本节重点介绍 :
- 降低采集资源消耗的收益
- 哪些是无用指标,什么判定依据
- 通过 grafana的 mysql 表获取所有的 查询表达式expr
- 通过 获取所有的prometheus rule文件获取所有的 告警表达式expr
- 通过 获取所有的prometheus 采集器接口 获取所有的采集metrics
- 计算可得到现在没用到的metrics列表
- 计算方法为 所有采集到的-(告警的+看图的)
降低采集资源消耗的收益
- 缓存系统内存使用降低
- 监控系统为了加快查询速度会在各个环节上设置缓存
- 那么如果采集指标过多,无疑会使缓存内存使用变多
- 存储系统磁盘使用降低
- 持久话存储的磁盘使用量和监控指标的数量是成正比的
- 组件间网络传输流量降低
- 更多的监控指标数据意味着,组件间网络传输流量更大
- 查询速度提升降低
- 更多的监控指标意味着查询的速度会被拖慢
收益实例
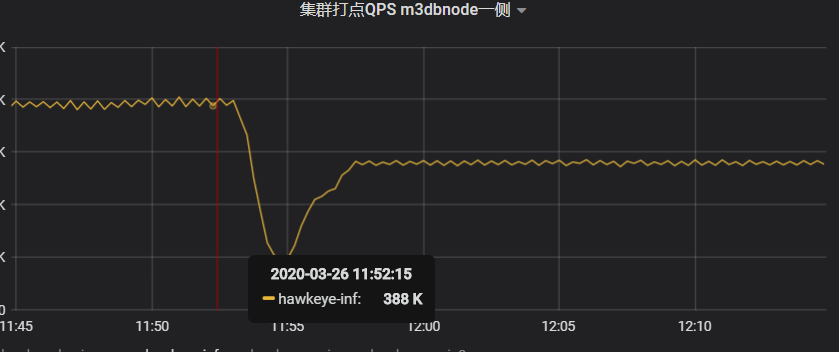
- 分析cadvisor 和 node_exporter中可以被drop的指标及其采集方式,去掉后 采集qps下降25%
哪些是无用指标,什么判定依据
- 一句话就可以总结 :always collect ,never used
指标的使用
- 看图使用
- 告警使用
那么系统中除了看图和告警使用的指标理论上都可以去掉
- 但是要注意的点是,有些指标今天没用到是还没发现它的意义
- 有可能明天就会使用
具体的判定依据
看图侧
- 假设所有的看图都配置在grafana中
- 通过grafana 的dashboard 接口或者 grafana的 mysql 表获取所有的 查询表达式expr
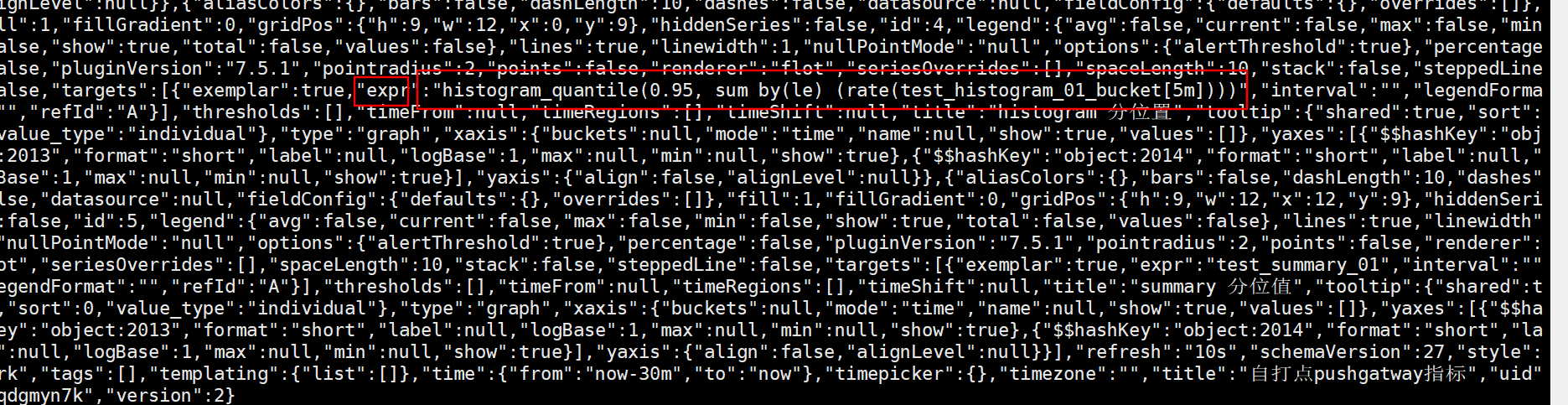
- 对应就是众多的promql,在其中解析出所有的metrics
- 就可以获得看图侧的 metrics 列表 ,可以命名为graph_metrics_set
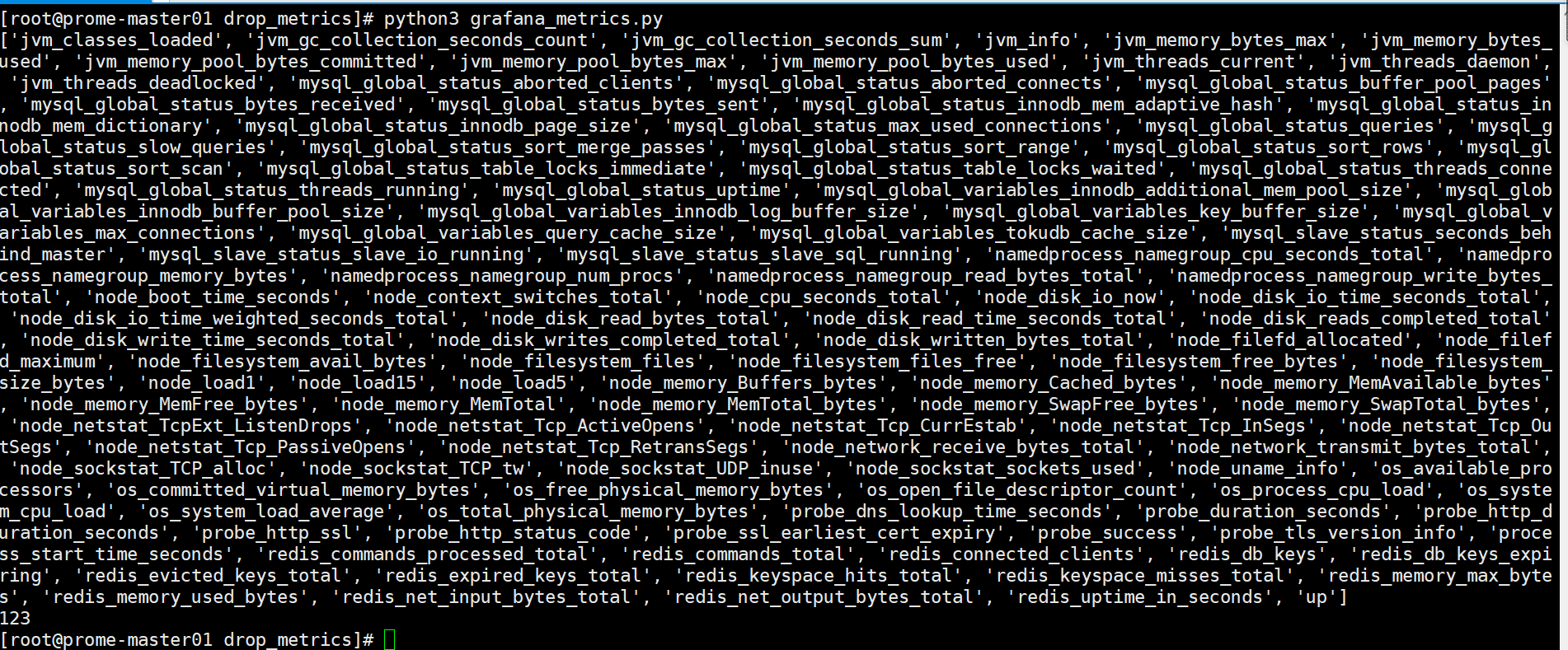
python脚本
- 创建db对象连接grafana 数据库
- 查询所有的 dashboard
- 遍历dashboard中的panel 对象获取 expr对象
- 将expr和prometheus metric 正则匹配,匹配到就是metric
# pip install sqlalchemy PyMySQL
import re
import json
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
METRIC_NAME_RE = re.compile(r'.*?([a-zA-Z_:][a-zA-Z0-9_:]*){.*?')
GRAFANA_SLAVE_DB_HOST = "172.20.70.205"
GRAFANA_SLAVE_DB_PORT = 3306
GRAFANA_SLAVE_DB_USER = "root"
GRAFANA_SLAVE_DB_PASS = "123123"
def init_grafana_db_session():
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/grafana'.format(
GRAFANA_SLAVE_DB_USER,
GRAFANA_SLAVE_DB_PASS,
GRAFANA_SLAVE_DB_HOST,
GRAFANA_SLAVE_DB_PORT))
# 创建DBSession类型:
dbSession = sessionmaker(bind=engine, autocommit=True)
return dbSession()
def get_metrics_from_grafana_db():
ds = init_grafana_db_session()
res = ds.execute('select data,slug from dashboard ')
exprs = set()
for r in res:
try:
data = json.loads(r[0])
panels = data.get("panels")
if not panels:
continue
for p in panels:
if not p:
continue
targets = p.get("targets")
if not targets:
continue
for i in targets:
ee = i.get("expr")
ddd = METRIC_NAME_RE.findall(ee)
exprs.update(set(ddd))
except Exception as e:
print(e)
ss = sorted(list(exprs))
print(ss)
return ss
get_metrics_from_grafana_db()
告警侧
- 获取所有的prometheus rule文件
- 根据rule文件中的promql 解析出metrics,可以命名为 alert_metrics_set
python 脚本
- 打开rule yaml 文件,逐行获取
- 用正则匹配,匹配到的即为metric
import re
METRIC_NAME_RE = re.compile(r'.*?([a-zA-Z_:][a-zA-Z0-9_:]*){.*?')
def get_metrics_from_rule_file(rule_file):
exprs = set()
with open(rule_file, encoding='UTF-8') as f:
for i in f.readlines():
if not "expr" in i:
continue
ddd = METRIC_NAME_RE.findall(i)
exprs.update(set(ddd))
ss = sorted(list(exprs))
print(ss)
return ss
get_metrics_from_rule_file("rule.yml")
采集侧
- 根据所有的采集器的接口获取其对应的metrics列表,对应接口如下
/api/v1/label/__name__/values
- 意思是获取__name__标签的values列表,也就是所有的metircs_name
- 截图
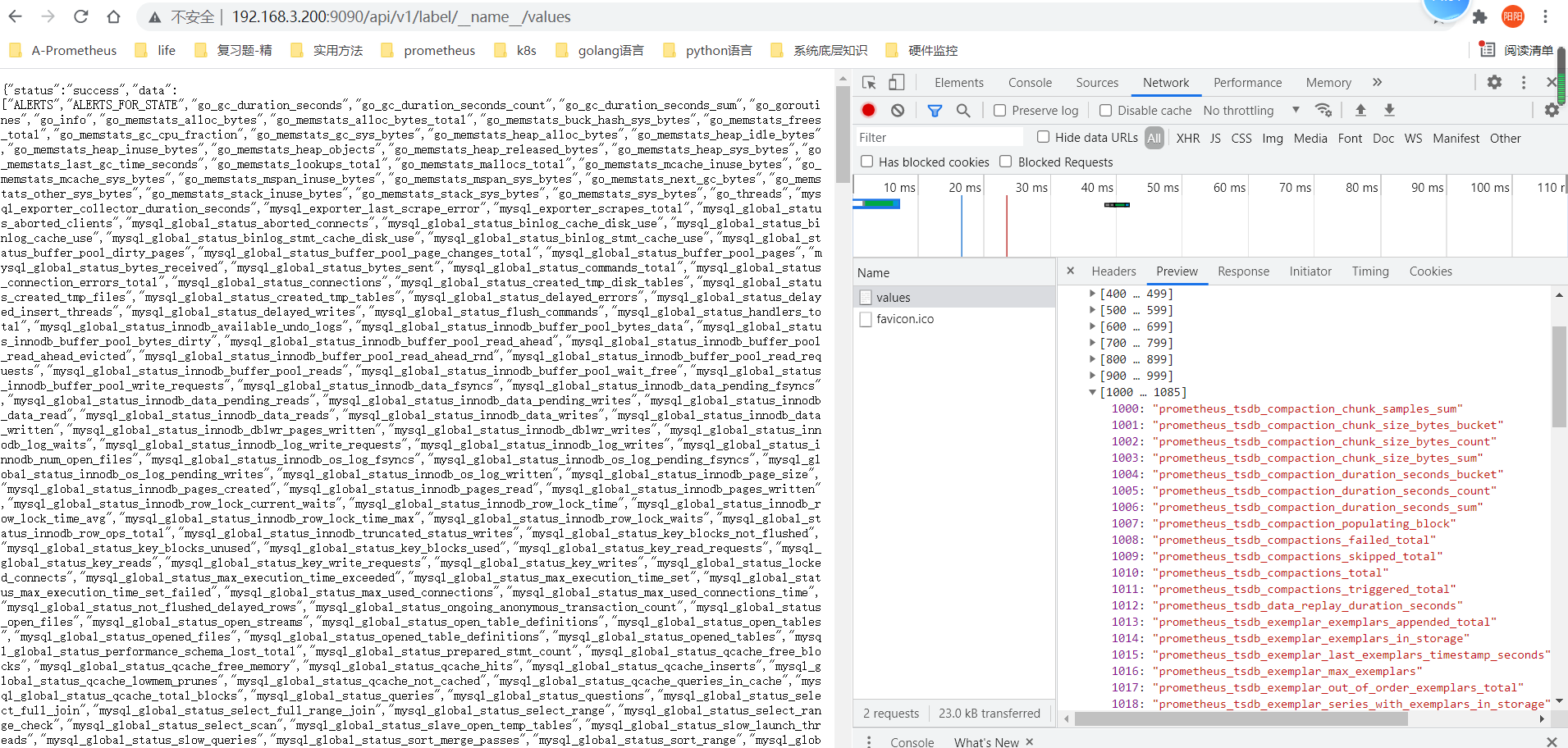
- 可以命名为 scrape_metrics_set
python脚本
import requests
def get_metrics_names(host):
url = "http://{}/api/v1/label/__name__/values".format(host)
res = requests.get(url)
print(res.status_code)
exprs = res.json().get("data")
if not exprs:
return
ss = sorted(list(exprs))
print(ss)
return ss
get_metrics_names("172.20.70.215:8091")
计算可得到现在没用到的metrics列表
- 计算方法为 所有采集到的-(告警的+看图的)
scrape_metrics_set - (alert_metrics_set + graph_metrics_set)
本节重点总结 :
- 降低采集资源消耗的收益
- 哪些是无用指标,什么判定依据
- 通过 grafana的 mysql 表获取所有的 查询表达式expr
- 通过 获取所有的prometheus rule文件获取所有的 告警表达式expr
- 通过 获取所有的prometheus 采集器接口 获取所有的采集metrics
- 计算可得到现在没用到的metrics列表
- 计算方法为 所有采集到的-(告警的+看图的)