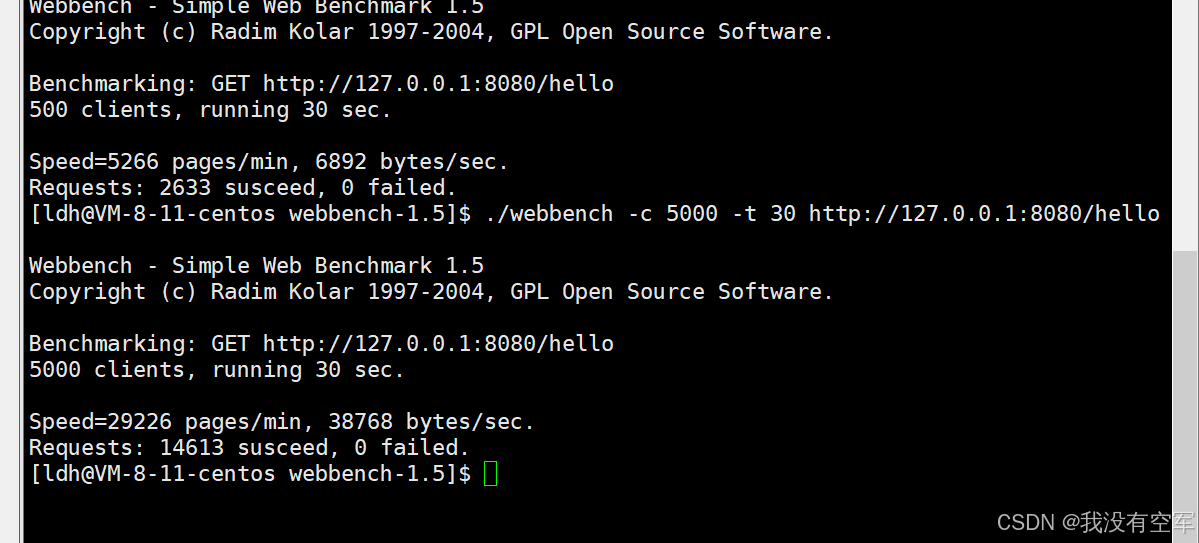
ok了这周学习了mybatis框架,今天最后一天,加油各位!!!(接上文)

八.MyBatis扩展
8.1 Mapper批量映射优化
需求
Mapper
配置文件很多时,在全局配置文件中一个一个注册太
麻烦,希望有一个办法能够一劳永逸。
配置方式
Mybatis
允许在指定
Mapper
映射文件时,只指定其所在的
包:
<mappers>
<package name="com.lzw.mapper"/>
</mappers>
此时这个包下的所有
Mapper
配置文件将被自动加载、注
册,比较方便。
资源创建要求
- Mapper 接口和 Mapper 配置文件名称一致
- Mapper 接口:EmployeeMapper.java
- Mapper 配置文件:EmployeeMapper.xml
- Mapper 配置文件放在 Mapper 接口所在的包内
- 可以将mapperxml文件放在mapper接口所在的包!
- 可以在sources下创建mapper接口包一致的文件夹结构存放mapperxml文件


8.2 分页插件PageHelper
8.2.1 PageHelper插件介绍
MyBatis
对插件进行了标准化的设计,并提供了一套可扩展的
插件机制。插件可以在用于语句执行过程中进行拦截,并允许
通过自定义处理程序来拦截和修改
SQL
语句、映射语句的结
果等。
PageHelper
是
MyBatis
中比较著名的分页插件,它提供了多
种分页方式(例如
MySQL
和
Oracle
分页方式),支持多种
数据库,并且使用非常简单。下面就介绍一下
PageHelper
的
使用方式。
8.2.2 PageHelper插件使用
- pom.xml引入依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.11</version>
</dependency>- mybatis-config.xml配置分页插件
<plugins>
<plugin
interceptor="com.github.pagehelper.PageIntercept
or">
<property name="helperDialect"
value="mysql"/>
</plugin>
</plugins>
其中,
com.github.pagehelper.PageInterceptor
是
PageHelper
插件的名称,
dialect
属性用于指定数据库类型
(支持多种数据库)
- 分页插件使用
public interface EmployeeMapper {
//查询所有员工信息
public List<Employee> findAll();
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper
3.0//EN"
"https://mybatis.org/dtd/mybatis-3-
mapper.dtd">
<mapper
namespace="com.lzw.mapper.EmployeeMapper">
<select id="findAll" resultType="Employee">
select * from t_emp
</select>
</mapper>@Test
public void testDemo(){
//使用工具类获取SqlSession对象
SqlSession sqlSession =
SqlSessionUtil.openSession();
//基于接口获取实现类对象(代理对象)
EmployeeMapper employeeMapper =
sqlSession.getMapper(EmployeeMapper.class);
//通过多态调用方法
//开启分页查询,但是分页更丰富的功能并非来自于它
PageHelper.startPage(3,3);
List<Employee> employeeList =
employeeMapper.findAll();
PageInfo<Employee> pageInfo=new
PageInfo<>(employeeList,3);
System.out.println("当前
页:"+pageInfo.getPageNum());
System.out.println("每页的数
量:"+pageInfo.getPageSize());
System.out.println("总页
数:"+pageInfo.getPages());
System.out.println("总条
数:"+pageInfo.getTotal());
System.out.println("是否为第一
页:"+pageInfo.isIsFirstPage());
System.out.println("是否为最后一
页"+pageInfo.isIsLastPage());
System.out.println("上一
页:"+pageInfo.getPrePage());
System.out.println("下一
页:"+pageInfo.getNextPage());
//导航条上页码的数量
System.out.println("导航页码
数:"+pageInfo.getNavigatePages());
System.out.println("==================");
//导航条上具体的页码
int[] nums =
pageInfo.getNavigatepageNums();
for (int num : nums) {
System.out.print(num+"\t");
}
System.out.println("");
//释放资源
sqlSession.close();
}8.3 ORM介绍
8.3.1 ORM思维介绍
ORM
(
Object-Relational Mapping
,对象
-
关系映射)是一种
将数据库和面向对象编程语言中的对象之间进行转换的技术。
它将对象和关系数据库的概念进行映射,通过一系列的操作将
对象关联到数据表中的一行或多行上。
让我们可以使用面向对象思维进行数据库操作!!
8.3.2 ORM 框架通常有半自动和全自动两种方式
-
半自动 ORM 通常需要程序员手动编写 SQL 语句或者配置文件,将实体类和数据表进行映射,还需要手动将查询的结果集转换成实体对象。
-
全自动 ORM 则是将实体类和数据表进行自动映射,使用API 进行数据库操作时, ORM 框架会自动执行 SQL 语句并将查询结果转换成实体对象,程序员无需再手动编写 SQL语句和转换代码。
8.3.3 半自动和全自动 ORM 框架的区别
映射方式:半自动
ORM
框架需要程序员手动指定实体类
和数据表之间的映射关系,通常使用
XML
文件或注解方式
来指定;全自动
ORM
框架则可以自动进行实体类和数据
表的映射,无需手动干预。
查询方式:半自动
ORM
框架通常需要程序员手动编写
SQL
语句并将查询结果集转换成实体对象;全自动
ORM
框架可以自动组装
SQL
语句、执行查询操作,并将查询结
果转换成实体对象。
性能:由于半自动
ORM
框架需要手动编写
SQL
语句,因
此程序员必须对
SQL
语句和数据库的底层知识有一定的了
解,才能编写高效的
SQL
语句;而全自动
ORM
框架通过
自动优化生成的
SQL
语句来提高性能,程序员无需进行优
化.
学习成本:半自动
ORM
框架需要程序员手动编写
SQL
语
句和映射配置,要求程序员具备较高的数据库和
SQL
知
识;全自动
ORM
框架可以自动生成
SQL
语句和映射配
置,程序员无需了解过多的数据库和
SQL
知识。
常见的半自动
ORM
框架包括
MyBatis
等;常见的全自动
ORM
框架包括
Hibernate
、
Spring Data JPA
、MyBatis-
Plus
等。
8.4 逆向工程
8.4.1 逆向工程介绍
MyBatis
的逆向工程是一种自动化生成持久层代码和映射文件
的工具,它可以根据数据库表结构和设置的参数生成对应的实
体类、
Mapper.xml
文件、
Mapper
接口等代码文件,简化了
开发者手动生成的过程。逆向工程使开发者可以快速地构建起
DAO
层,并快速上手进行业务开发。
MyBatis
的逆向工程有两种方式:通过
MyBatis Generator
插件实现和通过
Maven
插件实现。无论是哪种方式,逆向工
程一般需要指定一些配置参数,例如数据库连接
URL
、用户
名、密码、要生成的表名、生成的文件路径等等。
总的来说,
MyBatis
的逆向工程为程序员提供了一种方便快捷
的方式,能够快速地生成持久层代码和映射文件,是半自动
ORM
思维像全自动发展的过程,提高程序员的开发效率
注意:逆向工程只能生成单表
crud
的操作,多表查询依然需
要我们自己编写
8.4.2 逆向工程插件MyBatisX使用
MyBatisX
是一个
MyBatis
的代码生成插件,可以通过简单的
配置和操作快速生成
MyBatis Mapper
、
pojo
类和
Mapper.xml
文件。下面是使用
MyBatisX
插件实现逆向工程
的步骤:
安装插件:
在
IntelliJ IDEA
中打开插件市场,搜索
MyBatisX
并安装。
使用
IntelliJ IDEA
连接数据库




8.5 注解开发
使用注解开发会比配置文件开发更加方便。如下就是使用注解
进行开发
public interface EmployeeMapper {
@Select("select * from t_emp where emp_id =
#{empId}")
public Employee findEmpById(Integer EmpId);
//查询所有员工信息
public List<Employee> findAll();
}注解是用来替换映射配置文件方式配置的,所以使用了注解,就不需要再映射配置文件中书写对应的statement
Mybatis
针对
CURD
操作都提供了对应的注解,已经做到见
名知意。如下:
- 查询 :@Select
- 添加 :@Insert
- 修改 :@Update
- 删除 :@Delete
注意:注解完成简单功能,配置文件完成复杂功能。
public interface EmployeeMapper {
//@Results注解相当于ResultMap
@Select("select * from t_emp where emp_id =
#{empId}")
@Results(value={
@Result(id=true,column =
"emp_id",property = "empId"),
@Result(column = "emp_name",property
= "empName"),
@Result(column =
"emp_salary",property = "empSalary")
})
public Employee findEmpById(Integer EmpId);
//查询所有员工信息
public List<Employee> findAll();
}8.6 设置模板


ok了家人们,下周见,特别是你hh