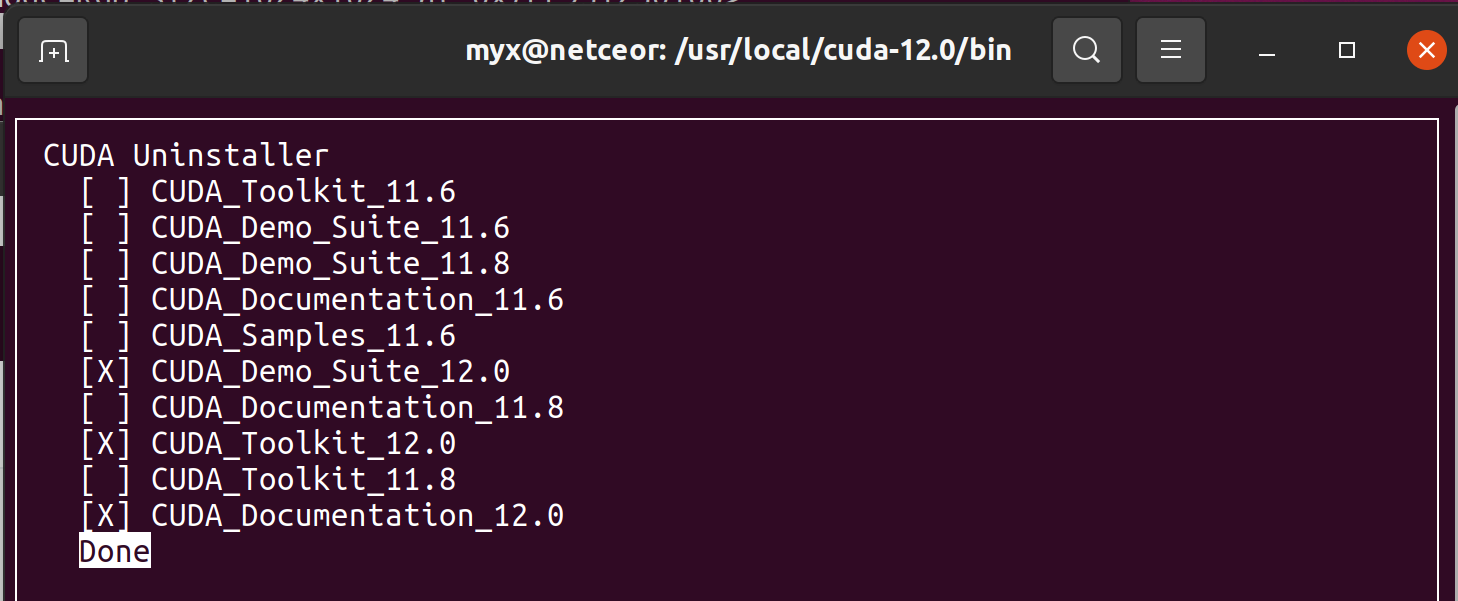
快速排序法

递归法
霍尔版本(左右指针法)
1.思路
1、选出一个key,一般是最左边或是最右边的。
2、定义一个begin和一个end,begin从左向右走,end从右向左走。(需要注意的是:若选择最左边的数据作为key,则需要end先走;若选择最右边的数据作为key,则需要bengin先走)。
3、在走的过程中,若end遇到小于key的数,则停下,begin开始走,直到begin遇到一个大于key的数时,将begin和right的内容交换,end再次开始走,如此进行下去,直到begin和end最终相遇,此时将相遇点的内容与key交换即可。(选取最左边的值作为key)
4.此时key的左边都是小于key的数,key的右边都是大于key的数
5.将key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作,此时此部分已有序
📝tip1

- 常选左为key,那右边先走。
📝优化一:选key的常见三种方法
-
1.三数取中(比较推荐)
- 三数取中 left mid right
- 大小居中的值,也就是不是最大也不是最小的
-
2.随机取一个
-
3.取中间位置
//关于选kevi——三数取中,作为kevi(比较好)
int Getmid(int* arr, int left, int right)
{
//方法1:三数取中
//left mid right
//找到三者——中间值的下标,返回
int mid = (left + right) / 2;
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{
return mid;
}
else if(arr[right]<arr[mid])
{
return right;
}
else
{
return left;
}
}
else //此时已经arr[left]>arr[mid]
{
if (arr[right] < arr[mid])
{
return mid;
}
else if (arr[left] < arr[right])
{
return left;
}
else
{
return right;
}
}
}
//方法2:随机取一个(还行)
int GetRand(int* arr, int left, int right)
{
srand((size_t)time(NULL));
return rand() % (right-left+1)+left;
}
//方法3:取中间位置
int GetMid(int* arr, int left, int right)
{
return (left + right) / 2;
}
📝优化二:小区间优化
优化小数组的交换,就是为了解决大才小用问题
原因:对于很小和部分有序的数组,快排不如插排好。当待排序序列的长度分割到一定大小后,继续分割的效率比插入排序要差,此时可以使用插排而不是快排
截止范围:待排序序列长度N = 10,虽然在5~20之间任一截止范围都有可能产生类似的结果,这种做法也避免了一些有害的退化情形。
if (right - left + 1 < 10)
{
InsertSort(a + left, right - left + 1); //使用插入排序
return;
}
2.图解
单趟动图:

3.代码
代码如下:
//hoare(霍尔)版本(左右指针法)
#include<stdio.h>
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void QuickSort(int* arr,int left,int right)
{
//递归终止条件
if (left >= right)
return;
//记录一下,因为后面要变化
int begin=left;
int end=right;
//选左边为key
int mid = Getmid(arr, left, right); //三数取中
Swap(&arr[mid],&arr[left]); //把找到的,移到最左边
int kevi = left;
while (left < right)
{
//右先走
// 注意:left<right
//right,找小
while (left < right &&arr[right] >= arr[kevi])
{
right--;
}
//left找大
while (left < right && arr[left]<= arr[kevi])
{
left++;
}
//交换(大和小的)
Swap(&arr[left], &arr[right]);
}
//交换key和相遇点
Swap(&arr[kevi], &arr[right]);
kevi = right; //更新kevi
//递归
// 右边大于kevi 左边小于kevi
//此时[begin,kevi) kevi [kevi+1,end]
QuickSort(arr, begin,kevi-1);
QuickSort(arr, kevi+1,end);
}
运行结果:

挖坑法
1.思路
- 选key,左边为key(坑)
- 右边先走,找小(小于key),找到把值放key(坑里),此时right变新坑
- 左边后走,找大(大于key),找到把值放key(坑里),此时left变新坑。
- 一直相遇,把一开始key的值放相遇点
- 递归下去
2.图解

3.代码
//挖坑法
void QuickSort_keng(int* arr,int begin,int end)
{
//递归结束
if (begin >= end)
return;
//
int left = begin;
int right = end;
int mid = Getmid(arr, left, right); //三数取中
Swap(&arr[mid], &arr[left]); //换过来
int kevi = arr[left]; //设置开始的坑位,保存key的值
int keng = left; //记录坑位的位置
while (left < right)
{
//right 找小
while (left<right&&arr[right] >= kevi)
{
right--;
}
Swap(&arr[right], &arr[keng]); //交换,right位置变成新的坑位
keng = right;
//left找大
while (left < right && arr[left] <= kevi)
{
left++;
}
Swap(&arr[left], &arr[keng]); //交换,left位置变成新的坑位
keng = left;
}
//最终把kevi放keng位置(相遇点)
arr[keng] = kevi;
//递归
QuickSort_keng(arr,begin,keng-1);
QuickSort_keng(arr, keng+1, end);
}

前后指针法
1.思路
- 1、选出一个key,一般是最左边或是最右边的。
- 2、起始时,prev指针指向序列开头,cur指针指向prev+1(前后指针)。
- 3、若cur指向的内容小于key,则prev先向后移动一位,然后交换prev和cur指针指向的内容,然后cur指针++;
- 4、若cur指向的内容大于key,则cur指针直接++。如此进行下去,直到cur到达end位置,此时将key和++prev指针指向的内容交换即可。
经过一次单趟排序,最终也能使得key左边的数据全部都小于key,key右边的数据全部都大于key。
然后也还是将key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作
2.图解

3.代码
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//前后指针版本
void QuickSort_prev(int* arr, int begin, int end)
{
//递归结束
if (begin >= end) return;
记录区间范围
int left =begin;
int right = end;
int kevi = left; //记录key的下标
//前后指针
int prev =left;
int cur = left + 1;
while (cur <= right)
{
if (arr[cur] < arr[kevi] && ++prev != cur)
{
//把小的交换到前面
Swap(&arr[cur],&arr[prev]);
}
cur++;
}
//cur越界了,交换kevi和prev
Swap(&arr[kevi], &arr[prev]);
kevi = prev;
//递归
QuickSort_prev(arr, left, kevi - 1);
QuickSort_prev(arr, kevi + 1, right);
}
非递归法
1.思路
-
使用stack来存储待处理的区间,先入栈的是右端点,然后是左端点。
-
在while循环中,只要栈不为空,就继续处理。
-
每次从栈中弹出两个元素,分别代表当前处理区间的左右端点。
-
执行一趟快速排序的划分操作,使用kevi作为基准元素的索引,prev用于记录小于基准元素的最后一个元素的位置。
-
在while循环中,cur遍历当前区间,如果发现比基准元素小的元素,则将其与prev位置的元素交换。
-
划分完成后,将基准元素与prev位置的元素交换,确保基准元素位于中间位置。
-
检查新的区间是否需要继续排序,如果需要,则将新的区间端点压入栈中。
-
重复步骤2-7,直到栈为空,这意味着所有元素都已经被排序。
2.图解

3.代码
这里得单趟,我套用了前面 前后指针的方法
//非递归
void QuickSort_None(int* arr, int begin, int end)
{
stack<int> st; //栈
//先入右,后入左
st.push(end);
st.push(begin);
//不为空
while (!st.empty())
{
//出栈区间,开始一趟
int left = st.top();
st.pop();
int right = st.top();
st.pop();
//走单趟
int kevi = left;
int prev = left;
int cur = left+1;
while (cur <= right)
{
//把小的换到前面
if (arr[cur] < arr[kevi] && ++prev != cur)
{
Swap(&arr[prev], &arr[cur]);
}
++cur;
}
//把kevi换到相遇点
Swap(&arr[kevi],&arr[prev]);
kevi = prev;
//入栈新区间-先右后左
// [begin,kevi-1] kevi [kevi+1,end]
if (kevi + 1 < right)
{
st.push(end); //先右后左
st.push(kevi+1);
}
if (left<kevi-1)
{
st.push(kevi-1); // 先右后左
st.push(left);
}
}
}
算法性能

1.时间复杂度

2.空间复杂度

3.稳定性
不稳定
下面2 2 1 的例子,两个2相对位置发生变化