作者:知乎@一根呆毛授权发布
传统的端到端网络是用多个小model串起来,但这会有误差累积的问题,因此我们提出了UniAD,一个综合框架,把所有任务整合到一个网络。整一个网络都是为planner而进行设计的。
Introduction
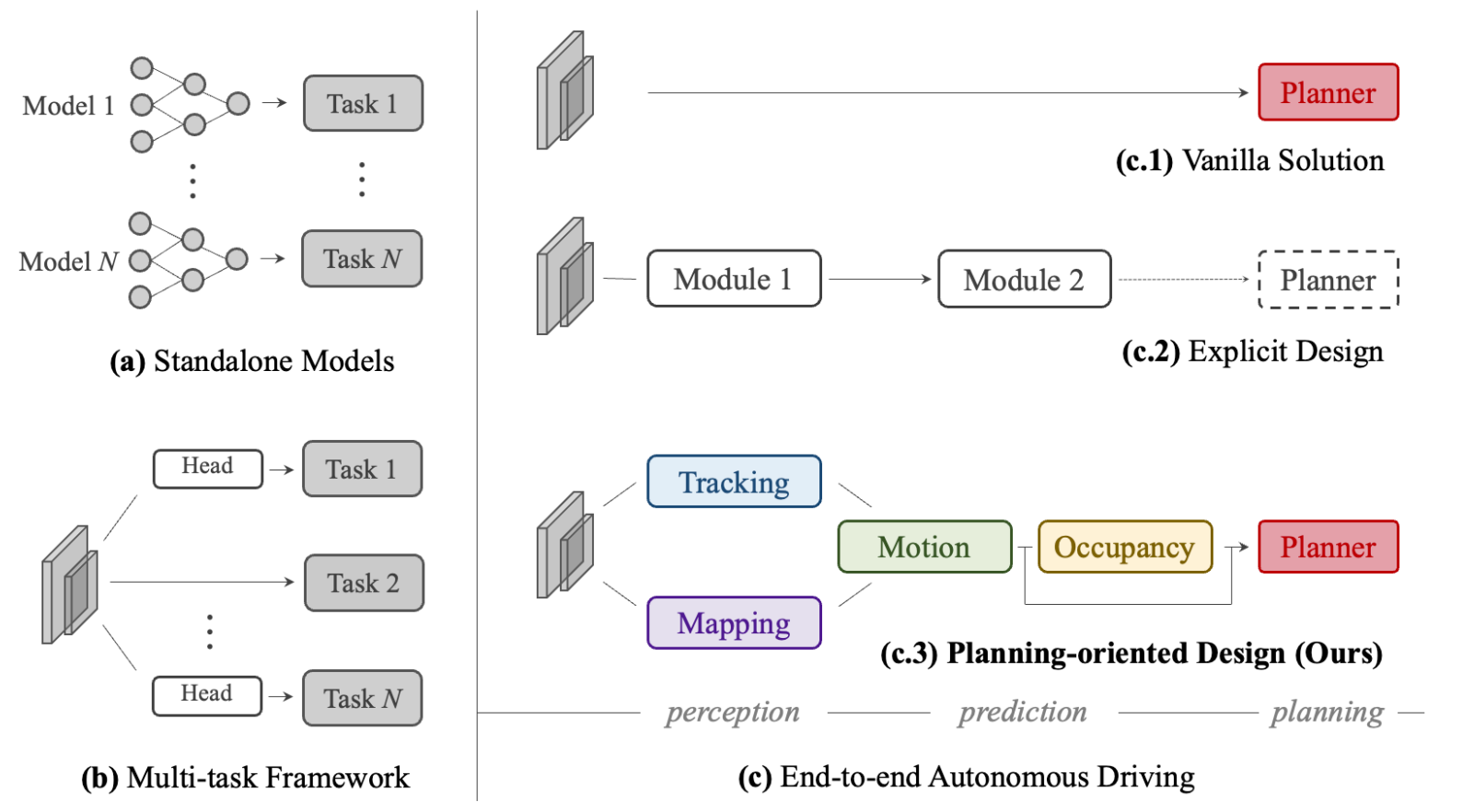
a传统方案:单独部署各个小model
b共享同一个backbone,但是分了多个不同的head
c.1. 直接一步到位从2D图到planner。但明显可解释性比较差,且安全缺乏保证。
c.2. 串联的形式,但以往的做法都没有完整地从头预测到planner,都只做了整条pipeline里的部分模块。
c.3. 一共使用了5个模块来处理所有的任务,真正的端到端,不是直接串联的形式。
把所有模块搭建起来的核心是使用了query的形式,而所有模块都采用了transformer的model。query的形式拥有更广阔的视野,可以对各种物体进行query,也因此能减少累积的误差。
Methodology
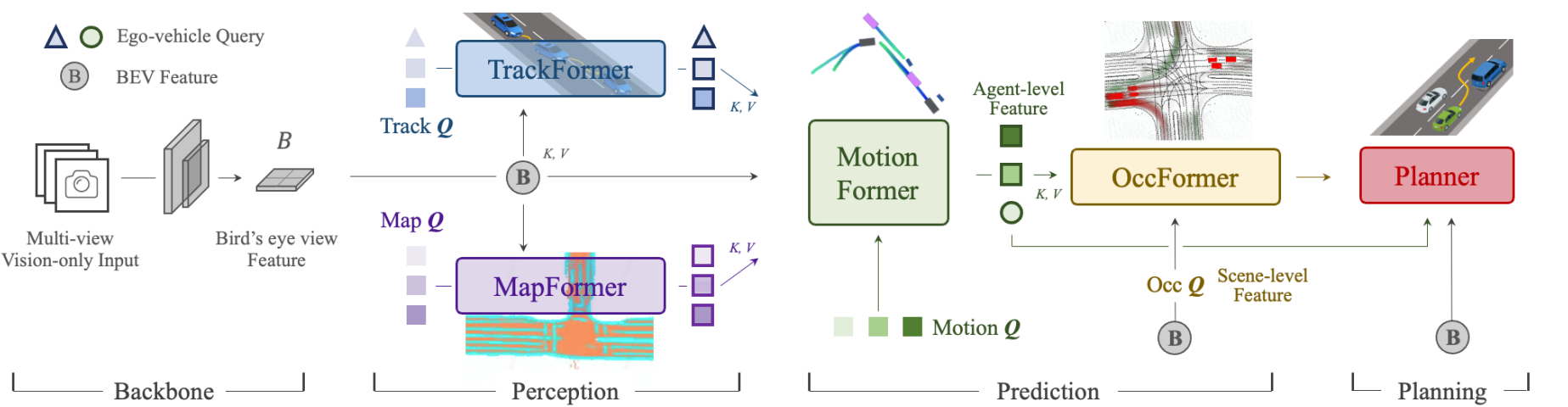
使用BEVFormer进行多相机的特征提取,投影查询建立鸟瞰图每个体素的特征,方便之后的模块拿到环境信息。TrackFormer负责从BEV中提取出agent的检测结果(同时也是track结果),得到的query其实也包含了一部分历史信息。MapFormer则是进行了地图的语义分割。MotionFormer负责建立agent和map之间的交互,得到joint的预测,同时也会处理ego和agent之间的交互给后续使用。OccFormer则使用BEV为query,motion为KV,进行每个时刻的占用网格预测。最后Planner使用之前的ego和agent交互的特征和来得到轨迹,以及用占用网格来使轨迹避免碰撞。
Perception
感知部分包含了tracking(agent的检测与跟踪)和mapping(map元素的特征提取)。
TrackFormer
使用DETR的做法,K和V都是BEV的结果,一开始query是固定给的embedding,然后输出detection结果,这些检测结果作为下一个时刻的query,用于tracking上一帧检测出来的物体,同时还会有新的空query(和最开始的一样)加入,用于检测新出现的物体。这样输出的结果就是每个agent的feature
Q
A
Q_A
QA
。在此基础上,还会有一个新的query来负责ego,这个query会在planning中使用。

MapFormer
使用Panoptic SegFormer的做法,只是变成了3D版。以此来进行BEV每个稀疏像素的分割。包含了lane, divider, crossing, drivable area. 最后输出的是稀疏的地图像素feature
Q
M
Q_M
QM。
Prediction
预测部分包含了motion预测和occupancy预测。
MotionFormer
MotionFormer使用感知部分得到的 Q A Q_A QA 和 Q M Q_M QM 信息作为K和V,预测k个mode的行为,都是scene-centric的(不是在agent坐标系下融合的)。这样可以一口气出结果,避免了转坐标系的计算。同时trackFormer的ego query也会放进来进行ego和agent间的交互。
先来看对于每个agent而言的motion query是怎么定义的。
首先是query position Q p o s Q_{pos} Qpos . 一共有4项,
Q p o s = MLP ( PE ( I s ) ) + MLP ( PE ( I a ) ) + MLP ( PE ( x ^ 0 ) ) + MLP ( PE ( x ^ T l − 1 ) ) \begin{aligned}Q_{\mathrm{pos}} & =\operatorname{MLP}\left(\operatorname{PE}\left(I^s\right)\right)+\operatorname{MLP}\left(\operatorname{PE}\left(I^a\right)\right) \\& +\operatorname{MLP}\left(\operatorname{PE}\left(\hat{\mathbf{x}}_0\right)\right)+\operatorname{MLP}\left(\operatorname{PE}\left(\hat{\mathbf{x}}_T^{l-1}\right)\right)\end{aligned} Qpos=MLP(PE(Is))+MLP(PE(Ia))+MLP(PE(x^0))+MLP(PE(x^Tl−1))
I
S
I^S
IS 是scene-level的anchor position。这个是全局坐标系中的ego的anchor轨迹(多mode)。
I
a
I^a
Ia 是agent-level的anchor position。这个是agent坐标系中的anchor轨迹(多mode)。
以上两个anchor都是从数据gt中用k-means获得的。
x
^
0
\hat{x}_0
x^0 是agent的当前位置。
x
^
T
l
−
1
\hat{x}_T^{l-1}
x^Tl−1 代表上一个transformer结构得到的预测 goal points(会有多层transformer结构进行不断微调预测轨迹) 。而一开始的这项则使用
I
S
I^S
IS 的goal points。
以上feature都经过positional embedding和MLP后再加起来一起作为一个agent的query。
后面还会讲到query context是怎么算的,这个 Q p o s Q_{pos} Qpos 和 Q c t x Q_{ctx} Qctx 共同组成多重交互的query Q。
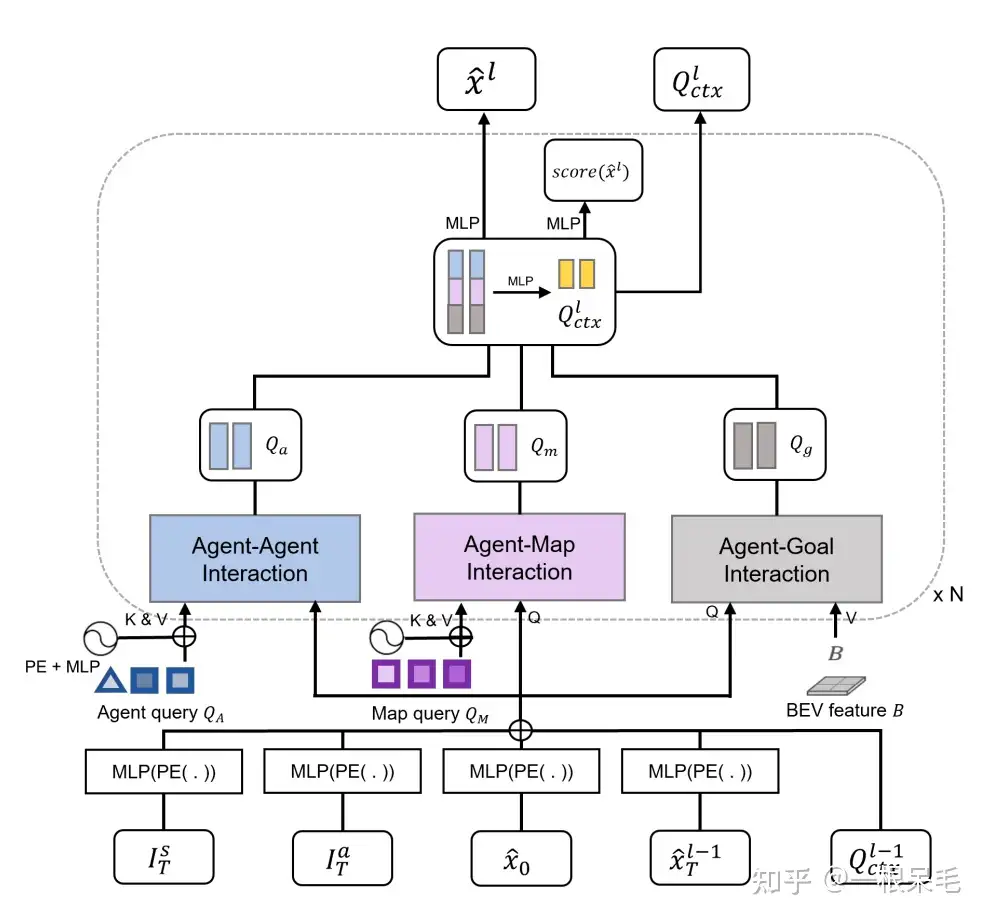
然后来看多重交互的框架。
整个交互模块由多个transformer组成,分为3种交互融合:agent和agent之间,agent和map之间,agent和goal之间。进行多次这样的模块,以实现先粗后细地不断调整轨迹到准确的轨迹。
对于agent间,agent和map的交互,都采用多头cross-attention。其中Q采用的是上面提到的再经过self attention. K和V则是 Q A Q_A QA或 Q M Q_M QM.
Q a / m = MHCA ( MHSA ( Q ) , Q A / Q M ) Q_{a / m}=\operatorname{MHCA}\left(\operatorname{MHSA}(Q), Q_A / Q_M\right) Qa/m=MHCA(MHSA(Q),QA/QM)
agent和goal之间的话,目标时学出朝着目标goal前进的能力。用deformable attention来处理,Q是上文提到的, K是上一个模块预测出的轨迹的最后一个点,V是整个BEV的feature。朝目标前进时需要看的V的feature一般不会只停留在固定的某个点上(只看goal那就不知道路上会不会有别的阻碍了),需要让它能动态学出到底取哪个位置的feature效果更好。
Q g = DeformAttn ( Q , x ^ T l − 1 , B ) Q_g=\operatorname{DeformAttn}\left(Q, \hat{\mathbf{x}}_T^{l-1}, B\right) Qg=DeformAttn(Q,x^Tl−1,B)
以上3个attention模块是并行的,最后得到
Q
a
Q_a
Qa,
Q
m
Q_m
Qm
Q
g
Q_g
Qg.
。将它们concat在一起后经过MLP得到一个query context
Q
c
t
x
Q_{ctx}
Qctx
. 这个东西会传递到下一个transformer模块里,或者说在最后一个模块后加上decoder得到最后的轨迹。
由于用于监督的gt本身可能存在noise(因为所谓的gt也是用感知model得到的,自然会有noise),因此还加上了Non-linear Optimization来让gt变得更平滑,这样拿来监督的话就会更符合现实。
定义优化轨迹的cost function:被smooth的轨迹和gt之间,需要有3项限制,轨迹之间点点的距离,轨迹的goal之间的距离,以及smooth的轨迹本身的物理量之间的运动学关系。希望这个函数最小。
c ( x , x ~ ) = λ x y ∥ x , x ~ ∥ 2 + λ goal ∥ x T , x ~ T ∥ 2 + ∑ ϕ ∈ Φ ϕ ( x ) c(\mathbf{x}, \tilde{\mathbf{x}})=\lambda_{\mathrm{xy}}\|\mathbf{x}, \tilde{\mathbf{x}}\|_2+\lambda_{\text {goal }}\left\|\mathbf{x}_T, \tilde{\mathbf{x}}_T\right\|_2+\sum_{\phi \in \Phi} \phi(\mathbf{x}) c(x,x~)=λxy∥x,x~∥2+λgoal ∥xT,x~T∥2+ϕ∈Φ∑ϕ(x)
而被优化出来的轨迹就是能让上面这个函数最小的轨迹,其中优化过程中采用了multiple-shooting的方法,应该是分段进行优化,而不是一口气把所有点都优化了。
x ~ ∗ = arg min x c ( x , x ~ ) \tilde{\mathbf{x}}^*=\arg \min _{\mathbf{x}} c(\mathbf{x}, \tilde{\mathbf{x}}) x~∗=argxminc(x,x~)
OccFormer
occupancy grid map是一个离散的BEV,但是一个表示未来是否被占用的BEV。之前的做法使用RNN结构来建模。但这样依赖于手工处理每个agent的未来占用,因为在压缩整个BEV的特征时,里面有很多和agent无关的信息,因此很难预测agent的行为。因此提出了OccFormer,来兼顾scene和agent的feature。对于scene而言,在预测未来的时刻的信息时,需要agent的feature来进行attention,使用矩阵相乘的方法来融合agent的feature和scene的feature,这么做不需要太多的后处理。
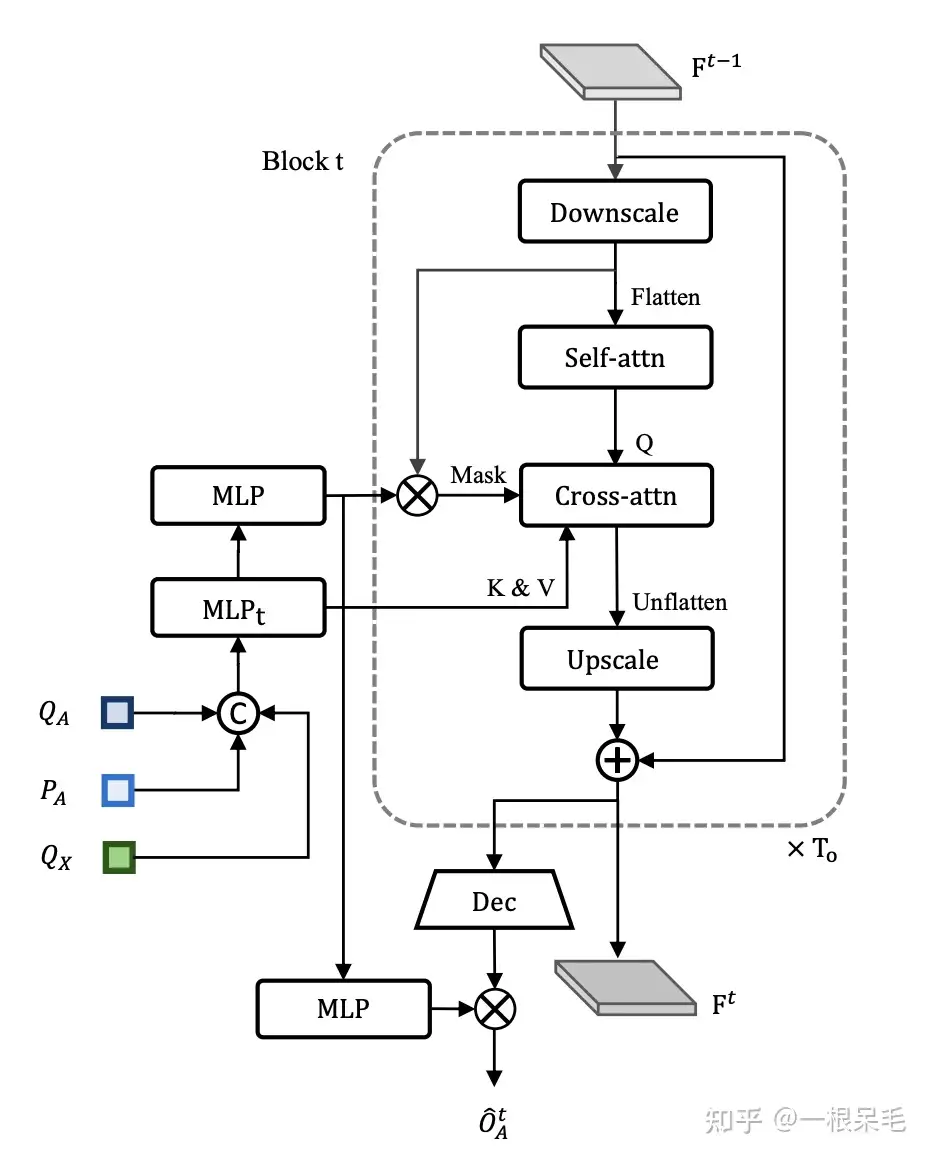
OccFormer一共有 T o T_o To 个连续的block形成RNN的结构, T o T_o To 代表的是预测的时刻,一般来说比 motion任务的丁更小。每个block的输入是agent的feature G t G^t Gt 和上一个block的state F t − 1 F^{t-1} Ft−1 ,输出是 F t F^t Ft ,包含了t时刻的instance和scene的信息. 从MotionFormer的结果里在模态维度进行 max-pool得到agent的motion预测query Q X ∈ R N a × D Q_X \in R^{N_a \times D} QX∈RNa×D ,同时还有上游的track query Q A Q_A QA ,以及当前位置的position embedding + P A { }^{+} P_A +PA ,一起concat后用MLP处理得到每个时刻的agent feature G t G^t Gt.
G t = MLP t ( [ Q A , P A , Q X ] ) , t = 1 , … , T o G^t=\operatorname{MLP}_t\left(\left[Q_A, P_A, Q_X\right]\right), t=1, \ldots, T_o Gt=MLPt([QA,PA,QX]),t=1,…,To
而对于场景信息,使用BEV特征B,作为初始的state F 0 F^0 F0, 实际使用时先下采样到1/4(为了运算快)输入,输出前再上采样,以此来节省算力。
Pixel-agent interaction
Instance feature G t G^t Gt 作为K和V,而下采样的 F t F^t Ft(写为 F d s t F_{ds}^t Fdst)经过一次self-attnetion作为Q,然后进行cross-attention,以此来不断获得每个时刻的BEV的占用。这个cross-attention会使用mask,这个mask时确保了每个像素只能看到占据这个像素的物体所占据的所有像素(考虑其他物体的像素并没有太大意义,因为一个像素不可能被两个物体霸占)。
D d s t = MHCA ( MHSA ( F d s t ) , G t , attn mask = O m t ) D_{\mathrm{ds}}^t=\operatorname{MHCA}\left(\operatorname{MHSA}\left(F_{\mathrm{ds}}^t\right), G^t, \text { attn mask }=O_m^t\right) Ddst=MHCA(MHSA(Fdst),Gt, attn mask =Omt)
Instance-level occupancy
对于agent level的占用,是需要判断每一个agent的占用情况。使用一个decode网络,提取出一个scene-level的BEV占用 F d e c t ∈ R C × H × W F_{d e c}^t \in R^{C \times H \times W} Fdect∈RC×H×W. 然后用之前的mask输出过一个MLP得到的 U t ∈ R N a × C U^t \in R^{N_a \times C} Ut∈RNa×C 和这个占用进行矩阵相乘,以提取出每个agent的占用。
O ^ A t = U t ⋅ F d e c t \hat{O}_A^t=U^t \cdot F_{\mathrm{dec}}^t O^At=Ut⋅Fdect
Planning
此paper不使用高精地图以及route,而是使用导航的信号 (比如左转,右转,前进)。把这些信号embed进learnable embeddings。由于在MotionFormer中已经有了ego的多mode的输出 Q c t x e g o Q_{c t x}^{e g o} Qctxego ,并且trackFormer里也提取出了ego的的feature Q A ego Q_A^{\text {ego }} QAego ,于是可以把他们三者组合在一起,成为plan query。以此query可以在BEV feature里取周遭的特征,然后decode为未来的 waypoints τ ^ \hat{\tau} τ^.
而为了避免碰撞,则是采用了优化控制的办法,使用了Newton法来找出能使碰撞函数最小的轨迹。它的输入是规划的轨迹 τ ^ \hat{\tau} τ^ ,新的轨迹 τ \tau τ ,以及占用网格 O ^ \hat{O} O^.
τ ∗ = arg min f ( τ , τ ^ , O ^ ) \tau^*=\arg \min f(\tau, \hat{\tau}, \hat{O}) τ∗=argminf(τ,τ^,O^)
而对cost函数的定义如下
f ( τ , τ ^ , O ^ ) = λ coord ∥ τ , τ ^ ∥ 2 + λ obs ∑ t D ( τ t , O ^ t ) D ( τ t , O ^ t ) = ∑ ( x , y ) ∈ S 1 σ 2 π exp ( − ∥ τ t − ( x , y ) ∥ 2 2 2 σ 2 ) \begin{gathered}f(\tau, \hat{\tau}, \hat{O})=\lambda_{\text {coord }}\|\tau, \hat{\tau}\|_2+\lambda_{\text {obs }} \sum_t \mathcal{D}\left(\tau_t, \hat{O}^t\right) \\\mathcal{D}\left(\tau_t, \hat{O}^t\right)=\sum_{(x, y) \in \mathcal{S}} \frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{\left\|\tau_t-(x, y)\right\|_2^2}{2\sigma^2}\right)\end{gathered} f(τ,τ^,O^)=λcoord ∥τ,τ^∥2+λobs t∑D(τt,O^t)D(τt,O^t)=(x,y)∈S∑σ2π1exp(−2σ2∥τt−(x,y)∥22)
这个cost函数的目标是和规划的轨迹尽可能接近,同时碰撞尽可能少。cost函数里的碰撞loss则是在对应时刻选择网格内和轨迹点距离小于一定阈值的,且被占用的网格,去计算这些网格和这个轨迹点之间的差异之和(采用高斯分布来算,应该能起到一定的平滑效果)。

Learning
训练过程是两阶段的,第一阶段训练感知部分,训练几个epoch后,再把所有模块一起训练,这样会更加stable
🏎️自动驾驶小白说官网:https://www.helloxiaobai.cn