代码: ollama/ollama: Get up and running with Llama 3.1, Mistral, Gemma 2, and other large language models. (github.com)
官网: Ollama
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
安装
运行以下命令安装 Ollama:
curl -fsSL <https://ollama.com/install.sh> | sh
AMD Radeon GPU 支持
虽然 AMD 已将amdgpu驱动程序贡献给官方 Linux 内核源代码,但版本较旧,可能不支持所有 ROCm 功能。我们建议您从 https://www.amd.com/en/support/linux-drivers 安装最新的驱动程序,以便为您的 Radeon GPU 提供最佳支持。
手动安装
下载ollama二进制文件
Ollama 以独立二进制文件的形式分发。将其下载到 PATH 中的目录中:
sudo curl -L <https://ollama.com/download/ollama-linux-amd64> -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
添加 Ollama 作为启动服务(推荐)
为 Ollama 创建用户:
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
在以下位置创建服务文件 /etc/systemd/system/ollama.service:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
然后启动服务:
sudo systemctl daemon-reload
sudo systemctl enable ollama
安装 CUDA 驱动程序(可选 - 适用于 Nvidia GPU)
下载并安装CUDA:https://developer.nvidia.com/cuda-downloads
通过运行以下命令来验证驱动程序是否已安装,该命令将打印有关 GPU 的详细信息:
nvidia-smi
安装 ROCm(可选 - 适用于 Radeon GPU)
下载并安装:https://rocm.docs.amd.com/projects/install-on-linux/en/latest/tutorial/quick-start.html
确保安装 ROCm v6
启动 Ollama
使用以下方式启动 Ollama systemd:
sudo systemctl start ollama
更新
通过再次运行安装脚本来更新 ollama:
curl -fsSL <https://ollama.com/install.sh> | sh
或者通过下载 ollama 二进制文件:
sudo curl -L <https://ollama.com/download/ollama-linux-amd64> -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
查看日志
要查看作为启动服务运行的 Ollama 的日志,请运行:
journalctl -e -u ollama
卸载
删除 ollama 服务:
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service
从 bin 目录中删除 ollama 二进制文件(/usr/local/bin、/usr/bin或/bin):
sudo rm $(which ollama)
删除下载的模型和 Ollama 服务用户和组:
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
GPU支持状态
Nvidia
Ollama 支持计算能力 5.0 及以上的 Nvidia GPU。
要检查您的显卡是否受支持,请查看您的计算兼容性:https://developer.nvidia.com/cuda-gpus
| Compute Capability | Family | Cards |
| ------------------ | ------------------- | ----------------------------------------------------------------------------------------------------------- |
| 9.0 | NVIDIA | `H100` |
| 8.9 | GeForce RTX 40xx | `RTX 4090` `RTX 4080` `RTX 4070 Ti` `RTX 4060 Ti` |
| | NVIDIA Professional | `L4` `L40` `RTX 6000` |
| 8.6 | GeForce RTX 30xx | `RTX 3090 Ti` `RTX 3090` `RTX 3080 Ti` `RTX 3080` `RTX 3070 Ti` `RTX 3070` `RTX 3060 Ti` `RTX 3060` |
| | NVIDIA Professional | `A40` `RTX A6000` `RTX A5000` `RTX A4000` `RTX A3000` `RTX A2000` `A10` `A16` `A2` |
| 8.0 | NVIDIA | `A100` `A30` |
| 7.5 | GeForce GTX/RTX | `GTX 1650 Ti` `TITAN RTX` `RTX 2080 Ti` `RTX 2080` `RTX 2070` `RTX 2060` |
| | NVIDIA Professional | `T4` `RTX 5000` `RTX 4000` `RTX 3000` `T2000` `T1200` `T1000` `T600` `T500` |
| | Quadro | `RTX 8000` `RTX 6000` `RTX 5000` `RTX 4000` |
| 7.0 | NVIDIA | `TITAN V` `V100` `Quadro GV100` |
| 6.1 | NVIDIA TITAN | `TITAN Xp` `TITAN X` |
| | GeForce GTX | `GTX 1080 Ti` `GTX 1080` `GTX 1070 Ti` `GTX 1070` `GTX 1060` `GTX 1050` |
| | Quadro | `P6000` `P5200` `P4200` `P3200` `P5000` `P4000` `P3000` `P2200` `P2000` `P1000` `P620` `P600` `P500` `P520` |
| | Tesla | `P40` `P4` |
| 6.0 | NVIDIA | `Tesla P100` `Quadro GP100` |
| 5.2 | GeForce GTX | `GTX TITAN X` `GTX 980 Ti` `GTX 980` `GTX 970` `GTX 960` `GTX 950` |
| | Quadro | `M6000 24GB` `M6000` `M5000` `M5500M` `M4000` `M2200` `M2000` `M620` |
| | Tesla | `M60` `M40` |
| 5.0 | GeForce GTX | `GTX 750 Ti` `GTX 750` `NVS 810` |
| | Quadro | `K2200` `K1200` `K620` `M1200` `M520` `M5000M` `M4000M` `M3000M` `M2000M` `M1000M` `K620M` `M600M` `M500M` |
GPU 选择
如果您的系统中有多个 NVIDIA GPU,并且您想限制 Ollama 只使用其中的一部分,您可以设置 CUDA_VISIBLE_DEVICES 为 GPU 的逗号分隔列表。虽然可以使用数字 ID,但由于排序可能会变化,所以使用 UUID 更为可靠。您可以通过运行 nvidia-smi -L 来查找 GPU 的 UUID。如果您想忽略 GPU 并强制使用 CPU,请使用无效的 GPU ID(例如,“-1”)。
笔记本电脑的挂起与恢复
在 Linux 上,经过挂起/恢复周期后,有时 Ollama 可能会无法识别您的 NVIDIA GPU,并改为在 CPU 上运行。您可以通过以下命令重新加载 NVIDIA UVM 驱动来解决这个问题:
sudo rmmod nvidia_uvm && sudo modprobe nvidia_uvm
AMD Radeon
Ollama 支持以下 AMD GPU:
| Family | Cards and accelerators |
| -------------- | ---------------------------------------------------------------------------------------------------------------------------------------------- |
| AMD Radeon RX | `7900 XTX` `7900 XT` `7900 GRE` `7800 XT` `7700 XT` `7600 XT` `7600` `6950 XT` `6900 XTX` `6900XT` `6800 XT` `6800` `Vega 64` `Vega 56` |
| AMD Radeon PRO | `W7900` `W7800` `W7700` `W7600` `W7500` `W6900X` `W6800X Duo` `W6800X` `W6800` `V620` `V420` `V340` `V320` `Vega II Duo` `Vega II` `VII` `SSG` |
| AMD Instinct | `MI300X` `MI300A` `MI300` `MI250X` `MI250` `MI210` `MI200` `MI100` `MI60` `MI50` |
覆盖
Ollama 利用 AMD ROCm 库,但它并不支持所有 AMD GPU。在某些情况下,您可以强制系统尝试使用接近的 LLVM 版本。例如,Radeon RX 5400 是 gfx1034(也称为 10.3.4),但 ROCm 目前不支持此版本。最接近的支持是 gfx1030。您可以通过设置环境变量 HSA_OVERRIDE_GFX_VERSION=“10.3.0”,来尝试在不受支持的 AMD GPU 上运行。如果您有不受支持的 AMD GPU,您可以尝试使用下面列出的支持类型。
目前已知支持的 GPU 类型包括以下 LLVM 版本。此表显示了映射到这些 LLVM 版本的一些示例 GPU:
| LLVM Target | An Example GPU |
|-----------------|---------------------|
| gfx900 | Radeon RX Vega 56 |
| gfx906 | Radeon Instinct MI50 |
| gfx908 | Radeon Instinct MI100 |
| gfx90a | Radeon Instinct MI210 |
| gfx940 | Radeon Instinct MI300 |
| gfx941 | |
| gfx942 | |
| gfx1030 | Radeon PRO V620 |
| gfx1100 | Radeon PRO W7900 |
| gfx1101 | Radeon PRO W7700 |
| gfx1102 | Radeon RX 7600 |
AMD 正在努力通过即将发布的 ROCm v6 增强版来扩大对 GPU 系列的支持,这将增加更多 GPU 的支持。
GPU 选择
如果您的系统中安装了多个 AMD GPU,并且您想限制 Ollama 只使用其中的一部分,您可以将 HIP_VISIBLE_DEVICES 设置为 GPU 的逗号分隔列表。您可以使用 rocminfo 命令查看设备列表。如果您想忽略 GPU 并强制使用 CPU,请使用无效的 GPU ID(例如,“-1”)。
容器权限
在某些 Linux 发行版中,SELinux 可能会阻止容器访问 AMD GPU 设备。您可以在宿主系统上运行 sudo setsebool container_use_devices=1 来允许容器使用设备。
Metal(苹果 GPU)
Ollama 通过 Metal API 支持苹果设备上的 GPU 加速。
最新版本:Tool 调用
为什么我们需要工具调用?
我们需要工具调用的原因是大语言模型通常只能回答到某个时间点之前的问题。这意味着除非它们可以直接访问互联网,否则它们无法获取当前的事件、情况等信息——而大多数模型都做不到这一点。
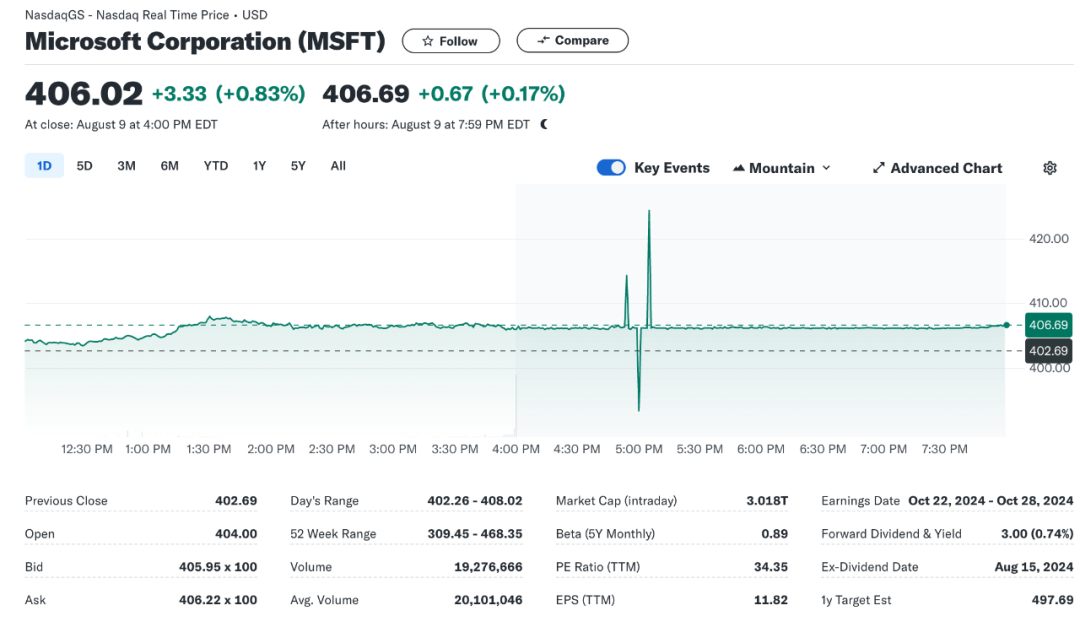
因此,如果你询问一个大语言模型当前巴黎的温度,它是无法告诉你答案的。同样,询问某只特定股票的当前价格也是如此。
>>> what is the current price of MSFT (Microsoft)
As I'm a large language model, I don't have direct access to real-time market data. However, I can suggest some
ways for you to find out the current stock price of Microsoft (MSFT):
1. **Financial websites**: Visit reputable financial websites like:
* Yahoo Finance (finance.yahoo.com)
* Google Finance (finance.google.com)
* Bloomberg (bloomberg.com)
* CNBC (cnbc.com)
2. **Stock market apps**: Use a mobile app like:
* Robinhood
* Fidelity Investments
* eTrade
* TradingView
3. **Direct from the source**: Visit Microsoft's investor relations page (ir.microsoft.com) for real-time stock
data.
As of my knowledge cutoff, the current price of MSFT was around $245-$250 per share. However, please note that
this information may be outdated, and I recommend checking a reliable financial website or app for the most recent
and accurate price.
If you want to get an estimate, here are some historical price ranges:
* 52-week high: around $280
* 52-week low: around $210
Keep in mind that stock prices can fluctuate rapidly due to various market factors. Always consult multiple
sources or a financial advisor for more precise and up-to-date information.
示例代码 —— 查找一只股票的当前价格
我们来看这个问题。
首先,我们需要一个函数来返回一只股票的当前价格。我们可以使用 Yahoo Finance 来实现。
import yfinance as yf
def get_current_stock_price(ticker_symbol):
# Get the stock data
stock = yf.Ticker(ticker_symbol)
# Get the current price
current_price = stock.history(period='1d')['Close'].iloc[0]
return current_price
接下来,将这个函数作为工具告知 Ollama。
import ollama
# Want the current price of Microsoft - ticker symbol MSFT
response = ollama.chat(
model='llama3.1',
messages=[{'role': 'user','content':
'What is the current price of MSFT'}],
# provide a tool to get the current price of a stock
tools=[{
'type': 'function',
'function': {
'name': 'get_current_stock_price',
'description': 'Get the current price for a stock',
'parameters': {
'type': 'object',
'properties': {
'ticker_symbol': {
'type': 'string',
'description': 'The ticker symbol of the stock',
},
},
'required': ['ticker_symbol'],
},
},
},
],
)
print(response['message']['tool_calls'])
动态调用工具。
# Create a dictionary mapping function names to functions
function_map = {
'get_current_stock_price': get_current_stock_price,
# Add more functions here as needed
}
def call_function_safely(response, function_map):
# Extract the function name and arguments from the response
tool_call = response['message']['tool_calls'][0]
function_name = tool_call['function']['name']
arguments = tool_call['function']['arguments']
# Look up the function in the function map
function_to_call = function_map.get(function_name)
if function_to_call:
try:
# Call the function with the arguments
result = function_to_call(**arguments)
print(f"The current price of {arguments['ticker_symbol']} is : {result}")
except TypeError as e:
print(f"Argument error: {e}")
else:
print(f"{function_name} is not a recognized function")
call_function_safely(response, function_map)
这个操作产生了以下结果,
The current price of MSFT is : 427.4599914550781
对我来说,这个结果相当准确了。
Q & A
我怎样才能升级 Ollama?
对于 macOS 和 Windows 用户,Ollama 会自动下载更新。只需点击任务栏或菜单栏的 Ollama 图标,然后选择“重新启动以更新”即可应用更新。当然,您也可以选择手动下载最新版本来进行更新。
如果您使用的是 Linux,只需再次运行安装脚本就可以了:
curl -fsSL <https://ollama.com/install.sh> | sh
如何查看日志?
想了解更多关于如何利用日志的信息,请参阅 Ollama 如何排除故障
我的显卡能用来运行 Ollama 吗?
请查阅 Ollama 对GPU 支持信息
我该如何设置上下文窗口的大小?
Ollama 默认设置的上下文窗口大小为 2048 个词元。
如果您想在使用 Ollama 时更改这一设置,可以使用 /set 参数:
/set parameter num_ctx 4096
如果您通过 API 使用,需要指定 num_ctx 参数:
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3",
"prompt": "Why is the sky blue?",
"options": {
"num_ctx": 4096
}
}'
如何确认模型是否已经加载到 GPU 上?
通过运行 ollama ps 命令,您可以查看哪些模型当前已加载到内存中。
ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3:70b bcfb190ca3a7 42 GB 100% GPU 4 minutes from now
“处理器”列会显示模型加载到的内存类型:
- 100% GPU 表示模型完全加载到 GPU
- 100% CPU 表示模型完全加载到系统内存
- 48%/52% CPU/GPU 表示模型同时部分加载到 GPU 和系统内存
如何配置 Ollama 服务器?
您可以通过设置环境变量来配置 Ollama 服务器。
在 Mac 上设置环境变量
如果您是以 macOS 应用程序的形式运行 Ollama,可以使用 launchctl 设置环境变量:
- 对于每个环境变量,执行 launchctl setenv 命令。
launchctl setenv OLLAMA_HOST "0.0.0.0"
- 之后,重启 Ollama 应用程序。
在 Linux 上设置环境变量
如果 Ollama 以 systemd 服务的形式运行,应通过 systemctl 设置环境变量:
- 编辑 systemd 服务,执行 systemctl edit ollama.service 命令。这会打开一个编辑器。
- 对于每个环境变量,在 [Service] 段落下添加一个 Environment 行:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
- 保存并退出。
- 重新加载 systemd 并重启 Ollama:
systemctl daemon-reload
systemctl restart ollama
在 Windows 上设置环境变量
在 Windows 上,Ollama 会继承您的用户和系统环境变量。
- 首先,通过在任务栏上点击它的图标来退出 Ollama。
- 打开“设置”(Windows 11)或“控制面板”(Windows 10)应用,搜索环境变量。
- 点击“为您的账户编辑环境变量”。
- 为您的用户账户编辑或创建新的变量,比如 OLLAMA_HOST、OLLAMA_MODELS 等。
- 点击 OK/应用 以保存。
- 从 Windows 开始菜单启动 Ollama 应用程序。
如何在代理后使用 Ollama?
如果配置了 HTTP_PROXY 或 HTTPS_PROXY 环境变量,Ollama 就能够兼容代理服务器。使用这些变量时,请确保它们被设置在 Ollama 服务能够访问到的地方。当使用 HTTPS_PROXY 时,请确保代理证书被安装为系统证书。关于如何在您的平台上使用环境变量,请参考上文。
如何在 Docker 中使用代理后的 Ollama?
通过在启动容器时传递 -e HTTPS_PROXY=https://proxy.example.com 参数,可以配置 Ollama Docker 容器映像以使用代理。
另外,也可以配置 Docker 守护进程来使用代理。无论是在 macOS、Windows 还是 Linux 上的 Docker Desktop,还是使用 systemd 的 Docker 守护进程,都有相应的配置说明。
使用 HTTPS 时,请确保将证书安装为系统证书。这可能需要使用自签名证书时创建一个新的 Docker 映像。
FROM ollama/ollama
COPY my-ca.pem /usr/local/share/ca-certificates/my-ca.crt
RUN update-ca-certificates
构建并运行这个映像:
docker build -t ollama-with-ca .
docker run -d -e HTTPS_PROXY=[<https://my.proxy.example.com>](<https://my.proxy.example.com/>) -p 11434:11434 ollama-with-ca
Ollama 是否将我的输入和输出发送回 ollama.com?
不会。Ollama 在本地运行,对话数据不会离开您的设备。
如何在我的网络上暴露 Ollama?
默认情况下,Ollama 绑定到 127.0.0.1 的 11434 端口。您可以通过 OLLAMA_HOST 环境变量来更改绑定地址。
请参考上文,了解如何在您的平台上设置环境变量。
如何使用代理服务器运行 Ollama?
Ollama 运行一个 HTTP 服务器,可以通过如 Nginx 这样的代理服务器来暴露。要做到这一点,请配置代理以转发请求,并在必要时设置所需的头部信息(如果不在网络上暴露 Ollama)。例如,使用 Nginx:
server {
listen 80;
server_name example.com; # Replace with your domain or IP
location / {
proxy_pass <http://localhost:11434>;
proxy_set_header Host localhost:11434;
}
}
如何通过 ngrok 使用 Ollama?
Ollama 可以通过一系列隧道工具进行访问。例如,使用 Ngrok:
ngrok http 11434 --host-header="localhost:11434"
如何使用 Cloudflare Tunnel 运行 Ollama?
要通过 Cloudflare Tunnel 使用 Ollama,请使用 --url 和 --http-host-header 标志:
cloudflared tunnel --url http://localhost:11434 --http-host-header="localhost:11434"
如何允许更多网页源访问 Ollama?
默认情况下,Ollama 允许来自 127.0.0.1 和 0.0.0.0 的跨域请求。可以通过设置 OLLAMA_ORIGINS 环境变量来配置更多的来源。
请参考上文,了解如何在您的平台上设置环境变量。
模型存储在哪里?
- macOS:~/.ollama/models
- Linux:/usr/share/ollama/.ollama/models
- Windows:C:\Users%username%.ollama\models
如何将它们设置到不同的位置?
如果您需要使用不同的目录,请将 OLLAMA_MODELS 环境变量设置为您选择的目录。请参考上文,了解如何在您的平台上设置环境变量。
如何在 Visual Studio Code 中使用 Ollama?
对于 VSCode 以及其他编辑器,已经有大量可利用 Ollama 的插件。请参阅主仓库 readme 文件底部的扩展和插件列表。
如何在 Docker 中使用 GPU 加速运行 Ollama?
Ollama Docker 容器可在 Linux 或 Windows(带有 WSL2)上配置 GPU 加速。这需要 nvidia-container-toolkit。有关更多详情,请参阅 ollama/ollama。
由于 macOS 的 Docker Desktop 缺乏 GPU 穿透和仿真,因此不支持 GPU 加速。
为什么 Windows 10 上的 WSL2 网络缓慢?
这可能会影响安装 Ollama 以及下载模型。
打开控制面板 > 网络和互联网 > 查看网络状态和任务,然后点击左侧面板上的“更改适配器设置”。找到 vEthernel (WSL) 适配器,右键选择属性。点击配置并打开高级标签页。搜索每个属性,直到找到 Large Send Offload Version 2 (IPv4) 和 Large Send Offload Version 2 (IPv6)。禁用这两个属性。
如何预加载模型以加快 Ollama 的响应时间?
如果您使用 API,可以通过向 Ollama 服务器发送空请求来预加载模型,适用于 /api/generate 和 /api/chat API 端点。
使用 generate 端点预加载 mistral 模型,可以使用:
curl <http://localhost:11434/api/generate> -d '{"model": "mistral"}'
要使用 chat completions 端点,可以使用:
curl <http://localhost:11434/api/chat> -d '{"model": "mistral"}'
要通过 CLI 预加载模型,可以使用命令:
ollama run llama3 ""
如何保持模型常驻内存或立即卸载?
默认情况下,模型在内存中保持 5 分钟后会被卸载,以便于在进行多次请求时快速响应。但是,您可能希望在 5 分钟之前释放内存,或者希望模型无限期地保持加载。使用 /api/generate 和 /api/chat API 端点的 keep_alive 参数来控制模型保持在内存中的时间。
keep_alive 参数可以设置为:
- 一个时间字符串(如 “10m” 或 “24h”)
- 秒数(如 3600)
- 任何负数,将使模型保持在内存中加载(例如 -1 或 “-1m”)
- ‘0’,将在生成响应后立即卸载模型
例如,要预加载一个模型并保留它在内存中,请使用:
curl <http://localhost:11434/api/generate> -d '{"model": "llama3", "keep_alive": -1}'
要卸载模型并释放内存,请使用:
curl <http://localhost:11434/api/generate> -d '{"model": "llama3", "keep_alive": 0}'
您还可以通过在启动 Ollama 服务器时设置 OLLAMA_KEEP_ALIVE 环境变量来更改所有模型加载到内存中的时间。OLLAMA_KEEP_ALIVE 变量使用与 keep_alive 参数类型相同的参数类型。参考关于如何配置 Ollama 服务器的部分来正确设置环境变量。
如果您希望覆盖 OLLAMA_KEEP_ALIVE 设置,可以在 /api/generate 或 /api/chat API 端点使用 keep_alive API 参数。
如何管理 Ollama 服务器可以处理的最大请求数?
如果向服务器发送了过多请求,将返回 503 错误,表示服务器过载。您可以通过设置 OLLAMA_MAX_QUEUE 来调整可能排队的请求数量。
Ollama 如何处理并发请求?
Ollama 支持两级并发处理。如果您的系统有足够的可用内存(使用 CPU 推理时的系统内存或 GPU 推理时的 VRAM),则可以同时加载多个模型。对于给定模型,如果在加载模型时有足够的可用内存,它被配置为允许并行处理请求。
如果在已加载一个或多个模型的情况下,没有足够的可用内存来加载新模型请求,则所有新请求将被排队,直到新模型可以被加载。随着先前模型变为空闲,一个或多个将被卸载以腾出空间给新模型。排队的请求将按顺序处理。在使用 GPU 推理时,新模型必须能够完全适应 VRAM 以允许并发模型加载。
对于给定模型的并行请求处理将增加上下文大小,取决于并行请求的数量。例如,2K 上下文与 4 个并行请求将导致 8K 上下文和额外的内存分配。
以下服务器设置可用于调整 Ollama 如何在大多数平台上处理并发请求:
- OLLAMA_MAX_LOADED_MODELS: 可以同时加载的最大模型数量,前提是它们适合可用内存。默认值是 GPU 数量的 3 倍或 CPU 推理的 3。
- OLLAMA_NUM_PARALLEL: 每个模型将同时处理的最大并行请求数量。默认值将根据可用内存自动选择 4 或 1。
- OLLAMA_MAX_QUEUE: Ollama 在繁忙时将排队的最大请求数量。默认值是 512。
注意:由于 ROCm v5.7 在可用 VRAM 报告方面的限制,Windows 上带 Radeon GPU 的默认值当前设置为最大 1 个模型。一旦 ROCm v6 可用,Windows Radeon 将遵循上述默认值。您可以在 Radeon 上启用并发模型加载,但请确保不要加载超过 GPU VRAM 所能容纳的模型数量。