 还会尝试找寻 /etc/gitconfig 文件,只不过看当初 Git 装在什么目录,就以此作为根目录来定位。
用户信息
配置个人的用户名称和电子邮件地址:
$ git config --global user.name "runoob"
$ git config --global user.email test@runoob.com
如果用了 –global 选项,那么更改的配置文件就是位于你用户主目录下的那个,以后你所有的项目都会默认使用这里配置的用户信息。
如果要在某个特定的项目中使用其他名字或者电邮,只要去掉 --global 选项重新配置即可,新的设定保存在当前项目的 .git/config 文件里。
[user]
name = regentwan
email = wanrunjun@gmail.com
[merge]
tool = vimdiff
[gui]
recentrepo = C:/Users/runjun.wan/Desktop/gitdown1
recentrepo = C:/Users/runjun.wan/Desktop/gitdown
[http]
sslVerify = false
[credential]
helper = store
文本编辑器
设置Git默认使用的文本编辑器, 一般可能会是 Vi 或者 Vim。如果你有其他偏好,比如 Emacs 的话,可以重新设置::
$ git config --global core.editor emacs
差异分析工具
还有一个比较常用的是,在解决合并冲突时使用哪种差异分析工具。比如要改用 vimdiff 的话:
$ git config --global merge.tool vimdiff
Git 可以理解 kdiff3,tkdiff,meld,xxdiff,emerge,vimdiff,gvimdiff,ecmerge,和 opendiff 等合并工具的输出信息。
当然,你也可以指定使用自己开发的工具,具体怎么做可以参阅第七章。
查看配置信息
要检查已有的配置信息,可以使用 git config --list 命令:
git clone报错解决
git 报错fatal: unable to access ‘https://github.com/********.git/‘: OpenSSL SSL_read: Connection was reset
解决办法:
git config --global credential.helper store
git clone出现错误"fatal: unable to access ‘https://github.com/XXX.git/’: Failed to connect to github.com port 443: Timed out"解决办法
解决办法:将https改成git
git clone git://github.com/XXX.git
Git 创建仓库
本章节我们将为大家介绍如何创建一个 Git 仓库。
你可以使用一个已经存在的目录作为Git仓库。
git init
Git 使用 git init 命令来初始化一个 Git 仓库,Git 的很多命令都需要在 Git 的仓库中运行,所以 git init 是使用 Git 的第一个命令。
在执行完成 git init 命令后,Git 仓库会生成一个 .git 目录,该目录包含了资源的所有元数据,其他的项目目录保持不变。
使用方法
使用当前目录作为 Git 仓库,我们只需使它初始化。
git init
该命令执行完后会在当前目录生成一个 .git 目录。
使用我们指定目录作为Git仓库。
git init newrepo
初始化后,会在 newrepo 目录下会出现一个名为 .git 的目录,所有 Git 需要的数据和资源都存放在这个目录中。
如果当前目录下有几个文件想要纳入版本控制,需要先用 git add 命令告诉 Git 开始对这些文件进行跟踪,然后提交:
$ git add *.c
$ git add README
$ git commit -m '初始化项目版本'
以上命令将目录下以 .c 结尾及 README 文件提交到仓库中。
注: 在 Linux 系统中,commit 信息使用单引号 ',Windows 系统,commit 信息使用双引号 "。
所以在 git bash 中 git commit -m ‘提交说明’ 这样是可以的,在 Windows 命令行中就要使用双引号 git commit -m “提交说明”。
git clone
我们使用 git clone 从现有 Git 仓库中拷贝项目(类似 svn checkout)。
克隆仓库的命令格式为:
git clone <repo>
如果我们需要克隆到指定的目录,可以使用以下命令格式:
git clone <repo> <directory>
参数说明:
- **repo:**Git 仓库。
- **directory:**本地目录。
比如,要克隆 Ruby 语言的 Git 代码仓库 Grit,可以用下面的命令:
$ git clone git://github.com/schacon/grit.git
执行该命令后,会在当前目录下创建一个名为grit的目录,其中包含一个 .git 的目录,用于保存下载下来的所有版本记录。
如果要自己定义要新建的项目目录名称,可以在上面的命令末尾指定新的名字:
$ git clone git://github.com/schacon/grit.git mygrit
配置
git 的设置使用 git config 命令。
显示当前的 git 配置信息:
$ git config --list
credential.helper=osxkeychain
core.repositoryformatversion=0
core.filemode=true
core.bare=false
core.logallrefupdates=true
core.ignorecase=true
core.precomposeunicode=true
编辑 git 配置文件:
$ git config -e # 针对当前仓库
或者:
$ git config -e --global # 针对系统上所有仓库
设置提交代码时的用户信息:
$ git config --global user.name "runoob"
$ git config --global user.email test@runoob.com
如果去掉 –global 参数只对当前仓库有效。
目录共享服务器
前提:安装python
利用python的http server搭建一个文件共享服务器,但是python自带的http server仅支持查看下载功能,并不支持上传功能。故本文稍作修改,能够同时支持上传下载。
1 导入server2.py文件
server2中加入了上传的代码,在python的安装目录中,进入Lib\http,将如下代码保存为server2.py。
__version__ = "0.1"
__all__ = ["SimpleHTTPRequestHandler"]
import html
import http.server
import mimetypes
import os
import posixpath
import re
import shutil
import urllib.error
import urllib.parse
import urllib.request
from io import BytesIO
class SimpleHTTPRequestHandler(http.server.BaseHTTPRequestHandler):
"""简单的http文件服务器,支持上传下载
"""
server_version = "SimpleHTTPWithUpload/" + __version__
def do_GET(self):
f = self.send_head()
if f:
self.copyfile(f, self.wfile)
f.close()
def do_HEAD(self):
f = self.send_head()
if f:
f.close()
def do_POST(self):
r, info = self.deal_post_data()
print((r, info, "by: ", self.client_address))
f = BytesIO()
f.write(b'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">')
f.write(b"<html>\n<title>Upload Result Page</title>\n")
f.write(b"<body>\n<h2>Upload Result Page</h2>\n")
f.write(b"<hr>\n")
if r:
f.write(b"<strong>Success:</strong>")
else:
f.write(b"<strong>Failed:</strong>")
f.write(info.encode())
f.write(("<br><a href=\"%s\">back</a>" % self.headers['referer']).encode())
f.write(b"</body>\n</html>\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(length))
self.end_headers()
if f:
self.copyfile(f, self.wfile)
f.close()
def deal_post_data(self):
content_type = self.headers['content-type']
if not content_type:
return (False, "Content-Type header doesn't contain boundary")
boundary = content_type.split("=")[1].encode()
remainbytes = int(self.headers['content-length'])
line = self.rfile.readline()
remainbytes -= len(line)
if not boundary in line:
return (False, "Content NOT begin with boundary")
line = self.rfile.readline()
remainbytes -= len(line)
fn = re.findall(r'Content-Disposition.*name="file"; filename="(.*)"', line.decode())
if not fn:
return (False, "Can't find out file name...")
path = self.translate_path(self.path)
fn = os.path.join(path, fn[0])
line = self.rfile.readline()
remainbytes -= len(line)
line = self.rfile.readline()
remainbytes -= len(line)
try:
out = open(fn, 'wb')
except IOError:
return (False, "Can't create file to write, do you have permission to write?")
preline = self.rfile.readline()
remainbytes -= len(preline)
while remainbytes > 0:
line = self.rfile.readline()
remainbytes -= len(line)
if boundary in line:
preline = preline[0:-1]
if preline.endswith(b'\r'):
preline = preline[0:-1]
out.write(preline)
out.close()
return (True, "File '%s' upload success!" % fn)
else:
out.write(preline)
preline = line
return (False, "Unexpect Ends of data.")
def send_head(self):
path = self.translate_path(self.path)
f = None
if os.path.isdir(path):
if not self.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(301)
self.send_header("Location", self.path + "/")
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
ctype = self.guess_type(path)
try:
# Always read in binary mode. Opening files in text mode may cause
# newline translations, making the actual size of the content
# transmitted *less* than the content-length!
f = open(path, 'rb')
except IOError:
self.send_error(404, "File not found")
return None
self.send_response(200)
self.send_header("Content-type", ctype)
fs = os.fstat(f.fileno())
self.send_header("Content-Length", str(fs[6]))
self.send_header("Last-Modified", self.date_time_string(fs.st_mtime))
self.end_headers()
return f
def list_directory(self, path):
try:
list = os.listdir(path)
except os.error:
self.send_error(404, "No permission to list directory")
return None
list.sort(key=lambda a: a.lower())
f = BytesIO()
displaypath = html.escape(urllib.parse.unquote(self.path))
f.write(b'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">')
f.write(("<html>\n<title>Directory listing for %s</title>\n" % displaypath).encode())
f.write(("<body>\n<h2>Directory listing for %s</h2>\n" % displaypath).encode())
f.write(b"<hr>\n")
f.write(b"<form ENCTYPE=\"multipart/form-data\" method=\"post\">")
f.write(b"<input name=\"file\" type=\"file\"/>")
f.write(b"<input type=\"submit\" value=\"upload\"/></form>\n")
f.write(b"<hr>\n<ul>\n")
for name in list:
fullname = os.path.join(path, name)
displayname = linkname = name
# Append / for directories or @ for symbolic links
if os.path.isdir(fullname):
displayname = name + "/"
linkname = name + "/"
if os.path.islink(fullname):
displayname = name + "@"
# Note: a link to a directory displays with @ and links with /
f.write(('<li><a href="%s">%s</a>\n'
% (urllib.parse.quote(linkname), html.escape(displayname))).encode())
f.write(b"</ul>\n<hr>\n</body>\n</html>\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(length))
self.end_headers()
return f
def translate_path(self, path):
path = path.split('?', 1)[0]
path = path.split('#', 1)[0]
path = posixpath.normpath(urllib.parse.unquote(path))
words = path.split('/')
words = [_f for _f in words if _f]
path = os.getcwd()
for word in words:
drive, word = os.path.splitdrive(word)
head, word = os.path.split(word)
if word in (os.curdir, os.pardir): continue
path = os.path.join(path, word)
return path
def copyfile(self, source, outputfile):
shutil.copyfileobj(source, outputfile)
def guess_type(self, path):
base, ext = posixpath.splitext(path)
if ext in self.extensions_map:
return self.extensions_map[ext]
ext = ext.lower()
if ext in self.extensions_map:
return self.extensions_map[ext]
else:
return self.extensions_map['']
if not mimetypes.inited:
mimetypes.init() # try to read system mime.types
extensions_map = mimetypes.types_map.copy()
extensions_map.update({
'': 'application/octet-stream', # Default
'.py': 'text/plain',
'.c': 'text/plain',
'.h': 'text/plain',
})
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--bind', '-b', default='', metavar='ADDRESS',
help='Specify alternate bind address '
'[default: all interfaces]')
parser.add_argument('--port', '-p', default=8000, type=int,
help='Specify alternate port [default: 8000]')
args = parser.parse_args()
http.server.test(HandlerClass=SimpleHTTPRequestHandler, port=args.port, bind=args.bind)
2 启动python http.server2服务
进入想要共享的目录后,输入如下命令:
python -m http.server2
这里为了本地测试可以修改一下host,进入C:\Windows\System32\drivers\etc,添加
127.0.0.1 localhost
::1 localhost
默认启动的是8000端口,后边配置也开启8000端口即可。
3 阿里云管理控制台添加安全组规则
为了外网能够正常访问该服务,需要配置入方向规则



4 常见问题
通过以上配置,基本上就可以在外网通过ip:port的方式访问了。

如果启动http.server2的时候显示只能通过ipv6的方式访问,则可以通过-b 0.0.0.0的方式添加ipv4访问:
python -m http.server2 -b 0.0.0.0
有时为了访问方便,可以通过-p设置端口参数为80,访问时可以直接省略80端口。
python -m http.server2 -p 80
nginx代理瓦片图
配置文件增加瓦片图路径
location /map/ {
alias D:/software/nginx-1.24.0/html/map/;
autoindex on;
}
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
location /map/ {
alias D:/software/nginx-1.24.0/html/map/;
autoindex on;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
nginx启动命令
start nginx # 开启nginx
nginx -s stop # 关闭nginx
nginx -s reload # 重新启动nginx
nginx -v # 查看版本号
nginx -t # 验证配置文件是否正确
https://www.jianshu.com/p/f8cad88c5e64