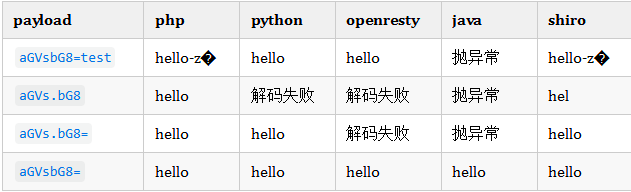
前面我们说TCP协议是可靠的、基于字节流、面向连接的传输层通信协议;
这里我想换种说法:与其说是TCP协议是可靠的,不如说传输层程序软件实现了TCP协议的规范(网络层次模型,每一层都有对应的程序软件),让TCP协议是可靠的。
1、数据分片(拆包)
如果传输的数据过小,例如数据只有1byte,那么为了传输这1byte数据,至少要消耗20字节IP头部+20字节TCP头部=40byte,这还不包括其二层头部所需要的开销,显然这种数据传输效率是很低的。
如果传输的数据过大,导致数据包很大,那么在IP传输中被分片的可能性会很大,接收方在处理分片包所消耗的资源和处理时间都会增大,同时如果IP分片在传输中发生了丢失,因为IP网络层没有重传机制,导致接收方接收不到完整数据,而要求发送方整个数据都重传,那么其网络开销也会增大。
所以传输层传输的数据不能过大也不能过小,最理想的状况是最大消息长度正好是IP不会被分片处理的最大长度;我们把这样一个合理的数据传输范围,叫做“最大消息长度”(MSS:Maximum Segment Size)。
那么这个数据传输范围是怎么进行确认的呢?

①② 通过建立连接的SYN包相互通知对方网络接口的MSS值。
③ 在两者之间选一个较小的作为MSS的值,发送数据。
上面通过TCP三次握手,选择了两端MSS较小的那个作为传输大小。如果发送的数据大于这个值,则会根据这个MSS值对数据进行分片,分片发送给接收端。
TCP层数据可能会进行分片,那如果某分片的数据中途丢失,那么数据在对端就无法还原了,面对这种情况,那么TCP协议又是如何规范的,如何保证主机一定收到对端的数据的呢?
2、到达确认
接收端接收到分片数据时,根据分片数据序号向发送端发送一个确认,发送端接收到确认信息才认为成功。

3、报文重传
发送方发送的某个报文如果长时间没有收到接收方的确认应答。则这个报文将会被重发。
重传方式有:超时重发、快速重发(SACK方法、Duplicate SACK)。
1)超时重发
发送方在发送分片时设置超时定时器,如果在定时器超时之后没有收到相应的确认,重发分片数据。超时重传时间是以 RTO (Retransmission Timeout 超时重传时间)表示。
情况一:数据包丢失

情况二:确认应答丢失

这种情况客户端会继续重复发送未被应答的报文,服务端接收到之后,会判断有没有曾经接收到,如果已存在,就丢弃新发来的包,然后返回确认应答报文。
服务端给客户端发送信息也是一样的逻辑。
那定时器是如何确定超时时间的呢?
在了解定时器是如何确定超时重传时间(RTO)之前,先了解一个概念:
往返时延(RTT:Round-Trip Time):表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。

那我们的超时重传时间(RTO)定多少合适呢?有人可能会说,让超时重传时间(RTO)稍大于包的往返时间(RTT)就可以了;听起来没错,但是网络是复杂的,每次包的往返时间可能都不一样,有的因为网络拥塞,花费时间比较长,有的则比较短;如果设置的过长,则如下所示:

- 当超时时间 RTO 较⼤时,重发慢,包丢了⽼半天才重发,没有效率,性能差,同时影响用户体验。
如果过短,则会如图所示:

- 当超时时间 RTO 较⼩时,会导致包可能并没有丢就被重发,这会增加⽹络拥塞,导致更多的超时,更多的超时导致更多的重发。
- 根据上述的两种情况,我们可以得知,超时重传时间 RTO 的值应该略⼤于报⽂往返 RTT 的值。
每发送一个分组,TCP都会进行RTT采样,这个采样并不会每一个数据包都采样,同一时刻发送的数据包中,只会针对一个数据包采样,这个采样数据被记为sampleRTT,用它来代表所有的RTT。
采样的方法一般有两种:
- TCP Timestamp选项(在TCP头部的选项里面)
TCP时间戳选项可以用来精确的测量RTT。
RTT = 当前时间 - 数据包中Timestamp选项的回显时间
这个回显时间是该数据包发出去的时间,知道了数据包的接收时间(当前时间)和发送时间
(回显时间),就可以轻松的得到RTT的一个测量值。这个方法简单并且准确,但是需要发送段和接收端都支持这个选项。
- 重传队列中数据包的TCP控制块
每个数据包第一次发送出去后都会放到重传队列中,数据包中的TCP控制块包含着一个变量,全连接信息里面的when,记录了该数据包的第一次发送时间。如果没有时间戳选项,那么RTT就等于当前时间和when的差值。
- 对于重传的数据包的响应,方法1可以用它来采集一个新的RTT测量样本,而方法二则不能(因为全连接信息里面的when不会因为重发而变化)。因为TCP Timestamp选项可以区分这个响应是原始数据包还是重传数据包触发的,从而计算出准确的RTT值。
重点来了:RTO的计算
实际上「报⽂往返 RTT 的值」是经常变化的,因为我们的⽹络也是时常变化的。也就因为「报⽂往返 RTT 的值」是经常波动变化的,所以「超时重传时间 RTO 的值」应该是⼀个动态变化的值。
(1)经典方法
为了避免单次RTT波动,计算RTO时新引入了变量SRTT,表示更加平滑的RTT数值,它的计算方法:
SRTT = x(上一次计算所得的SRTT) + (1 - x)RTT;
x被称为平滑因子,一般建议设置在[0.8, 0.9],意思是SRTT值百分之八十来自于之前的值,百分之二十来自于当前值。然后计算RTO的方法为:
RTO = min(ubound, max(lbound, y(SRTT)));
y是时延离散因子,推荐值为[1.3, 2.0],ubound是RTO的上边界,lbound是RTO的下边界。
算法的缺点:在RTT波动较大时,RTO不能明显适应网络变化。
(2)标准方法(Jacobson / Karels 算法)
标准方法引入了平均偏差的概念,它类似于统计学里面的方差,但是因为方差的计算过程代价较大,对于快速TCP来说不太适合。假设rtt的值为M,RTO的计算方式为:
| 1 | srtt = (1 - g)srtt + g(M); |
| 2 | rttval = (1 - h)rttval + h(|M - rttval|); |
| 3 | RTO = srtt + 4(rttval); |
其中g设置为1/8,h设置为1/4,对srtt而言,它有1/8取决于当前值,7/8取决于现有值。当RTT变化时,偏差增量越大,RTO的增量也越大。(其中:在Linux下,α = 0.125,β = 0.25, μ = 1,∂ = 4 ——这就是算法中的“调得一手好参数”,nobody knows why, it just works…) 最后的这个算法在被用在今天的TCP协议中。
关于计算RTT和RTO的算法,还有很多种,历史上针对这个的探讨从未停止过。
比较出名的拥塞算法还有谷歌的bbr算法,高版本的linux内核已经合入了bbr算法作为拥塞控制算法。
如果超时重发的数据,再次超时的时候,又需要重传的时候,TCP 的策略是超时间隔加倍。
也就是每当遇到⼀次超时重传的时候,都会将下⼀次超时时间间隔设为先前值的两倍。两次超时,就说明⽹络环境差,不宜频繁反复发送。
超时触发重传存在的问题是,超时周期可能相对较⻓。那是不是可以有更快的⽅式呢?
于是就可以⽤「快速重传」机制来解决超时重发的时间等待。
2)快速重发
TCP以一个段为单位(一个或多个字节组成一个段),每发一个段就进行一次应答处理,这样的传输方式由一个缺点。那就是,包的往返时间越长,网络的吞吐量越低,通信的性能就越低。所以为了解决这个问题,我们将不等待上一个包的确认应答而发送下一个包。这样,不同的包将不再串行而是可以并行,提高了网络吞吐。
快速重传(Fast Retransmit)机制,就是基于后退N协议,它不以时间为驱动,⽽是以确认信息为驱动重传。
快速重传机制,是如何⼯作的呢?其实很简单,⼀图胜千⾔。

在上图,发送⽅发出了 1,2,3,4,5 份数据:
- 第⼀份 Seq1 先送到了,于是就 Ack 回 2;
- 结果 Seq2 因为某些原因没收到,Seq3 到达了,于是还是 Ack 回 2;
- 后⾯的 Seq4 和 Seq5 都到了,但还是 Ack 回 2,因为 Seq2 还是没有收到;
- 发送端收到了三个 Ack = 2 的确认,知道了 Seq2 还没有收到,就会在定时器过期之前,重传丢失的 Seq2。
- 最后,收到了 Seq2,此时因为 Seq3,Seq4,Seq5 都收到了,于是 Ack 回 6 。
所以,快速重传的⼯作⽅式是当收到三个相同的 ACK 报⽂时,会在定时器过期之前,重传丢失的报⽂段。
快速重传机制只解决了⼀个问题,就是超时时间的问题,但是它依然⾯临着另外⼀个问题。就是重传的时候,是重传之前的⼀个,还是重传所有的问题。
⽐如对于上⾯的例⼦,是重传 Seq2 呢?还是重传 Seq2、Seq3、Seq4、Seq5 呢?因为发送端并不清楚这连续的三个 Ack 2 是谁传回来的。
根据 TCP 不同的实现,以上两种情况都是有可能的。可⻅,这是⼀把双刃剑。
为了解决不知道该重传哪些 TCP 报⽂,于是就有 SACK ⽅法。
(1)SACK方法
还有⼀种实现重传机制的⽅式叫: SACK ( Selective Acknowledgment 选择性确认)。
这种⽅式需要在 TCP 头部「选项」字段⾥加⼀个 SACK 的东⻄,它可以将缓存的地图发送给发送⽅,这样发送⽅就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
如下图,发送⽅收到了三次同样的 ACK 确认报⽂,于是就会触发快速重发机制,通过 SACK 信息发现只有 200~299 这段数据丢失,则重发时,就只选择了这个 TCP 段进⾏重复。

如果要⽀持 SACK ,必须双⽅都要⽀持。在 Linux 下,可以通过 net.ipv4.tcp_sack 参数打开这个功能(Linux 2.4 后默认打开)。
(2)Duplicate SACK方法
Duplicate SACK ⼜称 D-SACK ,其主要使⽤了 SACK 来告诉「发送⽅」有哪些数据被重复接收了。
情况1: 接收方确认报文丢包导致发送方重传

情况二:网络延时导致发送包超时送达

- 数据包(1000~1499) 被⽹络延迟了,导致「发送⽅」没有收到 Ack 1500 的确认报⽂。
- ⽽后⾯报⽂到达的三个相同的 ACK 确认报⽂,就触发了快速重传机制,但是在重传后,被延迟的数据包(1000~1499)⼜到了「接收⽅」;
- 所以「接收⽅」回了⼀个 SACK=1000~1500,因为 ACK 已经到了 3000,所以这个 SACK 是 D-SACK,表示收到了重复的包。
- 这样发送⽅就知道快速重传触发的原因不是发出去的包丢了,也不是因为回应的 ACK 包丢了,⽽是因为⽹络延迟了。
可⻅, D-SACK 有这么⼏个好处:
1. 可以让「发送⽅」知道,是发出去的包丢了,还是接收⽅回应的 ACK 包丢了;
2. 可以知道是不是「发送⽅」的数据包被⽹络延迟了;
3. 可以知道⽹络中是不是把「发送⽅」的数据包给复制了;
在 Linux 下可以通过 net.ipv4.tcp_dsack 参数开启/关闭这个功能(Linux 2.4 后默认打开)。
4、利用序列号和确认应答号提高可靠性
1)重复处理
接收端接收到发送端重复发来的报文,如何判断报文已经被接收到过了呢?就是通过比对已收到报文的序列号与发来的报文序列号进行对比,确认是否存在,如存在就丢弃第二次发来的报文。
2)失序处理
作为IP数据报来传输的TCP分片到达时可能会失序,比如,把一个大报文拆分成了1、2、3个包,1、3包先到,2包后到,这个时候TCP需要将收到的数据进行重新排序,然后以正确的顺序交给应用层;重新排序的逻辑就是根据报文的序列号进行重组。
3)序列号的生成逻辑
报文初始的序列号是随机生成的(在三次握手的时候),随机算法里面有一个时间的加入,所以能保证随机生成的序列与以前随机生成的不一样,如果一样可能会导致麻烦,产生数据错乱以及被黑客攻击。
序列号公式:
本次报文的序列号 = 上次报文序列号 + 上次报文携带字节数
这里我们假设客户端随机生成的序列号为X;三次握手阶段,第一次握手发送SYN报文序列为X,所以根据公式,第二次报文序列号 = X+1;上一次报文携带数据为1字节。
注:在三次握手阶段和四次挥手,SYN包和FIN包等虽然不携带数据,但是也会作为有一个字节的数据包。
三次握手建立连接的时候,首次携带数据,序列号定位第三次握手的序列号即X+1;携带数据的字节数是1000字节:

第一次报文的序列号 = 三次握手最后的确认报文序列号 ( X + 1)。
第二次发送报文携带数据1400字节:

此时该报文的序列号 = 三次握手最后的确认报文序列号 ( X + 1) + 1000= X + 1001;
第三次发送报文携带数据1200字节:

此时报文序列号 = ( X + 1001) + 1400= X + 2401;
确认应答号 = 上一次对端发送过来报文里面的序列号 + 上一次对端发送过来报文携带数据的字节数,表示你发的信息我收到了,序列号码是XXX。