目录
一,深度学习模型量化概述
1.1 模型量化定义
1.2 模型量化的方案
1.3,量化的分类
1.4 模型量化好处
总结:
二,常用量化框架
2.1 OpenVINO NCCF
OpenVINO NCCF量化流程
OpenVINO NCCF量化优势
2.2 TensorRT量化框架
TensorRT量化的基本概念
TensorRT量化的目标
TensorRT量化的实现方式
TensorRT量化的校准方法
2.3 PyTorch(torch.quantization)
训练后量化
1). 训练后动态量化
2). 训练后静态量化
3). 量化感知训练(QAT)
三,总结
四,参考文章:
文末领福利
一,深度学习模型量化概述
深度学习模型量化是一项重要的技术,旨在通过减少网络参数的比特宽度(比特宽度是指在特定时间内,数据传输过程中每个比特所占用的时间或空间)来减小模型大小和加速推理过程,同时保持模型性能,以便将模型部署到边缘或低算力设备上,实现降低成本、提高效率的目标。
1.1 模型量化定义
模型量化是指将神经网络的浮点算法转换为定点。量化有一些相似的术语,低精度(Low precision)可能是常见的。
-
低精度模型表示模型权重数值格式为 FP16(半精度浮点)或者 INT8(8位的定点整数),但是目前低精度往往就指代 INT8。
-
常规精度模型则一般表示模型权重数值格式为 FP32(32位浮点,单精度)。
-
混合精度(Mixed precision)则在模型中同时使用 FP32 和 FP16 的权重数值格式。FP16 减少了一半的内存大小,但有些参数或操作符必须采用 FP32 格式才能保持准确度。
1.2 模型量化的方案
在实践中将浮点模型转为量化模型的方法有以下三种方法:
data free:不使用校准集,传统的方法直接将浮点参数转化成量化数,使用上非常简单,但是一般会带来很大的精度损失,但是高通最新的论文 DFQ 不使用校准集也得到了很高的精度。
calibration:基于校准集方案,通过输入少量真实数据进行统计分析。很多芯片厂商都提供这样的功能,如 tensorRT、高通、海思、地平线、寒武纪
finetune:基于训练 finetune 的方案,将量化误差在训练时仿真建模,调整权重使其更适合量化。好处是能带来更大的精度提升,缺点是要修改模型训练代码,开发周期较长。
TensorFlow 框架按照量化阶段的不同,其模型量化功能分为以下两种:
-
QAT(Quantization-aware training) 训练时量化,伪量化,在线量化。
-
PTQ(Post-training quantization)训练后量化、离线量化;
PTQ(Post Training Quantization) 是训练后量化,也叫做离线量化,根据量化零点x0 是否为 0,训练后量化分为对称量化和非对称量化;根据数据通道顺序 NHWC(TensorFlow) 这一维度区分,训练后量化又分为逐层量化和逐通道量化。目前 nvidia 的 TensorRT 框架中使用了逐层量化的方法,每一层采用同一个阈值来进行量化。逐通道量化就是对每一层每个通道都有各自的阈值,对精度可以有一个很好的提升。
1.3,量化的分类
目前已知的加快推理速度概率较大的量化方法主要有:
二值化,其可以用简单的位运算来同时计算大量的数。对比从 nvdia gpu 到 x86 平台,1bit 计算分别有 5 到128倍的理论性能提升。且其只会引入一个额外的量化操作,该操作可以享受到 SIMD(单指令多数据流)的加速收益。
线性量化(最常见),又可细分为非对称,对称和 ristretto 几种。在 nvdia gpu,x86、arm 和 部分 AI 芯片平台上,均支持 8bit 的计算,效率提升从 1 倍到 16 倍不等,其中 tensor core 甚至支持 4bit计算,这也是非常有潜力的方向。线性量化引入的额外量化/反量化计算都是标准的向量操作,因此也可以使用 SIMD 进行加速,带来的额外计算耗时不大。
对数量化,一种比较特殊的量化方法。两个同底的幂指数进行相乘,那么等价于其指数相加,降低了计算强度。同时加法也被转变为索引计算。目前 nvdia gpu,x86、arm 三大平台上没有实现对数量化的加速库,但是目前已知海思 351X 系列芯片上使用了对数量化。
1.4 模型量化好处
加快推理速度,访问一次 32 位浮点型可以访问四次 int8 整型,整型运算比浮点型运算更快;CPU 用 int8 计算的速度更快。
某些硬件加速器如 DSP/NPU 只支持 int8。比如有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。
总结:
模型量化主要意义就是加快模型端侧的推理速度,并降低设备功耗和减少存储空间。
工业界一般只使用 INT8 量化模型,如 NCNN、TNN 等移动端模型推理框架都支持模型的 INT8 量化和量化模型的推理功能。
通常,可以根据 FP32 和 INT8 的转换机制对量化模型推理方案进行分类。一些框架简单地引入了 Quantize 和 Dequantize 层,当从卷积或全链接层送入或取出时,它将 FP32 转换为 INT8 或相反。在这种情况下,如下图的上半部分所示,模型本身和输入/输出采用 FP32 格式。深度学习推理框架加载模型时,重写网络以插入 Quantize 和 Dequantize 层,并将权重转换为 INT8 格式。
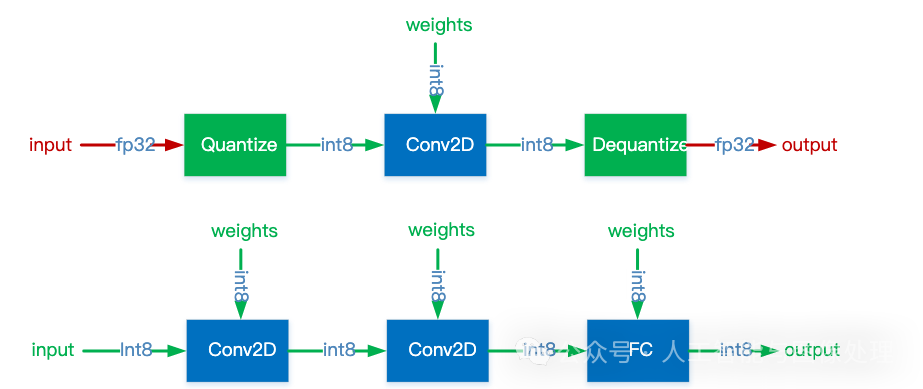
图一:混合 FP32/INT8 和纯 INT8 推理。红色为 FP32,绿色为 INT8 或量化
注意,之所以要插入反量化层(Dequantize),是因为量化技术的早期,只有卷积算子支持量化,但实际网络中还包含其他算子,而其他算子又只支持 FP32 计算,因此需要把 INT8 转换成 FP32。但随着技术的迭代,后期估计会逐步改善乃至消除 Dequantize 操作,达成全网络的量化运行,而不是部分算子量化运行。其他一些框架将网络整体转换为 INT8 格式,因此在推理期间没有格式转换,如上图的下半部分。该方法要求算子(Operator)都支持量化,因为运算符之间的数据流是 INT8。对于尚未支持的那些,它可能会回落到 Quantize/Dequantize 方案。
二,常用量化框架
当前工业界常用的主流量化工具与框架主要有以下三种!
2.1 OpenVINO NCCF
OpenVINO NCCF(Neural Network Compression Framework)量化框架是OpenVINO工具套件中的一个重要组成部分,旨在帮助开发者通过量化技术优化深度学习模型的性能。OpenVINO NCCF是一个用于深度学习模型压缩的框架,它提供了多种压缩算法,包括量化、剪枝、蒸馏等,以帮助开发者减小模型大小、提高推理速度和降低功耗。量化作为其中的一种重要技术,通过将模型中的浮点数参数转换为整数,实现了模型的压缩和加速。
OpenVINO NCCF量化流程
OpenVINO NCCF量化流程通常包括以下几个步骤:
-
模型准备:首先,需要有一个训练好的深度学习模型,该模型可以是PyTorch、TensorFlow等框架下的模型。
-
模型转换:将训练好的模型转换为OpenVINO的中间表示(IR)格式。这一步是可选的,但转换为IR格式可以更好地利用OpenVINO的优化功能。
-
量化配置:配置量化参数,包括量化精度(如INT8、FP16等)、量化策略(如对称量化、非对称量化等)以及量化目标设备(如CPU、GPU等)。
-
量化执行:使用OpenVINO NCCF提供的量化工具或API对模型进行量化。这一步通常包括前向传播以收集统计信息、计算量化参数以及应用量化参数到模型权重和激活中。
-
模型评估:对量化后的模型进行评估,以验证量化对模型精度的影响。如果精度损失在可接受范围内,则可以继续使用量化后的模型;否则,需要调整量化参数并重新执行量化。
-
模型部署:将量化后的模型部署到目标设备上,进行实际的推理任务。
OpenVINO NCCF量化优势
-
高精度保持:OpenVINO NCCF提供了多种量化策略和算法,可以帮助开发者在保持模型精度的同时实现显著的压缩和加速。
-
多硬件支持:OpenVINO NCCF支持多种硬件平台,包括Intel CPU、GPU、FPGA等,使得量化后的模型可以在不同的硬件上实现高效的推理。
-
易用性:OpenVINO NCCF提供了丰富的API和工具,使得开发者可以轻松地集成和使用量化功能,无需深入了解底层的量化算法和优化技术。
ResNet18的图像分类模型FP32与INT8量化版本推理速度比较:

在OpenVINO的官方文档和社区中,可以找到关于NCCF量化的详细示例和教程。这些示例通常包括模型准备、转换、量化、评估和部署等整个流程,为开发者提供了宝贵的参考和指导。
2.2 TensorRT量化框架
TensorRT量化是深度学习模型优化的一种重要手段,它通过将模型中的参数(如权重)从浮点数(如FP32)转换为整数(如INT8)来减少模型的存储和计算成本,从而达到模型压缩和运算加速的目的。
TensorRT量化的基本概念
NVIDIA的TensorRT是一个高性能的深度学习推理优化器,它支持多种深度学习框架(如TensorFlow、PyTorch等)的模型,并提供了一系列的优化技术,包括量化、层融合、动态张量等,以加速深度学习模型的推理速度。
TensorRT量化的目标
-
减少模型大小:通过量化,可以将模型的参数从浮点数转换为整数,从而显著减少模型的存储需求。
-
加速推理速度:在支持INT8等低精度整数运算的硬件上,使用量化后的模型可以显著提高推理速度。
-
降低功耗:在一些嵌入式或移动设备上,使用量化后的模型可以降低功耗,延长设备的使用时间。
TensorRT量化的实现方式
TensorRT支持多种量化方式,主要包括隐式量化和显式量化两种:
-
隐式量化:在TensorRT的早期版本中,隐式量化是主要的量化方式。它不需要修改模型结构或训练代码,只需要在模型推理过程中使用TensorRT提供的量化工具进行量化。隐式量化通常适用于训练后量化(PTQ)场景。
-
显式量化:从TensorRT 8.0版本开始,显式量化得到了全面支持。显式量化允许在模型训练过程中插入量化指令(如QDQ操作),并在模型推理过程中使用TensorRT进行量化。显式量化可以提供更高的量化精度和更好的性能优化。
TensorRT量化的校准方法
在TensorRT中,量化过程中需要使用校准数据集来确定量化参数(如缩放因子和零点)。TensorRT支持多种校准方法,包括熵校准和最小最大值校准等:
-
熵校准:熵校准是一种动态校准算法,它使用KL散度(KL Divergence)来度量推理数据和校准数据之间的分布差异。在校准过程中,TensorRT会分析每个张量的分布,并选择合适的量化参数以最小化KL散度。
-
最小最大值校准:最小最大值校准使用最小最大值算法来计算量化参数。在校准过程中,TensorRT会统计校准数据中的最小值和最大值,并根据这些值来计算量化参数。
2.3 PyTorch(torch.quantization)
PyTorch的量化支持主要包括三种方式:训练后动态量化(Post Training Dynamic Quantization)、训练后静态量化(Post Training Static Quantization)以及量化感知训练(Quantization Aware Training, QAT)。
训练后量化
1). 训练后动态量化
概述:训练后动态量化是指在模型训练完成后,仅对模型的权重进行量化,而激活(activations)在推理过程中进行量化。这种方式适用于那些对精度要求不是特别高,但需要快速部署的场景。
特点:
-
简单易用:不需要重新训练模型,只需要对训练好的模型进行量化。
-
性能提升:与浮点数模型相比,量化后的模型在推理速度上会有显著提升,同时模型大小也会减小。
示例代码:
import torch from torch import nn from torch.quantization import quantize_dynamicclass DemoModel(nn.Module): def __init__(self): super(DemoModel, self).__init__ self.conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=1) self.relu = nn.ReLU self.fc = nn.Linear(2, 2)def forward(self, x): x = self.conv(x) x = self.relu(x) x = self.fc(x) return xmodel_fp32 = DemoModel model_int8 = quantize_dynamic( model=model_fp32, qconfig_spec={nn.Linear}, # 仅对Linear层进行量化 dtype=torch.qint8 )
2). 训练后静态量化
概述:训练后静态量化是指对模型训练完成后,不仅对权重进行量化,还对激活进行量化。这种方式需要收集一些代表性的数据来标定(calibrate)量化参数,以确保量化后的模型精度尽可能接近原始模型。由于同时量化了权重和激活,因此量化后的模型精度通常比动态量化更高。需要收集代表性的数据来标定量化参数。
示例流程:
-
准备标定数据集。
-
加载并准备模型(设置eval模式,并附加量化配置)。
-
使用标定数据集对模型进行标定,以收集权重和激活的分布信息。
-
将标定后的模型转换为量化模型。
3). 量化感知训练(QAT)
虽然QAT不属于训练后量化的范畴,但它是另一种重要的量化方式,值得提及。QAT是在模型训练过程中插入伪量化模块,模拟量化效应,从而提高模型对量化操作的适应能力。这种方式可以在一定程度上弥补静态量化在精度上的损失。
三,总结
所谓的模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。由于该技术可以极大地缩小模型的大小,提高模型的运行速度,从而满足机器人、手机等嵌入式终端的需求,因而得到了工业界的大量应用。当前比较成熟的模型量化技术主要分为两种,即训练后量化和训练时量化,训练时量化不仅能够达到量化效果,同时还可以获得准确的量化结果。当前的很多深度学习框架中已经将模型量化方法嵌入其中,便于用户的模型部署。除此之外,无论是移动端还是服务器端,都可以看到新的计算设备正不断迎合量化技术,因而量化技术一定会越来越完善,从而进一步推动深度学习模型在低功率、低成本、低性能的终端上面的部署。
四,参考文章:
How to Make Large Language Models Play Nice with Your Software Using LangChain - KDnuggets
福利利领取:

IT类包含:
Java、云原生、GO语音、嵌入式、Linux、物联网、AI人工智能、python、C/C++/C#、软件测试、网络安全、Web前端、网页、大数据、Android大模型多线程、JVM、Spring、MySQL、Redis、Dubbo、中间件…等最全厂牌最新视频教程+源码+软件包+面试必考题和答案详解。
资源目录检索,查;获取+V,CD20230507
https://path.dirts.cn/sfoA5TURw