1.导言
论文地址:https://arxiv.org/abs/2404.12520
随着电动汽车(EV)的普及,高峰期的用电需求可能会大幅增加。因此,如何适当控制电动汽车充电并尽量减少高峰期的用电量是一项重要挑战。传统上,基于模型和单一代理的强化学习方法被用于电动汽车充电控制,但它们在处理不确定性、隐私和可扩展性方面面临挑战。
因此,本文提出了一种基于多代理强化学习(MARL)的分布式协调电动汽车充电控制方法。本文对所提出的方法进行了理论分析,并通过数值模拟对其性能进行了评估,结果表明该方法优于集中式方法,而且在有大量电动汽车用户的实际情况下非常有效。
2.相关研究
以往有关电动汽车充电控制的研究大致分为基于模型的强化学习方法和无模型强化学习方法。
2.1 基于模型的方法
- 已提出的方法包括二元优化、混合整数线性规划、稳健优化、随机优化、模型预测控制和动态规划。
- 这些方法都需要精确的系统模型。
2.2 强化学习法
- 单个代理强化学习方法:如深度 Q-learning、贝叶斯神经网络、Advantage Actor-Critic 和 DDPG 已被应用。假定完全可观测,但从隐私角度看不切实际。
- 多代理强化学习方法:一些研究将其用于学习多个电动汽车站和充电运营商的定价策略。然而,许多研究似乎并未考虑代理之间的合作。此外,在某些情况下,也尝试过通过联邦强化学习进行代理间协调,但其前提是每个代理都能观察到整个网络的需求。
在上述研究的基础上,本文的新颖之处在于提出了一种分散式 MARL 方法,这种方法在运行时考虑了合作并保护隐私。
3 . 建议方法
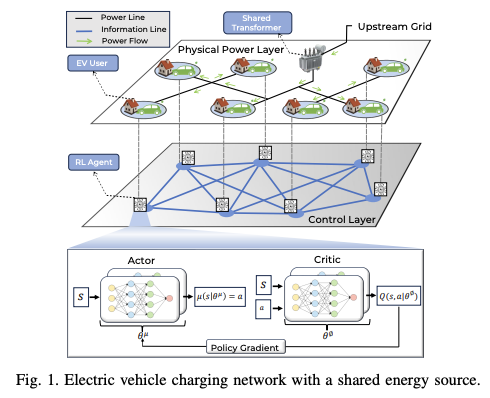
在所提出的方法中,电动汽车网络中的每个电动汽车用户都有一个安装在智能电表上的强化学习代理,如图 1 所示。网络有两层,由物理电源层和控制层组成。
在物理电源层,所有电动汽车通过共享变压器连接到上游电网(公用事业公司)。在控制层,安装在每个电动汽车用户智能电表中的 RL 代理负责根据动态电价和物理层限制(如共享变压器)有效管理和协调电动汽车充电。
作为具体的控制策略,本文提出了两种多代理 DDPG 方法,一种是集中式方法(CTDE-DDPG),另一种是分散式方法(I-DDPG)。
3.1 独立发展集团(I-DDPG)
- 完全分散式方法。
- 每个代理都有自己的代理-批评网络,并将其他代理视为环境的一部分。
- 计算成本低,政策梯度方差小,但容易受到非平稳性的影响。
3.2 集中培训 分散执行 DDPG (CTDE-DDPG)
- 代理之间仅在学习过程中进行合作,在执行过程中进行分布式操作 - 每个代理共享一个集中的价值函数,并集中管理词缀网络 - 代理之间的合作可减轻非平稳性的影响,但计算成本高,策略梯度方差大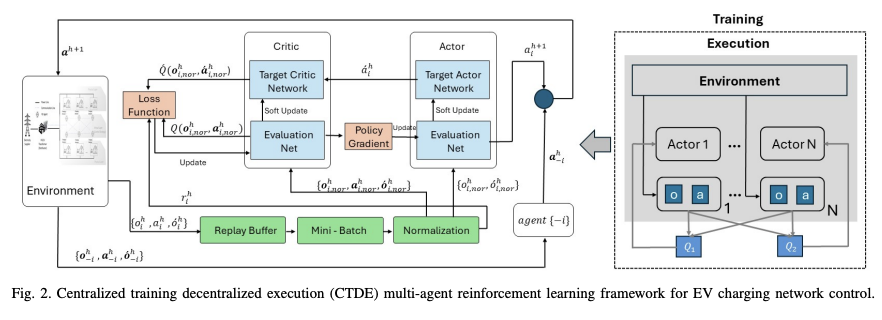
在图 2 所示的 CTDE-DDPG 框架中,代理之间仅在学习阶段共享信息,而每个代理在执行阶段独立运行。在学习阶段,所有代理都能获取所有代理的观察结果和行动,但在执行阶段,它们无法获取此类信息。每个代理都有一个代理-批判网络,在学习阶段,代理根据本地观察结果选择行动,然后由一个集中的价值函数(即共同批判网络)进行评估。另一方面,在运行阶段,行动者是分散的,他们只根据本地信息决定自己的行动。
因此,在 CTDE-DDPG 中,学习过程中的合作可以减轻代理之间的不稳定性,同时在执行过程中保护隐私。而在 I-DDPG 中,代理的学习和执行是相互独立的。
4. 试验
4.1 实验装置
对基于 IEEE 5 巴士系统的电动汽车网络进行了模拟,并对多达 20 个代理(电动汽车用户)的场景进行了评估。充电阶段包括 34 个步骤。表 I 显示了 DDPG 的超参数。
4.2 一般性能
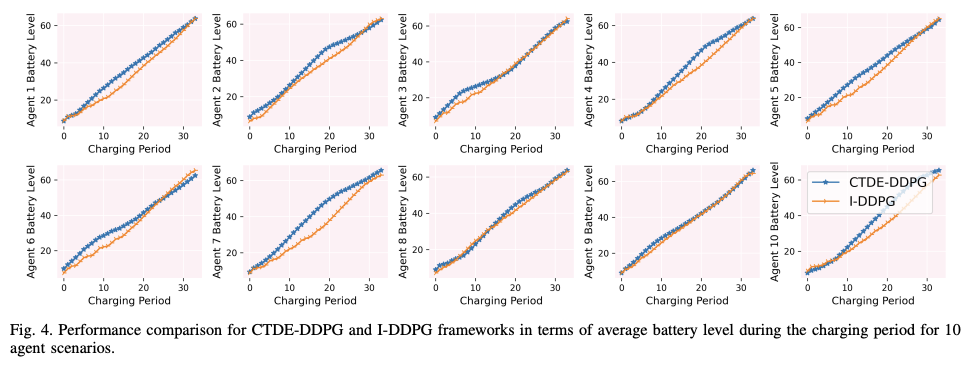 图 4 显示了 10 个代理的平均剩余电池容量。从图中可以看出,两种方法都能满足电动汽车用户的要求。
图 4 显示了 10 个代理的平均剩余电池容量。从图中可以看出,两种方法都能满足电动汽车用户的要求。
4.3 合作价值函数的影响。
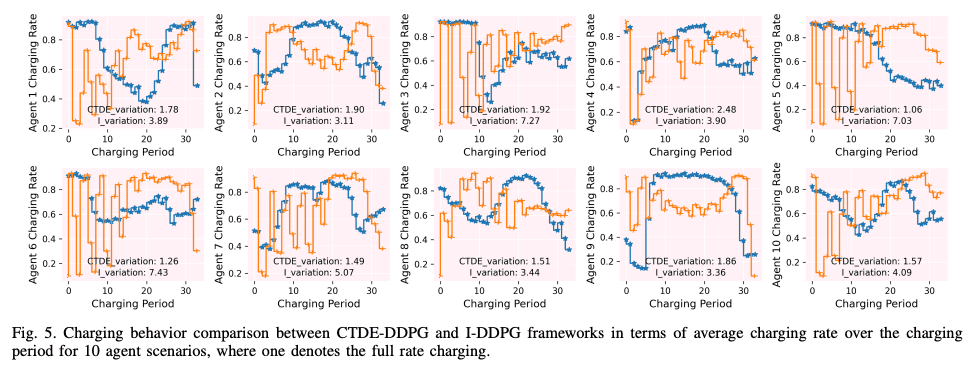 图 5 显示了 10 个药剂的平均充电率:I-DDPG 显示了一种振荡充电模式,而 CTDE-DDPG 显示了一种平滑充电模式。根据公式 (21) 的定义,CTDE-DDPG 的总变化(简称 TV)比 I-DDPG 小约 36%。
图 5 显示了 10 个药剂的平均充电率:I-DDPG 显示了一种振荡充电模式,而 CTDE-DDPG 显示了一种平滑充电模式。根据公式 (21) 的定义,CTDE-DDPG 的总变化(简称 TV)比 I-DDPG 小约 36%。
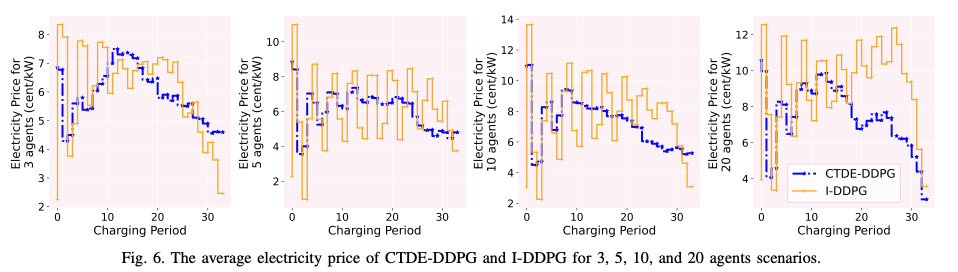
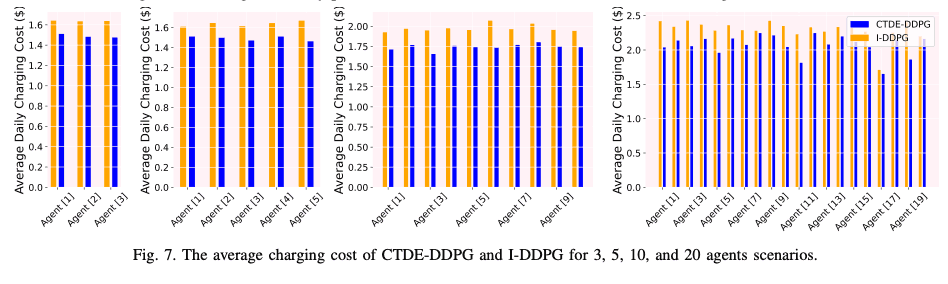 图 6 显示了平均电价,图 7 显示了每天的平均充电成本。代理数量越多,CTDE-DDPG 的价格/成本往往越低。
图 6 显示了平均电价,图 7 显示了每天的平均充电成本。代理数量越多,CTDE-DDPG 的价格/成本往往越低。
4.4 趋同与公平
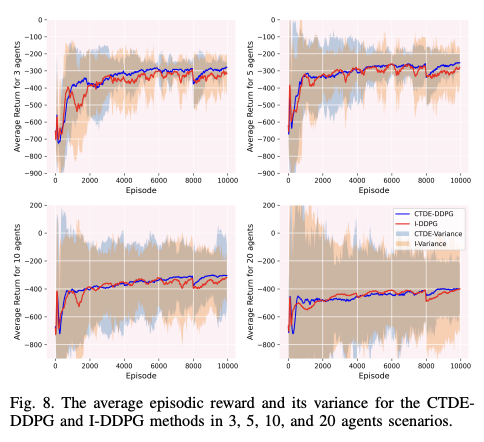 图 8 显示了平均每集奖励。两种方法都收敛于相同的策略,但方差往往更大。
图 8 显示了平均每集奖励。两种方法都收敛于相同的策略,但方差往往更大。
 图 9 显示了最差和最佳代理的性能比(公平性)。随着代理数量的增加,I-DDPG 的公平性下降了,而 CTDE-DDPG 则保持了良好的公平性。
图 9 显示了最差和最佳代理的性能比(公平性)。随着代理数量的增加,I-DDPG 的公平性下降了,而 CTDE-DDPG 则保持了良好的公平性。
根据理论分析,CTDE-DDPG 的政策梯度方差较大,但合作学习能够缓解非平稳性。这种合作有助于平滑收费模式、稳定价格和提高公平性。即使代理数量增加,CTDE-DDPG 的表现也很稳健。这些实验结果表明,CTDE-DDPG 是一种有效的分布式协调充电控制方法,可应用于大规模电动汽车网络。
5. 结论
本研究提出了一种用于电动汽车网络充电控制的集中式和分散式多代理强化学习方法,并从理论和实验两方面证明了该方法的有效性。所提出的方法既能提供高效的基于合作的充电控制,又能在执行过程中保护隐私。研究还发现,所提出的方法在大型电动汽车网络中具有鲁棒性。