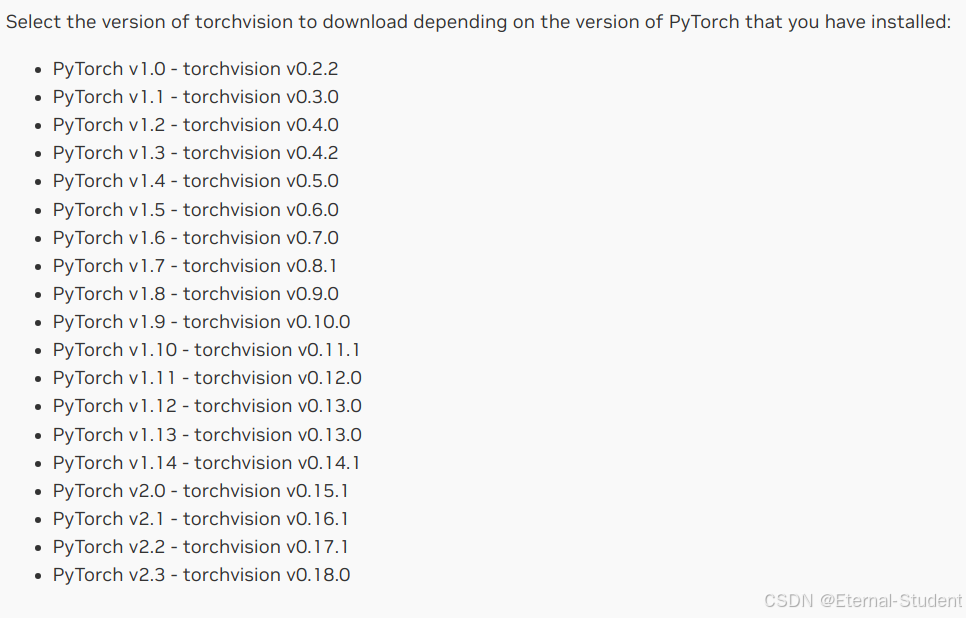
2.2 hadoop运行环境的搭建
2.2.1 环境准备
1)安装模板虚拟机,IP地址 192.168.10.100,主机名hadoop100,内存41GB,硬盘50GB
2)虚拟机配置
首先测试虚拟机是否可以正常上网,测试方法ping www.baidu.com

3)安装epel-release
注:Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于是一个软件仓库,大多数rpm包在官方 repository 中是找不到的)
yum install -y epel-release安装出现问题的解决方法https://blog.csdn.net/m0_62569064/article/details/142967108?sharetype=blogdetail&sharerId=142967108&sharerefer=PC&sharesource=m0_62569064&spm=1011.2480.3001.8118
4)如果Linux 是安装的最小系统版本,还需要安装net-tools,vim
yum install -y net-tools yum install -y vim5)关闭防火墙,关闭防火墙开机自启
#关闭防火墙
systemctl stop firewalld systemctl disable firewalld.service注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安全的防火墙
6)如果没有atguigu用户的话,创建atguigu用户,并修改atguigu用户的密码
useradd atguigu passwd atguigu7)给atguigu账号root 的权限
vim /etc/sudoers在最后加一句

然后保存后退出,退出root
exit移动到/opt目录下,创建module和software两个目录
cp /opt sudo mkdir module sudo mkdir software sudo chown atguigu:atguigu module/ software/
8)卸载自带的jdk
我们先来查看一下,我们的虚拟机中是否安装了jdk
rpm -qa | grep -i Java
rpm -qa | grep -i Java | xargs -n1 rpm -e --nodeps
rpm -qa:查询安装的所有的rpm软件包
grep-i:忽略大小写
xargs-n1:表示每次只传递一个参数
rpm-e -nodeps:强制卸载软件

然后重启虚拟机
reboot2.2.2 克隆虚拟机
首先给虚拟机关机

然后进行克隆就可以了





然后就完成安装了
修改克隆机IP
#修改本机的ip 就是把192.168.10.100改成192.168.10.102
vim /etc/sysconfig/network-scripts/ifcfg-ens33
#修改主机名称
vim /etc/hostname
#查看主机映射
vim /etc/hosts
#重启虚拟机
reboot103和104和以上的修改方式一样
配置完三台虚拟机后,再在每台虚拟机上检测一下是否修改成功
#查看ip
ifconfig
#查看主机名
hostname
#ping一下外网
ping www.baidu.com然后用远程连接工具进行连接
2.2.3 安装JDK
首先准备好安装在Linux系统上的jdk的压缩包,然后把压缩包传到虚拟机的 /opt/software/的目录下,如果是用X-Shell连接就用Xftp传输,我用的是MobaXterm旁边有可视化界面可以直接传。
然后解压到/opt/module/的目录下
#解压 tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module
查看是否解压完成,解压到指定位置
cd /opt/module
ll配置环境变量
cd jdk1.8.0_212/
sudo vim /etc/profile其中有一段代码

这段代码就是遍历/etc/profile.d下的所有的以.sh结尾的文件
cd /etc/profile.d
ll
里面一堆.sh结尾的文件
然后自己创建一个
sudo vim my_env.sh
编辑文件中的内容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
然后重新加载一下
source /etc/profile java -version
成功安装好了
2.2.4 安装hadoop
和上面的步骤差不多,都是解压,配置环境变量之类的,把你的Hadoop的安装包传上去
#解压 tar -zxvf "hadoop安装包" -C "解压的目录下"
#配置环境变量 cd /opt/module cd "hadoop的文件夹下"
sudo vim /etc/profile.d/my_env.sh
source /etc/profile hadoop
看一下Hadoop里面有哪些内容

其中的bin目录下有好多命令

我们经常会用到的有
hdfs:与hdfs存储相关的命令
mapred:计算相关的命令
yarn:资源调度相关的命令
进入etc下

include中都是一些缓存文件
然后就是lib库,就是本地动态链接库,后面的除了sbin几乎就用不到了
sbin中

start-dfs.sh是启动集群的一个命令
start-yarn.sh是启动一个资源调度器的一个命令
mr-jobhistory-daemon.sh启动历史服务器的一个命令
hadoop-daemon.sh单节点
然后就是最后一个share分享,里面都是大量的学习资料,各种说明文档,然后我们进入到share中的hadoop中的mapreduce,里面提供一些官方提供的一些案例,方便后续进行一个使用。
总之,以后经常使用的就是bin etc sbin





![[含文档+PPT+源码等]精品基于springboot实现的原生微信小程序小型电子拍卖系统](https://img-blog.csdnimg.cn/img_convert/939632b93fe2eced86f271a1979715e5.jpeg)