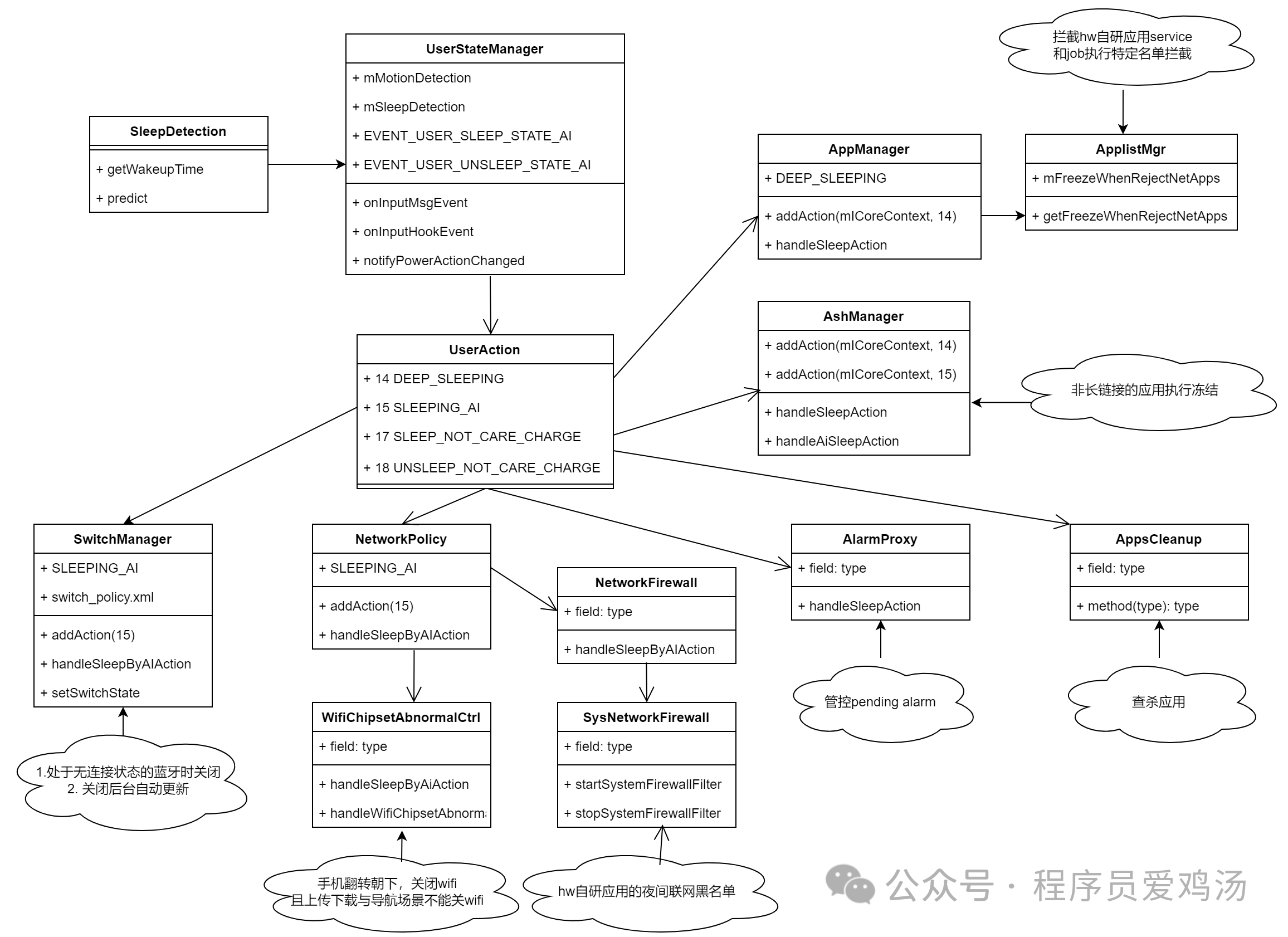
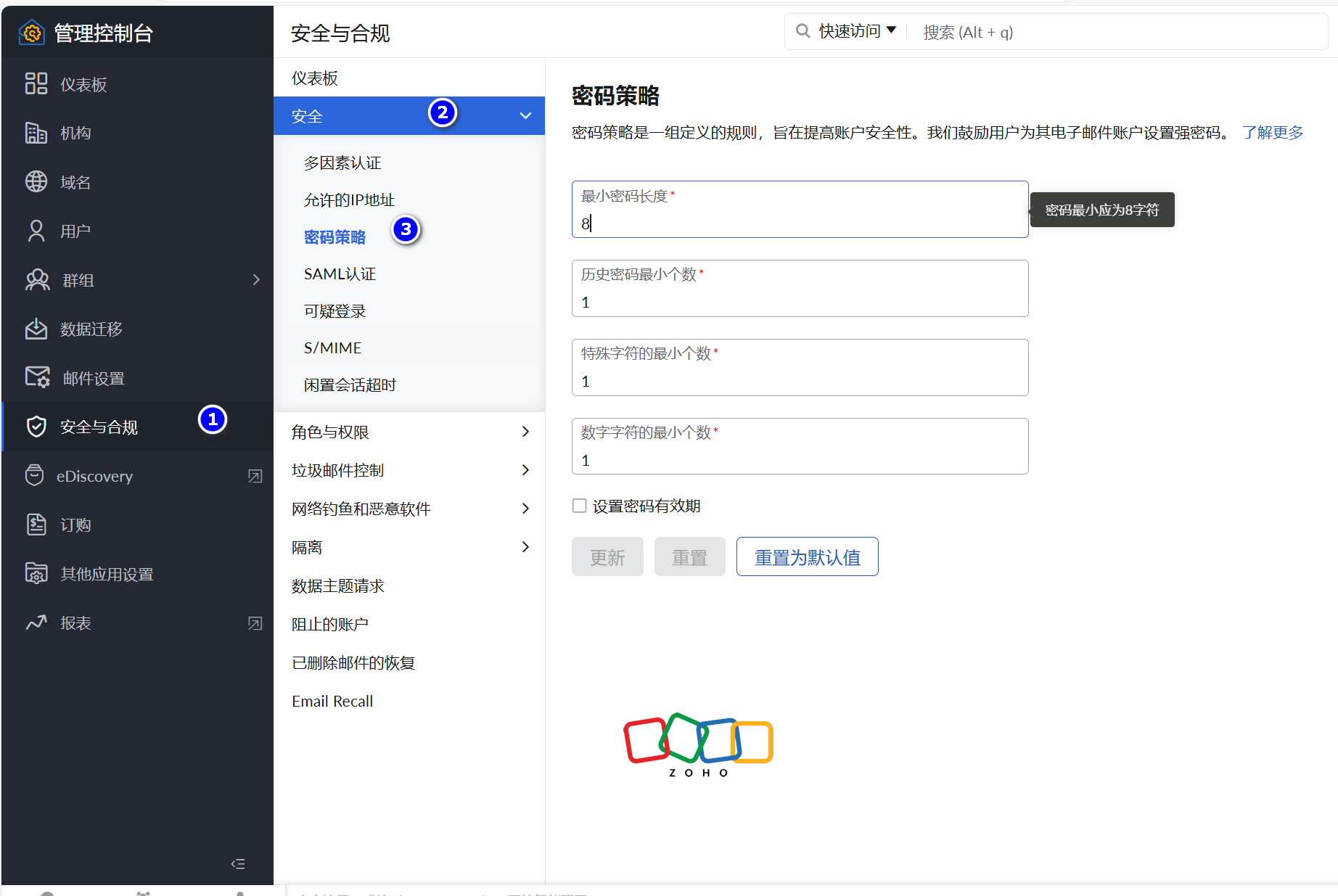
Linux的习题

Linux环境与版本
1.linux 2.6.* 内核默认支持的文件系统有哪些?[多选]
A.ext3
B.ext2
C.ext4
D.xfs
E.ufs
正确答案:ABCD
A 全称Linux extended file system, extfs,即Linux扩展文件系统,ext2为第二代
D XFS一种高性能的日志文件系统,2000年5月,Silicon Graphics以GNU通用公共许可证发布这套系统的源代码,之后被移植到Linux 内核上。XFS 特别擅长处理大文件,同时提供平滑的数据传输
E UFS是UNIX文件系统的简称,它来源于4.3Tahoe发行版中提供的BSD Fat Fast File System(FFS)系统,属于FFS的演化版本
2.以下哪个命令输出Linux内核的版本信息:
A.uname -r
B.vmstat
C.sar
D.stat
正确答案:A
uname -r 查看linux内核版本信息
vmstat 报告关于内核线程、虚拟内存、磁盘、陷阱和 CPU 活动的统计信息
sar 主要帮助我们掌握系统资源的使用情况,特别是内存和CPU的使用情况
stat 用于显示文件的状态信息
3.Linux 有三个查看文件的命令,若希望在查看文件内容过程中可以用光标上下移动来查看文件内容,应使用命令。
A.cat
B.more
C.less
D.menu
正确答案:C
A cat 打印文件内容到终端显示
B more 分页显示文件内容,但是通常向上翻页不好使
C less 分页显示文件内容,可以灵活上下移动光标和翻页
D menu 没有这个指令(至少centos7上默认没有这个命令)
4.在使用mkdir命令创建新的目录时,在其父目录不存在时先创建父目录的选项是
A.-m
B.-d
C.-f
D.-p
正确答案:D
A -m 在创建目录的同时设置权限
B -d 没有这个选项
C -f 没有这个选项
D -p 在创建多层级目录的时候若上级目录不存在则创建
5.在Linux系统中, 为找到文件try_grep含有以a字母为行开头的内容, 可以使用命令?
A.grep -E #$ try_grep
B.grep -E #a try_grep
C.grep -E ^$ try_grep
D.grep -E ^a try_grep
正确答案:D
grep选项中,-E选项可以用来扩展选项为正则表达式;
$ 表示匹配文件末尾,字符需要在 $ 之前表示以字符结尾 a$表示以a结尾
表示匹配文件起始,字符需要在之后表示以字符起始 ^a表示以a起始
6.linux查看cpu占用的命令是什么?
A.top
B.netstat
C.free
D.df
正确答案:A
A top 查看cpu资源使用状态
B netstat 查看网络连接状态
C free 查看内存资源状态
D df 查看磁盘分区资源状态
7.批量删除当前目录下后缀名为.c的文件。如a.c、b.c。
A.rm *.c
B.find . -name “*.c” -maxdepth 1 | xargs rm
C.find . -name “*.c” | xargs rm
D.以上都不正确
正确答案:AB
A rm *.c *通配符,表示匹配任意字符任意次
B find . -name “*.c” -maxdepth 1 | xargs rm
find . -name “*.c” -maxdepth 1 找到当前目录下.*结尾的文件,目录深度为1
xargs是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令,用于很多不支持|管道来传递参数的命令
相当于将前边命令的执行结果,也就是查找到的文件名,传递给后边的rm指令进行删除
C find . -name “*.c” | xargs rm 没有进行深度控制,删除的不仅是当前目录下的文件,会将子目录下的文件也删除
D 以上都不正确
电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

示例 1:
输入:digits = "23"
输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]
示例 2:
输入:digits = ""
输出:[]
示例 3:
输入:digits = "2"
输出:["a","b","c"]
提示:
0 <= digits.length <= 4digits[i]是范围['2', '9']的一个数字。
题目解析:

讲解算法原理:

解法:**
算法思路:
每个位置可选择的字符与其他位置并不冲突,因此不需要标记已经出现的字符,只需要将每个数字对 应的字符依次填⼊字符串中进⾏递归,在回溯是撤销填⼊操作即可。
在递归之前我们需要定义⼀个字典 hash,记录 2~9 各⾃对应的字符。
递归函数设计:void backtrack(unordered_map& phoneMap, string& digits, int index)
参数:index (已经处理的元素个数),ans (字符串当前状态),res (所有成⽴的字符串);
返回值:⽆
函数作⽤:查找所有合理的字⺟组合并存储在答案列表中。
递归函数流程如下:
- 递归结束条件:当 index 等于 digits 的⻓度时,将 ans 加⼊到 res 中并返回;
- 取出当前处理的数字 digit,根据 phoneMap 取出对应的字⺟列表 letters;
- 遍历字⺟列表 letters,将当前字⺟加⼊到组合字符串 ans 的末尾,然后递归处理下⼀个数字(传 ⼊ index + 1,表⽰处理下⼀个数字);
- 递归处理结束后,将加⼊的字⺟从 ans 的末尾删除,表⽰回溯。
- 最终返回 res 即可。
class Solution {
public:
string hash[10]={"","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"};
string path;
vector<string> ret;
vector<string> letterCombinations(string digits) {
//判断是否有元素,如果元素为0,返回空的ret
if(digits.size()==0) return ret;
//如果是0或者1,返回空的ret
dfs(digits,0); return ret;
}
//引用返回,减少时间复杂度
void dfs(string&digits,int pos)
{
//如果递归到底,往path里面进行尾插元素,并返回
if(pos==digits.size())
{
ret.push_back(path);
return;
}
//如果还未到底,继续递归,得到下标要ASCLL减去字符‘0’的ASCLL值
for(auto ch :hash[digits[pos]-'0'])
{
//尾插
path.push_back(ch);
//往下递归
dfs(digits,pos+1);
path.pop_back();
//恢复现场
}
}
};