目录
序言
1 拉取 Qwen2.5-Coder-7B 模型
2 编写python测试模型
3 启动webui导入模型测试
4 模型评估
4.1 前期准备工作
4.2 Qwen2.5-Coder-7B 模型评估
数据说明
综合分析
4.3 deepseek-coder-7b-base-v1.5 模型评估
数据说明
综合分析
4.4 模型比较
1. 文本生成质量
2. 模型准备时间
3. 运行时间
4. 处理效率
综合比较
结论
序言
autoDL的环境准备
【LLaMA-Factory】【autoDL】:大模型微调实践-CSDN博客
1 拉取 Qwen2.5-Coder-7B 模型
编写python代码
from huggingface_hub import snapshot_download
# huggingface地址:https://huggingface.co/
# 在这上面找到模型路径,修改即可
model_path = "Qwen/Qwen2.5-Coder-7B"
cache_dir = "/root/autodl-tmp/Qwen-Code"
snapshot_download(repo_id=model_path, local_dir=cache_dir, local_dir_use_symlinks=False)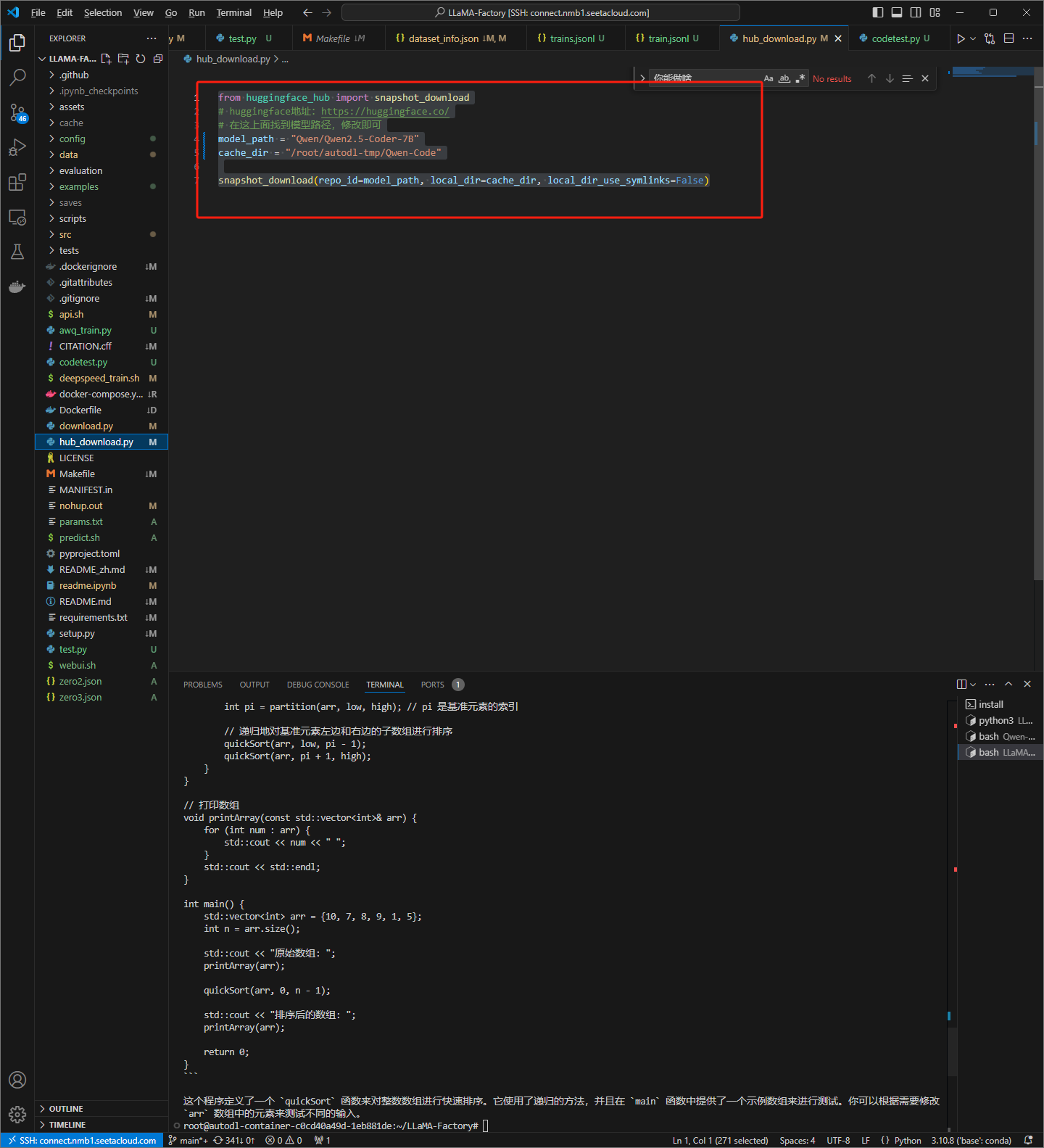
学术加速

运行python代码,拉取模型
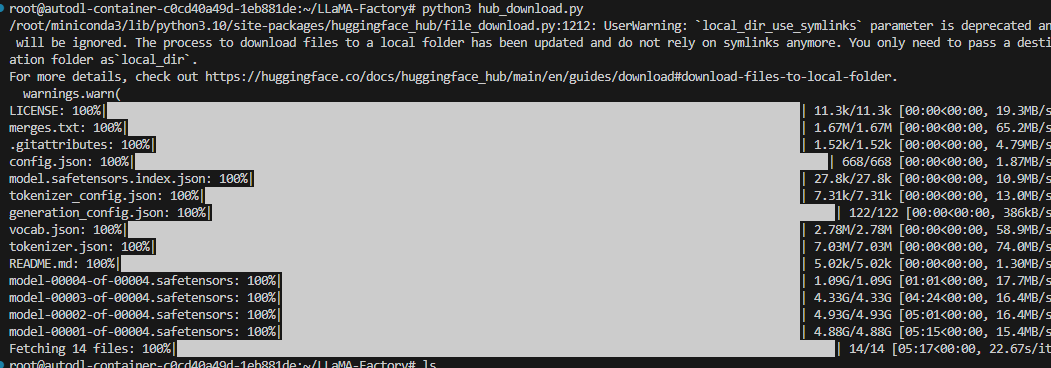
2 编写python测试模型
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 1. 加载 tokenizer 和模型
model_name = "Qwen/Qwen2.5-Coder-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 假设你的模型保存在本地路径 '/path/to/your/local/model'
local_model_path = "/root/autodl-tmp/Qwen-Code"
model = AutoModelForCausalLM.from_pretrained(local_model_path)
# 2. 准备输入文本
user_input = "使用C++编写一个快速排序"
input_ids = tokenizer.encode(user_input, return_tensors="pt") # 将输入编码为 token IDs
# 3. 使用模型生成文本
# 注意:可以设置生成参数如 max_length, num_return_sequences 等
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
# 4. 解码生成的 token IDs 为可读文本
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 5. 打印生成的文本
print(generated_text)运行结果
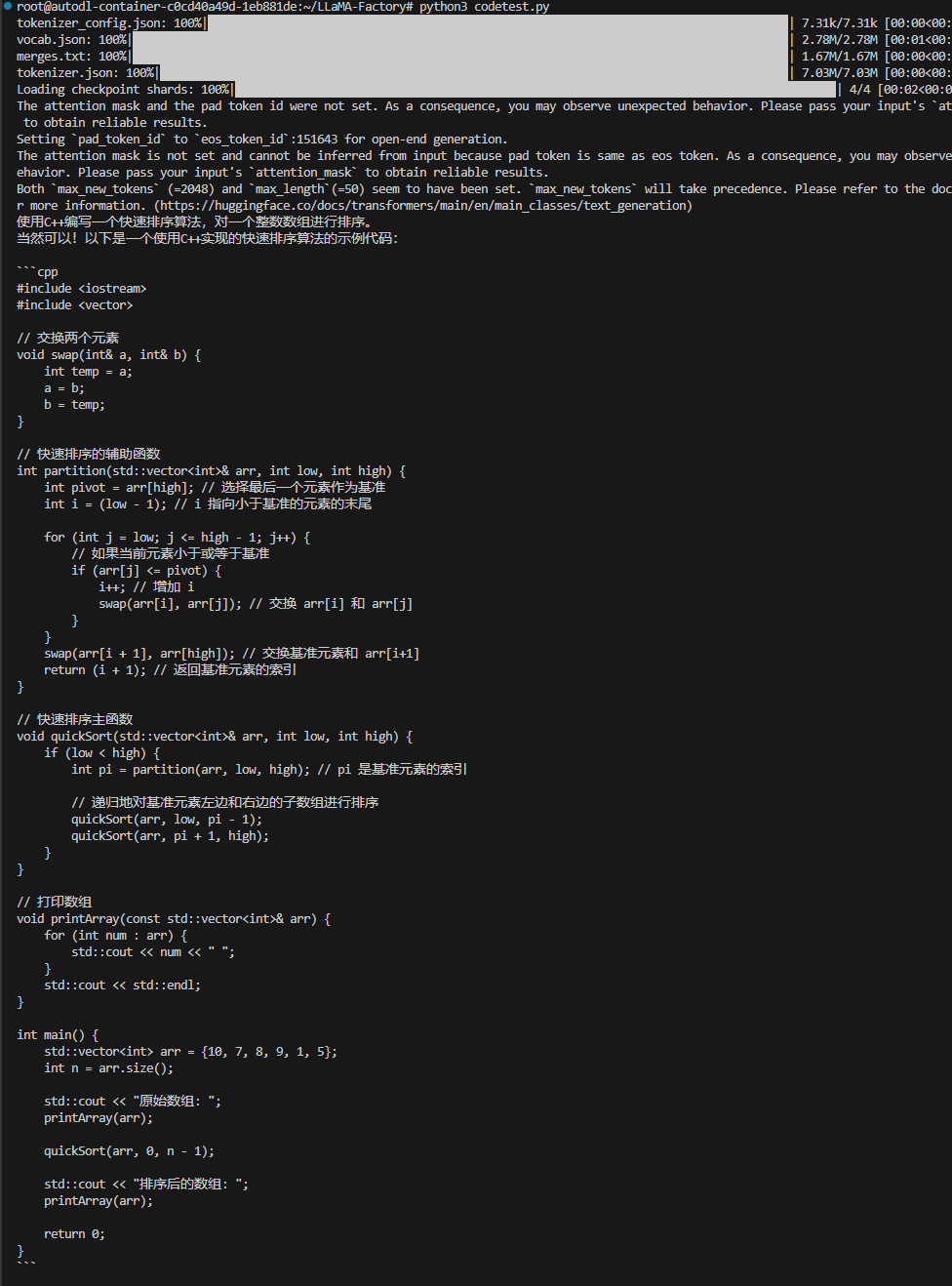
3 启动webui导入模型测试
启动 webui
python3 src/webui.py
导入模型
对话测试
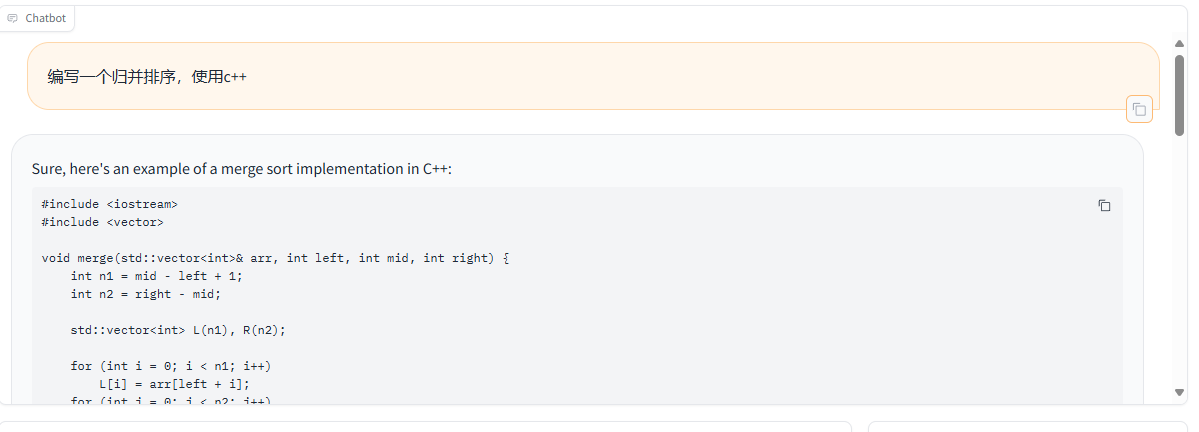
4 模型评估
清理系统内存
https://www.autodl.com/docs/qa1/
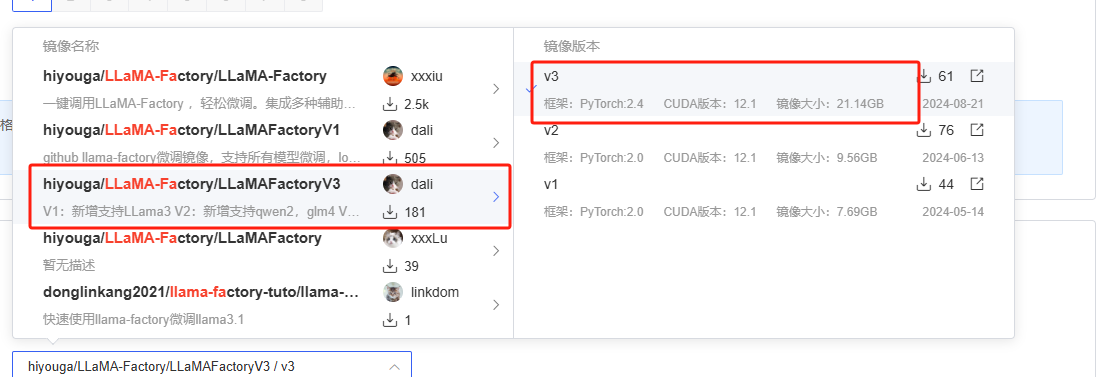
4.1 前期准备工作
硬件:两块4090显卡

环境:使用 hiyouga/LLaMA-Factory/LLaMAFactoryV3 / v3 镜像
该镜像 PyTorch版本为2.4 CUDA版本为 12.1
数据集准备
https://huggingface.co/datasets/deepseek-ai/DeepSeek-Prover-V1
数据清洗
import json
input_file_path = 'test.jsonl'
output_file_path = 'Test.jsonl'
with open(input_file_path, 'r', encoding='utf-8') as infile, \
open(output_file_path, 'w', encoding='utf-8') as outfile:
for line in infile:
data = json.loads(line.strip())
processed_data = {
"instruction": data.get("question"),
"input": "",
"output": data.get("response"),
"system": data.get("system_prompt"),
"history": []
}
json.dump(processed_data, outfile, ensure_ascii=False)
outfile.write('\n')
print("处理完成,结果已保存到", output_file_path)修改相应的dataset_info.json文件为测试做准备
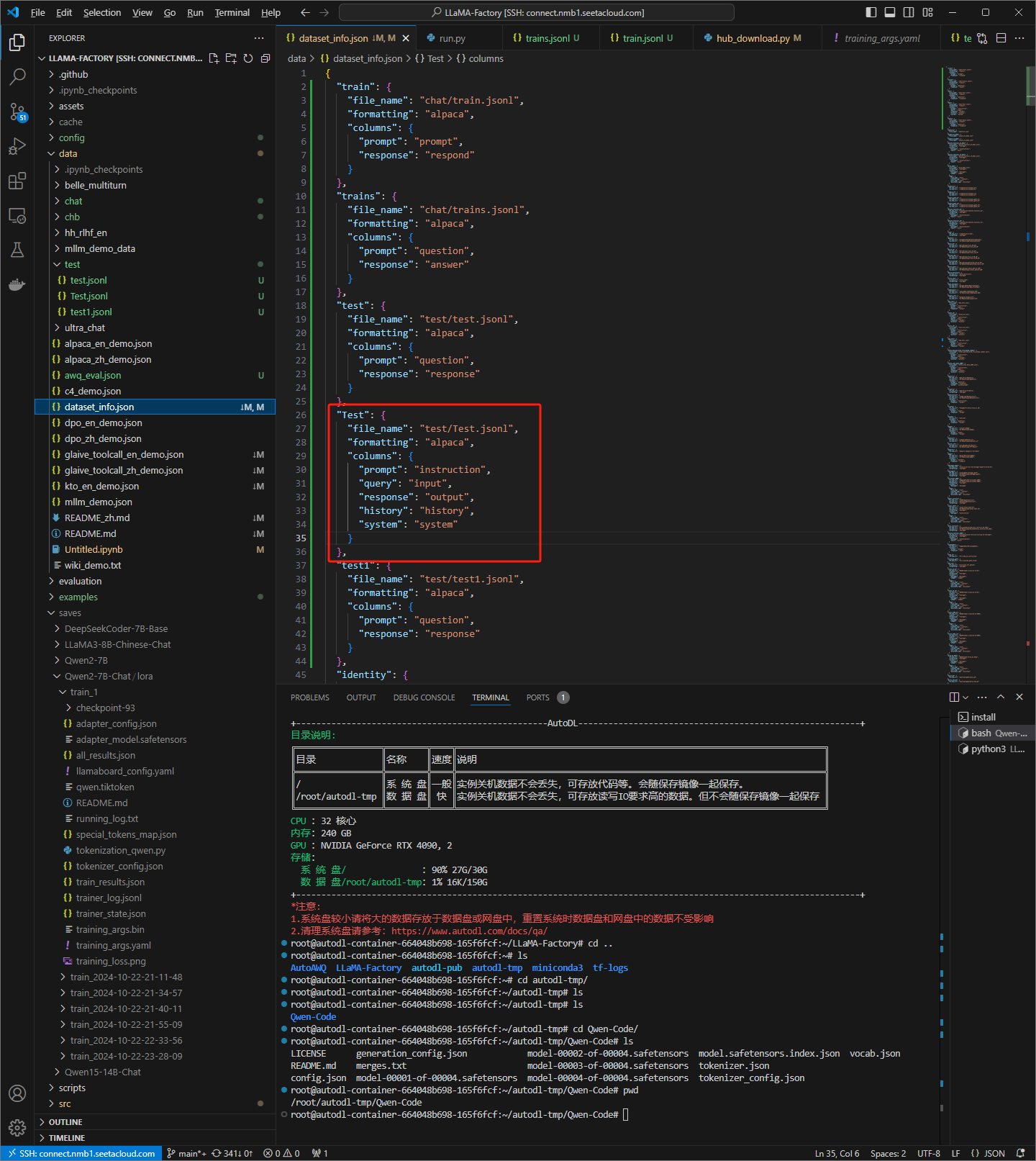
使用webui查看数据格式:可以清晰地看到提示词为一个计算机算法题目(包含题目描述,输入输出样式,甚至算法性能要求),回答为描述加代码

使用LLaMA-Factory的模型测评功能
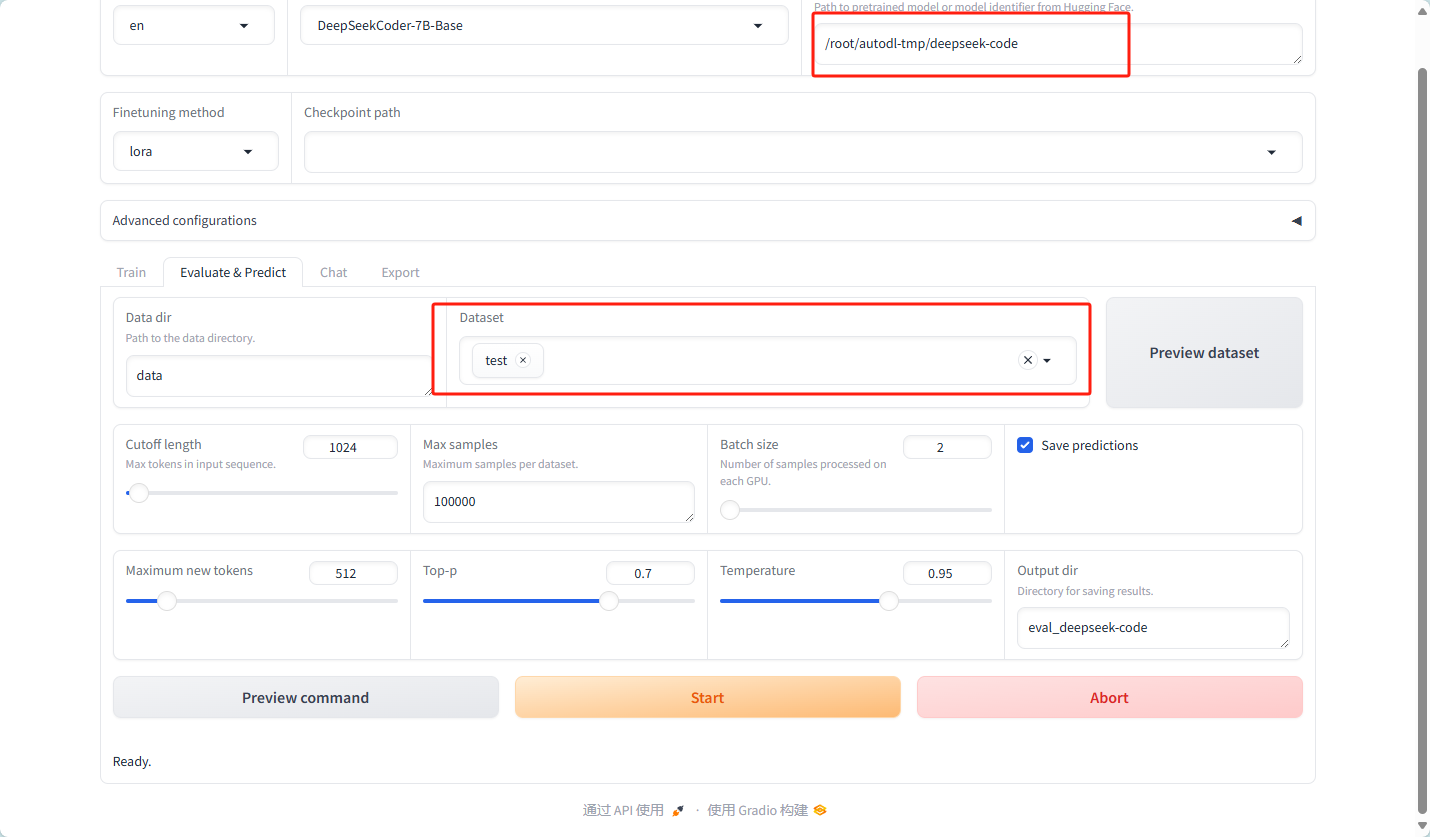
4.2 Qwen2.5-Coder-7B 模型评估
开始评估模型
由于时间太长,故减少数据集大小改为1000条
时间:40分钟 左右
结果:
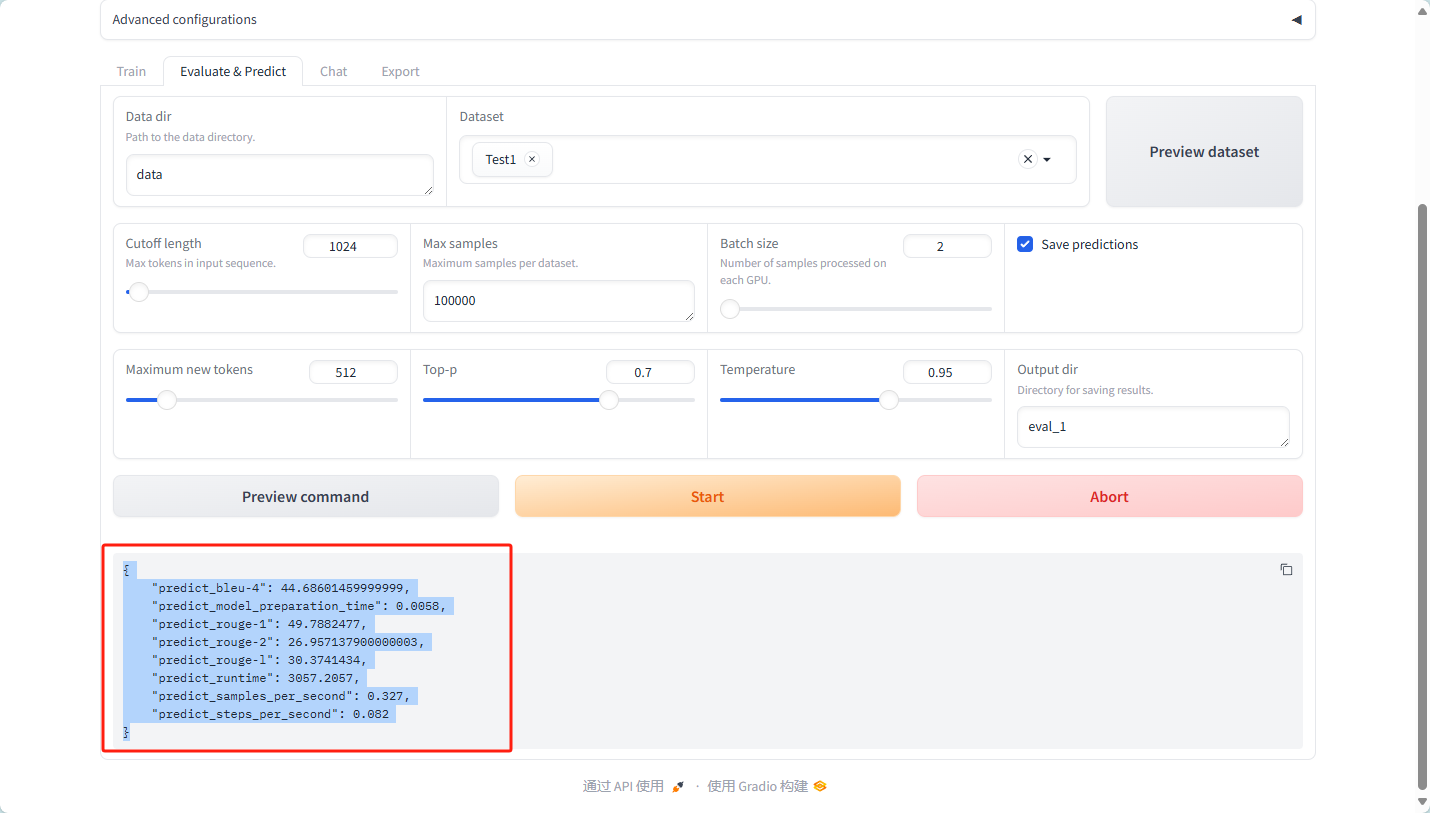
数据说明
1. BLEU-4 分数
predict_bleu-4: 44.68601459999999- BLEU(Bilingual Evaluation Understudy)是一种用于评估机器翻译或文本生成的质量的方法,其值范围通常是 0 到 100。BLEU-4 指的是使用 4-gram 进行评估的分数。
- 44.69 的分数表示模型生成的文本与参考文本有较好的重合度,通常认为 BLEU 分数在 40 以上是一个不错的结果。
2. 模型准备时间
predict_model_preparation_time: 0.0058- 这是模型准备预测所花费的时间(单位通常为秒),这个值非常小,说明模型加载或准备的效率很高。
3. ROUGE 分数
predict_rouge-1: 49.7882477- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种用于评估文本摘要和生成的指标,ROUGE-1 指的是 unigram 的重合度。
- 49.79 的分数同样表明生成文本与参考文本的重合度较好。
predict_rouge-2: 26.957137900000003- ROUGE-2 表示以 bigram 进行评估的分数,26.96 的分数表明模型在生成短语上的表现较 ROUGE-1 要低,通常这意味着模型生成的文本虽然有一些单词重合,但在短语层面上表现不如在单个单词层面。
predict_rouge-l: 30.3741434- ROUGE-L 用于评估生成文本的最长公共子序列(LCS),30.37 的结果说明生成文本在结构上能够保持一定的连贯性,但仍有改进的空间。
4. 预测运行时间
predict_runtime: 3057.2057- 预测的总运行时间(单位通常为秒),3057.21 秒相当于大约 50 分钟。这可能意味着在当前的数据集扫描所有样本所需的时间。
5. 每秒样本数
predict_samples_per_second: 0.327- 这是每秒处理的样本数,0.327 表明处理效率相对较低,可能是因样本量大、模型复杂度高,或者硬件资源受限导致。
6. 每秒步骤数
predict_steps_per_second: 0.082- 每秒执行的步骤数,这个值也相对较低,0.082 步意味着在处理过程中,每秒只进行少量的模型步骤。
综合分析
总的来说,这组数据表明该模型在生成文本时具有较好的质量(通过 BLEU 和 ROUGE 分数反映出来),但在性能上存在一定的延迟(较高的运行时间和低的每秒样本处理率)。改进的方向可能包括优化模型的推理速度、并行化处理、或使用更高效的硬件资源。
4.3 deepseek-coder-7b-base-v1.5 模型评估
v2版本的因为测试时显存溢出,所以选择v1.5版本
过程与Qwen2.5-Coder-7B相似,故此只分析数据
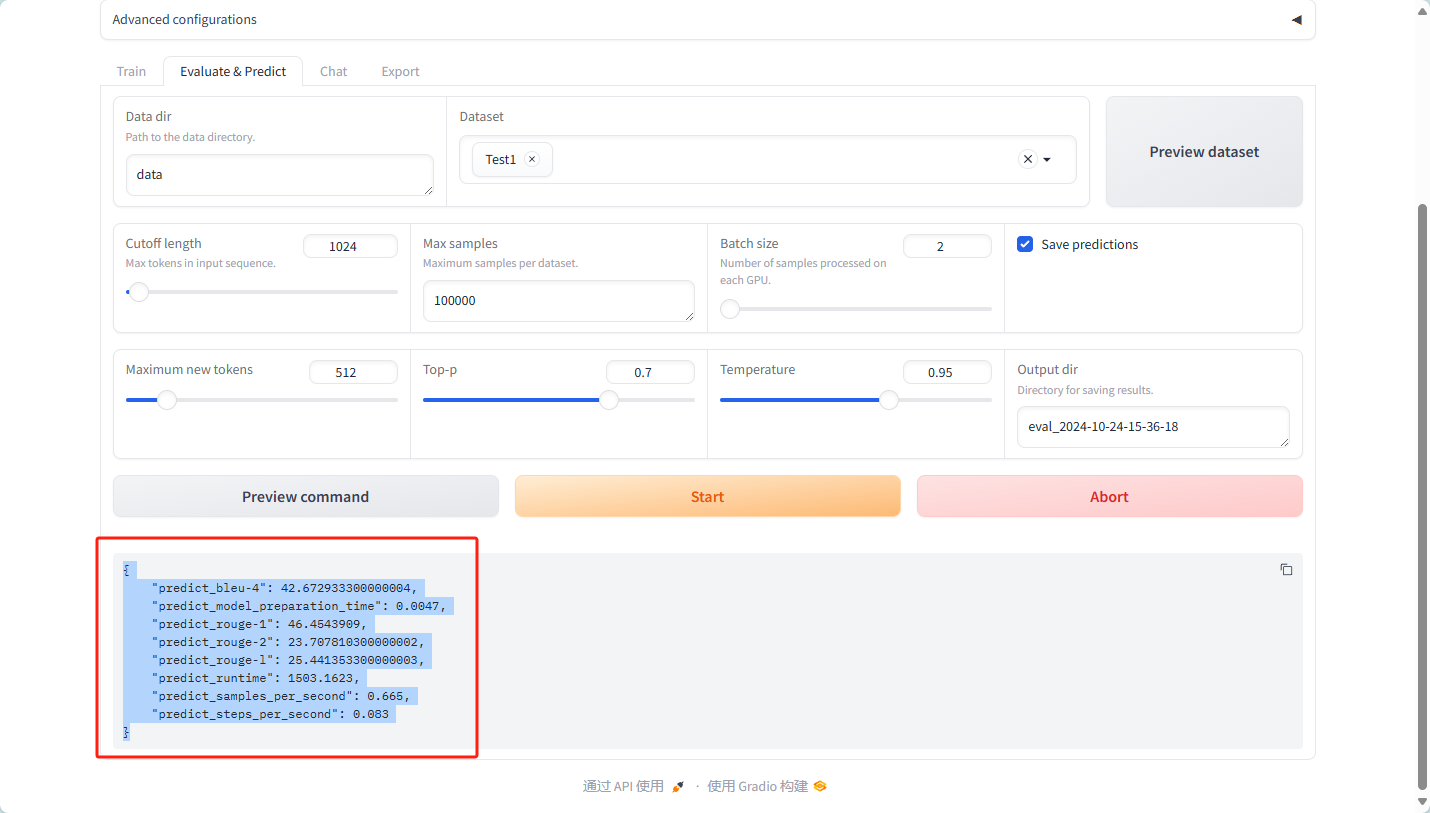
数据说明
- BLEU-4 (predict_bleu-4):
- 值:42.67
- 含义:BLEU(Bilingual Evaluation Understudy)分数是用于评估机器翻译质量的指标,范围通常为0到100。BLEU-4考虑了4-gram的匹配情况,42.67的分数表明模型在生成的文本与参考文本之间的匹配程度相对较高,表明模型生成的文本质量较好。
- 模型准备时间 (predict_model_preparation_time):
- 值:0.0047秒
- 含义:这表示准备模型进行预测所需的时间非常短,只有4.7毫秒,表明模型加载或初始化过程效率较高。
- ROUGE-1 (predict_rouge-1):
- 值:46.45
- 含义:ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种用于文本摘要的评估指标。ROUGE-1主要测量1-gram的重合度。46.45的得分表明生成的摘要与参考摘要之间有相对较高的相似性。
- ROUGE-2 (predict_rouge-2):
- 值:23.71
- 含义:ROUGE-2测量2-gram的重合度。23.71的得分相对较低,可能表明在更细致的语言匹配上(如短语和连贯性)模型的表现不如ROUGE-1。
- ROUGE-L (predict_rouge-l):
- 值:25.44
- 含义:ROUGE-L基于最长公共子序列(LCS)来评估生成文本的质量,25.44的分数表明模型生成的文本在结构和流畅性方面有一定的效果。
- 运行时间 (predict_runtime):
- 值:1503.1623秒
- 含义:这个值表示模型预测所花费的总时间约为1503秒,约25分钟。这可能表明模型在处理数据或生成结果时的效率需要改进。
- 每秒样本数 (predict_samples_per_second):
- 值:0.665
- 含义:该指标表示模型每秒处理的样本数量为0.665,说明模型的处理速度较慢,可能影响实际应用的效率。
- 每秒步骤数 (predict_steps_per_second):
- 值:0.083
- 含义:该指标表示模型每秒完成的处理步骤数量为0.083,表明模型在预测时的效率很低,可能需要优化算法或减少计算复杂度。
综合分析
- 性能评估:
- 整体来看,模型在语言生成(BLEU和ROUGE指标)上表现不错,特别是在BLEU-4和ROUGE-1上得分较高,表明生成的文本质量较高。
- 然而,ROUGE-2的得分较低,说明在更复杂的文本结构和短语匹配上存在改进的空间。
- 效率问题:
- 虽然模型的准备时间非常短,但整体运行时间和每秒处理的样本数量相对较低,表明在实际应用中可能会面临性能瓶颈。
- 为了提高模型的实用性,可能需要在模型架构或硬件上进行优化,增加处理速度。
4.4 模型比较
Qwencode模型
{
"predict_bleu-4": 44.68601459999999,
"predict_model_preparation_time": 0.0058,
"predict_rouge-1": 49.7882477,
"predict_rouge-2": 26.957137900000003,
"predict_rouge-l": 30.3741434,
"predict_runtime": 3057.2057,
"predict_samples_per_second": 0.327,
"predict_steps_per_second": 0.082
}
deepseekcode模型
{
"predict_bleu-4": 42.672933300000004,
"predict_model_preparation_time": 0.0047,
"predict_rouge-1": 46.4543909,
"predict_rouge-2": 23.707810300000002,
"predict_rouge-l": 25.441353300000003,
"predict_runtime": 1503.1623,
"predict_samples_per_second": 0.665,
"predict_steps_per_second": 0.083
}
对 deepseekcode 和 Qwencode 模型的性能进行比较,主要从多个指标入手,包括文本生成质量和处理效率。以下是详细的比较分析:
1. 文本生成质量
- BLEU-4 分数:
- deepseekcode: 42.67
- Qwencode: 44.69
- 分析: Qwencode 的 BLEU-4 分数高于 deepseekcode,表明 Qwencode 在生成文本的匹配程度上表现更好,生成的文本与参考文本的相似度更高。
- ROUGE-1 分数:
- deepseekcode: 46.45
- Qwencode: 49.79
- 分析: Qwencode 的 ROUGE-1 分数也高于 deepseekcode,说明 Qwencode 在生成摘要时与参考摘要的重合度更高。
- ROUGE-2 分数:
- deepseekcode: 23.71
- Qwencode: 26.96
- 分析: Qwencode 在 ROUGE-2 上的得分显著高于 deepseekcode,表明 Qwencode 在短语匹配方面表现更优。
- ROUGE-L 分数:
- deepseekcode: 25.44
- Qwencode: 30.37
- 分析: Qwencode 的 ROUGE-L 得分高,表示其生成文本在结构和流畅性方面表现更佳。
2. 模型准备时间
- 模型准备时间:
- deepseekcode: 0.0047秒
- Qwencode: 0.0058秒
- 分析: deepseekcode 的准备时间略低于 Qwencode,表明 deepseekcode 在模型加载或初始化时效率略高。
3. 运行时间
- 预测运行时间:
- deepseekcode: 1503.16秒
- Qwencode: 3057.21秒
- 分析: deepseekcode 的运行时间显著低于 Qwencode,表明 deepseekcode 在处理数据时效率更高。
4. 处理效率
- 每秒样本数:
- deepseekcode: 0.665
- Qwencode: 0.327
- 分析: deepseekcode 每秒处理的样本数大约是 Qwencode 的两倍,显示了 deepseekcode 在处理速度上的优势。
- 每秒步骤数:
- deepseekcode: 0.083
- Qwencode: 0.082
- 分析: 两个模型的每秒步骤数相似,基本持平。
综合比较
- 生成质量:
- Qwencode 在 BLEU 和 ROUGE 指标上均高于 deepseekcode,表明 Qwencode 在文本生成质量方面表现更优。
- 效率:
- deepseekcode 在模型准备时间、预测运行时间以及每秒样本数方面表现更好,显示了其在处理速度和效率上的优势。
结论
- 如果 生成文本的质量 是最重要的考量因素,Qwencode 是更优的选择,因为其 BLEU 和 ROUGE 分数更高。
- 如果 处理效率 和 响应时间 是优先考虑的因素,deepseekcode 是更佳选择,因为其在处理速度和模型准备上都表现得更快。