深入拆解Tomcat&Jetty(三)
专栏地址:https://time.geekbang.org/column/intro/100027701
1 Tomcat组件生命周期
Tomcat如何如何实现一键式启停
Tomcat 架构图和请求处理流程如图所示:

对组件之间的关系进行分析,发现启动时需要遵循以下两个原则:
- 第一个原则是先创建子组件,再创建父组件,子组件需要被“注入”到父组件中。
- 第二个原则是先创建内层组件,再创建外层组件,内层组建需要被“注入”到外层组件。
最直观的做法就是将图上所有的组件按照先小后大、先内后外的顺序创建出来,然后组装在一起。但这样的方式问题很大,一方面组件很多可能会造成遗漏,而且代码也会很冗余,另一方面不利于后期的功能拓展。
为了解决这个问题,我们希望找到一种通用的、统一的方法来管理组件的生命周期:LifeCycle
LifeCycle接口
我们把不变点抽象出来成为一个接口,这个接口跟生命周期有关,叫作 LifeCycle。LifeCycle 接口里应该定义这么几个方法:init()、start()、stop() 和 destroy(),每个具体的组件去实现这些方法。
理所当然,在父组件的 init() 方法里需要创建子组件并调用子组件的 init() 方法。同样,在父组件的 start() 方法里也需要调用子组件的 start() 方法,因此调用者可以无差别的调用各组件的 init() 方法和 start() 方法,这就是组合模式的使用,并且只要调用最顶层组件,也就是 Server 组件的 init() 和 start() 方法,整个 Tomcat 就被启动起来了。下面是 LifeCycle 接口的定义。

LifeCycle事件
因为各个组件 init() 和 start() 方法的具体实现是复杂多变的,比如在 Host 容器的启动方法里需要扫描 webapps 目录下的 Web 应用,创建相应的 Context 容器。如果后续逻辑变化的话,需要不断修改 start() 的方法,违反了开闭原则。
我们注意到,组件的 init() 和 start() 调用是由它的父组件的状态变化触发的,上层组件的初始化会触发子组件的初始化,上层组件的启动会触发子组件的启动,因此我们把组件的生命周期定义成一个个状态,把状态的转变看作是一个事件。而事件是有监听器的,在监听器里可以实现一些逻辑,并且监听器也可以方便的添加和删除,这就是典型的观察者模式。
具体来说就是在 LifeCycle 接口里加入两个方法:添加监听器和删除监听器。除此之外,我们还需要定义一个 Enum 来表示组件有哪些状态,以及处在什么状态会触发什么样的事件。因此 LifeCycle 接口和 LifeCycleState 就定义成了下面这样。

从图上可以看到,组件的生命周期有 NEW、INITIALIZING、INITIALIZED、STARTING_PREP、STARTING、STARTED 等,而一旦组件到达相应的状态就触发相应的事件,比如 NEW 状态表示组件刚刚被实例化;而当 init() 方法被调用时,状态就变成 INITIALIZING 状态,这个时候,就会触发 BEFORE_INIT_EVENT 事件,如果有监听器在监听这个事件,它的方法就会被调用。
LifeCycleBase 抽象基类
当我们定义好了接口,就要去写实现类实现它,而在一个接口的不同实现类里,可能很多逻辑都是一样的。那子类如何重用这部分逻辑呢?常见的方法就是定义一个基类来实现共同的逻辑,然后让各个子类去继承它,就达到了重用的目的。
而基类中往往会定义一些抽象方法,所谓的抽象方法就是说基类不会去实现这些方法,而是调用这些方法来实现骨架逻辑。抽象方法是留给各个子类去实现的,并且子类必须实现,否则无法实例化。

LifeCycleBase 在实现 Lifecycle接口的基础上,定义了如下四个抽象方法交给子类实现,并在内部逻辑中调用了该方法:
protected abstract void initInternal() throws LifecycleException;
protected abstract void startInternal() throws LifecycleException;
protected abstract void stopInternal() throws LifecycleException;
protected abstract void destroyInternal() throws LifecycleException;
结合下面代码进行分析:
@Override
public final synchronized void init() throws LifecycleException {
//1. 状态检查
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
try {
//2. 触发 INITIALIZING 事件的监听器
setStateInternal(LifecycleState.INITIALIZING, null, false);
//3. 调用具体子类的初始化方法
initInternal();
//4. 触发 INITIALIZED 事件的监听器
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
...
}
}
- 进行状态检查,只有是 New 状态的组件才能进行 init
- 触发 INITIALIZING 事件的监听器
- 调用具体子类的初始化方法
- 触发 INITIALIZED 事件的监听器
总之,LifeCycleBase 调用了抽象方法来实现骨架逻辑,LifeCycleBase 负责触发事件,并调用监听器的方法。那是什么时候、谁把监听器注册进来的呢?
- Tomcat 自定义了一些监听器,这些监听器是父组件在创建子组件的过程中注册到子组件 的。比如 MemoryLeakTrackingListener 监听器,用来检测 Context 容器中的内存泄漏,这个监听器是 Host 容器在创建 Context 容器时注册到 Context 中的。
- 我们还可以在 server.xml 中定义自己的监听器,Tomcat 在启动时会解析 server.xml, 创建监听器并注册到容器组件。
总览图:

2 Tomcat启动流程
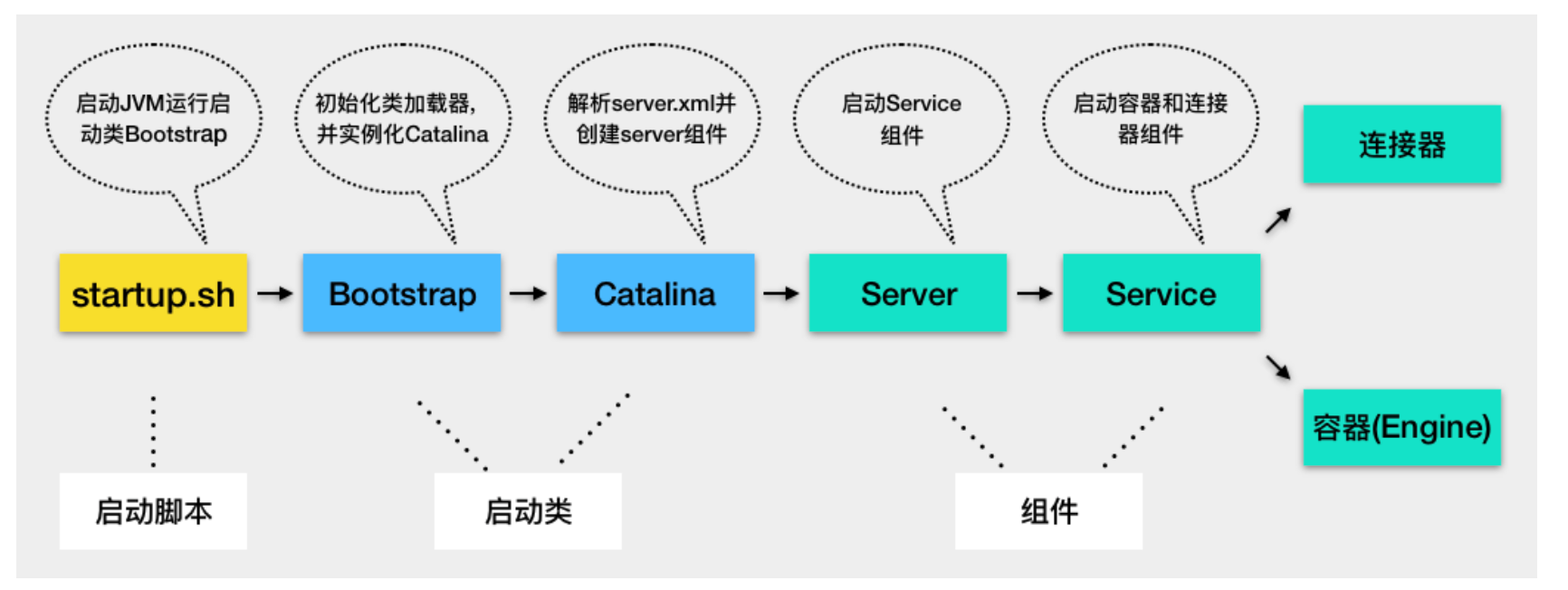
1.Tomcat 本质上是一个 Java 程序,因此 startup.sh 脚本会启动一个 JVM 来运行 Tomcat 的启动类 Bootstrap。
2.Bootstrap 的主要任务是初始化 Tomcat 的类加载器,并且创建 Catalina。(注意Tomcat和Java程序不是一个类加载器)
3.Catalina 是一个启动类,它通过解析 server.xml、创建相应的组件,并调用 Server 的 start 方法。
4.Server 组件的职责就是管理 Service 组件,它会负责调用 Service 的 start 方法。
5.Service 组件的职责就是管理连接器和顶层容器 Engine,因此它会调用连接器和 Engine 的 start 方法。
这样 Tomcat 的启动就算完成了。这些启动类或者组件不处理具体请求,它们的任务主要是“管理”,管理下层组件的生命周期,并且给下层组件分配任务,也就是把请求路由到负责“干活儿”的组件。
2.1 Catalina
Catalina 的主要任务就是创建 Server,它需要解析 server.xml,把在 server.xml 里配置的各种组件一一创建出来,接着调用 Server 组件的 init 方法和 start 方法,这样整个 Tomcat 就启动起来了。作为“管理者”,Catalina 还需要处理各种“异常”情况,比如当我们通过 “Ctrl + C” 关闭 Tomcat 时,Tomcat 将如何优雅的停止并且清理资源呢?因此 Catalina 在 JVM 中注册一个“关闭钩子”。
public void start() {
//1. 如果持有的 Server 实例为空,就解析 server.xml 创建出来
if (getServer() == null) {
load();
}
//2. 如果创建失败,报错退出
if (getServer() == null) {
log.fatal(sm.getString("catalina.noServer"));
return;
}
//3. 启动 Server
try {
getServer().start();
} catch (LifecycleException e) {
return;
}
// 创建并注册关闭钩子
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
}
// 用 await 方法监听停止请求
if (await) {
await();
stop();
}
}
“关闭钩子”其实就是一个线程,JVM 在停止之前会尝试执行这个线程的 run 方法。下面我们来看看 Tomcat 的“关闭钩子” CatalinaShutdownHook 做了些什么。
protected class CatalinaShutdownHook extends Thread {
@Override
public void run() {
try {
if (getServer() != null) {
Catalina.this.stop();
}
} catch (Throwable ex) {
...
}
}
}
从这段代码中你可以看到,Tomcat 的“关闭钩子”实际上就执行了 Server 的 stop 方法,Server 的 stop 方法会释放和清理所有的资源。
2.2 Server 组件
Server 组件的具体实现类是 StandardServer,我们来看下 StandardServer 具体实现了哪些功能。Server 继承了 LifeCycleBase,它的生命周期被统一管理,并且它的子组件是 Service,因此它还需要管理 Service 的生命周期,也就是说在启动时调用 Service 组件的启动方法,在停止时调用它们的停止方法。Server 在内部维护了若干 Service 组件,它是以数组来保存的,那 Server 是如何添加一个 Service 到数组中的呢?
@Override
public void addService(Service service) {
service.setServer(this);
synchronized (servicesLock) {
// 创建一个长度 +1 的新数组
Service results[] = new Service[services.length + 1];
// 将老的数据复制过去
System.arraycopy(services, 0, results, 0, services.length);
results[services.length] = service;
services = results;
// 启动 Service 组件
if (getState().isAvailable()) {
try {
service.start();
} catch (LifecycleException e) {
// Ignore
}
}
// 触发监听事件
support.firePropertyChange("service", null, service);
}
}
从上面的代码你能看到,它并没有一开始就分配一个很长的数组,而是在添加的过程中动态地扩展数组长度,当添加一个新的 Service 实例时,会创建一个新数组并把原来数组内容复制到新数组,这样做的目的其实是为了节省内存空间。
除此之外,Server 组件还有一个重要的任务是启动一个 Socket 来监听停止端口,这就是为什么你能通过 shutdown 命令来关闭 Tomcat。不知道你留意到没有,上面 Caralina 的启动方法的最后一行代码就是调用了 Server 的 await 方法。
在 await 方法里会创建一个 Socket 监听 8005 端口,并在一个死循环里接收 Socket 上的连接请求,如果有新的连接到来就建立连接,然后从 Socket 中读取数据;如果读到的数据是停止命令“SHUTDOWN”,就退出循环,进入 stop 流程。
2.3 Service 组件
Service 组件的具体实现类是 StandardService,我们先来看看它的定义以及关键的成员变量。
public class StandardService extends LifecycleBase implements Service {
// 名字
private String name = null;
//Server 实例
private Server server = null;
// 连接器数组
protected Connector connectors[] = new Connector[0];
private final Object connectorsLock = new Object();
// 对应的 Engine 容器
private Engine engine = null;
// 映射器及其监听器
protected final Mapper mapper = new Mapper();
protected final MapperListener mapperListener = new MapperListener(this);
}
StandardService 继承了 LifecycleBase 抽象类,此外 StandardService 中还有一些我们熟悉的组件,比如 Server、Connector、Engine 和 Mapper。
那为什么还有一个 MapperListener?这是因为 Tomcat 支持热部署,当 Web 应用的部署发生变化时,Mapper 中的映射信息也要跟着变化,MapperListener 就是一个监听器,它监听容器的变化,并把信息更新到 Mapper 中,这是典型的观察者模式。
作为“管理”角色的组件,最重要的是维护其他组件的生命周期。此外在启动各种组件时,要注意它们的依赖关系,也就是说,要注意启动的顺序。我们来看看 Service 启动方法:
protected void startInternal() throws LifecycleException {
//1. 触发启动监听器
setState(LifecycleState.STARTING);
//2. 先启动 Engine,Engine 会启动它子容器
if (engine != null) {
synchronized (engine) {
engine.start();
}
}
//3. 再启动 Mapper 监听器
mapperListener.start();
//4. 最后启动连接器,连接器会启动它子组件,比如 Endpoint
synchronized (connectorsLock) {
for (Connector connector: connectors) {
if (connector.getState() != LifecycleState.FAILED) {
connector.start();
}
}
}
}
从启动方法可以看到,Service 先启动了 Engine 组件,再启动 Mapper 监听器,最后才是启动连接器。这很好理解,因为内层组件启动好了才能对外提供服务,才能启动外层的连接器组件。而 Mapper 也依赖容器组件,容器组件启动好了才能监听它们的变化,因此 Mapper 和 MapperListener 在容器组件之后启动。组件停止的顺序跟启动顺序正好相反的,也是基于它们的依赖关系。
2.4 Engine 组件
最后我们再来看看顶层的容器组件 Engine 具体是如何实现的。Engine 本质是一个容器,因此它继承了 ContainerBase 基类,并且实现了 Engine 接口。
public class StandardEngine extends ContainerBase implements Engine {
}
我们知道,Engine 的子容器是 Host,所以它持有了一个 Host 容器的数组,这些功能都被抽象到了 ContainerBase 中,ContainerBase 中有这样一个数据结构:
protected final HashMap<String, Container> children = new HashMap<>();
ContainerBase 用 HashMap 保存了它的子容器,并且 ContainerBase 还实现了子容器的“增删改查”,甚至连子组件的启动和停止都提供了默认实现,比如 ContainerBase 会用专门的线程池来启动子容器。
for (int i = 0; i < children.length; i++) {
results.add(startStopExecutor.submit(new StartChild(children[i])));
}
所以 Engine 在启动 Host 子容器时就直接重用了这个方法。
那 Engine 自己做了什么呢?我们知道容器组件最重要的功能是处理请求,而 Engine 容器对请求的“处理”,其实就是把请求转发给某一个 Host 子容器来处理,具体是通过 Valve 来实现的。
通过前面的学习,我们知道每一个容器组件都有一个 Pipeline,而 Pipeline 中有一个基础阀(Basic Valve),而 Engine 容器的基础阀定义如下:
final class StandardEngineValve extends ValveBase {
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// 拿到请求中的 Host 容器
Host host = request.getHost();
if (host == null) {
return;
}
// 调用 Host 容器中的 Pipeline 中的第一个 Valve
host.getPipeline().getFirst().invoke(request, response);
}
}
这个基础阀实现非常简单,就是把请求转发到 Host 容器。你可能好奇,从代码中可以看到,处理请求的 Host 容器对象是从请求中拿到的,请求对象中怎么会有 Host 容器呢?这是因为请求到达 Engine 容器中之前,Mapper 组件已经对请求进行了路由处理,Mapper 组件通过请求的 URL 定位了相应的容器,并且把容器对象保存到了请求对象中。












![PostgreSQL的学习心得和知识总结(一百五十五)|[performance]优化期间将 WHERE 子句中的 IN VALUES 替换为 ANY](https://i-blog.csdnimg.cn/direct/e64811eefa534b10b01ef9f46f143b41.jpeg#pic_center)