服务器配置如下:
CPU/NPU:鲲鹏 CPU(ARM64)+A300I pro推理卡
系统:Kylin V10 SP1【下载链接】【安装链接】
驱动与固件版本版本:
Ascend-hdk-310p-npu-driver_23.0.1_linux-aarch64.run【下载链接】
Ascend-hdk-310p-npu-firmware_7.1.0.4.220.run【下载链接】
MCU版本:Ascend-hdk-310p-mcu_23.2.3【下载链接】
CANN开发套件:版本7.0.1【Toolkit下载链接】【Kernels下载链接】
测试om模型环境如下:
Python:版本3.8.11
推理工具:ais_bench
测试YOLO系列:v5/6/7/8/9/10/11
专栏其他文章:
Atlas800昇腾服务器(型号:3000)—驱动与固件安装(一)
Atlas800昇腾服务器(型号:3000)—CANN安装(二)
Atlas800昇腾服务器(型号:3000)—YOLO全系列om模型转换测试(三)
Atlas800昇腾服务器(型号:3000)—AIPP加速前处理(四)
Atlas800昇腾服务器(型号:3000)—YOLO全系列NPU推理【检测】(五)
Atlas800昇腾服务器(型号:3000)—YOLO全系列NPU推理【实例分割】(六)
Atlas800昇腾服务器(型号:3000)—YOLO全系列NPU推理【关键点】(七)
Atlas800昇腾服务器(型号:3000)—YOLO全系列NPU推理【跟踪】(八)
1 AIPP介绍
AIPP(Artificial Intelligence Pre-Processing)人工智能预处理,用于在AI Core上完成数据预处理,包括改变图像尺寸、色域转换(转换图像格式)、减均值/乘系数(改变图像像素),数据预处理之后再进行真正的模型推理。
该模块功能与DVPP相似,都可以实现媒体数据处理的功能,两者的功能范围有重合,比如改变图像尺寸、转换图像格式,但功能范围也有不同的,比如DVPP可以做图像编解码、视频编解码,AIPP可以做归一化配置。与DVPP不同的是,AIPP主要用于在AI Core上完成数据预处理,DVPP是昇腾AI处理器内置的图像处理单元,通过AscendCL媒体数据处理接口提供强大的媒体处理硬加速能力。
AIPP、DVPP可以分开独立使用,也可以组合使用。组合使用场景下,一般先使用DVPP对图片/视频进行解码、抠图、缩放等基本处理,但由于DVPP硬件上的约束,DVPP处理后的图片格式、分辨率有可能不满足模型的要求,因此还需要再经过AIPP进一步做色域转换、抠图、填充等处理。
AIPP根据配置方式不同 ,分为静态AIPP和动态AIPP;如果要将原始图片输出为满足推理要求的图片格式,则需要使用色域转换功能;如果要输出固定大小的图片,则需要使用AIPP提供的Crop(抠图)、Padding(补边)功能。
详情见文档:https://www.hiascend.com/document/detail/zh/canncommercial/80RC2/devaids/auxiliarydevtool/atlasatc_16_0016.html
2 YOLO前处理耗时分析
YOLO前处理,包括:resize, pad, HWC to CHW,BGR to RGB,归一化,增加维度CHW -> BCHW六个步骤。
代码如下:

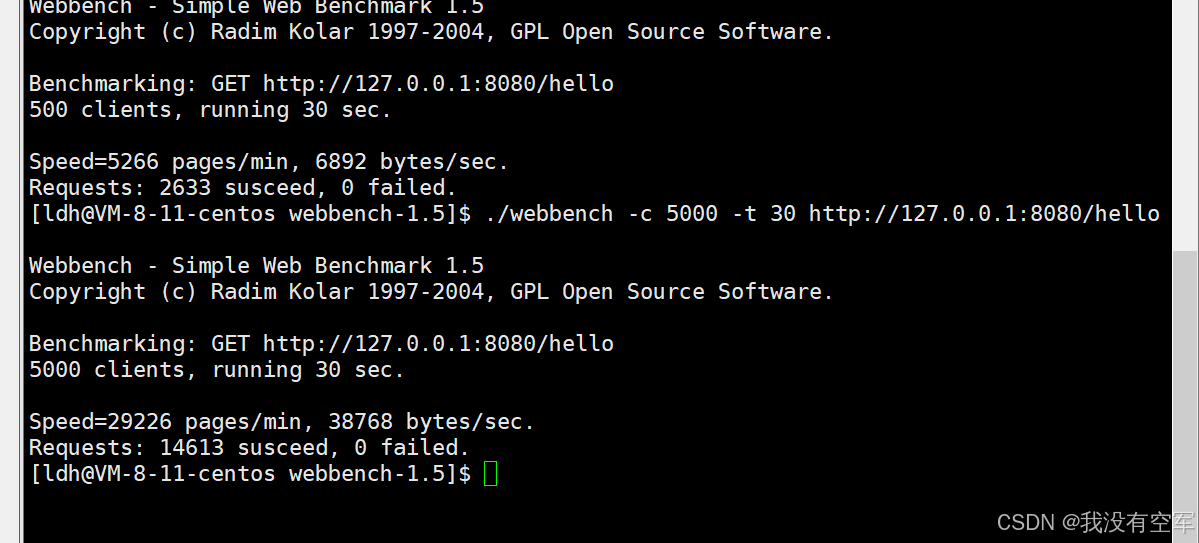
利用YOLOv8s.om模型对整个前处理耗时进行分析,耗时结果如下:
注意:推理1920×1080图像,模型输入1280×1280

由上可知,在整个前处理中,resize+pad操作的耗时少于2ms,而通道转换+归一化耗时占比极大!
因此,可将通道转换+归一化耗时较长的步骤利用AIPP进行加速处理,减少前处理耗时,同时保留resize操作在外,可保证模型输入尺寸一致!
3 AIPP算子优化YOLO的前处理过程
前处理包括:resize,pad,HWC to CHW,BGR to RGB,归一化,增加维度CHW -> BCHW
这里我们将resize, pad保留在外,HWC to CHW,BGR to RGB,归一化等集成到om模型中!
另外,HWC到CHW的转换由ATC工具自动完成。
ATC转换命令如下【主要附带一个AIPP配置文件】:
atc --framework=5 --model=yolov8s.onnx --input_format=NCHW --input_shape="images:1,3,1280,1280" --output_type=FP32 --output=yolov8s_aipp --soc_version=Ascend310P3 --insert_op_conf=aipp_conf.aippconfig
aipp_conf.aippconfig配置参数如下:【BGR to RGB,归一化】
主要参数src_image_size_w/h为输入模型宽高,rbuv_swap_switch是否进行色域转换,var_reci_chn_0/1/2由1/255求得。
其中,归一化计算公式:

# 通道转换rbuv_swap_switch参数设置为true
# 归一化系数需要根据用户模型实际需求配置,此处取默认值,即不改变像素的值
# 若配置归一化系数,将应用于通道交换之后的通道
aipp_op {
related_input_rank : 0
src_image_size_w : 1280
src_image_size_h : 1280
crop : false
padding : false
aipp_mode: static
input_format : RGB888_U8
csc_switch : false
rbuv_swap_switch : true
mean_chn_0 : 0
mean_chn_1 : 0
mean_chn_2 : 0
min_chn_0 : 0.0
min_chn_1 : 0.0
min_chn_2 : 0.0
var_reci_chn_0 : 0.00392157
var_reci_chn_1 : 0.00392157
var_reci_chn_2 : 0.00392157
}
BGR to RGB,归一化集成到om模型后,剩余前处理代码如下【只有resize和pad操作】:

最终耗时如下:【提升明显,推理时间也有所减少】
模型输入尺寸1280×1280的预处理+推理耗时从34ms降到13ms!!!

具体预处理代码如下【resize+pad】:
# 前处理,包括:resize, pad
def preprocess(self, img):
"""
Pre-processes the input image.
Args:
img (Numpy.ndarray): image about to be processed.
Returns:
img_process (Numpy.ndarray): image preprocessed for inference.
ratio (tuple): width, height ratios in letterbox.
pad_w (float): width padding in letterbox.
pad_h (float): height padding in letterbox.
"""
# Resize and pad input image using letterbox() (Borrowed from Ultralytics)
shape = img.shape[:2] # original image shape
new_shape = (self.model_height, self.model_width)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
ratio = r, r
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
pad_w, pad_h = (new_shape[1] - new_unpad[0]) / 2, (new_shape[0] - new_unpad[1]) / 2 # wh padding
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(pad_h - 0.1)), int(round(pad_h + 0.1))
left, right = int(round(pad_w - 0.1)), int(round(pad_w + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # 填充
return img, ratio, (pad_w, pad_h)
综上,如果我们模型的前处理时间耗时较长时,可以将耗时较长的步骤通过ATC追加AIPP配置集成到om模型中,从而达到前处理缩短的效果,该操作不限于YOLO的前处理!