📚 博客主页: StevenZeng学堂
🎉 本文专栏:
- 一文读懂Kubernetes
- 一文读懂Harbor
- 云原生安全实战指南
- 云原生存储实践指南

❤️ 摘要:随着企业数据量的增长和存储需求的复杂化,Ceph因其高可扩展性和灵活性,能够同时提供对象存储、块存储和文件存储三种服务,成为云计算、数据中心以及企业级应用中的核心存储方案。在本篇博客中,我们将使用Cephadm快速部署ceph集群,从浅到深了解和部署ceph集群。
目录
- 1 概念
- 1.1 什么是Ceph
- 1.1.1 Ceph的架构组件
- 1.2 什么是Cephadm
- 1.2.1 Cephadm的优势
- 1.3 什么是LVM
- 1.3.1 LVM的组成介绍
- 1.1 什么是Ceph
- 2 实践:部署Ceph集群
- 2.1 部署准备
- 2.1.1 修改主机名
- 2.1.2 添加hosts
- 2.1.3 配置网络
- 2.1.4 设置时区
- 2.1.5 设置时间同步服务
- 2.1.6 安装组件
- 2.2 引导集群
- 2.2.1 初始化集群
- 2.2.2 登录dashboard
- 2.2.3 添加节点
- 2.2.4 添加OSD设备
- 2.2.5 查看OSD的状态和信息
- 2.2.6 查看集群的状态
- 2.3 测试ceph集群
- 2.1 部署准备
- 3 总结
- 4 参考资料
1 概念
1.1 什么是Ceph

Ceph 是一款开源的分布式存储平台,它通过 RADOS(Reliable Autonomic Distributed Object Store)作为底层存储架构,提供以下三种存储模式:
- 块存储(RBD):面向虚拟机、数据库等应用场景,提供高性能和可扩展性。
- 对象存储(RGW):提供与 Amazon S3、OpenStack Swift 兼容的对象存储接口,适合非结构化数据存储。
- 文件存储(CephFS):分布式文件系统,支持大规模并发访问的文件共享应用场景。
1.1.1 Ceph的架构组件
- Monitor(Mon):维护集群状态,包括集群成员关系和映射信息。
- Object Storage Daemon(OSD):存储数据、处理数据复制、恢复、重平衡任务,是数据存储的核心。
- Manager(Mgr):管理集群的监控、日志、元数据等扩展功能。
- Metadata Server(MDS):用于Ceph文件系统(CephFS),管理文件系统元数据。
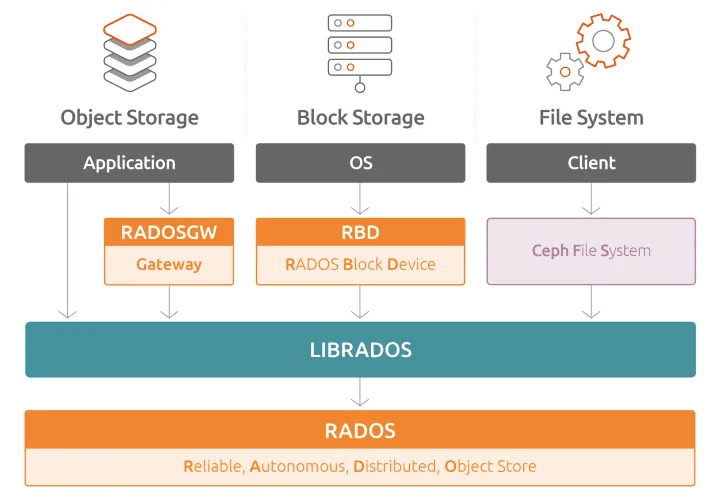
上图可见,Ceph 中的核心存储层是可靠的自治分布式对象存储 (RADOS)。Ceph 中的 RADOS 层由 Ceph 组件(对象存储守护进程 (OSD) 和 Ceph 监控器 (MON) 等)组成。
1.2 什么是Cephadm

Cephadm 是 Ceph 社区提供的集群管理工具,专为简化 Ceph 的部署、升级和日常运维而设计。Cephadm 使用容器(如 Docker、Podman)运行 Ceph 服务,使得集群节点可以快速安装、升级和回滚。
1.2.1 Cephadm的优势
- 容器化部署:使用容器运行 Ceph 服务,简化了软件依赖管理,避免了包管理冲突。
- 自动化管理:提供了自动化的监控、日志和集群状态管理功能。
- 无缝扩展:支持动态添加或删除节点,适用于云原生环境的横向扩展需求。
- 简化操作:只需要一个初始节点,之后可通过 Cephadm 自动引导其他节点,降低了手动配置的复杂度。
1.3 什么是LVM
LVM(Logical Volume Manager) 是 Linux 内核提供的一种逻辑卷管理工具,能够将多个物理存储设备(如磁盘、SSD)组合成逻辑卷进行管理。它的动态扩展性和灵活的分区管理,使得 Ceph OSD 可以在底层磁盘管理上更高效。
在 Ceph 中,LVM 主要用于 OSD 的底层存储管理,通过 LVM 可以创建多个物理卷、卷组和逻辑卷,为 Ceph 的数据存储提供支持。
1.3.1 LVM的组成介绍
下面是 LVM 中主要涉及的一些概念。
- 物理存储设备(Physical Media): 指系统的存储设备文件,比如 /dev/sda、/dev/sdb 等。
- PV(物理卷 Physical Volume):是 LVM 管理的基础单元, LVM 可以将一个物理存储设备(如整个硬盘或某个分区)转化为一个物理卷。
- VG(卷组 Volume Group): 由一个或多个物理卷(PV)组合而成的逻辑存储池,类似于基于磁盘阵列组合的传统磁盘。在 VG 中,你可以创建一个或多个逻辑卷(LV),这些 LV 就像传统的磁盘分区一样,可用于创建文件系统、挂载目录等操作。
- LV(逻辑卷 Logical Volume):是 LVM 中的最终使用单元, 类似于传统磁盘分区。与传统的分区不同,LV 的大小可以灵活调整,而不需要重新分区整个磁盘。

2 实践:部署Ceph集群
以下实践过程,使用cephadm工具部署一套三节点的Ceph存储集群。
2.1 部署准备
| 角色 | 系统 | 配置 | public网络 | cluster网络 |
|---|---|---|---|---|
| ceph-node1 | Ubuntu22.04 | 2U4G | 192.168.3.101 | 10.10.50.101 |
| ceph-node2 | Ubuntu22.04 | 2U4G | 192.168.3.102 | 10.10.50.102 |
| ceph-node3 | Ubuntu22.04 | 2U4G | 192.168.3.103 | 10.10.50.103 |
2.1.1 修改主机名
❔说明: cephadm工具会使用主机名管理节点主机,包括新增、删除、修改等,所以建议统一主机命令规范和做好主机名解析。
修改ceph-node1主机名,命令如下:
hostnamectl set-hostname ceph-node1
修改ceph-node2主机名,命令如下:
hostnamectl set-hostname ceph-node2
修改ceph-node3主机名,命令如下:
hostnamectl set-hostname ceph-node3
2.1.2 添加hosts
三个节点都需要修改/etc/hosts文件,添加以下内容:
192.168.3.101 ceph-node1
192.168.3.102 ceph-node2
192.168.3.103 ceph-node3
10.10.50.101 ceph-node1
10.10.50.102 ceph-node2
10.10.50.103 ceph-node3
2.1.3 配置网络
使用netplan配置主机节点网络, 三个节点都需要操作, 按实际环境修改配置。
备份原配置文件,并创建新的配置文件
mv /etc/netplan/00-installer-config.yaml /etc/netplan/00-installer-config.yaml.bak
touch /etc/netplan/ceph-node.yaml
ceph-node1配置如下:
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses:
- 192.168.3.101/24
nameservers:
addresses:
- 114.114.114.114
- 8.8.8.8
routes:
- to: default
via: 192.168.3.1
ens37:
dhcp4: no
dhcp6: no
addresses:
- 10.10.50.101/24
ceph-node2配置如下:
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses:
- 192.168.3.102/24
nameservers:
addresses:
- 114.114.114.114
- 8.8.8.8
routes:
- to: default
via: 192.168.3.1
ens37:
dhcp4: no
dhcp6: no
addresses:
- 10.10.50.102/24
ceph-node3配置如下:
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses:
- 192.168.3.103/24
nameservers:
addresses:
- 114.114.114.114
- 8.8.8.8
routes:
- to: default
via: 192.168.3.1
ens37:
dhcp4: no
dhcp6: no
addresses:
- 10.10.50.103/24
执行命令检查和生效配置
netplan try
成功配置输出
WARNING:root:Cannot call Open vSwitch: ovsdb-server.service is not running.
Do you want to keep these settings?
Press ENTER before the timeout to accept the new configuration
Changes will revert in 120 seconds
Configuration accepted.
2.1.4 设置时区
三个节点都设置时区,时区为中国上海时区:
timedatectl set-timezone Asia/Shanghai
检查是否设置成功
timedatectl show
输出如下:
Timezone=Asia/Shanghai
LocalRTC=no
CanNTP=yes
NTP=yes
NTPSynchronized=yes
TimeUSec=Mon 2024-10-21 15:47:01 CST
RTCTimeUSec=Mon 2024-10-21 15:47:01 CST
2.1.5 设置时间同步服务
三个节点都要操作,更新apt源
apt-get update
apt-get upgrade
安装chrony工具,实现集群内时间同步
apt-get install -y chrony
node1作为node2、3的时间服务器:
修改node1配置
# 保留一个外部ntp服务即可
pool ntp.ubuntu.com iburst maxsources 4
#pool 0.ubuntu.pool.ntp.org iburst maxsources 1
#pool 1.ubuntu.pool.ntp.org iburst maxsources 1
#pool 2.ubuntu.pool.ntp.org iburst maxsources 2
#
# 当外部ntp服务失效,系统基于本地时钟作为参考时间
local stratum 10
然后修改node2、node3配置
# 新增一行,指向ceph-node1
pool ceph-node1 iburst
# 注释原配置
#pool ntp.ubuntu.com iburst maxsources 4
#pool 0.ubuntu.pool.ntp.org iburst maxsources 1
#pool 1.ubuntu.pool.ntp.org iburst maxsources 1
#pool 2.ubuntu.pool.ntp.org iburst maxsources 2
启动时间服务
systemctl enable chrony --now
systemctl restart chrony
查看node1的同步情况
chrony source -v
输出如下:
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current best, '+' = combined, '-' = not combined,
| / 'x' = may be in error, '~' = too variable, '?' = unusable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^? prod-ntp-4.ntp4.ps5.cano> 2 6 1 2 +24ms[ +24ms] +/- 160ms
^? alphyn.canonical.com 2 6 1 1 +2451us[+2451us] +/- 148ms
^? prod-ntp-5.ntp4.ps5.cano> 2 6 1 2 -10ms[ -10ms] +/- 127ms
^? prod-ntp-3.ntp4.ps5.cano> 2 6 1 2 +4574us[+4574us] +/- 142ms
查看node2、node3的同步情况
chrony source -v
输出如下:
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current best, '+' = combined, '-' = not combined,
| / 'x' = may be in error, '~' = too variable, '?' = unusable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^? ceph-node1 0 8 0 - +0ns[ +0ns] +/- 0ns
2.1.6 安装组件
三个节点都要操作,安装组件
apt install -y lvm2 python3 python3-pip
重启虚拟机
reboot
- 系统升级后,重启使用最新的linux内核版本。
2.2 引导集群
查看cephadm版本
apt search cephadm
输出如下:
cephadm/jammy-updates,now 17.2.7-0ubuntu0.22.04.1 amd64 [installed]
cephadm utility to bootstrap ceph daemons with systemd and containers
- 自带源版本不是ceph官方最新版本
在node1上安装cephadm工具
apt install -y cephadm ceph-common
2.2.1 初始化集群
执行以下命令初始化ceph集群, 该命令会拉取cephadm对应版本的ceph组件容器镜像,然后并根据网络等初始化参数进行部署相关组件。
cephadm bootstrap --mon-ip 192.168.3.101 --cluster-network 10.10.50.0/24 --allow-fqdn-hostname
❔ 参数说明:
| 参数 | 说明 |
|---|---|
| –mon-ip | 指定第一个monitor的ip,即对外提供服务的ip地址 |
| –cluster-network | 指定集群子网, 该子网用于集群数据复制、数据重均衡、数据回复等。 |
| –allow-fqdn-hostname | 允许解析节点主机名 |
部署过程输出:
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit systemd-timesyncd.service is enabled and running
Repeating the final host check...
docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit systemd-timesyncd.service is enabled and running
Host looks OK
Cluster fsid: 38c60b7c-8c6f-11ef-8b92-c929f534b368
Verifying IP 192.168.3.101 port 3300 ...
Verifying IP 192.168.3.101 port 6789 ...
Mon IP `192.168.3.101` is in CIDR network `192.168.3.0/24`
Mon IP `192.168.3.101` is in CIDR network `192.168.3.0/24`
Pulling container image quay.io/ceph/ceph:v17...
Ceph version: ceph version 17.2.7 (b12291d110049b2f35e32e0de30d70e9a4c060d2) quincy (stable)
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network to 192.168.3.0/24
Setting cluster_network to 10.10.50.0/24
Wrote config to /etc/ceph/ceph.conf
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Creating mgr...
Verifying port 9283 ...
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr not available, waiting (4/15)...
mgr not available, waiting (5/15)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for mgr epoch 5...
mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to /etc/ceph/ceph.pub
Adding key to root@localhost authorized_keys...
Adding host ceph-node1...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph-node1:8443/
User: admin
Password: wer53x48hk
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/38c60b7c-8c6f-11ef-8b92-c929f534b368/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid 38c60b7c-8c6f-11ef-8b92-c929f534b368 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
❔ 工作流程说明:
- 在本地主机上拉取容器镜像,为新集群创建 Monitor 和 Manager 守护程序。
- 为 Ceph 集群生成新的 SSH 密钥,并将其添加到 root 用户的
/root/.ssh/authorized_keys文件中。 - 将公钥的副本写入
/etc/ceph/ceph.pub。 - 将最小配置文件写入
/etc/ceph/ceph.conf。需要此文件才能与 Ceph 守护进程通信。 - 将
client.admin管理(特权)密钥的副本写入/etc/ceph/ceph.client.admin.keyring。 - 将
_admin标签添加到引导主机。默认情况下,任何具有此标签的主机都将(也)获得/etc/ceph/ceph.conf和/etc/ceph/ceph.client.admin.keyring的副本。
⚠️ 注意:
部署后,提示dashboard的登录地址和权限,记得保存。
Ceph Dashboard is now available at:
URL: https://ceph-node1:8443/
User: admin
Password: wer53x48hk
2.2.2 登录dashboard
ceph-dashboard可以进行ceph集群初始化、ceph集群节点和组件管理、ceph集群监控等常用的运维功能,接下来尝试登录dashboard。
首先,修改访问主机的hosts,这里使用火绒修改:

添加ceph-node1的主机解析记录。
使用初始化密码登录, 登录后提示修改初始化密码:

如果忘记了初始化密码, 也可以使用命令修改dashboard密码:
echo admin@12345 | ceph dashboard set-login-credentials admin -i -
输出如下:
******************************************************************
*** WARNING: this command is deprecated. ***
*** Please use the ac-user-* related commands to manage users. ***
******************************************************************
Username and password updated
新版的命令推荐使用:
echo "admin@12345" | ceph dashboard ac-user-set-password admin -i -
效果一样,输出如下:
{"username": "admin", "password": "$2b$12$xoDkxE3.mCr6bThmUSrpJOiBcLRvGjPGLYIAYCQOz492jxdur18za", "roles": ["administrator"], "name": null, "email": null, "lastUpdate": 1729498208, "enabled": true, "pwdExpirationDate": null, "pwdUpdateRequired": false}
2.2.3 添加节点
查看ceph集群现在的主机
ceph orch host ls
输出如下:
HOST ADDR LABELS STATUS
ceph-node1 192.168.3.101 _admin
node1节点对其他节点进行ssh免密登录,在初始化后,cephadm会生成一对ssh密钥,存放在/etc/ceph/目录。
执行以下命令,把秘钥放到其他节点上:
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph-node2
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph-node3
在dashboard添加主机
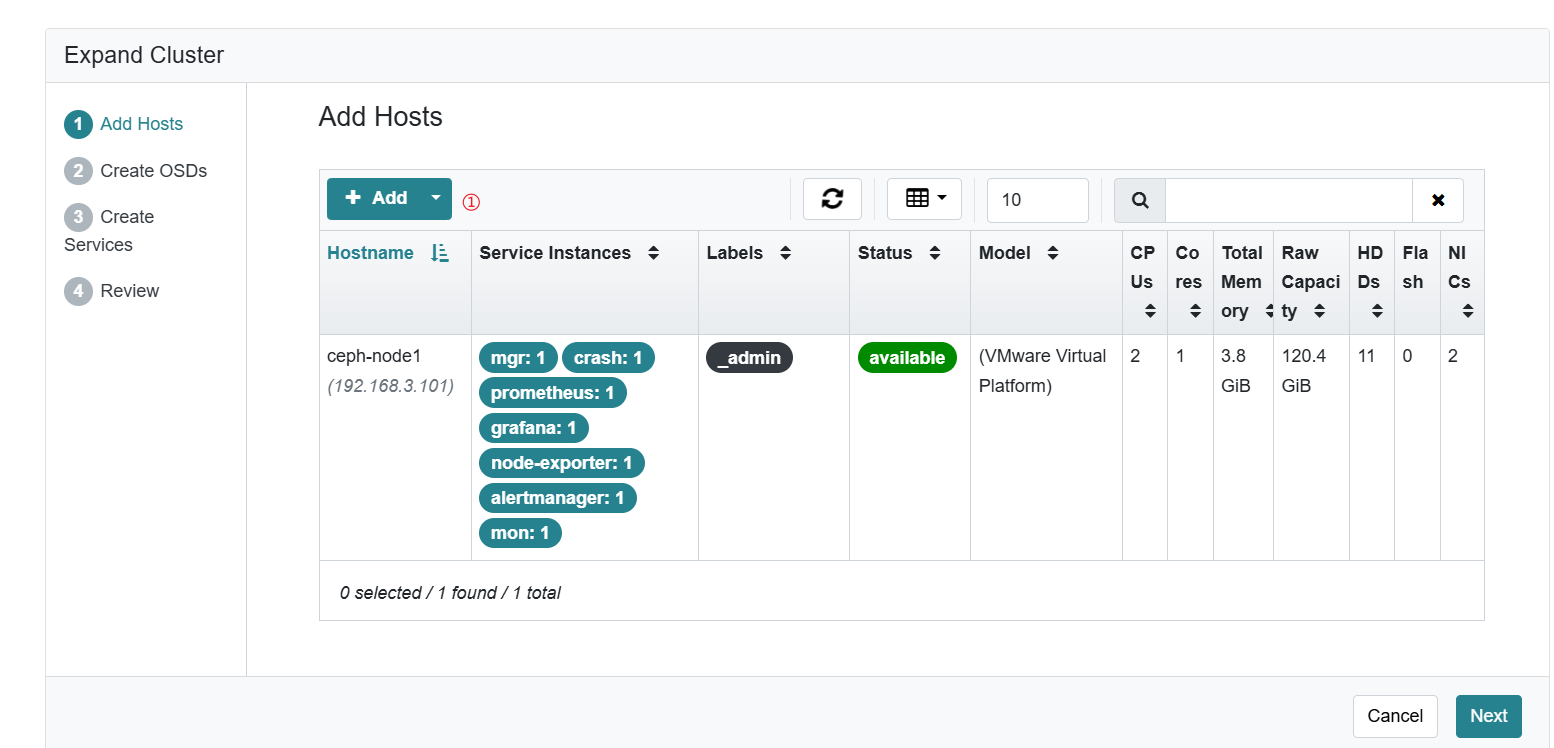
输入node2的主机信息,包括主机名和Public网络ip地址
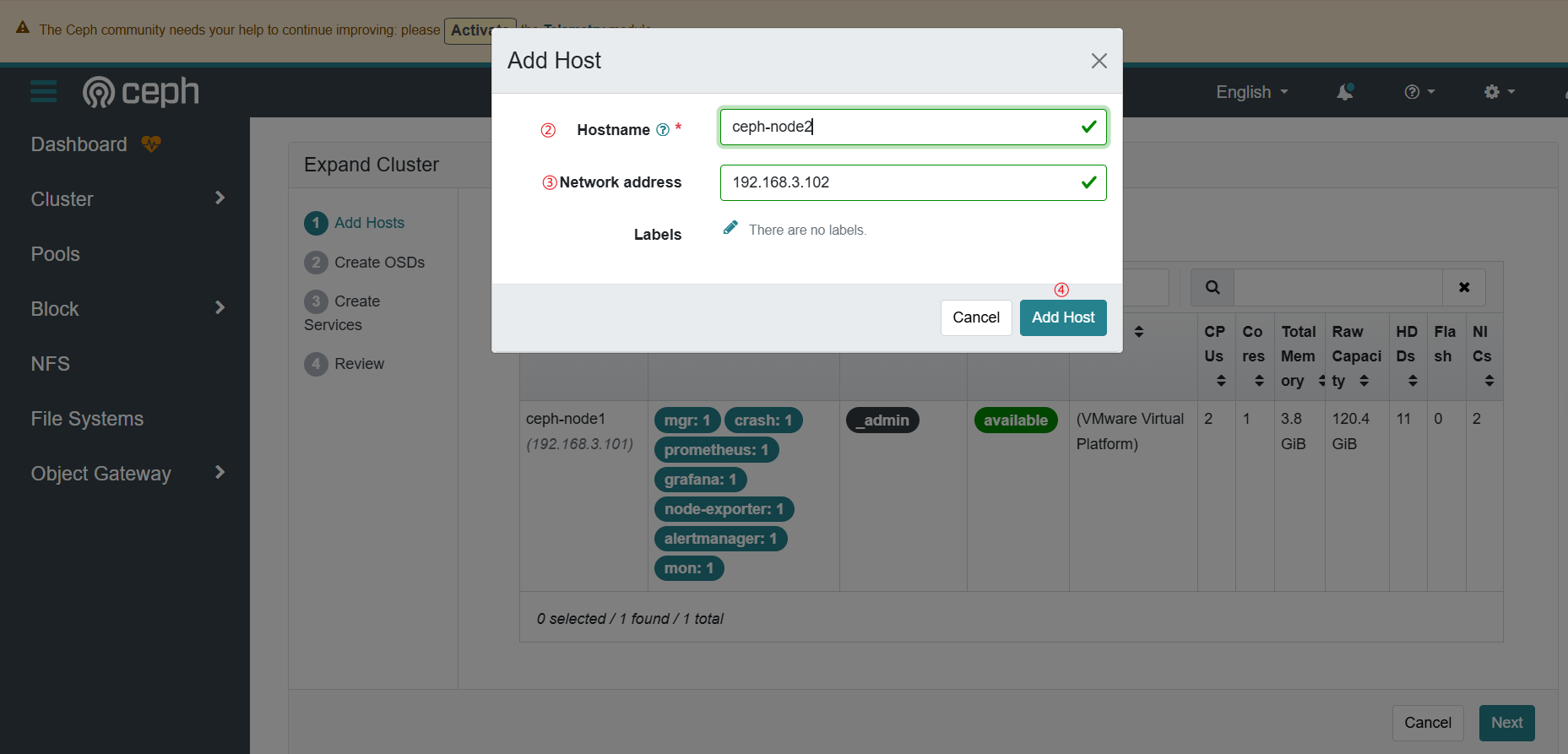
这样就添加上node2了。
或者可以使用命名添加主机到集群。
将node3主机添加到ceph集群中,执行以下命令:
ceph orch host add ceph-node3 192.168.3.103
输出如下:
Added host 'ceph-node3' with addr '192.168.3.103'
再查看ceph集群中的主机
ceph orch host ls
输出如下:
HOST ADDR LABELS STATUS
ceph-node1 192.168.3.101 _admin
ceph-node2 192.168.3.102 _no_schedule
ceph-node3 192.168.3.103
3 hosts in cluster
如果要删除某台主机,可以执行以下命令:
ceph orch host rm ceph-node3
输出如下:
Removed host 'ceph-node3'
2.2.4 添加OSD设备
2.2.4.1 添加OSD之前查看节点配置
查看集群可用的物理设备
ceph orch device ls
输出如下:
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
ceph-node1 /dev/sdb hdd 10.0G Yes 4m ago
ceph-node1 /dev/sdc hdd 10.0G Yes 4m ago
ceph-node2 /dev/sdb hdd 10.0G Yes 5m ago
ceph-node2 /dev/sdc hdd 10.0G Yes 5m ago
ceph-node3 /dev/sdb hdd 10.0G Yes 4m ago
ceph-node3 /dev/sdc hdd 10.0G Yes 4m ago
- 命令输出结果是当前添加ceph集群的节点的空闲设备清单。
⚠️提示: 如果一个存储设备想要加入ceph集群,要求满足2个条件:
- 1.设备未被使用。
- 2.设备的存储大小必须大于5GB。
如果担心不准确,可以登录到各节点,执行命令确认空闲设备信息:
lsblk
输出如下:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 2G 0 part /boot
└─sda3 8:3 0 98G 0 part
└─ubuntu--vg-ubuntu--lv 253:0 0 98G 0 lvm /
sdb 8:16 0 10G 0 disk
sdc 8:32 0 10G 0 disk
sr0 11:0 1 1024M 0 rom
查看OSD当前列表, 执行以下命令
ceph osd tree
输出如下:
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0 root default
- 默认是没有osd的, 即没有安装osd服务。
- 等添加完osd设备后,才会统一安装osd服务,并物理设备和osd服务的关系是一对一。
2.2.4.2 添加OSD设备到集群
将ceph- node1的设备添加到ceph集群
ceph orch daemon add osd ceph-node1:/dev/sdb,/dev/sdc
该命令允许您一次添加多个设备成osd,命令格式为
Usage:
ceph orch daemon add osd host:device1,device2,...
ceph orch daemon add osd host:data_devices=device1,device2,db_devices=device3,osds_per_device=2,...
或者, 使用dashboard添加osd,将node2、node3的设备添加到ceph集群
直接下一步
- 创建osd需要一定时间,等创建好后再查看结果。
2.2.5 查看OSD的状态和信息
执行命令查看osd添加情况:
ceph osd tree
输出如下:
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.05878 root default
-3 0.01959 host ceph-node1
0 hdd 0.00980 osd.0 up 1.00000 1.00000
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.01959 host ceph-node2
2 hdd 0.00980 osd.2 up 1.00000 1.00000
4 hdd 0.00980 osd.4 up 1.00000 1.00000
-5 0.01959 host ceph-node3
3 hdd 0.00980 osd.3 up 1.00000 1.00000
5 hdd 0.00980 osd.5 up 1.00000 1.00000
❔ 字段说明:
| 字段 | 说明 |
|---|---|
ID | 表示设备或节点的唯一标识符,负值表示聚合节点(如 root 或 host),正值代表具体的 OSD。 |
CLASS | 存储设备的类型,比如 hdd(机械硬盘)、ssd(固态硬盘)。如果没有显示,通常表示设备的类型没有分类。 |
WEIGHT | OSD 在数据分布和权重计算中的权重值,通常基于设备的存储容量。WEIGHT 值越高,表示该 OSD 可以存储更多的数据。 |
TYPE | 节点类型,root 表示根节点,host 表示主机,osd 表示具体的对象存储守护进程(OSD)。 |
NAME | 节点名称或 OSD 守护进程名称,如 ceph-node1 表示主机名,osd.0 表示 OSD 守护进程编号。 |
STATUS | 显示 OSD 的状态,up 表示 OSD 正在运行,down 表示 OSD 已关闭或无法访问。 |
REWEIGHT | OSD 的动态权重,用于手动调整数据分布。如果需要减小或增加某个 OSD 的数据分布,可以通过调节此值。通常为 1.00000,表示正常权重。 |
PRI-AFF | 表示 OSD 的主优先级关联,通常用于调节数据在 OSD 之间的读取优先级。值为 1.00000 表示正常优先级。 |
查看设备状态
lsblk -o NAME,FSTYPE,MOUNTPOINT /dev/sdb
输出如下:
NAME FSTYPE MOUNTPOINT
sdb LVM2_member
└─ ceph--bdd67cca--30c4--4bb7--99b2--7e8b613f8e75 - osd--block--3ff1a40f--8794--4241--b110--73438330491a ceph_bluestore
❔说明:
- /dev/sdb设备被格式化为lvm格式
- 将一个设备规划成一个PV、VG和LV,命名格式是VG+LV
指定osd0查看vg
vgdisplay ceph-bdd67cca-30c4-4bb7-99b2-7e8b613f8e75
输出如下:
--- Volume group ---
VG Name ceph-bdd67cca-30c4-4bb7-99b2-7e8b613f8e75
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 5
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 1
Act PV 1
VG Size <10.00 GiB
PE Size 4.00 MiB
Total PE 2559
Alloc PE / Size 2559 / <10.00 GiB
Free PE / Size 0 / 0
VG UUID zHjqjG-68Z2-sS7n-Q2cw-ncNk-kukF-U3Arlp
指定osd0查看lv
lvdisplay ceph-bdd67cca-30c4-4bb7-99b2-7e8b613f8e75
输出如下:
--- Logical volume ---
LV Path /dev/ceph-bdd67cca-30c4-4bb7-99b2-7e8b613f8e75/osd-block-3ff1a40f-8794-4241-b110-73438330491a
LV Name osd-block-3ff1a40f-8794-4241-b110-73438330491a
VG Name ceph-bdd67cca-30c4-4bb7-99b2-7e8b613f8e75
LV UUID jGDapH-Iy4V-rkR7-sDTc-zTAz-1O8S-9irpUT
LV Write Access read/write
LV Creation host, time ceph-node1, 2024-10-18 14:12:59 +0800
LV Status available
# open 24
LV Size <10.00 GiB
Current LE 2559
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
新版Ceph默认是使用bluestore引擎,osd格式化后挂载到主机的/var/lib/ceph/<Ceph_Cluster_ID>/osd.<OSD_ID>/目录中。 指定osd0路径,执行命令查看:
root@ceph-node1:~# ll /var/lib/ceph/38c60b7c-8c6f-11ef-8b92-c929f534b368/osd.0/
total 72
drwx------ 2 167 167 4096 Oct 18 14:13 ./
drwx------ 14 167 167 4096 Oct 18 14:13 ../
lrwxrwxrwx 1 167 167 93 Oct 18 14:13 block -> /dev/ceph-bdd67cca-30c4-4bb7-99b2-7e8b613f8e75/osd-block-3ff1a40f-8794-4241-b110-73438330491a
-rw------- 1 167 167 37 Oct 18 14:13 ceph_fsid
-rw------- 1 167 167 277 Oct 18 14:18 config
-rw------- 1 167 167 37 Oct 18 14:13 fsid
-rw------- 1 167 167 142 Oct 18 14:18 keyring
-rw------- 1 167 167 6 Oct 18 14:13 ready
-rw------- 1 167 167 3 Oct 18 14:13 require_osd_release
-rw------- 1 167 167 10 Oct 18 14:13 type
-rw------- 1 167 167 38 Oct 18 14:18 unit.configured
-rw------- 1 167 167 48 Oct 18 14:13 unit.created
-rw------- 1 167 167 90 Oct 18 14:13 unit.image
-rw------- 1 167 167 361 Oct 18 14:13 unit.meta
-rw------- 1 167 167 1644 Oct 18 14:13 unit.poststop
-rw------- 1 167 167 2827 Oct 18 14:13 unit.run
-rw------- 1 167 167 330 Oct 18 14:13 unit.stop
-rw------- 1 167 167 2 Oct 18 14:13 whoami
❔ 目录结构说明:
| 目录 | 说明 | 作用 |
|---|---|---|
| block | 指向实际存储数据的 块设备(/dev/ceph-xxxx/osd-block-xxxx)。 | 该链接指向 OSD 数据存储的物理卷或逻辑卷。在 BlueStore 引擎中,数据会直接写入块设备,而不通过文件系统,这可以提高性能。 |
| ceph_fsid | 文件内容是集群的 FSID(文件系统 ID),即整个 Ceph 集群的唯一标识符。 | 用于标识该 OSD 所属的 Ceph 集群。每个 Ceph 集群都有一个唯一的 FSID,所有 OSD 和守护进程会使用这个 FSID 来确认它们属于同一个集群。 |
| config | 这是 OSD 的配置文件,其中包含 Ceph OSD 守护进程的具体配置参数。 | 该文件包含了 OSD 的运行参数和配置选项。这些设置通常是由 ceph.conf 继承的,可以覆盖或调整 OSD 的个性化配置。 |
| fsid | 这是 OSD 自身的 FSID(文件系统 ID),与 ceph_fsid 不同,它是唯一标识该 OSD 的 UUID。 | 这个文件保存了每个 OSD 自己的 UUID,这对于 Ceph 集群管理和识别 OSD 非常重要。 |
| keyring | OSD 使用的身份认证密钥。 | 该文件包含 OSD 用于与其他 Ceph 守护进程(如 MON、MDS)进行认证和通信的密钥。Ceph 使用这种方式确保集群中的各个组件之间的通信是安全的。 |
| ready | 标志文件,用于指示 OSD 已经准备好运行。 | Ceph 启动 OSD 时会检查该文件是否存在,文件内容通常为 1,表示 OSD 已经准备好。如果没有这个文件,OSD 不会被标记为 “ready” 状态。 |
| type | 表示 OSD 使用的存储类型。 | 这个文件的内容通常是 bluestore,表示该 OSD 使用的是 BlueStore 存储引擎。 |
| unit.* 系列文件 | 这些文件是与 systemd 相关的服务管理文件,主要用于跟踪和控制 OSD 守护进程的状态。 | 帮助 Ceph 通过 systemd 来管理 OSD 的生命周期,跟踪 OSD 守护进程的启动、停止和运行状态。 |
| whoami | 文件内容为该 OSD 的编号。 | 这个文件存储了 OSD 的唯一编号(如文件内容 0 表示 osd.0),Ceph 通过该编号识别 OSD。这个文件确保 OSD 的编号与 Ceph 集群中的 OSD ID 一致。 |
2.2.6 查看集群的状态
执行以下命令查看集群状态:
ceph -s
输出如下:
cluster:
id: 38c60b7c-8c6f-11ef-8b92-c929f534b368
health: HEALTH_WARN
clock skew detected on mon.ceph-node2
services:
mon: 3 daemons, quorum ceph-node1,ceph-node3,ceph-node2 (age 75m)
mgr: ceph-node3.ctgktz(active, since 68m)
osd: 6 osds: 6 up (since 74m), 6 in (since 74m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
# 集群可用容量大小共计60GB
usage: 1.7 GiB used, 58 GiB / 60 GiB avail
pgs: 1 active+clean
❔ 字段说明:
- 集群信息(Cluster Information)
| 字段 | 说明 |
|---|---|
| Cluster ID | 是 Ceph 集群的唯一标识符(UUID)。这个 ID 在集群中每个节点上都是一致的,用于标识集群 |
| Health Status (健康状态) | 表示集群的健康状态 |
- 服务状态(Services Information)
| 字段 | 说明 |
|---|---|
| mon (Monitor) | 显示当前有 3 个 Monitor 守护进程,运行在 ceph-node1、ceph-node3 和 ceph-node2 上。这些监控节点组成了 仲裁(quorum),它们共同负责 Ceph 集群的状态管理和集群成员关系的协调。 |
| mgr (Manager) | 显示有一个 Manager 守护进程,运行在 ceph-node3 上,并且标记为 active,表示它是当前的活跃管理节点,管理集群监控、统计和调度功能。 |
| osd (Object Storage Daemon) | 显示集群中有 6 个 OSD 守护进程,所有的 OSD 都处于 up(运行状态)和 in(集群中)状态。 |
- 数据状态(Data Information)
| 字段 | 说明 |
|---|---|
| pools | 集群中有 1 个池(pool)。池是 Ceph 存储数据的逻辑分区,通常用来组织和管理存储对象。 |
| pgs (Placement Groups) | 显示集群中有 1 个 PG(Placement Group,放置组),PG 是 Ceph 数据分布的基本单元。PG 用于在 OSD 之间分布数据,1 个 PG 表示存储数据的分片数较少,适合小型集群。 |
| objects | 集群中存储了 2 个对象,共计占用 449 KiB 的存储空间。Ceph 将数据对象分布到 OSD 中,并对这些对象进行存储管理。 |
| usage | 集群总共使用了 1.7 GiB 的存储空间,当前可用存储空间为 58 GiB,总存储容量为 60 GiB。 |
| pgs | 显示当前有 1 个 PG 处于 active+clean 状态,表示 PG 是活跃的并且所有数据都被正确复制且一致。 |
2.3 测试ceph集群
创建存储池
ceph osd pool create stevenzeng
输出如下:
pool 'stevenzeng' created
⚠️ 注意: 通常创建池后会出现以下警告
“1 pool(s) do not have an application enabled”
执行以下命令处理
- 查看详细信息
root@ceph-node1:~# ceph health detail
[WRN] POOL_APP_NOT_ENABLED: 1 pool(s) do not have an application enabled
application not enabled on pool 'stevenzeng'
use ' ceph osd pool application enable <pool-name> <app-name> ', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications.
- 使用以上提示命令,启动应用功能,每个池只能开启一个应用功能
root@ceph-node1:~# ceph osd pool application enable stevenzeng rbd
enabled application 'rbd' on pool 'stevenzeng'
上传文件到测试存储池
rados put sys.txt /etc/os-release -p stevenzeng
查看存储池的文件
rados ls -p stevenzeng
输出如下:
os.txt
查看存储池文件的状态信息
rados -p stevenzeng stat os.txt
输出如下:
stevenzeng/os.txt mtime 2024-10-18T15:56:22.000000+0800, size 386
查看PG的副本在哪些OSD上,执行以下命令:
ceph osd map stevenzeng os.txt
输出如下:
osdmap e39 pool 'stevenzeng' (2) object 'os.txt' -> pg 2.486f5322 (2.2) -> up ([5,1,2], p5) acting ([5,1,2], p5)
- 不难发现,pg的三个副本分别在osd5,1,2。
删除文件
rados -p stevenzeng rm os.txt
查看文件是否存在
rados -p stevenzeng ls
在查看pg的映射关系
ceph osd map stevenzeng sys.txt
❓思考: 删除文件后发现映射信息还在,那如何删除这些映射信息呢?
- Ceph存储中默认设置了延迟删除的回收机制,Ceph的删除操作并不一定是即时生效的,特别是在繁忙的集群中。RADOS对象删除后,Ceph可能还会保留该对象的元数据(例如OSD映射关系)一段时间,等待后台的清理任务(如垃圾回收进程)来真正释放资源,同时这样也会保持数据一致性和优化性能。
3 总结
Cephadm 使得 Ceph 的部署流程简化为几条命令,特别适合云原生环境的快速扩展需求。通过Cephadm,你可以快速高效地部署 Ceph 集群,并利用容器化技术实现集群的自动化管理。本篇博客能够帮助你从浅入深了解Ceph存储的概念,并顺利部署 Ceph存储集群, 为业务构建高效、稳定的分布式存储系统。 接下来会为您解Ceph为Kubernetes集群提供存储的实践应用。
4 参考资料
[1] Ceph官方文档