目录
1、Linux软件包管理器yum
1.1 什么是软件包
1.2 安装软件
1.3 查看软件包
1.4 卸载软件
2、Linux编辑器-vim
2.1 vim的概念
2.2 vim的基本操作
2.3 vim的配置
3、Linux编译器-gcc/g++
3.1 gcc编译的过程编辑编辑编辑
3.2 详解链接
动态链接
静态链接
4、Linux项目自动化构建工具-make/makefile
4.1 make/makefile的使用
4.2 依赖关系与依赖方法
4.3 .PHONY
4.4 make的自动推导
4.5 多文件编译
5、小程序
5.1 回车换行
5.2 缓冲区
5.3 倒计时小程序
5.4 进度条小程序
6、git
6.1 版本控制
6.2 创建仓库
Linux
Windows
7、Linux调试器-gdb
7.1 debug与release
7.2 调试命令
7.3 cgdb
7.4 条件断点
1、Linux软件包管理器yum
Linux中,常见的软件安装方式:
a. yum/apt
b. .rpm安装包安装
c. 源码安装
Linux的软件生态
评价一款操作系统好不好,除了要看操作系统本身,还要看操作系统好不好获取、操作系统是否有活跃的社区、论坛、操作系统在官方中是否有完善的文档说明、操作系统的用户是那些,这一套称为软件生态
1.1 什么是软件包
在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序。但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装。软件包和软件包管理器, 就好比 "App" 和 "应用商店" 这样的关系。yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora, RedHat, Centos等发行版上。
所以,简单来说,软件包就是一个编译好的可执行程序。
1.2 安装软件
安装软件需要是root,也可sudo,因为安装软件通常是安装到/usr/bin目录下,这个目录的拥有者、所属组均为root,并且对于other没有写的权限
通常安装就是yun install -y ...,install是下载,将软件包下载并安装的效果,不加-y是会在下载完被询问是否需要安装
1.3 查看软件包
可以使用yum list将所有已安装和可安装的软件包罗列出来
会出现3列,第一列是软件包的名称,第二列是版本号,el7就是在CentOS7下使用,第三列是yum源的来历。
也可以使用管道来查看与某一关键词相关的软件包
1.4 卸载软件
可以使用yum remove -y ...来卸载软件,-y与install中含义相同
我们这里以lrzsz这个软件包为例,这个软件包是用于windows和Linux两种操作系统之间文件的传递的,sz将Linux中的文件传入windows中,拖拽将windows中的文件传入Linux中
若一个安装包已经安装,再install是不会做任何事情的,此时可以使用sz向windows传文件
将这个软件卸载后就无法再使用sz了![]()
再下载回来就可以正常使用了
此时会有一个问题,云服务器有那么多,yum install为什么就能知道去那一台云服务器上找到对应的软件包呢?实际上,yum是有对应的配置文件的,配置文件中就记录了软件包对应的yum源,yum会根据这些yum源,将自己的系统版本替换,再根据系统路径形成一条下载链接,然后yum会去调用一些工具通过下载链接下载下来。配置文件在/etc/yum.repos.d/中,一般看CentOS-Base.repo
可以使用vim来查看配置文件中的内容

若要配置yum源,首先要下载一个国内的yum源,然后替换掉/etc/yum.repos.d/中的,一般替换掉CentOS-Base.repo,注意,在替换掉之前需要先将下载下来的yum源改名为CentOS-Base.repo。配置后yum源就不是CentOS7的,而是配置的
2、Linux编辑器-vim
2.1 vim的概念
在之前,我们使用vs2022时,vs2022可以完成代码的编辑、编译、调试、运行等,称为集成开发环境,而vim仅仅只能完成代码的编辑。
vim有多种模式,这里主要介绍3种模式
(1)命令模式
一打开vim就是命令模式,在命令模式下只能输入命令,输入其他的无效
(2)插入模式
此时可以随机编辑内容
(3)底行模式
在文档内的最底行输入指令
2.2 vim的基本操作
使用vim打开一个普通文件就行编辑
(1)3种模式的互相切换
在底行模式下输入set nu/set number可调出行号
(2)光标所在行
a. 复制:yy,n + yy可以复制多行
b. 粘贴:p,n + p
c. 撤销:u
d. 剪切:dd,n + dd,剪切也可用于删除
(3)光标快速定位
a. shift + g = G:定位到文本的最末尾
b. gg:定位到文本的最开始
c. n + shift + g = n + G:定位到文本的第n行
d. 光标局部定位,可以使用上下左右,也可以使用HJKL,H左,J下,K上,L右
(4)每一行操作
a. shift + 4 = $:到行尾
b. shift + 6 = ^:到行首,行尾和行首也称为锚点
c. w:以单词为单位向后跳转
d. b:以单词为单位向前跳转
(5)局部删除编辑
a. x:光标位置向后逐字节删除,n + x
b. shift + x = X:光标位置向前逐字节删除,n + shift + x
注意:光标向后删除会删除掉光标所在位置的字符,光标向前删除是删除光标前一个
c. shift + ~:大小写快速切换,一直按住可以快速向后移动
d. n + r + 字符:将原本的字符替换为输入的字符
e. ctrl + r = R:撤销刚刚的撤销,可以与u相抵消
使用n+r+字符来替换字符是比较麻烦的,因为替换完1个字符后要手动向后移动,可以使用shift+r=R来进入替换模式,按Esc回到命令模式
在底行模式下,可以输入一些字符来进行在文本中查找,按n可跳转到下一处
插入模式、底行模式这两个模式是无法直接切换的,需要先切换到命令模式再切换。因为在插入模式中,所有输入都回被当成普通字符。如何模式都可有命令模式进入。
进入插入模式有3种方式,aio,a是光标向后移动一位,i是光标不动,o是光标向下新开一行
底行模式下:set/nu/number是加行号,set nonu是取消行号,w是保存,q是退出,w!是强制写入,q!是强制退出,wq,wq!
可在vim的底行模式下输入! + Linux中的指令来对vim的外部进行操作,按回车技能回到vim中
这个的真正作用是在不关闭vim的前提下对vim打开的文件进行编译
当然,也可以在vim里面运行,这里是退出vim再运行
可以使用vs来打开文件,此时会分屏,此时窗口可能有多个,但是光标只有一个

ctrl + w:将光标移动到下一个窗口,不断按w就可一直切换到想要的窗口
此时可将一个窗口的内容复制到另一个窗口
此时使用wq是关闭光标所在的窗口
shift + zz = ZZ,相当于wq,但是用wq,不建议使用shift + zz
如果我们想对代码进行注释,可以手动一行一行//,但是这样效率太低
此时可以使用ctrl + v进入视图模式,可以进行批量化注释
步骤是:ctrl+v -> HJKL进行区域选择 -> shift+i=I进入插入模式 -> 注释选择区域的第一行 -> Esc
这里不建议使用上下键
这里也不仅可以加注释,其他批量操作都可以|
到末尾全注释:ctrl+v -> shift + g -> shift+i=I进入插入模式 -> 注释选择区域的第一行 -> Esc
注释到第n行:ctrl+v -> n + shift + g -> shift+i=I进入插入模式 -> 注释选择区域的第一行 -> Esc
取消注释:ctrl -> HJKL进行区域选择 -> d
我们可以更新上面模式切换的图片
2.3 vim的配置
在用户目录下会有一些隐藏配置,每用vim打开文件,会在该用户的家目录下查找名为.vimrc的配置文件,没有则创建一个,在.vimrc中编辑即可配置vim
我们现在要配置vim,使之能够更方便地写代码,所以创建一个.vimrc来配置vim
我们随意向.vimrc中写入一条指令,看看效果
此时向.vimrc中写入了一条设置行号的指令,再用vim打开文件,里面就自动加了行号
我们现在是给普通用户cxf设置了vim,使用root或其他普通用户打开vim时是不会读取cxf的.vimrc的,即使进入了cxf的家目录。vim启动时,会读取当前用户家目录下的配置文件,给自己配置了,只会影响自己
我们前面有提到过sudo这个指令,是给普通用户提权的指令,实际上就是在/etc/sudoers这个配置文件中操作,此时需要切换为root
复制第一句,然后修改名字即可,后面不需要变,要wq!,因为这个文件对于root的权限也只有读
此时就可以使用sudo来进行提权操作了
现在创建文件就有3种方式了:touch、>、vim打开一个不存在的文件,是否往里面写入内容都行,只要最后有保存
3、Linux编译器-gcc/g++
前面我们在vim中编写了代码,若想要对代码进行编译并生成可执行文件,就需要使用gcc
3.1 gcc编译的过程
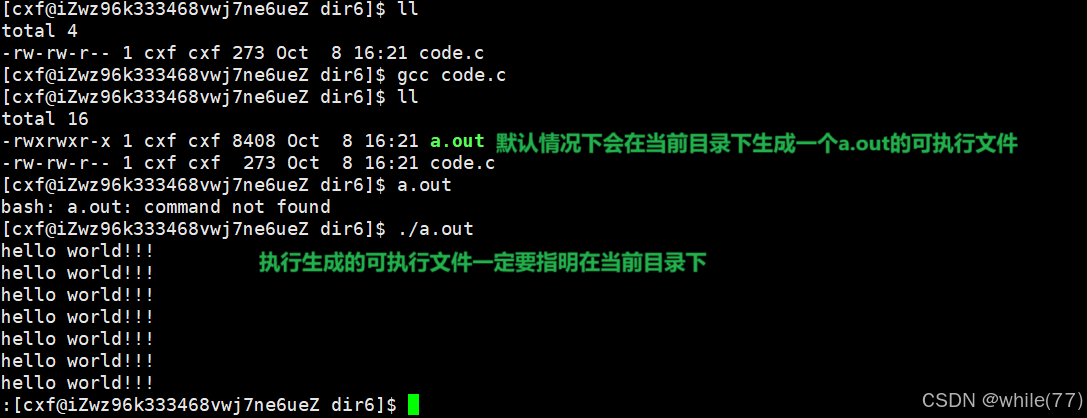
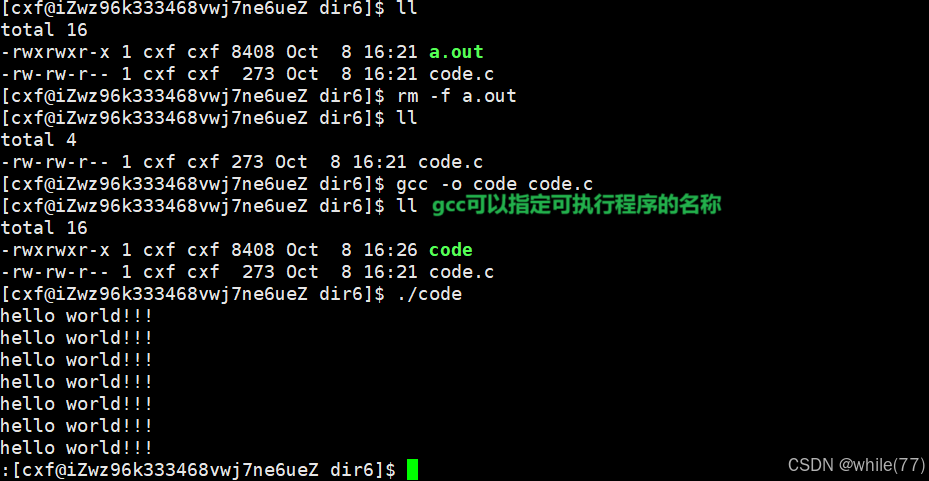
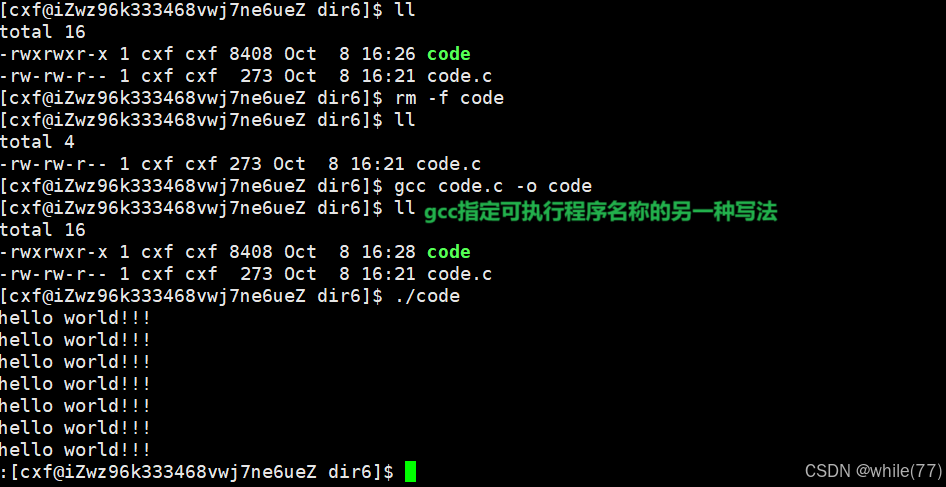
实际上,gcc在将源文件(.c)编译成可执行文件的过程中,有4步操作,分别是预处理、编译、编译、链接,可以通过gcc的选项来观察这4步
1、预处理(进行宏替换)

2、编译(生成汇编)

3、汇编(生成机器可识别的二进制代码)

汇编完成的文件(.o)称为可重定位目标文件
会发现code.o不可执行,即使加上了可执行权限仍然不可执行,这是因为code.o本身不可执行
4、链接(生成可执行文件或库文件)

3.2 详解链接
可以使用ldd+可执行程序来查看这个可执行程序来链接时链接了那些库|
code这个可执行程序在链接时链接了3个库,其中第一、三个库基本上所有程序都会有。从第二个库中可以看出code依赖的是c标准库,因为我们是使用c语言写的code.c

会发现ls指令也是用c语言写的,实际上很多指令都是用c语言写的
上面以.so结尾的是动态库,再后面的是版本号
讨论一个问题:是先有编译器还是先有语言?
先有编译器。最先开始计算机只有二进制,这时候是不需要编译器的,直到有了汇编时才有了编译器的需求,是先用二进制写一个汇编的编译器,将汇编代码翻译成二进制,这样才能够让汇编语言跑起来,否则语言无法编译。
讨论另一个问题:为什么要将高级语言变成汇编,再变成二进制呢?而不是直接从高级语言翻译成二进制呢?
可以。但是成本太高,并且历史也不是这么发展的。
C语言头文件在/usr/include下

随便打开一个头文件会发现里面就是大量函数的声明,这些函数的实现在库文件libc-2.17.so中
链接实际上就是根据头文件中的声明去库文件找对应的函数的过程。
链接方式有动态链接和静态链接两种
动态链接
动态链接需要用到动态库:.so(linux)、.dll(windows)
链接时编译器会告诉可执行程序,库函数要用到的动态库和地址,当调用到库函数时,就到动态库的这个地址找(执行到需要库的方法时,跳转到动态库,执行完再返回继续向后执行,这个过程称为跳转)
动态链接的优势是:所有人共享一个库,比较节省资源,可执行程序体积较小
动态链接的劣势是:一旦动态库缺失,所有程序都将无法执行,并且跳转较为浪费时间
静态链接
静态链接需要用到静态库:.a(linux)、.lib(windows)
静态链接就是当我们需要用到某一个库函数时,去静态库中拷贝一个库函数到我们的可执行程序中
静态链接的优势是:不依赖其他库,库丢失也无所谓
静态链接的劣势是:比较浪费资源,可执行程序的体积比较大
我们使用gcc生成的可执行程序默认是动态链接
可以使用file+文件来查看一个文件的文件类型
可以发现刚刚的code就是使用动态链接的方式生成的
另外,通过ldd也可以看到链接的库是.so,是动态库,也可证明是动态链接的方式生成的
若想要使用静态链接的方式生成一个可执行程序,需要先安装C/C++的静态库![]()

静态库在/lib64/libc.a中
4、Linux项目自动化构建工具-make/makefile
4.1 make/makefile的使用
当我们要对写好的代码进行编译时,可以使用gcc来编译,也可是使用make/makefile来编译,其中make是一个指令,而makefile是一个文件,makefile首字母也可以大写。

会发现,我们将makefile完成后,调用make即可生成可执行程序。当我们调用make时,会去寻找当前目录下的makefile,并执行里面的内容。
当我们要删除一个可执行程序时,可以使用rm,也可以使用make/makefile

4.2 依赖关系与依赖方法
在上面我们的makefile中实际上是写了两组依赖关系以及对应的依赖方法
依赖关系的下一行必须是依赖方法,并且依赖方法的前面一定要有一个Tab
.PHONY的后面跟的是伪目标文件。这里的clean就是伪目标文件,注意,并不是一定要取名为clean
makefile文件会被make从上到下扫描,第一个目标名是缺省形成的,如果想要执行其他组的依赖关系和依赖方法,make name(make name就是生成一个名字为name的目标文件):当我们调用make时能够形成一个proc的可执行程序是因为这时makefile从上到下扫描到的第一组依赖关系。而调用make clean时,就是要让其形成一个名称为clean的文件,此时就会去makefile中查找目标文件是clean的依赖关系,并执行其依赖方法
若将两组依赖关系的顺序兑换,调用方式也需要兑换

我们更加习惯于将清理放在最后面
实际上,依赖方法就是一条命令,可写任何命令,也可执行多条命令
makefile中的注释使用#
我们会发现,依赖方法执行时,会将依赖方法和结果同时输出。可以在依赖方法前加@,让其只输出结果,不输出依赖方法

若makefile中的gcc有错,则makefile中执行到gcc那一步就不会再向下执行了,终止推导程序
编译好后还可以将可执行程序重命名之类的,因为可以跟多条依赖方法
4.3 .PHONY
我们此时可能会有疑问,.PHONY的用处是什么?
我们先来看看make的一个特性
会发现,当已经有了可执行程序,并且没修改程序代码,再make会提示当前可执行程序是最新的,并且不会再重新生成一个可执行程序。若修改了proc.c中的内容,即使有可执行的proc,也会重新编译生成一个
clean有.PHONY时
clean没有.PHONY时
会发现clean无论有没有被.PHONY修饰都是一样的,可以一直make clean
我们在上面看到了没有被.PHONY修饰的proc,现在来看看使用.PHONY修饰后的proc有什么不同

会发现使用.PHONY修饰proc后,就可以一直make了
此时会有两点疑问:
(1).PHONY是如何做到的?
(2)为什么无论有没有.PHONY修饰,clean没有变化,而.PHONY修饰proc后有明显区别
我们首先来看第一个问题
使用stat可以查看一个文件的属性
任何文件都有3个时间
Access:文件最近被访问的时间
Modify:文件内容最近被修改的时间
Change:文件属性最近被修改的时间
注意:对属性修改,内容不会变,但是对内容修改,属性可能会变,如往文件中写入了内容,可能会导致文件的大小变大Access时间相较于另外两个时间并不是重点,但这里要对Access时间强调一点:不一定会随着访问而变化,因为在Linux中访问文件的次数是远大于另外两个之和的,cat一下也是访问文件,若每访问一次就会修改一下Access(文件是放在磁盘上的),这样操作系统就会与磁盘进行频繁的IO交互,影响效率。所以Access不是每一次访问都会刷新,而是积累一定次数才刷新
Modify也是创建时间
make是否需要重新编译,看的就是可执行程序与其对应的源文件的Modify,源文件的Modify若小于可执行程序的Modify,则不会重新编译,若大于则重新编译,不会出现等于的,因为必须是先有源文件才能有可执行程序
所以,问题(1)的答案就是。.PHONY会让依赖方法忽略掉时间对比,一直执行依赖方法。
接下来看问题(2)
proc调用的依赖方法是gcc,是会生成可执行程序的,这样就有了可执行程序和源文件,可以进行时间对比。但是clean的依赖方法是rm,不会生成文件,并且rm本身也不关心时间
这里建议clean时带上.PHONY,因为rm不关心时间,但是clean后面可能不止一条依赖方法,有些依赖方法可能关心时间,若因为其他关心时间的方法导致rm没有执行,则可能出错

touch -m 文件:可以修改文件被修改的时间到当前时间
4.4 make的自动推导


此时直接make要生成的文件是proc,proc的依赖文件是proc.o,会发现当前目录下并没有(依赖关系不存在,无法执行依赖方法),所以要先去生成proc.o,所以寻找proc.o作为目标文件的依赖关系,发现依赖文件是proc.s,仍然没有,继续向下,直到找到存在的依赖文件。
实际上,输入make指令后要读makefile文件,会有一个栈的结构,当依赖关系不存在时,就将依赖方法入栈,直到找到依赖关系存在的,就出栈,并执行命令
总结:make解释makefile时,会自动推导。一直推导,不执行依赖方法。直到推导到有依赖文件存在,然后逆向地执行所有的依赖方法。
通常不会像上面一样写的那么详细,而是会先用.c生成.o,再用.o生成可执行程序,windows下运行一个文件,除了生成可执行文件外,通常还会生成一个.obj文件,就是这里的.o文件
4.5 多文件编译
我们现在来使用另一种写法完成与上面那幅图相同的功能
%.o:形成与.c同名的.o文件
%.c:当前目录下所有的.c文件,展开到依赖列表中
$<:将右侧的依赖文件一个一个地交给gcc -c选项,形成同名的.o文件
上面proc的依赖列表中只有proc.o一个文件,所以只会形成一个.o文件,若proc的依赖列表中有多个.o文件,并且当前目录下也有足够的.c文件,则会同时生成多个.o文件
还可以更进一步地使用通配符
这里的src可能是一个依赖列表

$^:所有的依赖文件列表
$@:目标文件
现在我们想要修改可执行程序的名称,直接修改bin右边的值即可

为了简便,我们现在不生成.o文件
![]()

我们现在要一次make,将这两个.c文件都生成可执行程序

会发现,只生成了一个可执行程序,这是为什么呢?
因为在makefile中,只要形成了一个可执行程序后,makefile就不再执行。也就是说,make默认只形成一个可执行程序
若想要一次形成多个可执行程序,可以定义一个伪目标

为什么定义一个为目标就行了呢?
因为伪目标all依赖于bin1、bin2,此时makefile从上往下扫描时就会认为自己需要形成的是all,all依赖于bin1、bin2,就会向下寻找生成bin1、bin2的依赖关系,从而生成bin1、bin2,生成bin1、bin2后,all并没有依赖方法,所以直接结束
5、小程序
我们结合前面所学习到的知识点,来完成两个小程序,倒计时和进度条,要完成这两个小程序,首先需要了解两个小知识:回车换行、缓冲区
5.1 回车换行
回车(\r)是让光标回到所在行的最前面
换行(\n)是让光标到下一行的相同位置
在计算机中按回车键,实际上是回车+换行,即\r\n
输入\r是只回车。C/C++对\n进行了特殊处理,使其功能为\r\n
5.2 缓冲区
我们先通过一个程序来见一见缓冲区
sleep是让程序休眠的函数,sleep(n),让程序休眠n秒


此时成功生成了可执行程序,执行可执行程序时,先打印出了hello world,过了两秒程序才结束
我们现在修改一下程序,将换行去掉,看看有什么区别

此时也能打印出hello world,但是是程序运行2秒后才打印的,并且打印完立刻结束。在C语言中,一个函数是从上往下执行的,所以printf一定比sleep先执行,为什么printf执行后,没看见输出的字符串呢?在执行sleep的2秒内,这个字符串在哪里呢?
实际上,在执行sleep的2秒内,字符串在缓冲区中。当printf的末尾有\n时,强制刷新了缓冲区,将缓冲区内的内容输出了出来,而printf末尾没有\n时,不会刷新缓冲区,缓冲区内的内容就一直放在缓冲区,直到程序中有刷新缓冲区的内容被执行或程序结束,才会被输出。
程序编译好,变成二进制后是要加载到内存的,程序是被CPU执行的,CPU无法直接将字符串显示到显示器上,所以程序会在内存上对显示器开一段空间,这个空间就是缓冲区,将字符串从内存拷贝到内存。若这个字符串有\n,则立刻被刷新,若这个字符串没有\n,则在缓冲区暂存,直到缓冲区被写码或碰到\n才输出
若想让没有带\n的字符也立刻输出,可以使用fflush函数,刷新文件流
文件输出时,C语言有3个输出流,可以使用man stdin查看
显示时与输出有关的时stdout,缓冲区就在stdout指针指向的FILE对象中

此时除了字符串没有换行,都与有换行时的效果相同
5.3 倒计时小程序
有了前面的铺垫,现在来写一个倒计时小程序
先来完成一个从9减到0的倒计时小程序
这样是不好的,因为每输出一个数会换行
我们想要的效果是每次只输出一个数字,下一个数字会覆盖掉上一个数字,最后0保留
![]()
此时好像可以将\n换成\r,但是换成/r后,什么都没显示,为什么呢?
因为没有换行,也就没有刷新,不会输出,并且每次写入缓冲区后,都有\r,下次在写入缓冲区会将上一次写入缓冲区的覆盖掉。最后while结束时,缓冲区只有1个0,等到程序结束这个0才会被输出,但是注意,此时缓冲区的光标是在0前面的,因为printf输出0后又立马执行了\r,让光标回退到0的前面。所以程序结束后,输出0,因为缓冲区中光标是在0前面的,所以Xshell的命令行直接将0覆盖了,看起来的效果就是什么都没输出。前面printf("hello world")没有换行最后能够输出,并且Xshell命令行在其后面是因为printf向缓冲区写入hello world后,光标是在d的后面,Xshell命令就是从光标开始写的。
此时可以在最后面加一个换行,来查看是否有输出0

前面是什么都没有的,只在结束时才输出了一个0。在执行完while后,与上面是一样的,缓冲区中只有1个0,并且光标在0的前面,执行换行后,清空缓冲区将0输出了出来,并让缓冲区的光标移动到了下一行,这样Xshell的命令行就会在下一行打印,从而不会覆盖掉0
我们在printf后面加一个fflush,让其实时刷新,就可以看到倒计时的效果了

此时前面是有倒计时的,只不过结束时0被覆盖掉了,我们可以在最后面加一个换行,防止0被覆盖

注意:我们使用fflush刷新了缓冲区,但是缓冲区的光标是不会有变化的,若想要缓冲区的光标在不加入东西时有变化,只能使用\r或\n

像这里我们向缓冲区中写入东西后,不回车,即使刷新了缓冲区,将缓冲区的内容输出了,但是光标还是一直正常向后移动的,所以结构是9876543210
我们现在完成了从9向下的倒计时小程序,9到0位数都是相同的,我们看看我们的程序从10到0的倒计时,此时有位数变化

此时会发现程序的运行结果是不正常的。类型的概念只有语言上有,显示器上就是一个一个的字符。printf是格式化输出,格式化输出的意思就是将输出的东西都当成一个一个的字符。因为10是两个字符,放到缓冲区后回退到1的前面,后面的数字都只有1个字符,只会覆盖掉10的第1个字符,0永远不会被覆盖,也就一直保留着。
此时可以使用"%2d"来输出,让每个字符输出时,都占2个字符位,默认是右对齐,而我们想要的是左对齐,可以使用"%-2d"
此时就正常了
5.4 进度条小程序
我们现在要实现一个进度条小程序,这个进度条要预先开好100个字符的空间,进度条程序运行的过程中根据进度从左向右填入#,右边要有进度条进度的百分比,并且还要有|/-\的旋转光标
此次使用3个文件来完成进度条小程序代码的编写,先来完成进度条主体的编写





此时是不理想的,因为进度条应该是在一行的,并且此时也没有预留出100个空位
这里循环是进行了101次,循环结束后bar数组中也确实有101个字符,下标从0到100,但是最终输出的字符串只会有100个字符,因为bar[100]='#'放入后并没有输出![]()
此时效果并不是我们想要的,需要在最后面加上一个回车换行
实际上是需要回车+换行的,但是C/C++中的换行经过了特殊处理,所以只回车即可
此时就是我们想要的了
完善进度条
我们现在在进度条后面加上百分比和旋转光标


此时就完成了
真正的进度条
上面我们实现的进度条实际上只是呈现了一个进度条的效果,函数一调用直接从0到100,没办法与下载、加载等关联起来,所以我们现在要来实现一个能够与下载、加载等关联起来的进度条。此时不与上面一样使用旋转光标,而是采用5个.

我们可以在main.c中模拟一个下载程序,这里使用随机数主要是为了模拟网络波动

我们这里规定的是每前进百分之1的进度就添加一个#,如果想每前进百分之2进度添加一个#,可以将for循环中的i++改成i+=2
这里为了能够在for中定义变量i,需要gcc加上-std=c99,因为这是C99标准才允许的

现在运行这个程序是会有关于usleep的警告,但是没关系,仍然可以正常生成可执行程序
现在在进度条后面加上几个点,这样当下载很缓慢,但是仍然有在下载是能够通过此判断程序仍然在运行
这里需要给进度条后面的百分比预留一个位置,因为100%和99%的位数是不同的,增加到100%时若是突然向后一位,会覆盖到一个.
此时是有问题的
现在只有最先开始会从1个点到5个点,点满了之后没有更新。这种情况就是因为满了5个点后,假设整个进度条的长度是125,现在又回到了120个字符,后面5个字符仍然在哪里,实际上更新了,但是看起来是没有更新的,此时可以在任何情况下都输出125个字符
此时就正常了
我们可以像下面这样子,让current一直不变,进度条就一直不动,但是5个.就会一直变化
我们可以将download的参数写成一个函数指针,这样只要下载规则一样,进度条类似的可以应用与多个函数


6、git
6.1 版本控制
git可以用来进行版本控制。git是一个软件,可以使用git在云服务器上建一个代码仓库,再将其克隆到本地,这样就可对本地的数据与服务器上的数据进行同步。gitee和github都是基于git搭建的网站。
版本管理是在本地进行的,然后将其同步到远端仓库上去。
6.2 创建仓库
我们现在在gitee上创建一个代码仓库,然后将其分别克隆到windows和linux下,也就是在windows和linux下都与这个远端仓库进行关联
一定要初始化仓库
Readme文件是让文档拥有说明。Issue模板文件和Pull Request模板文件均与多人协作有关。
创建出来后,仓库里面就有了3个文件,README.en.md和README.md均为说明文档
Linux

复制这个链接,然后在linux下使用git clone + 链接即可将远端仓库克隆到本地
详细看一下本地仓库中都有一些什么,里面主要就是一个目录和普通文件
我们现在已经将远端仓库克隆到本地仓库了,现在试着通过本地仓库,像远端仓库传入文件,此时需要3步操作,也称为三板斧
我们现在在目录test_git下创建了一个代码文件,注意,此时并没有将其放到本地仓库,更不用说将其传输到远端仓库了,本地仓库是test_git里面的.git
我们此时可以使用git status来查看当前的仓库与远端仓库是否有变化
发现会提示多了一个test.c,并且提示可以使用git add + 文件
现在正式来将文件传输到代码仓库
git add

git add后,文件就放到了.git的暂存区中,也就是.git里面的index
此时再git status,会提示若想放弃提交,可以使用git reset HEAD + 文件,将文件清除出暂存区
git commit

git commit是将文件从本地仓库的暂存区,转存到本地仓库的objects中,此时才能算真正的将文件上传到了本地仓库,并且上传成功时都会生成一个文件id,可以通过这个文件id到.git的objects目录下找到文件的提交记录
提交信息会被保存在.git的logs中,可以通过git logs来查看提交信息
git push
![]()
再使用git push,并输入gitee的账号和密码,即可将本地仓库与远端仓库进行同步,此时就能将本地仓库多出来的文件上传到远端仓库了
可以看到,此时远端仓库上就有了test.c
若上传时想忽略掉某些文件,可将后缀放到,gitignore中
.gitignore中就是一些后缀,上传这些文件时,会自动忽略
Windows
在终端输入与linux下一样的命令即可将远端仓库克隆到本地

这里上传操作与linux下类似,就不过多赘述了
我们现在在windows下向远端仓库上传一个文件

此时远端仓库就有了这个文件了
我们现在试一下再使用linux提交
会发现此时提交失败了,这是为什么呢?
因为远端仓库与linux的本地仓库不同步。我们在windows下上传了一个文件到远端仓库,导致远端仓库比linux下的本地仓库多了一个文件。而当远端仓库与本地仓库不同步时,是不允许从本地仓库往远端仓库上传文件的。
此时我们可以使用git pull,来拉取远端仓库的内容
拉取后,会发现当前目录下就多了一个从windows上传的test.cpp,此时再git pull上传即可成功
在windows下,同样也可以使用git pull来拉取远端仓库的内容
假设我们现在在windows下和linux下对远端仓库中的同一份代码进行了修改,windows先提交,linux后提交,linux肯定会提交失败,我们现在要看一下,在linux下git pull后,文件会有什么变化
我们对code.c文件进行修改



提交失败后,我们进行了pull
git pull后会将windows和linux的修改拼接在一起,会有一些特殊字符,需要程序员自己修改,自己来拼接两部分
修改好code.c后push上传,若windows要再上传,仍然需要再pull一次
7、Linux调试器-gdb
7.1 debug与release
要进行调试,发布版本一定要是debug,release版本再编译时会取消调试信息,而debug会添加调试信息。gcc/g++编译形成的可执行程序默认是release的,若想要生成debug版本,需要加-g选项
我们写一个程序来进行验证




我们会发现myexe-debug的大小比myexe大,这是因为myexe-debug中添加了调试信息。我们还可以使用readelf来读取可执行程序中的管理信息。
会发现myexe中没有与debug相关的字段,而myexe-debug中有。这些含义debug字段的就是调试信息。
7.2 调试命令
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
list/l 函数名:列出某个函数的源代码。
r或run:运行程序。
n 或 next:单条执行。
s或step:进入函数调用
break(b) 行号:在某一行设置断点break 函数名:在某个函数开头设置断点
info break :查看断点信息。
finish:执行到当前函数返回,然后挺下来等待命令
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数
p 变量:打印变量值。
set var:修改变量的值
continue(或c):从当前位置开始连续而非单步执行程序
run(或r):从开始连续而非单步执行程序
delete breakpoints:删除所有断点
delete breakpoints n:删除序号为n的断点
disable breakpoints:禁用断点
enable breakpoints:启用断点
info(或i) breakpoints:参看当前设置了哪些断点
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
undisplay:取消对先前设置的那些变量的跟踪
until X行号:跳至X行
breaktrace(或bt):查看各级函数调用及参数info(i) locals:查看当前栈帧局部变量的值
quit:退出gdb
接下来就逐个看这些命令
l命令






r命令
直接让程序跑完,类似于vs中的F5
b命令
类似于vs中的F9
可以看到每一个断点信息的最前面都有一个Num,称为断点编号
给函数打断点时,是在函数的第一行打上断点,像上面的Sum在第3行,但实际上会打到第5行
c命令
从1个断点跳转到下一个断点
d命令

我们此时将1、2、3号断点都删掉,再打上新的断点会发现新的断点的断点编号是从4开始的。在一个调试周期下,断点编号是线性递增的。
打上断点后,执行r,程序就会停在断点处,可以使用info b来查看断点被命中的次数
可以使用enable或disable + 断点编号来启用或禁用断点
disable禁用断点后,断点还在,只是程序运行时并不会停下来
n命令
n命令是单行执行,类似于vs中的F10,是逐过程,遇到函数并不会进去
当我们使用r来运行程序,遇到断点停下后,再按r不会向后走,而是会被提问是否需要重新启动,此时可以使用n来运行下一步。并且执行一次n后,若想再继续向后走,可以什么都不输入,直接回车,这也是前面的gdb会记录最新的一条命令。
s命令
s命令是单行执行,类似于vs中的F11,是逐语句,遇到函数会进去
bt命令
查看此时的栈帧
我们此时在Sum函数中打了一个断点,r后此时停留在Sum函数中,bt后即可看到两层栈帧
调试到某一位置时仍然是可以使用l来查看代码的
display命令与undisplay命令
display是常显示某一个变量,相当于vs中的监视窗口
常显示的变量也是有编号的
可以使用undisplay + 编号来取消某一个变量的常显示
display不仅可以查看变量的值,还可以查看变量的地址
p命令
若现在不想常显示,但是想查看一下某一变量的值,此时可以使用p
p不仅可以用来打印变量,也可以用来打印运算结果
until命令
until是允许跳转到任意一行的命令
像这里我们通过断点停留在了Sum函数中,但是Sum中有一个for循环,一步一步调试可能要很久,我们就可以直接一个until,跳转到for循环结束的位置,注意:跳转时中间的命令都是会执行的
finish命令
将当前所处的函数跑完
info locals命令
显示当前临时变量的值
watch命令
执行时监视一个表达式(如变量)的值。如果监视的表达式在程序运行期间的值发生了变化,gdb就会暂停程序的执行,并通知使用者
watch就是给变量打断点,只是这个断点与前面给某一行打的断点不一样,不是运行到哪里就停下,而是当变量的值发生变化时暂停程序,并通知使用者。
set var命令
运行时,修改变量的值
可以让我们在发现问题时,立刻解决并验证
有了这些命令后,gdb与vs中调试的功能已经差不多了,但是,gdb的缺点是无法在调试的过程中看到代码。此时可以使用cgdb,这样就能一边调试一边查看代码了。
7.3 cgdb

cgdb会将终端分屏,操作与gdb类似
7.4 条件断点
条件断点就是满足一定条件时才会暂停程序的断点
新增条件断点有两种方式:1. 新增一个条件断点 2. 给已有断点增加条件
新增条件断点:b + 行数/函数 + if + 条件
给已有断点增加条件:condition + 断点编号 + 条件
无论时watch,还是条件断点,本质都是断点,删除时直接d + 编号即可