hello,大家好,本讲我们一起聊一下常见的几个并发工具类的使用和坑!
在日常工作中,我们经常会遇到多线程并发问题,比如ThreadLocal、锁、ConcurrentHashMap、CopyOnWriteArrayList等。那么如何正常的使用呢?下面我们来一探究竟!
一、ThreadLocal
ThreadLocal 相信大家都很熟悉了,它是为了解决多线程的资源竞争问题的,比如两个线程同时访问同一个变量并修改它,我们需要保证两个线程不互相影响。是一种用于实现线程本地存储的工具类,允许你为每个线程创建和维护独立的变量副本。这样,每个线程都可以独立地改变它自己的副本,而不会影响其他线程的副本。这对于需要在多线程环境中保持状态的情况特别有用,而又不希望使用同步机制来共享状态。
废话不多说,直接上代码~
比如我们有一个 SpringBoot 的 Web 项目,使用 ThreadLocal 来保存用户上下文信息。
代码如下:
@RequestMapping
@RestController
public class ThreadLocalController {
private static final ThreadLocal currentUser = ThreadLocal.withInitial(() -> null);
@GetMapping("wrong")
public Map wrong(@RequestParam("userId") Integer userId) {
//设置用户信息之前先查询一次ThreadLocal中的用户信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置用户信息到ThreadLocal
currentUser.set(userId);
// 设置用户信息之后再查询一次ThreadLocal中的用户信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
}
}
定义一个ThreadLocal类型的变量currentUser用于存储用户信息,在wrong方法中,在设置请求的用户 id 之前和之后分别获取一次currentUser存储的用户信息,并将结果返回。
配置文件:
server.tomcat.threads.max=1
将 tomcat 线程池的最大线程数设置成 1,原因后面再解释。
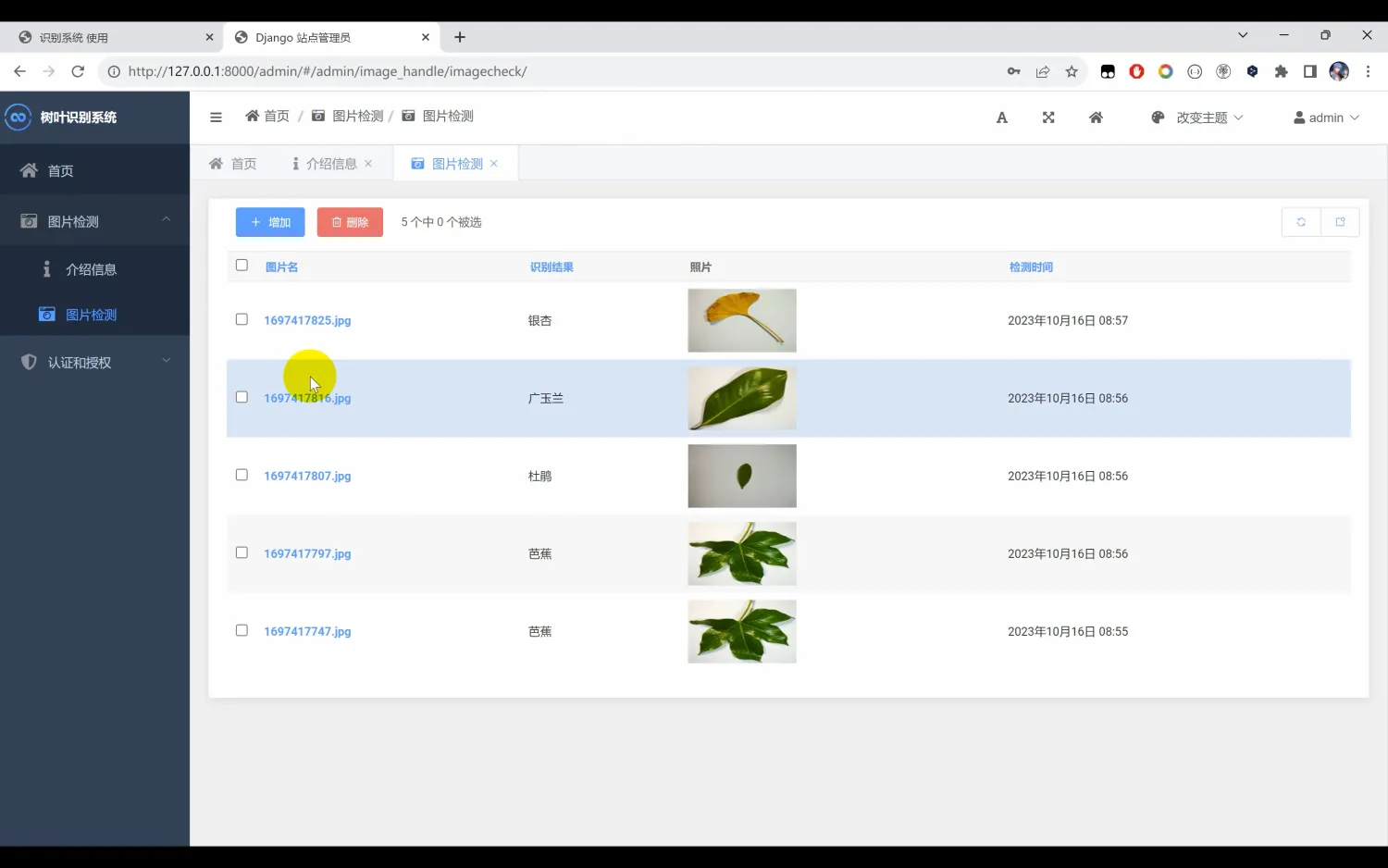
第一次请求http://localhost:8080/wrong?userId=1
请求结果:
{
"before": "http-nio-8080-exec-1:null",
"after": "http-nio-8080-exec-1:1"
}
符合预期,因为在设置用户之前,currentUser中是没有值的。
第二次请求http://localhost:8080/wrong?userId=2
请求结果:
{
"before": "http-nio-8080-exec-1:1",
"after": "http-nio-8080-exec-1:2"
}
我们看这个请求结果就出现问题了,按理说 before 应该也是 null,若是用户 1 的话,那我们在业务中通过currentUser中存储的用户操作数据时,数据上体现的操作人和实际操作人不一致。
为什么会产生这种问题呢?
springboot 程序是运行在 tomcat 上的,而 tomcat 中是有线程池来处理这些请求的(为了提高效率,避免频繁创建销毁线程),前面设置了server.tomcat.threads.max=1,也就是将 tomcat 最大线程设置为 1,所有的请求都是通过这个线程执行的。而ThreadLocal类型的变量currentUser是数据线程级别的,在第一次请求后,线程并没有被销毁,而是归还到了线程池中,也就是线程中的变量还是存在的。所以第二次请求时就可以获取到第一次请求设置的变量。所以我们在使用 ThreadLocal 是注意的点:
使用类似 ThreadLocal 工具来存放一些数据时,需要特别注意在代码运行完后,显式地去清空设置的数据
另外除了获取数据混乱的问题外,还可能导致内存泄漏问题,如每次请求都往ThreadLocal变量中放到数据,一直没有得到清空,从而导致内存泄漏。
正确的使用方式:
@GetMapping("right")
public Map right(@RequestParam("userId") Integer userId) {
String before = Thread.currentThread().getName() + ":" + currentUser.get();
currentUser.set(userId);
try {
String after = Thread.currentThread().getName() + ":" + currentUser.get();
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
} finally {
//在finally代码块中删除ThreadLocal中的数据,确保数据不串
currentUser.remove();
}
}
二、ConcurrentHashMap
ConcurrentHashMap 是 Java 中的一个线程安全的哈希表实现,用于在多线程环境下高效地存储和检索键值对。它是 java.util.concurrent 包的一部分,设计用于替代传统的 Hashtable 和同步包装的 HashMap(通过 Collections.synchronizedMap 生成的同步 Map)。
主要特点
-
高效并发:ConcurrentHashMap 允许多个线程并发地读写数据,而不会发生线程间的冲突。它通过分段锁(在 Java 8 之前)或 CAS 操作(在 Java 8 及之后)来实现高效的并发访问。
-
无锁读取:读取操作通常不需要加锁,能够在不锁定整个数据结构的情况下进行并发读取。
-
部分锁定:在 Java 8 之前,ConcurrentHashMap 使用分段锁(Segment)来减少锁的粒度。每个 Segment 是一个小的哈希表,只有在写操作时才需要锁定特定的 Segment。Java 8 之后,ConcurrentHashMap 使用了更为精细化的锁机制,结合 CAS 操作来进一步提高并发性能。
-
不允许 null 键或值:与 HashMap 不同,ConcurrentHashMap 不允许存储 null 键或 null 值。
特别要注意的是:ConcurrentHashMap 只能保证提供的原子性读写操作是线程安全的。
下面我们来解释下这句话。
假如有这样一个场景,map 可以存入 1000 个数据,现在map 中已有 900 个数据,现在用 10 个线程往 map 中插入数据,每次插入之前,先查询下 map 中还需要多少数据,然后放入。此时很多同学觉得使用ConcurrentHashMap可以解决这个所谓的线程并发问题,其实不然,上代码:
@RequestMapping("chm")
@RestController
public class CHMController {
Logger log = LoggerFactory.getLogger(CHMController.class);
//线程个数
private static int THREAD_COUNT = 10;
//总元素数量
private static int ITEM_COUNT = 1000;
//帮助方法,用来获得一个指定元素数量模拟数据的ConcurrentHashMap
private ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(Collectors.toConcurrentMap(i -> UUID.randomUUID().toString(), Function.identity(),
(o1, o2) -> o1, ConcurrentHashMap::new));
}
@GetMapping("wrong")
public String wrong() throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
//初始900个元素
log.info("init size:{}", concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
//使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//查询还需要补充多少个元素
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("gap size:{}", gap);
//补充元素
concurrentHashMap.putAll(getData(gap));
}));
//等待所有任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//最后元素个数会是1000吗?
log.info("finish size:{}", concurrentHashMap.size());
return "OK";
}
}
运行结果:
2024-10-21T18:30:35.789+08:00 INFO 8228 --- [demo] [nio-8080-exec-1] com.csdn.demo.controller.CHMController : finish size:1700
2024-10-21T18:35:43.793+08:00 INFO 8228 --- [demo] [nio-8080-exec-1] com.csdn.demo.controller.CHMController : init size:900
2024-10-21T18:35:43.794+08:00 INFO 8228 --- [demo] [Pool-2-worker-1] com.csdn.demo.controller.CHMController : gap size:100
2024-10-21T18:35:43.794+08:00 INFO 8228 --- [demo] [Pool-2-worker-4] com.csdn.demo.controller.CHMController : gap size:100
2024-10-21T18:35:43.794+08:00 INFO 8228 --- [demo] [Pool-2-worker-3] com.csdn.demo.controller.CHMController : gap size:100
2024-10-21T18:35:43.795+08:00 INFO 8228 --- [demo] [Pool-2-worker-5] com.csdn.demo.controller.CHMController : gap size:15
2024-10-21T18:35:43.795+08:00 INFO 8228 --- [demo] [Pool-2-worker-1] com.csdn.demo.controller.CHMController : gap size:0
2024-10-21T18:35:43.795+08:00 INFO 8228 --- [demo] [Pool-2-worker-2] com.csdn.demo.controller.CHMController : gap size:100
2024-10-21T18:35:43.795+08:00 INFO 8228 --- [demo] [Pool-2-worker-6] com.csdn.demo.controller.CHMController : gap size:100
2024-10-21T18:35:43.795+08:00 INFO 8228 --- [demo] [Pool-2-worker-1] com.csdn.demo.controller.CHMController : gap size:-181
2024-10-21T18:35:43.795+08:00 INFO 8228 --- [demo] [Pool-2-worker-7] com.csdn.demo.controller.CHMController : gap size:-300
2024-10-21T18:35:43.795+08:00 INFO 8228 --- [demo] [Pool-2-worker-5] com.csdn.demo.controller.CHMController : gap size:-315
2024-10-21T18:35:43.796+08:00 INFO 8228 --- [demo] [nio-8080-exec-1] com.csdn.demo.controller.CHMController : finish size:1415
通过运行结果可以看到,最后concurrentHashMap变量存入的数据为 1415 个,而不是预期的 1000 个。
- 初始大小为 900 个,正确
- 每个线程查出来缺少的数据有 100 的,有 15 的,还有负数的,显然是不对的
- 最后 map 中存入的总数是 1415
造成这种结果的原因是查询缺少多少个和添加数据操作不是原子的,这就解释了上面说的ConcurrentHashMap 只能保证提供的原子性读写操作是线程安全的。
解决方法也比较简单:那就是加锁synchronized
@GetMapping("right")
public String right() throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
log.info("init size:{}", concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//下面的这段复合逻辑需要锁一下这个ConcurrentHashMap
synchronized (concurrentHashMap) {
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("gap size:{}", gap);
concurrentHashMap.putAll(getData(gap));
}
}));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
log.info("finish size:{}", concurrentHashMap.size());
return "OK";
}
这样做虽然可以解决原子问题,但是并不能发挥出ConcurrentHashMap自身的能力。
其实我们可以使用ConcurrentHashMap提供的原子性方法 computeIfAbsent,判断 Key 是否存在 Value,如果不存在则把 Lambda 表达式运行后的结果放入 Map 作为 Value,如果存在则通过increment方法加 1
private Map<String, Long> gooduse() throws InterruptedException {
ConcurrentHashMap<String, LongAdder> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
//利用computeIfAbsent()方法来实例化LongAdder,然后利用LongAdder来进行线程安全计数
freqs.computeIfAbsent(key, k -> new LongAdder()).increment();
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//因为我们的Value是LongAdder而不是Long,所以需要做一次转换才能返回
return freqs.entrySet().stream()
.collect(Collectors.toMap(
e -> e.getKey(),
e -> e.getValue().longValue())
);
}
这种方式提升了性能(比synchronized)。原因在于computeIfAbsent底层使用 Java 自带的 Unsafe 实现的 CAS。它在虚拟机层面确保了写入数据的原子性,比加锁的效率高得多。
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
三、CopyOnWriteArrayList
最后我们简单的说说CopyOnWriteArrayList。从名字也可以看出来,它的原理就是写时复制。但是使用不当可能会造成严重的性能问题。因为很多同学只知道他是写时复制,却忽略了一个场景,那就是它适用于读多写少的场景,为什么呢?我们来看它的源码:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
synchronized (lock) {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
}
}
在添加元素时,先复制出一个数组,元素添加到复制出来的数组中,最后在重新设置回去,而复制数据这一步时非常耗时的。所以当我们的场景是读多写少时,可以使用CopyOnWriteArrayList来解决线程安全问题。
好啦,以上就是本篇文章要介绍的内容了,欢迎小伙伴们一起讨论!!!

![P7400 [COCI2020-2021#5] Magenta 题解](https://i-blog.csdnimg.cn/direct/448792d885f84545b19ecf914539201c.jpeg#pic_center)